
通知设置 新通知
Elasticsearch启动常见问题
数据库 being 发表了文章 0 个评论 2498 次浏览 2021-03-16 22:54

启动内存问题
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error='Cannot allocate memory' (errno=12)
分析: 默认分配的JVM内存为2g,所以当小内存的机器,默认启动的话,会报如上错误。
解决: 修改Eleasticsearch启动JVM内存参数, 修改文件: config/jvm.options
-Xms2g
-Xmx2g
修改为
-Xms1g
-Xmx1g
对于内存较低的云主机和虚拟机,你要测试Elasticsearch的基本功能,没有太大性能要求的话,这时候就需要修改启动内存。
启动用户问题
don't run elasticsearch as root
分析: 程序设计者,出于系统安全考虑设置的条件, 由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,如果获取root权限了,那问题就打了,所以默认官方是建议创建一个单独的用户用来运行ElasticSearch。
解决:添加单独的用户运行
groupadd es
useradd es -g es
更改elasticsearch文件夹及内部文件的所属用户及组为es:es
chown -R es:es elasticsearch
切换到es用户启动:
su - es
./bin/elasticsearch -d
# 或者root下
su es -c "/opt/elasticsearch/bin/elasticsearch -d"
Tips: ES5版本之前,还可以修改
ES_JAVA_OPTS启动参数,加上-Des.insecure.allow.root=true可以使用root启动,但是不推荐这么玩。
最大虚拟内存区域问题
max virtual memory areas vm.max_map_count [256000] is too low, increase to at least [262144]
什么是VMA(virtual memory areas):
This file contains the maximum number of memory map areas a process may have. Memory map areas are used as a side-effect of calling malloc, directly by mmap and mprotect, and also when loading shared libraries.
While most applications need less than a thousand maps, certain programs, particularly malloc debuggers, may consume lots of them, e.g., up to one or two maps per allocation.
The default value is 65536
max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
解决:
# 临时设置
sysctl -w vm.max_map_count=262144
# 永久设置
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
虚拟内存最大大小问题
max size virtual memory [67108864] for user [es] is too low, increase to [unlimited]
分析:引用官网的说法
The segment files that are the components of individual shards and the translog generations that are components of the translog can get large (exceeding multiple gigabytes). On systems where the max size of files that can be created by the Elasticsearch process is limited, this can lead to failed writes. Therefore, the safest option here is that the max file size is unlimited and that is what the max file size bootstrap check enforces. To pass the max file check, you must configure your system to allow the Elasticsearch process the ability to write files of unlimited size.
解决:
echo "* - as unlimited" >> /etc/security/limits.conf
echo "root - as unlimited" >> /etc/security/limits.conf
参考: https://stackoverflow.com/questions/42510873/vm-max-map-count-is-too-low
最大文件描述符问题
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
分析:elasticsearch启动bootstrap checks要求系统打开最大系统文件描述符为65536
解决:
# 临时 ulimit -f unlimited
echo "* soft nofile 65536" >> /etc/security/limits.conf
echo "* hard nofile 65536" >> /etc/security/limits.conf
确认:
ulimit -Hn
ulimit -Sn
最大线程数问题
max number of threads [3818] for user [es] is too low, increase to at least [4096]
分析:elasticsearch启动bootstrap checks要求打开最大线程数最低为4096
解决:
echo "* soft nproc 65535" >> /etc/security/limits.conf
echo "* hard nproc 65535" >> /etc/security/limits.conf
注意:修改这里,普通用户
max user process值是不生效的,需要修改/etc/security/limits.d/20-nproc.conf文件中的值。Centos6系统的是是90-nproc.conf文件。
修改 /etc/security/limits.d/20-nproc.conf
* soft nproc 65535
系统总限制
其实上面的 max user processes 65535 的值也只是表象,普通用户最大进程数无法达到65535 ,因为用户的max user processes的值,最后是受全局的kernel.pid_max的值限制。
也就是说kernel.pid_max=1024 ,那么你用户的max user processes的值是65535 ,用户能打开的最大进程数还是1024。
# 临时生效
echo 65535 > /proc/sys/kernel/pid_max
sysctl -w kernel.pid_max=65535
# 永久生效
echo "kernel.pid_max = 65535" >> /etc/sysctl.conf
sysctl -p
然后重启机器生效。
参考: https://www.cnblogs.com/xidianzxm/p/11820706.html
确认:
ulimit -Hu
ulimit -Su
运行目录权限问题
Exception in thread "main" java.nio.file.AccessDeniedException: /opt/elasticsearch-6.2.2-1/config/jvm.options
分析: es用户没有该文件夹的权限
解决:
chown es.es /opt/elasticsearch-6.2.2-1 -R
如果还有碰到其他问题的同学,可以留言补充。
各大行业龙头股合理买入价格?
互联网资讯 OS小编 发表了文章 0 个评论 2119 次浏览 2021-03-12 13:13

各大行业龙头股合理买入价格!昨天反弹,今天回调,再强调一次!
腾讯控股:550 ,极限500
贵州茅台:1600,比较安全,1800反弹
五粮液:160,非常安全
万科A: 现价分批
海天味业:135,确定性较高企业
宁德时代:250
恒瑞医药:85
泰格医药:105
药明康德:105
中国中免:225-230
迈瑞医疗:300-320
通策医疗:160
晨光文具:60
长春高新:380
东方财富:23
山西汾酒:160(波动非常大,
200会到,能到160就满分)
阳光电源:60
伊利股份:35
隆基股份:80(这股补跌
,需要调整,高于高瓴买入价格)
东方雨虹:40
美的集团:70
长江电力:18
比亚迪:160(这个都快到了,极限120,看着分批建仓就好,新能源产业链看整体走势,不纯看估值)
爱尔眼科:50(一直高估值)
恒立液压:65(涨了10倍,也该回归合理估值)
欧普康视:60
海尔智家:22
科沃斯:80
凯莱英:200以内,能到180就满分
三一重工:30
恒力石化:25
荣盛石化:23
同花顺:100,极限80
立讯精密:40内再看
平安银行:20内分批
招商银行:45内分批
作者:常春藤投资
链接原文: https://henduan.com/Rthe7
来源:雪球
修改MySQL5.7.31用户登录密码
数据库 chris 发表了文章 0 个评论 2326 次浏览 2021-03-08 22:30

默认一般安装完成MySQL数据库root用户的密码为空,一般需要设置好root的密码,要不会造成不安全的情况发生。然而登录MySQL数据库后发现5.7版本跟5.6版本User表结构发生了变化,原本的password字段没有了,这就导致在5.7下面修改用户密码的方式跟之前的版本不同,下面会介绍2种修改方式。
1. 使用set password语句
这种方法跟以前的版本修改密码是一致的,需要登录到MySQL后使用:
set password for root@localhost = password("123.com");
2. 直接更新user表
由于MySQL版本的升级,User表的结构改变了,好多网上使用的UPDATE语句不适用新版本的表结构,在这里我通过DESC语句来查看User表的结构,结果如图:
mysql> desc User;
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Host | char(60) | NO | PRI | | |
| User | char(32) | NO | PRI | | |
| Select_priv | enum('N','Y') | NO | | N | |
| Insert_priv | enum('N','Y') | NO | | N | |
| Update_priv | enum('N','Y') | NO | | N | |
| Delete_priv | enum('N','Y') | NO | | N | |
| Create_priv | enum('N','Y') | NO | | N | |
| Drop_priv | enum('N','Y') | NO | | N | |
| Reload_priv | enum('N','Y') | NO | | N | |
| Shutdown_priv | enum('N','Y') | NO | | N | |
| Process_priv | enum('N','Y') | NO | | N | |
| File_priv | enum('N','Y') | NO | | N | |
| Grant_priv | enum('N','Y') | NO | | N | |
| References_priv | enum('N','Y') | NO | | N | |
| Index_priv | enum('N','Y') | NO | | N | |
| Alter_priv | enum('N','Y') | NO | | N | |
| Show_db_priv | enum('N','Y') | NO | | N | |
| Super_priv | enum('N','Y') | NO | | N | |
| Create_tmp_table_priv | enum('N','Y') | NO | | N | |
| Lock_tables_priv | enum('N','Y') | NO | | N | |
| Execute_priv | enum('N','Y') | NO | | N | |
| Repl_slave_priv | enum('N','Y') | NO | | N | |
| Repl_client_priv | enum('N','Y') | NO | | N | |
| Create_view_priv | enum('N','Y') | NO | | N | |
| Show_view_priv | enum('N','Y') | NO | | N | |
| Create_routine_priv | enum('N','Y') | NO | | N | |
| Alter_routine_priv | enum('N','Y') | NO | | N | |
| Create_user_priv | enum('N','Y') | NO | | N | |
| Event_priv | enum('N','Y') | NO | | N | |
| Trigger_priv | enum('N','Y') | NO | | N | |
| Create_tablespace_priv | enum('N','Y') | NO | | N | |
| ssl_type | enum('','ANY','X509','SPECIFIED') | NO | | | |
| ssl_cipher | blob | NO | | NULL | |
| x509_issuer | blob | NO | | NULL | |
| x509_subject | blob | NO | | NULL | |
| max_questions | int(11) unsigned | NO | | 0 | |
| max_updates | int(11) unsigned | NO | | 0 | |
| max_connections | int(11) unsigned | NO | | 0 | |
| max_user_connections | int(11) unsigned | NO | | 0 | |
| plugin | char(64) | NO | | mysql_native_password | |
| authentication_string | text | YES | | NULL | |
| password_expired | enum('N','Y') | NO | | N | |
| password_last_changed | timestamp | YES | | NULL | |
| password_lifetime | smallint(5) unsigned | YES | | NULL | |
| account_locked | enum('N','Y') | NO | | N | |
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
45 rows in set (0.00 sec)
如上发现了一些疑似用来认证的字段,根据字段类型推断authentication_string应该是存储的用户密码,之后就开始尝试修改这一字段:
update user set authentication_string = password('123.com') where user='root' and host='localhost';
更改后退出发现依然不会生效,通过查阅资料发现,还需要把plugin字段的值改为mysql_native_password。个人感觉这个字段影响的是验证方式,更改之后就可以在登录的时候使用刚刚设置的密码来验证。修改语句如下:
update user set plugin = 'mysql_native_password' where user='root' and host='localhost';
后来了解到mysql_native_password和caching_sha2_password是MySQL的两种加密认证方式,一般MySQL 5默认使用前者,而8以后的版本使用后者,在这里虽然笔者使用的是5.7.31,但我确实是在更改了这个字段值以后才能正常用密码登录的。
unzip 6.0编译安装
运维 chris 发表了文章 0 个评论 2227 次浏览 2021-03-02 14:22

下载安装包
wget https://downloads.sourceforge.net/infozip/unzip60.tar.gz
wget http://www.linuxfromscratch.org/patches/blfs/svn/unzip-6.0-consolidated_fixes-1.patch
打patch
tar xf unzip60.tar.gz
cd unzip60
patch -Np1 -i ../unzip-6.0-consolidated_fixes-1.patch
编译安装
make -f unix/Makefile generic
make prefix=/opt/unzip MANDIR=/usr/share/man/man1 -f unix/Makefile install
参考: http://www.linuxfromscratch.org/blfs/view/svn/general/unzip.html
银河麒麟4.0.2 SP3系统可执行文件报权限不够
运维 chris 发表了文章 1 个评论 22561 次浏览 2021-02-01 11:31

现象
root@Kylin:~# cat aa.sh
echo 1
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# ls -l aa.sh
-rw-r--r-- 1 root root 7 2月 1 10:14 aa.sh
root@Kylin:~# chmod +x aa.sh
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# cat aa.sh
echo 1
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# ls -l aa.sh
-rw-r--r-- 1 root root 7 2月 1 10:14 aa.sh
root@Kylin:~# chmod +x aa.sh
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
如上所示,写了一个简单的Shell脚本,直接bash解释报权限错误,一般权限错误是没有执行权限什么的,但是如上给了权限还是报错。
因为也没有怎么深入使用过银河麒麟的操作系统,然后就上网查询了一下,是因为默认有个Kysec麒麟安全管理工具。
解决方案
方案一 : 通过图形桌面关闭执行控制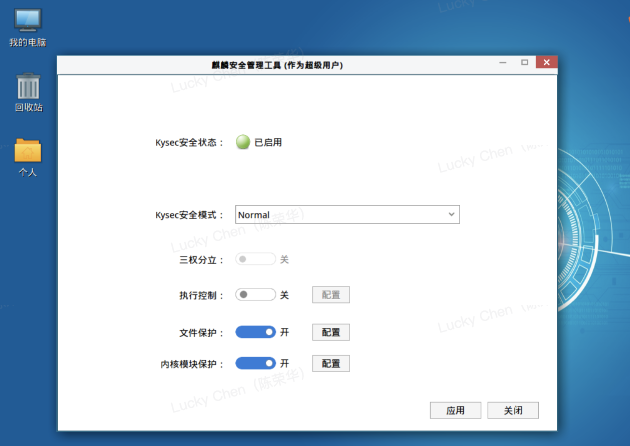
方案二: 通过命令设置麒麟系统安全状态为Softmode
root@Kylin:~# getstatus
KySec status: Normal
exec control: on
file protect: on
kmod protect: on
three admin : off
root@Kylin:~# setstatus Softmode
root@Kylin:~# getstatus
KySec status: Softmode
exec control: on
file protect: on
kmod protect: on
three admin : off
root@Kylin:~# bash aa.sh
1
设置开机启动设置:
root@Kylin:~# echo "setstatus Softmode" >> /lib/lsb/init-functions
方案三: 单独设置个别文件权限
oot@Kylin:~# setstatus Normal
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# kysec_set -n exectl -v trusted aa.sh
root@Kylin:~# bash aa.sh
1
kysec_set man手册
kysec_set(8) System Manager's Manual kysec_set(8)
NAME
kysec_set - set kysec label for specfied path(s)
SYNOPSIS
kysec_set [ -n part ] [ -r ] -v value path1 ..
DESCRIPTION
kysec_set set the kysec label of specified files or directories to
value. Kysec label is composed of three parts: identify part, pro‐
tect part and exectl part.
when not used with -n option, kysec label should be in such format:
"identify:protect:exectl". Set the new value to 'none' to clear the
corresponding part of kysec label.
for identify part, these values are valid:
secadm commands for secadm
audadm commands for auditadm
for exectl part, these values are valid:
unknown unknown files
original original system files
verified verified 3rd party files
kysoft software installer
trusted trusted files
for protect part, only readonly is valid.
OPTIONS
-n set specified part of kysec labels. part can be exectl,
userid or protect.
-r process labels recursively, only usable for directories.
-v the new label value
EE ALSO
getstatus(8), setstatus(8), kysec_get(8)
kysec_set(8)
Centos下升级OpenSSL版本
运维 chris 发表了文章 0 个评论 2107 次浏览 2020-12-20 15:28

1. 安装依赖
yum -y install perl perl-devel gcc gcc-c++
2. 升级
查看当前版本:
[root@centos7 src]$ openssl version
OpenSSL 1.0.2k-fips
下载新版本
当前最新版本是OpenSSL_1_1_1c(2019年7月5日),请到下面页面下载。
官网下载地址: https://www.openssl.org/source/
Github地址:https://github.com/openssl/openssl/releases
这里下载到/usr/local/src目录:
[root@centos7 ~]$ cd /usr/local/src
[root@centos7 src]$ wget https://github.com/openssl/openssl/archive/OpenSSL_1_1_1c.tar.gz
[root@centos7 src]$ tar xzvf ./OpenSSL_1_1_1c.tar.gz
[root@centos7 src]$ cd openssl-OpenSSL_1_1_1c/
接下来执行编译操作:
[root@centos7 src]$ ./config
如果没有安装Perl 5,执行config会有提示没有安装,需要先进行安装,执行yum install perl。
接下来依次执行下面的命令:
[root@centos7 src]$ make
[root@centos7 src]$ make test
[root@centos7 src]$ sudo make install
替换新旧版本:
[root@centos7 src]$ mv /usr/bin/openssl /usr/bin/oldopenssl
[root@centos7 src]$ ln -s /usr/local/bin/openssl /usr/bin/openssl
如果执行openssl version报下面错误:
[root@localhost openssl-OpenSSL_1_1_1c]$ openssl version
openssl: error while loading shared libraries: libssl.so.1.1: cannot open shared object file: No such file or directory
则执行下面命令解决:
[root@centos7 src]$ sudo ln -s /usr/local/lib64/libssl.so.1.1 /usr/lib64/
[root@centos7 src]$ sudo ln -s /usr/local/lib64/libcrypto.so.1.1 /usr/lib64/
然后查看当前版本:
[root@centos7 openssl-OpenSSL_1_1_1c]$ openssl version
OpenSSL 1.1.1c 28 May 2019
常见错误
错误:begin failed–compilation aborted at .././test/run_tests.pl
解决:sudo yum install perl-devel
错误:Parse errors: No plan found in TAP output
解决:yum install perl-Test-Simple





