
通知设置 新通知
mysql创建和删除表
数据库 Ansible 发表了文章 0 个评论 4177 次浏览 2015-06-26 19:15
简单的方式:
CREATE TABLE person (或者是
number INT(11),
name VARCHAR(255),
birthday DATE
);
CREATE TABLE IF NOT EXISTS person (
number INT(11),
name VARCHAR(255),
birthday DATE
);
查看mysql创建表:
> SHOW CREATE table person;
CREATE TABLE `person` (
`number` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`birthday` date DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
查看表所有的列:
> SHOW FULL COLUMNS from person;
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| number | int(11) | NULL | YES | | NULL | | select,insert,update,references | |
| name | varchar(255) | utf8_general_ci | YES | | NULL | | select,insert,update,references | |
| birthday | date | NULL | YES | | NULL | | select,insert,update,references | |
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
创建临时表
CREATE TEMPORARY TABLE temp_person (
number INT(11),
name VARCHAR(255),
birthday DATE
);
在创建表格时,您可以使用TEMPORARY关键词。只有在当前连接情况下,TEMPORARY表才是可见的。当连接关闭时,TEMPORARY表被自动取消。这意味着两个不同的连接可以使用相同的临时表名称,同时两个临时表不会互相冲突,也不与原有的同名的非临时表冲突。(原有的表被隐藏,直到临时表被取消时为止。)您必须拥有CREATE TEMPORARY TABLES权限,才能创建临时表。
如果表已存在,则使用关键词IF NOT EXISTS可以防止发生错误。
CREATE TABLE IF NOT EXISTS person2 (
number INT(11),
name VARCHAR(255),
birthday DATE
);
注意,原有表的结构与CREATE TABLE语句中表示的表的结构是否相同,这一点没有验证。注释:如果您在CREATE TABLE...SELECT语句中使用IF NOT EXISTS,则不论表是否已存在,由SELECT部分选择的记录都会被插入
在CREATE TABLE语句的末尾添加一个SELECT语句,在一个表的基础上创建表
CREATE TABLE new_tbl SELECT [i] FROM orig_tbl;注意,用SELECT语句创建的列附在表的右侧,而不是覆盖在表上mysql> SELECT [/i] FROM foo;也可以明确地为一个已生成的列指定类型
+---+
| n |
+---+
| 1 |
+---+
mysql> CREATE TABLE bar (m INT) SELECT n FROM foo;
mysql> SELECT * FROM bar;
+------+---+
| m | n |
+------+---+
| NULL | 1 |
+------+---+
CREATE TABLE foo (a TINYINT NOT NULL) SELECT b+1 AS a FROM bar;根据其它表的定义(包括在原表中定义的所有的列属性和索引),使用LIKE创建一个空表:
CREATE TABLE new_tbl LIKE orig_tbl;创建一个有主键,唯一索引,普通索引的表:
CREATE TABLE `people` (其中peopleid是主键,以firstname和lastname两列建立了一个唯一索引,以firstname,lastname,age三列建立了一个普通索引
`peopleid` smallint(6) NOT NULL AUTO_INCREMENT,
`firstname` char(50) NOT NULL,
`lastname` char(50) NOT NULL,
`age` smallint(6) NOT NULL,
`townid` smallint(6) NOT NULL,
PRIMARY KEY (`peopleid`),
UNIQUE KEY `unique_fname_lname`(`firstname`,`lastname`),
KEY `fname_lname_age` (`firstname`,`lastname`,`age`)
) ;
删除表
DROP TABLE tbl_name;
或者是
DROP TABLE IF EXISTS tbl_name;
清空表数据
TRUNCATE TABLE table_name
Docker入门学习
DevOps Ansible 发表了文章 2 个评论 4087 次浏览 2015-06-23 02:05

Docker是什么
Docker是一种容器技术,它可以将应用和环境等进行打包,形成一个独立的,类似于iOS的APP形式的“应用”,这个应用可以直接被分发到任意一个支持Docker的环境中,通过简单的命令即可启动运行。Docker是一种最流行的容器化实现方案。和虚拟化技术类似,它极大的方便了应用服务的部署;又与虚拟化技术不同,它以一种更轻量的方式实现了应用服务的打包。使用Docker可以让每个应用彼此相互隔离,在同一台机器上同时运行多个应用,不过他们彼此之间共享同一个操作系统。Docker的优势在于,它可以在更细的粒度上进行资源的管理,也比虚拟化技术更加节约资源。
上图:虚拟化和Docker架构对比,来自Docker官网
基本概念
开始试验Docker之前,我们先来了解一下Docker的几个基本概念:
镜像:我们可以理解为一个预配置的系统光盘,这个光盘插入电脑后就可以启动一个操作系统。当然由于是光盘,所以你无法修改它或者保存数据,每次重启都是一个原样全新的系统。Docker里面镜像基本上和这个差不多。
容器:同样一个镜像,我们可以同时启动运行多个,运行期间的产生的这个实例就是容器。把容器内的操作和启动它的镜像进行合并,就可以产生一个新的镜像。
开始
Docker基于LXC技术实现,依赖于Linux内核,所以Docker目前只能在Linux以原生方式运行。目前主要的Linux发行版在他们的软件仓库中内置了Docker:
Ubuntu: Ubuntu Trusty 14.04 (LTS) Ubuntu Precise 12.04 (LTS) Ubuntu Saucy 13.10
CentOS: Centos7
Docker要求64位环境,这些操作系统下可以直接通过命令安装Docker,老一些操作系统Docker官方也提供了安装方案。下面的实验基于CentOS 7进行。关于其他版本操作系统上Docker的安装,请参考官方文档:https://docs.docker.com/installation/ 。
在CentOS 7上安装Docker
使用yum从软件仓库安装Docker:
yum install docker
首先启动Docker的守护进程:
service docker start
如果想要Docker在系统启动时运行,执行:
chkconfig docker on
Docker在CentOS上好像和防火墙有冲突,应用防火墙规则后可能导致Docker无法联网,重启Docker可以解决。
Docker仓库
Docker使用类似git的方式管理镜像。通过基本的镜像可以定制创建出来不同种应用的Docker镜像。Docker Hub是Docker官方提供的镜像中心。在这里可以很方便地找到各类应用、环境的镜像。
由于Docker使用联合文件系统,所以镜像就像是夹心饼干一样一层层构成,相同底层的镜像可以共享。所以Docker还是相当节约磁盘空间的。要使用一 个镜像,需要先从远程的镜像注册中心拉取,这点非常类似git。
docker pull ubuntu
我们很容易就能从Docker Hub镜像注册中心下载一个最新版本的ubuntu镜像到本地。国内网络可能会稍慢,DAOCLOUD提供了Docker Hub的国内加速服务,可以尝试配置使用。
运行一个容器
使用Docker最关键的一步就是从镜像创建容器。有两种方式可以创建一个容器:使用docker create命令创建容器,或者使用docker run命令运行一个新容器。两个命令并没有太大差别,只是前者创建后并不会立即启动容器。
以ubuntu为例,我们启动一个新容器,并将ubuntu的Shell作为入口:
docker run -i -t ubuntu /bin/bash
这时候我们成功创建了一个Ubuntu的容器,并将当前终端连接为这个Ubuntu的bash shell。这时候就可以愉快地使用Ubuntu的相关命令了~可以快速体验一下。
参数-i表示这是一个交互容器,会把当前标准输入重定向到容器的标准输入中,而不是终止程序运行。-t指为这个容器分配一个终端。
好了,按Ctrl+D可以退出这个容器了。
在容器运行期间,我们可以通过docker ps命令看到所有当前正在运行的容器。添加-a参数可以看到所有创建的容器:
[root@localhost ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cb2b06c83a50 ubuntu:latest "sh -c /bin/bash" 7 minutes ago Exited (0) 7 seconds ago trusting_morse
每个容器都有一个唯一的ID标识,通过ID可以对这个容器进行管理和操作。在创建容器时,我们可以通过–name参数指定一个容器名称,如果没有指定系统将会分配一个,就像这里的“trusting_morse”(什么鬼TAT)。
当我们按Ctrl+D退出容器时,命令执行完了,所以容器也就退出了。要重新启动这个容器,可以使用docker start命令:
docker start -i trusting_morse
同样,-i参数表示需要交互式支持。
注意: 每次执行docker run命令都会创建新的容器,建议一次创建后,使用docker start/stop来启动和停用容器。
存储
在Docker容器运行期间,对文件系统的所有修改都会以增量的方式反映在容器使用的联合文件系统中,并不是真正的对只读层数据信息修改。每次运行容器对它的修改,都可以理解成对夹心饼干又添加了一层奶油。这层奶油仅供当前容器使用。当删除Docker容器,或通过该镜像重新启动时,之前的更改将会丢失。这样做并不便于我们持久化和共享数据。Docker的数据卷这个东西可以帮到我们。
在创建容器时,通过-v参数可以指定将容器内的某个目录作为数据卷加载:
docker run -i -t -v /home/www ubuntu:latest sh -c '/bin/bash'
在容器中会多一个/home/www挂载点,在这个挂载点存储数据会绕过联合文件系统。我们可以通过下面的命令来找到这个数据卷在主机上真正的存储位置:
docker inspect -f {{.Volumes}} trusting_morse
你会看到输出了一个指向到/var/lib/docker/vfs/dir/...的目录。cd进入后你会发现在容器中对/home/www的读写创建,都会反映到这儿。事实上,/home/www就是挂载自这个位置。
有时候,我们需要将本地的文件目录挂载到容器内的位置,同样是使用数据卷这一个特性,-v参数格式为:
docker run -it -v [host_dir]:[container_dir]
host_dir是主机的目录,container_dir是容器的目录.
容器和容器之间是可以共享数据卷的,我们可以单独创建一些容器,存放如数据库持久化存储、配置文件一类的东西,然而这些容器并不需要运行。
docker run --name dbdata ubuntu echo "Data container."
在需要使用这个数据容器的容器创建时–volumes-from [容器名]的方式来使用这个数据共享容器。
网络
Docker容器内的系统工作起来就像是一个虚拟机,容器内开放的端口并不会真正开放在主机上。可以使我们的容器更加安全,而且不会产生容器间端口的争用。想要将Docker容器的端口开放到主机上,可以使用类似端口映射的方式。
在Docker容器创建时,通过指定-p参数可以暴露容器的端口在主机上:
docker run -it -p 22 ubuntu sh -c '/bin/bash'
现在我们就将容器的22端口开放在了主机上,注意主机上对应端口是自动分配的。如果想要指定某个端口,可以通过-p [主机端口]:[容器端口]参数指定。
容器和容器之间想要网络通讯,可以直接使用–link参数将两个容器连接起来。例如WordPress容器对some-mysql的连接:
docker run --name some-wordpress --link some-mysql:mysql -p 8080:80 -d wordpress
环境变量
通过Docker打包的应用,对外就像是一个密闭的exe可执行文件。有时候我们希望Docker能够使用一些外部的参数来使用容器,这时候参数可以通过环境变量传递进去,通常情况下用来传递比如MySQL数据库连接这种的东西。环境变量通过-e参数向容器传递:
docker run --name some-wordpress -e WORDPRESS_DB_HOST=10.1.2.3:3306 \
-e WORDPRESS_DB_USER=... -e WORDPRESS_DB_PASSWORD=... -d wordpress
关于Docker到现在就有了一个基本的认识了。接下来我会给大家介绍如何创建镜像。
创建镜像
Docker强大的威力在于可以把自己开发的应用随同各种依赖环境一起打包、分发、运行。要创建一个新的Docker镜像,通常基于一个已有的Docker镜像来创建。Docker提供了两种方式来创建镜像:把容器创建为一个新的镜像、使用Dockerfile创建镜像。
将容器创建为镜像
为了创建一个新的镜像,我们先创建一个新的容器作为基底:
docker run -it ubuntu:latest sh -c '/bin/bash'
现在我们可以对这个容器进行修改了,例如我们可以配置PHP环境、将我们的项目代码部署在里面等:
apt-get install php
# some other opreations ...
当执行完操作之后,我们按Ctrl+D退出容器,接下来使用docker ps -a来查找我们刚刚创建的容器ID:
docker ps -a
可以看到我们最后操作的那个ubuntu容器。这时候只需要使用docker commit即可把这个容器变为一个镜像了:
docker commit 8d93082a9ce1 ubuntu:myubuntu
这时候docker容器会被创建为一个新的Ubuntu镜像,版本名称为myubuntu。以后我们可以随时使用这个镜像来创建容器了,新的容器将自动包含上面对容器的操作。
如果我们要在另外一台机器上使用这个镜像,可以将一个镜像导出:
docker save -o myubuntu.tar.gz ubuntu:myubuntu
现在我们可以把刚才创建的镜像打包为一个文件分发和迁移了。要在一台机器上导入镜像,只需要:
docker import myubuntu.tar.gz
这样在新机器上就拥有了这个镜像。
注意:通过导入导出的方式分发镜像并不是Docker的最佳实践,因为我们有Docker Hub。
Docker Hub提供了类似GitHub的镜像存管服务。一个镜像发布到Docker Hub不仅可以供更多人使用,而且便于镜像的版本管理。关于Docker Hub的使用,之后我会单独写一篇文章展开介绍。另外,在一个企业内部可以通过自建docker-registry的方式来统一管理和发布镜像。将Docker Registry集成到版本管理和上线发布的工作流之中,还有许多工作要做,在我整理出最佳实践后会第一时间分享。
使用Dockerfile创建镜像
使用命令行的方式创建Docker镜像通常难以自动化操作。在更多的时候,我们使用Dockerfile来创建Docker镜像。Dockerfile是一个纯文本文件,它记载了从一个镜像创建另一个新镜像的步骤。撰写好Dockerfile文件之后,我们就可以轻而易举的使用docker build命令来创建镜像了.
Dockerfile非常简单,仅有以下命令在Dockerfile中常被使用:
下面是一个Dockerfile的例子:
# This is a comment
FROM ubuntu:14.04
MAINTAINER Kate Smith <ksmith@example.com>
RUN apt-get update && apt-get install -y ruby ruby-dev
RUN gem install sinatra
这里其他命令都比较好理解,唯独CMD和ENTRYPOINT我需要特殊说明一下。CMD命令可用指定Docker容器启动时默认的命令,例如我们上面例子提到的docker run -it ubuntu:latest sh -c '/bin/bash'。其中sh -c '/bin/bash'就是通过手工指定传入的CMD。如果我们不加这个参数,那么容器将会默认使用CMD指定的命令启动。ENTRYPOINT是什么呢?从字面看是进入点。没错,它就是进入点。ENTRYPOINT用来指定特定的可执行文件、Shell脚本,并把启动参数或CMD指定的默认值,当作附加参数传递给ENTRYPOINT。
不好理解是吧?我们举一个例子:
ENTRYPOINT ['/usr/bin/mysql']
CMD ['-h 192.168.100.128', '-p']
假设这个镜像内已经准备好了mysql-client,那么通过这个镜像,不加任何额外参数启动容器,将会给我们一个mysql的控制台,默认连接到192.168.100.128这个主机。然而我们也可以通过指定参数,来连接别的主机。但是不管无论如何,我们都无法启动一个除了mysql客户端以外的程序。因为这个容器的ENTRYPOINT就限定了我们只能在mysql这个客户端内做事情。这下是不是明白了。
因此,我们在使用Dockerfile创建文件的时候,可以创建一个entrypoint.sh脚本,作为系统入口。在这个文件里面,我们可以进行一些基础性的自举操作,比如检查环境变量,根据需要初始化数据库等等。下面两个文件是我在SimpleOA项目中添加的Dockerfile和entrypoint.sh,仅供参考:
https://github.com/starlight36/SimpleOA/blob/master/Dockerfile https://github.com/starlight36/SimpleOA/blob/master/docker-entrypoint.sh
在准备好Dockerfile之后,我们就可以创建镜像了:
docker build -t starlight36/simpleoa .
关于Dockerfile的更详细说明,请参考 https://docs.docker.com/reference/builder/
杂项和最佳实践
在产品构建的生命周期里使用Docker,最佳实践是把Docker集成到现有的构建发布流程里面。这个过程并不复杂,可以在持续集成系统构建测试完成后,将打包的步骤改为docker build,持续集成服务将会自动将构建相应的Docker镜像。打包完成后,可以由持续集成系统自动将镜像推送到Docker Registry中。生产服务器可以直接Pull最新版本的镜像,更新容器即可很快地实现更新上线。目前Atlassian Bamboo已经支持Docker的构建了。
由于Docker使用联合文件系统,所以并不用担心多次发布的版本会占用更多的磁盘资源,相同的镜像只存储一份。所以最佳实践是在不同层次上构建Docker镜像。比如应用服务器依赖于PHP+Nginx环境,那么可以把定制好的这个PHP环境作为一个镜像,应用服务器从这个镜像构建镜像。这样做的好处是,如果PHP环境要升级,更新了这个镜像后,重新构建应用镜像即可完成升级,而不需要每个应用项目分别升级PHP环境。
新手经常会有疑问的是关于Docker打包的粒度,比如MySQL要不要放在镜像中?最佳实践是根据应用的规模和可预见的扩展性来确定Docker打包的粒度。例如某小型项目管理系统使用LAMP环境,由于团队规模和使用人数并不会有太大的变化(可预计的团队规模范围是几人到几千人),数据库也不会承受无法承载的记录数(生命周期内可能一个表最多会有数十万条记录),并且客户最关心的是快速部署使用。那么这时候把MySQL作为依赖放在镜像里是一种不错的选择。当然如果你在为一个互联网产品打包,那最好就是把MySQL独立出来,因为MySQL很可能会单独做优化做集群等。
使用公有云构建发布运行Docker也是个不错的选择。DaoCloud提供了从构建到发布到运行的全生命周期服务。特别适合像微擎这种微信公众平台、或者中小型企业CRM系统。上线周期更短,比使用IAAS、PAAS的云服务更具有优势。
参考资料:
深入理解Docker Volume
WordPress https://registry.hub.docker.com/_/wordpress/
Docker学习—镜像导出 http://www.sxt.cn/u/756/blog/5339
Dockerfile Reference https://docs.docker.com/reference/builder/
关于Dockerfile http://blog.tankywoo.com/docker/2014/05/08/docker-2-dockerfile.html
Docker 安全:通过 Docker 提升权限
大数据 Ansible 发表了文章 0 个评论 5510 次浏览 2015-06-22 14:37

如果你对 Docker 不熟悉的话,简单来说,Docker 是一个轻量级的应用容器。和常见的虚拟机类似,但是和虚拟机相比,资源消耗更低。并且,使用和 GitHub 类似的被 commit 的容器,非常容易就能实现容器内指定运行环境中的应用打包和部署。
问题
如果你有服务器上一个普通用户的账号,如果这个用户被加入了 docker 用户组,那么你很容易就能获得宿主机的 root 权限。
黑魔法:docker run -v /:/hostOS -i -t chrisfosterelli/rootplease
输出如下:
johndoe@testmachine:~$ docker run -v /:/hostOS -i -t chrisfosterelli/rootplease
[...]
You should now have a root shell on the host OS
Press Ctrl-D to exit the docker instance / shell
# whoami
root #此处是容器内部,但是容器已经 chroot /hostOS,所以相当于直接获取了宿主机的 root 权限。
译者一直以为是 Ctrl-D 之后,宿主机的 shell 变成 root,实际上不是。
咨询了作者 Chris Foster 得知,是在容器内获得宿主机的 root 权限。
是不是想起了以前译者在 Docker 安全 中提到的容器内部的 UID=0 对容器外部某个不明程序执行了 chmod +s?
解释
当然,所有的解释汇成一句话,应该就是:docker 组内用户执行命令的时候会自动在所有命令前添加 sudo。因为设计或者其他的原因,Docker 给予所有 docker 组的用户相当大的权力(虽然权力只体现在能访问 /var/run/docker.sock 上面)。
默认情况下,Docker 软件包是会默认添加一个 docker 用户组的。Docker 守护进程会允许 root 用户和 docker 组用户访问 Docker。给用户提供 Docker 权限和给用户无需认证便可以随便获取的 root 权限差别不大。
解决方案
对于 Docker 来说可能很难修复,因为涉及到他们的架构问题,所以需要重写非常多的关键代码才能避免这个问题。我个人的建议是不要使用 docker 用户组。当然,Docker 官方文档中最好也很清楚地写明这一点。不要让新人不懂得“和 root 权限差别不大”是什么意思。
Docker 官方也意识到了这个问题,尽管他们并没有很明显地表明想去修复它。在他们的安全文档中,他们也的确表示 docker 用户组的权限和 root 权限差别不大,并且敬告用户慎重使用。
漏洞详情
上面那条命令 docker run -v /:/hostOS -i -t chrisfosterelli/rootplease,主要的作用是:从 Docker Hub 上面下载我的镜像,然后运行。参数-v将容器外部的目录/挂载到容器内部 /hostOS,并且使用 -i 和 -t 参数进入容器的 shell。
这个容器的启动脚本是 exploit.sh,主要内容是:chroot 到容器的 /hostOS (也就是宿主机的 /),然后获取到宿主机的 root 权限。
当然可以从这个衍生出非常多的提权方法,但是这个方法是最直接的。
本文中所提到的代码托管在 Github(https://github.com/chrisfosterelli/dockerrootplease),镜像在 Docker Hub(https://registry.hub.docker.com/u/chrisfosterelli/rootplease/)。
翻译原文链接:https://henduan.com/xXoHn
Elasticsearch 分片交互过程详解
数据库 Ansible 发表了文章 1 个评论 6282 次浏览 2015-06-18 01:40

一、Elasticseach如何将数据存储到分片中
问题:当我们要在ES中存储数据的时候,数据应该存储在主分片和复制分片中的哪一个中去;当我们在ES中检索数据的时候,又是怎么判断要查询的数据是属于哪一个分片。
数据存储到分片的过程是一定规则的,并不是随机发生的。
规则:shard = hash(routing) % number_of_primary_shards
Routing值可以是一个任意的字符串,默认情况下,它的值为存数数据对应文档 _id 值,也可以是用户自定义的值。Routing这个字符串通过一个hash的函数处理,并返回一个数值,然后再除以索引中主分片的数目,所得的余数作为主分片的编号,取值一般在0到number_of_primary_shards - 1的这个范围中。通过这种方法计算出该数据是存储到哪个分片中。
正是这种路由机制,导致了主分片的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索。
二、主分片与复制分片如何交互
为了说明这个问题,我用一个例子来说明。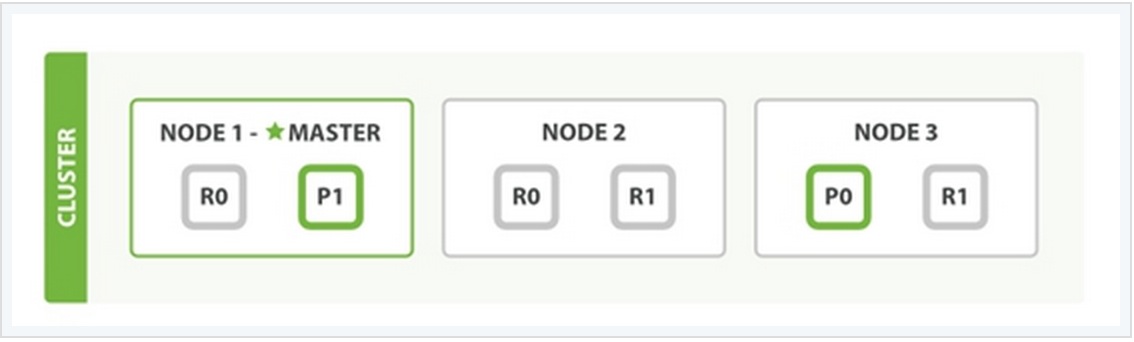
在上面这个例子中,有三个ES的node,其中每一个index中包含两个primary shard,每个primary shard拥有2个replica shard。下面从几种常见的数据操作来说明二者之间的交互情况。
1、索引与删除一个文档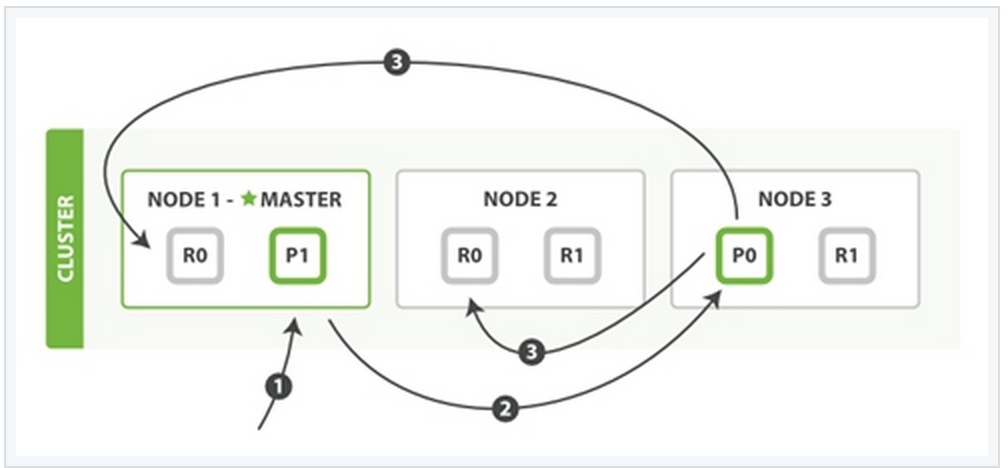
这两种过程均可以分为三个过程来描述:
阶段1:客户端发送了一个索引或者删除的请求给node 1。
阶段2:node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3在shard 0 的primary shard上执行请求。如果请求执行成功,它node 3将并行地将该请求发给shard 0的其余所有replica shard上,也就是存在于node 1和node 2中的replica shard。如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
2、更新一个文档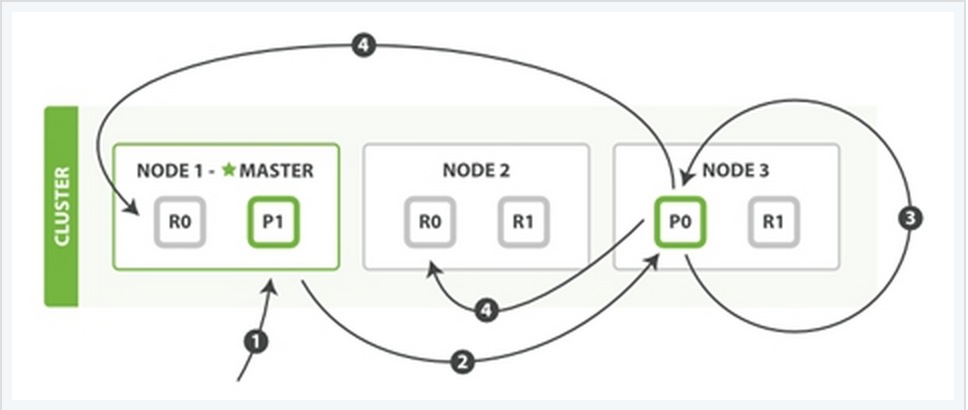
该过程可以分为四个阶段来描述:
阶段1:客户端向node 1发送一个文档更新的请求。
阶段2:同样的node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3从文档所在的primary shard中获取到它的JSON文件,并修改其中的_source中的内容,之后再重新索引该文档到其primary shard中。
阶段4:如果node 3成功地更新了文档,node 3将会把文档新的版本并行地发给其余所有的replica shard所在node中。这些node也同样重新索引新版本的文档,执行后则向node 3确认成功,当node 3接收到所有的成功确认之后,再向客户端发送一个更新成功的信息。
3、检索文档
CRUD这些操作的过程中一般都是结合一些唯一的标记例如:_index,_type,以及routing的值,这就意味在执行操作的时候都是确切的知道文档在集群中的哪个node中,哪个shard中。
而检索过程往往需要更多的执行模式,因为我们并不清楚所要检索的文档具体位置所在, 它们可能存在于ES集群中个任何位置。因此,一般情况下,检索的执行不得不去询问index中的每一个shard。
但是,找到所有匹配检索的文档仅仅只是检索过程的一半,在向客户端返回一个结果列表之前,必须将各个shard发回的小片的检索结果,拼接成一个大的已排好序的汇总结果列表。正因为这个原因,检索的过程将分为查询阶段与获取阶段(Query Phase and Fetch Phase)。
Query Phase
在最初的查询过程中,查询请求会广播到index中的每一个primary shard和replica shard中,每一个shard会在本地执行检索,并建立一个优先级队列(priority queue)。这个优先级队列是一个根据文档匹配度这个指标所排序列表,列表的长度由分页参数from和size两个参数所决定。例如: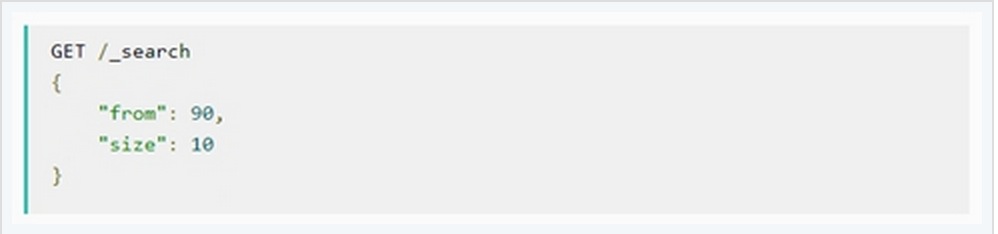
下面从一个例子中说明这个过程:
Query Phase阶段可以再细分成3个小的子阶段:
子阶段1:客户端发送一个检索的请求给node 3,此时node 3会创建一个空的优先级队列并且配置好分页参数from与size。
子阶段2:node 3将检索请求发送给该index中个每一个shard(这里的每一个意思是无论它是primary还是replica,它们的组合可以构成一个完整的index数据)。每个shard在本地执行检索,并将结果添加到本地优先级队列中。
子阶段3:每个shard返回本地优先级序列中所记录的_id与sort值,并发送node 3。Node 3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
Fetch PhaseQuery Phase主要定位了所要检索数据的具体位置,但是我们还必须取回它们才能完成整个检索过程。而Fetch Phase阶段的任务就是将这些定位好的数据内容取回并返回给客户端。
同样也用一个例子来说明这个过程: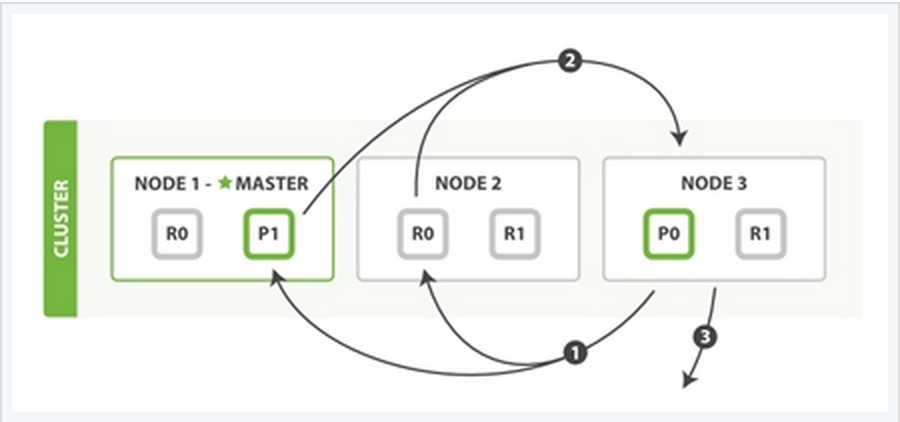
Fetch Phase过程可以分为三个子过程来描述:
子阶段1:node 3获取了所有待检索数据的定位之后,发送一个mget的请求给与数据相关的shard。
子阶段2:每个收到node 3的get请求的shard将读取相关文档_source中的内容,并将它们返回给node 3。
子阶段3:当node 3获取到了所有shard返回的文档后,node 3将它们合并成一条汇总的结果,返回给客户端。





