
通知设置 新通知
mysql创建和删除表
Ansible 发表了文章 0 个评论 4177 次浏览 2015-06-26 19:15
简单的方式:
CREATE TABLE person (或者是
number INT(11),
name VARCHAR(255),
birthday DATE
);
CREATE TABLE IF NOT EXISTS person (
number INT(11),
name VARCHAR(255),
birthday DATE
);
查看mysql创建表:
> SHOW CREATE table person;
CREATE TABLE `person` (
`number` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`birthday` date DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
查看表所有的列:
> SHOW FULL COLUMNS from person;
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| Field | Type | Collation | Null | Key | Default | Extra | Privileges | Comment |
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
| number | int(11) | NULL | YES | | NULL | | select,insert,update,references | |
| name | varchar(255) | utf8_general_ci | YES | | NULL | | select,insert,update,references | |
| birthday | date | NULL | YES | | NULL | | select,insert,update,references | |
+----------+--------------+-----------------+------+-----+---------+-------+---------------------------------+---------+
创建临时表
CREATE TEMPORARY TABLE temp_person (
number INT(11),
name VARCHAR(255),
birthday DATE
);
在创建表格时,您可以使用TEMPORARY关键词。只有在当前连接情况下,TEMPORARY表才是可见的。当连接关闭时,TEMPORARY表被自动取消。这意味着两个不同的连接可以使用相同的临时表名称,同时两个临时表不会互相冲突,也不与原有的同名的非临时表冲突。(原有的表被隐藏,直到临时表被取消时为止。)您必须拥有CREATE TEMPORARY TABLES权限,才能创建临时表。
如果表已存在,则使用关键词IF NOT EXISTS可以防止发生错误。
CREATE TABLE IF NOT EXISTS person2 (
number INT(11),
name VARCHAR(255),
birthday DATE
);
注意,原有表的结构与CREATE TABLE语句中表示的表的结构是否相同,这一点没有验证。注释:如果您在CREATE TABLE...SELECT语句中使用IF NOT EXISTS,则不论表是否已存在,由SELECT部分选择的记录都会被插入
在CREATE TABLE语句的末尾添加一个SELECT语句,在一个表的基础上创建表
CREATE TABLE new_tbl SELECT [i] FROM orig_tbl;注意,用SELECT语句创建的列附在表的右侧,而不是覆盖在表上mysql> SELECT [/i] FROM foo;也可以明确地为一个已生成的列指定类型
+---+
| n |
+---+
| 1 |
+---+
mysql> CREATE TABLE bar (m INT) SELECT n FROM foo;
mysql> SELECT * FROM bar;
+------+---+
| m | n |
+------+---+
| NULL | 1 |
+------+---+
CREATE TABLE foo (a TINYINT NOT NULL) SELECT b+1 AS a FROM bar;根据其它表的定义(包括在原表中定义的所有的列属性和索引),使用LIKE创建一个空表:
CREATE TABLE new_tbl LIKE orig_tbl;创建一个有主键,唯一索引,普通索引的表:
CREATE TABLE `people` (其中peopleid是主键,以firstname和lastname两列建立了一个唯一索引,以firstname,lastname,age三列建立了一个普通索引
`peopleid` smallint(6) NOT NULL AUTO_INCREMENT,
`firstname` char(50) NOT NULL,
`lastname` char(50) NOT NULL,
`age` smallint(6) NOT NULL,
`townid` smallint(6) NOT NULL,
PRIMARY KEY (`peopleid`),
UNIQUE KEY `unique_fname_lname`(`firstname`,`lastname`),
KEY `fname_lname_age` (`firstname`,`lastname`,`age`)
) ;
删除表
DROP TABLE tbl_name;
或者是
DROP TABLE IF EXISTS tbl_name;
清空表数据
TRUNCATE TABLE table_name
Elasticsearch 分片交互过程详解
Ansible 发表了文章 1 个评论 6282 次浏览 2015-06-18 01:40

一、Elasticseach如何将数据存储到分片中
问题:当我们要在ES中存储数据的时候,数据应该存储在主分片和复制分片中的哪一个中去;当我们在ES中检索数据的时候,又是怎么判断要查询的数据是属于哪一个分片。
数据存储到分片的过程是一定规则的,并不是随机发生的。
规则:shard = hash(routing) % number_of_primary_shards
Routing值可以是一个任意的字符串,默认情况下,它的值为存数数据对应文档 _id 值,也可以是用户自定义的值。Routing这个字符串通过一个hash的函数处理,并返回一个数值,然后再除以索引中主分片的数目,所得的余数作为主分片的编号,取值一般在0到number_of_primary_shards - 1的这个范围中。通过这种方法计算出该数据是存储到哪个分片中。
正是这种路由机制,导致了主分片的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索。
二、主分片与复制分片如何交互
为了说明这个问题,我用一个例子来说明。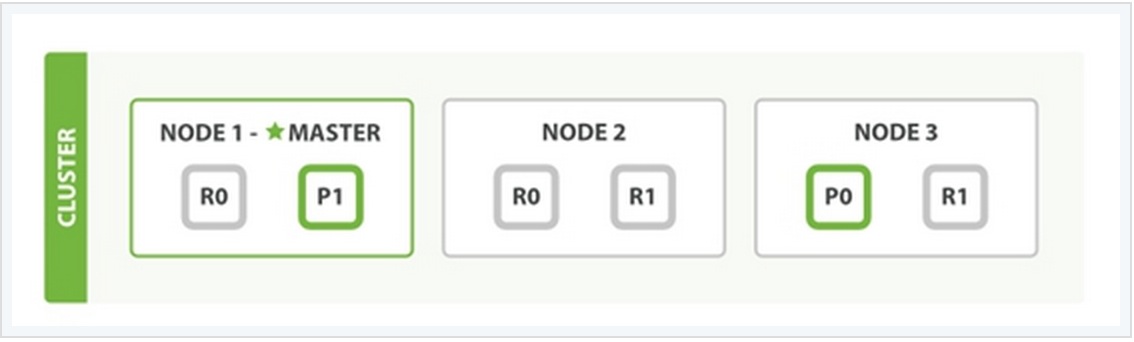
在上面这个例子中,有三个ES的node,其中每一个index中包含两个primary shard,每个primary shard拥有2个replica shard。下面从几种常见的数据操作来说明二者之间的交互情况。
1、索引与删除一个文档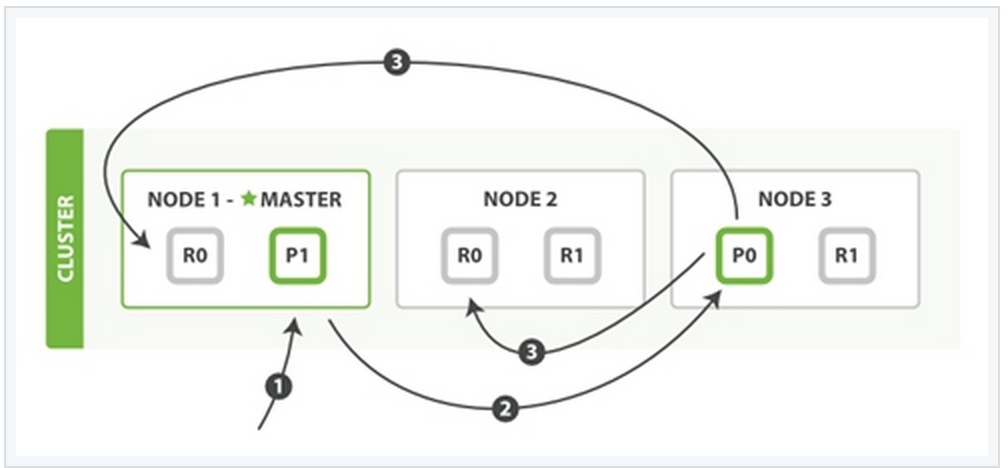
这两种过程均可以分为三个过程来描述:
阶段1:客户端发送了一个索引或者删除的请求给node 1。
阶段2:node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3在shard 0 的primary shard上执行请求。如果请求执行成功,它node 3将并行地将该请求发给shard 0的其余所有replica shard上,也就是存在于node 1和node 2中的replica shard。如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
2、更新一个文档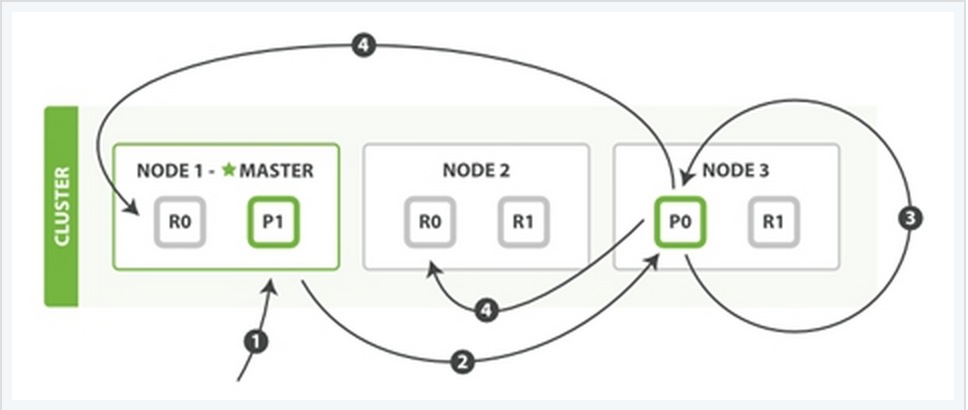
该过程可以分为四个阶段来描述:
阶段1:客户端向node 1发送一个文档更新的请求。
阶段2:同样的node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3从文档所在的primary shard中获取到它的JSON文件,并修改其中的_source中的内容,之后再重新索引该文档到其primary shard中。
阶段4:如果node 3成功地更新了文档,node 3将会把文档新的版本并行地发给其余所有的replica shard所在node中。这些node也同样重新索引新版本的文档,执行后则向node 3确认成功,当node 3接收到所有的成功确认之后,再向客户端发送一个更新成功的信息。
3、检索文档
CRUD这些操作的过程中一般都是结合一些唯一的标记例如:_index,_type,以及routing的值,这就意味在执行操作的时候都是确切的知道文档在集群中的哪个node中,哪个shard中。
而检索过程往往需要更多的执行模式,因为我们并不清楚所要检索的文档具体位置所在, 它们可能存在于ES集群中个任何位置。因此,一般情况下,检索的执行不得不去询问index中的每一个shard。
但是,找到所有匹配检索的文档仅仅只是检索过程的一半,在向客户端返回一个结果列表之前,必须将各个shard发回的小片的检索结果,拼接成一个大的已排好序的汇总结果列表。正因为这个原因,检索的过程将分为查询阶段与获取阶段(Query Phase and Fetch Phase)。
Query Phase
在最初的查询过程中,查询请求会广播到index中的每一个primary shard和replica shard中,每一个shard会在本地执行检索,并建立一个优先级队列(priority queue)。这个优先级队列是一个根据文档匹配度这个指标所排序列表,列表的长度由分页参数from和size两个参数所决定。例如: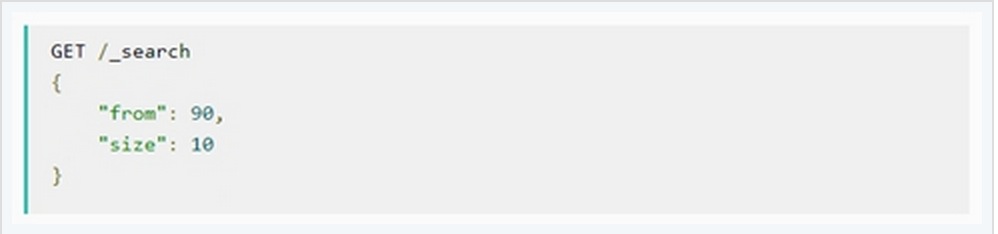
下面从一个例子中说明这个过程:
Query Phase阶段可以再细分成3个小的子阶段:
子阶段1:客户端发送一个检索的请求给node 3,此时node 3会创建一个空的优先级队列并且配置好分页参数from与size。
子阶段2:node 3将检索请求发送给该index中个每一个shard(这里的每一个意思是无论它是primary还是replica,它们的组合可以构成一个完整的index数据)。每个shard在本地执行检索,并将结果添加到本地优先级队列中。
子阶段3:每个shard返回本地优先级序列中所记录的_id与sort值,并发送node 3。Node 3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
Fetch PhaseQuery Phase主要定位了所要检索数据的具体位置,但是我们还必须取回它们才能完成整个检索过程。而Fetch Phase阶段的任务就是将这些定位好的数据内容取回并返回给客户端。
同样也用一个例子来说明这个过程: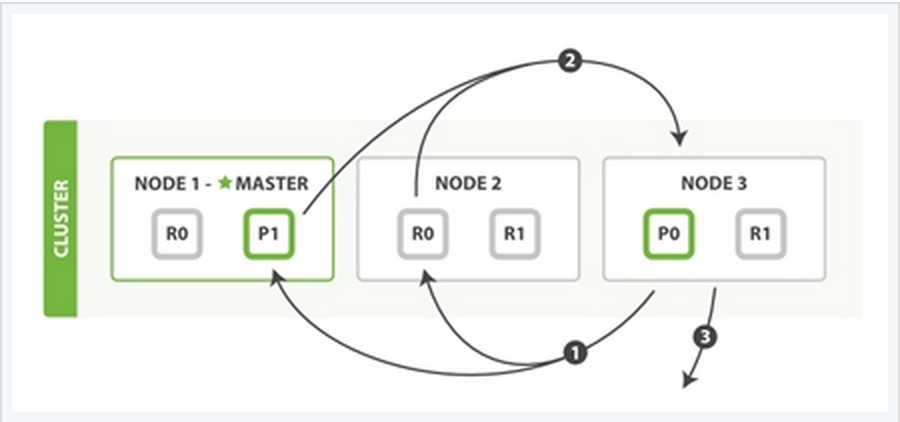
Fetch Phase过程可以分为三个子过程来描述:
子阶段1:node 3获取了所有待检索数据的定位之后,发送一个mget的请求给与数据相关的shard。
子阶段2:每个收到node 3的get请求的shard将读取相关文档_source中的内容,并将它们返回给node 3。
子阶段3:当node 3获取到了所有shard返回的文档后,node 3将它们合并成一条汇总的结果,返回给客户端。





