
Kafka
Kafka Topic创建三步曲
大数据 空心菜 发表了文章 0 个评论 2182 次浏览 2020-09-19 15:22


通常在生产环境新增业务主题,我们都需要提前预测到,然后做好充分的准备,本文将介绍在生产环境中创建Topic时需要考虑的所有参数。
首先创建新Topic的时候,我们需要设置合理的分区数和副本数,不合理的设置将会给系统的性能和可靠性带来影响。
创建一个Topic
kafka/bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 2 \
--partitions 3 \
--topic unique-topic-name
分区(Partitions)
Kafka主题分为多个分区,其中包含以不变顺序排列的消息。分区中的每个消息均通过其唯一偏移量进行分配和标识。
分区使我们可以在多个Broker之间分配主题数据,从而平衡Broker之间的负载。每个分区只能由一个Consumer Group使用,因此,服务的并行性受Topic拥有的分区数约束。
分区数受两个主要因素的影响,即消息数和每条消息的平均大小。如果交易量很大,您将需要使用代理数量作为乘法倍数,以允许在所有使用者上共享负载,并避免创建热分区,该分区会对特定代理造成高负载。我们的目标是使分区吞吐量达到1MB/s。
设置分区数:
--partitions [number]
副本(Replicas)

如果leader分区发生故障并且需要跟随者(follower)副本替换它并成为领导者(leader),则Kafka可以选择复制Topic分区。在配置Topic时,请记住,分区是为实现快速读写速度,可伸缩性和分发大量数据而设计的。
另一方面,复制因子(RF)旨在确保指定的容错目标。副本不会直接影响性能,因为在任何给定时间,只有一个(leader)领导者分区负责通过Broker服务器处理生产者和使用者请求。
在决定复制因子时的另一个考虑因素是,为了满足生产容量会话,需要考虑服务需要的消费者数量。
设置复制因子(RF):
如果你的Topic承载的是关键业务,推荐你设置复制因子为3,其他的设置为2就够了。
--replication-factor [number]
Tips: 但这里需要注意一点的是, RF <= Broker Number
保留(Retention)
将消息保留在Topic中的时间或最大Topic大小。根据你的用例确定。默认情况下,保留期限为7天,但这是可配置的。
设置Retention:
--config retention.ms=[number]
压缩(Compaction)
为了释放空间并清理不需要的记录,Kafka压缩可以根据记录的日期和大小删除记录。它还可以删除具有相同键的每个记录,同时保留该记录的最新版本。基于键的压缩对于控制Topic的大小非常有用,其中只有最新的记录版本才是重要的。
启用压缩:
log.cleanup.policy=compact
分享阅读原文: http://suo.im/5W8p1p
kafka __consumer_offsets过大造成磁盘满问题
运维 回复了问题 2 人关注 1 个回复 15222 次浏览 2018-09-12 16:46
Kafka日志设置和清除策略
大数据 push 发表了文章 0 个评论 19442 次浏览 2017-04-15 16:00

一、日志设置
1、修改日志级别
config/log4j.properties中日志的级别设置的是TRACE,在长时间运行过程中产生的日志大小吓人,所以如果没有特殊需求,强烈建议将其更改成INFO级别。具体修改方法如下所示,将config/log4j.properties文件中最后的几行中的TRACE改成INFO,修改前如下所示:
log4j.logger.kafka.network.RequestChannel$=TRACE, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=TRACE, requestAppender
#log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=TRACE, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=TRACE, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.state.change.logger=TRACE, stateChangeAppender
log4j.additivity.state.change.logger=false
修改后如下所示:
log4j.logger.kafka.network.RequestChannel$=INFO, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=INFO, requestAppender
#log4j.logger.kafka.server.KafkaApis=INFO, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=INFO, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=INFO, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.state.change.logger=INFO, stateChangeAppender
log4j.additivity.state.change.logger=false
2、修改日志存放位置
还有就是默认Kafka运行的时候都会通过log4j打印很多日志文件,比如server.log, controller.log, state-change.log等,而都会将其输出到$KAFKA_HOME/logs目录下,这样很不利于线上运维,因为经常容易出现打爆文件系统,一般安装的盘都比较小,而数据和日志会指定打到另一个或多个更大空间的分区盘
具体方法是,打开$KAFKA_HOME/bin/kafka-run-class.sh,找到下面标示的位置,并定义一个变量,指定的值为系统日志输出路径,重启broker即可生效。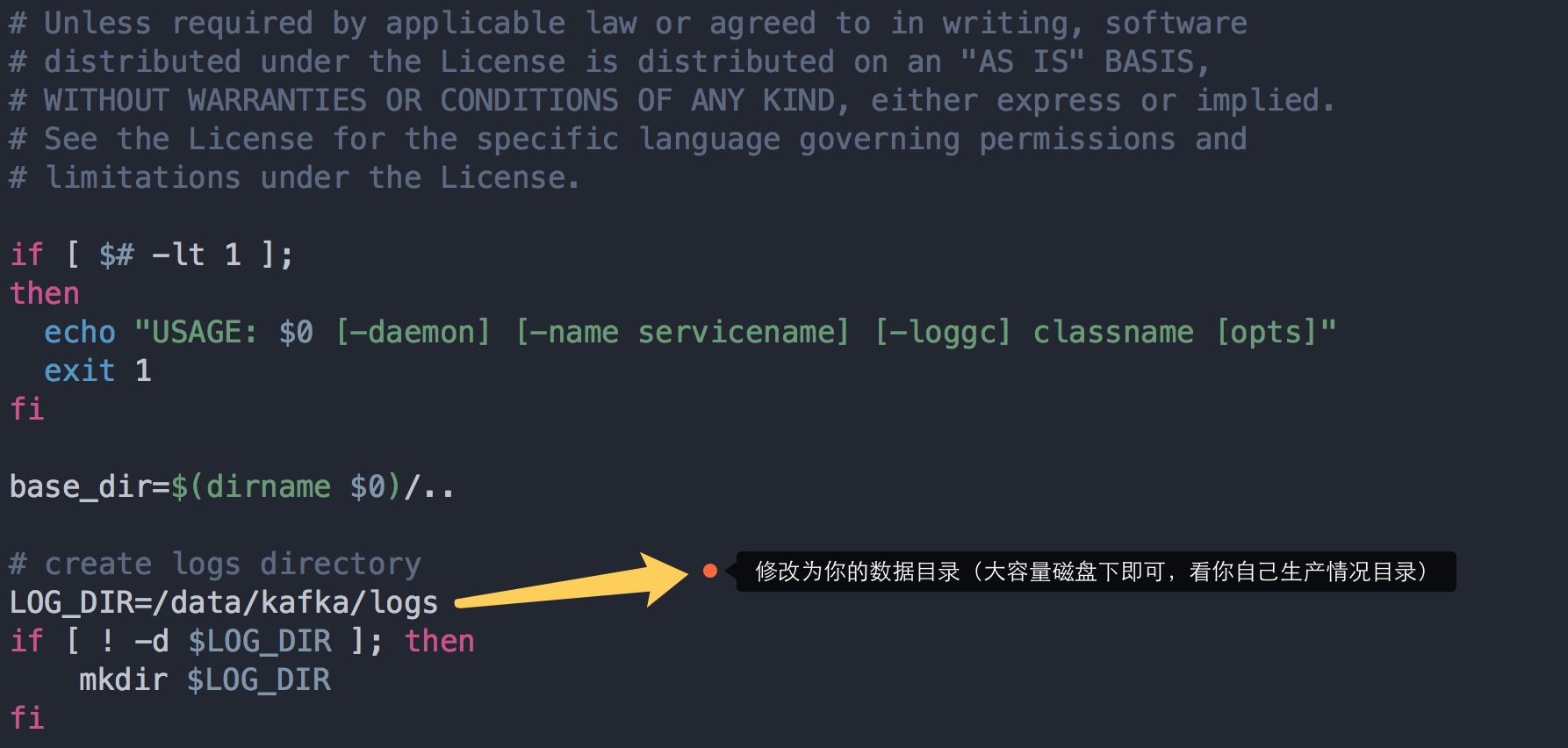
二、日志清理和策略
1、利用Kafka日志管理器
Kafka日志管理器允许定制删除策略。目前的策略是删除修改时间在N天之前的日志(按时间删除),也可以使用另外一个策略:保留最后的N GB数据的策略(按大小删除)。为了避免在删除时阻塞读操作,采用了copy-on-write形式的实现,删除操作进行时,读取操作的二分查找功能实际是在一个静态的快照副本上进行的,这类似于Java的CopyOnWriteArrayList。
Kafka消费日志删除思想:Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用
log.cleanup.policy=delete启用删除策略
直接删除,删除后的消息不可恢复。可配置以下两个策略:
清理超过指定时间清理:
log.retention.hours=16
超过指定大小后,删除旧的消息:
log.retention.bytes=1073741824
2、压缩策略
将数据压缩,只保留每个key最后一个版本的数据。首先在broker的配置中设置log.cleaner.enable=true启用cleaner,这个默认是关闭的。在Topic的配置中设置log.cleanup.policy=compact启用压缩策略。
压缩策略的细节如下:
如上图,在整个数据流中,每个Key都有可能出现多次,压缩时将根据Key将消息聚合,只保留最后一次出现时的数据。这样,无论什么时候消费消息,都能拿到每个Key的最新版本的数据。
压缩后的offset可能是不连续的,比如上图中没有5和7,因为这些offset的消息被merge了,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,比如,当试图获取offset为5的消息时,实际上会拿到offset为6的消息,并从这个位置开始消费。
这种策略只适合特俗场景,比如消息的key是用户ID,消息体是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
压缩策略支持删除,当某个Key的最新版本的消息没有内容时,这个Key将被删除,这也符合以上逻辑。
Kafka Topic创建三步曲
大数据 空心菜 发表了文章 0 个评论 2182 次浏览 2020-09-19 15:22
通常在生产环境新增业务主题,我们都需要提前预测到,然后做好充分的准备,本文将介绍在生产环境中创建Topic时需要考虑的所有参数。
首先创建新Topic的时候,我们需要设置合理的分区数和副本数,不合理的设置将会给系统的性能和可靠性带来影响。
创建一个Topic
kafka/bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 2 \
--partitions 3 \
--topic unique-topic-name
分区(Partitions)
Kafka主题分为多个分区,其中包含以不变顺序排列的消息。分区中的每个消息均通过其唯一偏移量进行分配和标识。
分区使我们可以在多个Broker之间分配主题数据,从而平衡Broker之间的负载。每个分区只能由一个Consumer Group使用,因此,服务的并行性受Topic拥有的分区数约束。
分区数受两个主要因素的影响,即消息数和每条消息的平均大小。如果交易量很大,您将需要使用代理数量作为乘法倍数,以允许在所有使用者上共享负载,并避免创建热分区,该分区会对特定代理造成高负载。我们的目标是使分区吞吐量达到1MB/s。
设置分区数:
--partitions [number]
副本(Replicas)
如果leader分区发生故障并且需要跟随者(follower)副本替换它并成为领导者(leader),则Kafka可以选择复制Topic分区。在配置Topic时,请记住,分区是为实现快速读写速度,可伸缩性和分发大量数据而设计的。
另一方面,复制因子(RF)旨在确保指定的容错目标。副本不会直接影响性能,因为在任何给定时间,只有一个(leader)领导者分区负责通过Broker服务器处理生产者和使用者请求。
在决定复制因子时的另一个考虑因素是,为了满足生产容量会话,需要考虑服务需要的消费者数量。
设置复制因子(RF):
如果你的Topic承载的是关键业务,推荐你设置复制因子为3,其他的设置为2就够了。
--replication-factor [number]
Tips: 但这里需要注意一点的是, RF <= Broker Number
保留(Retention)
将消息保留在Topic中的时间或最大Topic大小。根据你的用例确定。默认情况下,保留期限为7天,但这是可配置的。
设置Retention:
--config retention.ms=[number]
压缩(Compaction)
为了释放空间并清理不需要的记录,Kafka压缩可以根据记录的日期和大小删除记录。它还可以删除具有相同键的每个记录,同时保留该记录的最新版本。基于键的压缩对于控制Topic的大小非常有用,其中只有最新的记录版本才是重要的。
启用压缩:
log.cleanup.policy=compact
分享阅读原文: http://suo.im/5W8p1p
Kafka日志设置和清除策略
大数据 push 发表了文章 0 个评论 19442 次浏览 2017-04-15 16:00
一、日志设置
1、修改日志级别
config/log4j.properties中日志的级别设置的是TRACE,在长时间运行过程中产生的日志大小吓人,所以如果没有特殊需求,强烈建议将其更改成INFO级别。具体修改方法如下所示,将config/log4j.properties文件中最后的几行中的TRACE改成INFO,修改前如下所示:
log4j.logger.kafka.network.RequestChannel$=TRACE, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=TRACE, requestAppender
#log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=TRACE, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=TRACE, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.state.change.logger=TRACE, stateChangeAppender
log4j.additivity.state.change.logger=false
修改后如下所示:
log4j.logger.kafka.network.RequestChannel$=INFO, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=INFO, requestAppender
#log4j.logger.kafka.server.KafkaApis=INFO, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=INFO, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=INFO, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.state.change.logger=INFO, stateChangeAppender
log4j.additivity.state.change.logger=false
2、修改日志存放位置
还有就是默认Kafka运行的时候都会通过log4j打印很多日志文件,比如server.log, controller.log, state-change.log等,而都会将其输出到$KAFKA_HOME/logs目录下,这样很不利于线上运维,因为经常容易出现打爆文件系统,一般安装的盘都比较小,而数据和日志会指定打到另一个或多个更大空间的分区盘
具体方法是,打开$KAFKA_HOME/bin/kafka-run-class.sh,找到下面标示的位置,并定义一个变量,指定的值为系统日志输出路径,重启broker即可生效。
二、日志清理和策略
1、利用Kafka日志管理器
Kafka日志管理器允许定制删除策略。目前的策略是删除修改时间在N天之前的日志(按时间删除),也可以使用另外一个策略:保留最后的N GB数据的策略(按大小删除)。为了避免在删除时阻塞读操作,采用了copy-on-write形式的实现,删除操作进行时,读取操作的二分查找功能实际是在一个静态的快照副本上进行的,这类似于Java的CopyOnWriteArrayList。
Kafka消费日志删除思想:Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用
log.cleanup.policy=delete启用删除策略
直接删除,删除后的消息不可恢复。可配置以下两个策略:
清理超过指定时间清理:
log.retention.hours=16
超过指定大小后,删除旧的消息:
log.retention.bytes=1073741824
2、压缩策略
将数据压缩,只保留每个key最后一个版本的数据。首先在broker的配置中设置log.cleaner.enable=true启用cleaner,这个默认是关闭的。在Topic的配置中设置log.cleanup.policy=compact启用压缩策略。
压缩策略的细节如下:
如上图,在整个数据流中,每个Key都有可能出现多次,压缩时将根据Key将消息聚合,只保留最后一次出现时的数据。这样,无论什么时候消费消息,都能拿到每个Key的最新版本的数据。
压缩后的offset可能是不连续的,比如上图中没有5和7,因为这些offset的消息被merge了,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,比如,当试图获取offset为5的消息时,实际上会拿到offset为6的消息,并从这个位置开始消费。
这种策略只适合特俗场景,比如消息的key是用户ID,消息体是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
压缩策略支持删除,当某个Key的最新版本的消息没有内容时,这个Key将被删除,这也符合以上逻辑。
如何为Kafka集群选择合适的主题和分区数量
大数据 Ansible 发表了文章 0 个评论 5174 次浏览 2016-12-26 00:03

这是许多Kafka用户提出的常见问题。 这篇文章的目的是解释几个重要的决定因素,并提供一些简单的公式。
更多的分区提供更高的吞吐量
首先要理解的是,主题分区是Kafka中并行性的单位。 在生产者和代理端,对不同分区的写入可以完全并行完成。 因此,昂贵的操作(例如压缩)可以利用更多的硬件资源。 在消费者方面,Kafka总是将一个分区的数据提供给一个消费者线程。 因此,消费者(在消费者组内)的并行度受所消耗的分区的数量的限制。 因此,一般来说,Kafka集群中的分区越多,吞吐量就越高。
用于选择分区数量的粗略公式基于吞吐量。 你衡量整个,你可以在生产单个分区(称之为P)和消费实现(称为C)。 比方说,你的目标吞吐量吨 。 然后,你需要至少有MAX(T / P,T / C)分区。 人们可以在生产者上实现的每分区吞吐量取决于诸如批处理大小,压缩编解码器,确认类型,复制因子等等的配置。然而,一般来说,可以在10秒的MB /如在此所示单个分区的基准 。 消费者吞吐量通常是与应用相关的,因为它对应于消费者逻辑可以如何快速地处理每个消息。 所以,你真的需要测量它。
虽然可以随着时间增加分区的数量,但是如果使用密钥生成消息,则必须小心。 当发布带密钥的消息时,Kafka基于密钥的散列将消息确定性地映射到分区。 这提供了保证具有相同密钥的消息总是路由到同一分区。 此保证对于某些应用可能是重要的,因为分区内的消息总是按顺序递送给消费者。 如果分区的数量改变,则这样的保证可能不再保持。 为了避免这种情况,一种常见的做法是过度分区。 基本上,您可以根据未来的目标吞吐量确定分区数,比如一两年后。 最初,您可以根据您的当前吞吐量只有一个小的Kafka集群。 随着时间的推移,您可以向集群添加更多代理,并按比例将现有分区的一部分移动到新代理(可以在线完成)。 这样,当使用密钥时,您可以跟上吞吐量增长,而不会破坏应用程序中的语义。
除了吞吐量,还有一些其他因素,在选择分区数时值得考虑。 正如你将看到的,在某些情况下,分区太多也可能产生负面影响。
更多分区需要打开更多的文件句柄
每个分区映射到broker中文件系统中的目录。 在该日志目录中,每个日志段将有两个文件(一个用于索引,另一个用于实际数据)。 目前,在Kafka中,每个broker打开每个日志段的索引和数据文件的文件句柄。 因此,分区越多,底层操作系统中需要配置打开文件句柄限制的分区越多。 这大多只是一个配置问题。 我们已经看到生产Kafka集群中,运行的每个broker打开的文件句柄数超过30000。
更多分区可能是不可用性增加
Kafka支持群集内复制 ,它提供更高的可用性和耐用性。 分区可以有多个副本,每个副本存储在不同的代理上。 其中一个副本被指定为领导者,其余的副本是追随者。 在内部,Kafka自动管理所有这些副本,并确保它们保持同步。 生产者和消费者对分区的请求都在领导副本上提供。 当代理失败时,该代理上具有leader的分区变得暂时不可用。 Kafka将自动将那些不可用分区的领导者移动到其他一些副本以继续服务客户端请求。 这个过程由指定为控制器的Kafka代理之一完成。 它涉及在ZooKeeper中为每个受影响的分区读取和写入一些元数据。 目前,ZooKeeper的操作是在控制器中串行完成的。
在通常情况下,当代理被干净地关闭时,控制器将主动地将领导者一次一个地关闭关闭代理。 单个领导者的移动只需要几毫秒。 因此,从客户的角度来看,在干净的代理关闭期间只有一小窗口的不可用性。
然而,当代理不干净地关闭(例如,kill -9)时,所观察到的不可用性可能与分区的数量成比例。 假设代理具有总共2000个分区,每个具有2个副本。 大致来说,这个代理将是大约1000个分区的领导者。 当这个代理不干净失败时,所有这1000个分区完全不能同时使用。 假设为单个分区选择新的领导需要5毫秒。 对于所有1000个分区,选择新的领导将需要5秒钟。 因此,对于一些分区,它们的观察到的不可用性可以是5秒加上检测故障所花费的时间。
如果一个是不幸的,失败的代理可能是控制器。 在这种情况下,选举新领导者的过程将不会开始,直到控制器故障转移到新的代理。 控制器故障转移自动发生,但需要新控制器在初始化期间从ZooKeeper读取每个分区的一些元数据。 例如,如果Kafka集群中有10,000个分区,并且从ZooKeeper初始化元数据每个分区需要2ms,则可以向不可用性窗口添加20多秒。
一般来说,不洁的故障是罕见的。 但是,如果在这种极少数情况下关心可用性,则可能最好将每个代理的分区数限制为两个到四千个,集群中的分区总数限制到几万个。
更多分区可能会增加端到端延迟
Kafka中的端到端延迟由从生产者发布消息到消费者读取消息的时间来定义。 Kafka仅在提交后向消费者公开消息,即,当消息被复制到所有同步副本时。 因此,提交消息的时间可以是端到端等待时间的显着部分。 默认情况下,对于在两个代理之间共享副本的所有分区,Kafka代理仅使用单个线程从另一个代理复制数据。 我们的实验表明,将1000个分区从一个代理复制到另一个代理可以添加大约20毫秒的延迟,这意味着端到端延迟至少为20毫秒。 这对于一些实时应用来说可能太高。
请注意,此问题在较大的群集上减轻。 例如,假设代理上有1000个分区引导,并且在同一个Kafka集群中有10个其他代理。 剩余的10个代理中的每个仅需要从第一代理平均获取100个分区。 因此,由于提交消息而增加的延迟将仅为几毫秒,而不是几十毫秒。
作为一个经验法则,如果你关心的延迟,它可能是一个好主意,每个经纪人的分区数量限制为100 * b * r,其中b是经纪人在kafka集群的数量和r是复制因子。
更多分区可能需要更多的内存在客户端
在最新的0.8.2版本,我们汇合到我们平台1.0,我们已经开发出一种更有效的Java生产商。 新生产者的一个好的功能是它允许用户设置用于缓冲传入消息的内存量的上限。 在内部,生产者缓冲每个分区的消息。 在累积了足够的数据或已经过去足够的时间之后,累积的消息从缓冲器中移除并发送到代理。
如果增加分区的数量,消息将在生产者中的更多分区中累积。 所使用的内存总量现在可能超过配置的内存限制。 当这种情况发生时,生产者必须阻止或丢弃任何新的消息,这两者都不是理想的。 为了防止这种情况发生,需要重新配置具有较大内存大小的生产者。
作为经验法则,为了实现良好的吞吐量,应该在生成器中分配至少几十KB的每个分区,并且如果分区的数量显着增加,则调整存储器的总量。
消费者也存在类似的问题。 消费者每个分区获取一批消息。 消费者消耗的分区越多,需要的内存就越多。 然而,这通常只是不是实时的消费者的问题。
总结
通常,Kafka集群中的更多分区导致更高的吞吐量。 然而,人们不得不意识到在总体上或每个代理中具有过多分区对可用性和等待时间的潜在影响。 在未来,我们计划改进一些限制,使Kafka在分区数方面更具可扩展性。
翻译原文:https://www.confluent.io/blog/how-to-choose-the-number-of-topicspartitions-in-a-kafka-cluster/
作者:饶俊
Kafka topic 常用命令介绍
大数据 空心菜 发表了文章 0 个评论 4380 次浏览 2016-10-26 22:47

本文主要记录平时kafka topic命令常使用的命令集,包括listTopic,createTopic,deleteTopic和describeTopic和alertTopic等,我这里是基于kafka 0.8.1.1版本,具体情况如下所示。
一、 describe topic 显示topic详细信息
# ./kafka-topics.sh --describe --zookeeper localhost:21811. 如上面可见,如果指定了--topic就是只显示给定topic的信息,否则显示所有topic的详细信息。
Topic:mobTopic PartitionCount:4 ReplicationFactor:1 Configs:
Topic: mobTopic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: mobTopic Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: mobTopic Partition: 2 Leader: 2 Replicas: 2 Isr: 2
Topic: mobTopic Partition: 3 Leader: 0 Replicas: 0 Isr: 0
Topic:serverTopic PartitionCount:4 ReplicationFactor:1 Configs:
Topic: serverTopic Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: serverjsTopic Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: serverjsTopic Partition: 2 Leader: 1 Replicas: 1 Isr: 1
Topic: serverjsTopic Partition: 3 Leader: 2 Replicas: 2 Isr: 2
Topic:bugTopic PartitionCount:4 ReplicationFactor:1 Configs:
Topic: bugTopic Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: bugTopic Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: bugTopic Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: bugTopic Partition: 3 Leader: 1 Replicas: 1 Isr: 1
2. 如果指定了under-replicated-partitions,那么就显示那些副本数量不足的分区(ISR size < AR.size)
3. 如果指定了unavailable-partitions,那么就显示那些leader副本已不可用的分区
4. 从zookeeper上获取当前所有可用的broker
5. 遍历每个要describe的topic,
6. 获取这个topic的分区副本分配信息,若该信息不存在说明topic不存在
7. 否则将分配信息按照分区号进行排序
10. 如果没有指定步骤2中的参数也没有指定步骤3中的参数,那么显示分区数信息、副本系数信息以及配置信息
11. 默认情况下还会显示各个分区的信息
12. 从zookeeper中获取每个分区的ISR、Leader、AR信息并显示
二、create topic 创建topic
# kafka-topics.sh --zookeeper localhost:2181 --create --topic mobTopic --replication-factor 1 --partitions 4
- 从命令行中获取要创建的topic名称
- 解析命令行指定的topic配置(如果存在的话),配置都是x=a的格式
- 若指定了replica-assignment参数表明用户想要自己分配分区副本与broker的映射——通常都不这么做,如果不提供该参数Kafka帮你做这件事情
- 检查必要的参数是否已指定,包括:zookeeper, replication-factor,partition和topic
- 获取/brokers/ids下所有broker并按照broker id进行升序排序
- 在broker上分配各个分区的副本映射 (没有指定replica-assignment参数,这也是默认的情况)
- 检查topic名字合法性、自定义配置的合法性,并且要保证每个分区都必须有相同的副本数
- 若zookeeper上已有对应的路径存在,直接抛出异常表示该topic已经存在
- 确保某个分区的多个副本不会被分配到同一个broker
- 若提供了自定义的配置,更新zookeeper的/config/topics/[topic]节点的数据
- 创建/brokers/topics/[topic]节点,并将分区副本分配映射数据写入该节点
三、delete topic 删除topic
# ./kafka-topics.sh --zookeeper locahost:2181 --delete --topic mobTopic
- 获取待删除的topic,如果没有指定--topic就是删除所有的topic
- 对于每个要删除的topic,在zookeeper上的/admin/delete_topics下创建对应的子节点。kafka目前的删除topic逻辑只是在Zookeeper上标记而已,会有专门的线程负责监听该路径下的变更并负责更新zookeeper上其他节点上的数据,但底层的日志文件目前还是需要手动删除。
四、alert 修改topic的partion
# ./kafka-topics.sh --zookeeper localhost:2181 --alter --topic mobTopic --partitions 10减少目前kakfa应该是不支持.
Kafka性能测试
大数据 chris 发表了文章 0 个评论 11757 次浏览 2016-10-13 23:24

测试背景
Apache Kafka是一种高吞吐、可扩展的分布式消息队列服务,它最初由LinkedIn公司开发,最后发展为Apache基金会的一个项目。目前kafka已经广泛应用于大数据分析,消息处理等环境,官方文档介绍kafka为提高吞吐率做了很多设计,但是其性能究竟如何呢?本文对kafka在不同参数下的性能进行测试。
测试目标
测试kafka 0.8n的性能(Producer/Consumer性能)。当消息大小、批处理大小、压缩等参数变化时对吞吐率的影响。
测试环境
软件版本:kafka 0.8.1.1
硬件环境:3台多磁盘服务组成的kafka集群。各服务器CPU E5645,内存47G,12快SAS盘,配置千兆网卡,配置如下:

测试方法
使用kafka官方提供的kafa-perf工具做性能测试,在测试时使用ganglia,kafka Web Console来记录服务情况。
测试步骤
一、测试环境准备
1、测试工具kafka-perf编译
kafka官方提供的二进制版本,并不包括性能测试的jar包,会报错找不到ProducerPerformance,要自己重新编译,编译方法如下:
git clone https://git-wip-us.apache.org/repos/asf/kafka.git kafka.git
cd kafka.git/
git checkout -b 0.8.1 origin/0.8.1
vim build.gradle #编辑配置
./gradlew -PscalaVersion=2.10.4 perf:jar #生成2.10.4的kafka-perf的jar包,复制到libs目录下
cp perf/build/libs/kafka-perf_2.10-0.8.1.1-SNAPSHOT.jar /usr/local/kafka/libs/
2、启动kafka
cd /usr/local/kafka
vim config/server.properties #内容见下图
./bin/kafka-server-start.sh config/server.properties &

kafka-producer-perf-test.sh中参数说明:
messages 生产者发送走的消息数量bin/kafka-consumer-perf-test.sh中参数说明:
message-size 每条消息的大小
batch-size 每次批量发送消息的数量
topics 生产者发送的topic
threads 生产者
broker-list 安装kafka服务的机器ip:porta列表
producer-num-retries 一个消息失败发送重试次数
request-timeouts-ms 一个消息请求发送超时时间
zookeeper zk配置
messages 消费者消费消息的总数量
topic 消费者需要消费的topic
threads 消费者使用几个线程同时消费
group 消费者组名称
socket-buffer-sizes socket缓存大小
fetch-size 每次想kafka broker请求消费消息大小
consumer.timeout.ms 消费者去kafka broker拿一条消息的超时时间
二、测试生产者吞吐率
此项只测试producer在不同的batch-zie,patition等参数下的吞吐率,也就是数据只被及计划,没有consumer读取数据消费情况。
生成Topic:
生成不同复制因子,partition的topic
bin/kafka-topics.sh --zookeepr 10.x.x.x:2181/kafka/k1001 --create --topic test-pati1-rep1 --partitions 1 --replication-factor 1测试producer吞吐率
bin/kafka-topics.sh --zookeepr 10.x.x.x:2181/kafka/k1001 --create --topic test-pati1-rep2 --partitions 1 --replication-factor 2
bin/kafka-topics.sh --zookeepr 10.x.x.x:2181/kafka/k1001 --create --topic test-pati10-rep1 --partitions 10 --replication-factor 1
bin/kafka-topics.sh --zookeepr 10.x.x.x:2181/kafka/k1001 --create --topic test-pati10-rep2 --partitions 10 --replication-factor 2
bin/kafka-topics.sh --zookeepr 10.x.x.x:2181/kafka/k1001 --create --topic test-pati100-rep1 --partitions 100 --replication-factor 1
bin/kafka-topics.sh --zookeepr 10.x.x.x:2181/kafka/k1001 --create --topic test-pati100-rep2 --partitions 100 --replication-factor 2
调整batch-size,thread,topic,压缩等参数测试producer吞吐率。
示例:
a)批处理为1,线程数为1,partition为1,复制因子为1说明:消息大小统一使用和业务场景中日志大小相近的512Bype,消息数为50w或200w条。
bin/kafka-producer-perf-test.sh --messages 2000000 --message-size 512 --batch-size 1 --topic test-pati1-rep1
--partitions 1 --threads 1 --broker-list host1:9092,host2:9092,host3:9092
b)批处理为10,线程数为1,partition为1,复制因子为2
bin/kafka-producer-perf-test.sh --messages 2000000 --message-size 512 --batch-size 10 --topic test-pati1-rep2
--partitions 1 --threads 1 --broker-list host1:9092,host2:9092,host3:9092
c)批处理为100,线程数为10,partition为10,复制因子为2,不压缩,sync
bin/kafka-producer-perf-test.sh --messages 2000000 --message-size 512 --batch-size 100 --topic test-pati10-rep2 --partitions 10 --threads 10 --compression-codec 0 --sync 1 --broker-list host1:9092,host2:9092,host3:9092
d)批处理为100,线程数为10,partition为10,复制因子为2,gzip压缩,sync
bin/kafka-producer-perf-test.sh --messages 2000000 --message-size 512 --batch-size 100 --topic test-pati10-rep2 --partitions 10 --threads 10 --compression-codec 1 --sync 1 --broker-list host1:9092,host2:9092,host3:9092
三、测试消费者吞吐率
测试consumer吞吐率
调整批处理数,线程数,partition数,复制因子,压缩等进行测试。
示例:
a)批处理为10,线程数为10,partition为1,复制因子为1
./bin/kafka-consumer-perf-test.sh --messages 500000 --batch-size 10 --topic test-pai1-rep2 --partitions 1 --threads 10 --zookeeper zkhost:2181/kafka/k1001
b)批处理为10,线程数为10,partition为10,复制因子为2
./bin/kafka-consumer-perf-test.sh --messages 500000 --batch-size 10 --topic test-pai1-rep2 --partitions 10 --threads 10 --zookeeper zkhost:2181/kafka/k1001
c)批处理为100,线程数为10,partition为1,复制因子为1,不压缩
./bin/kafka-consumer-perf-test.sh --messages 500000 --batch-size 100 --topic test-pai100-rep1 --partitions 1 --threads 10 --compression-codec 0 --zookeeper zkhost:2181/kafka/k1001
d)批处理为100,线程数为10,partition为1,复制因子为1,Snappy压缩
./bin/kafka-consumer-perf-test.sh --messages 500000 --batch-size 100 --topic test-pai100-rep1 --partitions 1 --threads 10 --compression-codec 2 --zookeeper zkhost:2181/kafka/k1001
测试结果及分析
1、生产者测试结果及分析
调整线程数,批处理数,复制因子等参考,对producer吞吐率进行测试。在测试时消息大小为512Byte,消息数为200w,结果如下:



调整sync模式,压缩方式得到吞吐率数据如表3.在本次测试中msg=512Byte,message=2000000,Partition=10,batch_zie=100


结果分析:
1)kafka在批处理,多线程,不适用同步复制的情况下,吞吐率是比较高的,可以达80MB/s,消息数达17w条/s以上。
2)使用批处理或多线程对提升生产者吞吐率效果明显。

3)复制因子会对吞吐率产生较明显影响
使用同步复制时,复制因子会对吞吐率产生较明显的影响。复制因子为2比因子为1(即无复制)时,吞吐率下降40%左右。

4)使用sync方式,性能有明显下降。
使用Sync方式producer吞吐率会有明显下降,表3中async方式最大吞吐率由82.0MB/s,而使用sync方式时吞吐率只有13.33MB/s.

5)压缩与吞吐率
见图3,粉笔使用Gzip及Snappy方式压缩,吞吐率反而有下降,原因待分析。而Snappy方式吞吐率高于gzip方式。
6)分区数与吞吐率
分区数增加生产者吞吐率反而有所下降
2、消费者结果及分析
调整批处理数,分区数,复制因子等参数,对consumer吞吐率进行测试。在测试时消息大小为512Byte,消息数为200结果如下:


调整压缩方式,分区数,批处理数等,测试参数变化时consumer的吞吐率。测试的复制因子为1。


结果分析:1)kafka consumer吞吐率在parition,threads较大的情况下,在测试场景下,最大吞吐率达到了123MB/s,消息数为25w条/s
2)复制因子,影响较小。replication factor并不会影响consumer的吞吐率测试,运维consumer智慧从每个partition的leader读数据,而与replication factor无关。同样,consumer吞吐率也与同步复制还是异步复制无关。

3)线程数和partition与吞吐率关系

图5为msg_size=512,batch_zie=100时的测试数据备份。可以看到当分区数较大时,如partion为100时,增加thread数可显著提升consumer的吞吐率。Thread10较thread1提升了10倍左右,而thread为100时叫thread为1提升了近20倍,达到120MB/s.
但要注意在分区较大时线程数不改大于分区数,否则会出现No broker partitions consumed by consumer,对提升吞吐率也没有帮助。图5中partion为10时,thread_10,thread_100吞吐率相近都为35MB/s左右。
4)批处理数对吞吐率影响
图表5中可以看出改变批处理数对吞吐率影响不大
5)压缩与吞吐率

图表6当thread=10,复制因子=1不压缩,Gzip,Snappy时不同parititon时Concumser吞吐率。由上图可以看到此场景下,压缩对吞吐率影响小。
Kafka集群中如何平衡Topics
大数据 空心菜 发表了文章 3 个评论 11648 次浏览 2016-09-12 14:55
为什么我们需要平衡Topic
当一个kafka集群中一个节点关闭或者宕机,该服务器的负载任务将分配到集群中的其他节点,这种分配是不均匀的;即负载不是均匀的分布在集群中所有节点,我们需要做一些措施来实现这一平衡(也称为再平衡)。
再平衡我们需要注意两件事情。一是leader连任,或首选副本选举,另一种是分区的再平衡。多数情况下,一个节点宕机,然后过段时间又重新加入集群,第二种情况就是,当我们想要么减少或增加集群中节点的数目。 让我们来看看如何处理这些不同的场景平衡Topic的情况。
我下面的案例以5个broker的kafka集群为例。
案例1:当broker因为维护或由于服务器故障而关闭,并在一定的时间恢复
有两种方法来处理这种情况。 一种是添加以下行到代理配置“auto.leader.rebalance.enable”自动重新平衡,但这个报告是个问题 。 另一种方法是手动使用“kafka-preferred-replica-election.sh”的工具。
编辑配置文件server.properties配置文件,添加auto.leader.rebalance.enable = false

我们让broker4宕机,然后看看topic负载如何分布

在这里我们可以看到负载不均匀分布,接下来我们在恢复broker4看看。

现在,我们可以看到,即使broker4已经恢复到集群中服务了,但是它不是作为一个领导者作用于任何分区。那让我们使用kafka-preferred-replica-election.sh工具来平衡负载试试。


现在我们可以看到topic分布是平衡的。
案例2:一个节点宕机且无法恢复
我们创建了一个新的broker,即使设置其borker.id为以前的broker的ID,那也是不能恢复的,只能手动运行kafka-preferred-replica-election.sh是topic平衡。
案例3:增加或者减少kafka集群中节点数量
增加或者删除节点,平衡topic步骤如下:
- 使用分区重新分配的工具(kafka-reassign-partition.sh),使用--generta参数生成一个推荐配置,这显示了当前和建议的副本分配情况;
- 复制推荐分配配置方案到jason文件中;
- 执行分区重新分配工具(kafka-reassign-partition.sh -execute)来更新元数据平衡。 确保运行的时候集群中节点负载问题,因为这个过程是在不同节点间发生数据移动;
- 等待一段时间(基于必须移动一定量的数据),并使用--verify选项验证平衡成功完成
- 一旦分区重新分配完成后,运行“kafka-preferred-replica-election.sh”工具来完成平衡。
在这里我们假设为减少kafka集群中的节点数(这里为介绍broker5),当节点终止后,我们使用使用分区重新分配工具,生成一份当前和建议的副本任务作为JSONs候选人分配的配置。

把建议重新分配配置复制到一个JSON文件并执行分区重新分配的工具。 这将更新元数据,然后开始四处移动数据来平衡负载。


接下来我们验证重新平衡/重新分配是否成功:

一旦重新分配所有分区是成功的,我们运行的首选副本竞选工具来平衡的主题,然后运行“描述主题”来检查主题平衡。


现在我们可以看到topic(以及leaders和replicas)都是平衡的。
英文原文:https://blog.imaginea.com/how-to-rebalance-topics-in-kafka-cluster/
Kafka入门简介
大数据 chris 发表了文章 2 个评论 3613 次浏览 2016-09-02 15:01
Kafka背景
Kafka它本质上是一个消息系统,由当时从LinkedIn出来创业的三人小组开发,他们开发出了Apache Kafka实时信息队列技术,该技术致力于为各行各业的公司提供实时数据处理服务解决方案。Kafka为LinkedIn的中枢神经系统,管理从各个应用程序的汇聚,这些数据经过处理后再被分发到其他地方。Kafka不同于传统的企业信息队列系统,它是以近乎实时的方式处理流经一个公司的所有数据,目前已经服务于LinkedIn、Netflix、Uber以及Verizon,并为此建立了实时信息处理平台。
流水数据是所有站点对其网站使用情况做报表时都要用到的数据中最常用的一部分,流水数据包括PV,浏览内容信息以及搜索记录等。这些数据通常是先以日志文件的形式存在,然后有周期的去对这些日志文件进行统计分析处理,然后获得需要的KPI指标结果。
Kafka应用场景
我们在接触一门新技术或是新语言时,得明白这门技术(或是语言)的应用场景,也就说要明白它能做什么,服务的对象是谁,下面用一个图来说明,如下图所示:

首先,Kafka可以应用于消息系统,比如,当下较为热门的消息推送,这些消息推送系统的消息源,可以使用Kafka作为系统的核心组建来完成消息的生产和消息的消费。然后是网站的行迹,我们可以将企业的Portal,用户的操作记录等信息发送到Kafka中,按照实际业务需求,可以进行实时监控,或者做离线处理等。最后,一个是日志收集,类似于Flume套件这样的日志收集系统,但Kafka的设计架构采用push/pull,适合异构集群,Kafka可以批量提交消息,对Producer来说,在性能方面基本上是无消耗的,而在Consumer端中,我们可以使用HDFS这类的分布式文件存储系统进行存储。
Kafka架构原理
Kafka的设计之初是希望做一个统一的信息收集平台,能够实时的收集反馈信息,并且具有良好的容错能力。Kafka中我们最直观的感受就是它的消费者与生产者,如下图所示:
Producer And Consumer:

这里Kafka对消息的保存是根据Topic进行归类的,由消息生产者(Producer)和消息消费者(Consumer)组成,另外,每一个Server称为一个Broker。对于Kafka集群而言,Producer和Consumer都依赖于ZooKeeper来保证数据的一致性。
Topic:
在每条消息输送到Kafka集群后,消息都会由一个Type,这个Type被称为一个Topic,不同的Topic的消息是分开存储的。如下图所示:

一个Topic会被归类为一则消息,每个Topic可以被分割为多个Partition,在每条消息中,它在文件中的位置称为Offset,用于标记唯一一条消息。在Kafka中,消息被消费后,消息仍然会被保留一定时间后在删除,比如在配置信息中,文件信息保留7天,那么7天后,不管Kafka中的消息是否被消费,都会被删除;以此来释放磁盘空间,减少磁盘的IO消耗。
在Kafka中,一个Topic的多个分区,被分布在Kafka集群的多个Server上,每个Server负责分区中消息的读写操作。另外,Kafka还可以配置分区需要备份的个数,以便提高可用行。由于用到来ZK来协调,每个分区都有一个Server为Leader状态,服务对外响应(如读写操作),若该Leader宕机,会由其他的Follower来选举出新的Leader来保证集群的高可用性。
总结
kafka是一个非常强悍的消息队列系统,他支持持久化和数据偏移,从而实现多个消费者同时消费一份数据是没有问题的。简单的来说他就是一个生产者消费模型的架构,居于zookeeper来管理每个Topic的信息记录和偏移量,从而达到高效和多复用的概念,消息不会消失,除非过期。
Kafka consumer处理大消息数据问题分析
大数据 空心菜 发表了文章 0 个评论 11558 次浏览 2016-07-22 22:34
案例分析
今天在处理kafka consumer的程序的时候,发现如下错误:
ERROR [2016-07-22 07:16:02,466] com.flow.kafka.consumer.main.KafkaConsumer: Unexpected Error Occurred如上log可以看出,问题就是有一个较大的消息数据在codeTopic的partition 3上,然后consumer未能消费,提示我可以减小broker允许进入的消息数据的大小,或者增大consumer程序消费数据的大小。
! kafka.common.MessageSizeTooLargeException: Found a message larger than the maximum fetch size of this consumer on topic codeTopic partition 3 at fetch offset 94. Increase the fetch size, or decrease the maximum message size the broker will allow.
! at kafka.consumer.ConsumerIterator.makeNext(ConsumerIterator.scala:91) ~[pip-kafka-consumer.jar:na]
! at kafka.consumer.ConsumerIterator.makeNext(ConsumerIterator.scala:33) ~[pip-kafka-consumer.jar:na]
! at kafka.utils.IteratorTemplate.maybeComputeNext(IteratorTemplate.scala:66) ~[pip-kafka-consumer.jar:na]
! at kafka.utils.IteratorTemplate.hasNext(IteratorTemplate.scala:58) ~[pip-kafka-consumer.jar:na]
! at com.flow.kafka.consumer.main.KafkaConsumer$KafkaRiverFetcher.run(KafkaConsumer.java:291) ~[original-pip-kafka-consumer.jar:na]
! at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) [na:1.7.0_51]
! at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) [na:1.7.0_51]
! at java.lang.Thread.run(Thread.java:744) [na:1.7.0_51]
从log上来看一目了然,如果要解决当前问题的话,1、减小broker消息体大小(设置message.max.bytes
参数)。;2、增大consumer获取数据信息大小(设置fetch.message.max.bytes参数)。默认broker消息体大小为1000000字节即为1M大小。
消费者方面:fetch.message.max.bytes——>这将决定消费者可以获取的数据大小。
broker方面:replica.fetch.max.bytes——>这将允许broker的副本发送消息在集群并确保消息被正确地复制。如果这是太小,则消息不会被复制,因此,消费者永远不会看到的消息,因为消息永远不会承诺(完全复制)。
broker方面:message.max.bytes——>可以接受数据生产者最大消息数据大小。
由我的场景来看较大的消息体已经进入到了kafka,我这里要解决这个问题,只需要增加consumer的fetch.message.max.bytes数值就好。我单独把那条数据消费出来,写到一个文件中发现那条消息大小为1.5M左右,为了避免再次发生这种问题我把consumer程序的fetch.message.max.bytes参数调节为了3072000即为3M,重启consumer程序,查看log一切正常,解决这个消费错误到此结束,下面介绍一下kafka针对大数据处理的思考。
kafka的设计初衷
Kafka设计的初衷是迅速处理小量的消息,一般10K大小的消息吞吐性能最好(可参见LinkedIn的kafka性能测试)。但有时候,我们需要处理更大的消息,比如XML文档或JSON内容,一个消息差不多有10-100M,这种情况下,Kakfa应该如何处理?
针对这个问题,可以参考如下建议:
- [] 最好的方法是不直接传送这些大的数据。如果有共享存储,如NAS, HDFS, S3等,可以把这些大的文件存放到共享存储,然后使用Kafka来传送文件的位置信息。[/][] 第二个方法是,将大的消息数据切片或切块,在生产端将数据切片为10K大小,使用分区主键确保一个大消息的所有部分会被发送到同一个kafka分区(这样每一部分的拆分顺序得以保留),如此以来,当消费端使用时会将这些部分重新还原为原始的消息。[/][] 第三,Kafka的生产端可以压缩消息,如果原始消息是XML,当通过压缩之后,消息可能会变得不那么大。在生产端的配置参数中使用compression.codec和commpressed.topics可以开启压缩功能,压缩算法可以使用GZip或Snappy。[/]
不过如果上述方法都不是你需要的,而你最终还是希望传送大的消息,那么,则可以在kafka中设置下面一些参数:
broker 配置:
- []message.max.bytes (默认:1000000) – broker能接收消息的最大字节数,这个值应该比消费端的fetch.message.max.bytes更小才对,否则broker就会因为消费端无法使用这个消息而挂起。[/][]log.segment.bytes (默认: 1GB) – kafka数据文件的大小,确保这个数值大于一个消息的长度。一般说来使用默认值即可(一般一个消息很难大于1G,因为这是一个消息系统,而不是文件系统)。[/][]replica.fetch.max.bytes (默认: 1MB) – broker可复制的消息的最大字节数。这个值应该比message.max.bytes大,否则broker会接收此消息,但无法将此消息复制出去,从而造成数据丢失。[/]
- []fetch.message.max.bytes (默认 1MB) – 消费者能读取的最大消息。这个值应该大于或等于message.max.bytes。所以,如果你一定要选择kafka来传送大的消息,还有些事项需要考虑。要传送大的消息,不是当出现问题之后再来考虑如何解决,而是在一开始设计的时候,就要考虑到大消息对集群和主题的影响。[/][]性能: 根据前面提到的性能测试,kafka在消息为10K时吞吐量达到最大,更大的消息会降低吞吐量,在设计集群的容量时,尤其要考虑这点。[/][]可用的内存和分区数:Brokers会为每个分区分配replica.fetch.max.bytes参数指定的内存空间,假设replica.fetch.max.bytes=1M,且有1000个分区,则需要差不多1G的内存,确保 分区数最大的消息不会超过服务器的内存,否则会报OOM错误。同样地,消费端的fetch.message.max.bytes指定了最大消息需要的内存空间,同样,分区数最大需要内存空间 不能超过服务器的内存。所以,如果你有大的消息要传送,则在内存一定的情况下,只能使用较少的分区数或者使用更大内存的服务器。[/][]垃圾回收:到现在为止,我在kafka的使用中还没发现过此问题,但这应该是一个需要考虑的潜在问题。更大的消息会让GC的时间更长(因为broker需要分配更大的块),随时关注GC的日志和服务器的日志信息。如果长时间的GC导致kafka丢失了zookeeper的会话,则需要配置zookeeper.session.timeout.ms参数为更大的超时时间。[/]
具体使用情况可以视具体情况而定。
参考:http://www.4byte.cn/question/288008/kafka-sending-a-15mb-message.html
Kafka Offset Monitor页面字段解释
大数据 Ansible 发表了文章 0 个评论 4727 次浏览 2016-06-24 17:43

如上图所示:
id:kafka broker实例的id号
host:kafka 实例的ip地址
port:kafka 实例服务端口
Topic:Topic的名字
Partition:Topic包含的分区,上图中pythonTopic中包含4个分区(默认分区从0开始)
Offset:Kafka Consumer已经消费分区上的消息数
logSize:已经写到该分区的消息数
Lag:未读取也就是未消费的消息数(Lag = logSize - Offset)
Owner:改分区位于哪个Broker上,上图中只有一个Broker(consumer group name + consumer hostname + broker.id)
Created:分区创建时间
Last Seen:Offset 和 logSize 数字最后一次刷新时间间隔
有时候刚启动kafka的时候,可能发现Lag为负值,这明显是不对的,但是当Producer 和 Consumer对kafka进行写和读的时候,数字会显示正常,具体为什么会出现负值,我也不从而知,我估计是bug。
Kafka文件系统设计
大数据 Geek小A 发表了文章 0 个评论 3357 次浏览 2016-04-09 17:08
Kafka简要说明

关键特⾊:
- []可伸缩架构[/][]高吞吐量[/][]consumer⾃动负载均衡 [/][]支持集群多副本[/]
topic名称为:report_pushTopic中partition存储分布


Partiton文件存储⽅方式

- []每个partion(目录)相当于一个巨型⽂件被平均分配到多个⼤小相等的多个segment(段)文件中。但每个段segment file消息数量不⼀定相等,这种特性⽅便old segment file快速被删除。[/][]每个partiton只需要⽀持顺序读写就⾏了,segment文件生命周期由服务端配置参数决定。 [/]
下⾯面介绍一下partion⽂文件存储中segment file组成结构。一个商业化消息队列的性能好坏,其文件系统存储结构设计是衡量⼀个消息队列服务程序最关 键指标之一,他也是消息队列中最核心且最能体现消息队列技术⽔平的部分。在本节中我们将⾛进segment file内部⼀探究竟。segment file组成:由2⼤大部分组成,分别为segment data file和segment index file,此2个⽂件⼀一对应,成对出现.segment中 index — data file对应关系Partiton中segment⽂文件存储结构

index为稀疏索引结构,并不存储每条记录的元数据信息,⽽是与单条或多条消息大⼩比较,如果总消息⼤小大于该阀值才写一次index,默认阀值4096字节。partiton中segment⽂件存储结构-index 00000000000000000000.index索引⽂件存储结构: 每次记录相应log文件记录的相对条数和物理偏移位置,共8bytes 4 byte 当前segment file offset - last seg file offset记录条数offset4 byte 对应segment file物理偏移地址 position......... part中segment文件存储结构-data file

一个消息(message chunk)数据块可能包含多条消息,但同⼀个数据块中的消息只有⼀个offset(partiions第多少msg chunk),所以当一个消息块有多条数据处理完部分数据发生异常时,消费者重新去取数据,就会再次取得这个数据块,然后消费过的数据就会被重新消费。
数据库稀疏索引例⼦

稀疏索引只为数据⽂件的每个存储块设⼀个键-指针对,它⽐稠密索引节省了更多的存储空间,但查找给定值的记录需更多的时间。只有当数据文件是按照某个查 找键排序时,在该查找键上建⽴的稀疏索引才能被使用,而稠密索引则可以应⽤在任何的查找键。如图2所⽰示,稀疏索引只为每个存储块设一个键-指针对。键值 是每个数据块中第一个记录的对应值。
同一个topic下有不同分区,每个分区下⾯会划分为多个(段)文件,只有一个当前文件在写,其他⽂文件只读。当写满一个文件(写满的意思是达到设定值)则切换⽂文件,新建一个当前文件用来写,老的当前⽂件切换为只读。文件的命名以起始偏移量来命名。 看一个例⼦子,假设report_push这个topic下的0-0分区可能有以下这些⽂文件:如何在partition中快速定位segment file

其中00000000000000000000.index表⽰示最开始的文件,起始偏移量为0.第⼆个⽂文件 00000000000000368769.index的消息量起始偏移量为368769.同样,第三个⽂件00000000000000737337.index的起始偏移量为737337.以起始偏移量命名并排序这些 文件,那么当消费者要拉取某个消息起始偏移量位置的数据变的相当简单,只要根据 传上来的offset[b]⼆分查找[/b]文件列表,定位到具体文件,然后将绝对offset减去文件的起始节点转化为相对offset,即可开始传输数据。例如,同样以上面的例⼦为例,假设消费者想抓取从第368969消息位置开始的数据,则根据368969⼆分查找,定位到00000000000000368769.log这个文件(368969在368769和737337之间),根据索引文件二分搜索可以确定读取数据最⼤大小,栗子:

如何在segment file查找msg chunk


⾼效文件系统特点 :kafka的⽂文件系统结构—>总结
- []一个大文件分成多个⼩文件段。[/][]多个⼩⽂件段,容易定时清除或删除已经消费完文件,减少磁盘占用。[/][]index全部映射到memory直接操作,避免segment file被交换到磁盘增加IO操作次数。[/][]根据索引元数据信息,可以确定consumer每次批量拉取最大msg chunk数量。[/][]索引⽂文件元数据存储用的是相对前一个segment file的offset存储,节省空间⼤小。[/]

