
代理到底有几种功能模式?
代理服务技术是在互联网早期就出现被使用的。一般实现代理技术的方式就是在服务器上安装代理服务软件,让其成为一个代理服务器,从而实现代理技术。常用的代理技术分为正向代理、反向代理和透明代理。本文就是针对这三种代理来讲解一些基本原理和具体的适用范围和nginx的配置案例,便于大家更深入理解代理服务技术。
一、正向代理(Forward Proxy)
一般情况下,如果没有特别说明,代理技术默认说的是正向代理技术。
正向代理(forward)是一个位于客户端 【用户A】和原始服务器(origin server)【服务器B】之间的服务器【代理服务器Z】,为了从原始服务器取得内容,用户A向代理服务器Z发送一个请求并指定目标(服务器B),然后代理服务器Z向服务器B转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理,如下图所示:

从上面的概念中,我们看出,文中所谓的正向代理就是代理服务器【Z】替代访问方【用户A】去访问目标服务器【服务器B】。
这就是正向代理的意义所在。而为什么要用代理服务器【Z】去代替访问方【用户A】去访问服务器【B】呢?为什么不直接访问呢,这就要从场景和代理服务器使用的意义说起。
使用正向代理的意义和场景有如下几种:
1、用户访问本来无法访问的服务器B的资源

假设最初用户A要访问服务器B需要经过R1和R2路由器这样一个路由节点,如果路由器R1或者路由器R2发生故障,那么就无法访问服务器B了。但是如果用户A让代理服务器Z去代替自己访问服务器B,由于代理服务器Z没有在路由器R1或R2节点中,而是通过其它的路由节点访问服务器B,那么用户A就可以得到服务器B的数据了。
现实中的例子就是“翻墙”。不过自从VPN技术被广泛应用外,“翻墙”不但使用了传统的正向代理技术,有的还使用了VPN技术。
2、加速访问服务器B资源
这种说法目前不像以前那么流行了,主要是带宽流量的飞速发展。早期的正向代理中,很多人使用正向代理就是提速。
还是如图2假设用户A到服务器B,经过R1路由器和R2路由器,而R1到R2路由器的链路是一个低带宽链路。而用户A到代理服务器Z,从代理服务器Z到服务器B都是高带宽链路。那么很显然就可以加速访问服务器B了。
3、Cache作用

Cache(缓存)技术和代理服务技术是紧密联系的(不光是正向代理,反向代理也使用了Cache(缓存)技术。如上图所示,如果在用户A访问服务器B某数据F之前,已经有人通过代理服务器Z访问过服务器B上得数据F,那么代理服务器Z会把数据F保存一段时间,如果有人正好取该数据F,那么代理服务器Z不再访问服务器B,而把缓存的数据F直接发给用户A。这一技术在Cache中术语就叫Cache命中。如果有更多的像用户A的用户来访问代理服务器Z,那么这些用户都可以直接从代理服务器Z中取得数据F,而不用千里迢迢的去服务器B下载数据了。
4、客户端访问授权
这方面的内容现今使用的还是比较多的,例如一些公司采用ISA Server做为正向代理服务器来授权用户是否有权限访问互联网,如下图所示:

如上图防火墙作为网关,用来过滤外网对其的访问。假设用户A和用户B都设置了代理服务器,用户A允许访问互联网,而用户B不允许访问互联网(这个在代理服务器Z上做限制)这样用户A因为授权,可以通过代理服务器访问到服务器B,而用户B因为没有被代理服务器Z授权,所以访问服务器B时,数据包会被直接丢弃。
5、隐藏访问者的行踪
如下图所示,我们可以看出服务器B并不知道访问自己的实际是用户A,因为代理服务器Z代替用户A去直接与服务器B进行交互。如果代理服务器Z被用户A完全控制(或不完全控制),会惯以“肉鸡”术语称呼。

总结正向代理是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须设置正向代理服务器,当然前提是要知道正向代理服务器的IP地址,还有代理程序的端口。
Nginx正向代理配置示例如下:
server{
resolver 8.8.8.8;
resolver_timeout 30s;
listen 82;
location / {
proxy_pass http://$http_host$request_uri;
proxy_set_header Host $http_host;
proxy_buffers 256 4k;
proxy_max_temp_file_size 0;
proxy_connect_timeout 30;
proxy_cache_valid 200 302 10m;
proxy_cache_valid 301 1h;
proxy_cache_valid any 1m;
}
}1、不能有hostname。 2、必须有resolver, 即dns,即上面的8.8.8.8,超时时间(30秒)可选。
3、配置正向代理参数,均是由 Nginx 变量组成。
proxy_pass $scheme://$host$request_uri;4、配置缓存大小,关闭磁盘缓存读写减少I/O,以及代理连接超时时间。
proxy_set_header Host $http_host;
proxy_buffers 256 4k;5、配置代理服务器 Http 状态缓存时间。
proxy_max_temp_file_size 0;
proxy_connect_timeout 30;
proxy_cache_valid 200 302 10m;配置好后,重启nginx,以浏览器为例,要使用这个代理服务器,则只需将浏览器代理设置为http://+服务器ip地址+:+82(82是刚刚设置的端口号)即可使用了。
proxy_cache_valid 301 1h;
proxy_cache_valid any 1m;
二、反向代理(reverse proxy)
反向代理正好与正向代理相反,对于客户端而言代理服务器就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端。
使用反向代理服务器的作用如下:
1、保护和隐藏原始资源服务器

用户A始终认为它访问的是原始服务器B而不是代理服务器Z,但实用际上反向代理服务器接受用户A的应答,从原始资源服务器B中取得用户A的需求资源,然后发送给用户A。由于防火墙的作用,只允许代理服务器Z访问原始资源服务器B。尽管在这个虚拟的环境下,防火墙和反向代理的共同作用保护了原始资源服务器B,但用户A并不知情。
2、负载均衡

当反向代理服务器不止一个的时候,我们甚至可以把它们做成集群,当更多的用户访问资源服务器B的时候,让不同的代理服务器Z(x)去应答不同的用户,然后发送不同用户需要的资源。
当然反向代理服务器像正向代理服务器一样拥有Cache的作用,它可以缓存原始资源服务器B的资源,而不是每次都要向原始资源服务器组请求数据,特别是一些静态的数据,比如图片和文件,如果这些反向代理服务器能够做到和用户X来自同一个网络,那么用户X访问反向代理服务器X,就会得到很高质量的速度。这正是CDN技术的核心。如下图所示:

我们并不是讲解CDN,所以去掉了CDN最关键的核心技术智能DNS。只是展示CDN技术实际上利用的正是反向代理原理这块。
反向代理结论与正向代理正好相反,对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容原本就是它自己的一样。
基本上,网上做正反向代理的程序很多,能做正向代理的软件大部分也可以做反向代理。开源软件中最流行的就是squid,既可以做正向代理,也有很多人用来做反向代理的前端服务器。另外MS ISA也可以用来在Windows平台下做正向代理。反向代理中最主要的实践就是WEB服务,近些年来最火的就是Nginx了。网上有人说Nginx不能做正向代理,其实是不对的。Nginx也可以做正向代理,不过用的人比较少了。
Nginx反向代理示例:
http {
# 省略了前面一般的配置,直接从负载均衡这里开始
# 设置地址池,后端3台服务器
upstream http_server_pool {
server 192.168.1.2:8080 weight=2 max_fails=2 fail_timeout=30s;
server 192.168.1.3:8080 weight=3 max_fails=2 fail_timeout=30s;
server 192.168.1.4:8080 weight=4 max_fails=2 fail_timeout=30s;
}
# 一个虚拟主机,用来反向代理http_server_pool这组服务器
server {
listen 80;
# 外网访问的域名
server_name www.test.com;
location / {
# 后端服务器返回500 503 404错误,自动请求转发到upstream池中另一台服务器
proxy_next_upstream error timeout invalid_header http_500 http_503 http_404;
proxy_pass http://http_server_pool;
proxy_set_header Host www.test.com;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
access_log logs/www.test.com.access.log combined;
}
}最简单的反向代理演示(在一台服务器上做代理服务器,将http请求转发到另一台IIS服务器上,通过二级域名形式访问。)编辑vim nginx.confserver {
listen 80;
server_name test.zhoumengkang.com;
location / {
proxy_pass http://121.199.**.*:80;
}
}参考:http://www.blogjava.net/xiaomage234/archive/2011/09/08/358247.html
三、透明代理
如果把正向代理、反向代理和透明代理按照人类血缘关系来划分的话。那么正向代理和透明代理是很明显堂亲关系,而正向代理和反向代理就是表亲关系了 。
透明代理的意思是客户端根本不需要知道有代理服务器的存在,它改编你的request fields(报文),并会传送真实IP。注意,加密的透明代理则是属于匿名代理,意思是不用设置使用代理了。
透明代理实践的例子就是时下很多公司使用的行为管理软件。如下图所示:

用户A和用户B并不知道行为管理设备充当透明代理行为,当用户A或用户B向服务器A或服务器B提交请求的时候,透明代理设备根据自身策略拦截并修改用户A或B的报文,并作为实际的请求方,向服务器A或B发送请求,当接收信息回传,透明代理再根据自身的设置把允许的报文发回至用户A或B,如上图,如果透明代理设置不允许访问服务器B,那么用户A或者用户B就不会得到服务器B的数据。
Nginx透明代理配置示例:
# cat /etc/nginx/sites-enabled/proxyRAW Paste Data
server {
resolver 8.8.8.8;
access_log off;
listen [::]:8080;
location / {
proxy_pass $scheme://$host$request_uri;
proxy_set_header Host $http_host;
proxy_buffers 256 4k;
proxy_max_temp_file_size 0k;
}
}
iptables -t nat -A PREROUTING -s 10.8.0.0/24 -p tcp --dport 80 -j DNAT --to 192.168.0.253:8080
# cat /etc/nginx/sites-enabled/proxy参考:
server {
resolver 8.8.8.8;
access_log off;
listen [::]:8080;
location / {
proxy_pass $scheme://$host$request_uri;
proxy_set_header Host $http_host;
proxy_buffers 256 4k;
proxy_max_temp_file_size 0k;
}
}
iptables -t nat -A PREROUTING -s 10.8.0.0/24 -p tcp --dport 80 -j DNAT --to 192.168.0.253:8080
http://z00w00.blog.51cto.com/515114/1031287
https://mengkang.net/78.html 收起阅读 »
Nginx location配置及rewrite规则写法总结

location正则写法
简单示例如下:
location = / {
# 精确匹配 /,主机名后面不能带任何字符串
[ configuration A ]
}
location / {
# 因为所有的地址都以 / 开头,所以这条规则将匹配到所有请求 ,比如我们代理的一个站点根
# 但是正则和最长字符串会优先匹配
[ configuration B ]
}
location /documents/ {
# 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索
# 只有后面的正则表达式没有匹配到时,这一条才会采用这一条
[ configuration C ]
}
location ~ /documents/Abc {
# 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索
# 只有后面的正则表达式没有匹配到时,这一条才会采用这一条
[ configuration CC ]
}
location ^~ /images/ {
# 匹配任何以 /images/ 开头的地址,匹配符合以后,停止往下搜索正则,采用这一条。
[ configuration D ]
}
location ~* \.(gif|jpg|jpeg)$ {
# 匹配所有以 gif,jpg或jpeg 结尾的请求
# 然而,所有请求 /images/ 下的图片会被 config D 处理,因为 ^~ 到达不了这一条正则
[ configuration E ]
}
location /images/ {
# 字符匹配到 /images/,继续往下,会发现 ^~ 存在
[ configuration F ]
}
location /images/abc {
# 最长字符匹配到 /images/abc,继续往下,会发现 ^~ 存在
# F与G的放置顺序是没有关系的
[ configuration G ]
}
location ~ /images/abc/ {
# 只有去掉 config D 才有效:先最长匹配 config G 开头的地址,继续往下搜索,匹配到这一条正则,采用
[ configuration H ]
}
location ~* /js/.*/\.js- =开头表示精确匹配 如A中只匹配根目录结尾的请求,后面不能带任何字符串。
- ^~ 开头表示uri以某个常规字符串开头,不是正则匹配
- ~ 开头表示区分大小写的正则匹配;
- ~* 开头表示不区分大小写的正则匹配
- / 通用匹配, 如果没有其它匹配,任何请求都会匹配到
按照上面的location顺序,以下的匹配示例成立:(location =) > (location 完整路径) > (location ^~ 路径) > (location ~,~* 正则顺序) > (location 部分起始路径) > (/)
- / -> config A # 精确完全匹配,即使/index.html也匹配不了
- /downloads/download.html -> config B # 匹配B以后,往下没有任何匹配,采用B
- /images/1.gif -> configuration D # 匹配到F,往下匹配到D,停止往下
- /images/abc/def -> config D # 最长匹配到G,往下匹配D,停止往下,你可以看到 任何以/images/开头的都会匹配到D并停止,FG写在这里是没有任何意义的,H是永远轮不到的,这里只是为了说明匹配顺序
- /documents/document.html -> config C # 匹配到C,往下没有任何匹配,采用C
- /documents/1.jpg -> configuration E # 匹配到C,往下正则匹配到E
- /documents/Abc.jpg -> config CC # 最长匹配到C,往下正则顺序匹配到CC,不会往下到E
实际使用建议
所以实际使用中,个人觉得至少有三个匹配规则定义,如下:#直接匹配网站根,通过域名访问网站首页比较频繁,使用这个会加速处理,官网如是说。#这里是直接转发给后端应用服务器了,也可以是一个静态首页# 第一个必选规则location = / { proxy_pass http://tomcat:8080/index}# 第二个必选规则是处理静态文件请求,这是nginx作为http服务器的强项# 有两种配置模式,目录匹配或后缀匹配,任选其一或搭配使用location ^~ /static/ { root /webroot/static/;}location ~* \.(gif|jpg|jpeg|png|css|js|ico)$ { root /webroot/res/;}#第三个规则就是通用规则,用来转发动态请求到后端应用服务器#非静态文件请求就默认是动态请求,自己根据实际把握#毕竟目前的一些框架的流行,带.php,.jsp后缀的情况很少了location / { proxy_pass http://tomcat:8080/}参考:http://tengine.taobao.org/book/chapter_02.html http://nginx.org/en/docs/http/ngx_http_rewrite_module.html ewrite功能就是,使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标志位实现url重写以及重定向。rewrite只能放在server{},location{},if{}中,并且只能对域名后边的除去传递的参数外的字符串起作用,例如 http://seanlook.com/a/we/index.php?id=1&u=str 只对/a/we/index.php重写。语法rewrite regex replacement [flag]; 如果相对域名或参数字符串起作用,可以使用全局变量匹配,也可以使用proxy_pass反向代理。表明看rewrite和location功能有点像,都能实现跳转,主要区别在于rewrite是在同一域名内更改获取资源的路径,而location是对一类路径做控制访问或反向代理,可以proxy_pass到其他机器。很多情况下rewrite也会写在location里,它们的执行顺序是:[list=1]Rewrite规则
- last : 相当于Apache的[L]标记,表示完成rewrite
- break : 停止执行当前虚拟主机的后续rewrite指令集
- redirect : 返回302临时重定向,地址栏会显示跳转后的地址
- permanent : 返回301永久重定向,地址栏会显示跳转后的地址
- 当表达式只是一个变量时,如果值为空或任何以0开头的字符串都会当做false
- 直接比较变量和内容时,使用=或!=
- ~正则表达式匹配,~*不区分大小写的匹配,!~区分大小写的不匹配
if ($http_user_agent ~ MSIE) { rewrite ^(.*)$ /msie/$1 break;} //如果UA包含"MSIE",rewrite请求到/msid/目录下if ($http_cookie ~* "id=([^;]+)(?:;|$)") { set $id $1; } //如果cookie匹配正则,设置变量$id等于正则引用部分if ($request_method = POST) { return 405;} //如果提交方法为POST,则返回状态405(Method not allowed)。return不能返回301,302if ($slow) { limit_rate 10k;} //限速,$slow可以通过 set 指令设置if (!-f $request_filename){ break; proxy_pass http://127.0.0.1; } //如果请求的文件名不存在,则反向代理到localhost 。这里的break也是停止rewrite检查if ($args ~ post=140){ rewrite ^ http://example.com/ permanent;} //如果query string中包含"post=140",永久重定向到example.comlocation ~* \.(gif|jpg|png|swf|flv)$ { valid_referers none blocked www.jefflei.com www.leizhenfang.com; if ($invalid_referer) { return 404; } //防盗链} 全局变量下面是可以用作if判断的全局变量:- $args : #这个变量等于请求行中的参数,同$query_string
- $content_length : 请求头中的Content-length字段。
- $content_type : 请求头中的Content-Type字段。
- $document_root : 当前请求在root指令中指定的值。
- $host : 请求主机头字段,否则为服务器名称。
- $http_user_agent : 客户端agent信息
- $http_cookie : 客户端cookie信息
- $limit_rate : 这个变量可以限制连接速率。
- $request_method : 客户端请求的动作,通常为GET或POST。
- $remote_addr : 客户端的IP地址。
- $remote_port : 客户端的端口。
- $remote_user : 已经经过Auth Basic Module验证的用户名。
- $request_filename : 当前请求的文件路径,由root或alias指令与URI请求生成。
- $scheme : HTTP方法(如http,https)。
- $server_protocol : 请求使用的协议,通常是HTTP/1.0或HTTP/1.1。
- $server_addr : 服务器地址,在完成一次系统调用后可以确定这个值。
- $server_name : 服务器名称。
- $server_port : 请求到达服务器的端口号。
- $request_uri : 包含请求参数的原始URI,不包含主机名,如:”/foo/bar.php?arg=baz”。
- $uri : 不带请求参数的当前URI,$uri不包含主机名,如”/foo/bar.html”。
- $document_uri : 与$uri相同。
$host:localhost$server_port:88$request_uri:http://localhost:88/test1/test2/test.php$document_uri:/test1/test2/test.php$document_root:/var/www/html$request_filename:/var/www/html/test1/test2/test.php常用正则
- . : 匹配除换行符以外的任意字符
- ? : 重复0次或1次
- + : 重复1次或更多次
- * : 重复0次或更多次
- \d :匹配数字
- ^ : 匹配字符串的开始
- $ : 匹配字符串的介绍
- {n} : 重复n次
- {n,} : 重复n次或更多次
- [c] : 匹配单个字符c
- [a-z] : 匹配a-z小写字母的任意一个
小括号()之间匹配的内容,可以在后面通过$1来引用,$2表示的是前面第二个()里的内容。正则里面容易让人困惑的是\转义特殊字符。
rewrite实例
示例1:
http {
# 定义image日志格式
log_format imagelog '[$time_local] ' $image_file ' ' $image_type ' ' $body_bytes_sent ' ' $status;
# 开启重写日志
rewrite_log on;
server {
root /home/www;
location / {
# 重写规则信息
error_log logs/rewrite.log notice;
# 注意这里要用‘’单引号引起来,避免{}
rewrite '^/images/([a-z]{2})/([a-z0-9]{5})/(.*)\.(png|jpg|gif)$' /data?file=$3.$4;
# 注意不能在上面这条规则后面加上“last”参数,否则下面的set指令不会执行
set $image_file $3;
set $image_type $4;
}
location /data {
# 指定针对图片的日志格式,来分析图片类型和大小
access_log logs/images.log mian;
root /data/images;
# 应用前面定义的变量。判断首先文件在不在,不在再判断目录在不在,如果还不在就跳转到最后一个url里
try_files /$arg_file /image404.html;
}
location = /image404.html {
# 图片不存在返回特定的信息
return 404 "image not found\n";
}
}对形如/images/ef/uh7b3/test.png的请求,重写到/data?file=test.png,于是匹配到location /data,先看/data/images/test.png文件存不存在,如果存在则正常响应,如果不存在则重写tryfiles到新的image404 location,直接返回404状态码。示例2:
rewrite ^/images/(.*)_(\d+)x(\d+)\.(png|jpg|gif)$ /resizer/$1.$4?width=$2&height=$3? last;对形如/images/bla_500x400.jpg的文件请求,重写到/resizer/bla.jpg?width=500&height=400地址,并会继续尝试匹配location。 收起阅读 »


Centos7下添加开机自启动服务和脚本
1、添加开机自启服务
我这里以docker 服务为例,设置如下两条命令即可:
# systemctl enable docker.service #设置docker服务为自启动服务 相当于我们的 chkconfig docker on
# sysstemctl start docker.service #启动docker服务
2、添加开机自启脚本
在centos7中增加脚本有两种常用的方法,以脚本StartTomcat.sh为例:
#!/bin/bash方法一:
# description:开机自启脚本
/usr/local/tomcat/bin/startup.sh #启动tomcat
1、赋予脚本可执行权限(/opt/script/StartTomcat.sh是你的脚本路径)
# chmod +x /opt/script/StartTomcat.sh2、打开/etc/rc.d/rc.local文件,在末尾增加如下内容
echo "/opt/script/StartTomcat.sh" >> /etc/rc.d/rc.local3、在centos7中,/etc/rc.d/rc.local的权限被降低了,所以需要执行如下命令赋予其可执行权限
chmod +x /etc/rc.d/rc.local
方法二:
1、将脚本移动到/etc/rc.d/init.d目录下
# mv /opt/script/StartTomcat.sh /etc/rc.d/init.d2、增加脚本的可执行权限
chmod +x /etc/rc.d/init.d/StartTomcat.sh3、添加脚本到开机自动启动项目中
cd /etc/rc.d/init.d收起阅读 »
chkconfig --add StartTomcat.sh
chkconfig StartTomcat.sh on
Shell脚本判断变量或者文件是否存在案例

脚本代码1:
#!/bin/bash
# site: openskill.cn
myPath="/data/logs"
myFile="/data/logs/access.log"
# 这里的-x 参数判断$myPath是否存在并且是否具有可执行权限
if [ ! -x "$myPath"];then
mkdir "$myPath"
fi
# 这里的-d 参数判断$myPath是否存在
if [ ! -d "$myPath"]; then
mkdir "$myPath"
fi
# 这里的-f参数判断$myFile是否存在
if [ ! -f "$myFile" ]; then
touch "$myFile"
fi
# 其他参数还有-n,-n是判断一个变量是否是否有值
if [ ! -n "$myVar" ]; then
echo "$myVar is empty"
exit 0
fi
# 两个变量判断是否相等
if [ "$var1" = "$var2" ]; then
echo '$var1 eq $var2'
else
echo '$var1 ne $var2'
fi
脚本代码2:
#/bin/bash收起阅读 »
#如果文件夹不存在,创建文件夹
if [ ! -d "/data" ]; then
mkdir /data
fi
#shell判断文件,目录是否存在或者具有权限
folder="/data/www"
file="/data/www/log"
# -x 参数判断 $folder 是否存在并且是否具有可执行权限
if [ ! -x "$folder"]; then
mkdir "$folder"
fi
# -d 参数判断 $folder 是否存在
if [ ! -d "$folder"]; then
mkdir "$folder"
fi
# -f 参数判断 $file 是否存在
if [ ! -f "$file" ]; then
touch "$file"
fi
# -n 判断一个变量是否有值
if [ ! -n "$var" ]; then
echo "$var is empty"
exit 0
fi
# 判断两个变量是否相等
if [ "$var1" = "$var2" ]; then
echo '$var1 eq $var2'
else
echo '$var1 ne $var2'
fi
shell中条件判断if中的-a到-z的意思
[ -a FILE ] 如果 FILE 存在则为真。
[ -b FILE ] 如果 FILE 存在且是一个块特殊文件则为真。
[ -c FILE ] 如果 FILE 存在且是一个字特殊文件则为真。
[ -d FILE ] 如果 FILE 存在且是一个目录则为真。
[ -e FILE ] 如果 FILE 存在则为真。
[ -f FILE ] 如果 FILE 存在且是一个普通文件则为真。
[ -g FILE ] 如果 FILE 存在且已经设置了SGID则为真。
[ -h FILE ] 如果 FILE 存在且是一个符号连接则为真。
[ -k FILE ] 如果 FILE 存在且已经设置了粘制位则为真。
[ -p FILE ] 如果 FILE 存在且是一个名字管道(F如果O)则为真。
[ -r FILE ] 如果 FILE 存在且是可读的则为真。
[ -s FILE ] 如果 FILE 存在且大小不为0则为真。
[ -t FD ] 如果文件描述符 FD 打开且指向一个终端则为真。
[ -u FILE ] 如果 FILE 存在且设置了SUID (set user ID)则为真。
[ -w FILE ] 如果 FILE 如果 FILE 存在且是可写的则为真。
[ -x FILE ] 如果 FILE 存在且是可执行的则为真。
[ -O FILE ] 如果 FILE 存在且属有效用户ID则为真。
[ -G FILE ] 如果 FILE 存在且属有效用户组则为真。
[ -L FILE ] 如果 FILE 存在且是一个符号连接则为真。
[ -N FILE ] 如果 FILE 存在 and has been mod如果ied since it was last read则为真。
[ -S FILE ] 如果 FILE 存在且是一个套接字则为真。
[ FILE1 -nt FILE2 ] 如果 FILE1 has been changed more recently than FILE2,or 如果 FILE1 exists and FILE2 does not则为真。
[ FILE1 -ot FILE2 ] 如果 FILE1 比 FILE2 要老, 或者 FILE2 存在且 FILE1 不存在则为真。
[ FILE1 -ef FILE2 ] 如果 FILE1 和 FILE2 指向相同的设备和节点号则为真。
[ -o OPTIONNAME ] 如果 shell选项 “OPTIONNAME” 开启则为真。
[ -z STRING ] “STRING” 的长度为零则为真。
[ -n STRING ] or [ STRING ] “STRING” 的长度为非零 non-zero则为真。
[ ARG1 OP ARG2 ] “OP” is one of -eq, -ne, -lt, -le, -gt or -ge. These arithmetic binary operators return true if “ARG1” is equal to, not equal to, less than, less than or equal to, greater than, or greater than or equal to “ARG2”, respectively. “ARG1” and “ARG2” are integers.
数字判断
[ $count -gt "1"] 如果$count 大于1 为真
-gt 大于
-lt 小于
-ne 不等于
-eq 等于
-ge 大于等于
-le 小于等于
[ STRING1 == STRING2 ] 如果2个字符串相同。 “=” may be used instead of “==” for strict POSIX compliance则为真。
[ STRING1 != STRING2 ] 如果字符串不相等则为真。
[ STRING1 < STRING2 ] 如果 “STRING1” sorts before “STRING2” lexicographically in the current locale则为真。
[ STRING1 > STRING2 ] 如果 “STRING1” sorts after “STRING2” lexicographically in the current locale则为真。 收起阅读 »
Shell下判断一个命令是否存的最好方法

通常情况下,我们利用Shell脚本写一些服务启动脚本或者软件的初始化启动脚本的时候,经常会依赖一些外部的目录,比如Linux下解压zip压缩包你会依赖unzip命令等情况。那在shell下我们怎么判断一个命令是否存在呢,看完下面的分析你就了解了。
1、which非SHELL的内置命令,用起来比内置命令的开销大,并且非内置命令会依赖平台的实现,不同平台的实现可能不同。
[root@node1 ~]# type scp从上面可以看出command为内置命令,而which非内置命令。
scp is /usr/bin/scp
[root@node1 ~]# type command
command is a shell builtin
[root@node1 ~]# type which
which is aliased to `alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
2、很多系统的which并不设置退出时的返回值,即使要查找的命令不存在,which也返回0
[root@node1 ~]# which ls所以许多系统的which实现,都偷偷摸摸干了一些“不足为外人道也”的事情。
/usr/bin/ls
[root@node1 ~]# echo $?
0
[root@node1 ~]# which www
no www in /usr/bin /bin /usr/sbin /sbin /usr/local/bin /usr/local/bin /usr/local/sbin /usr/ccs/bin
[root@node1 ~]# echo $?
0
所以,不要用which,可以使用下面的方法:
$ command -v foo >/dev/null 2>&1 || { echo >&2 "I require foo but it's not installed. Aborting."; exit 1; }
$ type foo >/dev/null 2>&1 || { echo >&2 "I require foo but it's not installed. Aborting."; exit 1; }
$ hash foo 2>/dev/null || { echo >&2 "I require foo but it's not installed. Aborting."; exit 1; }The following is a portable way to check whether a command exists in PATH and is executable:更精彩的分析参考:http://stackoverflow.com/questions/592620/check-if-a-program-exists-from-a-bash-script 收起阅读 »
[ -x "$(command -v foo)" ]
Example:
if ! [ -x "$(command -v git)" ]; then
echo 'Error: git is not installed.' >&2
exit 1
fi
修改Ubuntu14.10网卡逻辑名实践
网卡信息查询
eth0 Link encap:以太网 硬件地址 52:54:00:09:e2:11上述HWaddr后面为eth0接口的MAC地址: 52:54:00:09:e2:11
inet 地址:10.0.3.94 广播:10.0.3.255 掩码:255.255.255.0
inet6 地址: fe80::5054:ff:fe09:e211/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 跃点数:1
接收数据包:4541 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:1908 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1000
接收字节:288707 (288.7 KB) 发送字节:691213 (691.2 KB)
lo Link encap:本地环回
inet 地址:127.0.0.1 掩码:255.0.0.0
inet6 地址: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 跃点数:1
接收数据包:2503 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:2503 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:0
接收字节:836481 (836.4 KB) 发送字节:836481 (836.4 KB)
查看已有网卡逻辑名:
root@ubuntu1410:~# ls /sys/class/net/
eth0 lo
查看指定网卡MAC地址:
eth0 Link encap:以太网 硬件地址 52:54:00:09:e2:11
inet 地址:10.0.3.94 广播:10.0.3.255 掩码:255.255.255.0
inet6 地址: fe80::5054:ff:fe09:e211/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 跃点数:1
接收数据包:5512 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:2332 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1000
接收字节:351337 (351.3 KB) 发送字节:855606 (855.6 KB)
生成配置文件
root@ubuntu1410:~# export INTERFACE="eth0"首先引入两个变量INTERFACE,MATCHADDR,然后执行write_net_rules,查看生成的文件70-persistent-net.rules
root@ubuntu1410:~# export MATCHADDR="52:54:00:09:e2:11"
root@ubuntu1410:~# /lib/udev/write_net_rules # 生成命令
root@ubuntu1410:~# ls /etc/udev/rules.d/
70-persistent-net.rules
文件内容如下,删除KERNEL项,并修改NAME值。
# This file was automatically generated by the /lib/udev/write_net_rules修改后:
# program, run by the persistent-net-generator.rules rules file.
#
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="52:54:00:09:e2:11", KERNEL=="eth*", NAME="eth0"
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="52:54:00:09:e2:11", NAME="em0"
禁用源网卡逻辑名规则文件
root@ubuntu1410:/etc/udev/rules.d# cd /lib/udev/rules.d/
root@ubuntu1410:/lib/udev/rules.d# mv 75-persistent-net-generator.rules 75-persistent-net-generator.rules.disabled
修改网卡配置
root@ubuntu1410:~# cat /etc/network/interfaces修改后:
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
iface eth0 inet static
address 10.0.3.94
gateway 10.0.3.1
netmask 255.255.255.0
dns-nameservers 222.222.222.222
# The loopback network interface不需要重启网卡,直接重启系统。
auto lo
iface lo inet loopback
# The primary network interface
auto em0
iface em0 inet static
address 10.0.3.94
gateway 10.0.3.1
netmask 255.255.255.0
dns-nameservers 222.222.222.222
重启后查看新的网卡逻辑名
root@ubuntu1410:~# ls /sys/class/net/到这里,网卡逻辑名称就修改完成了。 收起阅读 »
em0 lo
root@ubuntu1410:~# ifconfig em0
em0 Link encap:以太网 硬件地址 52:54:00:09:e2:11
inet 地址:10.0.3.94 广播:10.0.3.255 掩码:255.255.255.0
inet6 地址: fe80::5054:ff:fe09:e211/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 跃点数:1
接收数据包:8413 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:3456 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1000
接收字节:525779 (525.7 KB) 发送字节:1092548 (1.0 MB)
root@ubuntu1410:~#
搜索引擎科学上网技能大放送
在今天,用户可以通过搜索引擎轻松找出自己想要的信息,但还是难以避免结果不尽如人意的情况。实际上,用户仅需掌握几个常用技巧即可轻松化解这种尴尬。
正常情况下我们搜索的关键是正确的关键词和搜搜引擎的选择,通过正确的搜索我们能得到答案的问题可以到80%以上。
常用引擎推荐
No.1 谷歌(https://google.com)
No.2 百度 (https://www.baidu.com/)
No.3 鸭鸭快跑 (https://duckduckgo.com/)
No.4 必应 (http://cn.bing.com/ )
No.5 搜狗 (https://www.sogou.com/)
排错搜索过程
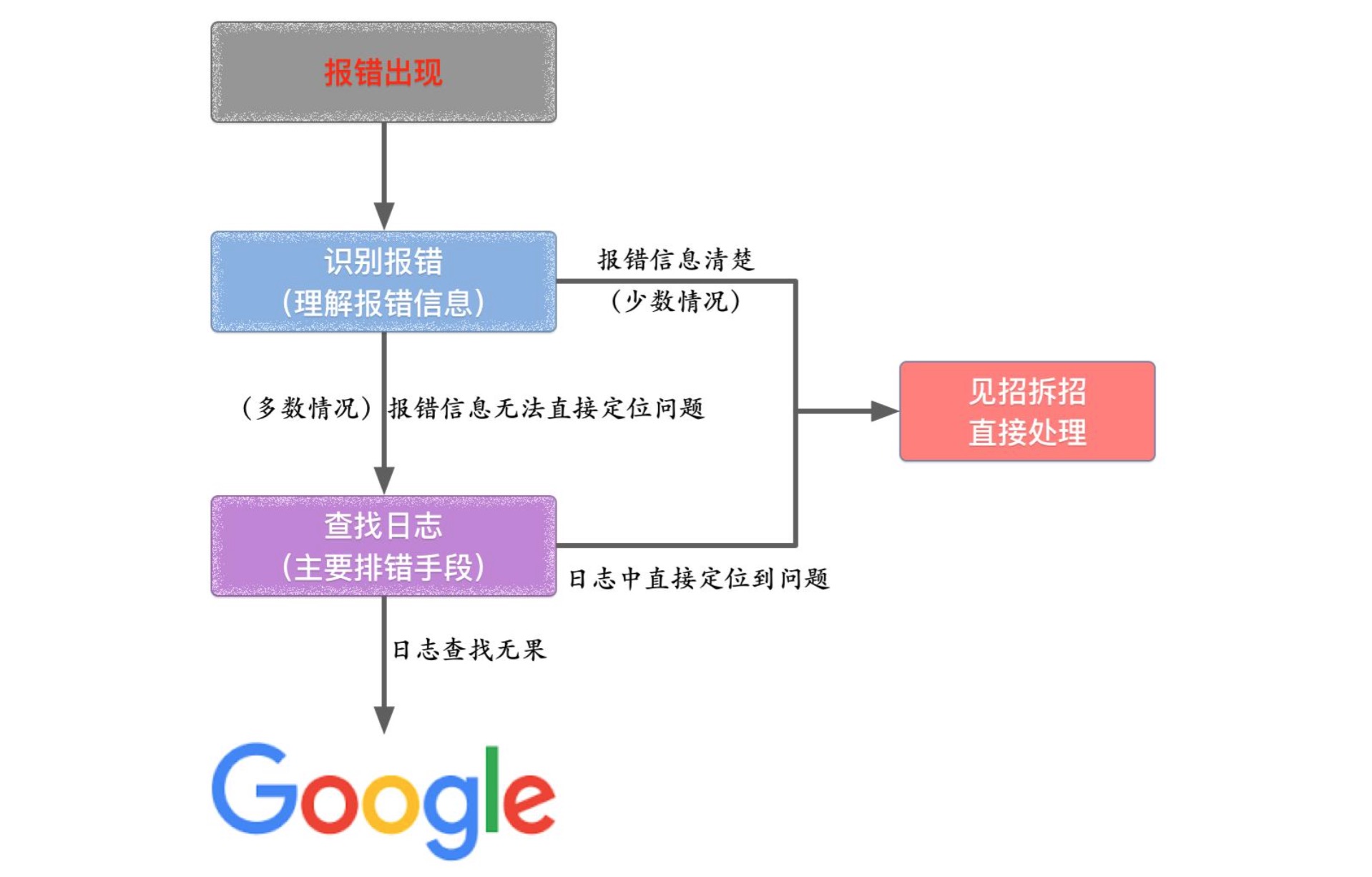
1、准确搜索
最简单、有效的准确搜索方式是在关键词上加上双引号,在这种情况下,搜索引擎只会反馈和关键词完全吻合的搜索结果, 把搜索词放在双引号中,代表完全匹配搜索,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必 须完全匹配.
比方说在搜索「zabbix mysql」的时候,在没有给关键词加上双引号的情况,搜索引擎会显示所有分别和「zabbix」以及「mysql」相关的信息,但这些显然并不是我们想要的结果。但在加上双引号后,搜索引擎则仅会在页面上反馈和「zabbix mysql」相吻合的信息。
准确搜索在排除常见但相近度偏低的信息时非常有用,可以为用户省去再度对结果进行筛选的麻烦。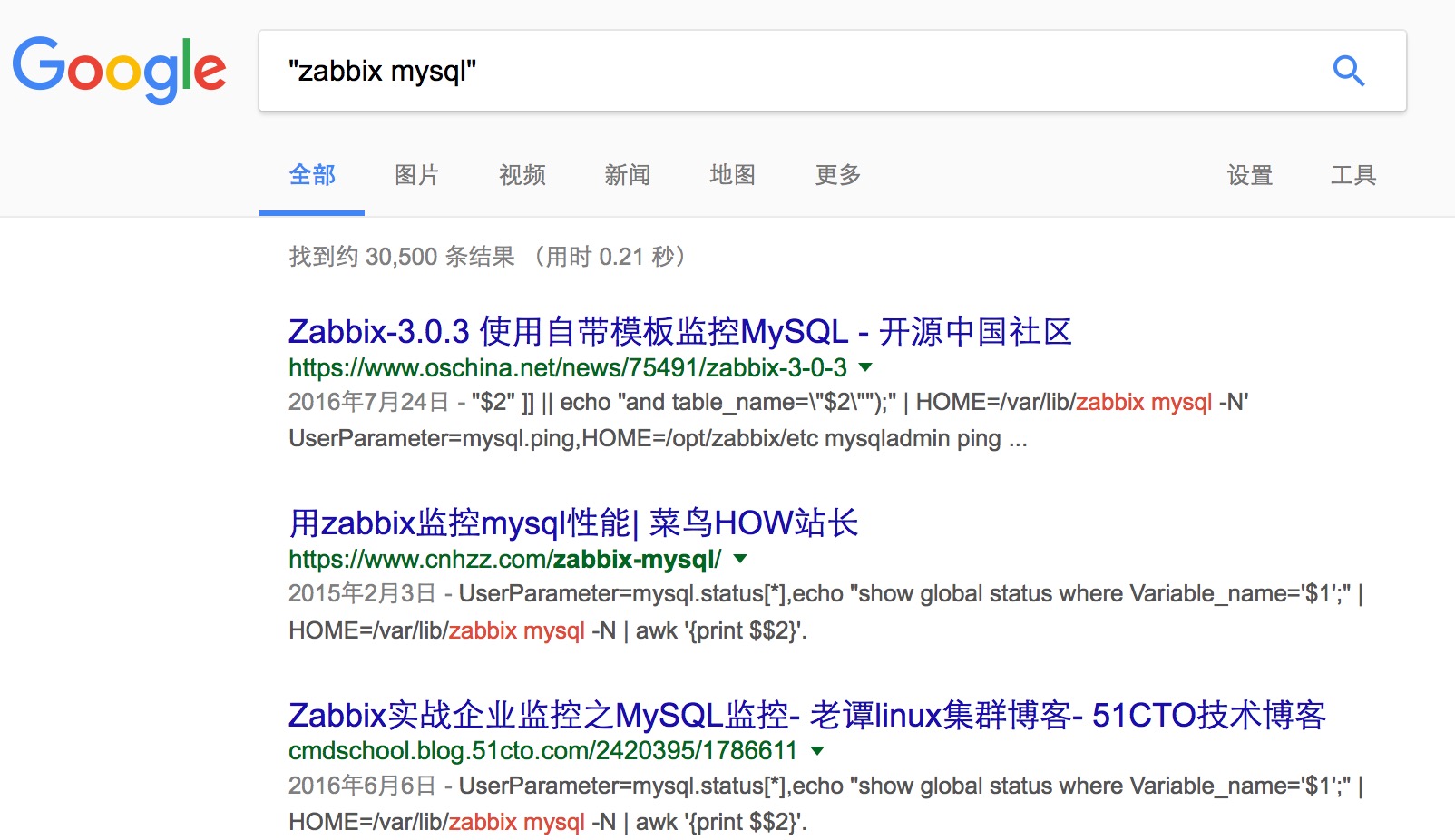
2、加号
在搜索引擎框里把多个关键字用加号(+)连接起来,搜索引擎就会自动去匹配互联网上与所有关键词相关的内容,默认与 空格等效,百度和Google都支持。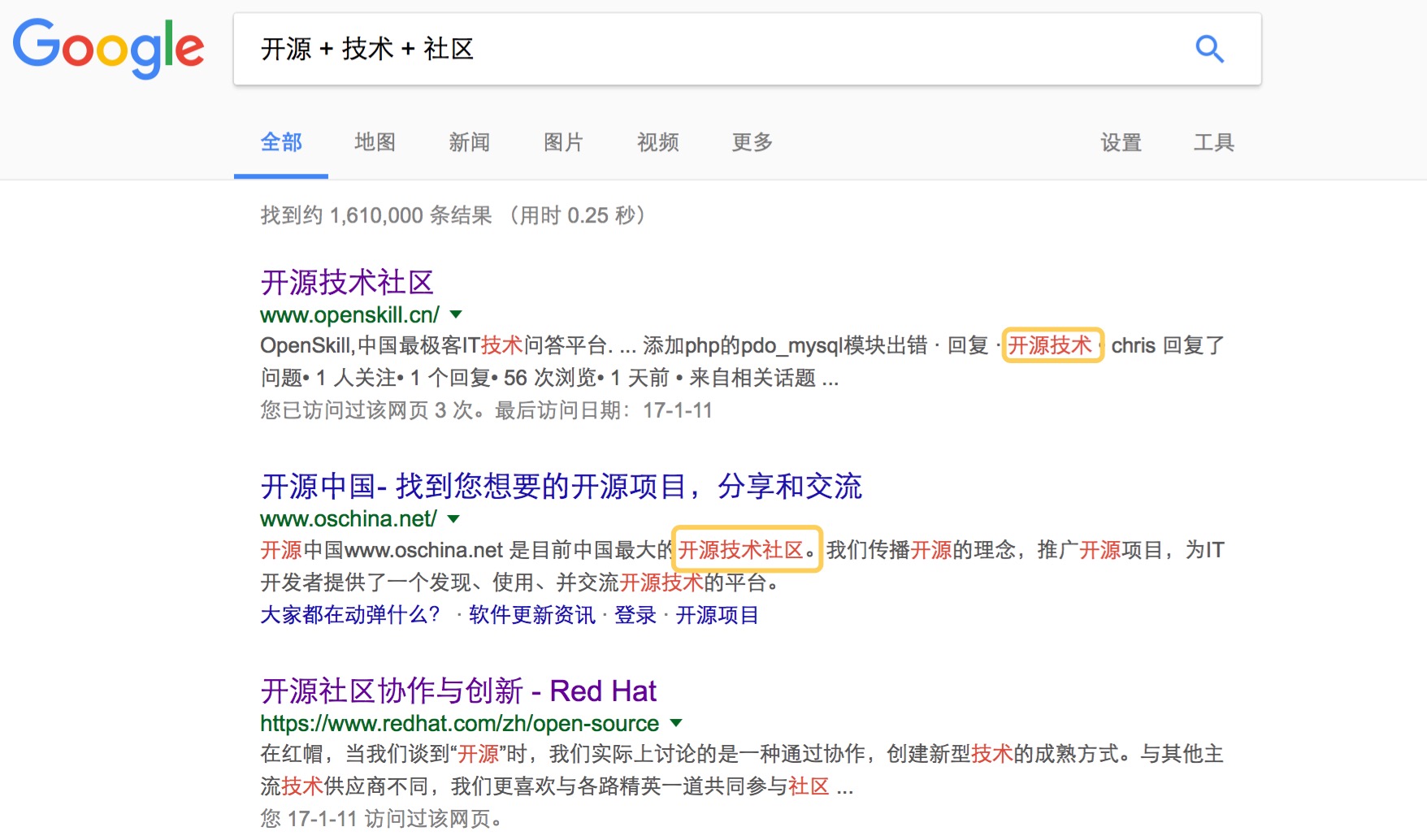
3、减号-排除关键词
如果在进行准确搜索时没有找到自己想要的结果,用户可以对包含特定词汇的信息进行排除,仅需使用减号即可。
减号代表搜索不包含减号后面的词的页面。使用这个指令时减号前面必须是空格,减号后面没有空格,紧跟着需要排除的词 。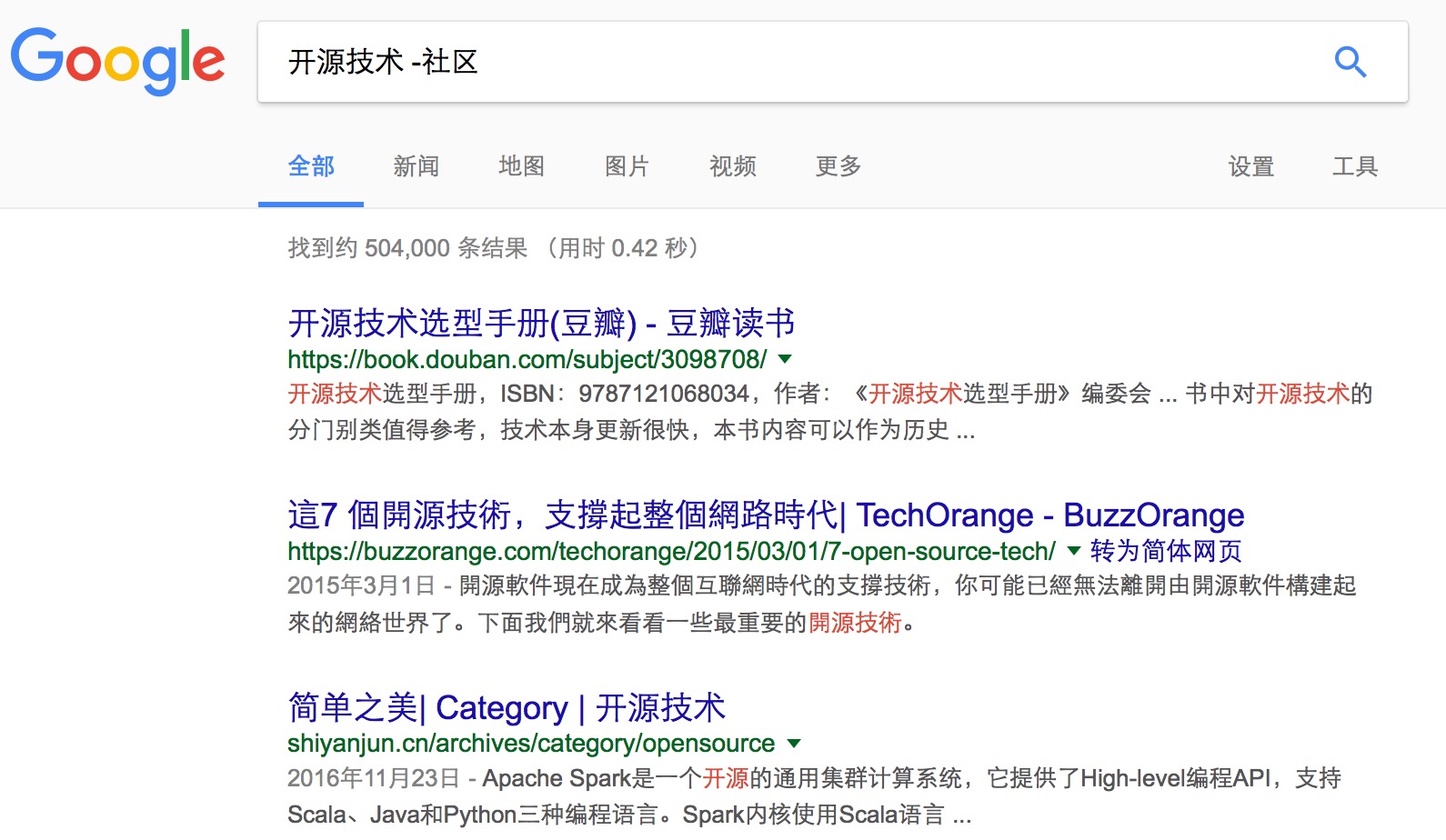
4、OR或逻辑搜索
在默认搜索下,搜索引擎会反馈所有和查询词汇相关的结果,但通过使用「OR」逻辑,你可以得到和两个关键词分别相关的结果,而不仅仅是和两个关键词 都同时相关的结果。巧妙使用「OR」搜索可以让你在未能确定哪个关键词对于搜索结果起决定作用时依然可以确保搜索结果的准确性。
5、同义词搜索
有时候对不太确切的关键词进行搜索反而会显得更加合适。在未能准确判断关键词的情况下,你可以通过同义词进行搜索。
如果你在搜索引擎输入「plumbing ~university」,你所得到的反馈结果会包含「plumbing universities」和「plumbing colleges」等相似条目。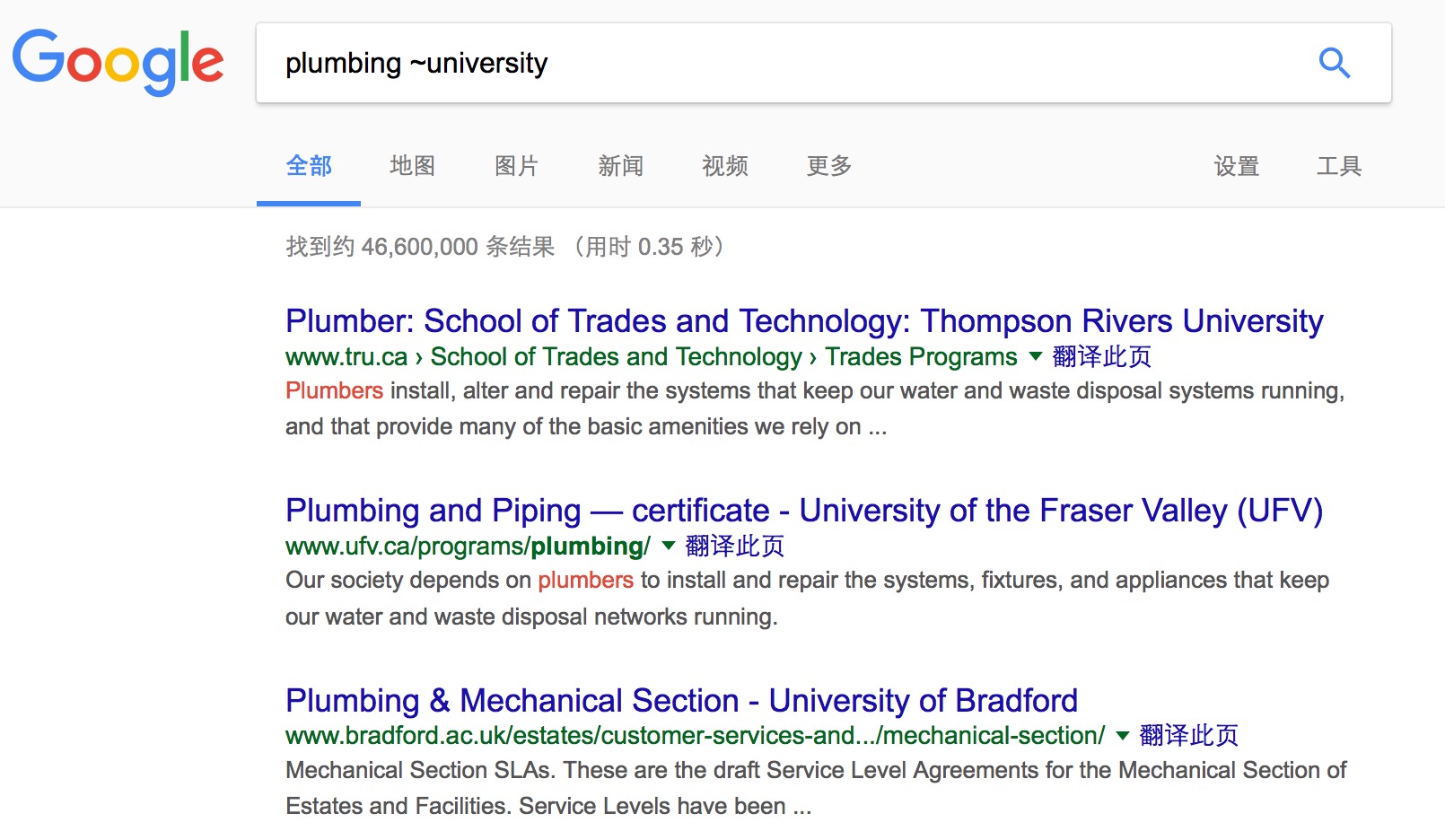
6、善用星号
正如拼图游戏「Scrabble」的空白方块一样,在搜索引擎中,我们可以用星号填补关键词中的缺失部分,不论缺失的是一连串单词的其中一个还是一个单词的某一部分。此外,当你希望搜索一篇确定性偏低的文章时,也可以使用星号填补缺失部分。
例如,如果你在搜索引擎中输入「architect*」,你所得到的反馈结果将会是所有包含 architect、architectural、architecture、architected、architecting 以及其他所有以「architect」作为开头的词汇的条目。
常用的案例:搜索报错中的特定路径 , 有个词忘记了或者不会打: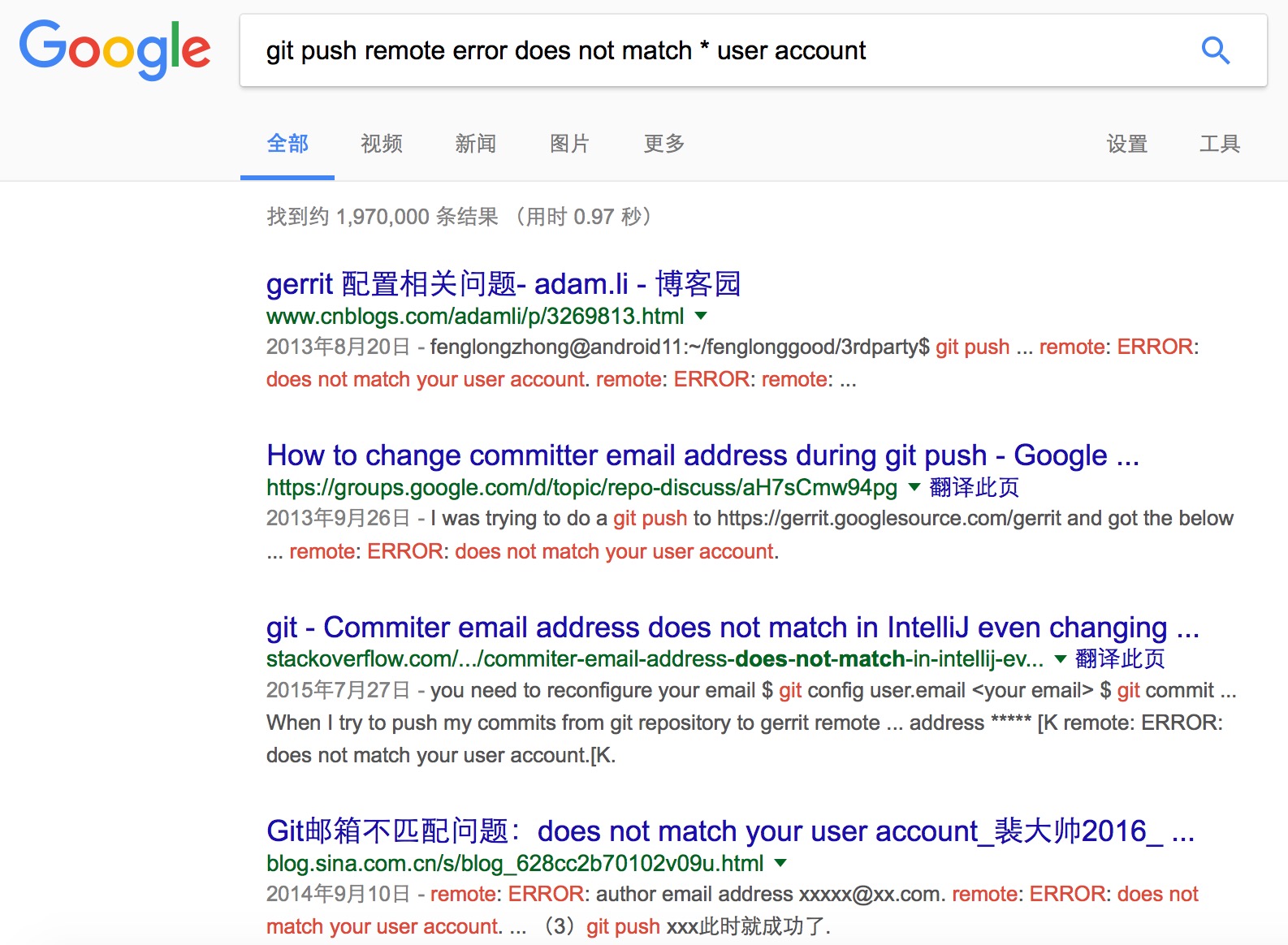
7、在两个数值之间进行搜索
在寻找问题的答案时,一个很好的方法是在一定范围内寻找和关键词相关的资讯。例如想要找出 1920 至 1950 年间的英国首相,直接在搜索引擎中输入「英国首相 1920.. 1950」即可得出想要的结果。
记住,数值之间的符号是两个英文句号加一个空格键。
8、inurl
该指令用于搜索查询词出现在url中的页面。BaiDu和Google都支持inurl指令。inurl指令支持中文和英文。 比如搜索:inurl:hadoop,返回的结果都是网址url中包含“hadoop”的页面。由于关键词出现在url 中对排名有一定影响,使用inurl:搜索可以更准确地找到与关键字相关的内容。
例如:inurl:openskill hadoop
9、intitle在网页标题、链接和主体中搜索关键词
有时你或许会遇上找出所有和关键词相关的所有网页标题、链接和网页主体的需求,在这个时候你需要使用的是限定词「inurl:」(供在 url 链接中搜索使用)、「intext:」(供在网页主体中搜索使用)以及「intitle:」(供在网页标题中搜索使用)。
使用intitle 指令找到的文件更为准确。出现在title中,说明页面内容跟关键字有很大关联。
10、allintitle
allintitle:搜索返回的是页面标题中包含多组关键词的文件。例如 :allintitle:zabbix docker,就相当于:intitle:zabbix intitle:docker,返回的是标题中中既包含“zabbix”,也包含“docker”的页面,显著提高搜索命中率。
11、allinurl
与allintitle: 类似,allinurl:zabbix hadoop,就相当于 : inurl:zabbix inurl:hadoop
12、site站内搜索
绝大部分网站的搜索功能都有所欠缺,因此,更好的方法是通过 Google 等搜索引擎对站内的信息进行搜索。
你只需要在搜索引擎上输入「site:openskill.cn」加上关键词,搜索引擎就会反馈网站「openskill.cn」内和关键词相关的所有条目。如果再结合准确搜索功能,这项功能将会变得更加强大。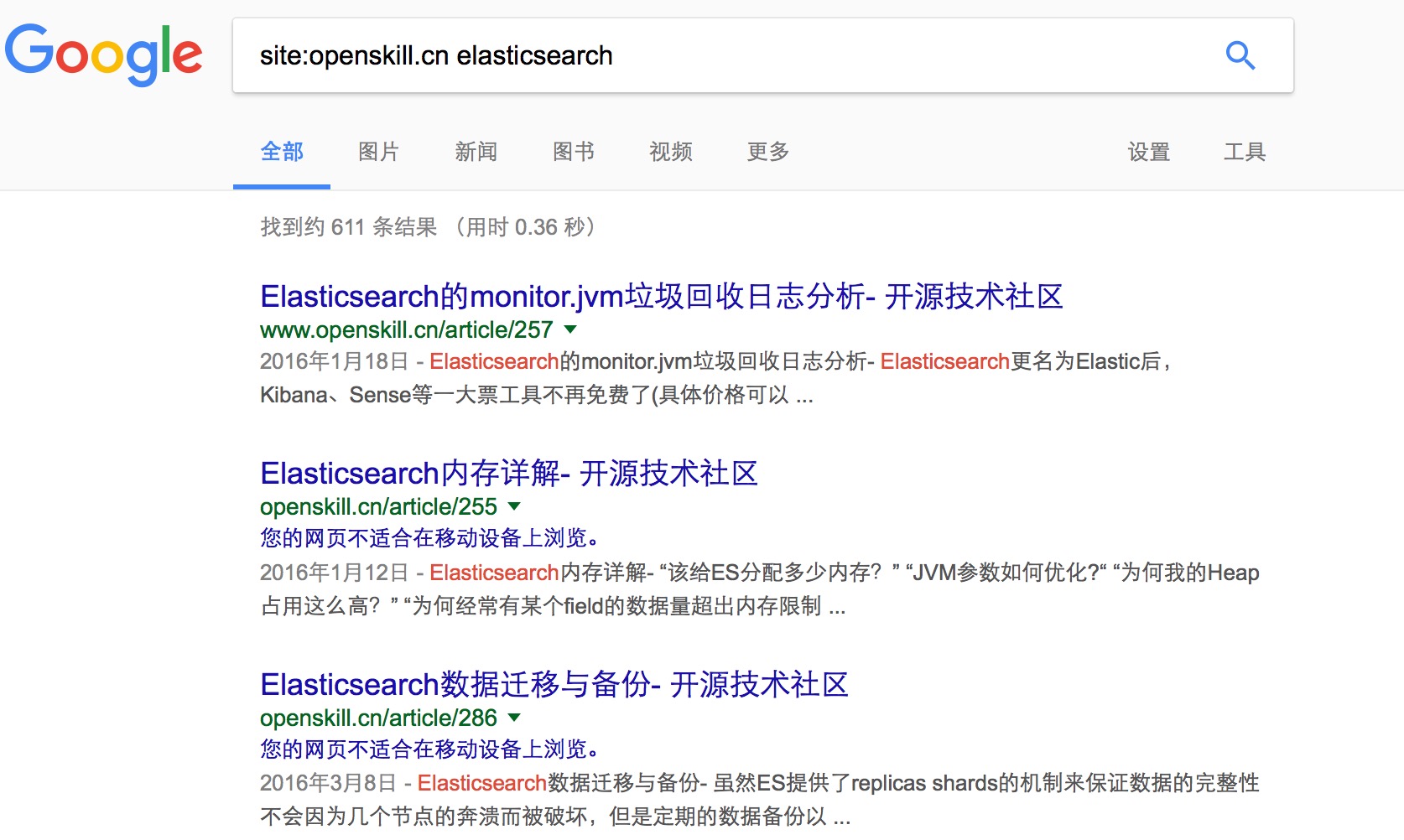
13、filetype
用于搜索特定文件格式。Google 和bd都支持filetype指令。 比如搜索filetype:pdf docker 返回的就是包含SEO 这个关键词的所有pdf 文件。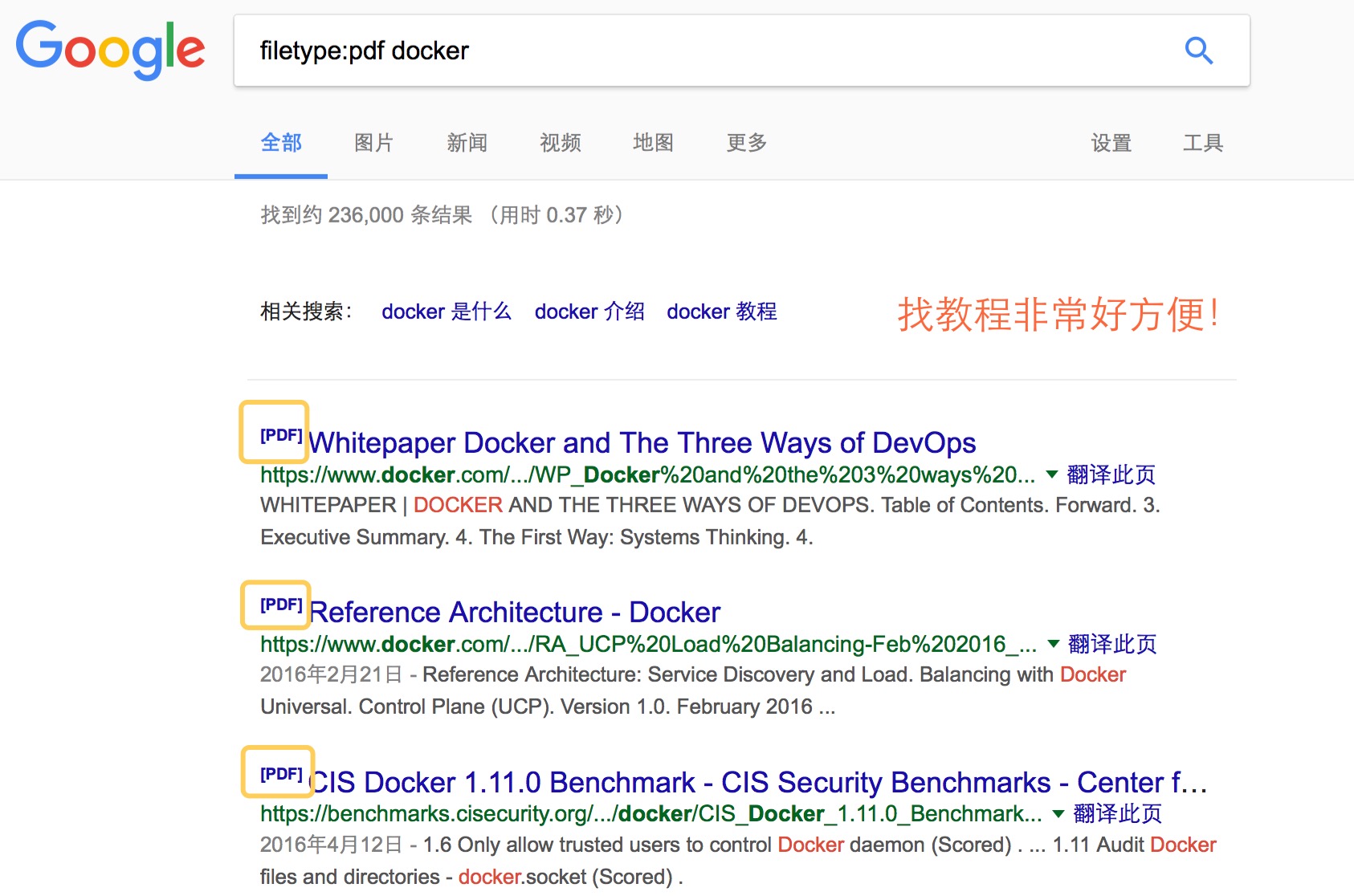
14、搜索相关网站
查找与您已浏览过的网址类似的网站, 例如,你仅需在搜索引擎中输入「related:openskill.cn」即可得到所有和「openskill.cn」相关的网站反馈结果。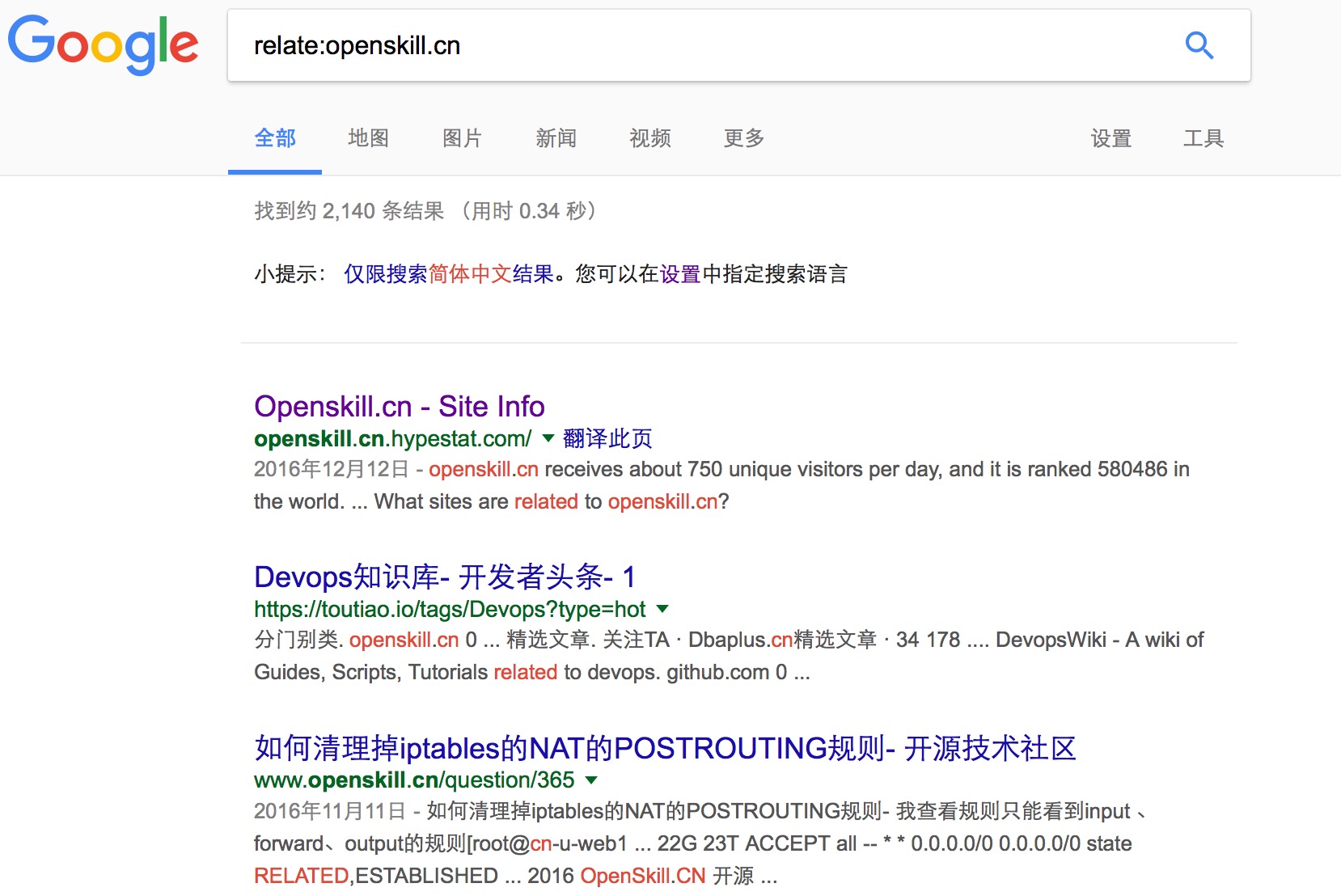
15、搜索技能的组合使用
你可以对上述所有搜索技能进行组合运用,以便按照自己的意愿缩小或者扩展搜索范围。尽管有些技能或许并不常用,但准确搜索和站内搜索这些技能的使用范围还是相当广泛的。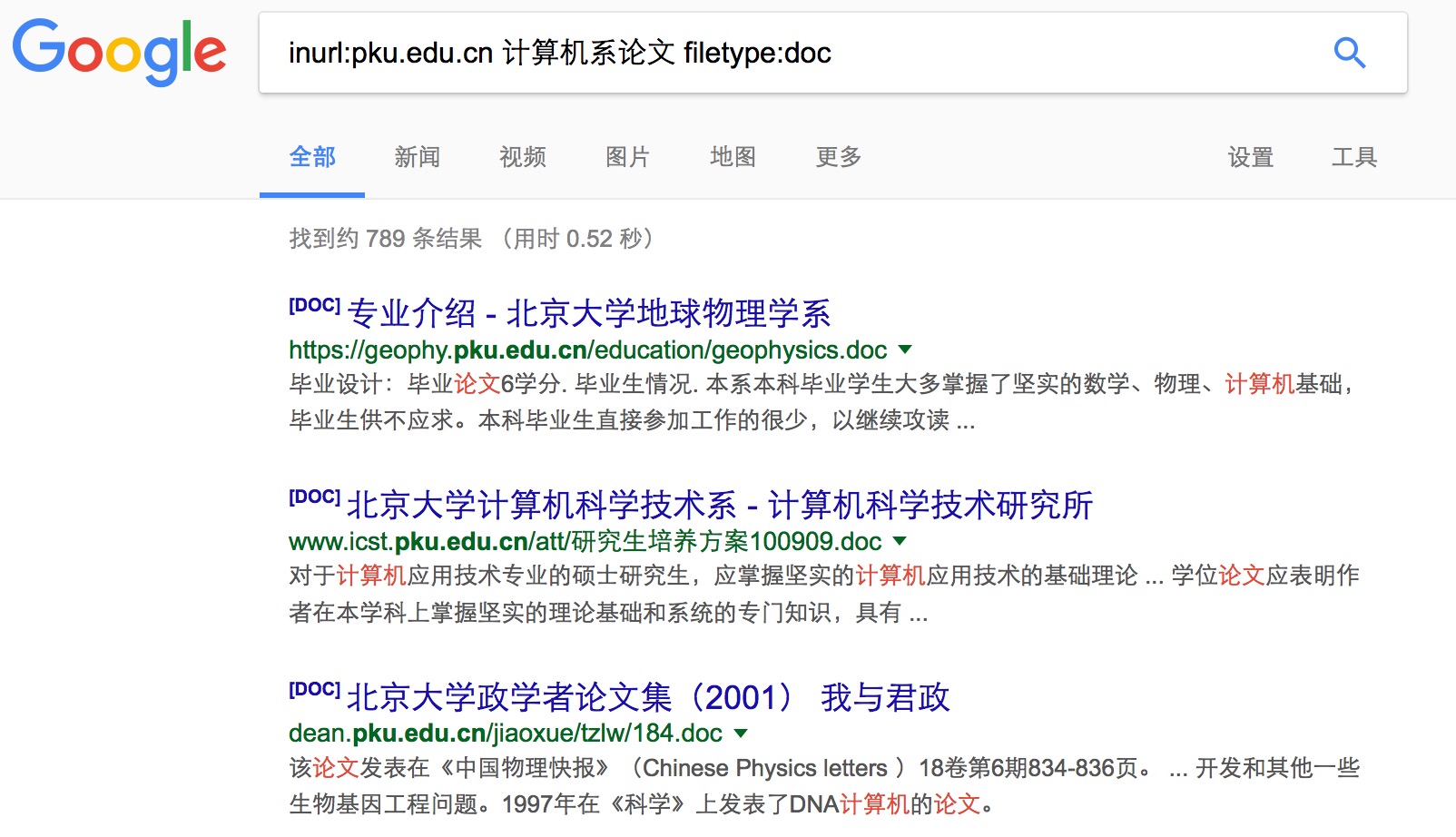
其他技巧

随着 Google 等搜索引擎对于用户自然语言的理解程度与日俱增,这些搜索技能可以派上用场的情况或许将会变得越来越少,至少这是所有搜索引擎共同追求的目标。但是在当下,掌握这些搜索技能还是非常必要的。
参考:http://www.cnblogs.com/feiyuhuo/p/5398238.html http://blog.jobbole.com/72211/
收起阅读 »企业OpenVPN部署认证实战

相关概念
1、vpn 介绍
vpn 虚拟专用网络,是依靠isp和其他的nsp,在公共网络中建立专用的数据通信网络的技术。在vpn中任意两点之间的链接并没有传统的专网所需的端到端的物理链路,而是利用公共网络资源动态组成的,可以理解为通过私有的隧道技术在公共数据网络上模拟出来的和专网有相同功能的点到点的专线技术,所谓虚拟是指不需要去拉实际的长途物理线路,而是借用公共的Internet网络实现。
2、vpn 作用
vpn可以帮助公司用的远程用户(出差,家里)公司的分之机构、商业合作伙伴及供应商等公司和自己的公司内部网络之间建立可信的安全连接或者局域网连接,确保数据的加密安全传输和业务访问,对于运维工程师来说,还可以连接不同的机房为局域网,处理相关的业务流。
3、常见vpn功能的开源产品
3.1 pptp vpn
最大优势在于无需在windows客户端单独安装vpn客户端软件,windows默认就支持pptp vpn拨号功能。他是属于点对点的方式应用,比较适合远程企业用户拨号到企业进行办公等应用,缺点很多小区及网络设备不支持pptp导致无法访问。
3.2 SSL VPN(openvpn)
PPTP主要为常在外面移动或者家庭办公的用户考虑的,而OpenVpn不但可以使用与PPTP的场景,还是和针对企业异地两地总分公司之间的vpn不间断按需链接,例如:ERP,OA及时通讯工具等在总分公司企业中的应用,缺点:需要单独安装客户端软件。
3.3 IPSEC VPN
IPSEC VPN 也适合针对企业异地两地中分公司或者多个IDC机房之间的VPN的不间断按需链接,并且在部署使用上更简单方便。IPSEC Vpn的开源产品openswan.
4、openvpn通讯原理
openvpn所有的通讯都基于一个单一的ip端口(默认1194),默认使用udp协议,同时也支持tcp。openvpn能通过大多数的代理服务器,并且能在NAT的环境很好的工作。openvpn服务端具有客户端“推送”某些网络配置信息的功能,这些信息包括,ip地址,路由设置等。 OPenvpn提供了2个虚拟网络接口:通过TUN/Tap驱动,通过他们,可以建立三层IP隧道,或者虚拟二层以太网,后者可以传送任何类型的二层以太网数据。传送的数据可通过LZO算法压缩。openvpn2.0以后版本每个进程可以同时管理数个并发的隧道。
5、openvpn协议选择
在选择协议的时候,需要注意2个加密隧道支架你的网络状况,如果高延迟或者丢包较多的情况下,请选择TCP协议作为底层协议,UDP协议由于存在无连接和重传机制,导致隧道上层的协议进行重传,效率非常低下,这里建议用tcp协议方式。
6、openvpn的依赖及核心技术
openvpn依赖Openssl,可以使用预设的私钥,第三方证书,用户名密码等进行身份验证。openvpn的技术核心是虚拟网卡,其次是SSL协议实现。
服务器端安装部署
相关软件:lzo压缩模块,可加快传输速度,openvpn 主程序。
安装环境:centos6.4 x64 下安装
1、安装lzo
# cd /usr/local/src/2、安装openvpn
# wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.03.tar.gz
# tar zxf lzo-2.06.tar.gz
# cd lzo-2.06
# ./configure
# make
# make install
# yum install -y openssl* -y && cd /usr/local/src/
# wget http://www.openvpn.net/release/openvpn-2.2.2.tar.gz
# tar zxf openvpn-2.2.2.tar.gz
# cd openvpn-2.2.2
# ./configure --with-lzo-headers=/usr/local/include --with-lzo-lib=/usr/local/lib
# make
# make install
安装环境:ubuntu 12.04 x64 下安装
1、主程序安装
# aptitude install openvpn2、检查安装
# aptitude install libpam-dev libpam-mysql libmysql++-dev sasl2-bin
# ls /usr/share/doc/|grep openvpn3、生成证书
openvpn ##发现已经存在。
#cd /usr/share/doc/openvpn/examples/easy-rsa/2.0/4、建立给server用的certificate & key
# . ./vars ##### 重成环境变量 以下生成的文件都在/usr/share/doc/openvpn/examples/easy-rsa/2.0/keys 下
# ./clean-all ###用来清除之前生成的所有的key
# ./build-ca ####生成ca.crt ca.key
#./build-key-server server5、建立给client用的certificate & key(可以建立多个client)
##“Common Name” 设成 “server”
##会产生以下文件
01.pem
server.crt
server.csr
server.key
## “Common Name” 设成 “clinet1” 以此类推6、建立 Diffie Hellman parameters 和 ta.key
# ./build-key client1
##生成
client1.crt
client1.csr
client1.key
# ./build-key client2
# ./build-key client3
##当然,你也可以只生成一个client,我就是这样做的
# ./build-dh #建立 Diffie Hellman parameters 会生成dh{n}.pem。
# openvpn --genkey --secret ta.key #生成ta.key,防止ddos攻击,client和server同时存储7、拷贝相关文件至/etc/openvpn下。# mv keys/* /etc/openvpn/8、建立配置文件/etc/openvpn/server.conf
# mv ta.key /etc/openvpn/ #不要遗漏
local 10.0.9.10 ###本机IP,这是一个内网IP,不过在路由上已经做了IP 的映射到一个外网ip9、开启操作系统的IP转发设置。
port 1194##指定端口
proto tcp #制定协议
dev tun
;tls-server
ca ca.crt
cert server.crt
key server.key
tls-auth ta.key 0
dh dh1024.pem
server 10.8.0.0 255.255.255.0#拨入后的ip段及网关
ifconfig-pool-persist ipp.txt
#push “redirect-gateway” # 自動將 client 的 default gateway 設成經由 VPN server 出去
keepalive 10 120 # 保持連線,每 10 秒 ping 一次,若是 120 秒未收到封包,即認定 client 斷線
comp-lzo #启用压缩
max-clients 20 # 最多同時只能有十個 client
user nobody
group nogroup # vpn daemon 執行時的身份(在非 Windows 平台中使用)
persist-key #当vpn超时后,当重新启动vpn后,保持上一次使用的私钥,而不重新读取私钥。
persist-tun #通过keepalive检测vpn超时后,当重新启动vpn后,保持tun或者tap设备自动链接状态。
status /etc/openvpn/easy-rsa/keys/openvpn-status.log #日志状态信息
log /var/log/openvpn.log #日志文件
verb 3 ## 日志文件冗余。
# 以下二行是將 vpn server 內部的虛擬 ip 機器開放給 client 使用
push "route 10.0.1.0 255.255.255.0"
push "route 10.0.2.0 255.255.255.0"
push "route 10.0.3.0 255.255.255.0"
plugin ./openvpn-auth-pam.so /usr/sbin/openvpn ###这个是用来mysql 认证的,如不需要可注释掉
# echo 1 > /proc/sys/net/ipv4/ip_forward10、建立mysql认证文件。
# iptables -t nat -A POSTROUTING -s 10.8.0.0/24 -o eth0 -j MASQUERADE
# vi /etc/pam.d/openvpn11、创建vpn库、授权、建表
auth sufficient pam_mysql.so user=vpn passwd=vpnjkb host=127.0.0.1:3306 db=vpn \
table=vpnuser usercolumn=name passwdcolumn=password \
where=active=1 sqllog=0 crypt=2 verbose=1
account required pam_mysql.so user=vpn passwd=vpnjkb host=127.0.0.1:3306 db=vpn \
table=vpnuser usercolumn=name passwdcolumn=password \
where=active=1 sqllog=0 crypt=2 verbose=1
mysql> create database vpn;##创建数据库vpn。12、拷贝文件
mysql> GRANT ALL ON vpn.* TO vpn@localhost IDENTIFIED BY ‘vpnjkb‘;##授权localhost上的用户vpn(密码vpn123)有对数据库vpn的所有操作权限。
mysql> flush privileges;##更新sql数据库的权限设置。
mysql> use vpn;##使用刚创建的的vpn数据库。
mysql> CREATE TABLE vpnuser (
-> name char(20) NOT NULL,
-> password char(128) default NULL,
-> active int(10) NOT NULL DEFAULT 1,
-> PRIMARY KEY (name)
-> );
mysql> insert into vpnuser (name,password) values(’soai’,password(’soai’));
##命令解释:
#创建vpn用户,对vpn这个database有所有操作权限,密码为vpn123
#active不为1,无权使用VPN
# cp /usr/lib/openvpn/openvpn-auth-pam.so /etc/openvpn/13、可选配置
#client-cert-not-required #不请求客户的CA证书,使用User/Pass验证14、下载相关文件给客户端用
#username-as-common-name #使用客户提供的UserName作为Common Name
#client-to-client #如果让Client之间可以相互看见,去掉本行的注释掉,否则Client之间无法相互访问
#duplicate-cn #是否允许一个User同时登录多次,去掉本行注释后可以使用同一个用户名登录多次
##下载下列文件
client.crt clinet.key ca.crt ta.key
客户端配置
1、客户端下载地址:
http://swupdate.openvpn.org/community/releases/openvpn-2.2.2-install.exe ##windows
http://swupdate.openvpn.org/community/releases/openvpn-2.2.2.tar.gz ##linux or mac
2、创建client.ovpn文件
client3、把client.ovpn加上之前client.crt clinet.key ca.crt ta.key 放入一个config文件夹,并移动至vpn安装的主目录
dev tun
proto tcp
remote 8.8.8.8 1194 #公网ip 和 端口
nobind
persist-key
persist-tun
ca ca.crt
cert client.crt
key client.key
tls-auth ta.key 1
;comp-lzo
verb 3
auth-user-pass
4、启动客户端,输入用户名密码即可。#用户名密码在服务器端,mysql中添加的用户密码。
其他
1、关于auto认证相关可参考:http://b.gkp.cc/2010/08/08/setup-openvpn-with-mysql-auth/
2、后期维护
a、如果后期重新添加key的话
source varsb、后期客户端的吊销
./build-key
source vars检查keys/index.txt,发现被吊销的用户前面有个R
./revoke-full xiaowang #-->会生成crl.pem文件
怎么使吊销的生效呢,就是在server.conf里面加上 #crl-verify /etc/openvpn/keys/crl.pem,然后重启openvpn服务生效。 收起阅读 »





