
通知设置 新通知
大型网站系统架构演化之路
运维 being 发表了文章 0 个评论 3369 次浏览 2016-01-10 16:26
前言
一个成熟的大型网站(如淘宝、天猫、腾讯等)的系统架构并不是一开始设计时就具备完整的高性能、高可用、高伸缩等特性的,它是随着用户量的增加,业务功能的扩展逐渐演变完善的,在这个过程中,开发模式、技术架构、设计思想也发生了很大的变化,就连技术人员也从几个人发展到一个部门甚至一条产品线。所以成熟的系统架构是随着业务的扩展而逐步完善的,并不是一蹴而就;不同业务特征的系统,会有各自的侧重点,例如淘宝要解决海量的商品信息的搜索、下单、支付;例如腾讯要解决数亿用户的实时消息传输;百度它要处理海量的搜索请求;他们都有各自的业务特性,系统架构也有所不同。尽管如此我们也可以从这些不同的网站背景下,找出其中共用的技术,这些技术和手段广泛运用在大型网站系统的架构中,下面就通过介绍大型网站系统的演化过程,来认识这些技术和手段。
一、最开始的网站架构
最初的架构,应用程序、数据库、文件都部署在一台服务器上,如图:

二、应用、数据、文件分离
随着业务的扩展,一台服务器已经不能满足性能需求,故将应用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,达到最佳的性能效果。

三、利用缓存改善网站性能
在硬件优化性能的同时,同时也通过软件进行性能优化,在大部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,大部分网站访问都遵循28原则(即80%的访问请求,最终落在20%的数据上),所以我们可以对热点数据进行缓存,减少这些数据的访问路径,提高用户体验。

缓存实现常见的方式是本地缓存、分布式缓存。当然还有CDN、反向代理等,这个后面再讲。本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,OSCache就是常用的本地缓存组件。本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,速度按理没有本地缓存快,常用的分布式缓存是Memcached、Redis。
四、使用集群改善应用服务器性能
应用服务器作为网站的入口,会承担大量的请求,我们往往通过应用服务器集群来分担请求数。应用服务器前面部署负载均衡服务器调度用户请求,根据分发策略将请求分发到多个应用服务器节点。

常用的负载均衡技术硬件的有F5,价格比较贵,软件的有LVS、Nginx、HAProxy。LVS是四层负载均衡,根据目标地址和端口选择内部服务器,Nginx和HAProxy是七层负载均衡,可以根据报文内容选择内部服务器,因此LVS分发路径优于Nginx和HAProxy,性能要高些,而Nginx和HAProxy则更具配置性,如可以用来做动静分离(根据请求报文特征,选择静态资源服务器还是应用服务器)。
五、数据库读写分离和分库分表
随着用户量的增加,数据库成为最大的瓶颈,改善数据库性能常用的手段是进行读写分离以及分库分表,读写分离顾名思义就是将数据库分为读库和写库,通过主备功能实现数据同步。分库分表则分为水平切分和垂直切分,水平切分则是对一个数据库特大的表进行拆分,例如用户表。垂直切分则是根据业务的不同来切分,如用户业务、商品业务相关的表放在不同的数据库中。

六、使用CDN和反向代理提高网站性能
假如我们的服务器都部署在成都的机房,对于四川的用户来说访问是较快的,而对于北京的用户访问是较慢的,这是由于四川和北京分别属于电信和联通的不同发达地区,北京用户访问需要通过互联路由器经过较长的路径才能访问到成都的服务器,返回路径也一样,所以数据传输时间比较长。对于这种情况,常常使用CDN解决,CDN将数据内容缓存到运营商的机房,用户访问时先从最近的运营商获取数据,这样大大减少了网络访问的路径。比较专业的CDN运营商有蓝汛、网宿。

而反向代理,则是部署在网站的机房,当用户请求达到时首先访问反向代理服务器,反向代理服务器将缓存的数据返回给用户,如果没有缓存数据才会继续访问应用服务器获取,这样做减少了获取数据的成本。反向代理有Squid,Nginx。
七、使用分布式文件系统
用户一天天增加,业务量越来越大,产生的文件越来越多,单台的文件服务器已经不能满足需求,这时就需要分布式文件系统的支撑。常用的分布式文件系统有GFS、HDFS、TFS。

八、使用NoSql和搜索引擎
对于海量数据的查询和分析,我们使用nosql数据库加上搜索引擎可以达到更好的性能。并不是所有的数据都要放在关系型数据中。常用的NOSQL有mongodb、hbase、redis,搜索引擎有lucene、solr、elasticsearch。

九、将应用服务器进行业务拆分
随着业务进一步扩展,应用程序变得非常臃肿,这时我们需要将应用程序进行业务拆分,如百度分为新闻、网页、图片等业务。每个业务应用负责相对独立的业务运作。业务之间通过消息进行通信或者共享数据库来实现。

十、搭建分布式服务
这时我们发现各个业务应用都会使用到一些基本的业务服务,例如用户服务、订单服务、支付服务、安全服务,这些服务是支撑各业务应用的基本要素。我们将这些服务抽取出来利用分部式服务框架搭建分布式服务。阿里的Dubbo是一个不错的选择。

总结
大型网站的架构是根据业务需求不断完善的,根据不同的业务特征会做特定的设计和考虑,本文只是讲述一个常规大型网站会涉及的一些技术和手段。
分享阅读整理原文:http://www.cnblogs.com/leefreeman/p/3993449.html
参考书籍:《大型网站技术架构》《海量运维运营规划》
十条命令一分钟分析出Linux服务器性能
运维 push 发表了文章 0 个评论 3204 次浏览 2016-01-09 20:47
概述
通过执行以下命令,可以在1分钟内对系统资源使用情况有个大致的了解。
- []uptime[/][]dmesg | tail[/][]vmstat 1[/][]mpstat -P ALL 1[/][]pidstat 1[/][]iostat -xz 1[/][]free -m[/][]sar -n DEV 1[/][]sar -n TCP,ETCP 1[/][]top[/]
uptime
$ uptime23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02这个命令可以快速查看机器的负载情况。在Linux系统中,这些数据表示等待CPU资源的进程和阻塞在不可中断IO进程(进程状态为D)的数量。这些数据可以让我们对系统资源使用有一个宏观的了解。命令的输出分别表示1分钟、5分钟、15分钟的平均负载情况。通过这三个数据,可以了解服务器负载是在趋于紧张还是区域缓解。如果1分钟平均负载很高,而15分钟平均负载很低,说明服务器正在命令高负载情况,需要进一步排查CPU资源都消耗在了哪里。反之,如果15分钟平均负载很高,1分钟平均负载较低,则有可能是CPU资源紧张时刻已经过去。上面例子中的输出,可以看见最近1分钟的平均负载非常高,且远高于最近15分钟负载,因此我们需要继续排查当前系统中有什么进程消耗了大量的资源。可以通过下文将会介绍的vmstat、mpstat等命令进一步排查。
dmesg | tail
$ dmesg | tail[1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0[...][1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child[1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB, file-rss:0kB[2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. Check SNMP counters.该命令会输出系统日志的最后10行。示例中的输出,可以看见一次内核的oom kill和一次TCP丢包。这些日志可以帮助排查性能问题。千万不要忘了这一步。
vmstat 1
$ vmstat 1procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 032 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 032 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 032 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 032 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0^Cvmstat(8) 命令,每行会输出一些系统核心指标,这些指标可以让我们更详细的了解系统状态。后面跟的参数1,表示每秒输出一次统计信息,表头提示了每一列的含义,这几介绍一些和性能调优相关的列:
- []r:等待在CPU资源的进程数。这个数据比平均负载更加能够体现CPU负载情况,数据中不包含等待IO的进程。如果这个数值大于机器CPU核数,那么机器的CPU资源已经饱和。[/][]free:系统可用内存数(以千字节为单位),如果剩余内存不足,也会导致系统性能问题。下文介绍到的free命令,可以更详细的了解系统内存的使用情况。[/][]si, so:交换区写入和读取的数量。如果这个数据不为0,说明系统已经在使用交换区(swap),机器物理内存已经不足。[/][]us, sy, id, wa, st:这些都代表了CPU时间的消耗,它们分别表示用户时间(user)、系统(内核)时间(sys)、空闲时间(idle)、IO等待时间(wait)和被偷走的时间(stolen,一般被其他虚拟机消耗)。[/]
mpstat -P ALL 1
$ mpstat -P ALL 1Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.7807:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.9907:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.0007:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.0007:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03[...]该命令可以显示每个CPU的占用情况,如果有一个CPU占用率特别高,那么有可能是一个单线程应用程序引起的。pidstat 1
$ pidstat 1Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)07:41:02 PM UID PID %usr %system %guest %CPU CPU Command07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/007:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat07:41:03 PM UID PID %usr %system %guest %CPU CPU Command07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat^Cpidstat命令输出进程的CPU占用率,该命令会持续输出,并且不会覆盖之前的数据,可以方便观察系统动态。如上的输出,可以看见两个JAVA进程占用了将近1600%的CPU时间,既消耗了大约16个CPU核心的运算资源。
iostat -xz 1
$ iostat -xz 1Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)avg-cpu: %user %nice %system %iowait %steal %idle 73.96 0.00 3.73 0.03 0.06 22.21Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %utilxvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03[...]^Ciostat命令主要用于查看机器磁盘IO情况。该命令输出的列,主要含义是:- []r/s, w/s, rkB/s, wkB/s:分别表示每秒读写次数和每秒读写数据量(千字节)。读写量过大,可能会引起性能问题。[/][]await:IO操作的平均等待时间,单位是毫秒。这是应用程序在和磁盘交互时,需要消耗的时间,包括IO等待和实际操作的耗时。如果这个数值过大,可能是硬件设备遇到了瓶颈或者出现故障。[/][]avgqu-sz:向设备发出的请求平均数量。如果这个数值大于1,可能是硬件设备已经饱和(部分前端硬件设备支持并行写入)。[/][]%util:设备利用率。这个数值表示设备的繁忙程度,经验值是如果超过60,可能会影响IO性能(可以参照IO操作平均等待时间)。如果到达100%,说明硬件设备已经饱和。[/]
free –m
$ free -m total used free shared buffers cachedMem: 245998 24545 221453 83 59 541-/+ buffers/cache: 23944 222053Swap: 0 0 0free命令可以查看系统内存的使用情况,-m参数表示按照兆字节展示。最后两列分别表示用于IO缓存的内存数,和用于文件系统页缓存的内存数。需要注意的是,第二行-/+ buffers/cache,看上去缓存占用了大量内存空间。这是Linux系统的内存使用策略,尽可能的利用内存,如果应用程序需要内存,这部分内存会立即被回收并分配给应用程序。因此,这部分内存一般也被当成是可用内存。如果可用内存非常少,系统可能会动用交换区(如果配置了的话),这样会增加IO开销(可以在iostat命令中提现),降低系统性能。
sar -n DEV 1
$ sar -n DEV 1Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.0012:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.0012:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0012:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.0012:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.0012:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00^Csar命令在这里可以查看网络设备的吞吐率。在排查性能问题时,可以通过网络设备的吞吐量,判断网络设备是否已经饱和。如示例输出中,eth0网卡设备,吞吐率大概在22 Mbytes/s,既176 Mbits/sec,没有达到1Gbit/sec的硬件上限。
sar -n TCP,ETCP 1
$ sar -n TCP,ETCP 1Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)12:17:19 AM active/s passive/s iseg/s oseg/s12:17:20 AM 1.00 0.00 10233.00 18846.0012:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s12:17:20 AM 0.00 0.00 0.00 0.00 0.0012:17:20 AM active/s passive/s iseg/s oseg/s12:17:21 AM 1.00 0.00 8359.00 6039.0012:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s12:17:21 AM 0.00 0.00 0.00 0.00 0.00^Csar命令在这里用于查看TCP连接状态,其中包括:
- []active/s:每秒本地发起的TCP连接数,既通过connect调用创建的TCP连接;[/][]passive/s:每秒远程发起的TCP连接数,即通过accept调用创建的TCP连接;[/][]retrans/s:每秒TCP重传数量;[/]
TCP连接数可以用来判断性能问题是否由于建立了过多的连接,进一步可以判断是主动发起的连接,还是被动接受的连接。TCP重传可能是因为网络环境恶劣,或者服务器压力过大导致丢包。
top
$ toptop命令包含了前面好几个命令的检查的内容。比如系统负载情况(uptime)、系统内存使用情况(free)、系统CPU使用情况(vmstat)等。因此通过这个命令,可以相对全面的查看系统负载的来源。同时,top命令支持排序,可以按照不同的列排序,方便查找出诸如内存占用最多的进程、CPU占用率最高的进程等。
top - 00:15:40 up 21:56, 1 user, load average: 31.09, 29.87, 29.92
Tasks: 871 total, 1 running, 868 sleeping, 0 stopped, 2 zombie
%Cpu(s): 96.8 us, 0.4 sy, 0.0 ni, 2.7 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 25190241+total, 24921688 used, 22698073+free, 60448 buffers
KiB Swap: 0 total, 0 used, 0 free. 554208 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20248 root 20 0 0.227t 0.012t 18748 S 3090 5.2 29812:58 java
4213 root 20 0 2722544 64640 44232 S 23.5 0.0 233:35.37 mesos-slave
66128 titancl+ 20 0 24344 2332 1172 R 1.0 0.0 0:00.07 top
5235 root 20 0 38.227g 547004 49996 S 0.7 0.2 2:02.74 java
4299 root 20 0 20.015g 2.682g 16836 S 0.3 1.1 33:14.42 java
1 root 20 0 33620 2920 1496 S 0.0 0.0 0:03.82 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:05.35 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:06.94 kworker/u256:0
8 root 20 0 0 0 0 S 0.0 0.0 2:38.05 rcu_sched
但是,top命令相对于前面一些命令,输出是一个瞬间值,如果不持续盯着,可能会错过一些线索。这时可能需要暂停top命令刷新,来记录和比对数据。
总结
排查Linux服务器性能问题还有很多工具,上面介绍的一些命令,可以帮助我们快速的定位问题。例如前面的示例输出,多个证据证明有JAVA进程占用了大量CPU资源,之后的性能调优就可以针对应用程序进行。
英文原文:http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
翻译原文:http://www.infoq.com/cn/news/2015/12/linux-performance
开源分布式数据库Mysql中间件Mycat
开源项目 chris 发表了文章 1 个评论 6935 次浏览 2016-01-09 19:54
什么是MYCAT
- []一个彻底开源的,面向企业应用开发的大数据库集群[/][]支持事务、ACID、可以替代MySQL的加强版数据库[/][]一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群[/][]一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server[/][]结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品[/][]一个新颖的数据库中间件产品[/]
Mycat特性
- []支持SQL92标准[/][]遵守Mysql原生协议,跨语言,跨数据库的通用中间件代理。[/][]基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster。[/][]支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster[/][]基于Nio实现,有效管理线程,高并发问题。[/][]支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数。[/][]支持2表join,甚至基于caltlet的多表join。[/][]支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。[/][]支持多租户方案。[/][]支持分布式事务(弱xa)。[/][]支持全局序列号,解决分布式下的主键生成问题。[/][]分片规则丰富,插件化开发,易于扩展。[/][]强大的web,命令行监控。[/][]支持前端作为mysq通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 、巨杉。[/][]支持密码加密[/][]支持IP白名单[/][]支持SQL黑名单、sql注入攻击拦截[/][]集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)。[/]
Mycat架构

Mycat高可用方案




Mycat监控
- []支持对Mycat、Mysql性能监控[/][]支持对Mycat的JVM内存提供监控服务[/][]支持对线程的监控[/][]支持对操作系统的CPU、内存、磁盘、网络的监控[/]


低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。1.5版本架构目标

长期规划2.0
- []完全实现分布式事务,完全的支持分布式。[/][]通过Mycat web(eye)完成可视化配置,及智能监控,自动运维。[/][]通过mysql 本地节点,完整的解决数据扩容难度,实现自动扩容机制,解决扩容难点。[/][]支持基于zookeeper的主从切换及Mycat集群化管理。[/][]通过Mycat Balance 替代第三方的Haproxy,LVS等第三方高可用,完整的兼容Mycat集群节点的动态上下线。[/][]接入Spark等第三方工具,解决数据分析及大数据聚合的业务场景。[/][]通过Mycat智能优化,分析分片热点,提供合理的分片建议,索引建议,及数据切分实时业务建议。[/]
优势
基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得MYCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,我们能看到更远。业界优秀的开源项目和创新思路被广泛融入到MYCAT的基因中,使得MYCAT在很多方面都领先于目前其他一些同类的开源项目,甚至超越某些商业产品。
MYCAT背后有一支强大的技术团队,其参与者都是5年以上资深软件工程师、架构师、DBA等,优秀的技术团队保证了MYCAT的产品质量。
MYCAT并不依托于任何一个商业公司,因此不像某些开源项目,将一些重要的特性封闭在其商业产品中,使得开源项目成了一个摆设。
Mycat关注
老外都开始关注Mycat了!

Mycat官方论坛:http://i.mycat.io/forum.php
Mycat Github:https://github.com/MyCATApache
Mycat权威指南第一版_V1.5.1:http://pan.baidu.com/s/1i3SFOpf
IOS崩溃命令行工具atosl安装记录
编程 空心菜 发表了文章 3 个评论 9495 次浏览 2016-01-08 14:07

Centos安装
1、安装依赖包libdwarf、binutils-devel、lasso、tbb
yum -y install libdwarf-devel libdwarf-tools binutils-devel lasso libdwarf lasso-python libdwarf-tools libdwarf-static tbb
2、创建libdwarf.h软连接
ln -s /usr/include/libdwarf/libdwarf.h /usr/include/libdwarf.h
ln -s /usr/include/libdwarf/dwarf.h /usr/include/dwarf.h
3、获取atosl源码
cd /usr/local/ && git clone https://github.com/facebook/atosl.git
4、安装atosl
cd atosl #进入源码目录
echo "LDFLAGS += -L/usr/bin" > ./config.mk.local #添加objdump环境目录
make #编译安装
5、测试命令
默认安装完成后,命令是在你源码包路径下
Example:/usr/local/atosl是我源码存储目录,那安装完成后命令路径为/usr/local/atosl/atosl
所以需要做个软连接让环境变量中可以查到:
# ln -s /usr/local/atosl/atosl /usr/bin/atosl
命令结果如下: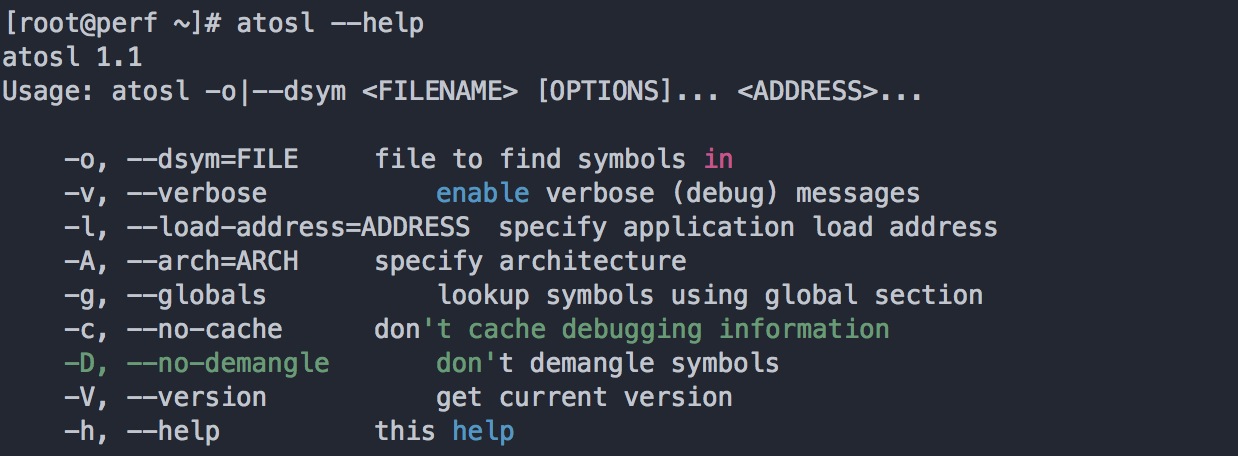
Ubuntu安装
1、安装libdwarf-dev、 dwarfdump、binutils-dev 、libiberty-dev软件包
$ sudo apt-get install libdwarf-dev dwarfdump binutils-dev libiberty-dev
2、从github克隆下载atosl源码
$ git clone https://github.com/facebook/atosl.git
3、进入源码目录安装
$ cd atosl
Create a local config config.mk.local which contains a flag with the location of your binutil apps. (in Ubuntu by default that's /usr/bin). If you're not sure, you can find out by executing cat /var/lib/dpkg/info/binutils.list | less and copy the path of the file objdump. E.g. if the entry is /usr/bin/objdump, your path is /usr/bin.
So in the end, your config.mk.local should look like this:
$ echo "LDFLAGS += -L/usr/bin" > ./config.mk.local
$ make
4、测试命令
参考:
https://github.com/facebook/hhvm/issues/536
https://github.com/facebook/hhvm/wiki/Building-and-installing-HHVM-on-CentOS-6.3
http://stackoverflow.com/questions/15070680/ios-symbolication-server-side
浅谈IT培训知识体系
科技前沿 Rock 发表了文章 1 个评论 3372 次浏览 2016-01-07 02:19
前言
有时候经常会被别的部门叫去培训IT知识体系,想对公司整个技术组织架构有个详细的了解和对IT知识体系的了解。但是同事们的技术专业水平又不是很强,那我们应该怎么逐步讲解,然后放大知识面,逐步深入呢?看完下面几个方面,你相信你就知道怎么切入了!
一、设备管理

设备管理主要包括如下两方面:
1、服务器、交换机、路由器、存储设备运维管理
2、IDC现状及未来发展趋势分析
二、网络管理

网络管理主要包括如下几方面:
1、企业网络架构
2、防火墙工作原理
3、常用网络协议
4、DNS工作原理及其作用
5、VLAN、VPN工作原理及作用
6、CDN原理及监控
三、软件系统架构

软件系统架构主要包括如下几方面:
1、企业应用架构设计
2、分布式系统
3、互联网架构演变
四、中间件管理

中间件管理主要包括如下几方面:
1、Liunx操作系统基本知识
2、各种操作系统对比
3、应用服务器工作原理及故障排除
4、负载均衡F5/Nginx/LVS/HAProxy原理和作用
5、JVM作用及工作原理
五、数据库管理

数据库管理主要包括如下几方面:
1、MySql数据库性能监控
2、MySql数据库日志监控
3、MySql数据库服务监控
4、NoSql数据库服务监控
5、NoSql数据库性能监控
6、数据库事件管理与配置管理
7、分布式数据管理了解
六、安全管理

安全管理主要包括如下几方面:
1、操作系统安全,账号保护、重要文件防护、防攻击,安全服务等
2、网络安全
3、应用安全,网站监控常用技术
七、云计算

云计算主要包括如下几方面:
1、IaaS基础设施服务
2、PaaS基础平台服务
3、SaaS软件服务
4、Cass容器集成服务
八、大数据

大数据主要包括如下几方面:
1、Hadoop生态系统体系
2、大数据聚合分析
3、大数据存储迁移
4、集群管理,大数据消息系统
以上都是个人总结,各位看官勿喷!
docker web化管理
开源项目 Something 发表了文章 4 个评论 8327 次浏览 2016-01-05 18:03
背景
目前很多公司都在使用docker,docker也是一种趋势,我们公司也在使用docker,所以我也跟着学习使用docker,根据基本需求,结合api做了一个web程序
实验环境
本次试验使用两台实体机做模拟docker集群,一台虚拟机做docker镜像服务器,一台虚拟机做web管理机原理图:
系统软件环境及版本:
selinux disabled
iptables -F
三台docker机器系统使用centos7.1,两台模拟机群docker机软件docker+pipework+openswitch+etcd+dhcp,docker镜像服务器跑了一个registry容器提供镜像服务
Web管理机使用ubuntu,python+django+uwsgi

程序流程图:

原理
通过web界面创建删除容器和镜像,web服务器通过api操作三台docker机器,创建容器时通过dhcp获取ip,pipework给容器附上获取的ip,并把容器信息写入etcd库中,由于容器重启后ip消失,我通过监控脚本给启动没有ip的容器重新附上ip。容器支持ssh,有好处也有风险。
网络这块我是用交换机提供的网段,容器使用的ip和实体机在同一valn,你也可以一个集群使用一个valn,这里我是用同一valn。容器ip可以从交换机dhcp获取,不懂交换机,我直接用一台docker实体机起了dhcp服务,为该段提供dhcp服务。
安装
1.1 docker集群节点
两台机器软件一样,我就以AB区别,软件基本一样,A多了一个dhcp,没有使用交换机提供dhcp1.2 安装openswitch:
如果后期不想在docker集群中划分vlan,可以使用系统自带的brctl命令创建桥接网卡,下面创建桥接网卡的脚本相应的变一下,ovs-vsctl改为brctl1.3 下载pipework:
yum install gcc make python-devel openssl-devel kernel-devel graphviz kernel-debug-devel autoconf automake rpm-build redhat-rpm-config libtool
wget http://openvswitch.org/releases/openvswitch-2.3.1.tar.gz
tar zxvf openvswitch-2.3.1.tar.gz
mkdir -p ~/rpmbuild/SOURCES
cp openvswitch-2.3.1.tar.gz ~/rpmbuild/SOURCES/
sed 's/openvswitch-kmod, //g' openvswitch-2.3.1/rhel/openvswitch.spec > openvswitch-2.3.1/rhel/openvswitch_no_kmod.spec
rpmbuild -bb --without check openvswitch-2.3.1/rhel/openvswitch_no_kmod.spec
#之后会在~/rpmbuild/RPMS/x86_64/里有2个文件
-rw-rw-r-- 1 ovswitch ovswitch 2013688 Jan 15 03:20 openvswitch-2.3.1-1.x86_64.rpm
-rw-rw-r-- 1 ovswitch ovswitch 7712168 Jan 15 03:20 openvswitch-debuginfo-2.3.1-1.x86_64.rpm
yum localinstall ~/rpmbuild/RPMS/x86_64/openvswitch-2.3.1-1.x86_64.rpm
systemctl enable openvswitch
systemctl start openvswitch
git clone https://github.com/jpetazzo/pipework.git1.4 网卡配置
chmod +x pipework
cp pipework /usr/bin/pipework
脚本下载地址
在节点机器上1.5 安装docker
pwd
/root
check_modify_container.py create_docker_container_use_dhcp_ip.sh openvswitch_docker.sh
#openvswitch_docker.sh 是网卡初始化脚本
#create_docker_container_use_dhcp_ip.sh 是创建容器时会调用的脚本
#check_modify_container.py 容器ip监控脚本
crontab -e
[i]/5 [/i] [i] [/i] * python /root/check_modify_container.py #监控脚本每五分钟执行一次
em1 为管理网段ip
Ovs1桥接在em2上,为docker内网网段ip
配置网卡,这里使用桥接
cat openvswitch_docker.sh
#!/bin/bash
#删除docker测试机
#docker rm `docker stop $(docker ps -a -q)`
#删除已有的openvswitch交换机
ovs-vsctl list-br|xargs -I {} ovs-vsctl del-br {}
#创建交换机
ovs-vsctl add-br ovs1
#把物理网卡加入ovs1
ovs-vsctl add-port ovs1 em2
ip link set ovs1 up
ifconfig em2 0
ifconfig ovs1 192.168.157.21 netmask 255.255.255.0
chmod +x openvswitch_docker.sh
sh openvswitch_docker.sh
也可以写到配置文件中
我的em1为管理网卡10.0.0.21
A机器中安装dhcp,集群中一台机器配置dhcp就可以了,网段根据你的环境改变
yum install -y dhcp
vim /etc/dhcp/dhcpd.conf
log-facility local7;
ddns-update-style none;
subnet 192.168.157.0 netmask 255.255.255.0 {
range 192.168.157.100 192.168.157.200;
option domain-name-servers 202.106.0.20;
option routers 192.168.157.1;
option broadcast-address 192.168.157.255;
default-lease-time 80000;
max-lease-time 80000;
}
systemctl enable dhcpd
systemctl start dhcpd
yum install -y docker1.6 Etcd安装
vim /etc/sysconfig/docker
OPTIONS='--selinux-enabled --insecure-registry 192.168.46.130:5000 -b=none -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock'
#指定镜像服务器为192.168.46.130,net使用none模式,监听2375端口,这个端口提供api访问的
systemctl start docker.service
systemctl enable docker.service
yum install libffi libffi-devel python-devel2.1 docker镜像服务器
yum -y install epel-release
yum -y install python-pip
yum install etcd -y
vim /etc/etcd/etcd.conf
ETCD_NAME=default
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379"
[size=16]#这里etcd我没有做成集群,每台docker机的数据就保存在本机的etcd库中,不与其他节点同步,也不需要提供其他节点访问,这里设置监听本机[/size]
systemctl enable etcd
systemctl start etcd
镜像服务器在安装配置完docker后,从官网pull下来一个registry镜像,启动创建一个镜像服务器容器
docker search registry
docker pull docker.io/registry
docker run --restart always -d -p 5000:5000 -v /opt/data/registry:/tmp/registry docker.io/registry
安装docker请重复1.53.1 web服务器
Django web程序下载地址
Web服务器系统我用的ubuntu,主要是安装软件简单,源及软件更新比较快
[quote]>> import django
>>> django.VERSION
(1, 7, 1, 'final', 0)这是我的django版本
apt-get install mysql-server mysql-client
apt-get install python-pip
pip install Django==1.7.1 #你也可以安装最新版本,不确定我写的程序能否正常运行
apt-get install python-mysqldb
pip install docker-py #要调用docker api,所以要安装相关python包
apt-get install curl
apt-get install mysql-server
apt-get isntall mysql-client
sudo apt-get install libmysqlclient-dev
apt-get install python-paramiko #web程序中也会用到curl和paramiko
git clone https://github.com/SomethingCM/Web-for-docker.git 到本地
cd Web-for-docker/docker_demo
vim docker_demo/settings.py
#修改数据库配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'docker', #docker 库名
'USER': 'root', #mysql登陆用户
'PASSWORD': 'dockerchen',#密码,如果mysql设置了用户名密码可以填写,没有则为空
'HOST':'',
'PORT':'',
}
}
#修改完以后创建表
./manage.py syncdb
#执行的时候会让你设置后台root用户密码,两次输入密码创建表成功
./manage.py runserver 0.0.0.0:80
初始化设置
在浏览器中输入 IP:port/admin 设置后台 IP为web服务器的ip登陆后台admin初始化设置


添加仓库节点

添加节点



前台登陆



编写dockerfile创建镜像


把现有容器打包成镜像

创建容器

关于怎么用django+uwsgi发布网站这里就不叙述了
由于各种原因项目中途GAMEOVE了,没有具体的需求,不知道如何往下写了,有兴趣的朋友可以参考一下[/quote]
vim问题ycm_client_support.[so|pyd|dll] and ycm_core.[so|pyd|dll] not detected解决
运维 being 发表了文章 0 个评论 4885 次浏览 2016-01-04 21:55
ycm_client_support.[so|pyd|dll] and ycm_core.[so|pyd|dll] not detected; you need to compile YCM before using it. Read the docs!这个需要到~/.vim/bundle/YouCompleteMe,你的YCM目录下,加入如下命令解决:
./install.sh --clang-completer但是执行过程中错误如下:
Some folders in /home/sky-tm/.vim/bundle/YouCompleteMe/third_party/ycmd/third_party are empty; you probably forgot to run: git submodule update --init --recursive遇错解错,按照提示按照呗:
git submodule update --init --recursive等执行完成后,再次执行命令
./install.sh --clang-completer又报错了!!!!
Your C++ compiler supports C++11, compiling in that mode.执行如下命令解决,按照clang
Downloading Clang 3.5
CMake Error at ycm/CMakeLists.txt:62 (message):
No pre-built Clang 3.6 binaries for 32 bit linux. You'll have to compile
Clang 3.6 from source. See the YCM docs for details on how to use a
user-compiled libclang.
./install.sh --clang-completer --system-libclang然后在执行:
./install.sh --clang-completer结果为:

build成功了!终于解决了!
Mysql架构的演化
数据库 Rock 发表了文章 2 个评论 4065 次浏览 2016-01-03 23:44
Mysql微型高可用架构
方案:Mysql主从复制,读写分离

服务器资源:两台服务器
优点:架构简单,节省资源
缺点:任何一台服务器down机,都会对业务造成影响。
网站发展初期,到一定程度,单台Mysql的读写效率是满足不了生产的应用的了。即使在网站使用了缓存后,大部分数据的读操作访问都不通过数据库完成,但是仍然有一部分的读操作(缓存不命中、缓存过期)和全部的写操作还是需要访问数据库,当数据库的访问达到一定压力后,数据库会因为负载过高成为整个系统的瓶颈。所以初期的读写分离很重要!
Mysql小型高可用架构
方案:MySQL双主、主从 + Keepalived主从自动切换

服务器资源:四台服务器
优点:架构简单,资源适度
缺点:无法线性扩展,主从失败之后需要手动恢复主从架构。
单一的读写分离,满足不了业务需求之后,我们需要横向扩展多主多从,来达到压力分流和多向写入的设计。
MySQL中型高可用架构
方案:MMM + MySQL双主 + 多从高可用方案

服务器资源:
1、至少五台服务器,2台MySQL主库,2台MySQL从库,1台MMM Monitor;
2、1台MMM Monitor选择低配;
3、如果不采用F5作为从库的负载均衡器,可用2台服务器部署LVS或HAProxy+Keepalived组合来代替;
优点:双主热备模式,读写分离,SLAVE集群可线性扩展
缺点:读写分离需要在程序端解决,Master大批量写操作时会产生主从延时
MySQL大型高可用架构
主要思路:中间件+MySQL Sharding
如方案:Cobar、Mycat等中间件+MySQL技术
另外,还分享些MySQL一些主流的高可用架构:
- []MySQL双主 + Keepalived主备自动切换方案(上面已有)[/][]MySQL主从 + Keepalived主从自动切换方案(上面已有)[/][]MMM+MySQL双主 + 多从高可用方案(上面已有)[/][]MySQL + Pecemaker(Heartbeat) + DRBD高可用[/][]MySQL + RHCS 高可用方案[/][]MySQL + Cluser 集群架构[/][]Percona Xtradb Cluster 集群高可用性解决方案[/][]中间件 + MySQL 大型集群解决方案(上面已提到)[/]
MySQL + Pecemaker(Heartbeat) + DRBD高可用 && MySQL + RHCS 高可用方案

Percona Xtradb Cluster 集群高可用性解决方案

MySQL多机房部署架构参考案例








