
Elasticsearch Recovery详解
基础知识点
在Eleasticsearch中recovery指的就是一个索引的分片分配到另外一个节点的过程;一般在快照恢复、索引副本数变更、节点故障、节点重启时发生。由于master保存整个集群的状态信息,因此可以判断出哪些shard需要做再分配,以及分配到哪个结点,例如:
- 如果某个shard主分片在,副分片所在结点挂了,那么选择另外一个可用结点,将副分片分配(allocate)上去,然后进行主从分片的复制;
- 如果某个shard的主分片所在结点挂了,副分片还在,那么将副分片升级为主分片,然后做主从分片复制;
- 如果某个shard的主副分片所在结点都挂了,则暂时无法恢复,等待持有相关数据的结点重新加入集群后,从该结点上恢复主分片,再选择另外的结点复制副分片。
正常情况下,我们可以通过ES的health的API接口,查看整个集群的健康状态和整个集群数据的完整性:
状态及含义如下:
- green: 所有的shard主副分片都是正常的;
- yellow: 所有shard的主分片都完好,部分副分片没有或者不完整,数据完整性依然完好;
- red: 某些shard的主副分片都没有了,对应的索引数据不完整。
ecovery过程要消耗额外的资源,CPU、内存、结点之间的网络带宽等等。 这些额外的资源消耗,有可能会导致集群的服务性能下降,或者一部分功能暂时不可用。了解一些recovery的过程和相关的配置参数,对于减小recovery带来的资源消耗,加快集群恢复过程都是很有帮助的。
减少集群Full Restart造成的数据来回拷贝
ES集群可能会有整体重启的情况,比如需要升级硬件、升级操作系统或者升级ES大版本。重启所有结点可能带来的一个问题: 某些结点可能先于其他结点加入集群, 先加入集群的结点可能已经可以选举好master,并立即启动了recovery的过程,由于这个时候整个集群数据还不完整,master会指示一些结点之间相互开始复制数据。
那些晚到的结点,一旦发现本地的数据已经被复制到其他结点,则直接删除掉本地“失效”的数据。 当整个集群恢复完毕后,数据分布不均衡,显然是不均衡的,master会触发rebalance过程,将数据在节点之间挪动。
整个过程无谓消耗了大量的网络流量;合理设置recovery相关参数则可以防范这种问题的发生。
gateway.expected_nodes
gateway.expected_master_nodes
gateway.expected_data_nodes
以上三个参数是说集群里一旦有多少个节点就立即开始recovery过程。 不同之处在于,第一个参数指的是master或者data节点都算在内,而后面两个参数则分指master和data node。
在期待的节点数条件满足之前, recovery过程会等待gateway.recover_after_time (默认5分钟) 这么长时间,一旦等待超时,则会根据以下条件判断是否启动:
gateway.recover_after_nodes
gateway.recover_after_master_nodes
gateway.recover_after_data_nodes
举例来说,对于一个有10个data node的集群,如果有以下的设置:
gateway.expected_data_nodes: 10
gateway.recover_after_time: 5m
gateway.recover_after_data_nodes: 8
那么集群5分钟以内10个data node都加入了,或者5分钟以后8个以上的data node加入了,都会立即启动recovery过程。
减少主副本之间的数据复制
如果不是full restart,而是重启单个data node,仍然会造成数据在不同结点之间来回复制。为避免这个问题,可以在重启之前,先关闭集群的shard allocation:
然后在节点重启完成加入集群后,再重新打开: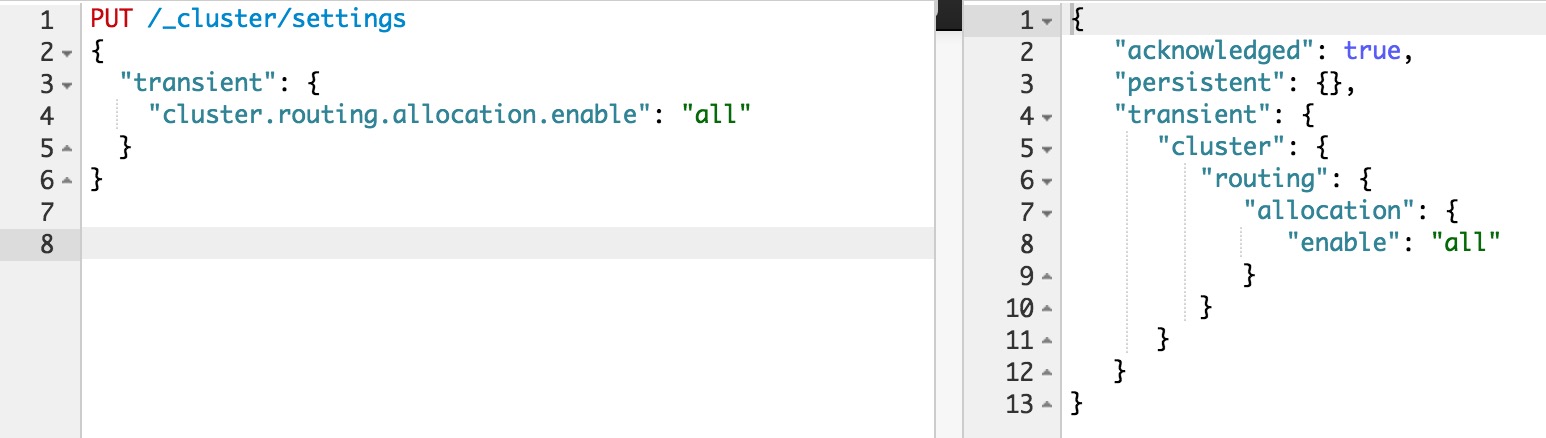
这样在节点重启完成后,尽量多的从本地直接恢复数据。
但是在ES1.6版本之前,即使做了以上措施,仍然会发现有大量主副本之间的数据拷贝。从表面去看,这点很让人不能理解。 主副本数据完全一致,ES应该直接从副本本地恢复数据就好了,为什么要重新从主片再复制一遍呢? 原因在于recovery是简单对比主副本的segment file来判断哪些数据一致可以本地恢复,哪些不一致需要远端拷贝的。而不同节点的segment merge是完全独立运行的,可能导致主副本merge的深度不完全一样,从而造成即使文档集完全一样,产生的segment file却不完全一样。
为了解决这个问题,ES1.6版本以后加入了synced flush的新特性。 对于5分钟没有更新过的shard,会自动synced flush一下,实质是为对应的shard加了一个synced flush ID。这样当重启节点的时候,先对比一下shard的synced flush ID,就可以知道两个shard是否完全相同,避免了不必要的segment file拷贝,极大加快了冷索引的恢复速度。
需要注意的是synced flush只对冷索引有效,对于热索引(5分钟内有更新的索引)没有作用。 如果重启的结点包含有热索引,那么还是免不了大量的文件拷贝。因此在重启一个结点之前,最好按照以下步骤执行,recovery几乎可以瞬间完成:
- 暂停数据写入程序
- 关闭集群shard allocation
- 手动执行POST /_flush/synced
- 重启节点
- 重新开启集群shard allocation
- 等待recovery完成,集群health status变成green
- 重新开启数据写入程序
特大热索引为何恢复慢
对于冷索引,由于数据不再更新,利用synced flush特性,可以快速直接从本地恢复数据。 而对于热索引,特别是shard很大的热索引,除了synced flush派不上用场需要大量跨节点拷贝segment file以外,translog recovery是导致慢的更重要的原因。
从主片恢复数据到副片需要经历3个阶段:
- 对主片上的segment file做一个快照,然后拷贝到复制片分配到的结点。数据拷贝期间,不会阻塞索引请求,新增索引操作记录到translog里;
- 对translog做一个快照,此快照包含第一阶段新增的索引请求,然后重放快照里的索引操作。此阶段仍然不阻塞索引请求,新增索引操作记录到translog里;
- 为了能达到主副片完全同步,阻塞掉新索引请求,然后重放阶段二新增的translog操作。
可见,在recovery完成之前,translog是不能够被清除掉的(禁用掉正常运作期间后台的flush操作)。如果shard比较大,第一阶段耗时很长,会导致此阶段产生的translog很大。重放translog比起简单的文件拷贝耗时要长得多,因此第二阶段的translog耗时也会显著增加。等到第三阶段,需要重放的translog可能会比第二阶段还要多。 而第三阶段是会阻塞新索引写入的,在对写入实时性要求很高的场合,就会非常影响用户体验。 因此,要加快大的热索引恢复速度,最好的方式是遵从上一节提到的方法: 暂停新数据写入,手动sync flush,等待数据恢复完成后,重新开启数据写入,这样可以将数据延迟影响可以降到最低。
万一遇到Recovery慢,想知道进度怎么办呢? CAT Recovery API可以显示详细的recovery各个阶段的状态。 这个API怎么用就不在这里赘述了,参考: CAT Recovery。
其他Recovery相关的专家级设置
还有其他一些专家级的设置(参考: recovery)可以影响recovery的速度,但提升速度的代价是更多的资源消耗,因此在生产集群上调整这些参数需要结合实际情况谨慎调整,一旦影响应用要立即调整回来。 对于搜索并发量要求高,延迟要求低的场合,默认设置一般就不要去动了。 对于日志实时分析类对于搜索延迟要求不高,但对于数据写入延迟期望比较低的场合,可以适当调大indices.recovery.max_bytes_per_sec,提升recovery速度,减少数据写入被阻塞的时长。
最后要说的一点是ES的版本迭代很快,对于Recovery的机制也在不断的优化中。 其中有一些版本甚至引入了一些bug,比如在ES1.4.x有严重的translog recovery bug,导致大的索引trans log recovery几乎无法完成 (issue #9926) 。因此实际使用中如果遇到问题,最好在Github的issue list里搜索一下,看是否使用的版本有其他人反映同样的问题。
分享阅读参考: https://henduan.com/rCWPD
收起阅读 »Kafka入门简介
Kafka背景
Kafka它本质上是一个消息系统,由当时从LinkedIn出来创业的三人小组开发,他们开发出了Apache Kafka实时信息队列技术,该技术致力于为各行各业的公司提供实时数据处理服务解决方案。Kafka为LinkedIn的中枢神经系统,管理从各个应用程序的汇聚,这些数据经过处理后再被分发到其他地方。Kafka不同于传统的企业信息队列系统,它是以近乎实时的方式处理流经一个公司的所有数据,目前已经服务于LinkedIn、Netflix、Uber以及Verizon,并为此建立了实时信息处理平台。
流水数据是所有站点对其网站使用情况做报表时都要用到的数据中最常用的一部分,流水数据包括PV,浏览内容信息以及搜索记录等。这些数据通常是先以日志文件的形式存在,然后有周期的去对这些日志文件进行统计分析处理,然后获得需要的KPI指标结果。
Kafka应用场景
我们在接触一门新技术或是新语言时,得明白这门技术(或是语言)的应用场景,也就说要明白它能做什么,服务的对象是谁,下面用一个图来说明,如下图所示:

首先,Kafka可以应用于消息系统,比如,当下较为热门的消息推送,这些消息推送系统的消息源,可以使用Kafka作为系统的核心组建来完成消息的生产和消息的消费。然后是网站的行迹,我们可以将企业的Portal,用户的操作记录等信息发送到Kafka中,按照实际业务需求,可以进行实时监控,或者做离线处理等。最后,一个是日志收集,类似于Flume套件这样的日志收集系统,但Kafka的设计架构采用push/pull,适合异构集群,Kafka可以批量提交消息,对Producer来说,在性能方面基本上是无消耗的,而在Consumer端中,我们可以使用HDFS这类的分布式文件存储系统进行存储。
Kafka架构原理
Kafka的设计之初是希望做一个统一的信息收集平台,能够实时的收集反馈信息,并且具有良好的容错能力。Kafka中我们最直观的感受就是它的消费者与生产者,如下图所示:
Producer And Consumer:

这里Kafka对消息的保存是根据Topic进行归类的,由消息生产者(Producer)和消息消费者(Consumer)组成,另外,每一个Server称为一个Broker。对于Kafka集群而言,Producer和Consumer都依赖于ZooKeeper来保证数据的一致性。
Topic:
在每条消息输送到Kafka集群后,消息都会由一个Type,这个Type被称为一个Topic,不同的Topic的消息是分开存储的。如下图所示:

一个Topic会被归类为一则消息,每个Topic可以被分割为多个Partition,在每条消息中,它在文件中的位置称为Offset,用于标记唯一一条消息。在Kafka中,消息被消费后,消息仍然会被保留一定时间后在删除,比如在配置信息中,文件信息保留7天,那么7天后,不管Kafka中的消息是否被消费,都会被删除;以此来释放磁盘空间,减少磁盘的IO消耗。
在Kafka中,一个Topic的多个分区,被分布在Kafka集群的多个Server上,每个Server负责分区中消息的读写操作。另外,Kafka还可以配置分区需要备份的个数,以便提高可用行。由于用到来ZK来协调,每个分区都有一个Server为Leader状态,服务对外响应(如读写操作),若该Leader宕机,会由其他的Follower来选举出新的Leader来保证集群的高可用性。
总结
kafka是一个非常强悍的消息队列系统,他支持持久化和数据偏移,从而实现多个消费者同时消费一份数据是没有问题的。简单的来说他就是一个生产者消费模型的架构,居于zookeeper来管理每个Topic的信息记录和偏移量,从而达到高效和多复用的概念,消息不会消失,除非过期。 收起阅读 »
Hadoop 2.6.0修改配置PID文件路径
修改原因
Hadoop启动后的PID文件默认配置是保存在 /tmp 目录下的,而linux下 /tmp 目录会定时清理,所以在集群运行一段时间后如果在停Hadoop相关服务是会出现类似:no datanode to stop 的错误提示,一般生产环境中我们需要重新修改PID的保存路径。关于Linux定期清理tmp目录参考我之前的文章:http://openskill.cn/article/413
Hadoop修改
1、HDFS
增加或修改:$HADOOP_HOME/etc/hadoop/hadoop-env.sh如下:
# 修改为你想存放的路径
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
2、MapReduce
增加或修改:$HADOOP_HOME/etc/hadoop/mapred-env.sh如下:
# 修改mapred的pid存放路径**ps: 自定义存储目录需要先创建好。
export HADOOP_MAPRED_PID_DIR=/data/hadoop/pids
Hbase 修改
增加或修改:$HBASE_HOME/conf/hbase-env.sh 如下:
#hbase PID存放路径配置
export HBASE_PID_DIR=/data/hadoop/pids
命名规则说明
我阅读了一下stop-all.sh stop-dfs.sh,stop-yarn.sh脚本,发现原理都是通过一个pid文件来停止集群的。
这些进程的pid文件默认都是保存在系统的/tmp目录下面,Linux系统(Centos/RHEL等)每个一段时间就会清楚/tmp下面的内容,如果/tmp下没有相关的pid文件停止就会出错“no datanode to stop”
当我重启出现问题的时候我怕强制kill -9杀进程的话会破坏集群,于是我想到一个方法,按照pid文件的命名规则重新在/tmp目录下面创建这些pid文件,在翻看了一堆sbin目录下的脚本之后,找到了它们的命名规则。
比如hadoop相关进程的pid文件命名规则为:
pid=$HADOOP_PID_DIR/hadoop-$HADOOP_IDENT_STRING-$command.pidYarn进程相关的PID文件:
pid=$YARN_PID_DIR/yarn-$YARN_IDENT_STRING-$command.pid默认情况下$HADOOP_PID_DIR和$YARN_PID_DIR都为/tmp,$HADOOP_IDENT_STRING和$YARN_IDENT_STRING都为当前系统登录的用户名,比如我的用户名为root,$command为当前执行的命令:
比如执行了一个 hadoop-daemon.sh stop namenode,这时候就会去找/tmp/hadoop-root-namenode.pid文件拿到namenode进程的pid号,来停止namenode进程。
了解原理之后,于是我就开始手动创建这些文件,我首先jps把所有进程的pid都记录下来了,然后在/tmp目录按照命名规则创建好了这些进程的pid文件,然后再重新执行stop-all.sh命令,ok可以成功关闭集群了。这是我处理的一个过程,最后为了避免这种情况,我就做了如上修改的操作! 收起阅读 »
Kafka consumer处理大消息数据问题分析
案例分析
今天在处理kafka consumer的程序的时候,发现如下错误:
ERROR [2016-07-22 07:16:02,466] com.flow.kafka.consumer.main.KafkaConsumer: Unexpected Error Occurred如上log可以看出,问题就是有一个较大的消息数据在codeTopic的partition 3上,然后consumer未能消费,提示我可以减小broker允许进入的消息数据的大小,或者增大consumer程序消费数据的大小。
! kafka.common.MessageSizeTooLargeException: Found a message larger than the maximum fetch size of this consumer on topic codeTopic partition 3 at fetch offset 94. Increase the fetch size, or decrease the maximum message size the broker will allow.
! at kafka.consumer.ConsumerIterator.makeNext(ConsumerIterator.scala:91) ~[pip-kafka-consumer.jar:na]
! at kafka.consumer.ConsumerIterator.makeNext(ConsumerIterator.scala:33) ~[pip-kafka-consumer.jar:na]
! at kafka.utils.IteratorTemplate.maybeComputeNext(IteratorTemplate.scala:66) ~[pip-kafka-consumer.jar:na]
! at kafka.utils.IteratorTemplate.hasNext(IteratorTemplate.scala:58) ~[pip-kafka-consumer.jar:na]
! at com.flow.kafka.consumer.main.KafkaConsumer$KafkaRiverFetcher.run(KafkaConsumer.java:291) ~[original-pip-kafka-consumer.jar:na]
! at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) [na:1.7.0_51]
! at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) [na:1.7.0_51]
! at java.lang.Thread.run(Thread.java:744) [na:1.7.0_51]
从log上来看一目了然,如果要解决当前问题的话,1、减小broker消息体大小(设置message.max.bytes
参数)。;2、增大consumer获取数据信息大小(设置fetch.message.max.bytes参数)。默认broker消息体大小为1000000字节即为1M大小。
消费者方面:fetch.message.max.bytes——>这将决定消费者可以获取的数据大小。
broker方面:replica.fetch.max.bytes——>这将允许broker的副本发送消息在集群并确保消息被正确地复制。如果这是太小,则消息不会被复制,因此,消费者永远不会看到的消息,因为消息永远不会承诺(完全复制)。
broker方面:message.max.bytes——>可以接受数据生产者最大消息数据大小。
由我的场景来看较大的消息体已经进入到了kafka,我这里要解决这个问题,只需要增加consumer的fetch.message.max.bytes数值就好。我单独把那条数据消费出来,写到一个文件中发现那条消息大小为1.5M左右,为了避免再次发生这种问题我把consumer程序的fetch.message.max.bytes参数调节为了3072000即为3M,重启consumer程序,查看log一切正常,解决这个消费错误到此结束,下面介绍一下kafka针对大数据处理的思考。
kafka的设计初衷
Kafka设计的初衷是迅速处理小量的消息,一般10K大小的消息吞吐性能最好(可参见LinkedIn的kafka性能测试)。但有时候,我们需要处理更大的消息,比如XML文档或JSON内容,一个消息差不多有10-100M,这种情况下,Kakfa应该如何处理?
针对这个问题,可以参考如下建议:
- [] 最好的方法是不直接传送这些大的数据。如果有共享存储,如NAS, HDFS, S3等,可以把这些大的文件存放到共享存储,然后使用Kafka来传送文件的位置信息。[/][] 第二个方法是,将大的消息数据切片或切块,在生产端将数据切片为10K大小,使用分区主键确保一个大消息的所有部分会被发送到同一个kafka分区(这样每一部分的拆分顺序得以保留),如此以来,当消费端使用时会将这些部分重新还原为原始的消息。[/][] 第三,Kafka的生产端可以压缩消息,如果原始消息是XML,当通过压缩之后,消息可能会变得不那么大。在生产端的配置参数中使用compression.codec和commpressed.topics可以开启压缩功能,压缩算法可以使用GZip或Snappy。[/]
不过如果上述方法都不是你需要的,而你最终还是希望传送大的消息,那么,则可以在kafka中设置下面一些参数:
broker 配置:
- []message.max.bytes (默认:1000000) – broker能接收消息的最大字节数,这个值应该比消费端的fetch.message.max.bytes更小才对,否则broker就会因为消费端无法使用这个消息而挂起。[/][]log.segment.bytes (默认: 1GB) – kafka数据文件的大小,确保这个数值大于一个消息的长度。一般说来使用默认值即可(一般一个消息很难大于1G,因为这是一个消息系统,而不是文件系统)。[/][]replica.fetch.max.bytes (默认: 1MB) – broker可复制的消息的最大字节数。这个值应该比message.max.bytes大,否则broker会接收此消息,但无法将此消息复制出去,从而造成数据丢失。[/]
- []fetch.message.max.bytes (默认 1MB) – 消费者能读取的最大消息。这个值应该大于或等于message.max.bytes。所以,如果你一定要选择kafka来传送大的消息,还有些事项需要考虑。要传送大的消息,不是当出现问题之后再来考虑如何解决,而是在一开始设计的时候,就要考虑到大消息对集群和主题的影响。[/][]性能: 根据前面提到的性能测试,kafka在消息为10K时吞吐量达到最大,更大的消息会降低吞吐量,在设计集群的容量时,尤其要考虑这点。[/][]可用的内存和分区数:Brokers会为每个分区分配replica.fetch.max.bytes参数指定的内存空间,假设replica.fetch.max.bytes=1M,且有1000个分区,则需要差不多1G的内存,确保 分区数最大的消息不会超过服务器的内存,否则会报OOM错误。同样地,消费端的fetch.message.max.bytes指定了最大消息需要的内存空间,同样,分区数最大需要内存空间 不能超过服务器的内存。所以,如果你有大的消息要传送,则在内存一定的情况下,只能使用较少的分区数或者使用更大内存的服务器。[/][]垃圾回收:到现在为止,我在kafka的使用中还没发现过此问题,但这应该是一个需要考虑的潜在问题。更大的消息会让GC的时间更长(因为broker需要分配更大的块),随时关注GC的日志和服务器的日志信息。如果长时间的GC导致kafka丢失了zookeeper的会话,则需要配置zookeeper.session.timeout.ms参数为更大的超时时间。[/]
具体使用情况可以视具体情况而定。
参考:http://www.4byte.cn/question/288008/kafka-sending-a-15mb-message.html 收起阅读 »
Flume(NG)架构设计要点及配置实践
架构设计要点
Flume的架构主要有一下几个核心概念:
- []Event:一个数据单元,带有一个可选的消息头[/][]Flow:Event从源点到达目的点的迁移的抽象[/][]Client:操作位于源点处的Event,将其发送到Flume Agent[/][]Agent:一个独立的Flume进程,包含组件Source、Channel、Sink[/][]Source:用来消费传递到该组件的Event[/][]Channel:中转Event的一个临时存储,保存有Source组件传递过来的Event[/][]Sink:从Channel中读取并移除Event,将Event传递到Flow Pipeline中的下一个Agent(如果有的话)[/]

# list the sources, sinks and channels for the agent尖括号里面的,我们可以根据实际需求或业务来修改名称。下面详细说明:表示配置一个Agent的名称,一个Agent肯定有一个名称。与是Agent的Source组件的名称,消费传递过来的Event。与是Agent的Channel组件的名称。与是Agent的Sink组件的名称,从Channel中消费(移除)Event。上面配置内容中,第一组中配置Source、Sink、Channel,它们的值可以有1个或者多个;第二组中配置Source将把数据存储(Put)到哪一个Channel中,可以存储到1个或多个Channel中,同一个Source将数据存储到多个Channel中,实际上是Replication;第三组中配置Sink从哪一个Channel中取(Task)数据,一个Sink只能从一个Channel中取数据。下面,根据官网文档,我们展示几种Flow Pipeline,各自适应于什么样的应用场景:.sources = .sinks = .channels = # set channel for source .sources. .channels = ... .sources. .channels = ...# set channel for sink .sinks. .channel = .sinks. .channel =
- []多个Agent顺序连接[/]

- []多个Agent的数据汇聚到同一个Agent[/]

- []多路(Multiplexing)Agent[/]

# List the sources, sinks and channels for the agent上面指定了selector的type的值为replication,其他的配置没有指定,使用的Replication方式,Source1会将数据分别存储到Channel1和Channel2,这两个channel里面存储的数据是相同的,然后数据被传递到Sink1和Sink2。Multiplexing方式,selector可以根据header的值来确定数据传递到哪一个channel,配置格式,如下所示:.sources = .sinks = .channels = # set list of channels for source (separated by space) .sources. .channels = # set channel for sinks .sinks. .channel = .sinks. .channel = .sources. .selector.type = replicating
# Mapping for multiplexing selector上面selector的type的值为multiplexing,同时配置selector的header信息,还配置了多个selector的mapping的值,即header的值:如果header的值为Value1、Value2,数据从Source1路由到Channel1;如果header的值为Value2、Value3,数据从Source1路由到Channel2。.sources. .selector.type = multiplexing .sources. .selector.header = .sources. .selector.mapping. = .sources. .selector.mapping. = .sources. .selector.mapping. = #... .sources. .selector.default =
- []实现load balance功能[/]

a1.sinkgroups = g1a1.sinkgroups.g1.sinks = k1 k2 k3a1.sinkgroups.g1.processor.type = load_balancea1.sinkgroups.g1.processor.backoff = truea1.sinkgroups.g1.processor.selector = round_robina1.sinkgroups.g1.processor.selector.maxTimeOut=10000
- []实现failover功能[/]
a1.sinkgroups = g1a1.sinkgroups.g1.sinks = k1 k2 k3a1.sinkgroups.g1.processor.type = failovera1.sinkgroups.g1.processor.priority.k1 = 5a1.sinkgroups.g1.processor.priority.k2 = 7a1.sinkgroups.g1.processor.priority.k3 = 6a1.sinkgroups.g1.processor.maxpenalty = 20000
我们看一下,Flume NG都支持哪些功能(目前最新版本是1.5.0.1),了解它的功能集合,能够让我们在应用中更好地选择使用哪一种方案。说明Flume NG的功能,实际还是围绕着Agent的三个组件Source、Channel、Sink来看它能够支持哪些技术或协议。我们不再对各个组件支持的协议详细配置进行说明,通过列表的方式分别对三个组件进行概要说明:基本功能
- []Flume Source[/]

- []Flume Channel[/]

- []Flume Sink[/]

安装Flume NG非常简单,我们使用最新的1.5.0.1版本,执行如下命令:应用实践
cd /usr/localwget http://mirror.bit.edu.cn/apache/flume/1.5.0.1/apache-flume-1.5.0.1-bin.tar.gztar xvzf apache-flume-1.5.0.1-bin.tar.gzcd apache-flume-1.5.0.1-bin如果需要使用到Hadoop集群,保证Hadoop相关的环境变量都已经正确配置,并且Hadoop集群可用。下面,通过一些实际的配置实例,来了解Flume的使用。为了简单期间,channel我们使用Memory类型的channel。
- []Avro Source+Memory Channel+Logger Sink[/]
# Define a memory channel called ch1 on agent1agent1.channels.ch1.type = memory# Define an Avro source called avro-source1 on agent1 and tell it# to bind to 0.0.0.0:41414. Connect it to channel ch1.agent1.sources.avro-source1.channels = ch1agent1.sources.avro-source1.type = avroagent1.sources.avro-source1.bind = 0.0.0.0agent1.sources.avro-source1.port = 41414# Define a logger sink that simply logs all events it receives# and connect it to the other end of the same channel.agent1.sinks.log-sink1.channel = ch1agent1.sinks.log-sink1.type = logger# Finally, now that we've defined all of our components, tell# agent1 which ones we want to activate.agent1.channels = ch1agent1.channels.ch1.capacity = 1000agent1.sources = avro-source1agent1.sinks = log-sink1首先,启动Agent进程:
bin/flume-ng agent -c ./conf/ -f conf/flume-conf.properties -Dflume.root.logger=DEBUG,console -n agent1然后,启动Avro Client,发送数据:
bin/flume-ng avro-client -c ./conf/ -H 0.0.0.0 -p 41414 -F /usr/local/programs/logs/sync.log -Dflume.root.logger=DEBUG,console
- []Avro Source+Memory Channel+HDFS Sink[/]
# Define a source, channel, sinkagent1.sources = avro-source1agent1.channels = ch1agent1.sinks = hdfs-sink# Configure channelagent1.channels.ch1.type = memoryagent1.channels.ch1.capacity = 1000000agent1.channels.ch1.transactionCapacity = 500000# Define an Avro source called avro-source1 on agent1 and tell it# to bind to 0.0.0.0:41414. Connect it to channel ch1.agent1.sources.avro-source1.channels = ch1agent1.sources.avro-source1.type = avroagent1.sources.avro-source1.bind = 0.0.0.0agent1.sources.avro-source1.port = 41414# Define a logger sink that simply logs all events it receives# and connect it to the other end of the same channel.agent1.sinks.hdfs-sink1.channel = ch1agent1.sinks.hdfs-sink1.type = hdfsagent1.sinks.hdfs-sink1.hdfs.path = hdfs://h1:8020/data/flume/agent1.sinks.hdfs-sink1.hdfs.filePrefix = sync_fileagent1.sinks.hdfs-sink1.hdfs.fileSuffix = .logagent1.sinks.hdfs-sink1.hdfs.rollSize = 1048576agent1.sinks.hdfs-sink1.rollInterval = 0agent1.sinks.hdfs-sink1.hdfs.rollCount = 0agent1.sinks.hdfs-sink1.hdfs.batchSize = 1500agent1.sinks.hdfs-sink1.hdfs.round = trueagent1.sinks.hdfs-sink1.hdfs.roundUnit = minuteagent1.sinks.hdfs-sink1.hdfs.threadsPoolSize = 25agent1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = trueagent1.sinks.hdfs-sink1.hdfs.minBlockReplicas = 1agent1.sinks.hdfs-sink1.fileType = SequenceFileagent1.sinks.hdfs-sink1.writeFormat = TEXT首先,启动Agent:
bin/flume-ng agent -c ./conf/ -f conf/flume-conf-hdfs.properties -Dflume.root.logger=INFO,console -n agent1然后,启动Avro Client,发送数据:
bin/flume-ng avro-client -c ./conf/ -H 0.0.0.0 -p 41414 -F /usr/local/programs/logs/sync.log -Dflume.root.logger=DEBUG,console可以查看同步到HDFS上的数据:
hdfs dfs -ls /data/flume结果示例,如下所示:
-rw-r--r-- 3 shirdrn supergroup 1377617 2014-09-16 14:35 /data/flume/sync_file.1410849320761.log-rw-r--r-- 3 shirdrn supergroup 1378137 2014-09-16 14:35 /data/flume/sync_file.1410849320762.log-rw-r--r-- 3 shirdrn supergroup 259148 2014-09-16 14:35 /data/flume/sync_file.1410849320763.log
- []Spooling Directory Source+Memory Channel+HDFS Sink[/]
# Define source, channel, sinkagent1.sources = spool-source1agent1.channels = ch1agent1.sinks = hdfs-sink1# Configure channelagent1.channels.ch1.type = memoryagent1.channels.ch1.capacity = 1000000agent1.channels.ch1.transactionCapacity = 500000# Define and configure an Spool directory sourceagent1.sources.spool-source1.channels = ch1agent1.sources.spool-source1.type = spooldiragent1.sources.spool-source1.spoolDir = /home/shirdrn/data/agent1.sources.spool-source1.ignorePattern = event(_\d{4}\-\d{2}\-\d{2}_\d{2}_\d{2})?\.log(\.COMPLETED)?agent1.sources.spool-source1.batchSize = 50agent1.sources.spool-source1.inputCharset = UTF-8# Define and configure a hdfs sinkagent1.sinks.hdfs-sink1.channel = ch1agent1.sinks.hdfs-sink1.type = hdfsagent1.sinks.hdfs-sink1.hdfs.path = hdfs://h1:8020/data/flume/agent1.sinks.hdfs-sink1.hdfs.filePrefix = event_%y-%m-%d_%H_%M_%Sagent1.sinks.hdfs-sink1.hdfs.fileSuffix = .logagent1.sinks.hdfs-sink1.hdfs.rollSize = 1048576agent1.sinks.hdfs-sink1.hdfs.rollCount = 0agent1.sinks.hdfs-sink1.hdfs.batchSize = 1500agent1.sinks.hdfs-sink1.hdfs.round = trueagent1.sinks.hdfs-sink1.hdfs.roundUnit = minuteagent1.sinks.hdfs-sink1.hdfs.threadsPoolSize = 25agent1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = trueagent1.sinks.hdfs-sink1.hdfs.minBlockReplicas = 1agent1.sinks.hdfs-sink1.fileType = SequenceFileagent1.sinks.hdfs-sink1.writeFormat = TEXTagent1.sinks.hdfs-sink1.rollInterval = 0启动Agent进程,执行如下命令:bin/flume-ng agent -c ./conf/ -f conf/flume-conf-spool.properties -Dflume.root.logger=INFO,console -n agent1可以查看HDFS上同步过来的数据:
hdfs dfs -ls /data/flume结果示例,如下所示:
-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:52 /data/flume/event_14-09-17_10_52_00.1410922355094.log-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:52 /data/flume/event_14-09-17_10_52_00.1410922355095.log-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:52 /data/flume/event_14-09-17_10_52_00.1410922355096.log-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:52 /data/flume/event_14-09-17_10_52_00.1410922355097.log-rw-r--r-- 3 shirdrn supergroup 1530 2014-09-17 10:53 /data/flume/event_14-09-17_10_52_00.1410922355098.log-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:53 /data/flume/event_14-09-17_10_53_00.1410922380386.log-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:53 /data/flume/event_14-09-17_10_53_00.1410922380387.log-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:53 /data/flume/event_14-09-17_10_53_00.1410922380388.log-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:53 /data/flume/event_14-09-17_10_53_00.1410922380389.log-rw-r--r-- 3 shirdrn supergroup 1072265 2014-09-17 10:53 /data/flume/event_14-09-17_10_53_00.1410922380390.log
- []Exec Source+Memory Channel+File Roll Sink[/]
配置Agent,修改配置文件flume-conf-file.properties,内容如下:
# Define source, channel, sink启动Agent进程,执行如下命令:
agent1.sources = tail-source1
agent1.channels = ch1
agent1.sinks = file-sink1
# Configure channel
agent1.channels.ch1.type = memory
agent1.channels.ch1.capacity = 1000000
agent1.channels.ch1.transactionCapacity = 500000
# Define and configure an Exec source
agent1.sources.tail-source1.channels = ch1
agent1.sources.tail-source1.type = exec
agent1.sources.tail-source1.command = tail -F /home/shirdrn/data/event.log
agent1.sources.tail-source1.shell = /bin/sh -c
agent1.sources.tail-source1.batchSize = 50
# Define and configure a File roll sink
# and connect it to the other end of the same channel.
agent1.sinks.file-sink1.channel = ch1
agent1.sinks.file-sink1.type = file_roll
agent1.sinks.file-sink1.batchSize = 100
agent1.sinks.file-sink1.serializer = TEXT
agent1.sinks.file-sink1.sink.directory = /home/shirdrn/sink_data
bin/flume-ng agent -c ./conf/ -f conf/flume-conf-file.properties -Dflume.root.logger=INFO,console -n agent1可以查看File Roll Sink对应的本地文件系统目录/home/shirdrn/sink_data下,示例如下所示:
-rw-rw-r-- 1 shirdrn shirdrn 13944825 Sep 17 11:36 1410924990039-1有关Flume NG更多配置及其说明,请参考官方用户手册,非常详细。
-rw-rw-r-- 1 shirdrn shirdrn 11288870 Sep 17 11:37 1410924990039-2
-rw-rw-r-- 1 shirdrn shirdrn 0 Sep 17 11:37 1410924990039-3
-rw-rw-r-- 1 shirdrn shirdrn 20517500 Sep 17 11:38 1410924990039-4
-rw-rw-r-- 1 shirdrn shirdrn 16343250 Sep 17 11:38 1410924990039-5
参考链接:
http://flume.apache.org/FlumeUserGuide.html
https://blogs.apache.org/flume/entry/flume_ng_architecture
分享阅读原文:http://shiyanjun.cn/archives/915.html
作者:时延军
收起阅读 »
Elasticsearch Monitoring
查看集群状态
curl -s '127.0.0.1:9200/_cluster/health?pretty'
查看集群中所有索引的状态
curl -s '127.0.0.1:9200/_cluster/health?pretty&level=indices'
查看集群中所有索引分片的状态
curl -s '127.0.0.1:9200/_cluster/health?pretty&level=shards'
节点
查看集群中所有节点的配置信息
curl -s '127.0.0.1:9200/_nodes/?pretty'
查看集群中指定节点的配置信息
curl -s '127.0.0.1:9200/_nodes/{ip|name}?pretty'
查看集群中所有节点的状态信息
curl -s '127.0.0.1:9200/_nodes/stats/?pretty'
查看集群中指定节点的状态信息
curl -s '127.0.0.1:9200/_nodes/{ip|name}/stats/?pretty'
查看集群中所有节点的指定状态信息
curl -s '127.0.0.1:9200/_nodes/stats/{indices|os|process|jvm|thread_pool|fs}?pretty'
查看集群中指定节点的指定状态信息
curl -s '127.0.0.1:9200/_nodes/{ip|name}/stats/{indices|os|process|jvm|thread_pool|fs}?pretty'
cat
curl -s '127.0.0.1:9200/_cat/?'
索引
查看指定索引的状态信息原文作者:erica.zhou
curl -s 127.0.0.1:9200/_cat/indices/{index}?v
查看指定索引的分片信息
curl -s 127.0.0.1:9200/_cat/shards/{index}?v
查看指定索引的段信息
curl -s 127.0.0.1:9200/_cat/segments/{index}?v
原文地址:http://www.z-dig.com/elasticsearch-monitoring.html 收起阅读 »
Elasticsearch 2.3.1配置文件说明
elasticsearch的config文件夹里面有两个配置文件:elasticsearch.yml和logging.yml,第一个是es的基本配置文件,第二个是日志配置文件,es也是使用log4j来记录日志的,所以logging.yml里的设置按普通log4j配置文件来设置就行了。下面主要讲解下elasticsearch.yml这个文件中可配置的东西。收起阅读 »
cluster.name:elasticsearch
配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
node.name:"FranzKafka"
节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。
node.master:true
指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。
node.data:true
指定该节点是否存储索引数据,默认为true。
index.number_of_shards:5
设置默认索引分片个数,默认为5片。
index.number_of_replicas:1
设置默认索引副本个数,默认为1个副本。
path.conf:/path/to/conf
设置配置文件的存储路径,默认是es根目录下的config文件夹。
path.data:/path/to/data
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:
path.data:/path/to/data1,/path/to/data2
path.work:/path/to/work
设置临时文件的存储路径,默认是es根目录下的work文件夹。
path.logs:/path/to/logs
设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins:/path/to/plugins
设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.mlockall:true
设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit-l unlimited`命令。
network.bind_host:192.168.0.1
设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
network.publish_host:192.168.0.1
设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
network.host:192.168.0.1
这个参数是用来同时设置bind_host和publish_host上面两个参数。
transport.tcp.port:9300
设置节点间交互的tcp端口,默认是9300。
transport.tcp.compress:true
设置是否压缩tcp传输时的数据,默认为false,不压缩。
http.port:9200
设置对外服务的http端口,默认为9200。
http.max_content_length:100mb
设置内容的最大容量,默认100mb
http.enabled:false
是否使用http协议对外提供服务,默认为true,开启。
gateway.type:local
gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说。
gateway.recover_after_nodes:1
设置集群中N个节点启动时进行数据恢复,默认为1。
gateway.recover_after_time:5m
设置初始化数据恢复进程的超时时间,默认是5分钟。
gateway.expected_nodes:2
设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。
cluster.routing.allocation.node_initial_primaries_recoveries:4
初始化数据恢复时,并发恢复线程的个数,默认为4。
cluster.routing.allocation.node_concurrent_recoveries:2
添加删除节点或负载均衡时并发恢复线程的个数,默认为4。
indices.recovery.max_size_per_sec:0
设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。
indices.recovery.concurrent_streams:5
设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
discovery.zen.minimum_master_nodes:1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.ping.timeout:3s
设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
discovery.zen.ping.multicast.enabled:false
设置是否打开多播发现节点,默认是true。
discovery.zen.ping.unicast.hosts:["host1", "host2:port","host3[portX-portY]"]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
Kafka Offset Monitor页面字段解释

如上图所示:
id:kafka broker实例的id号
host:kafka 实例的ip地址
port:kafka 实例服务端口
Topic:Topic的名字
Partition:Topic包含的分区,上图中pythonTopic中包含4个分区(默认分区从0开始)
Offset:Kafka Consumer已经消费分区上的消息数
logSize:已经写到该分区的消息数
Lag:未读取也就是未消费的消息数(Lag = logSize - Offset)
Owner:改分区位于哪个Broker上,上图中只有一个Broker(consumer group name + consumer hostname + broker.id)
Created:分区创建时间
Last Seen:Offset 和 logSize 数字最后一次刷新时间间隔
有时候刚启动kafka的时候,可能发现Lag为负值,这明显是不对的,但是当Producer 和 Consumer对kafka进行写和读的时候,数字会显示正常,具体为什么会出现负值,我也不从而知,我估计是bug。 收起阅读 »
Python可用的分布式协调系统(ZooKeeper,Consul, etcd)介绍
在对分布式的应用做协调的时候,主要会碰到以下的应用场景:
- []业务发现(service discovery)[/]
- []名字服务 (name service)[/]
- []配置管理 (configuration management)[/]
- []故障发现和故障转移 (failure detection and failover)[/]
- []领导选举(leader election)[/]
- []分布式的锁 (distributed exclusive lock)[/]
- []消息和通知服务 (message queue and notification)[/]
Zookeeper 是使用最广泛,也是最有名的解决分布式服务的协调问题的开源软件了,它最早和Hadoop一起开发,后来成为了Apache的顶级项目,很多开源的项目都在使用ZooKeeper,例如大名鼎鼎的Kafka。 Zookeeper本身是一个分布式的应用,通过对共享的数据的管理来实现对分布式应用的协调。ZooKeeper使用一个树形目录作为数据模型,这个目录和文件目录类似,目录上的每一个节点被称作ZNodes。ZooKeeper

from kazoo.client import KazooClientimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Ensure a path, create if necessaryzk.ensure_path("/test/zk1")# Create a node with datazk.create("/test/zk1/node", b"a test value")# Determine if a node existsif zk.exists("/test/zk1"): print "the node exist"# Print the version of a node and its datadata, stat = zk.get("/test/zk1")print("Version: %s, data: %s" % (stat.version, data.decode("utf-8")))# List the childrenchildren = zk.get_children("/test/zk1")print("There are %s children with names %s" % (len(children), children))zk.stop()通过对ZNode的操作,我们可以完成一些分布式服务协调的基本需求,包括名字服务,配置服务,分组等等。 故障检测(Failure Detection)在分布式系统中,一个最基本的需求就是当某一个服务出问题的时候,能够通知其它的节点或者某个管理节点。ZooKeeper提供ephemeral Node的概念,当创建该Node的服务退出或者异常中止的时候,该Node会被删除,所以我们就可以利用这种行为来监控服务运行状态。以下是worker的代码from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Ensure a path, create if necessaryzk.ensure_path("/test/failure_detection")# Create a node with datazk.create("/test/failure_detection/worker", value=b"a test value", ephemeral=True)while True: print "I am alive!" time.sleep(3)zk.stop()以下的monitor 代码,监控worker服务是否运行。from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Determine if a node existswhile True: if zk.exists("/test/failure_detection/worker"): print "the worker is alive!" else: print "the worker is dead!" break time.sleep(3)zk.stop()领导选举Kazoo直接提供了领导选举的API,使用起来非常方便。from kazoo.client import KazooClientimport timeimport uuidimport logginglogging.basicConfig()my_id = uuid.uuid4()def leader_func(): print "I am the leader {}".format(str(my_id)) while True: print "{} is working! ".format(str(my_id)) time.sleep(3)zk = KazooClient(hosts='127.0.0.1:2181')zk.start()election = zk.Election("/electionpath")# blocks until the election is won, then calls# leader_func()election.run(leader_func)zk.stop()你可以同时运行多个worker,其中一个会获得Leader,当你杀死当前的leader后,会有一个新的leader被选出。 分布式锁锁的概念大家都熟悉,当我们希望某一件事在同一时间只有一个服务在做,或者某一个资源在同一时间只有一个服务能访问,这个时候,我们就需要用到锁。from kazoo.client import KazooClientimport timeimport uuidimport logginglogging.basicConfig()my_id = uuid.uuid4()def work(): print "{} is working! ".format(str(my_id))zk = KazooClient(hosts='127.0.0.1:2181')zk.start()lock = zk.Lock("/lockpath", str(my_id))print "I am {}".format(str(my_id))while True: with lock: work() time.sleep(3) zk.stop()当你运行多个worker的时候,不同的worker会试图获取同一个锁,然而只有一个worker会工作,其它的worker必须等待获得锁后才能执行。 监视ZooKeeper提供了监视(Watch)的功能,当节点的数据被修改的时候,监控的function会被调用。我们可以利用这一点进行配置文件的同步,发消息,或其他需要通知的功能。from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()@zk.DataWatch('/path/to/watch')def my_func(data, stat): if data: print "Data is %s" % data print "Version is %s" % stat.version else : print "data is not available"while True: time.sleep(10)zk.stop()除了我们上面列举的内容外,Kazoo还提供了许多其他的功能,例如:计数,租约,队列等等,大家有兴趣可以参考它的文档。 Consul 是用Go开发的分布式服务协调管理的工具,它提供了服务发现,健康检查,Key/Value存储等功能,并且支持跨数据中心的功能。Consul提供ZooKeeper类似的功能,它的基于HTTP的API可以方便的和各种语言进行绑定。自然Python也在列。与Zookeeper有所差异的是Consul通过基于Client/Server架构的Agent部署来支持跨Data Center的功能。Consul

import consulc = consul.Consul()# set data for key fooc.kv.put('foo', 'bar')# poll a key for updatesindex = Nonewhile True: index, data = c.kv.get('foo', index=index) print data['Value'] c.kv.delete('foo')这里和ZooKeeper对Znode的操作几乎是一样的。 服务发现(Service Discovery)和健康检查(Health Check) Consul的另一个主要的功能是用于对分布式的服务做管理,用户可以注册一个服务,同时还提供对服务做健康检测的功能。首先,用户需要定义一个服务。{ "service": { "name": "redis", "tags": ["master"], "address": "127.0.0.1", "port": 8000, "checks": [ { "script": "/usr/local/bin/check_redis.py", "interval": "10s" } ] }}其中,服务的名字是必须的,其它的字段可以自选,包括了服务的地址,端口,相应的健康检查的脚本。当用户注册了一个服务后,就可以通过Consul来查询该服务,获得该服务的状态。 Consul支持三种Check的模式:- []调用一个外部脚本(Script),在该模式下,consul定时会调用一个外部脚本,通过脚本的返回内容获得对应服务的健康状态。[/][]调用HTTP,在该模式下,consul定时会调用一个HTTP请求,返回2XX,则为健康;429 (Too many request)是警告。其它均为不健康[/][]主动上报,在该模式下,服务需要主动调用一个consul提供的HTTP PUT请求,上报健康状态。[/]
- []Consul.Agent.Service[/][]Consul.Agent.Check[/]
import consulimport timec = consul.Consul()s = c.session.create(name="worker",behavior='delete',ttl=10)print "session id is {}".format(s)while True: c.session.renew(s) print "I am alive ..." time.sleep(3)Moniter代码用于监控worker相关联的session的状态,但发现worker session已经不存在了,就做出响应的处理。import consulimport timedef is_session_exist(name, sessions): for s in sessions: if s['Name'] == name: return True return Falsec = consul.Consul()while True: index, sessions = c.session.list() if is_session_exist('worker', sessions): print "worker is alive ..." else: print 'worker is dead!' break time.sleep(3)这里注意,因为是基于ttl(最小10秒)的检测,从业务中断到被检测到,至少有10秒的时延,对应需要实时响应的情景,并不适用。Zookeeper使用ephemeral Node的方式时延相对短一点,但也非实时。 领导选举和分布式的锁 无论是Consul本身还是Python客户端,都不直接提供Leader Election的功能,但是这篇文档介绍了如何利用Consul的KV存储来实现Leader Election,利用Consul的KV功能,可以很方便的实现领导选举和锁的功能。当对某一个Key做put操作的时候,可以创建一个session对象,设置一个acquire标志为该 session,这样就获得了一个锁,获得所得客户则是被选举的leader。代码如下:import consulimport timec = consul.Consul()def request_lead(namespace, session_id): lock = c.kv.put(leader_namespace,"leader check", acquire=session_id) return lockdef release_lead(session_id): c.session.destroy(session_id)def whois_lead(namespace): index,value = c.kv.get(namespace) session = value.get('Session') if session is None: print 'No one is leading, maybe in electing' else: index, value = c.session.info(session) print '{} is leading'.format(value['ID'])def work_non_block(): print "working"def work_block(): while True: print "working" time.sleep(3)leader_namespace = 'leader/test'[size=16] initialize leader key/value node[/size]leader_index, leader_node = c.kv.get(leader_namespace)if leader_node is None: c.kv.put(leader_namespace,"a leader test")while True: whois_lead(leader_namespace) session_id = c.session.create(ttl=10) if request_lead(leader_namespace,session_id): print "I am now the leader" work_block() release_lead(session_id) else: print "wait leader elected!" time.sleep(3)利用同样的机制,可以方便的实现锁,信号量等分布式的同步操作。 监视Consul的Agent提供了Watch的功能,然而Python客户端并没有相应的接口。 Etcd 是另一个用GO开发的分布式协调应用,它提供一个分布式的Key/Value存储来进行共享的配置管理和服务发现。 同样的etcd使用基于HTTP的API,可以灵活的进行不同语言的绑定,我们用的是这个客户端https://github.com/jplana/python-etcd 基本操作Etcd
import etcdclient = etcd.Client() client.write('/nodes/n1', 1)print client.read('/nodes/n1').valueetcd对节点的操作和ZooKeeper类似,不过etcd不支持ZooKeeper的ephemeral Node的概念,要监控服务的状态似乎比较麻烦。 分布式锁etcd支持分布式锁,以下是一个例子。import syssys.path.append("../../")import etcdimport uuidimport timemy_id = uuid.uuid4()def work(): print "I get the lock {}".format(str(my_id))client = etcd.Client() lock = etcd.Lock(client, '/customerlock', ttl=60)with lock as my_lock: work() lock.is_locked() # True lock.renew(60)lock.is_locked() # False老版本的etcd支持leader election,但是在最新版该功能被deprecated了,参见https://coreos.com/etcd/docs/0.4.7/etcd-modules/ 其它 我们针对分布式协调的功能讨论了三个不同的开源应用,其实还有许多其它的选择,我这里就不一一介绍,大家有兴趣可以访问以下的链接:- []eureka https://github.com/Netflix/eureka [/]
- []curator http://curator.apache.org/[/]
- []doozerd https://github.com/ha/doozerd[/]
- []openreplica http://openreplica.org/[/]
- []serf http://www.serfdom.io/[/]
- []noah https://github.com/lusis/Noah[/]
- []copy cat https://github.com/kuujo/copycat[/]
基于日志的分布式协调的框架,使用Java开发
总结
ZooKeeper无疑是分布式协调应用的最佳选择,功能全,社区活跃,用户群体很大,对所有典型的用例都有很好的封装,支持不同语言的绑定。缺点是,整个应用比较重,依赖于Java,不支持跨数据中心。
Consul作为使用Go语言开发的分布式协调,对业务发现的管理提供很好的支持,他的HTTP API也能很好的和不同的语言绑定,并支持跨数据中心的应用。缺点是相对较新,适合喜欢尝试新事物的用户。
etcd是一个更轻量级的分布式协调的应用,提供了基本的功能,更适合一些轻量级的应用来使用。
参考
如果大家对于分布式系统的协调想要进行更多的了解,可以阅读一下的链接:
http://stackoverflow.com/questions/6047917/zookeeper-alternatives-cluster-coordination-service
http://txt.fliglio.com/2014/05/encapsulated-services-with-consul-and-confd/
http://txt.fliglio.com/2013/12/service-discovery-with-docker-docker-links-and-beyond/
http://www.serfdom.io/intro/vs-zookeeper.html
http://devo.ps/blog/zookeeper-vs-doozer-vs-etcd/
https://www.digitalocean.com/community/articles/how-to-set-up-a-serf-cluster-on-several-ubuntu-vps
http://www.slideshare.net/JyrkiPulliainen/taming-pythons-with-zoo-keeper-ep2013?qid=e1267f58-090d-4147-9909-ec673525e76b&v=qf1&b=&from_search=8
http://muratbuffalo.blogspot.com/2014/09/paper-summary-tango-distributed-data.html
https://developer.yahoo.com/blogs/hadoop/apache-zookeeper-making-417.html
http://www.knewton.com/tech/blog/2014/12/eureka-shouldnt-use-zookeeper-service-discovery
http://codahale.com/you-cant-sacrifice-partition-tolerance/
原文地址:http://my.oschina.net/taogang/blog/410864 收起阅读 »
大数据与物联网
- []物联网的核心和基础仍然 是互联网,是在互联网基础上的延伸和扩展的网络;[/][]其用户端延伸和扩展到了任何物 品与物品之间,进行信息交换和通信。物联网就是"物物相连的互联网"。[/]
物联网通过智能感知、识别技术与普适计算、泛在网络的融合应用,被称为继计算机、互联网之后世界信息 产业发展的第三次浪潮。物联网是互联网的应用拓展,与其说物联网是网络,不如说物联网是业务和应用。因此,应用创新是物联网发展的核心,以用户体验为核心的创新 2.0 是物联网发展的灵魂。
物联网架构可分为三层,包括感知层、网络层和应用层:
- []感知层:由各种传感器构成,包括温湿度传感器、二维码标签、RFID标签和读写 器、摄像头、GPS 等感知终端。感知层是物联网识别物体、采集信息的来源; [/][]网络层:由各种网络,包括互联网、广电网、网络管理系统和云计算平台等组成, 是整个物联网的中枢,负责传递和处理感知层获取的信息;[/][]应用层:是物联网和用户的接口,它与行业需求结合,实现物联网的智能应用。 物联网用途广泛,遍及智能交通、环境保护、政府工作、公共安全、平安家居、智能消防、工业监测、环境监测、路灯照明管控、景观照明管控、楼宇照明管控、广场照明管控、 老人护理、个人健康、花卉栽培、水系监测、食品溯源、敌情侦查和情报搜集等多个领域。 [/]
国际电信联盟于 2005 年的报告曾 收起阅读 »





