

云计算大数据
什么是Serverless?
DevOps 星物种 发表了文章 1 个评论 1952 次浏览 2021-04-24 22:29

1. 无服务器(Serverless)计算是什么
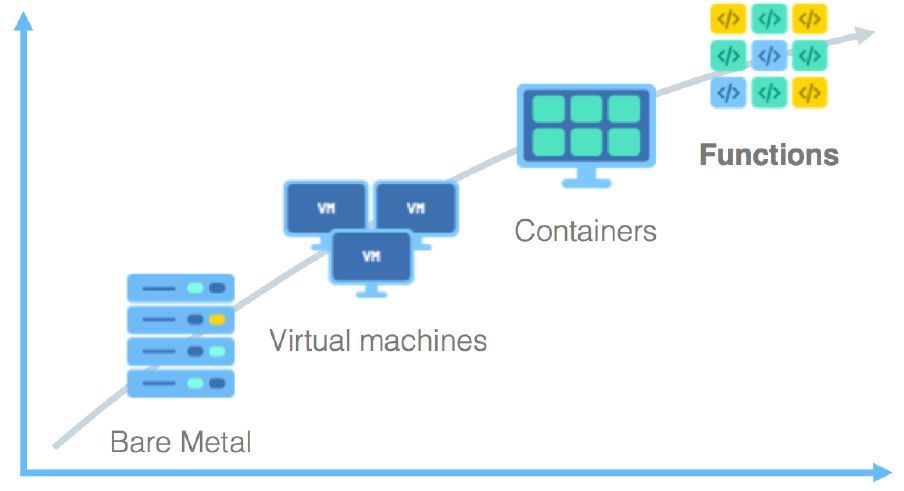
云计算涌现出很多改变传统IT架构和运维方式的新技术,比如虚拟机、容器、微服务,无论这些技术应用在哪些场景,降低成本、提升效率是云服务永恒的主题。
过去十年来,我们已经把应用和环境中很多通用的部分变成了服务。Serverless的出现,带来了跨越式变革。Serverless把主机管理、操作系统管理、资源分配、扩容,甚至是应用逻辑的全部组件都外包出去,把它们看作某种形式的商品——厂商提供服务,我们掏钱购买。
过去是“构建一个框架运行在一台服务器上,对多个事件进行响应”,Serverless则变为“构建或使用一个微服务或微功能来响应一个事件”,做到当访问时,调入相关资源开始运行,运行完成后,卸载所有开销,真正做到按需按次计费。这是云计算向纵深发展的一种自然而然的过程。
Serverless是一种构建和管理基于微服务架构的完整流程,允许你在服务部署级别而不是服务器部署级别来管理你的应用部署。它与传统架构的不同之处在于,完全由第三方管理,由事件触发,存在于无状态(Stateless)、暂存(可能只存在于一次调用的过程中)计算容器内。构建无服务器应用程序意味着开发者可以专注在产品代码上,而无须管理和操作云端或本地的服务器或运行时。Serverless真正做到了部署应用无需涉及基础设施的建设,自动构建、部署和启动服务。
国内外的各大云厂商 Amazon、微软、Google、IBM、阿里云、腾讯云、华为云相继推出Serverless产品,Serverless也从概念、愿景逐步走向落地,在各企业、公司应用开来。
2. 理解Serverless技术 - FaaS和BaaS
Serverless由开发者实现的服务端逻辑运行在无状态的计算容器中,它由事件触发, 完全被第三方管理,其业务层面的状态则被开发者使用的数据库和存储资源所记录。Serverless涵盖了很多技术,分为两类:FaaS和BaaS。
2.1 FaaS(Function as a Service,函数即服务)
FaaS意在无须自行管理服务器系统或自己的服务器应用程序,即可直接运行后端代码。其中所指的服务器应用程序,是该技术与容器和PaaS(平台即服务)等其他现代化架构最大的差异。
FaaS可以取代一些服务处理服务器(可能是物理计算机,但绝对需要运行某种应用程序),这样不仅不需要自行供应服务器,也不需要全时运行应用程序。
FaaS产品不要求必须使用特定框架或库进行开发。在语言和环境方面,FaaS函数就是常规的应用程序。例如AWS Lambda的函数可以通过Javascript、Python以及任何JVM语言(Java、Clojure、Scala)等实现。然而Lambda函数也可以执行任何捆绑有所需部署构件的进程,因此可以使用任何语言,只要能编译为Unix进程即可。FaaS函数在架构方面确实存在一定的局限,尤其是在状态和执行时间方面。
在迁往FaaS的过程中,唯一需要修改的代码是“主方法/启动”代码,其中可能需要删除顶级消息处理程序的相关代码(“消息监听器接口”的实现),但这可能只需要更改方法签名即可。在FaaS的世界中,代码的其余所有部分(例如向数据库执行写入的代码)无须任何变化。
相比传统系统,部署方法会有较大变化 – 将代码上传至FaaS供应商,其他事情均可由供应商完成。目前这种方式通常意味着需要上传代码的全新定义(例如上传zip或JAR文件),随后调用一个专有API发起更新过程。
FaaS中的函数可以通过供应商定义的事件类型触发。对于亚马逊AWS,此类触发事件可以包括S3(文件)更新、时间(计划任务),以及加入消息总线的消息(例如Kinesis)。通常你的函数需要通过参数指定自己需要绑定到的事件源。
大部分供应商还允许函数作为对传入Http请求的响应来触发,通常这类请求来自某种该类型的API网关(例如AWS API网关、Webtask)。
2.2 BaaS(Backend as a Service,后端即服务)
BaaS(Backend as a Service,后端即服务)是指我们不再编写或管理所有服务端组件,可以使用领域通用的远程组件(而不是进程内的库)来提供服务。理解BaaS,需要搞清楚它与PaaS的区别。
首先BaaS并非PaaS,它们的区别在于:PaaS需要参与应用的生命周期管理,BaaS则仅仅提供应用依赖的第三方服务。典型的PaaS平台需要提供手段让开发者部署和配置应用,例如自动将应用部署到Tomcat容器中,并管理应用的生命周期。BaaS不包含这些内容,BaaS只以API的方式提供应用依赖的后端服务,例如数据库和对象存储。BaaS可以是公共云服务商提供的,也可以是第三方厂商提供的。其次从功能上讲,BaaS可以看作PaaS的一个子集,即提供第三方依赖组件的部分。
BaaS服务还允许我们依赖其他人已经实现的应用逻辑。对于这点,认证就是一个很好的例子。很多应用都要自己编写实现注册、登录、密码管理等逻辑的代码,而对于不同的应用这些代码往往大同小异。完全可以把这些重复性的工作提取出来,再做成外部服务,而这正是Auth0和Amazon Cognito等产品的目标。它们能实现全面的认证和用户管理,开发团队再也不用自己编写或者管理实现这些功能的代码。
3. 无服务器(Serverless)计算如何工作?
与使用虚拟机或一些底层的技术来部署和管理应用程序相比,无服务器计算提供了一种更高级别的抽象。因为它们有不同的抽象和“触发器”的集合。
拿计算来讲,这种抽象有一个特定函数和抽象的触发器,它通常是一个事件。以数据库为例,这种抽象也许是一个表,而触发器相当于表的查询或搜索,或者通过在表中做一些事情而生成的事件。
比如一款手机游戏,允许用户在不同的平台上为全球顶级玩家使用高分数表。当请求此信息时,请求从应用程序到API接口。API接口或许会触发AWS的Lambda函数,或者无服务器函数,这些函数再从数据库表中获取到数据流,返回包含前五名分数的一定格式的数据。
一旦构建完成,应用程序的功能就可以在基于移动和基于 Web 的游戏版本中重用。
这跟设置服务器不同,不是必须要有Amazon EC2实例或服务器,然后等待请求。环境由事件触发,而响应事件所需的逻辑只在响应时执行。这意味着,运行函数的资源只有在函数运行时被创建,产生一种非常高效的方法来构建应用程序。
4. 无服务器(Serverless)适用于哪些场景?
在现阶段,Serverless主要应用在以下几个场景。首先在Web及移动端服务中,可以整合API网关和Serverles服务构建Web及移动后端,帮助开发者构建可弹性扩展、高可用的移动或 Web后端应用服务。在IoT场景下可高效的处理实时流数据,由设备产生海量的实时信息流数据,通过Serverles服务分类处理并写入后端处理。另外在实时媒体资讯内容处理场景里,用户上传的音视频到对象存储OBS,通过上传事件触发多个函数,分别完成高清转码、音频转码等功能,满足用户对实时性和并发能力的高要求。无服务器计算还适合于任何事件驱动的各种不同的用例,这包括物联网,移动应用,基于网络的应用程序和聊天机器人等。这里简单说两个场景,方便大家思考。
4.1 场景一:应用负载有显著的波峰波谷
Serverless 应用成功与否的评判标准并不是公司规模的大小,而是其业务背后的具体技术问题,比如业务波峰波谷明显,如何实现削峰填谷。一个公司的业务负载具有波峰波谷时,机器资源要按照峰值需求预估;而在波谷时期机器利用率则明显下降,因为不能进行资源复用而导致浪费。
业界普遍共识是,当自有机器的利用率小于 30%,使用 Serverless 后会有显著的效率提升。对于云服务厂商,在具备了足够多的用户之后,各种波峰波谷叠加后平稳化,聚合之后资源复用性更高。比如,外卖企业负载高峰是在用餐时期,安防行业的负载高峰则是夜间,这是受各个企业业务定位所限的;而对于一个成熟的云服务厂商,如果其平台足够大,用户足够多,是不应该有明显的波峰波谷现象的。
4.2 场景二:典型用例 - 基于事件的数据处理
视频处理的后端系统,常见功能需求如下:视频转码、抽取数据、人脸识别等,这些均为通用计算任务,可由函数计算执行。
开发者需要自己写出实现逻辑,再将任务按照控制流连接起来,每个任务的具体执行由云厂商来负责。如此,开发变得更便捷,并且构建的系统天然高可用、实时弹性伸缩,用户不需要关心机器层面问题。
5. Serverless的问题
对于企业来说,支持Serverless计算的平台可以节省大量时间和成本,同时可以释放员工,让开发者得以开展更有价值的工作,而不是管理基础设施。另一方面可以提高敏捷度,更快速地推出新应用和新服务,进而提高客户满意度。但是Serverless不是完美的,它也存在一些问题,需要慎重应用在生产环境。
5.1 不适合长时间运行应用
Serverless 在请求到来时才运行。这意味着,当应用不运行的时候就会进入 “休眠状态”,下次当请求来临时,应用将会需要一个启动时间,即冷启动时间。如果你的应用需要一直长期不间断的运行、处理大量的请求,那么你可能就不适合采用 Serverless 架构。如果你通过 CRON 的方式或者 CloudWatch 来定期唤醒应用,又会比较消耗资源。这就需要我们对它做优化,如果频繁调用,这个资源将会常驻内存,第一次冷启之后,就可以一直服务,直到一段时间内没有新的调用请求进来,则会转入“休眠”状态,甚至被回收,从而不消耗任何资源。
5.2 完全依赖于第三方服务
当你所在的企业云环境已经有大量的基础设施的时候,Serverless 对于你来说,并不是一个好东西。当我们采用某云服务厂商的 Serverless 架构时,我们就和该服务供应商绑定了,那么我们再将服务迁到别的云服务商上就没有那么容易了。
我们需要修改一下系列的底层代码,能采取的应对方案,便是建立隔离层。这意味着,在设计应用的时候,就需要隔离 API 网关、隔离数据库层,考虑到市面上还没有成熟的 ORM 工具,让你既支持Firebase,又支持 DynamoDB等等。这些也将带给我们一些额外的成本,可能带来的问题会比解决的问题多。
5.3 缺乏调试和开发工具
当我使用 Serverless Framework 的时候,遇到了这样的问题:缺乏调试和开发工具。后来,我发现了 serverless-offline、dynamodb-local 等一系列插件之后,问题有一些改善。然而,对于日志系统来说,这仍然是一个艰巨的挑战。
每次你调试的时候,你需要一遍又一遍地上传代码。而每次上传的时候,你就好像是在部署服务器,并不能总是快速地定位出问题在哪。后来,找了一个类似于 log4j 这样的可以分级别记录日志的 Node.js 库 winston。它可以支持 error、warn、info、verbose、debug、silly 六个不同级别的日志,再结合大数据进行日志分析过滤,才能快速定位问题。
5.4 构建复杂
Serverless 很便宜,但是这并不意味着它很简单。AWS Lambda的 CloudFormation配置是如此的复杂,并且难以阅读及编写(JSON 格式),虽然CloudFomation提供了Template模板,但想要使用它的话,需要创建一个Stack,在Stack中指定你要使用的Template,然后aws才会按照Template中的定义来创建及初始化资源。
而Serverless Framework的配置更加简单,采用的是 YAML 格式。在部署的时候,Serverless Framework 会根据我们的配置生成 CloudFormation 配置。然而这也并非是一个真正用于生产的配置,真实的应用场景远远比这复杂。
6. 总结
云计算经过这么多年的发展,逐渐进化到用户仅需关注业务和所需的资源。比如,通过K8S这类编排工具,用户只要关注自己的计算和需要的资源(CPU、内存等)就行了,不需要操心到机器这一层。
Serverless架构让人们不再操心运行所需的资源,只需关注自己的业务逻辑,并且为实际消耗的资源付费。可以说,随着Serverless架构的兴起,真正的云计算时代才算到来了。
任何新概念新技术的落地,本质上都是要和具体业务去结合,去真正解决具体问题。虽然Serverless很多地方不成熟,亟待完善。不过Serverless自身的优越特性,对于开发者来说,吸引力是巨大的。相信随着技术的飞速发展,Serverless在未来还有无限可能!
作者介绍:孙杰 北京中油瑞飞资深架构师,著名技术博客博主。
Zookeeper新手指南
云原生 空心菜 发表了文章 0 个评论 2482 次浏览 2021-03-27 22:41

目标
今天,我们将开始迈向Apache ZooKeeper的新旅程。在这个ZooKeeper教程中,我们将看到Apache ZooKeeper的含义以及ZooKeeper的流行度。此外,我们将了解ZooKeeper 的功能,优点,应用和用例。此外,我们将讨论不同的术语,如ZooKeeper Client,ZooKeeper Cluster,ZooKeeper WebUI。除此之外,Apache ZooKeeper教程将为使用ZooKeeper的原因提供答案。此外,我们将看到使用ZooKeeper的公司。最后,我们将看到Apache ZooKeeper架构。
由于ZooKeeper本质上是分布式的,因此在进一步研究之前,了解分布式应用程序的一两件事非常重要。因此,首先,我们将看到ZooKeeper讨论,快速介绍分布式应用程序。
那么,让我们开始Apache ZooKeeper教程。
什么是分布式应用程序?
为了以快速有效的方式完成特定任务,分布式应用程序可以在给定时间(同时)在网络中的多个系统上运行。它们可以通过中间协调来实现。此外,我们可以说,通过使用所涉及的所有系统的计算能力,复杂且耗时的任务(需要数小时才能完成非分布式应用程序(在单个系统中运行))可以在几分钟内通过帮助完成分布式应用程序。
此外,通过将分布式应用程序配置为在更多系统上运行,可以进一步减少完成任务的时间。有一个集群,它基本上是一组运行分布式应用程序的系统。在集群中有机器在运行,那些在集群中运行的机器就是我们所说的节点。
通常,服务器和客户端应用程序是分布式应用程序的两个部分。定义两者:
服务器端应用
具有通用接口的分布式应用程序就是我们所说的服务器端应用程序。基本上,它确保客户端可以连接到群集中的任何服务器并获取相同的结果。
客户端应用
有助于与分布式应用程序交互的工具就是我们所说的客户端应用程序。
分布式应用的好处
a.可靠性
如果一个或几个系统发生故障,则不会使整个系统失效。
b.可伸缩性
通过添加更多的机器,只需对应用程序的配置进行少量更改,而无需停机,就可以根据需要提高性能。
c.透明度
这仅仅意味着它隐藏了系统的复杂性。而且,它显示自己是一个单独的实体/应用程序。
分布式应用程序的挑战
1.竞争条件
有时有两个或更多的机器试图执行一个特定的任务,即使当任务实际上只需要在任何给定的时间由一台机器来完成。
2.死锁
为了无限期地完成,两个或多个操作等待彼此。
3.不一致
这意味着数据部分失效。
什么是ZooKeeper?
我们称之为ZooKeeper的分布式协调服务也有助于管理大量主机。由于特别是在分布式环境中管理和协调服务是一个复杂的过程,因此ZooKeeper由于其简单的架构和API而解决了这个问题。ZooKeeper是最好的,不用担心应用程序的分布式特性,它允许开发人员专注于核心应用程序逻辑。
最初,为了以简单而强大的方式访问应用程序,ZooKeeper框架最初是在“Yahoo!”上构建的。但在此之后,为了组织Hadoop,HBase和其他分布式框架所使用的服务,Apache ZooKeeper成为了标准。例如,要跟踪分布式数据的状态,Apache HBase使用ZooKeeper。
此外,它们还可以轻松支持大型Hadoop集群。为了检索信息,每个客户机与其中一个服务器通信。但是,在过去,大多数工作都需要在实现分布式应用程序时修复错误。虽然我们可以说,实现中的这些各种困难是创建ZooKeeper背后的主要原因。因为它简明扼要地关注整个集群的同步和协调。
Zookeeper受众
那些希望通过使用ZooKeeper框架在大数据分析领域开展事业的专业人士可以参考这个Zookeeper序列文章。因为这个Apache ZooKeeper序列教程文章将详细介绍如何使用ZooKeeper创建分布式集群。
Zookeeper运行先决条件
虽然,在继续使用这个ZooKeeper教程之前,必须对Java有一个很好的理解,因为它的服务器运行在JVM,分布式进程以及Linux环境中。
Zookeeper的功能
有一些最好的Apache ZooKeeper功能,这使它从人群中脱颖而出:
简单
在共享的分层命名空间的帮助下,它进行协调。
可靠性
即使多个节点发生故障,系统也会继续运行。
速度
在“读取”更常见的情况下,它以10:1的比例运行。
可扩展性
通过部署更多集群节点,可以提高性能。
ZooKeeper教程设计
下面,我们将讨论Apache ZooKeeper的一些设计目标: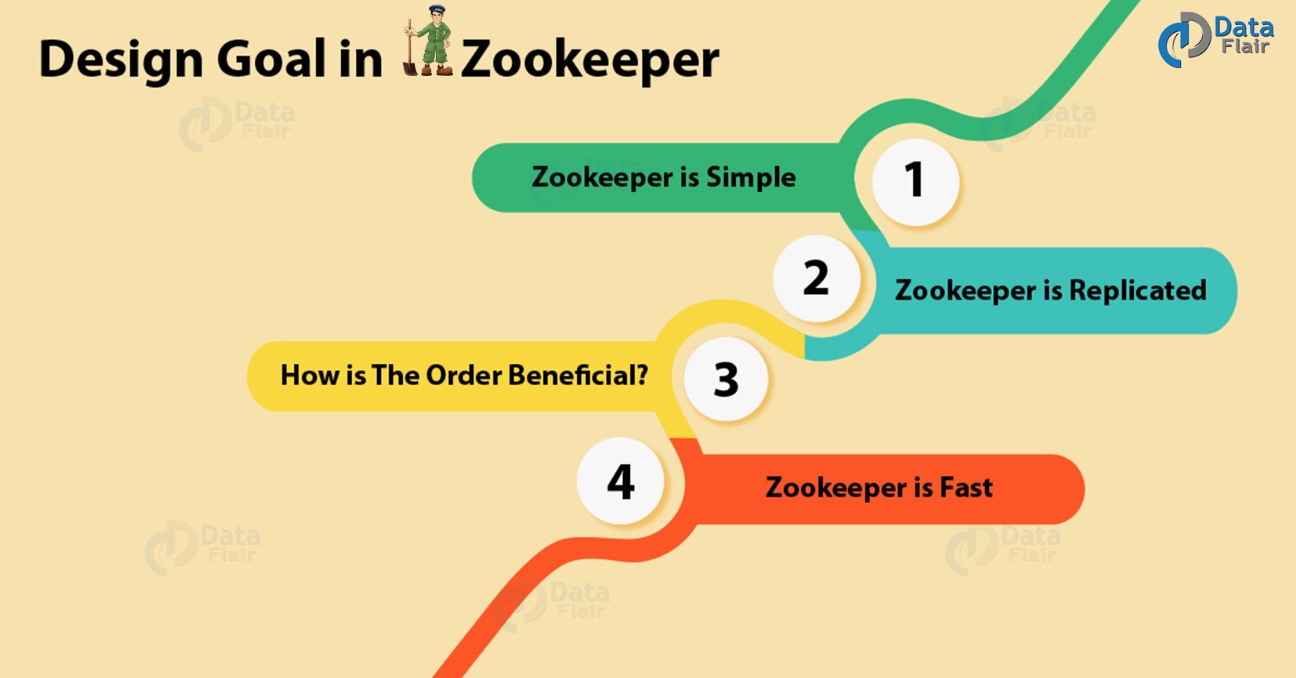
a. Zookeeper是简单的
在使用ZooKeeper时,所有分布式进程都可以相互协调。这种协调可以通过共享的分层命名空间实现。但是,它的组织方式与标准文件系统相同。这里的命名空间由数据寄存器组成,我们称之为znodes,用ZooKeeper的说法。但是,这些与文件和目录相同。此外,ZooKeeper数据保留在内存中,因为它实现了高吞吐量和低延迟数量。
b. Zookeeper支持复制
Apache ZooKeeper本身旨在通过一组称为集合的主机进行复制,就像它协调的分布式进程一样。
c. 如何让Zookeeper顺序一致性更有效?
为了实现更高级别的抽象(同步原语,后续操作),需要使用顺序一致性。
d. Zookeepr很快
特别是,在“读取占优势”的工作负载中,ZooKeeper的工作速度非常快。
Apache ZooKeeper架构
在这个Apache ZooKeeper教程的下面,给出了ZooKeeper架构的几个组成部分,例如:
- 服务器端应用程序:通过通用接口,这些应用程序便于与客户端应用程序进
- 客户端应用程序:有几种工具可以帮助与分布式应用程序进行交互。
- ZooKeeper节点:这些是集群运行的系统。
- Znode:通过集群中的任何节点,我们都可以更新或修改Znode。
我们可以通过一组机器轻松地通过Hadoop ZooKeeper的架构复制ZooKeeper服务。但是,每个都维护一个内存数据树的映像以及事务日志。此外,客户端应用程序联系到单个服务器并且还建立TCP链接。因此,通过他们,他们发送请求,接收回复,观看事件等等。
为什么选择Apache ZooKeeper?
基本上,为了在(节点组)之间进行协调并使用强大的同步技术维护共享数据,集群使用 Apache ZooKeeper。但是,对于编写分布式应用程序,ZooKeeper本身就是一个提供多种服务的分布式应用程序。所以,我们在这里列出了ZooKeeper提供的常用服务,例如: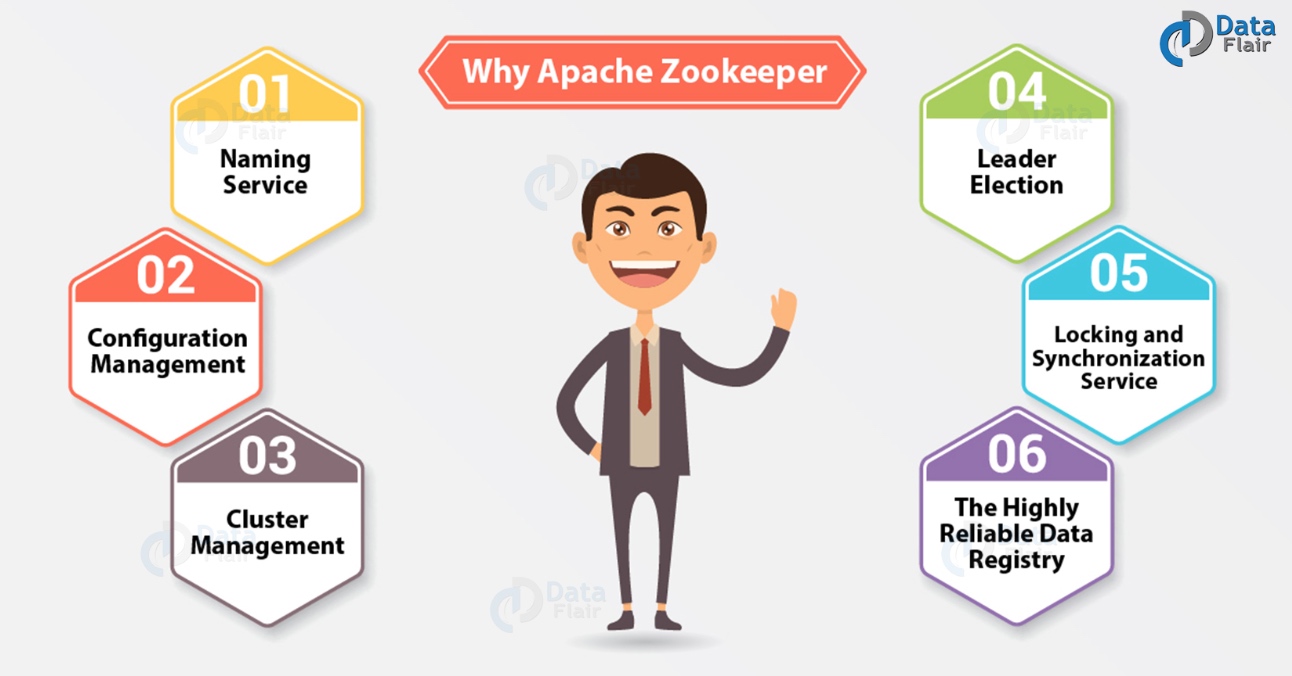
a. 命名服务
在群集中,按名称标识节点。
b. 配置管理
对于加入节点,系统的最新和最新配置信息。
c. 集群管理
实时地,在群集和节点状态中加入/下架节点。
d. Leader选举
出于协调目的,选择一个节点作为领导者。
e. 锁定和同步服务
在修改它时,锁定数据。在连接其他分布式应用程序(如Apache HBase)时,此机制可帮助我们自动进行故障恢复。
f. 高度可靠的数据注册表
即使一个或几个节点关闭 了数据的可用性。
由于分布式应用程序也提供了很少的复杂和难以破解的挑战,因此,为了克服所有挑战,ZooKeeper框架提供了一个完整的机制。此外,使用故障安全同步方法,我们可以处理竞争条件和死锁。此外,ZooKeeper解决了数据与原子性的不一致性。
使用Docker容器化ZooKeeper
通过使用Docker容器化ZooKeeper。因此,作为一个很大的好处,可以按需添加和删除节点。但是,只能通过在Docker镜像中添加ZooKeeper并在集群的每个主服务器上使用它来运行容器。
此外,它应该独立地创建一个集群,或者它应该能够在启动容器期间连接到现有集群并成为其一部分。因此,它允许使用Docker容器化动态重新配置整个Hadoop集群,这是使用Docker容器的好处。
什么是ZooKeeper客户端?
与所有分布式应用程序一样,Zookeeper分布式应用程序也包含服务器和客户端。它有一个集中的界面,客户端可以通过该界面连接到服务。但是,这些客户端可以是命令行或GUI客户端。基本上,可用于与ZooKeeper分布式应用程序交互的工具就是我们所说的ZooKeeper客户端应用程序。
什么是Zookeeper群集?
因为我们需要在集群模式下拥有ZooKeeper基础架构,以便在我们大规模运行Apache ZooKeeper时使系统处于最佳值。我们还将ZooKeeper集群称为集合体。但是,如果ZooKeeper集群必须成功运行,请确保大多数集群节点始终需要启动并运行。
ZooKeeper WebUI
基本上,要使用ZooKeeper资源管理,ZooKeeper WebUI或Web用户界面是一种更简单的方法。因此,WebUI允许使用Web用户界面使用ZooKeeper,而不是使用命令行与ZooKeeper应用程序进行交互。因此,我们可以说它使工作变得更加容易和有效。
Apache ZooKeeper应用程序
简而言之,为了大规模创建高度可用的分布式系统,它已成为最受欢迎的选择之一。因此,Apache基金会最成功的项目之一是ZooKeeper项目。
点击链接了解有关ZooKeeper Applications的更多信息
Apache ZooKeeper通过为实现不同的大数据工具提供坚实的基础,使公司能够在大数据世界中顺利运行。因此,它是大规模实施的最优选应用之一,因为它能够一次提供多种益处。
使用ZooKeeper的公司
现在,在这个Apache ZooKeeper教程中,我们提供了一个使用ZooKeeper的公司列表:
- Yahoo
- 易趣
- eBay
- Netflix
- Netflix
- Zynga
- Nutanix
- 百度
- 腾讯
- 阿里
- 携程
- 京东
- 小米
Apache ZooKeeper的好处
有各种ZooKeeper的好处,例如:
a. 同步
它允许互斥以及服务器进程之间的协作。因此,这有助于Apache HBase,用于配置管理
b. 有序消息
通过用表示其顺序的数字标记每个更新,它会跟踪。
c. 序列化
它确保我们的应用程序一致运行。要协调队列以执行正在运行的线程,可以在MapReduce中使用此方法。
d. 可靠性
应用更新后,它将从该时间开始持续,直到客户端覆盖更新。
e. 原子性
没有事务是部分的,数据传输成功或完全失败。
f. 顺序一致性
按照发送它们的顺序,它应用来自客户端的更新。
g. 单系统镜像
无论它连接到哪个服务器,客户端都会看到相同的服务视图。
h. 及时性
在一定的时间范围内,客户端对系统的视图是最新的。
ZooKeeper用例
Apache ZooKeeper教程中ZooKeeper的一些最突出的用例是:
- 管理配置
- 命名服务
- 选择Leader
- 对消息进行排队
- 管理通知系统
- 同步
通过使用ZooKeeper CLI,我们还可以与ZooKeeper集合进行通信。基本上,这为我们提供了使用各种选项的功能。此外,为了调试,还依赖于命令行界面。
教程英文原文: https://henduan.com/igCAR
Elasticsearch启动常见问题
数据库 being 发表了文章 0 个评论 2726 次浏览 2021-03-16 22:54

启动内存问题
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error='Cannot allocate memory' (errno=12)
分析: 默认分配的JVM内存为2g,所以当小内存的机器,默认启动的话,会报如上错误。
解决: 修改Eleasticsearch启动JVM内存参数, 修改文件: config/jvm.options
-Xms2g
-Xmx2g
修改为
-Xms1g
-Xmx1g
对于内存较低的云主机和虚拟机,你要测试Elasticsearch的基本功能,没有太大性能要求的话,这时候就需要修改启动内存。
启动用户问题
don't run elasticsearch as root
分析: 程序设计者,出于系统安全考虑设置的条件, 由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,如果获取root权限了,那问题就打了,所以默认官方是建议创建一个单独的用户用来运行ElasticSearch。
解决:添加单独的用户运行
groupadd es
useradd es -g es
更改elasticsearch文件夹及内部文件的所属用户及组为es:es
chown -R es:es elasticsearch
切换到es用户启动:
su - es
./bin/elasticsearch -d
# 或者root下
su es -c "/opt/elasticsearch/bin/elasticsearch -d"
Tips: ES5版本之前,还可以修改
ES_JAVA_OPTS启动参数,加上-Des.insecure.allow.root=true可以使用root启动,但是不推荐这么玩。
最大虚拟内存区域问题
max virtual memory areas vm.max_map_count [256000] is too low, increase to at least [262144]
什么是VMA(virtual memory areas):
This file contains the maximum number of memory map areas a process may have. Memory map areas are used as a side-effect of calling malloc, directly by mmap and mprotect, and also when loading shared libraries.
While most applications need less than a thousand maps, certain programs, particularly malloc debuggers, may consume lots of them, e.g., up to one or two maps per allocation.
The default value is 65536
max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
解决:
# 临时设置
sysctl -w vm.max_map_count=262144
# 永久设置
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
虚拟内存最大大小问题
max size virtual memory [67108864] for user [es] is too low, increase to [unlimited]
分析:引用官网的说法
The segment files that are the components of individual shards and the translog generations that are components of the translog can get large (exceeding multiple gigabytes). On systems where the max size of files that can be created by the Elasticsearch process is limited, this can lead to failed writes. Therefore, the safest option here is that the max file size is unlimited and that is what the max file size bootstrap check enforces. To pass the max file check, you must configure your system to allow the Elasticsearch process the ability to write files of unlimited size.
解决:
echo "* - as unlimited" >> /etc/security/limits.conf
echo "root - as unlimited" >> /etc/security/limits.conf
参考: https://stackoverflow.com/questions/42510873/vm-max-map-count-is-too-low
最大文件描述符问题
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
分析:elasticsearch启动bootstrap checks要求系统打开最大系统文件描述符为65536
解决:
# 临时 ulimit -f unlimited
echo "* soft nofile 65536" >> /etc/security/limits.conf
echo "* hard nofile 65536" >> /etc/security/limits.conf
确认:
ulimit -Hn
ulimit -Sn
最大线程数问题
max number of threads [3818] for user [es] is too low, increase to at least [4096]
分析:elasticsearch启动bootstrap checks要求打开最大线程数最低为4096
解决:
echo "* soft nproc 65535" >> /etc/security/limits.conf
echo "* hard nproc 65535" >> /etc/security/limits.conf
注意:修改这里,普通用户
max user process值是不生效的,需要修改/etc/security/limits.d/20-nproc.conf文件中的值。Centos6系统的是是90-nproc.conf文件。
修改 /etc/security/limits.d/20-nproc.conf
* soft nproc 65535
系统总限制
其实上面的 max user processes 65535 的值也只是表象,普通用户最大进程数无法达到65535 ,因为用户的max user processes的值,最后是受全局的kernel.pid_max的值限制。
也就是说kernel.pid_max=1024 ,那么你用户的max user processes的值是65535 ,用户能打开的最大进程数还是1024。
# 临时生效
echo 65535 > /proc/sys/kernel/pid_max
sysctl -w kernel.pid_max=65535
# 永久生效
echo "kernel.pid_max = 65535" >> /etc/sysctl.conf
sysctl -p
然后重启机器生效。
参考: https://www.cnblogs.com/xidianzxm/p/11820706.html
确认:
ulimit -Hu
ulimit -Su
运行目录权限问题
Exception in thread "main" java.nio.file.AccessDeniedException: /opt/elasticsearch-6.2.2-1/config/jvm.options
分析: es用户没有该文件夹的权限
解决:
chown es.es /opt/elasticsearch-6.2.2-1 -R
如果还有碰到其他问题的同学,可以留言补充。
Centos系统下升级git命令版本
运维 Rock 发表了文章 0 个评论 2298 次浏览 2020-12-15 15:45

有些软件的自动安装依赖于git的版本,而且大多数Centos服务器上的git要么是1.7.1或者就是1.8.x,如果要大面积升级的话,还是用yum包管理器直接升级比较方便.
1. 获取安装源
1.1 Centos6
wget http://opensource.wandisco.com/centos/6/git/x86_64/wandisco-git-release-6-1.noarch.rpm
rpm -ivh wandisco-git-release-6-1.noarch.rpm
1.2 Centos7
wget http://opensource.wandisco.com/centos/7/git/x86_64/wandisco-git-release-7-1.noarch.rpm
rpm -ivh wandisco-git-release-7-1.noarch.rpm
# 或者
wget http://opensource.wandisco.com/centos/7/git/x86_64/wandisco-git-release-7-2.noarch.rpm
rpm -ivh wandisco-git-release-7-2.noarch.rpm
2. 安装git 2.x
yum install git -y
3. 验证
[root@linux-chromium rock]# git --version
git version 2.22.0
可以看到git已经升级到2.22.0的版本了, Centos6还可以利用如下源升级:
wget https://centos6.iuscommunity.org/ius-release.rpm
rpm -ivh ius-release.rpm
yum install git2u -y
Prometheus配置文件热加载
运维 push 发表了文章 0 个评论 4649 次浏览 2020-11-05 16:36

Promtheus的TSDB时序数据库在存储了大量的数据后,每次重启Prometheus进程的时间会越来越慢, 而且日常运维工作中会经常调整Prometheus的配置文件信息,比如一些静态配置,实际上Prometheus提供了在运行时热加载配置信息的功能,在这里介绍一下。
Prometheus配置热加载提供了2种方法:
- kill -HUP pid 发送SIGHUP信号方法
- 通过Prometheus服务API接口,发送发送一个POST请求到
/-/reload
Tips: 从 Prometheus2.0 开始,热加载功能是默认关闭的,如需开启,需要在启动 Prometheus 的时候,添加
--web.enable-lifecycle参数。
我个人更倾向于采用curl -XPOST http://localhost:9090/-/reload 的方式,因为每次reload过后, pid会改变,使用kill方式需要找到当前进程号。
如果配置热加载成功,Prometheus会打印出下面的log:
... msg="Loading configuration file" filename=prometheus.yml ...
下面我们来看看这两种方式内部实现原理。
第一种方法: 通过 kill 命令的 HUP (hang up) 参数实现
首先Prometheus在 cmd/promethteus/main.go 中实现了对进程系统调用监听,如果收到syscall.SIGHUP信号,将执行reloadConfig函数。
代码类似如下:
{
// Reload handler.
// Make sure that sighup handler is registered with a redirect to the channel before the potentially
// long and synchronous tsdb init.
hup := make(chan os.Signal, 1)
signal.Notify(hup, syscall.SIGHUP)
cancel := make(chan struct{})
g.Add(
func() error {
<-reloadReady.C
for {
select {
case <-hup:
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
}
case rc := <-webHandler.Reload():
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
rc <- err
} else {
rc <- nil
}
case <-cancel:
return nil
}
}
},
func(err error) {
// Wait for any in-progress reloads to complete to avoid
// reloading things after they have been shutdown.
cancel <- struct{}{}
},
)
}
第二种:通过 web 模块的 /-/reload请求实现:
首先 Prometheus 在 web(web/web.go) 模块中注册了一个 POST 的 http 请求 /-/reload, 它的 handler 是 web.reload 函数,该函数主要向 web.reloadCh chan 里面发送一个 error。
其次在Prometheus 的cmd/promethteus/main.go中有个单独的 goroutine 来监听web.reloadCh,当接受到新值的时候会执行 reloadConfig 函数。
func() error {
<-reloadReady.C
for {
select {
case <-hup:
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
}
case rc := <-webHandler.Reload():
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
rc <- err
} else {
rc <- nil
}
case <-cancel:
return nil
}
}
},
Prometheus内部提供了成熟的hot reload方案,这大大方便配置文件的修改和重新加载,在Prometheus生态中,很多Exporter也采用类似约定的实现方式。
Kafka Topic创建三步曲
大数据 空心菜 发表了文章 0 个评论 2464 次浏览 2020-09-19 15:22


通常在生产环境新增业务主题,我们都需要提前预测到,然后做好充分的准备,本文将介绍在生产环境中创建Topic时需要考虑的所有参数。
首先创建新Topic的时候,我们需要设置合理的分区数和副本数,不合理的设置将会给系统的性能和可靠性带来影响。
创建一个Topic
kafka/bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 2 \
--partitions 3 \
--topic unique-topic-name
分区(Partitions)
Kafka主题分为多个分区,其中包含以不变顺序排列的消息。分区中的每个消息均通过其唯一偏移量进行分配和标识。
分区使我们可以在多个Broker之间分配主题数据,从而平衡Broker之间的负载。每个分区只能由一个Consumer Group使用,因此,服务的并行性受Topic拥有的分区数约束。
分区数受两个主要因素的影响,即消息数和每条消息的平均大小。如果交易量很大,您将需要使用代理数量作为乘法倍数,以允许在所有使用者上共享负载,并避免创建热分区,该分区会对特定代理造成高负载。我们的目标是使分区吞吐量达到1MB/s。
设置分区数:
--partitions [number]
副本(Replicas)

如果leader分区发生故障并且需要跟随者(follower)副本替换它并成为领导者(leader),则Kafka可以选择复制Topic分区。在配置Topic时,请记住,分区是为实现快速读写速度,可伸缩性和分发大量数据而设计的。
另一方面,复制因子(RF)旨在确保指定的容错目标。副本不会直接影响性能,因为在任何给定时间,只有一个(leader)领导者分区负责通过Broker服务器处理生产者和使用者请求。
在决定复制因子时的另一个考虑因素是,为了满足生产容量会话,需要考虑服务需要的消费者数量。
设置复制因子(RF):
如果你的Topic承载的是关键业务,推荐你设置复制因子为3,其他的设置为2就够了。
--replication-factor [number]
Tips: 但这里需要注意一点的是, RF <= Broker Number
保留(Retention)
将消息保留在Topic中的时间或最大Topic大小。根据你的用例确定。默认情况下,保留期限为7天,但这是可配置的。
设置Retention:
--config retention.ms=[number]
压缩(Compaction)
为了释放空间并清理不需要的记录,Kafka压缩可以根据记录的日期和大小删除记录。它还可以删除具有相同键的每个记录,同时保留该记录的最新版本。基于键的压缩对于控制Topic的大小非常有用,其中只有最新的记录版本才是重要的。
启用压缩:
log.cleanup.policy=compact
分享阅读原文: http://suo.im/5W8p1p
CDH Hadoop + HBase HA 部署详解
大数据 空心菜 发表了文章 0 个评论 8419 次浏览 2016-11-07 21:07

CDH 的部署和 Apache Hadoop 的部署是没有任何区别的。这里着重的是 HA的部署,需要特殊说明的是NameNode HA 需要依赖 Zookeeper。
准备
Hosts文件配置:
cat > /etc/hosts << _HOSTS_
127.0.0.1 localhost
10.0.2.59 cdh-m1
10.0.2.60 cdh-m2
10.0.2.61 cdh-s1
_HOSTS_
各个节点服务情况
cdh-m1 Zookeeper JournalNode NameNode DFSZKFailoverController HMaster
cdh-m2 Zookeeper JournalNode NameNode DFSZKFailoverController HMaster
cdh-s1 Zookeeper JournalNode DataNode HRegionServer
对几个新服务说明下:
- JournalNode 用于同步 NameNode 元数据,和 Zookeeper 一样需要 2N+1个节点存活集群才可用;
- DFSZKFailoverController(ZKFC) 用于主备切换,类似 Keepalived 所扮演的角色。
NTP 服务
设置时区
rm -f /etc/localtime
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
配置NTP Server
yum install -y ntp
cat > /etc/ntp.conf << _NTP_
driftfile /var/lib/ntp/drift
restrict default nomodify
restrict -6 default nomodify
server cn.ntp.org.cn prefer
server news.neu.edu.cn iburst
server dns.sjtu.edu.cn iburst
server 127.127.1.1 iburst
tinker dispersion 100
tinker step 1800
tinker stepout 3600
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys
_NTP_
# NTP启动时立即同步
cat >> /etc/ntp/step-tickers << _NTP_
server cn.ntp.org.cn prefer
server news.neu.edu.cn iburst
server dns.sjtu.edu.cn iburst
_NTP_
# 同步硬件时钟
cat >> /etc/sysconfig/ntpd << _NTPHW_
SYNC_HWCLOCK=yes
_NTPHW_
启动并设置开机自启动
/etc/init.d/ntpd start
chkconfig ntpd on
配置 NTP Client
yum install -y ntp
# 注意修改内网NTP Server地址
cat > /etc/ntp.conf << _NTP_
driftfile /var/lib/ntp/drift
restrict default nomodify
restrict -6 default nomodify
restrict 127.0.0.1
restrict -6 ::1
server 10.0.2.59 prefer
tinker dispersion 100
tinker step 1800
tinker stepout 3600
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys
_NTP_
# NTP启动时立即同步
cat >> /etc/ntp/step-tickers << _NTP_
server 10.0.2.59 prefer
_NTP_
# 同步硬件时钟
cat >> /etc/sysconfig/ntpd << _NTPHW_
SYNC_HWCLOCK=yes
_NTPHW_
启动并设置开机自启动
/etc/init.d/ntpd start
chkconfig ntpd on
检查 NTP 同步
ntpq -p
# 结果
remote refid st t when poll reach delay offset jitter
==============================================================================
*time7.aliyun.co 10.137.38.86 2 u 17 64 3 44.995 5.178 0.177
news.neu.edu.cn .INIT. 16 u - 64 0 0.000 0.000 0.000
202.120.2.90 .INIT. 16 u - 64 0 0.000 0.000 0.000
JDK配置
创建目录
mkdir -p /data/{install,app,logs,pid,appData}
mkdir /data/appData/tmp
cd /data/install
wget -c http://oracle.com/jdk-7u51-linux-x64.gz
tar xf jdk-7u51-linux-x64.gz -C /data/app
cd /data/app
ln -s jdk1.7.0_51 jdk1.7
cat >> /etc/profile << _PATH_
export JAVA_HOME=/data/app/jdk1.7
export CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar
export PATH=\$JAVA_HOME/bin:\$PATH
_PATH_
source /etc/profile
创建运行账户
useradd -u 600 run
下载 安装包
# http://archive.cloudera.com/cdh5/cdh/5/
cd /data/install
wget -c http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.4.5.tar.gz
wget -c http://archive.apache.org/dist/zookeeper/zookeeper-3.4.5/zookeeper-3.4.5.tar.gz
wget -c http://archive.cloudera.com/cdh5/cdh/5/hbase-1.0.0-cdh5.4.5.tar.gz
安装 Zookeeper
cd /data/install
tar xf zookeeper-3.4.5.tar.gz -C /data/app
cd /data/app
ln -s zookeeper-3.4.5 zookeeper
设置环境变量
sed -i '/^export PATH=/i\export ZOOKEEPER_HOME=/data/app/zookeeper' /etc/profile
sed -i 's#export PATH=#&\$ZOOKEEPER_HOME/bin:#' /etc/profile
source /etc/profile
删除无用文件
cd $ZOOKEEPER_HOME
rm -rf *xml *txt zookeeper-3.4.5.jar.* src recipes docs dist-maven contrib
rm -f $ZOOKEEPER_HOME/bin/*.cmd $ZOOKEEPER_HOME/bin/*.txt
rm -f $ZOOKEEPER_HOME/conf/zoo_sample.cfg
创建数据目录
mkdir -p /data/appData/zookeeper/{data,logs}
配置
cat > $ZOOKEEPER_HOME/conf/zoo.cfg << _ZOO_
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/data/appData/zookeeper/data
dataLogDir=/data/appData/zookeeper/logs
server.1=cdh-m1:2888:3888
server.2=cdh-m2:2888:3888
server.3=cdh-s1:2888:3888
_ZOO_
修改Zookeeper的日志打印方式,与日志路径设置, 编辑
$ZOOKEEPER_HOME/bin/zkEnv.sh
在27行后加入两个变量
ZOO_LOG_DIR=/data/logs/zookeeper
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
创建 myid文件
# 注意myid与配置文件保持一致
echo 1 >/data/appData/zookeeper/data/myid
设置目录权限
chown -R run.run /data/{app,appData,logs}
启动、停止
# 启动
runuser - run -c 'zkServer.sh start'
# 停止
runuser - run -c 'zkServer.sh stop'
安装 Hadoop
tar xf hadoop-2.6.0-cdh5.4.5.tar.gz -C /data/app
cd /data/app
ln -s hadoop-2.6.0-cdh5.4.5 hadoop
设置环境变量
sed -i '/^export PATH=/i\export HADOOP_HOME=/data/app/hadoop' /etc/profile
sed -i 's#export PATH=#&\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:#' /etc/profile
source /etc/profile
删除无用文件
cd $HADOOP_HOME
rm -rf *txt share/doc src examples* include bin-mapreduce1 cloudera
find . -name "*.cmd"|xargs rm -f
新建数据目录
mkdir -p /data/appData/hdfs/{name,edits,data,jn,tmp}
配置
切换到配置文件目录
cd $HADOOP_HOME/etc/hadoop
编辑 core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- HDFS 集群名称,可指定端口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdfs-cdh</value>
</property>
<!-- 临时文件目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/appData/hdfs/tmp</value>
</property>
<!-- 回收站设置,0不启用回收站,1440 表示1440分钟后删除 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<!-- SequenceFiles在读写中可以使用的缓存大小,单位 bytes 默认 4096 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 可用压缩算法,启用在hdfs-site.xml中,需要编译动态链接库才能用 -->
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
</configuration>
编辑 hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定hdfs 集群名称,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>hdfs-cdh</value>
</property>
<!-- 指定 Zookeeper 用于NameNode HA,默认官方配置在core-site.xml中,为了查看清晰配置到hdfs-site.xml也是可用的 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>cdh-m1:2181,cdh-m2:2181,cdh-s1:2181</value>
</property>
<!-- hdfs-cdh 下有两个NameNode,分别为 nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.hdfs-cdh</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.hdfs-cdh.nn1</name>
<value>cdh-m1:9000</value>
</property>
<!-- nn1 HTTP通信地址 -->
<property>
<name>dfs.namenode.http-address.hdfs-cdh.nn1</name>
<value>cdh-m1:50070</value>
</property>
<!-- nn2 RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.hdfs-cdh.nn2</name>
<value>cdh-m2:9000</value>
</property>
<!-- nn2 HTTP通信地址 -->
<property>
<name>dfs.namenode.http-address.hdfs-cdh.nn2</name>
<value>cdh-m2:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存储路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://cdh-m1:8485;cdh-m2:8485;cdh-s1:8485;/hdfs-cdh</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置主备切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.hdfs-cdh</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置主备切换方法,每个方法一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 指定运行用户的秘钥,需要NameNode双向免密码登录,用于主备自动切换 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/run/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence 超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>50000</value>
</property>
<!-- NameNode 数据本地存储路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/appData/hdfs/name</value>
</property>
<!-- DataNode 数据本地存储路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/appData/hdfs/data</value>
</property>
<!-- JournalNode 数据本地存储路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/appData/hdfs/jn</value>
</property>
<!-- 修改文件存储到edits,定期同步到DataNode -->
<property>
<name>dfs.namenode.edits.noeditlogchannelflush</name>
<value>true</value>
</property>
<!-- edits 数据本地存储路径 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>/data/appData/hdfs/edits</value>
</property>
<!-- 开启Block Location metadata允许impala知道数据块在哪块磁盘上 默认关闭 -->
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
<!-- 权限检查 默认开启 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- block 大小设置 -->
<property>
<name>dfs.blocksize</name>
<value>64m</value>
</property>
</configuration>
小于5个DataNode建议添加如下配置
<!-- 数据副本数量,不能超过DataNode数量,大集群建议使用默认值 默认 3 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 当副本写入失败时不分配新节点,小集群适用 -->
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
在 hadoop-env.sh 中添加如下变量
export JAVA_HOME=/data/app/jdk1.7
export HADOOP_LOG_DIR=/data/logs/hadoop
export HADOOP_PID_DIR=/data/pid
# SSH端口 可选
export HADOOP_SSH_OPTS="-p 22"
Heap 设置,单位 MB
export HADOOP_HEAPSIZE=1024
权限设置
chown -R run.run /data/{app,appData,logs}
chmod 777 /data/pid
格式化
格式化只需要执行一次,格式化之前启动Zookeeper
切换用户
su - run
启动所有 JournalNode
hadoop-daemon.sh start journalnode
格式化 Zookeeper(为 ZKFC 创建znode)
hdfs zkfc -formatZK
NameNode 主节点格式化并启动
hdfs namenode -format
hadoop-daemon.sh start namenode
NameNode 备节点同步数据并启动
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
启动 ZKFC
hadoop-daemon.sh start zkfc
启动 DataNode
hadoop-daemon.sh start datanode
启动与停止
切换用户
su - run
集群批量启动
需要配置运行用户ssh-key免密码登录,与$HADOOP_HOME/etc/hadoop/slaves
# 启动
start-dfs.sh
# 停止
stop-dfs.sh
单服务启动停止
启动HDFS
hadoop-daemon.sh start journalnode
hadoop-daemon.sh start namenode
hadoop-daemon.sh start zkfc
hadoop-daemon.sh start datanode
停止HDFS
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop journalnode
hadoop-daemon.sh stop zkfc
测试
HDFS HA 测试
打开 NameNode 状态页:
http://cdh-m1:50010
http://cdh-m2:50010
在 Overview 后面能看见 active 或 standby,active 为当前 Master,停止 active 上的 NameNode,检查 standby是否为 active。
HDFS 测试
hadoop fs -mkdir /test
hadoop fs -put /etc/hosts /test
hadoop fs -ls /test
结果:
-rw-r--r-- 2 java supergroup 89 2016-06-15 10:30 /test/hosts
# 其中权限后面的列(这里的2)代表文件总数,即副本数量。
HDFS 管理命令
# 动态加载 hdfs-site.xml
hadoop dfsadmin -refreshNodes
HBase安装配置
cd /data/install
tar xf hbase-1.0.0-cdh5.4.5.tar.gz -C /data/app
cd /data/app
ln -s hbase-1.0.0-cdh5.4.5 hbase
设置环境变量
sed -i '/^export PATH=/i\export HBASE_HOME=/data/app/hbase' /etc/profile
sed -i 's#export PATH=#&\$HBASE_HOME/bin:#' /etc/profile
source /etc/profile
删除无用文件
cd $HBASE_HOME
rm -rf *.txt pom.xml src docs cloudera dev-support hbase-annotations hbase-assembly hbase-checkstyle hbase-client hbase-common hbase-examples hbase-hadoop2-compat hbase-hadoop-compat hbase-it hbase-prefix-tree hbase-protocol hbase-rest hbase-server hbase-shell hbase-testing-util hbase-thrift
find . -name "*.cmd"|xargs rm -f
配置
进入配置文件目录
cd $HBASE_HOME/conf
编辑 hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- HBase 数据存储路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hdfs-cdh/hbase</value>
</property>
<!-- 完全分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- HMaster 节点 -->
<property>
<name>hbase.master</name>
<value>cdh-m1:60000,cdh-m2:60000</value>
</property>
<!-- Zookeeper 节点 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>cdh-m1:2181,cdh-m2:2181,cdh-s1:2181</value>
</property>
<!-- znode 路径,Zookeeper集群中有多个HBase集群需要设置不同znode -->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<!-- HBase 协处理器 -->
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>
</configuration>
在 hbase-env.sh 中添加如下变量
export JAVA_HOME=/data/app/jdk1.7
export HBASE_LOG_DIR=/data/logs/hbase
export HBASE_PID_DIR=/data/pid
export HBASE_MANAGES_ZK=false
# SSH 默认端口 可选
export HBASE_SSH_OPTS="-o ConnectTimeout=1 -p 36000"
Heap 设置,单位 MB
export HBASE_HEAPSIZE=1024
可选设置 regionservers 中添加所有RegionServer主机名,用于集群批量启动、停止。
启动与停止
切换用户
su - run
集群批量启动
需要配置运行用户ssh-key免密码登录,与$HBASE_HOME/conf/regionservers
# 启动
start-hbase.sh
# 停止
stop-hbase.sh
单服务启动停止
HMaster
# 启动
hbase-daemon.sh start master
# 停止
hbase-daemon.sh stop master
HRegionServer
# 启动
hbase-daemon.sh start regionserver
# 停止
hbase-daemon.sh stop regionserver
测试
HBase HA 测试
浏览器打开两个HMaster状态页:
http://cdh-m1:60010
http://cdh-m2:60010
可以在Master后面看见其中一个主机名,Backup Masters中看见另一个。
停止当前Master,刷新另一个HMaster状态页会发现Master后面已经切换,HA成功。
HBase 测试
进入hbase shell 执行:
create 'users','user_id','address','info'
list
put 'users','anton','info:age','24'
get 'users','anton'
# 最终结果
COLUMN CELL
info:age timestamp=1465972035945, value=24
1 row(s) in 0.0170 seconds
清除测试数据:
disable 'users'
drop 'users'
到这里安装就全部完成。
Elasticsearch Recovery详解
大数据 OpenSkill 发表了文章 0 个评论 5709 次浏览 2016-09-08 23:56

基础知识点
在Eleasticsearch中recovery指的就是一个索引的分片分配到另外一个节点的过程;一般在快照恢复、索引副本数变更、节点故障、节点重启时发生。由于master保存整个集群的状态信息,因此可以判断出哪些shard需要做再分配,以及分配到哪个结点,例如:
- 如果某个shard主分片在,副分片所在结点挂了,那么选择另外一个可用结点,将副分片分配(allocate)上去,然后进行主从分片的复制;
- 如果某个shard的主分片所在结点挂了,副分片还在,那么将副分片升级为主分片,然后做主从分片复制;
- 如果某个shard的主副分片所在结点都挂了,则暂时无法恢复,等待持有相关数据的结点重新加入集群后,从该结点上恢复主分片,再选择另外的结点复制副分片。
正常情况下,我们可以通过ES的health的API接口,查看整个集群的健康状态和整个集群数据的完整性:
状态及含义如下:
- green: 所有的shard主副分片都是正常的;
- yellow: 所有shard的主分片都完好,部分副分片没有或者不完整,数据完整性依然完好;
- red: 某些shard的主副分片都没有了,对应的索引数据不完整。
ecovery过程要消耗额外的资源,CPU、内存、结点之间的网络带宽等等。 这些额外的资源消耗,有可能会导致集群的服务性能下降,或者一部分功能暂时不可用。了解一些recovery的过程和相关的配置参数,对于减小recovery带来的资源消耗,加快集群恢复过程都是很有帮助的。
减少集群Full Restart造成的数据来回拷贝
ES集群可能会有整体重启的情况,比如需要升级硬件、升级操作系统或者升级ES大版本。重启所有结点可能带来的一个问题: 某些结点可能先于其他结点加入集群, 先加入集群的结点可能已经可以选举好master,并立即启动了recovery的过程,由于这个时候整个集群数据还不完整,master会指示一些结点之间相互开始复制数据。
那些晚到的结点,一旦发现本地的数据已经被复制到其他结点,则直接删除掉本地“失效”的数据。 当整个集群恢复完毕后,数据分布不均衡,显然是不均衡的,master会触发rebalance过程,将数据在节点之间挪动。
整个过程无谓消耗了大量的网络流量;合理设置recovery相关参数则可以防范这种问题的发生。
gateway.expected_nodes
gateway.expected_master_nodes
gateway.expected_data_nodes
以上三个参数是说集群里一旦有多少个节点就立即开始recovery过程。 不同之处在于,第一个参数指的是master或者data节点都算在内,而后面两个参数则分指master和data node。
在期待的节点数条件满足之前, recovery过程会等待gateway.recover_after_time (默认5分钟) 这么长时间,一旦等待超时,则会根据以下条件判断是否启动:
gateway.recover_after_nodes
gateway.recover_after_master_nodes
gateway.recover_after_data_nodes
举例来说,对于一个有10个data node的集群,如果有以下的设置:
gateway.expected_data_nodes: 10
gateway.recover_after_time: 5m
gateway.recover_after_data_nodes: 8
那么集群5分钟以内10个data node都加入了,或者5分钟以后8个以上的data node加入了,都会立即启动recovery过程。
减少主副本之间的数据复制
如果不是full restart,而是重启单个data node,仍然会造成数据在不同结点之间来回复制。为避免这个问题,可以在重启之前,先关闭集群的shard allocation:
然后在节点重启完成加入集群后,再重新打开: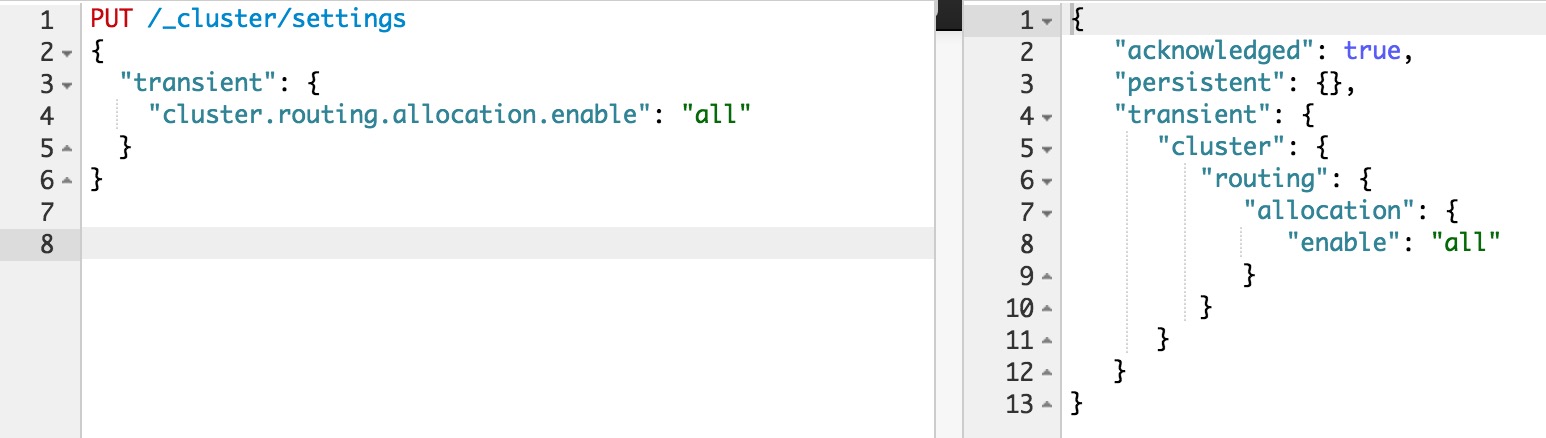
这样在节点重启完成后,尽量多的从本地直接恢复数据。
但是在ES1.6版本之前,即使做了以上措施,仍然会发现有大量主副本之间的数据拷贝。从表面去看,这点很让人不能理解。 主副本数据完全一致,ES应该直接从副本本地恢复数据就好了,为什么要重新从主片再复制一遍呢? 原因在于recovery是简单对比主副本的segment file来判断哪些数据一致可以本地恢复,哪些不一致需要远端拷贝的。而不同节点的segment merge是完全独立运行的,可能导致主副本merge的深度不完全一样,从而造成即使文档集完全一样,产生的segment file却不完全一样。
为了解决这个问题,ES1.6版本以后加入了synced flush的新特性。 对于5分钟没有更新过的shard,会自动synced flush一下,实质是为对应的shard加了一个synced flush ID。这样当重启节点的时候,先对比一下shard的synced flush ID,就可以知道两个shard是否完全相同,避免了不必要的segment file拷贝,极大加快了冷索引的恢复速度。
需要注意的是synced flush只对冷索引有效,对于热索引(5分钟内有更新的索引)没有作用。 如果重启的结点包含有热索引,那么还是免不了大量的文件拷贝。因此在重启一个结点之前,最好按照以下步骤执行,recovery几乎可以瞬间完成:
- 暂停数据写入程序
- 关闭集群shard allocation
- 手动执行POST /_flush/synced
- 重启节点
- 重新开启集群shard allocation
- 等待recovery完成,集群health status变成green
- 重新开启数据写入程序
特大热索引为何恢复慢
对于冷索引,由于数据不再更新,利用synced flush特性,可以快速直接从本地恢复数据。 而对于热索引,特别是shard很大的热索引,除了synced flush派不上用场需要大量跨节点拷贝segment file以外,translog recovery是导致慢的更重要的原因。
从主片恢复数据到副片需要经历3个阶段:
- 对主片上的segment file做一个快照,然后拷贝到复制片分配到的结点。数据拷贝期间,不会阻塞索引请求,新增索引操作记录到translog里;
- 对translog做一个快照,此快照包含第一阶段新增的索引请求,然后重放快照里的索引操作。此阶段仍然不阻塞索引请求,新增索引操作记录到translog里;
- 为了能达到主副片完全同步,阻塞掉新索引请求,然后重放阶段二新增的translog操作。
可见,在recovery完成之前,translog是不能够被清除掉的(禁用掉正常运作期间后台的flush操作)。如果shard比较大,第一阶段耗时很长,会导致此阶段产生的translog很大。重放translog比起简单的文件拷贝耗时要长得多,因此第二阶段的translog耗时也会显著增加。等到第三阶段,需要重放的translog可能会比第二阶段还要多。 而第三阶段是会阻塞新索引写入的,在对写入实时性要求很高的场合,就会非常影响用户体验。 因此,要加快大的热索引恢复速度,最好的方式是遵从上一节提到的方法: 暂停新数据写入,手动sync flush,等待数据恢复完成后,重新开启数据写入,这样可以将数据延迟影响可以降到最低。
万一遇到Recovery慢,想知道进度怎么办呢? CAT Recovery API可以显示详细的recovery各个阶段的状态。 这个API怎么用就不在这里赘述了,参考: CAT Recovery。
其他Recovery相关的专家级设置
还有其他一些专家级的设置(参考: recovery)可以影响recovery的速度,但提升速度的代价是更多的资源消耗,因此在生产集群上调整这些参数需要结合实际情况谨慎调整,一旦影响应用要立即调整回来。 对于搜索并发量要求高,延迟要求低的场合,默认设置一般就不要去动了。 对于日志实时分析类对于搜索延迟要求不高,但对于数据写入延迟期望比较低的场合,可以适当调大indices.recovery.max_bytes_per_sec,提升recovery速度,减少数据写入被阻塞的时长。
最后要说的一点是ES的版本迭代很快,对于Recovery的机制也在不断的优化中。 其中有一些版本甚至引入了一些bug,比如在ES1.4.x有严重的translog recovery bug,导致大的索引trans log recovery几乎无法完成 (issue #9926) 。因此实际使用中如果遇到问题,最好在Github的issue list里搜索一下,看是否使用的版本有其他人反映同样的问题。
分享阅读参考: https://henduan.com/rCWPD
强制清除Elasticsearch中已删除的文件
大数据 空心菜 发表了文章 0 个评论 11219 次浏览 2016-06-05 01:14

Elasticsearch是建立在Apache Lucene基础上的实时分布式搜索引擎,Lucene为了提高搜索的实时性,采用不可再修改(immutable)方式将文档存储在一个个segment中。
也就是说,一个segment在写入到存储系统之后,将不可以再修改。那么Lucene是如何从一个segment中删除一个被索引的文档呢?
简单的讲,当用户发出命令删除一个被索引的文档#ABC时,该文档并不会被马上从相应的存储它的segment中删除掉,而是通过一个特殊的文件来标记该文档已被删除。
当用户再次搜索到#ABC时,Elasticsearch在segment中仍能找到#ABC,但由于#ABC文档已经被标记为删除,所以Lucene会从发回给用户的搜索结果中剔除#ABC,所以给用户感觉的是#ABC已经被删除了。
Elasticseach会有后台线程根据Lucene的合并规则定期进行Segment Merging合并操作,一般不需要用户担心或者采取任何行动。
被删除的文档在segment合并时,才会被真正删除掉。在此之前,它仍然会占用着JVM heap和操作系统的文件cache等资源。在某些情况下,我们需要强制Elasticsearch进行segment merging,已释放其占用的大量系统资源。
POST /{index}/_optimize?only_expunge_deletes=true&wait_for_completion=true
_optimize命令可强制进行segment合并,并删除所有标记为删除的文档。Segment merging要消耗CPU,以及大量的I/O资源,所以一定要在你的ElasticSearch集群处于维护窗口期间,并且有足够的I/O空间的(如:SSD)的条件下进行;否则很可能造成集群崩溃和数据丢失。
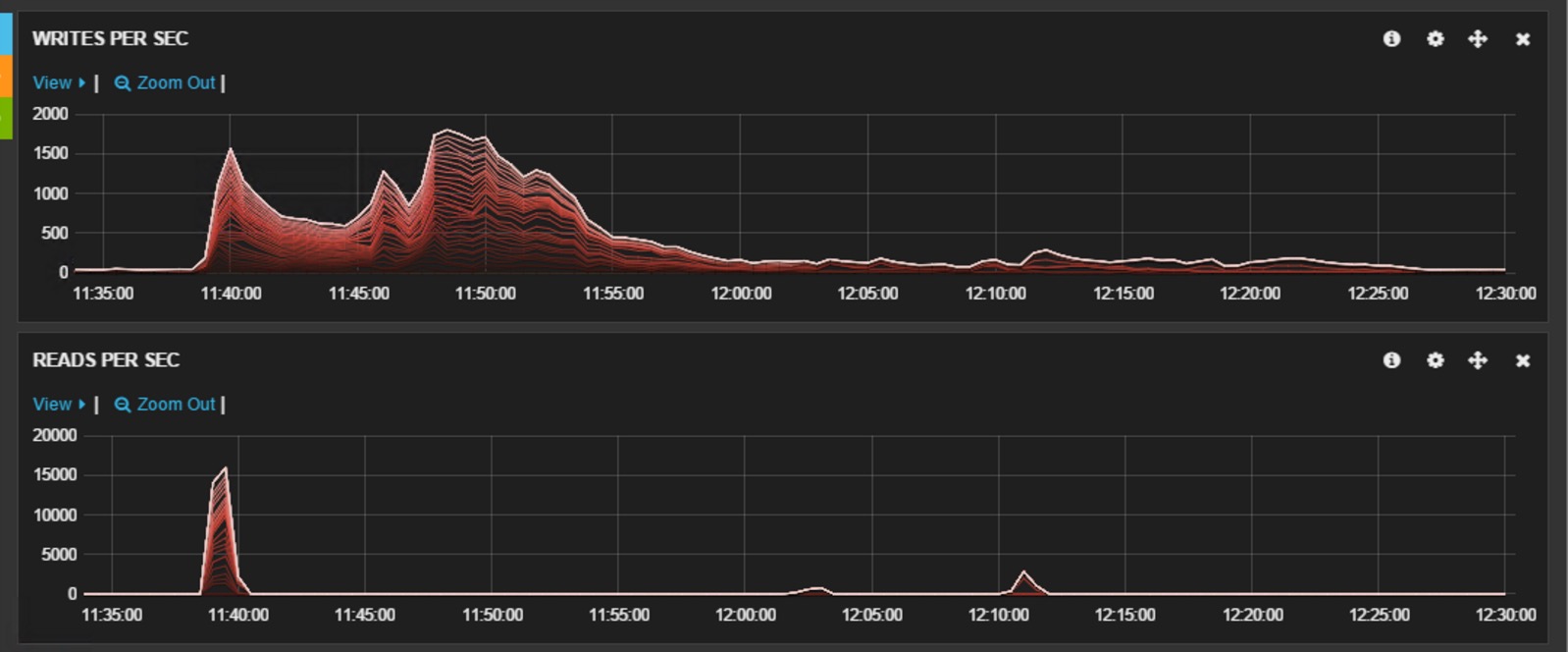
下图展示了我们在进行强制expunge时,所观察到的CPU和磁盘I/O的使用情况。该集群运行在微软的Azure云平台IaaS虚拟机上,所有的数据节点都采用 D13 虚拟机,数据存储在本地的SSD磁盘中。该集群是一个备份集群,为了保证合并顺利进行,在此期间暂停了所有对其进行的写操作,仅有少量的读操作。这里需要注意: expunge操作是一种不得已而为之的操作,即在Elasticsearch不能有效自动清除删除文件的情况下才执行该操作。同时建议在此操作期间,最好停止对集群的所有读/写操作,并暂停止shard的自动分配 ( cluster.routing.allocation.enable= none ),以防有节点被踢出后shard自动分配造成的数据丢失。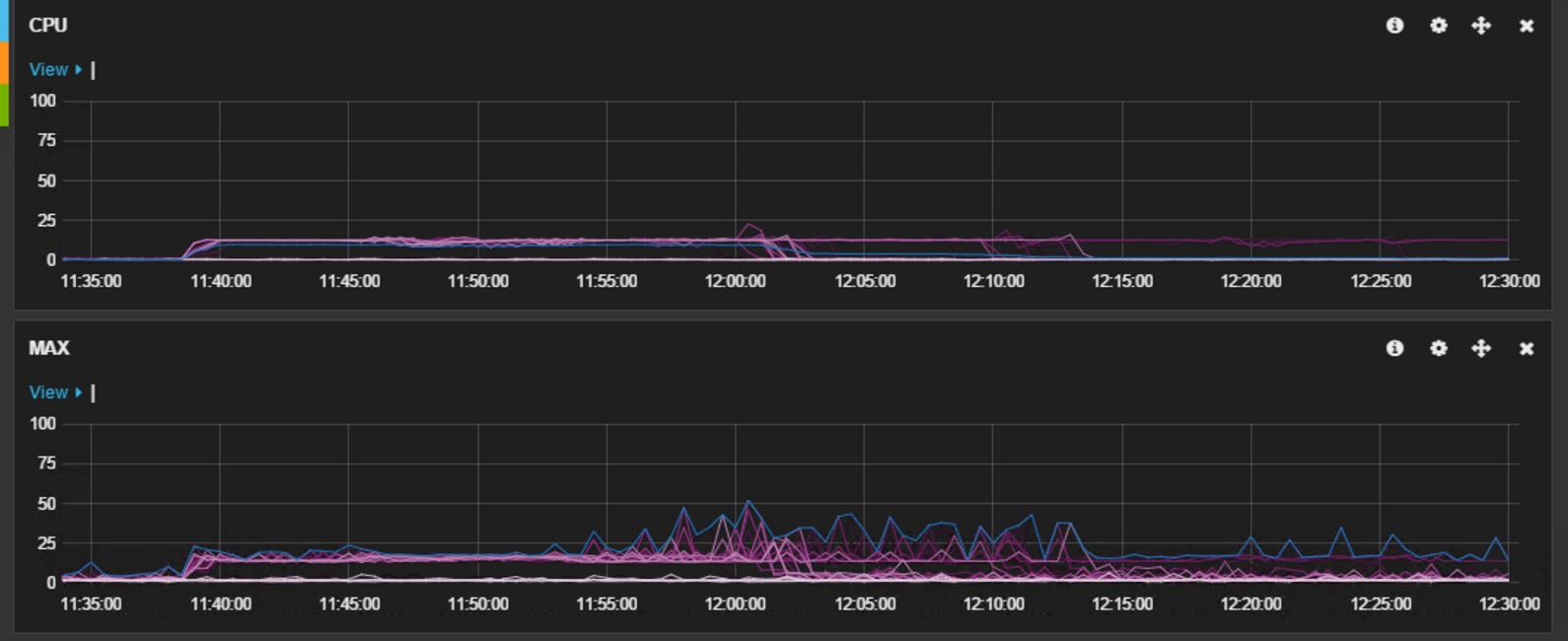
下面两个设置可以用于控制清除时的处理速度,其中给出值是默认值,可以根据需求进行调整,具体请参见Merge。
此外, 还可以临时将所有索引的replica设置为0,这样只用针对Primary进行expunge,以减小I/O压力。
PUT /{index}/_settings
{
"settings": {
"index.merge.policy.expunge_deletes_allowed": "10",
"index.merge.policy.max_merge_at_once_explicit" : "30"
}
}
参考资料:Lucene‘s Handling of Deleted Documents
分享阅读:http://blog.csdn.net/quicknet/article/details/46421505
Hbase/Hdfs删除节点
大数据 空心菜 发表了文章 0 个评论 9643 次浏览 2015-11-30 00:16
之前在文章 http://openskill.cn/article/178 中讲到怎么新增一个hdfs的datanode,所以我先讲一下怎么添加一个hbase的regionserver,然后再讲怎么删除!
添加hbase regionserver节点
添加步骤如下:
1、在hbase master上修改regionservers文件
# cd hbase_install_dir/conf2、如果你hbase集群使用自身zk集群的话,还需要修改hbase-site.xml文件,反之不用操作!
# echo "new_hbase_node_hostname" >> ./regionservers
# cd hbase_install_dir/conf3、同步以上修改的文件到hbase的各个节点上
# vim hbase-site.xml
找到hbase.zookeeper.quorum属性 -->加入新节点
4、在新节点上启动hbase regionserver
# cd hbase_install_dir/bin/5、在hbasemaster启动hbase shell
# ./hbase-daemon.sh start regionserver
用status命令确认一下集群情况hbase新增一个 regionserver节点补充完成了,下面介绍删除hbase和hdfs节点!
集群上既部署有Hadoop,又部署有HBase,因为HBase存储是基于Hadoop HDFS的,所以先要移除HBase节点,之后再移除Hadoop节点。添加则反之。
移除hbase regionserver节点
1、在0.90.2之前,我们只能通过在要卸载的节点上执行;我的hbase版本(0.98.7)
# cd hbase_install_dir来实现。这条语句执行后,该RegionServer首先关闭其负载的所有Region而后关闭自己。在关闭时,RegionServer在ZooKeeper中的"Ephemeral Node"会失效。此时,Master检测到RegionServer挂掉并把它作为一个宕机节点,并将该RegionServer上的Region重新分配到其他RegionServer。
# ./bin/hbase-daemon.sh stop regionserver
注意:使用此方法前,一定要关闭HBase Load Balancer。关闭方法:
hbase(main):001:0> balance_switch false总结:
true
0 row(s) in 0.3290 seconds
这种方法很大的一个缺点是该节点上的Region会离线很长时间。因为假如该RegionServer上有大量Region的话,因为Region的关闭是顺序执行的,第一个关闭的Region得等到和最后一个Region关闭并Assigned后一起上线。这是一个相当漫长的时间。以我这次的实验为例,现在一台RegionServer平均有1000个Region,每个Region Assigned需要4s,也就是说光Assigned就至少需要1个小时。2、自0.90.2之后,HBase添加了一个新的方法,即"graceful_stop",在你移除的服务器执行:
# cd hbase_install_dir该命令会自动关闭Load Balancer,然后Assigned Region,之后会将该节点关闭。除此之外,你还可以查看remove的过程,已经assigned了多少个Region,还剩多少个Region,每个Region 的Assigned耗时。
# ./bin/graceful_stop.sh hostname
补充graceful stop的一些其他命令参数:
# ./bin/graceful_stop.sh最终都需要我们手动打开load balancer:
Usage: graceful_stop.sh [--config &conf-dir>] [--restart] [--reload] [--thrift] [--rest] &hostname>
thrift If we should stop/start thrift before/after the hbase stop/start
rest If we should stop/start rest before/after the hbase stop/start
restart If we should restart after graceful stop
reload Move offloaded regions back on to the stopped server
debug Move offloaded regions back on to the stopped server
hostname Hostname of server we are to stop
hbase(main):001:0> balance_switch false然后再开启:
true
0 row(s) in 0.3590 seconds
hbase(main):001:0> balance_switch true对比两种方法,建议使用"graceful_stop"来移除hbase RegionServer节点。
false
0 row(s) in 0.3290 seconds
官网说明:http://hbase.apache.org/0.94/book/node.management.html http://hbase.apache.org/book.html#decommission
移除hdfs datanode节点
1、在core-site.xml文件下新增如下内容
2、创建exclude文件,把需要删除节点的主机名写入
dfs.hosts.exclude
/hdfs_install_dir/conf/excludes
# cd hdfs_install_dir/conf3、 然后在namenode节点执行如下命令,强制让namenode重新读取配置文件,不需要重启集群。
# vim excludes
添加需要删除的节点主机名,比如 hdnode1 保存退出
# cd hdfs_install_dir/bin/它会在后台进行Block块的移动
# ./hadoop dfsadmin -refreshNodes
4、 查看状态
等待第三步的操作结束后,需要下架的机器就可以安全的关闭了。
# ./hadoop dfsadmin -report可以查看到现在集群上连接的节点
正在执行Decommission,会显示:如下:
Decommission Status : Decommission in progress
执行完毕后,会显示:
Decommission Status : Decommissioned
Name: 10.0.180.6:50010也可以直接通过Hadoop 浏览器查看:
Decommission Status : Decommission in progress
Configured Capacity: 917033340928 (10.83 TB)
DFS Used: 7693401063424 (7 TB)
Non DFS Used: 118121652224 (110.00 GB)
DFS Remaining: 4105510625280(3.63 TB)
DFS Used%: 64.56%
DFS Remaining%: 34.45%
Last contact: Mon Nov 29 23:53:52 CST 2015
LIVE的节点可以查看到:http://master_ip:50070/dfsnodelist.jsp?whatNodes=LIVE
查看看到卸载的节点状态是:Decommission in progress
等待节点完成移除后,浏览:http://master_ip:50070/dfsnodelist.jsp?whatNodes=DEAD 结果如下:

完成后,删除的节点显示在dead nodes中。且其上的服务停止。Live Nodes中仅剩had2,had3
以上即为从Hadoop集群中Remove Node的过程,但是,有一点一定要注意:
hdfs-site.xml配置文件中dfs.replication值必须小于或者等于踢除节点后正常datanode的数量,即:
dfs.replication <= 集群所剩节点数修改备份系数可以参考:http://heylinux.com/archives/2047.html
重载入删除的datanode节点
1、修改namenode的core-site.xml文件,把我们刚刚加入的内容删除或者注释掉,我这里选择注释掉。2、 再执行重载namenode的配置文件
# ./bin/hadoop dfsadmin -refreshNodes3、最后去启动datanode上的datanode
# ./bin/hadoop-daemon.sh start datanode4、查看启动情况
starting datanode, logging to /usr/local/hadoop/bin/../logs/hadoop-root-datanode-had1.out
# jps重新载入HBase RegionServer节点
18653 Jps
19687 DataNode ---->启动正常
只需要重启regionserver进程即可。
参考:http://www.edureka.co/blog/commissioning-and-decommissioning-nodes-in-a-hadoop-cluster/
https://pravinchavan.wordpress.com/2013/06/03/removing-node-from-hadoop-cluster/
控制Elasticsearch分片和副本的分配
大数据 OpenSkill 发表了文章 1 个评论 20054 次浏览 2015-09-15 00:04
为了进行分片和副本的操作,ES需要确定将这些分片和副本放到集群节点的哪个位置,就是需要确定把每个分片和副本分配到哪台服务器/节点上。
一、显式控制分配
生产情景:
比如生产环境有三个索引分别为 man、woman、katoey
希望达到的效果:
man索引放置在一些集群节点上
woman索引又单独放置到集群的另外一些集群节点上
katoey索引希望放置在所有放置man索引和woman索引的集群节点上
这么做是因为katoey索引比其他两个索引小很多,因此我们可以将它和其他两个索引一起分配。
但是基于ES默认算法的处理方法,我们不能确定分片和副本的存放位置,但是ES允许我们对其做相应的控制!
1、指定节点的参数

如上图所示,我们将ES集群划分为两个"空间"。当然你也可以叫做区域,随便命名。我们将左边的三台ES节点服务器放置到zone_one的空间上面,将右边的三台ES节点服务器放到zone_two的空间上。
配置
为了做到我们需要的效果,我们需要将如下属性配置到左边三台ES集群节点服务器的elasticsearch.yml配置文件中
node.zone: zone_one将如下属性配置到右边的三台ES集群节点服务器elasticsearch.yml配置文件中
node.zone: zone_two
索引创建
当所有节点配置文件属性配置完成后,我们就可以根据空间名称,我们就可以创建索引放到指定的空间。
首先我们运行如下命令,来创建man索引:
# curl -XPOST "http://ESnode:9200/man'第一条命令是创建man索引;第二条命令是发送到_settings REST端点,用来指定这个索引的其他配置信息。我们将index.routing.allocation.include.zone属性设置为zone_one值,就是我们所希望的把man索引放置到node.zone属性值为zone_one的ES集群节点服务器上。
# curl -XPUT "http://ESnode:9200/man/_settings' -d '{
"index.routing.allocation.include.zone" : "zone_one"
}'
同样对woman索引我们做类似操作:
# curl -XPOST "http://ESnode:9200/woman'不同的是,这次指定woman索引放置在node.zone属性值为zone_two的ES集群节点服务器上
# curl -XPUT "http://ESnode:9200/woman/_settings' -d '{
"index.routing.allocation.include.zone" : "zone_two"
}'
最后我们需要将katoey索引放置到上面所有的ES集群节点上面,配置设置命令如下:
# curl -XPOST "http://ESnode:9200/katoey"
# curl -XPUT "http://ESnode:9200/katoey/_settings" -d '{
"index.routing.allocation.include.zone" : "zone_one,zone_two"
}'
2、分配时排除节点
跟我们上面操作为索引指定放置节点位置一样,我们也可以在索引分配的时候排除某些节点。参照之前的例子,我们新建一个people索引,但是不希望people索引放置到zone_one的ES集群节点服务器上,我们可以运行如下命令操作:
# curl -XPOST "http://EScode:9200/people"请注意,在这里我们使用的是index.routing.allocation.exclude.zone属性而不是index.routing.allocation.include.zone属性。
# curl -XPUT "http://EScode:9200/people/_settings" -d '{
"index.routing.allocation.exclude.zone" : "zone_one"
}'
使用IP地址进行分配配置
除了在节点的配置中添加一些特殊的属性参数外,我们还可以使用IP地址来指定你将分片和副本分配或者不分配到哪些节点上面。为了做到这点,我们应该使用_ip属性,把zone换成_ip就好了。例如我们希望lucky索引分配到IP地址为10.0.1.110和10.0.1.119的节点上,我们可以运行如下命令设置:
# curl -XPOST "http://ESnode:9200/lucky"
# curl -XPUT "http://ESnode:9200/lucky/_settings" -d '{
"index.routing.allocation.include._ip" "10.0.1.110,10.0.1.119"
}'
二、集群范围内分配
除了索引层面指定分配活着排除分配之外(上面我们所做的都是这两种情况),我们还可以指定集群中所有索引的分配。例如,我们希望将所有的新索引分配到IP地址为10.0.1.112和10.0.1.114的节点上,我们可以运行如下命令设置:
# curl -XPUT "http://ESnode:9200/_cluster/settings" -d '{
"transient" : {
"cluster.routing.allocation.include._ip" "10.0.1.112,10.0.1.114"
}
}' 集群级别的控制后续还会分享transient和persistent属性介绍
三、每个节点上分片和副本数量的控制
除了指定分片和副本的分配,我们还可以对一个索引指定每个节点上的最大分片数量。例如我们希望ops索引在每个节点上只有一个分片,我们可以运行如下命令:
# curl -XPUT "http://ESnode:9200/ops/_settings" -d '{
"index.routing.allocation.total_shards_per_node" : 1
}' 这个属性也可以直接配置到elasticsearch.ym配置文件中,或者使用上面命令在活动索引上更新。如果配置不当,导致主分片无法分配的话,集群就会处于red状态。
四、手动移动分片和副本
接下来我们介绍一下节点间手动移动分片和副本。可以使用ElasticSearch提供的_cluster/reroute REST端点进行控制,能够进行下面操作:
- []将一个分片从一个节点移动到另外一个节点[/][]取消对分片的分配[/][]强制对分片进行分配[/]
移动分片
假设我们有两个节点:es_node_one和es_node_two,ElasticSearch在es_node_one节点上分配了ops索引的两个分片,我们现在希望将第二个分片移动到es_node_two节点上。可以如下操作实现:
# curl -XPOST "http://ESnode:9200/_cluster/reroute" -d '{
"commands" : [ {
"move" : {
"index" : "ops",
"shard" : 1,
"from_node" : "es_node_one",
"to_node" : "es_node_two"
}
}]
}' 我们通过move命令的index属性指定移动哪个索引,通过shard属性指定移动哪个分片,最终通过from_node属性指定我们从哪个节点上移动分片,通过to_node属性指定我们希望将分片移动到哪个节点。取消分配
如果希望取消一个正在进行的分配过程,我们通过运行cancel命令来指定我们希望取消分配的索引、节点以及分片,如下所示:
# curl -XPOST "http://ESnode:9200/_cluster/reroute" -d '{
"commands" : [ {
"cancel" : {
"index" : "ops",
"shard" : 0,
"node" : "es_node_one"
}
} ]
}' 运行上面的命令将会取消es_node_one节上ops索引的第0个分片的分配分配分片
除了取消和移动分片和副本之外,我们还可以将一个未分配的分片分配到一个指定的节点上。假设ops索引上有一个编号为0的分片尚未分配,并且我们希望ElasticSearch将其分配到es_node_two上,可以运行如下命令操作:
# curl -XPOST "http://ESnode:9200/_cluster/reroute' -d '{
"commands" : [ {
"allocate" : {
"index" : "ops",
"shard" : 0,
"node" : "es_node_two"
}
} ]
}'一次HTTP请求包含多个命令我们可以在一次HTTP请求中包含多个命令,例如:
# curl -XPOST "http://ESnode:9200/_cluster/reroute" -d '{
"commands" : [
{"move" : {"index" : "ops", "shard" : 1, "from_node" : "es_node_one", "to_node" : "es_node_two"}},
{"cancel" : {"index" : "ops", "shard" : 0, "node" : "es_node_one"}}
]
}'
Elasticsearch 分片交互过程详解
数据库 Ansible 发表了文章 1 个评论 6455 次浏览 2015-06-18 01:40

一、Elasticseach如何将数据存储到分片中
问题:当我们要在ES中存储数据的时候,数据应该存储在主分片和复制分片中的哪一个中去;当我们在ES中检索数据的时候,又是怎么判断要查询的数据是属于哪一个分片。
数据存储到分片的过程是一定规则的,并不是随机发生的。
规则:shard = hash(routing) % number_of_primary_shards
Routing值可以是一个任意的字符串,默认情况下,它的值为存数数据对应文档 _id 值,也可以是用户自定义的值。Routing这个字符串通过一个hash的函数处理,并返回一个数值,然后再除以索引中主分片的数目,所得的余数作为主分片的编号,取值一般在0到number_of_primary_shards - 1的这个范围中。通过这种方法计算出该数据是存储到哪个分片中。
正是这种路由机制,导致了主分片的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索。
二、主分片与复制分片如何交互
为了说明这个问题,我用一个例子来说明。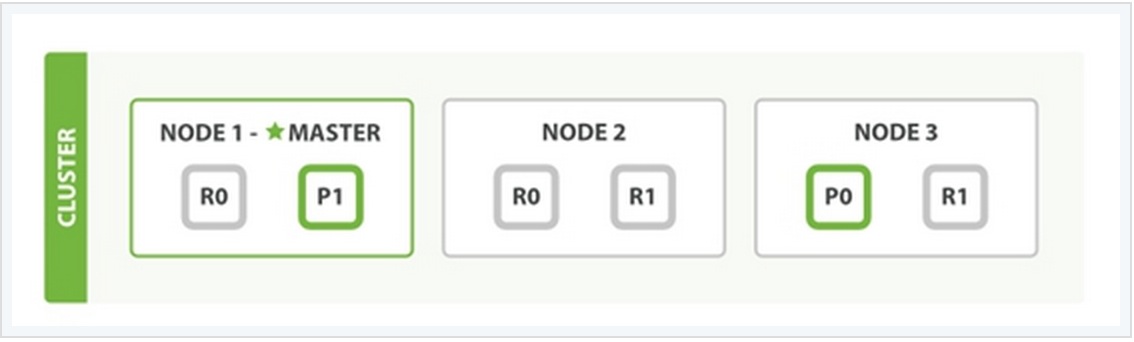
在上面这个例子中,有三个ES的node,其中每一个index中包含两个primary shard,每个primary shard拥有2个replica shard。下面从几种常见的数据操作来说明二者之间的交互情况。
1、索引与删除一个文档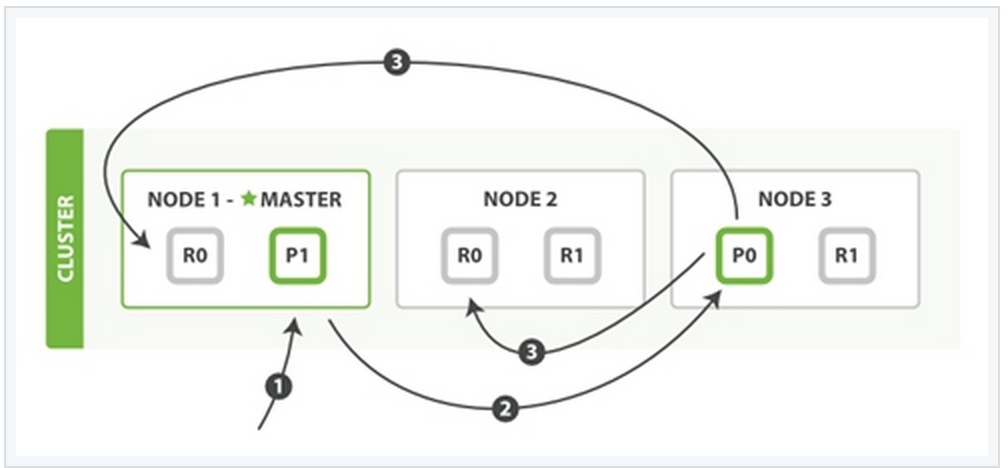
这两种过程均可以分为三个过程来描述:
阶段1:客户端发送了一个索引或者删除的请求给node 1。
阶段2:node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3在shard 0 的primary shard上执行请求。如果请求执行成功,它node 3将并行地将该请求发给shard 0的其余所有replica shard上,也就是存在于node 1和node 2中的replica shard。如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
2、更新一个文档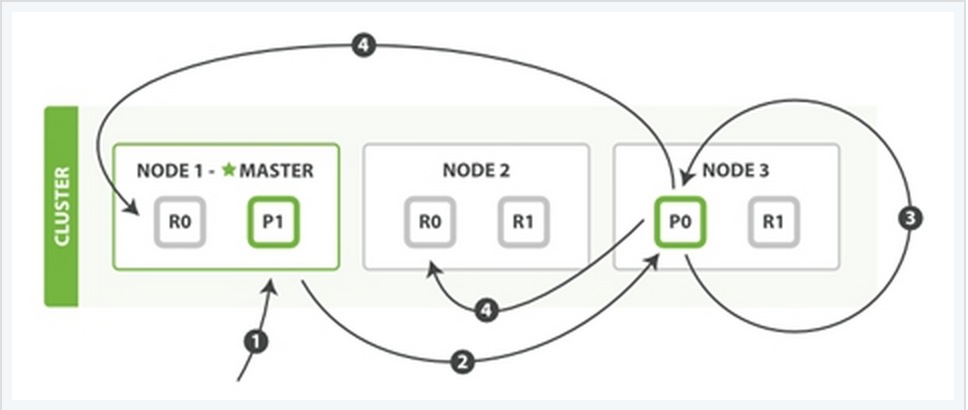
该过程可以分为四个阶段来描述:
阶段1:客户端向node 1发送一个文档更新的请求。
阶段2:同样的node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3从文档所在的primary shard中获取到它的JSON文件,并修改其中的_source中的内容,之后再重新索引该文档到其primary shard中。
阶段4:如果node 3成功地更新了文档,node 3将会把文档新的版本并行地发给其余所有的replica shard所在node中。这些node也同样重新索引新版本的文档,执行后则向node 3确认成功,当node 3接收到所有的成功确认之后,再向客户端发送一个更新成功的信息。
3、检索文档
CRUD这些操作的过程中一般都是结合一些唯一的标记例如:_index,_type,以及routing的值,这就意味在执行操作的时候都是确切的知道文档在集群中的哪个node中,哪个shard中。
而检索过程往往需要更多的执行模式,因为我们并不清楚所要检索的文档具体位置所在, 它们可能存在于ES集群中个任何位置。因此,一般情况下,检索的执行不得不去询问index中的每一个shard。
但是,找到所有匹配检索的文档仅仅只是检索过程的一半,在向客户端返回一个结果列表之前,必须将各个shard发回的小片的检索结果,拼接成一个大的已排好序的汇总结果列表。正因为这个原因,检索的过程将分为查询阶段与获取阶段(Query Phase and Fetch Phase)。
Query Phase
在最初的查询过程中,查询请求会广播到index中的每一个primary shard和replica shard中,每一个shard会在本地执行检索,并建立一个优先级队列(priority queue)。这个优先级队列是一个根据文档匹配度这个指标所排序列表,列表的长度由分页参数from和size两个参数所决定。例如: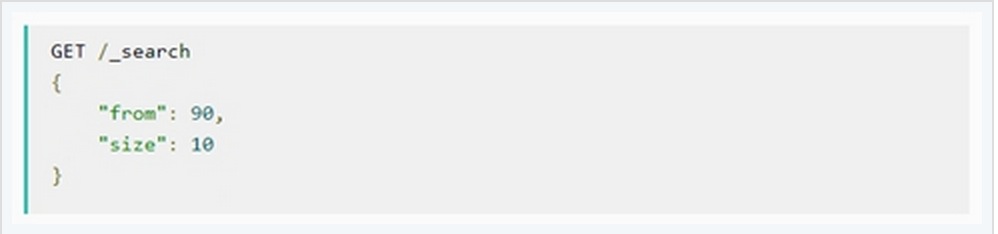
下面从一个例子中说明这个过程:
Query Phase阶段可以再细分成3个小的子阶段:
子阶段1:客户端发送一个检索的请求给node 3,此时node 3会创建一个空的优先级队列并且配置好分页参数from与size。
子阶段2:node 3将检索请求发送给该index中个每一个shard(这里的每一个意思是无论它是primary还是replica,它们的组合可以构成一个完整的index数据)。每个shard在本地执行检索,并将结果添加到本地优先级队列中。
子阶段3:每个shard返回本地优先级序列中所记录的_id与sort值,并发送node 3。Node 3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
Fetch PhaseQuery Phase主要定位了所要检索数据的具体位置,但是我们还必须取回它们才能完成整个检索过程。而Fetch Phase阶段的任务就是将这些定位好的数据内容取回并返回给客户端。
同样也用一个例子来说明这个过程: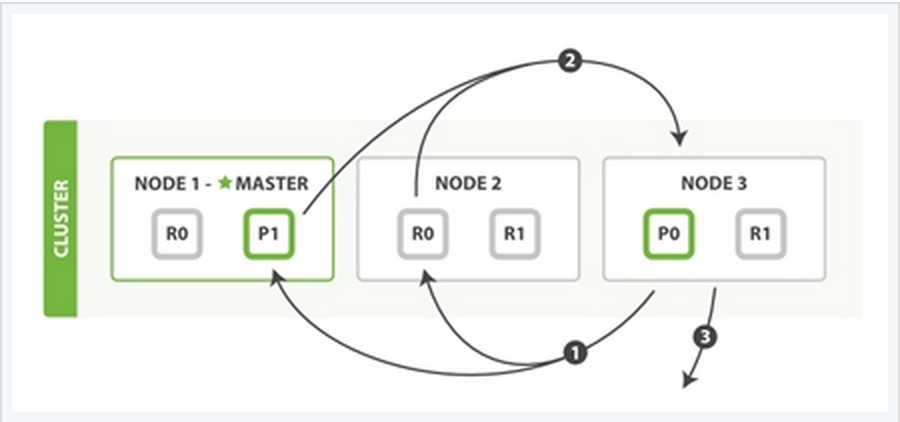
Fetch Phase过程可以分为三个子过程来描述:
子阶段1:node 3获取了所有待检索数据的定位之后,发送一个mget的请求给与数据相关的shard。
子阶段2:每个收到node 3的get请求的shard将读取相关文档_source中的内容,并将它们返回给node 3。
子阶段3:当node 3获取到了所有shard返回的文档后,node 3将它们合并成一条汇总的结果,返回给客户端。
OVM混合虚拟化设计目标及设计思路
大数据 maoliang 发表了文章 0 个评论 3291 次浏览 2016-09-29 09:42
OVM是要实现混合虚拟化,做一个大一统的资源管理和交付平台,纵观虚拟化市场,现在当属开源的KVM和Docker最火,我们工作过去有vmware,现在大量使用kvm,未来一定会考虑docker,但现有市场上的产品要么架构太大,开发难度高,易用性不够强,要么就是单纯的虚拟化,类似vmware等。
新形式下,我们需要的产品要同时具备如下目标:
跨平台,支持KVM、Esxi和Docker容器
因为我们单位过去采用虚拟化技术混杂,上面又遗留很多虚拟机,这就要求我们新开发产品能够兼容不同hypervior,同时还能识别并管理原有hypervior上的虚拟机,能够识别并导入原数据库技术并不难,难的是导入后还能纳入新平台管理,这部分我们又研发了自动捕获技术,而不同混合虚拟化管理技术可以摆脱对底层Hypervisor的依赖,专心于资源的统一管理。
单独的用户自助服务门户
过去采用传统虚拟化时,解决了安装部署的麻烦,但资源的申请和扩容、准备资源和切割资源仍然没有变,还是要让我们做,占据了日常运维工作的大部分工作量,每天确实烦人,所以我们想而这部分工作是可以放给相关的部门Leader或者专员,来减少运维的工作量,所以我们希望新设计的OVM允许用户通过一个单独的Web门户来直接访问自己的资源(云主机、云硬盘、网络等),而且对自己的资源进行管理,而不需要知道资源的具体位置,同时用户的所有云主机都建立在高可用环境之上,也不必担心实际物理硬件故障引起服务瘫痪。
Opscode Chef自动化运维集成
实行自助服务后,有一个问题,就是软件不同版本部署不兼容,这就需要设计能够把操作系统、中间件、数据库、web能统一打包部署,减少自助用户哭天喊地甚至骂我们,我们通过对chef的集成,可以一键更新所有的虚拟机,在指定的虚拟机上安装指定的软件。有了chef工具,为虚拟机打补丁、安装软件,只需要几个简单的命令即可搞定。
可持续性
做运维不要故障处理办法是不行,而且还要自动化的,同时我们有vmware和kvm,就需要新平台能在esxi上(不要vcenter,要付钱的)和kvm同时实现ha功能
可运维性
一个平台再强大,技术再厉害,如果不可运维,那结果可想而知。因此我们希望OVM可以给用户带来一个稳定、可控、安全的生产环境
弹性伸缩
自助服务部门拿到资源后,通过对各项目资源的限额,以及对各虚拟机和容器性能指标的实时监控,可以实现弹性的资源伸缩,达到合理分配利用资源。
资源池化
将数据中心的计算、存储、网络资源全部池化,然后通过OVM虚拟化平台统一对外提供IaaS服务。
2、OVM设计思路
OVM架构选型一
我们觉得架构就是一个产品的灵魂所在,决定着产品日后的发展。
我们团队在产品选型初期,分别调研了目前比较热门的openstack,以及前几年的明星产品convirt、ovirt,这几个产品可谓是典型的代表。
Openstack偏重于公有云,架构设计的很不错,其分布式、插件式的模块化架构,可以有效避免单点故障的发生,从发布之初便备受推崇,但是其存在的问题也同样令人头疼目前使用Openstack的大多是一些有实力的IDC、大型的互联网公司在用。而对于一般的企业来说,没有强大的开发和维护团队,并不敢大规模的采用openstack,初期使用一段时间后我们放弃了OS。
而前几年的convirt,在当时也掀起了一股使用热潮,其简单化的使用体验,足以满足小企业的虚拟化需求,但是他的问题是架构采用了集中式的架构,而且对于上了规模之后,也会带来性能方面的瓶颈,除非是把数据库等一些组件松藕合,解决起来也比较麻烦,所以到了后期也是不温不火,官方也停止了社区的更新和维护。
OVM架构选型二
通过对以上产品的优劣势分析,我们决定采用用分布式、松耦合的模块化插件架构,分布式使其可以规避单点故障,达到业务持续高可用,松耦合的模块化特点让产品在后期的扩展性方面不受任何限制,使其向下可以兼容数据中心所有硬件(通过OVM标准的Rest API接口),向上可以实现插件式的我们即将需要的工作流引擎、计费引擎、报表引擎、桌面云引擎和自动化运维引擎。
而目前阶段我们则专心于实现虚拟化的全部功能,发掘内部对虚拟化的需求,打造一款真正简单、易用、稳定、可运维的一款虚拟化管理软件,并预留向上、向下的接口留作后期发展。(架构图大家可以查看刚才上面发的图片)
虚拟化技术选择
Docker当下很火,其轻量级、灵活、高密度部署是优点,但是大规模使用还未成熟。许多场景还是需要依赖传统的虚拟化技术。所以我们选择传统虚拟化技术KVM+Docker,确保线上业务稳定性、连续性的同时,开发、测试环境又可以利用到Docker的轻量级、高密度和灵活。
另外很多用户的生产环境存在不止一种虚拟化技术,例如KVM+Esxi组合、KVM+XenServer组合、KVM+Hyper-V组合,而目前的虚拟化管理平台,大多都是只支持一种Hypervisor的管理,用户想要维护不同的虚拟化技术的虚拟机,就要反复的在不同环境之间切换。
基于此考虑,我和团队内部和外部一些同行选择兼容(兼容KVM、Esxi,Docker),并自主打造新一代虚拟化管理平台——混合虚拟化。
网络
网络方面,我们对所有Hypervisor的虚拟机使用统一的网络管理(包括Docker容器),这样做的一个好处就是可以减少运维工作量,降低网络复杂性。初期我们只实现2层的虚拟网络管理,为虚拟机和容器提供Vlan隔离、DHCP分配网络,当然也可以手工为虚拟机挑选一个网络,这个可以满足一般的虚拟化需求,后期我们会在此基础上增加虚拟网络防火墙、负载均衡。
存储
存储上面我们采用本地存储+NFS两种方式,对于一般中小企业来说,不希望购买高昂的商业存储,直接使用本地存储虚拟机的性能是最好的,而且我们也提供了存储快照、存储热迁移、虚拟机的无共享热迁移来提升业务安全。此外NFS作为辅助,可以为一些高风险业务提供HA。后期存储方面我们会考虑集成Ceph和GlusterFS存储来提升存储管理。
镜像中心
顾名思义,镜像中心就是用来存放镜像的。传统虚拟化我们使用NFS来作为镜像中心,所有宿主机共享一个镜像中心,这样可以更方便的来统一管理镜像,而针对Docker容器则保留了使用Docker自己的私有仓库,但是我们在WEB UI的镜像中心增加了从Docker私有仓库下载模板这么一个功能,实现了在同一个镜像中心的管理,后期我们会着重打造传统虚拟化镜像与Docker镜像的相互转换,实现两者内容的统一。
HA
OVM 主机HA依然坚持全兼容策略,支持对可管理的所有Hypervisor的HA。
在启用HA的资源池,当检测到一个Hypervisor故障,创建和运行在该Hypervisor共享存储上的虚拟机将在相同资源池下的另外一个主机上重启。
具体工作流程为:
第一次检测到故障会将该故障主机标记;
第二次检测依然故障将启动迁移任务;
迁移任务启动后将在该故障主机所在的资源池寻找合适的主机;
确定合适主机后,会将故障主机上所有的虚拟机自动迁移到合适的主机上面并重新启动;
VM分配策略
负载均衡
PERFORMANCE(性能): 这条策略分配虚拟机到不同的主机上。它挑选一组中可用资源最多的主机来部署虚拟机。如果有多个主机都有相同的资源可用,它使用一个循环算法,每个虚拟机分配到一个不同的主机上。
PROGRESSIVE(逐行扫描): 这条策略意味着,所有虚拟机将被分配在同一个主机上,直到它的资源被用尽。此项策略将一个主机资源使用完,然后再切换到另一个主机。
负载均衡级别
所有资源池: 如果选定此选项,则负载均衡级别策略将适用于所选定数据中心的所有资源池中的主机。
所有主机: 该策略将适用于所选数据中心单个资源池的所有主机。
特定主机: 该策略仅适用于所选的特定主机。
VM设计一
VM是整个虚拟化平台的核心,我们开发了一个单独的模块来负责虚拟机的相关操作。其采用异步通信和独立的并行操作,提升了虚拟机性能、稳定性和扩展性。
可扩展性:独立、并发
可追溯性:错误信息和log、监控控制台、性能
非阻塞操作:稳定性、改进重新配置、改进回滚、标准、统一的hypervisor通信、自动化测试
VM设计二
我们设计基于vApp来部署虚拟机,一个vApp可包含N个虚拟机:
N 个虚拟机配置
N个开机请求
我们希望并行运行N个配置(要求资源允许),并在配置后每个虚拟机请求一个开机。这些操作都是并发和独立的。
平台设计
OVM产品目前由三大组件、七大模块组成。其中三大组件分别为OVM UI、OVM API和OVM数据中心组件。
OVM UI提供WEB自服务界面,OVM API负责UI和数据中心组件之间的交互,OVM数据中心组件分别提供不同的功能。七大模块分别负责不同的功能实现,和三大组件之间分别交互。
VDC资源限额
管理员可以为每个VDC设置资源限额,防止资源的过度浪费。
账户管理
OVM提供存储SDK、备份SDK,以及虚拟防火墙SDK,轻松与第三方实现集成
获得帮助
下载请访问OVM社区官网:51ovm.com
使用过程中遇到什么问题及获得下载密码,加入OVM社区qq官方交流群:22265939
“ 实践是检验真理唯一标准“,OVM社区视您为社区的发展动力,此刻,诚邀您参与我们的调查,共同做出一款真正解决问题、放心的产品,一起推动国内虚拟化的进步和发展。
填写调查问卷!只需1分钟喔!
Hbase/Hdfs删除节点
大数据 空心菜 发表了文章 0 个评论 9643 次浏览 2015-11-30 00:16
之前在文章 http://openskill.cn/article/178 中讲到怎么新增一个hdfs的datanode,所以我先讲一下怎么添加一个hbase的regionserver,然后再讲怎么删除!
添加hbase regionserver节点
添加步骤如下:
1、在hbase master上修改regionservers文件
# cd hbase_install_dir/conf2、如果你hbase集群使用自身zk集群的话,还需要修改hbase-site.xml文件,反之不用操作!
# echo "new_hbase_node_hostname" >> ./regionservers
# cd hbase_install_dir/conf3、同步以上修改的文件到hbase的各个节点上
# vim hbase-site.xml
找到hbase.zookeeper.quorum属性 -->加入新节点
4、在新节点上启动hbase regionserver
# cd hbase_install_dir/bin/5、在hbasemaster启动hbase shell
# ./hbase-daemon.sh start regionserver
用status命令确认一下集群情况hbase新增一个 regionserver节点补充完成了,下面介绍删除hbase和hdfs节点!
集群上既部署有Hadoop,又部署有HBase,因为HBase存储是基于Hadoop HDFS的,所以先要移除HBase节点,之后再移除Hadoop节点。添加则反之。
移除hbase regionserver节点
1、在0.90.2之前,我们只能通过在要卸载的节点上执行;我的hbase版本(0.98.7)
# cd hbase_install_dir来实现。这条语句执行后,该RegionServer首先关闭其负载的所有Region而后关闭自己。在关闭时,RegionServer在ZooKeeper中的"Ephemeral Node"会失效。此时,Master检测到RegionServer挂掉并把它作为一个宕机节点,并将该RegionServer上的Region重新分配到其他RegionServer。
# ./bin/hbase-daemon.sh stop regionserver
注意:使用此方法前,一定要关闭HBase Load Balancer。关闭方法:
hbase(main):001:0> balance_switch false总结:
true
0 row(s) in 0.3290 seconds
这种方法很大的一个缺点是该节点上的Region会离线很长时间。因为假如该RegionServer上有大量Region的话,因为Region的关闭是顺序执行的,第一个关闭的Region得等到和最后一个Region关闭并Assigned后一起上线。这是一个相当漫长的时间。以我这次的实验为例,现在一台RegionServer平均有1000个Region,每个Region Assigned需要4s,也就是说光Assigned就至少需要1个小时。2、自0.90.2之后,HBase添加了一个新的方法,即"graceful_stop",在你移除的服务器执行:
# cd hbase_install_dir该命令会自动关闭Load Balancer,然后Assigned Region,之后会将该节点关闭。除此之外,你还可以查看remove的过程,已经assigned了多少个Region,还剩多少个Region,每个Region 的Assigned耗时。
# ./bin/graceful_stop.sh hostname
补充graceful stop的一些其他命令参数:
# ./bin/graceful_stop.sh最终都需要我们手动打开load balancer:
Usage: graceful_stop.sh [--config &conf-dir>] [--restart] [--reload] [--thrift] [--rest] &hostname>
thrift If we should stop/start thrift before/after the hbase stop/start
rest If we should stop/start rest before/after the hbase stop/start
restart If we should restart after graceful stop
reload Move offloaded regions back on to the stopped server
debug Move offloaded regions back on to the stopped server
hostname Hostname of server we are to stop
hbase(main):001:0> balance_switch false然后再开启:
true
0 row(s) in 0.3590 seconds
hbase(main):001:0> balance_switch true对比两种方法,建议使用"graceful_stop"来移除hbase RegionServer节点。
false
0 row(s) in 0.3290 seconds
官网说明:http://hbase.apache.org/0.94/book/node.management.html http://hbase.apache.org/book.html#decommission
移除hdfs datanode节点
1、在core-site.xml文件下新增如下内容
2、创建exclude文件,把需要删除节点的主机名写入
dfs.hosts.exclude
/hdfs_install_dir/conf/excludes
# cd hdfs_install_dir/conf3、 然后在namenode节点执行如下命令,强制让namenode重新读取配置文件,不需要重启集群。
# vim excludes
添加需要删除的节点主机名,比如 hdnode1 保存退出
# cd hdfs_install_dir/bin/它会在后台进行Block块的移动
# ./hadoop dfsadmin -refreshNodes
4、 查看状态
等待第三步的操作结束后,需要下架的机器就可以安全的关闭了。
# ./hadoop dfsadmin -report可以查看到现在集群上连接的节点
正在执行Decommission,会显示:如下:
Decommission Status : Decommission in progress
执行完毕后,会显示:
Decommission Status : Decommissioned
Name: 10.0.180.6:50010也可以直接通过Hadoop 浏览器查看:
Decommission Status : Decommission in progress
Configured Capacity: 917033340928 (10.83 TB)
DFS Used: 7693401063424 (7 TB)
Non DFS Used: 118121652224 (110.00 GB)
DFS Remaining: 4105510625280(3.63 TB)
DFS Used%: 64.56%
DFS Remaining%: 34.45%
Last contact: Mon Nov 29 23:53:52 CST 2015
LIVE的节点可以查看到:http://master_ip:50070/dfsnodelist.jsp?whatNodes=LIVE
查看看到卸载的节点状态是:Decommission in progress
等待节点完成移除后,浏览:http://master_ip:50070/dfsnodelist.jsp?whatNodes=DEAD 结果如下:
完成后,删除的节点显示在dead nodes中。且其上的服务停止。Live Nodes中仅剩had2,had3
以上即为从Hadoop集群中Remove Node的过程,但是,有一点一定要注意:
hdfs-site.xml配置文件中dfs.replication值必须小于或者等于踢除节点后正常datanode的数量,即:
dfs.replication <= 集群所剩节点数修改备份系数可以参考:http://heylinux.com/archives/2047.html
重载入删除的datanode节点
1、修改namenode的core-site.xml文件,把我们刚刚加入的内容删除或者注释掉,我这里选择注释掉。2、 再执行重载namenode的配置文件
# ./bin/hadoop dfsadmin -refreshNodes3、最后去启动datanode上的datanode
# ./bin/hadoop-daemon.sh start datanode4、查看启动情况
starting datanode, logging to /usr/local/hadoop/bin/../logs/hadoop-root-datanode-had1.out
# jps重新载入HBase RegionServer节点
18653 Jps
19687 DataNode ---->启动正常
只需要重启regionserver进程即可。
参考:http://www.edureka.co/blog/commissioning-and-decommissioning-nodes-in-a-hadoop-cluster/
https://pravinchavan.wordpress.com/2013/06/03/removing-node-from-hadoop-cluster/
新增一个hdfs的DataNode节点
大数据 空心菜 发表了文章 1 个评论 11558 次浏览 2015-11-11 01:51
场景
在hadoop中的分布式文件系统hdfs中,当存储节点磁盘使用达到预警值是,我们需要新增一个数据存储节点,来存储数据!我这里hdfs的版本是2.2.0!新增方法:
- []静态添加[/][]动态添加[/]
静态添加
静态新增的方式,就是相当于我们起初部署hdfs集群规划一样,停止NameNode,新增一个DateNode数据节点,这种方法不适用于线上提供服务的场景,具体操作如下:
1、停止NameNode节点
# cd hdfs_install_dir/sbin/
# ./hadoop-deamon.sh stop namenode
2、修改配置文件slaves文件,并修改/etc/hosts记录把新增的节点对应的ip和hostname追加到各节点
# cd hdfs_install_dir/etc/hadoop/
# echo "new_datanode_hostname" >> ./slaves
# echo "new_datanode_ip new_datanode_hostname" >> /etc/hosts
然后再利用rsync 同步配置文件和hosts文件,到各节点
3、确保Hadoop/HDFS集群的NameNode可以对新节点进行SSH免密码登录。
4、重新启动NameNode节点
5、如果你希望各数据节点磁盘使用量达到一个相对平衡的状态,就是百分比,你还需要执行hadoop balance命令,后面会具体讲到!
动态添加
动态添加,不需要停止启动NameNode节点,具体步骤如下:
1、修改所有hdfs集群机器的配置文件slaves文件,并修改/etc/hosts记录把新增的节点对应的ip和hostname追加到各节点
# cd hdfs_install_dir/etc/hadoop/
# echo "new_datanode_hostname" >> ./slaves
# echo "new_datanode_ip new_datanode_hostname" >> /etc/hosts
如果你使用ansible管理的话,hdfs集群的集群做一个叫hdfs的分组,两条命令搞定:
# ansible hdfs -m shell -a 'echo "new_datanode_hostname" >> hdfs_install_dir/etc/hadoop/slaves'
# ansible hdfs -m shell -a 'echo "new_datanode_ip new_datanode_hostname" >> /etc/hosts'
这样所有的节点slaves文件和host文件都更新了!
2、启动新增的datanode节点
# cd hdfs_install_dir/sbin
# ./hadoop-daemon.sh start datanode
3、查看是否正常加入到集群
web查看方式:http://NameNode_ip:50070/dfsnodelist.jsp?whatNodes=LIVE
命令查看方式:cd hdfs_install_dir/bin/ && ./hadoop dfsadmin -report
4、数据再平衡
添加新节点时,HDFS不会自动重新平衡。然而,HDFS提供了一个手动调用的重新平衡(reblancer)工具。这个工具将整个集群中的数据块分布调整到一个可人工配置的百分比阈值。如果在其他现有的节点上有空间存储问题,再平衡就会根据阀值,然后平衡分布数据。
执行再平衡命令,可选参数-threshold指定了磁盘容量的余量百分比,用来判定一个节点的磁盘利用率是过低还是过高。一个利用不足的数据节点其利用率低于平均利用率−阈值。过度利用的数据节点其利用率高于平均利用率+阈值。该参数设置的越小,整个集群越平衡,但会花费更多的时间进行再平衡操作。默认阈值为10%。平衡执行命令如下:
# cd hdfs_install_dir/sbin/
# ./start-balancer.sh -threshold 5
-threshold参数就是是指定平衡的阈值。
-threshold的默认是10,即每个datanode节点的实际hdfs存储使用量/集群hdfs存储量
具体解释例子如下:
datanode hdfs使用量1000G;
集群总hdfs存储量10T即10000G;
则t值为1000/10000 = 0.1 = 10%
当执行balance的-t参数小于0.1时,集群进行balance;
命令为:start-balancer.sh -threshold 10 ;
Expecting a number in the range of [1.0, 100.0]: 5%sh $HADOOP_HOME/bin/start-balancer.sh –t 10%
这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。
标注知识点
1、 balance命令可以在namenode或者datanode上启动,也可以随时利用stop-balance.sh脚本停止平衡!
2、balance的默认带宽是1M/s。 如果你希望修改平衡数据的带宽大小可以用./hdfs dfsadmin -setBalancerBandwidth 124288000命令指定
3、slave文件是用于重启时使用。集群的start和stop需要读取slave文件。启用datanode时只要在hdfs-site中配置了namenode位置,就可以将信息push给namenode。 这就是为什么slaves文件很重要的原因。

