

Linux
Centos系统进入单用户修改root用户密码
运维 OS小编 发表了文章 0 个评论 1335 次浏览 2022-05-16 17:15

1. 重启系统,在选择进入系统界面按字母e
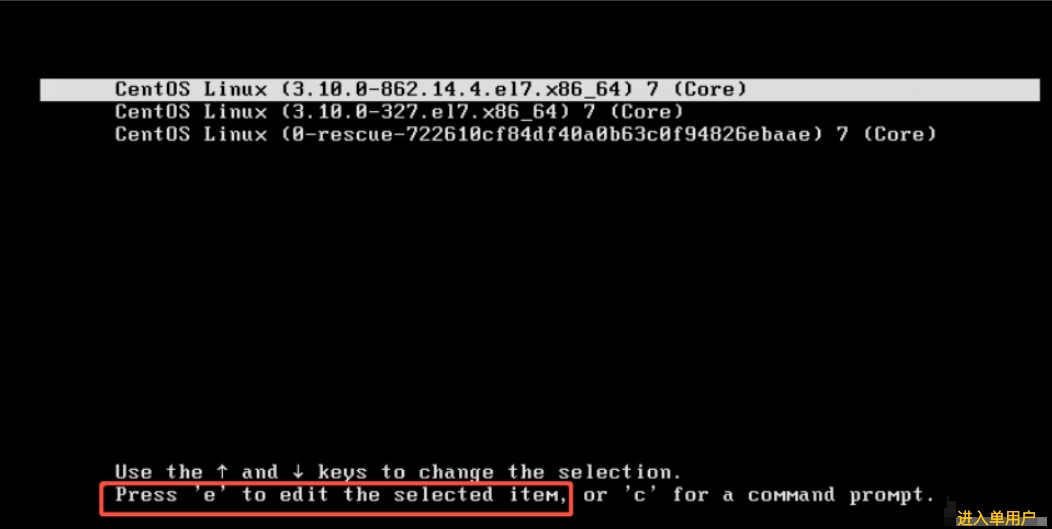
2. 在rhgb前添加’rw’ ,在行末添加 ‘init=/bin/sh’ ,按 ‘Ctrl+x’ 进入系统
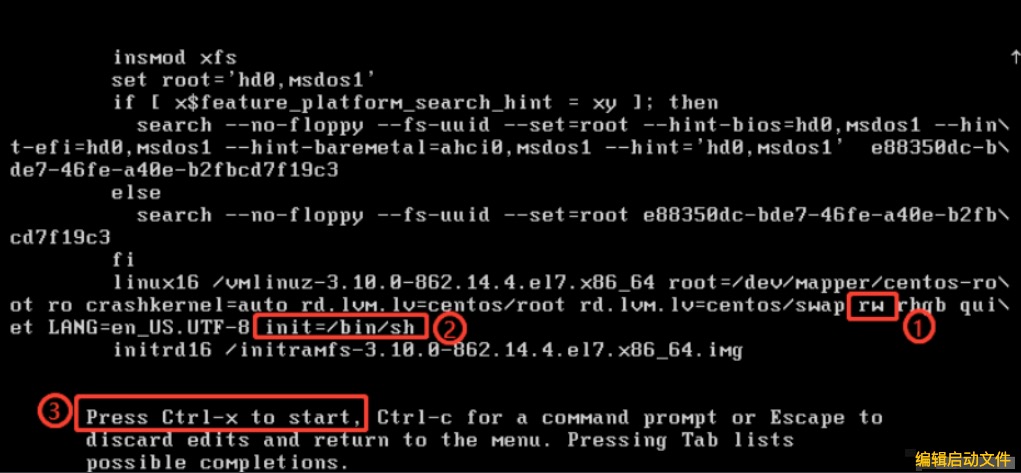
进入系统后,修改密码
echo "www.baidu.com | passwd --stdin root
touch /.autorelabel
exec /sbin/init
等待一会,点击回车,进入重启。
yum和apt-get命令对比
运维 星物种 发表了文章 0 个评论 2462 次浏览 2021-06-17 14:21

| 说明 | Redhat系 | Debian系 |
|---|---|---|
| 更新缓存 | yum makecache | apt-get update |
| 更新包 | yum update | apt-get upgrade |
| 检索包 | yum search | apt-cache search |
| 检索包内文件 | yum provides | apt-file search |
| 安装指定的包 | yum install | apt-get install |
| 删除指定的包 | yum remove | apt-get remove |
| 显示指定包的信息 | yum info | apt-cache show |
| 显示包所在组的一览 | yum grouplist | - |
| 显示指定包所在组的信息 | yum groupinfo | - |
| 安装指定的包组 | yum groupinstall | - |
| 删除指定的包组 | yum groupremove | - |
| 参考库的设定文件 | /etc/yum.repos.d/* | /etc/apt/sources.list |
| 安装完的包的列表 | rpm -qa | dpkg-query -l |
| 显示安装完的指定包的信息 | rpm -qi | apt-cache show |
| 安装完的指定包内的文件列表 | rpm -ql | dpkg-query -L |
| 安装完的包的信赖包的列表 | rpm -qR | apt-cache depends |
| 安装完的文件信赖的包 | rpm -qf | dpkg -S |
Centos下升级OpenSSL版本
运维 chris 发表了文章 0 个评论 2127 次浏览 2020-12-20 15:28

1. 安装依赖
yum -y install perl perl-devel gcc gcc-c++
2. 升级
查看当前版本:
[root@centos7 src]$ openssl version
OpenSSL 1.0.2k-fips
下载新版本
当前最新版本是OpenSSL_1_1_1c(2019年7月5日),请到下面页面下载。
官网下载地址: https://www.openssl.org/source/
Github地址:https://github.com/openssl/openssl/releases
这里下载到/usr/local/src目录:
[root@centos7 ~]$ cd /usr/local/src
[root@centos7 src]$ wget https://github.com/openssl/openssl/archive/OpenSSL_1_1_1c.tar.gz
[root@centos7 src]$ tar xzvf ./OpenSSL_1_1_1c.tar.gz
[root@centos7 src]$ cd openssl-OpenSSL_1_1_1c/
接下来执行编译操作:
[root@centos7 src]$ ./config
如果没有安装Perl 5,执行config会有提示没有安装,需要先进行安装,执行yum install perl。
接下来依次执行下面的命令:
[root@centos7 src]$ make
[root@centos7 src]$ make test
[root@centos7 src]$ sudo make install
替换新旧版本:
[root@centos7 src]$ mv /usr/bin/openssl /usr/bin/oldopenssl
[root@centos7 src]$ ln -s /usr/local/bin/openssl /usr/bin/openssl
如果执行openssl version报下面错误:
[root@localhost openssl-OpenSSL_1_1_1c]$ openssl version
openssl: error while loading shared libraries: libssl.so.1.1: cannot open shared object file: No such file or directory
则执行下面命令解决:
[root@centos7 src]$ sudo ln -s /usr/local/lib64/libssl.so.1.1 /usr/lib64/
[root@centos7 src]$ sudo ln -s /usr/local/lib64/libcrypto.so.1.1 /usr/lib64/
然后查看当前版本:
[root@centos7 openssl-OpenSSL_1_1_1c]$ openssl version
OpenSSL 1.1.1c 28 May 2019
常见错误
错误:begin failed–compilation aborted at .././test/run_tests.pl
解决:sudo yum install perl-devel
错误:Parse errors: No plan found in TAP output
解决:yum install perl-Test-Simple
常见系统glibc版本列表
运维 chris 发表了文章 0 个评论 4479 次浏览 2020-11-24 22:54

| 操作系统 | 操作系统位数 | Glibc版本 |
|---|---|---|
| Centos4.0 | 32bit | ldd (GNU libc) 2.3.4 |
| Centos5.0 | 32bit | ldd (GNU libc) 2.5 |
| Centos3.1 | 64bit | ldd (GNU libc) 2.3.2 |
| Centos3.3 | 64bit | ldd (GNU libc) 2.3.2 |
| Centos4.0 | 64bit | ldd (GNU libc) 2.3.4 |
| Centos5.0 | 64bit | ldd (GNU libc) 2.5 |
| Centos6.0 | 64bit | ldd (GNU libc) 2.12 |
| Centos6.5 | 64bit | ldd (GNU libc) 2.12 |
| Centos7.* | 64bit | ldd (GNU libc) 2.17 |
| Redhat6.5 | 64bit | ldd (GNU libc) 2.12 |
| Redhat7.0 | 64bit | ldd (GNU libc) 2.17 |
| Redhat7.3 | 64bit | ldd (GNU libc) 2.17 |
| Debian6.0 | 32bit | ldd (Debian EGLIBC 2.11.3-4) 2.11.3 |
| Debian7.0 | 32bit | ldd (Debian EGLIBC 2.13-38+deb7u12) 2.13 |
| Debian7.0 | 64bit | ldd (Debian EGLIBC 2.13-38+deb7u12) 2.13 |
| Suse9.0 | 32bit | ldd (GNU libc) 2.3.5 |
| Suse9.1 | 64bit | ldd (GNU libc) 2.3.3 |
| Suse10.0 | 32bit | ldd (GNU libc) 2.4 |
| Suse10.0 | 64bit | ldd (GNU libc) 2.3.5 |
| Suse11.0 | 64bit | ldd (GNU libc) 2.11.1 |
| Suse12.0 | 64bit | ldd (GNU libc) 2.19 |
| OpenSuse42 | 64bit | ldd (GNU libc) 2.19 |
| fedora22 | 64bit | ldd (GNU libc) 2.22 |
| ubuntu12 | 64bit | ldd (Ubuntu EGLIBC 2.15-0ubuntu10.6) 2.15 |
| ubuntu14 | 64bit | ldd (Ubuntu EGLIBC 2.19-0ubuntu6.9) 2.19 |
| Asianux Server 3 | 64bit | ldd (GNU libc) 2.5 |
| Power Linux 6.5 | 64bit | ldd (GNU libc) 2.12 |
| Power Linux7.3 | 64bit | ldd (GNU libc) 2.17 |
以后在补充一些常见系统过得Glibc版本。
linux下LD_LIBRARY_PATH介绍
运维 chris 发表了文章 0 个评论 13672 次浏览 2020-11-24 00:39

LD_LIBRARY_PATH是Linux环境变量名,该环境变量主要用于指定查找共享库(动态链接库)时除了默认路径之外的其他路径。
非常多的软件没有root权限安装会比较困难,主要就是因为各种系统库文件,也就是LD_LIBRARY_PATH这个环境变量里面的文件。比如前面我提到的lancet软件需要的库文件如下:
-llzma -lbz2 -lz -ldl -lpthread -lcurl -lcrypto -lbamtools
可以使用 ls /usr/lib |grep lib 查看自己是否有需要的库文件,当然还需查看其它库文件目录:echo $LD_LIBRARY_PATH 里面一般可以看到七八个已经定义好的库文件搜索路径。
当执行函数动态链接.so时,如果此文件不在缺省目录下 /lib和/usr/lib,那么就需要指定环境变量LD_LIBRARY_PATH 假如现在需要在已有的环境变量上添加新的路径名,则采用如下方式: LD_LIBRARY_PATH=NEWDIRS:$LD_LIBRARY_PATH (newdirs是新的路径串), 实例如下:
export LD_LIBRARY_PATH=/export/apps/anaconda2/2.4.1/lib/:$LD_LIBRARY_PATH
一般报错:
/usr/bin/ld: cannot find -llzma
collect2: error: ld returned 1 exit status
make[1]: *** [lancet] Error 1
make[1]: Leaving directory `/home/bobo/biosoft/lancet/lancet/src'
cp: cannot stat `lancet': No such file or directory
其实就是gcc编辑器找不到我们系统的liblzma这个库文件,就是我们的LD_LIBRARY_PATH定义的所有路径里面都没有这个liblzma这个库文件。
验证gcc编辑器能否找到指定库文件的方法是:
gcc -llzma --verbose
需要找到系统的库文件地址
事实上,我们的机器肯定是有这个库文件的,只不过是不在LD_LIBRARY_PATH定义的所有路径里面,简单查找如下:
locate liblzma
/export/apps/anaconda2/2.4.1/lib/liblzma.a
/export/apps/anaconda2/2.4.1/lib/liblzma.la
/export/apps/anaconda2/2.4.1/lib/liblzma.so
/export/apps/anaconda2/2.4.1/lib/liblzma.so.5
/export/apps/anaconda2/2.4.1/lib/liblzma.so.5.0.5
为了解决我,我们需要添加:
export LD_LIBRARY_PATH=/export/apps/anaconda2/4.0.0/lib/:$LD_LIBRARY_PATH
export LIBRARY_PATH=/export/apps/anaconda2/4.0.0/lib/:$LIBRARY_PATH
为什么修改LD_LIBRARY_PATH呢
因为运行时动态库的搜索路径的先后顺序是:
1.编译目标代码时指定的动态库搜索路径;
2.环境变量LD_LIBRARY_PATH指定的动态库搜索路径;
3.配置文件/etc/ld.so.conf中指定的动态库搜索路径;
4.默认的动态库搜索路径/lib和/usr/lib;
这个顺序是compile gcc时写在程序内的,通常软件源代码自带的动态库不会太多,而我们的/lib和/usr/lib只有root权限才可以修改,而且配置文件/etc/ld.so.conf也是root的事情,我们只好对LD_LIBRARY_PATH进行操作啦。
永久性添加
每次我使用该软件都需要临时修改库文件,因为上面的方法是临时设置环境变量 LD_LIBRARY_PATH ,重启或打开新的 Shell 之后,一切设置将不复存在。
为了让这种方法更完美一些,可以将该 LD_LIBRARY_PATH 的 export 语句写到系统文件中,例如 /etc/profile、/etc/export、~/.bashrc 或者 ~/.bash_profile 等等,取决于你正在使用的操
虽然LD_LIBRARY_PATH很方便,但是还是推荐大家在编译的时候指定-rpath来执行相对路径来找到动态链接库文件。
交叉编译详解概念篇
运维 OS小编 发表了文章 0 个评论 2008 次浏览 2020-11-01 01:53

1、交叉编译简介
1.1 什么是交叉编译
对于没有做过嵌入式编程的人, 可能不太理解交叉编译的概念, 那么什么是交叉编译?它有什么作用?
在解释什么是交叉编译之前,先要明白什么是本地编译。
本地编译:
本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台(CPU和系统)下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译:
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序:
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
1.2 为什么会有交叉编译
之所以要有交叉编译,主要原因是:
- Speed: 目标平台的运行速度往往比当前编译主机慢得多,许多专用的嵌入式硬件被设计为低成本和低功耗,没有太高的性能;
- Capability: 整个编译过程是非常消耗资源的,嵌入式系统往往没有足够的内存或磁盘空间;
- Availability: 即使目标平台资源很充足,可以本地编译,但是第一个在目标平台上运行的本地编译器总需要通过交叉编译获得;
- Flexibility: 一个完整的Linux编译环境需要很多支持包,交叉编译使我们不需要花时间将各种支持包移植到目标机器上。
1.3 为什么交叉编译比较困难
交叉编译的困难点在于两个方面:
不同的体系架构拥有不同的机器特性
- Word size: 是64位还是32位系统
- Endianness: 是大端还是小端系统
- Alignment: 是否必修按照4字节对齐方式进行访问
- Default signedness: 默认数据类型是有符号还是无符号
- NOMMU: 是否支持MMU
交叉编译时的主机环境与目标环境不同
- Configuration issues:具有单独配置步骤(标准./configure make make install)的软件包通常会测试字节序或页面大小等内容,以便在本地编译时可移植。交叉编译时,这些值在主机系统和目标系统之间会有所不同,因此在主机系统上运行测试会给出错误的答案。当目标没有该程序包或版本不兼容时,配置还可以检测主机上是否存在该程序包并包括对该程序包的支持;
- HOSTCC vs TARGETCC:许多构建过程需要编译内容才能在主机系统上运行,例如上述配置测试或生成代码的程序(例如创建.h文件的C程序,然后在主构建过程中#include )。仅用目标编译器替换主机编译器就会破坏需要构建在构建本身中运行的事物的软件包。这样的软件包需要访问主机和目标编译器,并且需要教它们何时使用它们;
- Toolchain Leaks:配置不正确的交叉编译工具链可能会将主机系统的某些位泄漏到已编译的程序中,从而导致通常易于检测但难以诊断和纠正的故障。工具链可能#include错误的头文件,或在链接时搜索错误的库路径。共享库通常依赖于其他共享库,这些共享库也可能潜入对主机系统的意外链接时引用;
- Libraries:动态链接的程序必须在编译时访问适当的共享库。需要将与目标系统共享的库添加到交叉编译工具链中,以便程序可以针对它们进行链接;
- Testing:在本机版本上,开发系统提供了便利的测试环境。交叉编译时,确认”hello world”构建成功可能需要配置(至少)引导加载程序,内核,根文件系统和共享库。
更详细的对比可以参看这篇文章,已经写的很详细了,在这就不细说了:Introduction to cross-compiling for Linux
2、交叉编译链
2.1 什么是交叉编译链
明白了什么是交叉编译,那我们来看看什么是交叉编译链。
首先编译过程是按照不同的子功能,依照先后顺序组成的一个复杂的流程,如下图: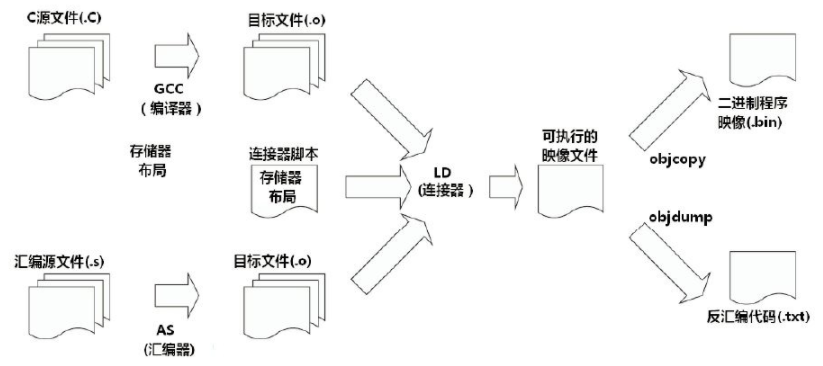
那么编译过程包括了预处理、编译、汇编、链接等功能。既然有不同的子功能,那每个子功能都是一个单独的工具来实现,它们合在一起形成了一个完整的工具集。
同时编译过程又是一个有先后顺序的流程,它必然牵涉到工具的使用顺序,每个工具按照先后关系串联在一起,这就形成了一个链式结构。
因此,交叉编译链就是为了编译跨平台体系结构的程序代码而形成的由多个子工具构成的一套完整的工具集。同时,它隐藏了预处理、编译、汇编、链接等细节,当我们指定了源文件(.c)时,它会自动按照编译流程调用不同的子工具,自动生成最终的二进制程序映像(.bin)。
注意: 严格意义上来说,交叉编译器,只是指交叉编译的gcc,但是实际上为了方便,我们常说的交叉编译器就是交叉工具链。本文对这两个概念不加以区分,都是指编译链。
2.2 交叉编译链的命名规则
我们使用交叉编译链时,常常会看到这样的名字:
arm-none-linux-gnueabi-gcc
arm-cortex_a8-linux-gnueabi-gcc
mips-malta-linux-gnu-gcc
其中,对应的前缀为:
arm-none-linux-gnueabi-
arm-cortex_a8-linux-gnueabi-
mips-malta-linux-gnu-
这些交叉编译链的命名规则似乎是通用的,有一定的规则:
arch-core-kernel-system
- arch: 用于哪个目标平台;
- core: 使用的是哪个CPU Core,如Cortex A8,但是这一组命名好像比较灵活,在其它厂家提供的交叉编译链中,有以厂家名称命名的,也有以开发板命名的,或者直接是none或cross的;
- kernel: 所运行的OS,见过的有Linux,uclinux,bare(无OS);
- system: 交叉编译链所选择的库函数和目标映像的规范,如gnu,gnueabi等。其中gnu等价于glibc+oabi、gnueabi等价于glibc+eabi。
注意: 这个规则是一个猜测,并没有在哪份官方资料上看到过。而且有些编译链的命名确实没有按照这个规则,也不清楚这是不是历史原因造成的。如果有谁在资料上见到过此规则的详细描述,欢迎指出错误。
3、包含的工具
Binutils是GNU工具之一,它包括链接器、汇编器和其他用于目标文件和档案的工具,它是二进制代码的处理维护工具。
Binutils工具包含的子程序如下:
- ld - GNU链接器;
- as - GNU汇编器;
- gold - 一个新的,更快的ELF链接器;
- addr2line - 把地址转换成文件名和所在的行数;
- ar - 用于创建,修改和提取档案的实用程序;
- c ++ filt-过滤以解编码编码的C ++符号;
- dlltool-创建用于构建和使用DLL的文件;
- elfedit-允许更改ELF格式文件;
- gprof-显示分析信息;
- nlmconv-将目标代码转换为NLM;
- nm-列出目标文件中的符号;
- objcopy-复制并转换目标文件;
- objdump-显示目标文件中的信息;
- ranlib-生成指向档案内容的索引;
- readelf-显示来自任何ELF格式对象文件的信息;
- size -列出的对象或归档文件的部分的尺寸;
- strings -列出文件中的可打印字符串;
- strip - 丢弃的符号;
- windmc -Windows兼容的消息编译器。
- windres -Windows资源文件的编译器。
binutils介绍 binutils详解 详细页面。
3.2 GCC
GNU编译器套件,支持C, C++, Java, Ada, Fortran, Objective-C等众多语言。
3.3 Glibc
Linux上通常使用的C函数库为glibc。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现。
因为嵌入式环境的资源及其紧张,所以现在除了glibc外,还有uClibc和eglibc可以选择,三者的关系可以参见这两篇文章:
3.4 GDB
GDB用于调试程序
4、如何得到交叉编译链
既然明白了交叉编译链的功能,那么在针对嵌入式系统开发时,我们需要的交叉编译链从哪儿得到?
主要有三个方式可以获取
4.1 下载已经做好的交叉编译链
使用其他人针对某些CPU平台已经编译好的交叉编译链。我们只需要找到合适的,下载下来使用即可。
常见的交叉编译链下载地址:
在 http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/ 下载已经编译好的交叉编译链
在 http://www.denx.de/en/Software/WebHome 下载已经编译好的交叉编译链
在https://launchpad.net/gcc-arm-embedded下载已经编译好的交叉编译链
一些制作交叉编译链的工具中,包含了已经制作好的交叉编译链,可以直接拿来使用。如crosstool-NG
如果购买了某个芯片或开发板,一般厂商会提供对应的整套开发软件,其中就包含了交叉编译链。
厂家提供的工具一般是经过了严格的测试,并打入了一些必要的补丁,所以这种方式往往是最可靠的工具来源。
4.2 使用工具定制交叉编译链
使用现存的制作工具,以简化制作交叉编译链这个事情的复杂度。我们只需要了解有哪些工具可以实现,并选个合适的工具,搞懂它的操作步骤即可。
- crosstool-NG
- Buildroot
- Embedded Linux Development Kit (ELDK)
工具还有很多,各有各的优势和劣势,大家可以慢慢研究,在这就不细说了。
4.3 从零开始构建交叉编译链
这个是最困难也最耗时间的,毕竟制作交叉编译链这样的事情,需要对嵌入式的编译原理了解的比较透彻,至少要知道出了问题要往哪个方面去翻阅资料。而且,也是最考耐心和细心的地方,配错一个选项或是一个步骤,都可能出现以前从来没见过的问题,而且这些问题往往还无法和这个选项或步骤直接联系起来。
当然如果搭建出来,肯定也是收获最大的,至少对于编译的流程和依赖都比较清楚了,细节上的东西可能还需要去翻看相应的协议或标准,但至少骨架会比较清楚。
详细的搭建过程可以参看后续的文章,这里面有详细的参数和步骤:
交叉编译详解 二 从零制作交叉编译链
为了方便大家搭建交叉编译链,我写了一个一键生成的脚本(包括源码下载和自动编译)。如果大家自己一直搭建不成功,不妨试试这个脚本,然后对比下自己的流程是否一致,参数是否有差异,也许能帮大家迈过这个障碍:
交叉编译详解 三 使用脚本自动生成交叉编译链
4.4 对比三种构建方式
| 项目 | 使用已有交叉编译链 | 自己制作交叉编译链 |
|---|---|---|
| 安装 | 一般提供压缩包 | 需要自己打包 |
| 源码版本 | 一般使用较老的稳定版本,对于一些新的GCC特性不支持 | 可以使用自己需要的GCC特性的版本 |
| 补丁 | 一般都会打上修复补丁 | 普通开发者很难辨别需要打上哪些补丁,资深开发者可以针对自己的需求合入补丁 |
| 源码溯源 | 可能不清楚源码版本和补丁情况 | 一切都可以定制 |
| 升级 | 一般不会升级 | 可以随时升级 |
| 优化 | 一般已经针对特定CPU特性和性能进行优化 | 一般无法做到比厂家优化的更好,除非自己设计的CPU |
| 技术支持 | 可以通过FAE进行支持,可能需要收费 | 只能通过社区支持,免费 |
| 可靠性验证 | 已经通过了完善的验证 | 自己验证,肯定没有专业人士验证的齐全 |
参考资料
1、Introduction to cross-compiling for Linux
4、 uclibc eglibc glibc之间的区别和联系
5、 Glibc vs uClibc Differences
6、交叉编译链下载地址
- http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/
- http://www.denx.de/en/Software/WebHome
- https://launchpad.net/gcc-arm-embedded
分享原文: http://m6z.cn/6tdD7y
Linux文件的三个时间属性
运维 Ansible 发表了文章 0 个评论 1605 次浏览 2020-10-16 16:45

时间属性介绍
Linux下一个文件通过stat命令可以查看到这个文件时间方面的属性,具体信息如下:
# stat tengine-2.0.0-23tf4566.tar.gz
File: 'tengine-2.0.0-23tf4566.tar.gz'
Size: 35995224 Blocks: 70304 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201842670 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 501/ UNKNOWN) Gid: ( 20/ games)
Access: 2020-07-30 14:07:46.617759798 +0000
Modify: 2020-07-30 12:57:35.000000000 +0000
Change: 2020-10-16 06:20:13.535869875 +0000
Birth: -
如上所示,可以看出来分别有Access Modify Change 三个关于时间的属性。
此三个属性初始时间记录都是文件被创建的时间:
- Access 指最后一次读取的时间(访问)
- Modify 指最后一次修改数据的时间(修改)
- Change 指最后一次修改元数据的时间(改变)
Access的意思是访问:
在终端上用cat、more 、less、grep、sed、 cp 、file 一个文件时,此文件的Access的时间记录都会被更新(空文件例外),纯粹的access是不会影响modify和change,但会受到modify行为的影响。
用ls -lu看到的文件时间是最近一次access的时间。对于目录而言,只是进入目录的话不会改变它的access时间,但只要用ls查看了此目录的内容(无论在何处),这个目录的access时间就会被更新。
Modify 意思是更改(内容)or 写入:
当更改了一个文件的内容的时候,此文件的modify的时间记录会被更新。用ls -l看到的文件时间是最近一次modify的时间。modify的行为是三个行为中最有影响力的行为,它发生以后,会使文件的access记录与change记录也同时得到更新, 对于目录亦是如此。
Change 改变(状态或属性):
对一个文件或者目录作mv、chown、chgrp操作后,它的Change时间记录被更新,change时间会受到modify行为的影响。用ls -lc看到的文件时间是最近一次change的时间。
# stat test.txt
File: ‘test.txt’
Size: 10 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201843904 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-10-16 06:44:21.925299516 +0000
Modify: 2020-10-16 06:44:21.925299516 +0000
Change: 2020-10-16 06:44:21.925299516 +0000
Birth: -
# cat test.txt
lucky boy
# stat test.txt
File: ‘test.txt’
Size: 10 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201843904 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-10-16 06:44:43.911988787 +0000
Modify: 2020-10-16 06:44:21.925299516 +0000
Change: 2020-10-16 06:44:21.925299516 +0000
Birth: -
如上用cat命令将文件test.txt的内容输出到终端( 执行 cat test.txt), 那么文件test.txt只有的Access被刷新。
# date >> test.txt
# stat test.txt
File: ‘test.txt’
Size: 39 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201843904 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-10-16 06:44:43.911988787 +0000
Modify: 2020-10-16 06:46:56.760155796 +0000
Change: 2020-10-16 06:46:56.760155796 +0000
Birth: -
如上把当前的时间追加到test.txt(执行 date >> test.txt) , 那么test.txt的Modify和Change都被刷新。
# chmod 777 test.txt
# stat test.txt
File: ‘test.txt’
Size: 39 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201843904 Links: 1
Access: (0777/-rwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-10-16 06:44:43.911988787 +0000
Modify: 2020-10-16 06:46:56.760155796 +0000
Change: 2020-10-16 06:48:45.676571600 +0000
Birth: -
如上把test.txt的权限改为777(执行 chmod 777 test.txt) , 那么只有test.txt的Change被刷新。
假如我们用vi命令把文件test.txt打开, 然后保存退出,那么test.txt的Access、Modify和Change都会被刷新。
同时我们也可以使用命令touch更新test.txt的Access和Modify时间:
touch -d 1999-01-01 test.txt // 将test.txt的Access和Modify时间改为1999-01-01
touch -a test.txt // 只将test.txt的Access时间改为当前系统时间
touch -m test.txt // 只将test.txt的Modify时间改为当前系统时间
当我们用ls -l test.txt看到的时间就是Modify时间。
按照时间排序文件
# ls -l
-rw-r--r-- 1 501 games 35995224 Jul 30 12:57 tengine-2.0.0-23tf4566.tar.gz
-rw-r--r-- 1 501 games 4321420 Jul 22 14:15 tengine-2.0.0-45axfa54.tar.gz
-rw-r--r-- 1 501 games 33238934 Jul 22 15:20 tengine-2.0.0-64af1234.tar.gz
如上有3个文件,如果按照时间排序呢?
按照修改时间排序:
ls -alt 等价于 ls --sort=time -la
按照创建时间排序:
ls -alc
按访问时间排序:
ls -alu
以上均可使用-r实现逆序排序
ls -alrt # 按修改时间排序
ls --sort=time -lra # 等价于> ls -alrt
ls -alrc # 按创建时间排序
ls -alru # 按访问时间排序
不管你是根据什么排序,加上-r 就会反序。
Centos系统进入单用户修改root用户密码
运维 OS小编 发表了文章 0 个评论 1335 次浏览 2022-05-16 17:15
1. 重启系统,在选择进入系统界面按字母e
2. 在rhgb前添加’rw’ ,在行末添加 ‘init=/bin/sh’ ,按 ‘Ctrl+x’ 进入系统
进入系统后,修改密码
echo "www.baidu.com | passwd --stdin root
touch /.autorelabel
exec /sbin/init
等待一会,点击回车,进入重启。
yum和apt-get命令对比
运维 星物种 发表了文章 0 个评论 2462 次浏览 2021-06-17 14:21
| 说明 | Redhat系 | Debian系 |
|---|---|---|
| 更新缓存 | yum makecache | apt-get update |
| 更新包 | yum update | apt-get upgrade |
| 检索包 | yum search | apt-cache search |
| 检索包内文件 | yum provides | apt-file search |
| 安装指定的包 | yum install | apt-get install |
| 删除指定的包 | yum remove | apt-get remove |
| 显示指定包的信息 | yum info | apt-cache show |
| 显示包所在组的一览 | yum grouplist | - |
| 显示指定包所在组的信息 | yum groupinfo | - |
| 安装指定的包组 | yum groupinstall | - |
| 删除指定的包组 | yum groupremove | - |
| 参考库的设定文件 | /etc/yum.repos.d/* | /etc/apt/sources.list |
| 安装完的包的列表 | rpm -qa | dpkg-query -l |
| 显示安装完的指定包的信息 | rpm -qi | apt-cache show |
| 安装完的指定包内的文件列表 | rpm -ql | dpkg-query -L |
| 安装完的包的信赖包的列表 | rpm -qR | apt-cache depends |
| 安装完的文件信赖的包 | rpm -qf | dpkg -S |
Centos下升级OpenSSL版本
运维 chris 发表了文章 0 个评论 2127 次浏览 2020-12-20 15:28
1. 安装依赖
yum -y install perl perl-devel gcc gcc-c++
2. 升级
查看当前版本:
[root@centos7 src]$ openssl version
OpenSSL 1.0.2k-fips
下载新版本
当前最新版本是OpenSSL_1_1_1c(2019年7月5日),请到下面页面下载。
官网下载地址: https://www.openssl.org/source/
Github地址:https://github.com/openssl/openssl/releases
这里下载到/usr/local/src目录:
[root@centos7 ~]$ cd /usr/local/src
[root@centos7 src]$ wget https://github.com/openssl/openssl/archive/OpenSSL_1_1_1c.tar.gz
[root@centos7 src]$ tar xzvf ./OpenSSL_1_1_1c.tar.gz
[root@centos7 src]$ cd openssl-OpenSSL_1_1_1c/
接下来执行编译操作:
[root@centos7 src]$ ./config
如果没有安装Perl 5,执行config会有提示没有安装,需要先进行安装,执行yum install perl。
接下来依次执行下面的命令:
[root@centos7 src]$ make
[root@centos7 src]$ make test
[root@centos7 src]$ sudo make install
替换新旧版本:
[root@centos7 src]$ mv /usr/bin/openssl /usr/bin/oldopenssl
[root@centos7 src]$ ln -s /usr/local/bin/openssl /usr/bin/openssl
如果执行openssl version报下面错误:
[root@localhost openssl-OpenSSL_1_1_1c]$ openssl version
openssl: error while loading shared libraries: libssl.so.1.1: cannot open shared object file: No such file or directory
则执行下面命令解决:
[root@centos7 src]$ sudo ln -s /usr/local/lib64/libssl.so.1.1 /usr/lib64/
[root@centos7 src]$ sudo ln -s /usr/local/lib64/libcrypto.so.1.1 /usr/lib64/
然后查看当前版本:
[root@centos7 openssl-OpenSSL_1_1_1c]$ openssl version
OpenSSL 1.1.1c 28 May 2019
常见错误
错误:begin failed–compilation aborted at .././test/run_tests.pl
解决:sudo yum install perl-devel
错误:Parse errors: No plan found in TAP output
解决:yum install perl-Test-Simple
常见系统glibc版本列表
运维 chris 发表了文章 0 个评论 4479 次浏览 2020-11-24 22:54
| 操作系统 | 操作系统位数 | Glibc版本 |
|---|---|---|
| Centos4.0 | 32bit | ldd (GNU libc) 2.3.4 |
| Centos5.0 | 32bit | ldd (GNU libc) 2.5 |
| Centos3.1 | 64bit | ldd (GNU libc) 2.3.2 |
| Centos3.3 | 64bit | ldd (GNU libc) 2.3.2 |
| Centos4.0 | 64bit | ldd (GNU libc) 2.3.4 |
| Centos5.0 | 64bit | ldd (GNU libc) 2.5 |
| Centos6.0 | 64bit | ldd (GNU libc) 2.12 |
| Centos6.5 | 64bit | ldd (GNU libc) 2.12 |
| Centos7.* | 64bit | ldd (GNU libc) 2.17 |
| Redhat6.5 | 64bit | ldd (GNU libc) 2.12 |
| Redhat7.0 | 64bit | ldd (GNU libc) 2.17 |
| Redhat7.3 | 64bit | ldd (GNU libc) 2.17 |
| Debian6.0 | 32bit | ldd (Debian EGLIBC 2.11.3-4) 2.11.3 |
| Debian7.0 | 32bit | ldd (Debian EGLIBC 2.13-38+deb7u12) 2.13 |
| Debian7.0 | 64bit | ldd (Debian EGLIBC 2.13-38+deb7u12) 2.13 |
| Suse9.0 | 32bit | ldd (GNU libc) 2.3.5 |
| Suse9.1 | 64bit | ldd (GNU libc) 2.3.3 |
| Suse10.0 | 32bit | ldd (GNU libc) 2.4 |
| Suse10.0 | 64bit | ldd (GNU libc) 2.3.5 |
| Suse11.0 | 64bit | ldd (GNU libc) 2.11.1 |
| Suse12.0 | 64bit | ldd (GNU libc) 2.19 |
| OpenSuse42 | 64bit | ldd (GNU libc) 2.19 |
| fedora22 | 64bit | ldd (GNU libc) 2.22 |
| ubuntu12 | 64bit | ldd (Ubuntu EGLIBC 2.15-0ubuntu10.6) 2.15 |
| ubuntu14 | 64bit | ldd (Ubuntu EGLIBC 2.19-0ubuntu6.9) 2.19 |
| Asianux Server 3 | 64bit | ldd (GNU libc) 2.5 |
| Power Linux 6.5 | 64bit | ldd (GNU libc) 2.12 |
| Power Linux7.3 | 64bit | ldd (GNU libc) 2.17 |
以后在补充一些常见系统过得Glibc版本。
linux下LD_LIBRARY_PATH介绍
运维 chris 发表了文章 0 个评论 13672 次浏览 2020-11-24 00:39
LD_LIBRARY_PATH是Linux环境变量名,该环境变量主要用于指定查找共享库(动态链接库)时除了默认路径之外的其他路径。
非常多的软件没有root权限安装会比较困难,主要就是因为各种系统库文件,也就是LD_LIBRARY_PATH这个环境变量里面的文件。比如前面我提到的lancet软件需要的库文件如下:
-llzma -lbz2 -lz -ldl -lpthread -lcurl -lcrypto -lbamtools
可以使用 ls /usr/lib |grep lib 查看自己是否有需要的库文件,当然还需查看其它库文件目录:echo $LD_LIBRARY_PATH 里面一般可以看到七八个已经定义好的库文件搜索路径。
当执行函数动态链接.so时,如果此文件不在缺省目录下 /lib和/usr/lib,那么就需要指定环境变量LD_LIBRARY_PATH 假如现在需要在已有的环境变量上添加新的路径名,则采用如下方式: LD_LIBRARY_PATH=NEWDIRS:$LD_LIBRARY_PATH (newdirs是新的路径串), 实例如下:
export LD_LIBRARY_PATH=/export/apps/anaconda2/2.4.1/lib/:$LD_LIBRARY_PATH
一般报错:
/usr/bin/ld: cannot find -llzma
collect2: error: ld returned 1 exit status
make[1]: *** [lancet] Error 1
make[1]: Leaving directory `/home/bobo/biosoft/lancet/lancet/src'
cp: cannot stat `lancet': No such file or directory
其实就是gcc编辑器找不到我们系统的liblzma这个库文件,就是我们的LD_LIBRARY_PATH定义的所有路径里面都没有这个liblzma这个库文件。
验证gcc编辑器能否找到指定库文件的方法是:
gcc -llzma --verbose
需要找到系统的库文件地址
事实上,我们的机器肯定是有这个库文件的,只不过是不在LD_LIBRARY_PATH定义的所有路径里面,简单查找如下:
locate liblzma
/export/apps/anaconda2/2.4.1/lib/liblzma.a
/export/apps/anaconda2/2.4.1/lib/liblzma.la
/export/apps/anaconda2/2.4.1/lib/liblzma.so
/export/apps/anaconda2/2.4.1/lib/liblzma.so.5
/export/apps/anaconda2/2.4.1/lib/liblzma.so.5.0.5
为了解决我,我们需要添加:
export LD_LIBRARY_PATH=/export/apps/anaconda2/4.0.0/lib/:$LD_LIBRARY_PATH
export LIBRARY_PATH=/export/apps/anaconda2/4.0.0/lib/:$LIBRARY_PATH
为什么修改LD_LIBRARY_PATH呢
因为运行时动态库的搜索路径的先后顺序是:
1.编译目标代码时指定的动态库搜索路径;
2.环境变量LD_LIBRARY_PATH指定的动态库搜索路径;
3.配置文件/etc/ld.so.conf中指定的动态库搜索路径;
4.默认的动态库搜索路径/lib和/usr/lib;
这个顺序是compile gcc时写在程序内的,通常软件源代码自带的动态库不会太多,而我们的/lib和/usr/lib只有root权限才可以修改,而且配置文件/etc/ld.so.conf也是root的事情,我们只好对LD_LIBRARY_PATH进行操作啦。
永久性添加
每次我使用该软件都需要临时修改库文件,因为上面的方法是临时设置环境变量 LD_LIBRARY_PATH ,重启或打开新的 Shell 之后,一切设置将不复存在。
为了让这种方法更完美一些,可以将该 LD_LIBRARY_PATH 的 export 语句写到系统文件中,例如 /etc/profile、/etc/export、~/.bashrc 或者 ~/.bash_profile 等等,取决于你正在使用的操
虽然LD_LIBRARY_PATH很方便,但是还是推荐大家在编译的时候指定-rpath来执行相对路径来找到动态链接库文件。
交叉编译详解概念篇
运维 OS小编 发表了文章 0 个评论 2008 次浏览 2020-11-01 01:53
1、交叉编译简介
1.1 什么是交叉编译
对于没有做过嵌入式编程的人, 可能不太理解交叉编译的概念, 那么什么是交叉编译?它有什么作用?
在解释什么是交叉编译之前,先要明白什么是本地编译。
本地编译:
本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台(CPU和系统)下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译:
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序:
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
1.2 为什么会有交叉编译
之所以要有交叉编译,主要原因是:
- Speed: 目标平台的运行速度往往比当前编译主机慢得多,许多专用的嵌入式硬件被设计为低成本和低功耗,没有太高的性能;
- Capability: 整个编译过程是非常消耗资源的,嵌入式系统往往没有足够的内存或磁盘空间;
- Availability: 即使目标平台资源很充足,可以本地编译,但是第一个在目标平台上运行的本地编译器总需要通过交叉编译获得;
- Flexibility: 一个完整的Linux编译环境需要很多支持包,交叉编译使我们不需要花时间将各种支持包移植到目标机器上。
1.3 为什么交叉编译比较困难
交叉编译的困难点在于两个方面:
不同的体系架构拥有不同的机器特性
- Word size: 是64位还是32位系统
- Endianness: 是大端还是小端系统
- Alignment: 是否必修按照4字节对齐方式进行访问
- Default signedness: 默认数据类型是有符号还是无符号
- NOMMU: 是否支持MMU
交叉编译时的主机环境与目标环境不同
- Configuration issues:具有单独配置步骤(标准./configure make make install)的软件包通常会测试字节序或页面大小等内容,以便在本地编译时可移植。交叉编译时,这些值在主机系统和目标系统之间会有所不同,因此在主机系统上运行测试会给出错误的答案。当目标没有该程序包或版本不兼容时,配置还可以检测主机上是否存在该程序包并包括对该程序包的支持;
- HOSTCC vs TARGETCC:许多构建过程需要编译内容才能在主机系统上运行,例如上述配置测试或生成代码的程序(例如创建.h文件的C程序,然后在主构建过程中#include )。仅用目标编译器替换主机编译器就会破坏需要构建在构建本身中运行的事物的软件包。这样的软件包需要访问主机和目标编译器,并且需要教它们何时使用它们;
- Toolchain Leaks:配置不正确的交叉编译工具链可能会将主机系统的某些位泄漏到已编译的程序中,从而导致通常易于检测但难以诊断和纠正的故障。工具链可能#include错误的头文件,或在链接时搜索错误的库路径。共享库通常依赖于其他共享库,这些共享库也可能潜入对主机系统的意外链接时引用;
- Libraries:动态链接的程序必须在编译时访问适当的共享库。需要将与目标系统共享的库添加到交叉编译工具链中,以便程序可以针对它们进行链接;
- Testing:在本机版本上,开发系统提供了便利的测试环境。交叉编译时,确认”hello world”构建成功可能需要配置(至少)引导加载程序,内核,根文件系统和共享库。
更详细的对比可以参看这篇文章,已经写的很详细了,在这就不细说了:Introduction to cross-compiling for Linux
2、交叉编译链
2.1 什么是交叉编译链
明白了什么是交叉编译,那我们来看看什么是交叉编译链。
首先编译过程是按照不同的子功能,依照先后顺序组成的一个复杂的流程,如下图:
那么编译过程包括了预处理、编译、汇编、链接等功能。既然有不同的子功能,那每个子功能都是一个单独的工具来实现,它们合在一起形成了一个完整的工具集。
同时编译过程又是一个有先后顺序的流程,它必然牵涉到工具的使用顺序,每个工具按照先后关系串联在一起,这就形成了一个链式结构。
因此,交叉编译链就是为了编译跨平台体系结构的程序代码而形成的由多个子工具构成的一套完整的工具集。同时,它隐藏了预处理、编译、汇编、链接等细节,当我们指定了源文件(.c)时,它会自动按照编译流程调用不同的子工具,自动生成最终的二进制程序映像(.bin)。
注意: 严格意义上来说,交叉编译器,只是指交叉编译的gcc,但是实际上为了方便,我们常说的交叉编译器就是交叉工具链。本文对这两个概念不加以区分,都是指编译链。
2.2 交叉编译链的命名规则
我们使用交叉编译链时,常常会看到这样的名字:
arm-none-linux-gnueabi-gcc
arm-cortex_a8-linux-gnueabi-gcc
mips-malta-linux-gnu-gcc
其中,对应的前缀为:
arm-none-linux-gnueabi-
arm-cortex_a8-linux-gnueabi-
mips-malta-linux-gnu-
这些交叉编译链的命名规则似乎是通用的,有一定的规则:
arch-core-kernel-system
- arch: 用于哪个目标平台;
- core: 使用的是哪个CPU Core,如Cortex A8,但是这一组命名好像比较灵活,在其它厂家提供的交叉编译链中,有以厂家名称命名的,也有以开发板命名的,或者直接是none或cross的;
- kernel: 所运行的OS,见过的有Linux,uclinux,bare(无OS);
- system: 交叉编译链所选择的库函数和目标映像的规范,如gnu,gnueabi等。其中gnu等价于glibc+oabi、gnueabi等价于glibc+eabi。
注意: 这个规则是一个猜测,并没有在哪份官方资料上看到过。而且有些编译链的命名确实没有按照这个规则,也不清楚这是不是历史原因造成的。如果有谁在资料上见到过此规则的详细描述,欢迎指出错误。
3、包含的工具
Binutils是GNU工具之一,它包括链接器、汇编器和其他用于目标文件和档案的工具,它是二进制代码的处理维护工具。
Binutils工具包含的子程序如下:
- ld - GNU链接器;
- as - GNU汇编器;
- gold - 一个新的,更快的ELF链接器;
- addr2line - 把地址转换成文件名和所在的行数;
- ar - 用于创建,修改和提取档案的实用程序;
- c ++ filt-过滤以解编码编码的C ++符号;
- dlltool-创建用于构建和使用DLL的文件;
- elfedit-允许更改ELF格式文件;
- gprof-显示分析信息;
- nlmconv-将目标代码转换为NLM;
- nm-列出目标文件中的符号;
- objcopy-复制并转换目标文件;
- objdump-显示目标文件中的信息;
- ranlib-生成指向档案内容的索引;
- readelf-显示来自任何ELF格式对象文件的信息;
- size -列出的对象或归档文件的部分的尺寸;
- strings -列出文件中的可打印字符串;
- strip - 丢弃的符号;
- windmc -Windows兼容的消息编译器。
- windres -Windows资源文件的编译器。
binutils介绍 binutils详解 详细页面。
3.2 GCC
GNU编译器套件,支持C, C++, Java, Ada, Fortran, Objective-C等众多语言。
3.3 Glibc
Linux上通常使用的C函数库为glibc。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现。
因为嵌入式环境的资源及其紧张,所以现在除了glibc外,还有uClibc和eglibc可以选择,三者的关系可以参见这两篇文章:
3.4 GDB
GDB用于调试程序
4、如何得到交叉编译链
既然明白了交叉编译链的功能,那么在针对嵌入式系统开发时,我们需要的交叉编译链从哪儿得到?
主要有三个方式可以获取
4.1 下载已经做好的交叉编译链
使用其他人针对某些CPU平台已经编译好的交叉编译链。我们只需要找到合适的,下载下来使用即可。
常见的交叉编译链下载地址:
在 http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/ 下载已经编译好的交叉编译链
在 http://www.denx.de/en/Software/WebHome 下载已经编译好的交叉编译链
在https://launchpad.net/gcc-arm-embedded下载已经编译好的交叉编译链
一些制作交叉编译链的工具中,包含了已经制作好的交叉编译链,可以直接拿来使用。如crosstool-NG
如果购买了某个芯片或开发板,一般厂商会提供对应的整套开发软件,其中就包含了交叉编译链。
厂家提供的工具一般是经过了严格的测试,并打入了一些必要的补丁,所以这种方式往往是最可靠的工具来源。
4.2 使用工具定制交叉编译链
使用现存的制作工具,以简化制作交叉编译链这个事情的复杂度。我们只需要了解有哪些工具可以实现,并选个合适的工具,搞懂它的操作步骤即可。
- crosstool-NG
- Buildroot
- Embedded Linux Development Kit (ELDK)
工具还有很多,各有各的优势和劣势,大家可以慢慢研究,在这就不细说了。
4.3 从零开始构建交叉编译链
这个是最困难也最耗时间的,毕竟制作交叉编译链这样的事情,需要对嵌入式的编译原理了解的比较透彻,至少要知道出了问题要往哪个方面去翻阅资料。而且,也是最考耐心和细心的地方,配错一个选项或是一个步骤,都可能出现以前从来没见过的问题,而且这些问题往往还无法和这个选项或步骤直接联系起来。
当然如果搭建出来,肯定也是收获最大的,至少对于编译的流程和依赖都比较清楚了,细节上的东西可能还需要去翻看相应的协议或标准,但至少骨架会比较清楚。
详细的搭建过程可以参看后续的文章,这里面有详细的参数和步骤:
交叉编译详解 二 从零制作交叉编译链
为了方便大家搭建交叉编译链,我写了一个一键生成的脚本(包括源码下载和自动编译)。如果大家自己一直搭建不成功,不妨试试这个脚本,然后对比下自己的流程是否一致,参数是否有差异,也许能帮大家迈过这个障碍:
交叉编译详解 三 使用脚本自动生成交叉编译链
4.4 对比三种构建方式
| 项目 | 使用已有交叉编译链 | 自己制作交叉编译链 |
|---|---|---|
| 安装 | 一般提供压缩包 | 需要自己打包 |
| 源码版本 | 一般使用较老的稳定版本,对于一些新的GCC特性不支持 | 可以使用自己需要的GCC特性的版本 |
| 补丁 | 一般都会打上修复补丁 | 普通开发者很难辨别需要打上哪些补丁,资深开发者可以针对自己的需求合入补丁 |
| 源码溯源 | 可能不清楚源码版本和补丁情况 | 一切都可以定制 |
| 升级 | 一般不会升级 | 可以随时升级 |
| 优化 | 一般已经针对特定CPU特性和性能进行优化 | 一般无法做到比厂家优化的更好,除非自己设计的CPU |
| 技术支持 | 可以通过FAE进行支持,可能需要收费 | 只能通过社区支持,免费 |
| 可靠性验证 | 已经通过了完善的验证 | 自己验证,肯定没有专业人士验证的齐全 |
参考资料
1、Introduction to cross-compiling for Linux
4、 uclibc eglibc glibc之间的区别和联系
5、 Glibc vs uClibc Differences
6、交叉编译链下载地址
- http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/
- http://www.denx.de/en/Software/WebHome
- https://launchpad.net/gcc-arm-embedded
分享原文: http://m6z.cn/6tdD7y
Linux文件的三个时间属性
运维 Ansible 发表了文章 0 个评论 1605 次浏览 2020-10-16 16:45
时间属性介绍
Linux下一个文件通过stat命令可以查看到这个文件时间方面的属性,具体信息如下:
# stat tengine-2.0.0-23tf4566.tar.gz
File: 'tengine-2.0.0-23tf4566.tar.gz'
Size: 35995224 Blocks: 70304 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201842670 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 501/ UNKNOWN) Gid: ( 20/ games)
Access: 2020-07-30 14:07:46.617759798 +0000
Modify: 2020-07-30 12:57:35.000000000 +0000
Change: 2020-10-16 06:20:13.535869875 +0000
Birth: -
如上所示,可以看出来分别有Access Modify Change 三个关于时间的属性。
此三个属性初始时间记录都是文件被创建的时间:
- Access 指最后一次读取的时间(访问)
- Modify 指最后一次修改数据的时间(修改)
- Change 指最后一次修改元数据的时间(改变)
Access的意思是访问:
在终端上用cat、more 、less、grep、sed、 cp 、file 一个文件时,此文件的Access的时间记录都会被更新(空文件例外),纯粹的access是不会影响modify和change,但会受到modify行为的影响。
用ls -lu看到的文件时间是最近一次access的时间。对于目录而言,只是进入目录的话不会改变它的access时间,但只要用ls查看了此目录的内容(无论在何处),这个目录的access时间就会被更新。
Modify 意思是更改(内容)or 写入:
当更改了一个文件的内容的时候,此文件的modify的时间记录会被更新。用ls -l看到的文件时间是最近一次modify的时间。modify的行为是三个行为中最有影响力的行为,它发生以后,会使文件的access记录与change记录也同时得到更新, 对于目录亦是如此。
Change 改变(状态或属性):
对一个文件或者目录作mv、chown、chgrp操作后,它的Change时间记录被更新,change时间会受到modify行为的影响。用ls -lc看到的文件时间是最近一次change的时间。
# stat test.txt
File: ‘test.txt’
Size: 10 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201843904 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-10-16 06:44:21.925299516 +0000
Modify: 2020-10-16 06:44:21.925299516 +0000
Change: 2020-10-16 06:44:21.925299516 +0000
Birth: -
# cat test.txt
lucky boy
# stat test.txt
File: ‘test.txt’
Size: 10 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201843904 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-10-16 06:44:43.911988787 +0000
Modify: 2020-10-16 06:44:21.925299516 +0000
Change: 2020-10-16 06:44:21.925299516 +0000
Birth: -
如上用cat命令将文件test.txt的内容输出到终端( 执行 cat test.txt), 那么文件test.txt只有的Access被刷新。
# date >> test.txt
# stat test.txt
File: ‘test.txt’
Size: 39 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201843904 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-10-16 06:44:43.911988787 +0000
Modify: 2020-10-16 06:46:56.760155796 +0000
Change: 2020-10-16 06:46:56.760155796 +0000
Birth: -
如上把当前的时间追加到test.txt(执行 date >> test.txt) , 那么test.txt的Modify和Change都被刷新。
# chmod 777 test.txt
# stat test.txt
File: ‘test.txt’
Size: 39 Blocks: 8 IO Block: 4096 regular file
Device: 802h/2050d Inode: 201843904 Links: 1
Access: (0777/-rwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2020-10-16 06:44:43.911988787 +0000
Modify: 2020-10-16 06:46:56.760155796 +0000
Change: 2020-10-16 06:48:45.676571600 +0000
Birth: -
如上把test.txt的权限改为777(执行 chmod 777 test.txt) , 那么只有test.txt的Change被刷新。
假如我们用vi命令把文件test.txt打开, 然后保存退出,那么test.txt的Access、Modify和Change都会被刷新。
同时我们也可以使用命令touch更新test.txt的Access和Modify时间:
touch -d 1999-01-01 test.txt // 将test.txt的Access和Modify时间改为1999-01-01
touch -a test.txt // 只将test.txt的Access时间改为当前系统时间
touch -m test.txt // 只将test.txt的Modify时间改为当前系统时间
当我们用ls -l test.txt看到的时间就是Modify时间。
按照时间排序文件
# ls -l
-rw-r--r-- 1 501 games 35995224 Jul 30 12:57 tengine-2.0.0-23tf4566.tar.gz
-rw-r--r-- 1 501 games 4321420 Jul 22 14:15 tengine-2.0.0-45axfa54.tar.gz
-rw-r--r-- 1 501 games 33238934 Jul 22 15:20 tengine-2.0.0-64af1234.tar.gz
如上有3个文件,如果按照时间排序呢?
按照修改时间排序:
ls -alt 等价于 ls --sort=time -la
按照创建时间排序:
ls -alc
按访问时间排序:
ls -alu
以上均可使用-r实现逆序排序
ls -alrt # 按修改时间排序
ls --sort=time -lra # 等价于> ls -alrt
ls -alrc # 按创建时间排序
ls -alru # 按访问时间排序
不管你是根据什么排序,加上-r 就会反序。
CentOS系统自动下载RPM包及其所有依赖的包
运维 Ansible 发表了文章 0 个评论 10500 次浏览 2017-10-08 19:15
方法1利用"Downloadonly"插件下载 RPM 软件包及其所有依赖包
我们可以通过 yum 命令的 “Downloadonly” 插件下载 RPM 软件包及其所有依赖包, 为了安装 Downloadonly 插件,以 root 身份运行以下命令:
yum install yum-plugin-downloadonly现在,运行以下命令去下载一个 RPM 软件包
yum install --downloadonly默认情况下,这个命令将会下载并把软件包保存到 /var/cache/yum/ 的 rhel-{arch}-channel/packageslocation 目录,不过,你也可以下载和保存软件包到任何位置,你可以通过 –downloaddir 选项来指定。
yum install --downloadonly --downloaddir=例子:
yum install --downloadonly --downloaddir=/root/mypackages/ httpd终端输出:
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: centos.excellmedia.net
* epel: epel.mirror.angkasa.id
* extras: centos.excellmedia.net
* updates: centos.excellmedia.net
Resolving Dependencies
--> Running transaction check
---> Package httpd.x86_64 0:2.4.6-40.el7.centos.4 will be installed
--> Processing Dependency: httpd-tools = 2.4.6-40.el7.centos.4 for package: httpd-2.4.6-40.el7.centos.4.x86_64
--> Processing Dependency: /etc/mime.types for package: httpd-2.4.6-40.el7.centos.4.x86_64
--> Processing Dependency: libaprutil-1.so.0()(64bit) for package: httpd-2.4.6-40.el7.centos.4.x86_64
--> Processing Dependency: libapr-1.so.0()(64bit) for package: httpd-2.4.6-40.el7.centos.4.x86_64
--> Running transaction check
---> Package apr.x86_64 0:1.4.8-3.el7 will be installed
---> Package apr-util.x86_64 0:1.5.2-6.el7 will be installed
---> Package httpd-tools.x86_64 0:2.4.6-40.el7.centos.4 will be installed
---> Package mailcap.noarch 0:2.1.41-2.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
=======================================================================================================================================
Package Arch Version Repository Size
=======================================================================================================================================
Installing:
httpd x86_64 2.4.6-40.el7.centos.4 updates 2.7 M
Installing for dependencies:
apr x86_64 1.4.8-3.el7 base 103 k
apr-util x86_64 1.5.2-6.el7 base 92 k
httpd-tools x86_64 2.4.6-40.el7.centos.4 updates 83 k
mailcap noarch 2.1.41-2.el7 base 31 k
Transaction Summary
=======================================================================================================================================
Install 1 Package (+4 Dependent packages)
Total download size: 3.0 M
Installed size: 10 M
Background downloading packages, then exiting:
(1/5): apr-1.4.8-3.el7.x86_64.rpm | 103 kB 00:00:01
(2/5): apr-util-1.5.2-6.el7.x86_64.rpm | 92 kB 00:00:01
(3/5): mailcap-2.1.41-2.el7.noarch.rpm | 31 kB 00:00:01
(4/5): httpd-tools-2.4.6-40.el7.centos.4.x86_64.rpm | 83 kB 00:00:01
(5/5): httpd-2.4.6-40.el7.centos.4.x86_64.rpm | 2.7 MB 00:00:09
---------------------------------------------------------------------------------------------------------------------------------------
Total 331 kB/s | 3.0 MB 00:00:09
exiting because "Download Only" specified

现在去你指定的目录位置下,你将会看到那里有下载好的软件包和依赖的软件。在我这种情况下,我已经把软件包下载到 /root/mypackages/ 目录下。
让我们来查看一下内容:
ls /root/mypackages/样本输出:
apr-1.4.8-3.el7.x86_64.rpm
apr-util-1.5.2-6.el7.x86_64.rpm
httpd-2.4.6-40.el7.centos.4.x86_64.rpm
httpd-tools-2.4.6-40.el7.centos.4.x86_64.rpm
mailcap-2.1.41-2.el7.noarch.rpm

正如你在上面输出所看到的, httpd软件包已经被依据所有依赖性下载完成了 。
请注意,这个插件适用于 yum install/yum update, 但是并不适用于 yum groupinstall。默认情况下,这个插件将会下载仓库中最新可用的软件包。然而你可以通过指定版本号来下载某个特定的软件版本。
例子:
yum install --downloadonly --downloaddir=/root/mypackages/ httpd-2.2.6-40.el7此外,你也可以如下一次性下载多个包:
yum install --downloadonly --downloaddir=/root/mypackages/ httpd vsftpd
方法 2 使用 "Yumdownloader"工具来下载 RPM 软件包及其所有依赖包
“Yumdownloader” 是一款简单,但是却十分有用的命令行工具,它可以一次性下载任何 RPM 软件包及其所有依赖包。
以 root 身份运行如下命令安装 “Yumdownloader” 工具。
yum install yum-utils一旦安装完成,运行如下命令去下载一个软件包,例如 httpd:
yumdownloader httpd为了根据所有依赖性下载软件包,我们使用 --resolve 参数:
yumdownloader --resolve httpd默认情况下,Yumdownloader 将会下载软件包到当前工作目录下。
为了将软件下载到一个特定的目录下,我们使用 --destdir 参数:
yumdownloader --resolve --destdir=/root/mypackages/ httpd或者
yumdownloader --resolve --destdir /root/mypackages/ httpd终端输出:
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: centos.excellmedia.net
* epel: epel.mirror.angkasa.id
* extras: centos.excellmedia.net
* updates: centos.excellmedia.net
--> Running transaction check
---> Package httpd.x86_64 0:2.4.6-40.el7.centos.4 will be installed
--> Processing Dependency: httpd-tools = 2.4.6-40.el7.centos.4 for package: httpd-2.4.6-40.el7.centos.4.x86_64
--> Processing Dependency: /etc/mime.types for package: httpd-2.4.6-40.el7.centos.4.x86_64
--> Processing Dependency: libaprutil-1.so.0()(64bit) for package: httpd-2.4.6-40.el7.centos.4.x86_64
--> Processing Dependency: libapr-1.so.0()(64bit) for package: httpd-2.4.6-40.el7.centos.4.x86_64
--> Running transaction check
---> Package apr.x86_64 0:1.4.8-3.el7 will be installed
---> Package apr-util.x86_64 0:1.5.2-6.el7 will be installed
---> Package httpd-tools.x86_64 0:2.4.6-40.el7.centos.4 will be installed
---> Package mailcap.noarch 0:2.1.41-2.el7 will be installed
--> Finished Dependency Resolution
(1/5): apr-util-1.5.2-6.el7.x86_64.rpm | 92 kB 00:00:01
(2/5): mailcap-2.1.41-2.el7.noarch.rpm | 31 kB 00:00:02
(3/5): apr-1.4.8-3.el7.x86_64.rpm | 103 kB 00:00:02
(4/5): httpd-tools-2.4.6-40.el7.centos.4.x86_64.rpm | 83 kB 00:00:03
(5/5): httpd-2.4.6-40.el7.centos.4.x86_64.rpm | 2.7 MB 00:00:19

让我们确认一下软件包是否被下载到我们指定的目录下:
ls /root/mypackages/终端输出:
apr-1.4.8-3.el7.x86_64.rpm
apr-util-1.5.2-6.el7.x86_64.rpm
httpd-2.4.6-40.el7.centos.4.x86_64.rpm
httpd-tools-2.4.6-40.el7.centos.4.x86_64.rpm
mailcap-2.1.41-2.el7.noarch.rpm

不像 Downloadonly 插件,Yumdownload 可以下载一组相关的软件包。
yumdownloader "@Development Tools" --resolve --destdir /root/mypackages/在我看来,我喜欢 Yumdownloader 更胜于 Yum 的 Downloadonly 插件。但是,两者都是十分简单易懂而且可以完成相同的工作。
这就是今天所有的内容,如果你觉得这份引导教程有用,清在你的社交媒体上面分享一下去让更多的人知道。
阅读分享,英文:https://www.ostechnix.com/download-rpm-package-dependencies-centos/ 中文:https://linux.cn/article-7937-1.html
VMware克隆Centos主机后网卡信息配置详解
运维 push 发表了文章 0 个评论 2972 次浏览 2017-07-30 17:21
1、修改udev规则文件获取Mac地址
/etc/udev/rules.d/70-persistent-net.rules 这个文件跟你的网卡mac地址有关系,当你的网卡启动的时候这个文件会分配一个网卡名称给你的网卡。
# vim /etc/udev/rules.d/70-persistent-net.rules
- 该文件中正常此时应该有两行信息
- 在文件中把 NAME="eth0″ 的这一行注释掉
- 对于另一行,把 NAME=”eth1″ 的这一行,把 NAME=”eth1″ 改为 NAME=”eth0″,并且把该行:ATTRS{address}=="00:0c:29:58:0d:5a″ 这个属性信息记下来,后面修改Mac地址就使用这个。

2、修改eth0网卡Mac地址配置
为什么要修改,因为跟克隆母机的Mac地址一样,在同一个内网内会冲突,修改前:

# vim /etc/sysconfig/network-scripts/ifcfg-eth0把 HWADDR 的值改为上面要求记下来的:00:0c:29:58:0d:5a

到这里网卡的Mac地址已经修改完成,跟母机的不一样了,这样就不会冲突了。
3、获取并修改UUID
维基百介绍UUID:
通用唯一识别码(英语:Universally Unique Identifier,简称UUID)是一种软件建构的标准,亦为自由软件基金会组织在分散式计算环境领域的一部份。
UUID的目的,是让分散式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其它人冲突的UUID。在这样的情况下,就不需考虑数据库创建时的名称重复问题。目前最广泛应用的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LUKS加密分区、GNOME、KDE、Mac OS X等等。另外我们也可以在e2fsprogs包中的UUID库找到实现。
获取UUID:获取UUid我们可以通过两种方式,1是通过uuidgen命名,二是通过读取文件/proc/sys/kernel/random/uuid
我们这里功能uuidgen命名获取:
# a=`uuidgen eth1`
# sed -i "s@UUID.*@UUID=${a}@g" ifcfg-eth0

到这里就Mac地址和UUID都全部替换完成,跟母机的完全不一样了。
4、重启网卡获取IP地址
# /etc/init.d/network restart

如上图可以看出获取IP地址正常,Mac地址也是我们修改后的,好了到这里就都完成了,完成后,方便后面实验,最好新建的主机都创建初始的快照。
不仅是 Linux 运维最佳实践
运维 OS小编 发表了文章 0 个评论 2573 次浏览 2017-06-30 00:07
@xufengnju(胥峰),资深运维专家,有 10 年运维经验,在业界颇具威望和影响力。也是盛大游戏高级研究员,2006 年毕业于南京大学,2011 年加入盛大游戏,工作至今,曾参与盛大游戏多款大型端游和手游的上线运维,主导运维自动化平台的功能设计和实施。拥有工信部认证高级信息系统项目管理师资格。
自动化运维在近几年一直都是很火热的话题,技术也一直在进步,因此对于技术人员来说,最重要的思维上、思想上的适应与转变。毕竟技术不是运维的终极追求,思想才是运维人员应该毕生修炼的目标!本次高手问答的高手嘉宾对运维服务体系有着深度的思考,因此问答中产生的内容也是十分有质量。
本文从多个角度整理了与运维相关的内容,包括工具的选择、运维中遇到的问题、自动化运维相关等等。
Q&A
一、工欲善其事必先利其器,如何选择工具?
1. 对服务器安全和监控,可以推荐一些开源工具吗?监控好像也就 nagios, cacti, zabbix,还有其他可以推荐的吗?安全方面如何监控?
监控工具各有侧重点,zabbix 同时支持 snmp 和自己的 agent,也支持自定义模板,在大部分场景下都是不错的选择。
另外,不要把 zabbix 视为只能监控服务器信息,通过自定义模板,也可以监控业务层面的指标。安全监控分为主动检测,如 Tenable Nessus,以及 IDS、IPS。
2. Linux 运维中,服务器版本都用什么版本?CentOS 5 还是 CentOS 6、Ubuntu?为什么选择这个版本?有做哪些测试?
目前我们以 CentOS6.X 为主。不同 Linux 分支各有特点,比如 Ubuntu 新版本发布较快,如果追求内核版本升级速度的话,可以考虑。CentOS 一直是我们的主要 Linux 发行版,主要是考虑到它的稳定性以及熟悉程度最高。
3. 对于使用缓存有什么推荐吗?一般就 Redis, Codis。还有那些比较好用的开源软件?
对于类似 session-id 这样的可以非持久存储的数据,可以考虑 memcached,使用一致性哈希算法分布式存储。
4. 做自动化发布,除了 Jenkins 持续集成工具,还有那些好用的工具呢?
目前我所知道的,一般都是 Hudson 或者 Jenkins,后者是前者分支出来的。这些工具都有丰富的插件,灵活使用这些插件是关键所在。
5. 问个 MySQL 问题,三个版本(MySQL(官方版本)、Percona Server 、MariaDB)您建议使用哪个版本,原因是?
我们团队一般使用的是官方版本。主要是考虑到支持和生态。
6. 服务器日志收集和分析有什么好工具推荐吗?ELK 貌似有点复杂,不太会用,有其他的推荐么?
ELK 确实是目前使用比较广泛的日志收集和分析的工具。虽然有些学习成本,但还是值得去研究和尝试的。
7. 书里有开源出一些工具和脚本吗,哪里可以下载到?
书上的脚本我正在整理,其中一部分通过 git 可以下载 https://github.com/xufengnju/books.git
8. 请问你们现在运维都是基于 Ansible 吗?我们之前都是用 chef puppt 来管理。最近感觉 Ansible 很火,还没实践用过,请问这个用起来差别大吗?
各种不同的批量管理工具各具特点,根据自己的熟悉程度和实际业务需要选择一个完全掌握即可
目前 IaaS 平台是自研的,基于 KVM
二、绝知此事要躬行,运维中遇到问题?1. LVS 和 HAPROXY 后端服务器规模可以到什么程度,比如有多少个应用,多少台后端服务器?
这个取决于应用的类型,在实际的业务场景下,需要关注 LVS 等负载均衡器本身的连接数、PPS 数据以及延迟。如果后端吞吐量比较大,可以考虑 LVS 的 DR 模式。一般情况下,负载均衡器不太会成为瓶颈。
负载均衡器本身的连接数、PPS 数据以及延迟如何进行计算和统计?
通过开源的 Zabbix 模板或者自定义模板,这些都不难实现。有没有相关的命令集进行统计,或者详细的统计实例?
针对 HAProxy 建议参考咱们书中 P76 页最佳实践 29 HAProxy 监控的内容。Zabbix 模板技术,建议参考下咱们书中第 12 章的内容。可以使用的命令包括 ipvsadm,netstat 等。
2. 对于涉及多个平台(Unix, Linux, Windows)的统一管理(认证,配置,服务)有什么好的解决方案或者思路么?
先说下认证这一块吧。Unix、Linux 都支持 OpenLDAP 认证,可以考虑,这个和 Windows 下的 AD 是兼容的。配置和服务可以考虑下开源的通用产品,比如 Ansible 或者 Salt。目前我们用的自研系统,思路和 Ansible 类似。
3. 如何监控服务,业务运行状态监控你是怎么做的?
我们的监控系统是自研的,对游戏来说,很重要的一个业务指标是在线人数,它是通过监控系统周期性轮询游戏服务器来进行收集和绘制图表的。
4. 你们是如何批量管理各个业务模块的机器系统及配置的。我们目录使用 Ansible 使用批量命令和脚本,业务上使用上线平台 SVN 管理业务程序及配置。是否开发了 CMDB 平台?
我们批量管理服务器的方式是 ssh,思路和 Ansible 类似。CMDB 提供基础数据的管理,是自研的。
5. 请问有使用过流量镜像吗?就是把线上的流量镜像一份,引到测试环境,用真实的用户数据测试,想了解下从 0 开始实施的过程。
关于流量镜像的原理,可以参考《Linux 运维最佳实践》第 15 章中网卡混杂模式和 RawSocket 技术。看了这一部分后,你应该可以自己写一套。我没有亲自实践过,你可以自己关注下 tcpcopy 这个项目。
6. CentOS 6 要如何做系统和网络优化?/etc/sysctl.conf 中的这个参数
net.ipv4.tcp_max_tw_buckets = 6000要如何设置,是越多越好吗?设置成 16000?
net.ipv4.tcp_max_tw_buckets = 16000
对于系统优化来说,要有针对性。tcp_max_tw_buckets 针对的是 time wait bucket,如系统中 timewait 状态较多,可以考虑 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_tw_recycle 这 2 个值调整。另外,如果使用长连接对于减少该状态的连接数有效。
7. 如果有 100 多台服务器,大部分都是在提供业务的服务器,如何升级呢?除了停机维护,现在有什么比较好的解决方案吗?
如果本身业务切分比较好,例如采用无状态的微服务等架构,可以通过前端负载均衡器进行灰度升级。如果应用做的不好,只有单台的这种,或者集中数据库,就比较麻烦了。
8. LVS 和 HAPROXY 分别能支持多少类似 FARM 的概念?
你说的 FARM 应该是某硬件负载均衡设备的专有名词,应该是负载均衡组的概念。在 LVS 和 HAProxy 里面,负载均衡组的数量上没有硬限制,但实践中一般不会配置太多,因为这涉及到维护成本以及 HA 环境下主备切换时的开销。
9. 系统是 CentOS release 6.5 (Final), 系统没有自动回收内存,16G,我自己写了个 Shell 脚本,每次执行判断小于 1G 的时候回收内存
可以关注下 sysctl 中 swap 以及 swappiness 的一些配置
10. 请问如果是有很多 ECS/VPS,系统一般是 CentOS。目前很多堡垒机也有类似的 SSH 同步密钥下发命令等功能,但是如果还有 Win的堡垒机支持很少。有别的开源工具或者办法来混合管理所有的 Linux, Windows 机器吗?
在我的这个演讲里面讲到了异构系统的批量管理方法,你可以参考下。
http://www.build.net/greatops/453250.html 。另外,你可以参考下 Ansible 或者 salt。
三、自动化运维相关,工程师思维?
1. 可以说下什么是自动化运维,如何才算服务器做了自动化运维?包括哪些?自动化发布,有问题可以回滚?
运维自动化是一个仁者见仁智者见智的概念。我的理解是,运维自动化要打通从代码开发完到正式上线的所有环节,包括版本构建、打通自动测试、自动化上线以及自动化监控。
在这个大命题下,可以根据自己工作环境和自动化水平的不同,选择一两个痛点开始进行自动化实践。最后形成完整体系。
2. 想请问一下自动化运维怎么做的?需要从那些方面考虑?我所考虑到的有实施运维,日常巡检维护,以及故障自动化处理,和提醒。除了这些请问还要注意那些方面?另外,随着 IT 技术的日新月异,涌现了很多新的应用,请问该如果有一个基本的路子来做运维,或者规律,流程来达到运维需求?例如现在比较火的OpenStack Docker 大数据。这些技术实现功能只是很小的一步,更多的是上线后的运维。更多是想要一种思路,能列举大家遇到过的问题,以及问题如何处理?
你的问题很好,但这个话题比较大。我先说下我的理解吧。传统的运维服务流程 ITIL 还有一定的价值,但需要结合一些 DevOps 思想来进行适当的改造,融合两者的长处。从拥抱变化开始,以一种开放的态度来进行运维。但不变的一点是,以为业务创造价值为最终目标,这就是运维的目标。
3. 实现运维自动化,最主要就是配置管理、状态管理和变更管理,其中配置管理要如何来做,有什么好的方法分享下吗?
对配置管理,我认为应该分为“基础架构资源配置管理”和“软件/应用配置管理”。
前者是一般意义上的 CMDB 的范畴,这个可以根据自己业务特点在开源 CMDB 方案的基础上做一定的适配;
对于后者,一方面是系统(例如版本控制系统的结合),一方面是流程(例如和变更管理挂钩)。在我们的实践中,这 2 个方面都有涉及。
4. 请问你主导运维自动化平台的功能设计和实施,是通过 Python 开发管理工具吗?另外,你们是重新开发,还是根据 Saltstack 之类的进行二次开发。
底层使用 SSH 协议建立服务器管理通道,上层使用 PHP 开发管理界面以及封装一些常用操作,比如密码修改、脚本下发和执行等。完全自主开发。
四、做好安全措施很重要,安全相关的问题1. 运维离不开安全,服务器的安全也很重要,书中有讲运维安全这块吗,如何把控安全这块?
书中有安全主题。安全是一个庞大的体系,书中主要讲了保障 Linux 系统安全的一些措施。其他安全主题,比如社会工程和入侵检测,可能需要看更专业的书。你可以先看看咱们《Linux 运维最佳实践》是否能满足你的基本安全需求。谢谢支持。
2. Web 安全监控有开源解决方案吗,能否做到在接入层就把一些可能的漏洞拦掉?Suricata?
Suricata 没有研究和实践过。《Linux 运维最佳实践》中第 11 章 Web 服务器安全部分提到了几个工具,你可以参考下。但 ModSecurity 规则在上线前要进行严格详细测试,不要出现误判。另外,建议对生产环境进行定期的安全扫描,例如使用 Tenable Nessus 工具等。安全专家的人工渗透测试也是必须的。
五、Docker 很火热,在运维中结合使用?1. 在网易游戏运维中是否用到了最近很火的 Docker 技术以及应用在哪,存在什么问题,如何解决?
目前我们在调研 Docker 技术,只有少量游戏测试使用。需要根据不同的业务模型选择对应的网络模型和存储方案。Docker 技术会改变传统的运维方式,要考虑和原有运维系统整合以及运维习惯的调整所带来的挑战。另外,我不是网易公司的,我目前在盛大游戏工作。
2. Docker 化对运维影响深远吗?
Docker 化对运维有影响,它带来的影响包括:持续交付、微服务以及 DevOps 理念的冲击。作为运维,我们要拥抱这个变化,通过不断学习和实践来迎接这些挑战。
3. 为何国内没有一家成熟的 Docker 方案公布细节呢?
Docker 还是一个新生事物,各家使用的场景和模式有所不同,而且会有一些二次开发的管理系统和调度系统。
六、不是所有对比都会产生伤害,工程师想的只是最优方案1. 游戏服务器运维和网站服务器运维以及 APP 服务器运维,有哪些不同点和相同点?
这个问题很有代表性。不同点是,网站和 APP 运维接触的通用开源软件比较多,游戏运维接触的大部分都是自研的程序。
共同点是,都需要掌握操作系统知识、软件硬件以及网络知识,还有排查问题的思路和容量规划等。两者都需要引入运维自动化的思维和体系。《Linux 运维最佳实践》最后 2 章描述了游戏运维的相关体系和技术。
2. 作为运维人员,Python 这样的脚本在进行系统管理和监控的时候相比 Shell 有怎样的优势呢?
作为高级编程语言,Python 有非常丰富的库,包括核心库和第三方库,很多时候不需要自己造轮子;
相比 Shell,它有更好的控制力、重试机制,比如对 Socket 设置超时等等。
3. CentOS 比起 Ubuntu 来说有啥优势?为什么服务器大多用 CentOS?
不同 Linux 分支各有特点,比如 Ubuntu 新版本发布较快,如果追求内核版本升级速度的话,可以考虑。CentOS 一直是我们的主要 Linux 发行版,稳定性以及熟悉程度最高。
选择某个发行版时,要考虑它的生态,比如上下游的支持,还有一点,就是运维人员招聘的方便程度,国内熟悉 CentOS 的稍多一些。
4. 想问下只有一台服务器,有多个应用,是用 LVS 做负载好还是 Nginx?差别大吗?
你说的后端应用是基于 HTTP 或者 HTTPS 的吗?如果是的话,并且吞吐量不大的情况下,使用 Nginx 即可;如果非 HTTP 或者 HTTPS 的 TCP 应用,建议使用 LVS;如果 HTTP 或者 HTTPS 吞吐量特别大的情况下,使用 LVS DR 模式。
七、You Need Backup,与备份相关的一些问题1. 1000 台机器规模,备份系统应该要做到什么程度?
1000 台服务器,要区分业务类型,如果类型单一,备份就比较好做。如果类型多,那么要考虑的地方包括:数据库更新的频率(全备+增量备份?还是只使用全备)、数据备份的大小、数据集中归档的要求。
2. 备份是怎么做的?上百 T 的图片、附件有什么高雅的备份方案?
在线备份这一块,可以考虑使用 erasure coding 算法,在增加一定可靠性的能力下,不至于导致备份存储的成本过高。同时要考虑离线备份,比如磁带。
八、路漫漫其修远兮,运维工程师的职业生涯1. 你觉得在未来,运维的核心会是什么,自动化,预判或是其他?
我觉得,未来的运维应该是智能化的。把现在需要人做的容量规划、扩缩容、排障全部实现智能化。运维的任务就是编程,把自己的能力灌输到机器上。当然,理想很丰满,现实很骨感。这需要我们的不懈努力。
2. 作为工作 4 年多的测试工作者,在运维方面也是有一定的涉猎,在公司维护自己的测试环境,有时候也需要一定运维功底,从 Windows Server 到 Linux,学习很多,也总结了很多。上家公司着手 Docker 部署的时候刚好离开公司了。真是有点遗憾,后续工作也没时间去实践,目前使用的是 ng 负载,采用 Tomcat 部署方案,工作实在比较忙,很想在运维方面也有一定的提升!不知道从何入手好,求大神指教。
从你的描述来看,目前是兼职运维。我建议是否可以考虑,在搭建环境之外,多多研究下其中的原理,同时用自动化脚本维护这些环境呢。相信你也有一些编程经验,这些对于你后续实践运维也是有帮助的。另外,就是可以多看看别人总结的运维案例,少走一些弯路。
3. 运维技术挺杂的,如何看待这种杂?给人感觉好像什么都会点,对于工作 5-6 年的运维来说,有什么好的学习建议?
4. 由于运维系统有全面的数据收集、自动处理、报警和自动恢复的机制,我们这里将运维和 BI 结合在一起。扩展运维工具和架构,将已成熟的 BI 接入运维体系,解放业务专员的工作,常规的业务分析、报表、数据监控都可依赖这套运维系统。在我们这里,运维从一层平台逐渐变成一种框架,有需要的场景都可以套用。技术一直在变,但最重要的不是技术,而是用技术提供服务的思想。 除了和 BI 结合,运维思维还可以和哪些相关业务场景结合,可以在新的方向上产生价值呢?
如你所说,运维技术要求范围确实蛮广的。我觉得,对于工作了一定时间的运维同学来说,可以考虑的方向有以下几个:
- DevOps 实践(加强自己的编程能力,系统学习一门高级编程语言,运维自动化)
- 对自己的技术薄弱点重点学习,比如系统学习网络知识
- 看一些比较好的运维技术书籍,学习别人的干货
5. Devops 对运维有那些改变,能简单说下嘛?我很赞同你的想法和实践,“用技术提供服务的思想”。我个人认为,运维的终极目标可能是“没有运维工程师的”自运维,或者叫智能运维,是 AI 在运维领域的深度融合和实践。容量规划算法的不断优化、基于公有云的资源自动调度都应该是智能化的。当然,实现这个目标还有很长的路要走。
6. 现在哪个版本的 Linux 使用最广泛,还有 Linux 运维,我们需要学习一些语言吗,比如 Python 之类,这样才能算是一个真正的好运维?Devops 从概念提出到现在已经有一段比较长的时间了,总体来说,我认为它带来的变化是:持续交付能力需要打通研发、测试和部署运维的整个链路,它对运维自动化的能力要求更高了。我们必须通过掌握一些运维自动化框架加上一定的编程能力才能根据业务场景来应对这种变化。另外,对运维来说,就是要拥抱变化,以开放的态度进行协作。
7. 请问您写书,是怎么坚持写下来的?是把平时工作重点的问题,记录下来,每天写一点,再总结吗?写书有什么工具软件吗,还是只是用 Word 来写?能分享下写运维书籍的方法吗?不要犹豫了,立即开始学习编程吧,不管 Perl 还是 Python,熟悉哪一种都行。在这里,我不对比 Perl 和 Python 的优缺点。坚持用自己的代码(加上别人的框架和库)来解决重复的运维问题,你会成长的更快。CentOS 用的比较多。《Linux 运维最佳实践》第 18 章是使用 Perl 进行系统自动化编程的内容,你可以先看看。如果感兴趣的话,立即开始吧。
这个问题非常好,也是我想分享的。写书的素材依赖于平时的积累,建议大家平时多写写标准的文档,word 格式可以参考咱们这本书的编排。比较重要的 3 点是:
- visio 图要保留下来,不能只存图片,因为可能还要调整排版
- 有些故障现场,尽量记录详细,现象和分析过程、辅助的日志和抓包文件等,建议都保留下来
- 脚本按照分类保存下来,以便查找
有关 Linux 运维最佳实践的问答内容至此结束,各位读者可以转到原帖浏览更多内容。
原文:运维技术干货 — 不仅是 Linux 运维最佳实践 。

