通知设置 新通知
Elasticsearch聚合限制内存使用
push 发表了文章 0 个评论 5541 次浏览 2016-09-14 15:05
限制内存使用
通常为了让聚合(或者任何需要访问字段值的请求)能够快点,访问fielddata一定会快点, 这就是为什么加载到内存的原因。但是加载太多的数据到内存会导致垃圾回收(gc)缓慢, 因为JVM试着发现堆里面的额外空间,甚至导致OutOfMemory异常。
最让你吃惊的是,你会发现Elaticsearch不是只把符合你的查询的值加载到fielddata. 而是把index里的所document都加载到内存,甚至是不同的 _type 的document。
逻辑是这样的,如果你在这个查询需要访问documents X,Y和Z, 你可能在下一次查询就需要访问别documents。而一次把所有的值都加载并保存在内存 , 比每次查询都去扫描倒排索引要更方便。
JVM堆是一个有限制的资源需要聪明的使用。有许多现成的机制去限制fielddata对堆内存使用的影响。这些限制非常重要,因为滥用堆将会导致节点的不稳定(多亏缓慢的垃圾回收)或者甚至节点死亡(因为OutOfMemory异常);但是垃圾回收时间过长,在垃圾回收期间,ES节点的性能就会大打折扣,查询就会非常缓慢,直到最后超时。
如何设置堆大小
对于环境变量 $ES_HEAP_SIZE 在设置Elasticsearch堆大小的时候有2个法则可以运用:
- 不超过RAM的50%
- 不超过32G
参数 indices.fielddata.cache.size 控制有多少堆内存是分配给fielddata。当你执行一个查询需要访问新的字段值的时候,将会把值加载到内存,然后试着把它们加入到fielddata。如果结果的fielddata大小超过指定的大小 ,为了腾出空间,别的值就会被驱逐出去。 默认情况下,这个参数设置的是无限制 — Elasticsearch将永远不会把数据从fielddata里替换出去。 这个默认值是故意选择的:fielddata不是临时的cache。它是一个在内存里为了快速执行必须能被访问的数据结构,而且构建它代价非常昂贵。如果你每个请求都要重新加载数据,性能就会很差。 一个有限的大小强迫数据结构去替换数据。我们将看看什么时候去设置下面的值,首先让我们看一个警告: 【warning】这个设置是一个保护措施,而不是一个内存不足的解决方案Fielddata大小

indices.fielddata.cache.size: 40%当然可以设置成堆大小的百分比,也可以是一个具体的值,比如 8gb;通过适当的设置这个值,最近被访问的fielddata将被清除出去,给新加载的数据腾出空间。 在网上你可能会看到另外一个设置参数: indices.fielddata.cache.expire 。千万不要使用这个设置!这个设置高版本已经废弃。这个设置告诉Elasticsearch把比过期时间老的数据从fielddata里驱逐出去,而不管这个值是否被用到。这对性能是非常可怕的 。驱逐数据是有代价的,并且这个有目的的高效的安排驱逐数据并没有任何真正的收获。没有任何理由去使用这个设置;我们一点也不能从理论上制造一个假设的有用的情景。现阶段存 在只是为了向后兼容。我们在这个书里提到这个设置是因为这个设置曾经在网络上的各种文章里 被作为一个 ``性能小窍门'' 被推荐过。记住永远不要使用它,就ok!
监控fielddata使用了多少内存以及是否有数据被驱逐是非常重要的。大量的数据被驱逐会导致严重的资源问题以及不好的性能。 Fielddata使用可以通过下面的方式来监控:监控fielddata
- 对于单个索引使用 {ref}indices-stats.html[indices-stats API]:
GET /_stats/fielddata?fields=*
- 对于单个节点使用 {ref}cluster-nodes-stats.html[nodes-stats API]:
GET /_nodes/stats/indices/fielddata?fields=*
- 或者甚至单个节点单个索引
GET /_nodes/stats/indices/fielddata?level=indices&fields=*通过设置 ?fields=* 内存使用按照每个字段分解了.
断路器(breaker)
聪明的读者可能已经注意到fielddata大小设置的一个问题。fielddata的大小是在数据被加载之后才校验的。如果一个查询尝试加载到fielddata的数据比可用的内存大会发生什么情况?答案是不客观的:你将会获得一个OutOfMemory异常。
Elasticsearch包含了一个 fielddata断路器 ,这个就是设计来处理这种情况的。断路器通过检查涉及的字段(它们的类型,基数,大小等等)来估计查询需要的内存。然后检查加 载需要的fielddata会不会导致总的fielddata大小超过设置的堆的百分比。
如果估计的查询大小超过限制,断路器就会触发并且查询会被抛弃返回一个异常。这个发生在数据被加载之前,这就意味着你不会遇到OutOfMemory异常。
Elasticsearch拥有一系列的断路器,所有的这些都是用来保证内存限制不会被突破:
indices.breaker.fielddata.limit这个 fielddata 断路器限制fielddata的大小为堆大小的60%,默认情况下。
indices.breaker.request.limit这个 request 断路器估算完成查询的其他部分要求的结构的大小,比如创建一个聚集通, 以及限制它们到堆大小的40%,默认情况下。
indices.breaker.total.limit这个total断路器封装了 request 和 fielddata 断路器去确保默认情况下这2个 使用的总内存不超过堆大小的70%。
断路器限制可以通过文件 config/elasticsearch.yml 指定,也可以在集群上动态更新:
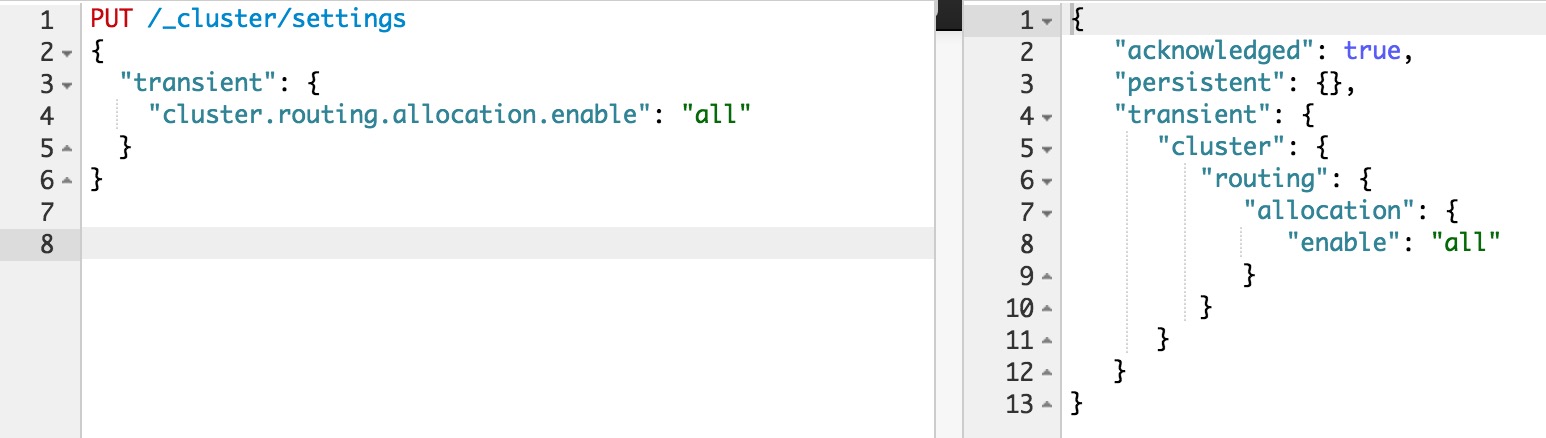
PUT /_cluster/settings这个限制设置的是堆的百分比。
{
"persistent" : {
"indices.breaker.fielddata.limit" : 40% (1)
}
}
最好把断路器设置成一个相对保守的值。记住fielddata需要和堆共享 request 断路器, 索引内存缓冲区,过滤器缓存,打开的索引的Lucene数据结构,以及各种各样别的临时数据 结构。所以默认为相对保守的60%。过分乐观的设置可能会导致潜在的OOM异常,从而导致整 个节点挂掉。
从另一方面来说,一个过分保守的值将会简单的返回一个查询异常,这个异常会被应用处理。 异常总比挂掉好。这些异常也会促使你重新评估你的查询:为什么单个的查询需要超过60%的 堆空间。
断路器和Fielddata大小
在 Fielddata大小部分我们谈到了要给fielddata大小增加一个限制去保证老的不使用 的fielddata被驱逐出去。indices.fielddata.cache.size 和 indices.breaker.fielddata.limit 的关系是非常重要的。如果断路器限制比缓冲区大小要小,就会没有数据会被驱逐。为了能够 让它正确的工作,断路器限制必须比缓冲区大小要大。
我们注意到断路器是和总共的堆大小对比查询大小,而不是和真正已经使用的堆内存区比较。 这样做是有一系列技术原因的(比如,堆可能看起来是满的,但是实际上可能正在等待垃圾 回收,这个很难准确的估算)。但是作为终端用户,这意味着设置必须是保守的,因为它是 和整个堆大小比较,而不是空闲的堆比较。
参考:Elasticsearch权威指南笔记
官网:https://www.elastic.co/guide/en/elasticsearch/guide/current/_limiting_memory_usage.html
Hadoop fs命令学习小记
空心菜 发表了文章 0 个评论 4263 次浏览 2016-09-13 20:08

1,hadoop fs –fs [local |
2,hadoop fs –ls
3,hadoop fs –lsr
4,hadoop fs –du
5,hadoop fs –dus
6,hadoop fs –mv
7,hadoop fs –cp
8,hadoop fs –rm [-skipTrash]
9,hadoop fs –rmr [skipTrash]
10,hadoop fs –rmi [skipTrash]
11,hadoop fs –put
12,hadoop fs –copyFromLocal
13,hadoop fs –moveFromLocal
14,hadoop fs –get [-ignoreCrc] [-crc]
15,hadoop fs –getmerge
16,hadoop fs –cat
17,hadoop fs –copyToLocal [-ignoreCrc] [-crc]
18,hadoop fs –mkdir
19,hadoop fs –setrep [-R] [-w]
20,hadoop fs –chmod [-R]
21,hadoop fs -chown [-R] [OWNER][:[GROUP]] PATH…:修改文件的所有者和组。-R表示递归。
22,hadoop fs -chgrp [-R] GROUP PATH…:等价于-chown … :GROUP …。
23,hadoop fs –count[-q]
最后就是万能的hadoop fs –help
Hbase shell常用命令小记
空心菜 发表了文章 0 个评论 3235 次浏览 2016-09-13 00:19

$HBASE_HOME/bin/hbase shell
如果有kerberos认证,需要事先使用相应的keytab进行一下认证(使用kinit命令),认证成功之后再使用hbase shell进入可以使用whoami命令可查看当前用户
hbase(main):002:0> whoami
2016-09-12 13:09:42,440 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
root (auth:SIMPLE)
groups: root
2、表的管理
1)查看有哪些表
hbase(main):001:0> list2)创建表
TABLE
pythonTrace
1 row(s) in 0.1320 seconds
语法:create