
通知设置 新通知
编译提示Could NOT find OpenSSL
OS小编 回复了问题 2 人关注 1 个回复 2509 次浏览 2020-12-07 15:06
PostgreSQL编译安装常见报错整理
chris 发表了文章 1 个评论 2528 次浏览 2020-12-07 00:29

PostgreSQL源码安装时如果相关依赖包缺失会导致编译失败,以下是常见的依赖包缺失问题,及解决办法。
依赖安装:
yum install -y perl-ExtUtils-Embed readline-devel zlib-devel pam-devel libxml2-devel libxslt-devel openldap-devel python-devel gcc-c++ openssl-devel cmake
问题1:
checking for flags to link embedded Perl... Can't locate ExtUtils/Embed.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .).BEGIN failed--compilation aborted.
configure: error: could not determine flags for linking embedded Perl.This probably means that ExtUtils::Embed or ExtUtils::MakeMaker is not installed.
解决:
yum install perl-ExtUtils-Embed
问题2:
configure: error: readline library not found If you have readline already installed, see config.log for details on the failure.
It is possible the compiler isn't looking in the proper directory. Use --without-readline to disable readline support.
解决:
yum install readline readline-devel
问题3:
checking for inflate in -lz... no configure: error: zlib library not found
If you have zlib already installed, see config.log for details on the failure. It is possible the compiler isn't looking in the proper directory.
Use --without-zlib to disable zlib support.
解决:
yum install zlib zlib-devel
问题4:
checking for CRYPTO_new_ex_data in -lcrypto... no
configure: error: library 'crypto' is required for OpenSSL
解决:
yum -y install opensll openssl-devel
问题5:
checking for pam_start in -lpam... no
configure: error: library 'pam' is required for PAM
解决:
yum -y install pam pam-devel
问题6:
checking for xmlSaveToBuffer in -lxml2... no
configure: error: library 'xml2' (version >= 2.6.23) is required for XML support
解决:
yum -y install libxml2 libxml2-devel
问题7:
checking for xsltCleanupGlobals in -lxslt... no
configure: error: library 'xslt' is required for XSLT support
解决:
yum -y install libxslt libxslt-devel
问题8:
checking for ldap.h... no
configure: error: header file is required for LDAP
解决:
yum -y install openldap openldap-devel
问题9:
checking for Python.h... no
configure: error: header file is required for Python
解决:
yum -y install python-devel
问题10:
Error when bootstrapping CMake: Cannot find appropriate C++ compiler on this system.
Please specify one using environment variable CXX.
See cmake_bootstrap.log for compilers attempted.
解决:
yum -y install gcc-c++
插件报错:
2020-05-06 06:17:12.624 UTC [1] FATAL: could not access file "pglogical": No such file or directory
2020-05-06 06:17:12.624 UTC [1] LOG: database system is shut down
解决参考: https://www.cnblogs.com/lottu/p/10972773.html , pg_pathman: https://www.cnblogs.com/guoxiangyue/p/10894467.html
常见系统glibc版本列表
chris 发表了文章 0 个评论 4717 次浏览 2020-11-24 22:54

| 操作系统 | 操作系统位数 | Glibc版本 |
|---|---|---|
| Centos4.0 | 32bit | ldd (GNU libc) 2.3.4 |
| Centos5.0 | 32bit | ldd (GNU libc) 2.5 |
| Centos3.1 | 64bit | ldd (GNU libc) 2.3.2 |
| Centos3.3 | 64bit | ldd (GNU libc) 2.3.2 |
| Centos4.0 | 64bit | ldd (GNU libc) 2.3.4 |
| Centos5.0 | 64bit | ldd (GNU libc) 2.5 |
| Centos6.0 | 64bit | ldd (GNU libc) 2.12 |
| Centos6.5 | 64bit | ldd (GNU libc) 2.12 |
| Centos7.* | 64bit | ldd (GNU libc) 2.17 |
| Redhat6.5 | 64bit | ldd (GNU libc) 2.12 |
| Redhat7.0 | 64bit | ldd (GNU libc) 2.17 |
| Redhat7.3 | 64bit | ldd (GNU libc) 2.17 |
| Debian6.0 | 32bit | ldd (Debian EGLIBC 2.11.3-4) 2.11.3 |
| Debian7.0 | 32bit | ldd (Debian EGLIBC 2.13-38+deb7u12) 2.13 |
| Debian7.0 | 64bit | ldd (Debian EGLIBC 2.13-38+deb7u12) 2.13 |
| Suse9.0 | 32bit | ldd (GNU libc) 2.3.5 |
| Suse9.1 | 64bit | ldd (GNU libc) 2.3.3 |
| Suse10.0 | 32bit | ldd (GNU libc) 2.4 |
| Suse10.0 | 64bit | ldd (GNU libc) 2.3.5 |
| Suse11.0 | 64bit | ldd (GNU libc) 2.11.1 |
| Suse12.0 | 64bit | ldd (GNU libc) 2.19 |
| OpenSuse42 | 64bit | ldd (GNU libc) 2.19 |
| fedora22 | 64bit | ldd (GNU libc) 2.22 |
| ubuntu12 | 64bit | ldd (Ubuntu EGLIBC 2.15-0ubuntu10.6) 2.15 |
| ubuntu14 | 64bit | ldd (Ubuntu EGLIBC 2.19-0ubuntu6.9) 2.19 |
| Asianux Server 3 | 64bit | ldd (GNU libc) 2.5 |
| Power Linux 6.5 | 64bit | ldd (GNU libc) 2.12 |
| Power Linux7.3 | 64bit | ldd (GNU libc) 2.17 |
以后在补充一些常见系统过得Glibc版本。
linux下LD_LIBRARY_PATH介绍
chris 发表了文章 0 个评论 13911 次浏览 2020-11-24 00:39

LD_LIBRARY_PATH是Linux环境变量名,该环境变量主要用于指定查找共享库(动态链接库)时除了默认路径之外的其他路径。
非常多的软件没有root权限安装会比较困难,主要就是因为各种系统库文件,也就是LD_LIBRARY_PATH这个环境变量里面的文件。比如前面我提到的lancet软件需要的库文件如下:
-llzma -lbz2 -lz -ldl -lpthread -lcurl -lcrypto -lbamtools
可以使用 ls /usr/lib |grep lib 查看自己是否有需要的库文件,当然还需查看其它库文件目录:echo $LD_LIBRARY_PATH 里面一般可以看到七八个已经定义好的库文件搜索路径。
当执行函数动态链接.so时,如果此文件不在缺省目录下 /lib和/usr/lib,那么就需要指定环境变量LD_LIBRARY_PATH 假如现在需要在已有的环境变量上添加新的路径名,则采用如下方式: LD_LIBRARY_PATH=NEWDIRS:$LD_LIBRARY_PATH (newdirs是新的路径串), 实例如下:
export LD_LIBRARY_PATH=/export/apps/anaconda2/2.4.1/lib/:$LD_LIBRARY_PATH
一般报错:
/usr/bin/ld: cannot find -llzma
collect2: error: ld returned 1 exit status
make[1]: *** [lancet] Error 1
make[1]: Leaving directory `/home/bobo/biosoft/lancet/lancet/src'
cp: cannot stat `lancet': No such file or directory
其实就是gcc编辑器找不到我们系统的liblzma这个库文件,就是我们的LD_LIBRARY_PATH定义的所有路径里面都没有这个liblzma这个库文件。
验证gcc编辑器能否找到指定库文件的方法是:
gcc -llzma --verbose
需要找到系统的库文件地址
事实上,我们的机器肯定是有这个库文件的,只不过是不在LD_LIBRARY_PATH定义的所有路径里面,简单查找如下:
locate liblzma
/export/apps/anaconda2/2.4.1/lib/liblzma.a
/export/apps/anaconda2/2.4.1/lib/liblzma.la
/export/apps/anaconda2/2.4.1/lib/liblzma.so
/export/apps/anaconda2/2.4.1/lib/liblzma.so.5
/export/apps/anaconda2/2.4.1/lib/liblzma.so.5.0.5
为了解决我,我们需要添加:
export LD_LIBRARY_PATH=/export/apps/anaconda2/4.0.0/lib/:$LD_LIBRARY_PATH
export LIBRARY_PATH=/export/apps/anaconda2/4.0.0/lib/:$LIBRARY_PATH
为什么修改LD_LIBRARY_PATH呢
因为运行时动态库的搜索路径的先后顺序是:
1.编译目标代码时指定的动态库搜索路径;
2.环境变量LD_LIBRARY_PATH指定的动态库搜索路径;
3.配置文件/etc/ld.so.conf中指定的动态库搜索路径;
4.默认的动态库搜索路径/lib和/usr/lib;
这个顺序是compile gcc时写在程序内的,通常软件源代码自带的动态库不会太多,而我们的/lib和/usr/lib只有root权限才可以修改,而且配置文件/etc/ld.so.conf也是root的事情,我们只好对LD_LIBRARY_PATH进行操作啦。
永久性添加
每次我使用该软件都需要临时修改库文件,因为上面的方法是临时设置环境变量 LD_LIBRARY_PATH ,重启或打开新的 Shell 之后,一切设置将不复存在。
为了让这种方法更完美一些,可以将该 LD_LIBRARY_PATH 的 export 语句写到系统文件中,例如 /etc/profile、/etc/export、~/.bashrc 或者 ~/.bash_profile 等等,取决于你正在使用的操
虽然LD_LIBRARY_PATH很方便,但是还是推荐大家在编译的时候指定-rpath来执行相对路径来找到动态链接库文件。
nginx编译报错/bin/sh: line 2: ./configure: No such file or directory
chris 回复了问题 2 人关注 1 个回复 8161 次浏览 2020-11-23 20:56
Prometheus配置文件热加载
push 发表了文章 0 个评论 4649 次浏览 2020-11-05 16:36

Promtheus的TSDB时序数据库在存储了大量的数据后,每次重启Prometheus进程的时间会越来越慢, 而且日常运维工作中会经常调整Prometheus的配置文件信息,比如一些静态配置,实际上Prometheus提供了在运行时热加载配置信息的功能,在这里介绍一下。
Prometheus配置热加载提供了2种方法:
- kill -HUP pid 发送SIGHUP信号方法
- 通过Prometheus服务API接口,发送发送一个POST请求到
/-/reload
Tips: 从 Prometheus2.0 开始,热加载功能是默认关闭的,如需开启,需要在启动 Prometheus 的时候,添加
--web.enable-lifecycle参数。
我个人更倾向于采用curl -XPOST http://localhost:9090/-/reload 的方式,因为每次reload过后, pid会改变,使用kill方式需要找到当前进程号。
如果配置热加载成功,Prometheus会打印出下面的log:
... msg="Loading configuration file" filename=prometheus.yml ...
下面我们来看看这两种方式内部实现原理。
第一种方法: 通过 kill 命令的 HUP (hang up) 参数实现
首先Prometheus在 cmd/promethteus/main.go 中实现了对进程系统调用监听,如果收到syscall.SIGHUP信号,将执行reloadConfig函数。
代码类似如下:
{
// Reload handler.
// Make sure that sighup handler is registered with a redirect to the channel before the potentially
// long and synchronous tsdb init.
hup := make(chan os.Signal, 1)
signal.Notify(hup, syscall.SIGHUP)
cancel := make(chan struct{})
g.Add(
func() error {
<-reloadReady.C
for {
select {
case <-hup:
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
}
case rc := <-webHandler.Reload():
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
rc <- err
} else {
rc <- nil
}
case <-cancel:
return nil
}
}
},
func(err error) {
// Wait for any in-progress reloads to complete to avoid
// reloading things after they have been shutdown.
cancel <- struct{}{}
},
)
}
第二种:通过 web 模块的 /-/reload请求实现:
首先 Prometheus 在 web(web/web.go) 模块中注册了一个 POST 的 http 请求 /-/reload, 它的 handler 是 web.reload 函数,该函数主要向 web.reloadCh chan 里面发送一个 error。
其次在Prometheus 的cmd/promethteus/main.go中有个单独的 goroutine 来监听web.reloadCh,当接受到新值的时候会执行 reloadConfig 函数。
func() error {
<-reloadReady.C
for {
select {
case <-hup:
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
}
case rc := <-webHandler.Reload():
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
rc <- err
} else {
rc <- nil
}
case <-cancel:
return nil
}
}
},
Prometheus内部提供了成熟的hot reload方案,这大大方便配置文件的修改和重新加载,在Prometheus生态中,很多Exporter也采用类似约定的实现方式。
企业不同时期的运维规划
OS小编 发表了文章 0 个评论 1640 次浏览 2020-11-02 22:32

企业创业期
企业创业初期,人员少,业务流量不大,服务器数量相对较少,系统复杂度不高。对于日常的业务管理操作,因人员少,吼一声,大家就登录服务器进行手工操作,属于各自为战,每个人都有自己的操作方式,权限管理混乱、编写代码的风格各异,缺少必要的操作标准、流程机制,比如业务目录环境都是各式各样的。在这个阶段建议建立如下规范:
- 统一权限管理:应用程序、操作员、管理员权限分离。
- 制定完善的操作流程:先开发环境验证、测试环境验证、预生产环境、生产环境的基础操作流程,最小操作权限、最小化的目录权限为准则。
- 制定代码发布流程和机制:以开发环境、测试环境发布为先,在预生产环境、生产环境发布制定相应的审核。
- 制定代码编写规范:制定排版、注释、标识命名、异常处理等相关规范,避免出现个性化的代码。
- 使用云商自有监控做基础监控,主要是cpu、内存、网络等。
- 强化系统、业务基线安全。
企业高速发展期
在企业发展期,拿到融资后,业务快速发展,随着服务器规模、系统复杂度的增加,全人工的操作方式已经不能满足业务的快速发展需要。因此,运维人员逐渐开始使用批量化的操作工具,针对不同操作类型出现了不同的脚本程序。
但各团队都有自己的工具,每次操作需求发生变化时都需要调整工具。这主要是因为对于环境、操作的规范不够,导致可程序化处理能力较弱。此时,虽然效率提升了一部分,但很快又遇到了瓶颈。在这个阶段建议建立如下规范:
- 制定运维相关脚本的编写标准:如统一相关备份空间、相关备份执行计划,制定相关脚本的执行人员、执行权限、执行时间。
- 统一同类工具的使用:如数据连接工具、备份工具、数据同步工具等。
- 确认相关的操作人,减少或者避免开发和测试在服务器上的相关操作。
- 部署监控平台进一步的监管数据库、进程、日志等。
- 使用第三方应用性能管理对应用性能做应用分析和优化。
企业稳定发展时期
在企业稳定期,在这个阶段,对于运维效率和误操作率有了更高的要求,我们决定开始建设运维平台,通过平台承载标准、流程,进而解放人力和提高质量。
这个时候对服务的变更动作进行了抽象,形成了操作方法、服务目录环境、服务运行方式等统一的标准。通过平台来约束操作流程。
在平台中强制需要运维人员填写相应的检查项,然后才可以继续执行后续的部署动作。在这个阶段建议建立如下运维平台:
- 统一运维操作和管理平台:操作管理、权限管理、资源。
- 统一日志平台:统一日志收集标准、日志收集接口,查询方式,查询授权。
- 统一监控平台:强化监控,从系统、数据库、缓存、中间件、接口、业务性能等。
- 统一发布平台:细化发布项目、发布权限、发布审核、回滚、备份等。
- 加强安全防护:上线前做安全加固、安全评估、渗透测试等。
- 统一开发规范:统一接口、数据库、配置文件等规范。
企业集团化、规模化发展时期
更大规模的服务数量、更复杂的服务关联关系、各个运维平台的林立,原有的将批量操作转化成平台操作的方式已经不再适合,需要对服务变更进行更高一层的抽象。比如智能告警、故障自愈、运营辅助决策等。
这个阶段需要大量的运维数据支持,做相应的数据分析、测试,才能使用,不然因误报或错误的故障自愈决策造成大规模的故障。
分享阅读原文: http://m6z.cn/6sGPLO
交叉编译详解概念篇
OS小编 发表了文章 0 个评论 2192 次浏览 2020-11-01 01:53

1、交叉编译简介
1.1 什么是交叉编译
对于没有做过嵌入式编程的人, 可能不太理解交叉编译的概念, 那么什么是交叉编译?它有什么作用?
在解释什么是交叉编译之前,先要明白什么是本地编译。
本地编译:
本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台(CPU和系统)下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译:
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序:
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
1.2 为什么会有交叉编译
之所以要有交叉编译,主要原因是:
- Speed: 目标平台的运行速度往往比当前编译主机慢得多,许多专用的嵌入式硬件被设计为低成本和低功耗,没有太高的性能;
- Capability: 整个编译过程是非常消耗资源的,嵌入式系统往往没有足够的内存或磁盘空间;
- Availability: 即使目标平台资源很充足,可以本地编译,但是第一个在目标平台上运行的本地编译器总需要通过交叉编译获得;
- Flexibility: 一个完整的Linux编译环境需要很多支持包,交叉编译使我们不需要花时间将各种支持包移植到目标机器上。
1.3 为什么交叉编译比较困难
交叉编译的困难点在于两个方面:
不同的体系架构拥有不同的机器特性
- Word size: 是64位还是32位系统
- Endianness: 是大端还是小端系统
- Alignment: 是否必修按照4字节对齐方式进行访问
- Default signedness: 默认数据类型是有符号还是无符号
- NOMMU: 是否支持MMU
交叉编译时的主机环境与目标环境不同
- Configuration issues:具有单独配置步骤(标准./configure make make install)的软件包通常会测试字节序或页面大小等内容,以便在本地编译时可移植。交叉编译时,这些值在主机系统和目标系统之间会有所不同,因此在主机系统上运行测试会给出错误的答案。当目标没有该程序包或版本不兼容时,配置还可以检测主机上是否存在该程序包并包括对该程序包的支持;
- HOSTCC vs TARGETCC:许多构建过程需要编译内容才能在主机系统上运行,例如上述配置测试或生成代码的程序(例如创建.h文件的C程序,然后在主构建过程中#include )。仅用目标编译器替换主机编译器就会破坏需要构建在构建本身中运行的事物的软件包。这样的软件包需要访问主机和目标编译器,并且需要教它们何时使用它们;
- Toolchain Leaks:配置不正确的交叉编译工具链可能会将主机系统的某些位泄漏到已编译的程序中,从而导致通常易于检测但难以诊断和纠正的故障。工具链可能#include错误的头文件,或在链接时搜索错误的库路径。共享库通常依赖于其他共享库,这些共享库也可能潜入对主机系统的意外链接时引用;
- Libraries:动态链接的程序必须在编译时访问适当的共享库。需要将与目标系统共享的库添加到交叉编译工具链中,以便程序可以针对它们进行链接;
- Testing:在本机版本上,开发系统提供了便利的测试环境。交叉编译时,确认”hello world”构建成功可能需要配置(至少)引导加载程序,内核,根文件系统和共享库。
更详细的对比可以参看这篇文章,已经写的很详细了,在这就不细说了:Introduction to cross-compiling for Linux
2、交叉编译链
2.1 什么是交叉编译链
明白了什么是交叉编译,那我们来看看什么是交叉编译链。
首先编译过程是按照不同的子功能,依照先后顺序组成的一个复杂的流程,如下图: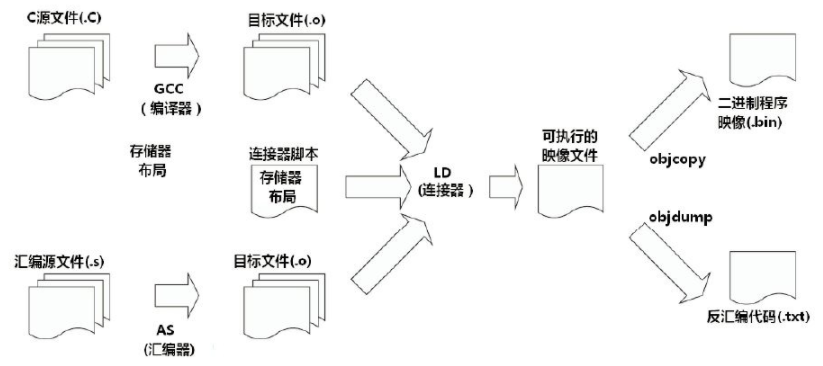
那么编译过程包括了预处理、编译、汇编、链接等功能。既然有不同的子功能,那每个子功能都是一个单独的工具来实现,它们合在一起形成了一个完整的工具集。
同时编译过程又是一个有先后顺序的流程,它必然牵涉到工具的使用顺序,每个工具按照先后关系串联在一起,这就形成了一个链式结构。
因此,交叉编译链就是为了编译跨平台体系结构的程序代码而形成的由多个子工具构成的一套完整的工具集。同时,它隐藏了预处理、编译、汇编、链接等细节,当我们指定了源文件(.c)时,它会自动按照编译流程调用不同的子工具,自动生成最终的二进制程序映像(.bin)。
注意: 严格意义上来说,交叉编译器,只是指交叉编译的gcc,但是实际上为了方便,我们常说的交叉编译器就是交叉工具链。本文对这两个概念不加以区分,都是指编译链。
2.2 交叉编译链的命名规则
我们使用交叉编译链时,常常会看到这样的名字:
arm-none-linux-gnueabi-gcc
arm-cortex_a8-linux-gnueabi-gcc
mips-malta-linux-gnu-gcc
其中,对应的前缀为:
arm-none-linux-gnueabi-
arm-cortex_a8-linux-gnueabi-
mips-malta-linux-gnu-
这些交叉编译链的命名规则似乎是通用的,有一定的规则:
arch-core-kernel-system
- arch: 用于哪个目标平台;
- core: 使用的是哪个CPU Core,如Cortex A8,但是这一组命名好像比较灵活,在其它厂家提供的交叉编译链中,有以厂家名称命名的,也有以开发板命名的,或者直接是none或cross的;
- kernel: 所运行的OS,见过的有Linux,uclinux,bare(无OS);
- system: 交叉编译链所选择的库函数和目标映像的规范,如gnu,gnueabi等。其中gnu等价于glibc+oabi、gnueabi等价于glibc+eabi。
注意: 这个规则是一个猜测,并没有在哪份官方资料上看到过。而且有些编译链的命名确实没有按照这个规则,也不清楚这是不是历史原因造成的。如果有谁在资料上见到过此规则的详细描述,欢迎指出错误。
3、包含的工具
Binutils是GNU工具之一,它包括链接器、汇编器和其他用于目标文件和档案的工具,它是二进制代码的处理维护工具。
Binutils工具包含的子程序如下:
- ld - GNU链接器;
- as - GNU汇编器;
- gold - 一个新的,更快的ELF链接器;
- addr2line - 把地址转换成文件名和所在的行数;
- ar - 用于创建,修改和提取档案的实用程序;
- c ++ filt-过滤以解编码编码的C ++符号;
- dlltool-创建用于构建和使用DLL的文件;
- elfedit-允许更改ELF格式文件;
- gprof-显示分析信息;
- nlmconv-将目标代码转换为NLM;
- nm-列出目标文件中的符号;
- objcopy-复制并转换目标文件;
- objdump-显示目标文件中的信息;
- ranlib-生成指向档案内容的索引;
- readelf-显示来自任何ELF格式对象文件的信息;
- size -列出的对象或归档文件的部分的尺寸;
- strings -列出文件中的可打印字符串;
- strip - 丢弃的符号;
- windmc -Windows兼容的消息编译器。
- windres -Windows资源文件的编译器。
binutils介绍 binutils详解 详细页面。
3.2 GCC
GNU编译器套件,支持C, C++, Java, Ada, Fortran, Objective-C等众多语言。
3.3 Glibc
Linux上通常使用的C函数库为glibc。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现。
因为嵌入式环境的资源及其紧张,所以现在除了glibc外,还有uClibc和eglibc可以选择,三者的关系可以参见这两篇文章:
3.4 GDB
GDB用于调试程序
4、如何得到交叉编译链
既然明白了交叉编译链的功能,那么在针对嵌入式系统开发时,我们需要的交叉编译链从哪儿得到?
主要有三个方式可以获取
4.1 下载已经做好的交叉编译链
使用其他人针对某些CPU平台已经编译好的交叉编译链。我们只需要找到合适的,下载下来使用即可。
常见的交叉编译链下载地址:
在 http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/ 下载已经编译好的交叉编译链
在 http://www.denx.de/en/Software/WebHome 下载已经编译好的交叉编译链
在https://launchpad.net/gcc-arm-embedded下载已经编译好的交叉编译链
一些制作交叉编译链的工具中,包含了已经制作好的交叉编译链,可以直接拿来使用。如crosstool-NG
如果购买了某个芯片或开发板,一般厂商会提供对应的整套开发软件,其中就包含了交叉编译链。
厂家提供的工具一般是经过了严格的测试,并打入了一些必要的补丁,所以这种方式往往是最可靠的工具来源。
4.2 使用工具定制交叉编译链
使用现存的制作工具,以简化制作交叉编译链这个事情的复杂度。我们只需要了解有哪些工具可以实现,并选个合适的工具,搞懂它的操作步骤即可。
- crosstool-NG
- Buildroot
- Embedded Linux Development Kit (ELDK)
工具还有很多,各有各的优势和劣势,大家可以慢慢研究,在这就不细说了。
4.3 从零开始构建交叉编译链
这个是最困难也最耗时间的,毕竟制作交叉编译链这样的事情,需要对嵌入式的编译原理了解的比较透彻,至少要知道出了问题要往哪个方面去翻阅资料。而且,也是最考耐心和细心的地方,配错一个选项或是一个步骤,都可能出现以前从来没见过的问题,而且这些问题往往还无法和这个选项或步骤直接联系起来。
当然如果搭建出来,肯定也是收获最大的,至少对于编译的流程和依赖都比较清楚了,细节上的东西可能还需要去翻看相应的协议或标准,但至少骨架会比较清楚。
详细的搭建过程可以参看后续的文章,这里面有详细的参数和步骤:
交叉编译详解 二 从零制作交叉编译链
为了方便大家搭建交叉编译链,我写了一个一键生成的脚本(包括源码下载和自动编译)。如果大家自己一直搭建不成功,不妨试试这个脚本,然后对比下自己的流程是否一致,参数是否有差异,也许能帮大家迈过这个障碍:
交叉编译详解 三 使用脚本自动生成交叉编译链
4.4 对比三种构建方式
| 项目 | 使用已有交叉编译链 | 自己制作交叉编译链 |
|---|---|---|
| 安装 | 一般提供压缩包 | 需要自己打包 |
| 源码版本 | 一般使用较老的稳定版本,对于一些新的GCC特性不支持 | 可以使用自己需要的GCC特性的版本 |
| 补丁 | 一般都会打上修复补丁 | 普通开发者很难辨别需要打上哪些补丁,资深开发者可以针对自己的需求合入补丁 |
| 源码溯源 | 可能不清楚源码版本和补丁情况 | 一切都可以定制 |
| 升级 | 一般不会升级 | 可以随时升级 |
| 优化 | 一般已经针对特定CPU特性和性能进行优化 | 一般无法做到比厂家优化的更好,除非自己设计的CPU |
| 技术支持 | 可以通过FAE进行支持,可能需要收费 | 只能通过社区支持,免费 |
| 可靠性验证 | 已经通过了完善的验证 | 自己验证,肯定没有专业人士验证的齐全 |
参考资料
1、Introduction to cross-compiling for Linux
4、 uclibc eglibc glibc之间的区别和联系
5、 Glibc vs uClibc Differences
6、交叉编译链下载地址
- http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/
- http://www.denx.de/en/Software/WebHome
- https://launchpad.net/gcc-arm-embedded
分享原文: http://m6z.cn/6tdD7y





