

System
Centos系统进入单用户修改root用户密码
运维 OS小编 发表了文章 0 个评论 1309 次浏览 2022-05-16 17:15

1. 重启系统,在选择进入系统界面按字母e
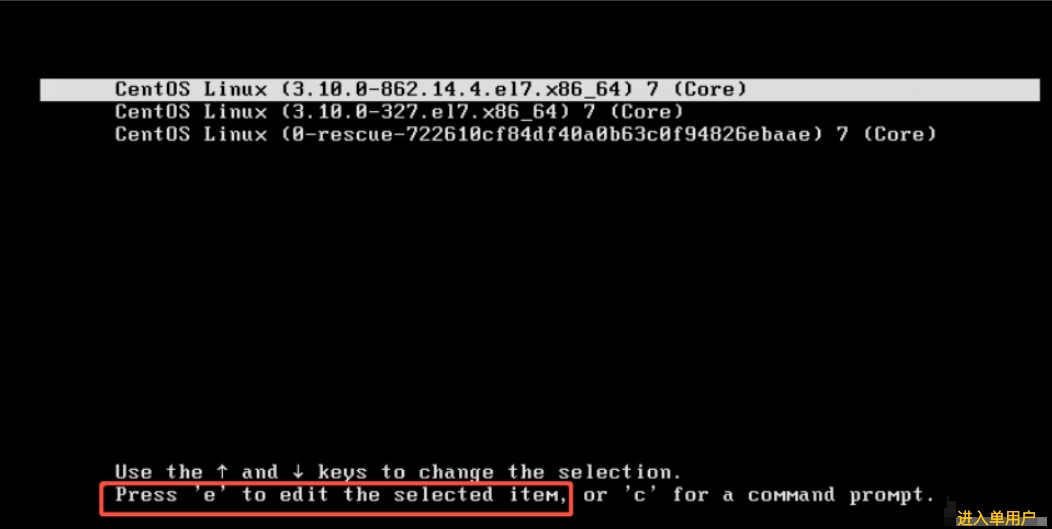
2. 在rhgb前添加’rw’ ,在行末添加 ‘init=/bin/sh’ ,按 ‘Ctrl+x’ 进入系统
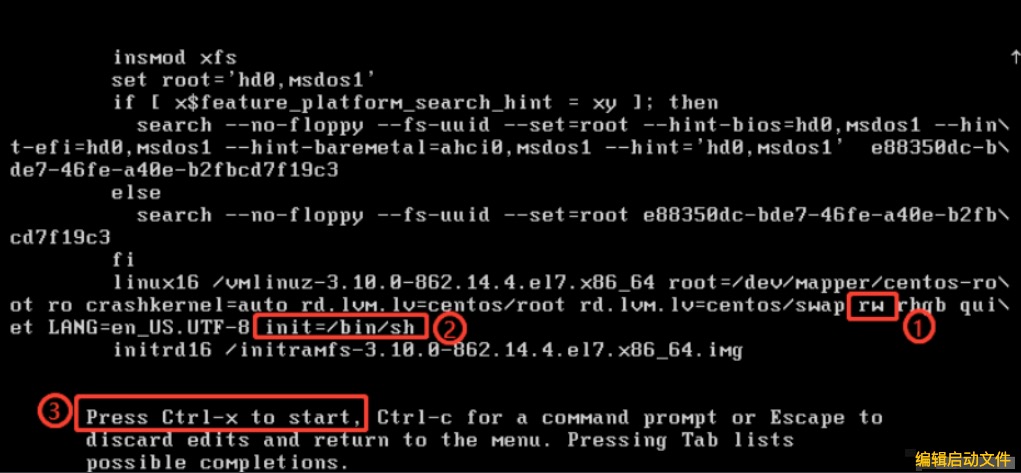
进入系统后,修改密码
echo "www.baidu.com | passwd --stdin root
touch /.autorelabel
exec /sbin/init
等待一会,点击回车,进入重启。
cmake编译程序设置动态链接库加载路径
编程 OS小编 发表了文章 3 个评论 14550 次浏览 2021-05-06 10:42

编译运行的程序需要链接到程序所在路径下的某些个动态库,为方便移植,必须设置链接库的相对路径,比如./lib等等。默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定; - 通过配置
LD_LIBRARY_PATH来指定; - 在
/lib和/usr/lib中查找;
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
为了方便移植运行一些编译安装的应用程序,在编译的时候需要设置链接库读取的相对路径目录, 比如../lib 或者./lib。
默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定rpath; - 通过配置
LD_LIBRARY_PATH来指定,运行加载; - 在
/lib和/usr/lib等系统默认动态库路径中查找。
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
以下两种方式都可以用来配置rpath路径。
1、使用gcc编译选项:
add_definitions(-std=c++11)
SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g -ggdb -Wl,-rpath=./:./lib") #-Wl,-rpath=./
SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wl,-rpath=./:./lib") #-Wall
2、使用cmake配置
set(CMAKE_SKIP_BUILD_RPATH FALSE)
set(CMAKE_BUILD_WITH_INSTALL_RPATH TRUE)
set(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
set(CMAKE_INSTALL_RPATH "./lib")
或者
SET(CMAKE_SKIP_BUILD_RPATH FALSE)
SET(CMAKE_BUILD_WITH_INSTALL_RPATH FALSE)
SET(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib:$ORIGIN/lib")
SET(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
其中RPATH可以使用"./lib"或"./"配置,有可以使用"$ORIGIN/lib"或"\${ORIGIN}/lib",这里必须加上\符号,否则无法识别。
还可以同时定义多个RPATH,比如:"$ORIGIN:$ORIGIN/lib",中间使用:分割。
参考:https://blog.csdn.net/wh8_2011/article/details/79519293
CMAKE和RPATH:https://blog.csdn.net/zhangzq86/article/details/80718559
CMAKE中RPATH的用法:https://blog.csdn.net/z296671124/article/details/86699720
Linux C编程使用相对路径加载动态库: https://blog.csdn.net/dreamcs/article/details/52138229
了解共享库动态加载
运维 OS小编 发表了文章 1 个评论 2206 次浏览 2021-04-30 15:59

在本文中,我将尝试解释在Linux系统中动态加载共享库的内部工作原理。
这边文章不是一个如何引导,尽管它确实展示了如何编译和调试共享库和可执行文件。为了解动态加载的内部工作方式进行了优化。写这篇文章是为了消除我在该主题上的知识欠缺,以便成为一名更好的程序员。我希望它也能帮助您变得更好。
什么是共享库
库是一个包含编译后的代码和数据的文件。一般来说,库非常有用,因为它们可以缩短编译时间(在编译应用程序时不必编译依赖关系的所有源代码)和模块化开发过程。
静态库链接到已编译的可执行文件(或另一个库)中。编译后,新组件将包含静态库的内容。
共享库在运行时由可执行文件(或其他共享库)加载。这让它们变得更加复杂,通常大家对这个领域可能存在认知障碍,我们将在这篇文章中讨论。
示例设置
为了探索共享库的世界,我们将在本文中使用一个示例。我们将从三个源文件开始:
main.cpp是我们定义的可执行文件的主文件, 它不会做太多, 只是从我们将要编译的随机库random调用一个函数:
$ vi main.cpp
#include "random.h"
int main() {
return get_random_number();
}
头文件random.h将定义一个简单的函数:
$ vi random.h
int get_random_number();
它将在其源文件中提供一个简单的实现, random.cpp:
$ vi random.cpp
#include "random.h"
int get_random_number(void) {
return 4;
}
Note: 所有示例均在Ubuntu 14.04系统上运行
编译共享库
在编译实际库之前,我们将从random.cpp创建一个目标文件:
$ clang++ -o random.o -c random.cpp
通常,一切正常后,构建工具不会打印到标准输出。以下是所有解释的参数:
-o random.o: 将输出文件名定义为random.-c: 不尝试任何链接(只编译)random.cpp: 输入文件
接下来,我们将目标文件编译到共享库中:
$ clang++ -shared -o librandom.so random.o
参数-shared用于指定应该构建共享库的标志。
注意:
librandom.so称为共享库。这不是随心所欲的, 呗调用的共享库应该以lib<name>.so使它们以后正确链接(如我们在下面的链接部分中所见)。
编译和链接动态可执行文件
首先,我们将为main.cpp创建一个共享对象:
$ clang++ -o main.o -c main.cpp
与之前完全相同random.o。
现在,我们将尝试创建一个可执行文件:
$ clang++ -o main main.o
main.o: In function `main':
main.cpp:(.text+0x10): undefined reference to `get_random_number()'
clang: error: linker command failed with exit code 1 (use -v to see invocation)
好吧,看来我们需要告诉clang我们要使用librandom.so:
$ clang++ -o main main.o -lrandom
/usr/bin/ld: cannot find -lrandom
clang: error: linker command failed with exit code 1 (use -v to see invocation)
注意: 我们选择动态链接
librandom.so到main。可以静态地执行此操作-并将random库中的所有符号直接加载到main可执行文件中。
我们告诉编译器我们要使用librandom文件。由于它是动态加载的,为什么我们在编译时需要它?好吧,原因是我们需要确保依赖的库包含可执行文件所需的所有符号。还要注意,我们指定random的是库的名称,而不是librandom.so。还记得关于库文件命名的约定吗?这是使用它的地方。
因此,我们需要让我们clang知道在哪里搜索共享库。我们用-L参数来做到这一点。请注意,由指定的路径-L仅在链接时影响搜索路径,而不会在运行时影响。我们将指定当前目录:
$ clang++ -o main main.o -lrandom -L.
现在它可以运行了,但是:
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
当找不到依赖项时,这是我们得到的错误。这将在我们的应用程序甚至运行一行代码之前发生,因为共享库是在可执行文件中的符号之前加载的。
到这就需要面对如下几个问题:
- main它怎么知道依赖
librandom.so? - main在哪里查找
librandom.so? - 要这么告诉main在当前目录查找
librandom.so?
要回答这些问题,我们将不得不更深入地研究这些文件的结构。
ELF - 可执行和可链接的格式
共享库和可执行文件格式称为ELF(可执行和可链接格式)。如果您查看Wikipedia文章,您会发现它是一团糟,因此我们不会一一列举。总之,ELF文件包含:
- ELF Header
- 文件数据,可能包含:
- 程序头表(段头列表)
- 段头表(列表章节标题)
- 以上两个标题指向的数据
ELF标头指定程序标头表中段的大小和数量,以及节标头表中段的大小和数量。每个这样的表都由固定大小的条目组成(我使用该条目在适当的表中描述段标题或节标题)。条目是标题,并且包含指向该段或节的实际主体位置的指针(文件中的偏移量)。该主体存在于文件的数据部分中。更复杂的是-每个部分都是一个段的一部分,一个段可以包含许多段。
实际上,相同的数据要么作为段的一部分引用,要么作为段的一部分引用,这取决于当前上下文。链接时使用分段,执行时使用分段。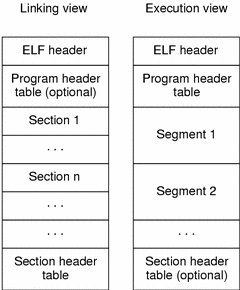
我们将使用readelf命令读取ELF。让我们从查看以下内容的ELF标头开始分析main:
$ readelf -h main
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x4005e0
Start of program headers: 64 (bytes into file)
Start of section headers: 4584 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 9
Size of section headers: 64 (bytes)
Number of section headers: 30
Section header string table index: 27
我们可以看到,这是Unix上的ELF文件(64位), 其类型为EXEC,这是一个可执行文件-符合预期。它有9个程序标头(意味着有9个segment)和30个节标头(即section)。
下一步-程序头(program headers):
$ readelf -l main
Elf file type is EXEC (Executable file)
Entry point 0x4005e0
There are 9 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x000000000000089c 0x000000000000089c R E 200000
LOAD 0x0000000000000dd0 0x0000000000600dd0 0x0000000000600dd0
0x0000000000000270 0x0000000000000278 RW 200000
DYNAMIC 0x0000000000000de8 0x0000000000600de8 0x0000000000600de8
0x0000000000000210 0x0000000000000210 RW 8
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x0000000000000774 0x0000000000400774 0x0000000000400774
0x0000000000000034 0x0000000000000034 R 4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x0000000000000dd0 0x0000000000600dd0 0x0000000000600dd0
0x0000000000000230 0x0000000000000230 R 1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .dynamic .got
同样,我们看到我们有9个程序标头。它们的类型LOAD(有2个),DYNAMIC,NOTE等等。我们也可以看到各段的部分所有权。
最后-节标题(section headers):
$ readelf -S main
There are 30 section headers, starting at offset 0x11e8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000400238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000400254 00000254
0000000000000020 0000000000000000 A 0 0 4
[..]
[21] .dynamic DYNAMIC 0000000000600de8 00000de8
0000000000000210 0000000000000010 WA 6 0 8
[..]
[28] .symtab SYMTAB 0000000000000000 00001968
0000000000000618 0000000000000018 29 45 8
[29] .strtab STRTAB 0000000000000000 00001f80
000000000000023d 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), l (large)
I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
为了简洁起见,我对此进行了修剪。我们看到列出的30个部分带有各种名称(例如.note.ABI-tag)和类型(例如SYMTAB)。
您现在可能会感到困惑, 不用担心一般不会考这方面的东西。在他们的:因为我们感兴趣的是这个文件的特定部分,我解释这个程序头表,ELF文件可以有(和共享特别库必须具有)段头一个描述段型的PT_DYNAMIC。该部分拥有一个名为的部分.dynamic,其中包含有用的信息以了解动态依赖性。
直接依赖
我们可以使用readelf实用工具来进一步探索.dynamic可执行文件的部分。
特别是,本节包含我们ELF文件的所有动态依赖项。我们仅将其指定librandom.so为依赖项,因此我们希望列出main的依赖项:
$ readelf -d main | grep NEEDED
0x0000000000000001 (NEEDED) Shared library: [librandom.so]
0x0000000000000001 (NEEDED) Shared library: [libstdc++.so.6]
0x0000000000000001 (NEEDED) Shared library: [libm.so.6]
0x0000000000000001 (NEEDED) Shared library: [libgcc_s.so.1]
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
objdump可执行文件可以提供类似的结果。在这种情况下,例如:objdump -p librandom.so | grep NEEDED将打印非常相似的输出。
我们可以看到librandom.so我们指定的,但是我们还得到了四个我们没有想到的额外依赖项。这些依赖性似乎出现在所有已编译的共享库中。这些是什么呢?
libstdc++: 标准C++库libm: 包含基本数学函数的库libgcc_s: GCC(GNU编译器集合)运行时库libc: C库:它定义了系统调用和其他基础设施如库open,malloc,printf,exit等。
好的, 我们已经知道main依赖于librandom.so, 那么,为什么在运行时main找不到librandom.so ?
运行时搜索路径
ldd是一个工具,使我们可以查看递归共享库的依赖关系。这意味着我们可以看到程序在运行时需要的所有共享库的完整列表。这也让我们看到了在那里这些依赖所在。让我们继续运行main,看看会发生什么:
$ ldd main
linux-vdso.so.1 => (0x00007fff889bd000)
librandom.so => not found
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f07c55c5000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f07c52bf000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f07c50a9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f07c4ce4000)
/lib64/ld-linux-x86-64.so.2 (0x00007f07c58c9000)
如上,我们看到了文件librandom.so依赖的动态链接库文件,但是提示是not found。
我们还可以看到,我们还有两个附加的库(vdso和ld-linux-x86-64)。它们是间接依赖关系, 更重要的是,我们看到ldd报告了库的位置。比如libstdc++ldd报告其位置为/usr/lib/x86_64-linux-gnu/libstdc++.so.6, 这是怎么知道的呢?
我们的依赖项中的每个共享库都按顺序在以下位置进行搜索:
- 可执行文件
rpath中列出的目录; LD_LIBRARY_PATH环境变量中的目录,该变量包含以冒号分隔的目录列表(例如:/path/to/libdir:/another/path);- 可执行文件
runpath中列出的目录; - 文件
/etc/ld.so.conf中包含的文件目录列表; - 默认系统库-通常为
/lib和/usr/lib(设置-z nodefaultlib参数编译时可跳过)
修复我们的可执行文件
好的, 我们验证了librandom.so是列出的依赖项,但找不到。我们知道在哪里搜索依赖项,ldd再次使用以下命令,确保目录实际上不在搜索路径中:
$ LD_DEBUG=libs ldd main
[..]
3650: find library=librandom.so [0]; searching
3650: search cache=/etc/ld.so.cache
3650: search path=/lib/x86_64-linux-gnu/tls/x86_64:/lib/x86_64-linux-gnu/tls:/lib/x86_64-linux-gnu/x86_64:/lib/x86_64-linux-gnu:/usr/lib/x86_64-linux-gnu/tls/x86_64:/usr/lib/x86_64-linux-gnu/tls:/usr/lib/x86_64-linux-gnu/x86_64:/usr/lib/x86_64-linux-gnu:/lib/tls/x86_64:/lib/tls:/lib/x86_64:/lib:/usr/lib/tls/x86_64:/usr/lib/tls:/usr/lib/x86_64:/usr/lib (system search path)
3650: trying file=/lib/x86_64-linux-gnu/tls/x86_64/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/tls/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/x86_64/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/tls/x86_64/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/tls/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/x86_64/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/librandom.so
3650: trying file=/lib/tls/x86_64/librandom.so
3650: trying file=/lib/tls/librandom.so
3650: trying file=/lib/x86_64/librandom.so
3650: trying file=/lib/librandom.so
3650: trying file=/usr/lib/tls/x86_64/librandom.so
3650: trying file=/usr/lib/tls/librandom.so
3650: trying file=/usr/lib/x86_64/librandom.so
3650: trying file=/usr/lib/librandom.so
[..]
我剪裁了输出。难怪找不到我们的共享库-所在目录librandom.so不在搜索路径中!解决此问题的最特别的方法是使用LD_LIBRARY_PATH:
$ LD_LIBRARY_PATH=. ./main
它可以工作,但不是很轻便。我们不想每次运行程序时都指定lib目录。更好的方法是将依赖项放入文件中, 这就需要设置rpath和runpath。
rpath和runpath
rpath并且runpath是我们的运行时搜索路径“清单”中最复杂的项目。可执行文件或共享库的rpath和runpath在.dynamic我们前面介绍的部分中是可选条目。它们都是要搜索的目录列表。
rpath的类型为
DT_RPATH, runpath的类型为DT_RUNPATH。
rpath和runpath之间的唯一区别是搜索它们的顺序。具体来说,它们与LD_LIBRARY_PATH的顺序: rpath在LD_LIBRARY_PATH之前搜索,而runpath在LD_LIBRARY_PATH之后搜索。这意味着rpath不能用环境变量动态改变,而runpath可以。
设置rpath,看看是否可以让main工作:
$ clang++ -o main main.o -lrandom -L. -Wl,-rpath,.
参数-Wl与-rpath逗号分隔将.标志传递给链接器。要进行设置runpath,我们还必须通过--enable-new-dtags参数设置(-Wl,--enable-new-dtags,-rpath,.)。让我们检查一下结果:
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [.]
$ ./main
可执行文件可以运行,但是已将其添加.到rpath当前的工作目录中。这意味着它将无法从其他目录运行:
$ cd /tmp
$ ~/code/shared_lib_demo/main
/home/nurdok/code/shared_lib_demo/main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
我们有几种解决方法。最简单的方法是复制librandom.so到搜索路径中的目录(例如/lib)。显然,更复杂的方法是我们要执行的操作-指定rpath相对于可执行文件的位置。
$ORIGIN
rpath和runpath中的路径可以是相对于当前工作目录的绝对路径(例如/path/to/my/libs/),但它们也可以是相对于可执行文件的。这是通过使用rpath定义中的$ORIGIN变量来实现的:
$ clang++ -o main main.o -lrandom -L. -Wl,-rpath,"\$ORIGIN"
注意,
$ORIGIN不是一个环境变量。如果你设置ORIGIN=/path,它将不起作用。它总是放置可执行文件的目录。
请注意,我们需要对美元符号进行转义(或使用单引号),以便我们的shell不会尝试对其进行扩展。结果是main可以在每个目录下工作并librandom.so正确找到:
$ ./main
$ cd /tmp
$ ~/code/shared_lib_demo/main
让我们使用我们的工具包来确保:
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [$ORIGIN]
$ ldd main
linux-vdso.so.1 => (0x00007ffe13dfe000)
librandom.so => /home/nurdok/code/shared_lib_demo/./librandom.so (0x00007fbd0ce06000)
[..]
运行时搜索目录之安全性
如果您从命令行更改了Linux用户密码,则可能使用了该passwd实用程序:
$ passwd
Changing password for nurdok.
(current) UNIX password:
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
密码被哈希之后存储在受root保护的文件/etc/shadow中,所以问题来了,非root用户如何更改此文件?
答案是passwd程序设置了setuid位,你可以通过ls看到:
$ ls -l `which passwd`
-rwsr-xr-x 1 root root 39104 2009-12-06 05:35 /usr/bin/passwd
# ^--- This means that the "setuid" bit is set for user execution.
这是s(该行的第四个字符)。设置了此权限位的所有程序均以该程序的所有者身份运行。在此示例中,用户是root(该行的第三个单词)。
这与共享库有什么关系? 我们举个例子.
现在我们在libs目录下有了librandom.so,并且我们将main程序的rpath设置为$ORIGIN/libs:
$ ls
libs main
$ ls libs
librandom.so
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [$ORIGIN/libs]
正常我们是可以运行main的,但是我们给它设置setuid位,并设置属主为root:
$ sudo chown root main
$ sudo chmod a+s main
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
好吧,rpath行不通。让我们尝试设置LD_LIBRARY_PATH:
$ LD_LIBRARY_PATH=./libs ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
还是不行,这里发生了什么?
出于安全考虑,使用提升的权限运行可执行文件(例如,当setuid,setgid特殊功能等)的搜索路径不同于正常:LD_LIBRARY_PATH被忽略,以及任何路径rpath或runpath包含$ORIGIN。
原因是使用这些搜索路径允许利用提升的特权可执行文件以as身份运行root。有关此漏洞利用的详细信息,请参见此处。
基本上,它允许您使提升特权的可执行文件加载您自己的库,该库将以root用户(或其他用户)身份运行。以root身份运行自己的代码几乎可以使您完全控制所使用的计算机。
如果您的可执行文件需要提升的特权,则需要在绝对路径中指定依赖项,或将其放置在默认位置(例如/lib)。
这里要注意的重要行为是,对于此类应用程序,ldd我们必须面对:
$ ldd main
linux-vdso.so.1 => (0x00007ffc2afd2000)
librandom.so => /home/nurdok/code/shared_lib_demo/libs/librandom.so (0x00007f1f666ca000)
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f1f663c6000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f1f660c0000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f1f65eaa000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1f65ae5000)
/lib64/ld-linux-x86-64.so.2 (0x00007f1f668cc000)
ldd不在乎setuid,它会$ORIGIN在搜索我们的依赖项时扩展。在调试对setuid应用程序的依赖项时,这可能是一个陷阱。
调试备忘单
如果在运行可执行文件时遇到此错误:
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
您可以尝试执行以下操作:
- 找出缺少哪些依赖项
ldd <executable>; - 如果您不能识别它们,则可以通过运行来检查它们是否是直接依赖项
readelf -d <executable> | grep NEEDED; - 确保依赖项确实存在。也许您忘了编译它们或将它们移动到libs目录中?
- 找出使用来搜索依赖项的位置
LD_DEBUG=libs ldd <executable>; - 如果您需要在搜索中添加目录:
临时:将目录添加到LD_LIBRARY_PATH环境变量
嵌入文件中:将目录添加到可执行文件或共享库的目录中,rpath或runpath通过传递-Wl,-rpath,<dir>(for rpath)或-Wl,--enable-new-dtags,-rpath,<dir>(for runpath)。使用$ORIGIN相对于可执行文件的路径。
- 如果ldd显示没有依赖项丢失,请查看您的应用程序是否具有提升的特权。如果是这样,ldd可能会撒谎。请参阅上面的安全问题。
原文: https://amir.rachum.com/blog/2016/09/17/shared-libraries/#debugging-cheat-sheet
参考:
https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
https://docs.oracle.com/cd/E23824_01/html/819-0690/chapter6-42444.html
https://www.gnu.org/software/libc/
http://tldp.org/HOWTO/Program-Library-HOWTO/shared-libraries.html
http://unix.stackexchange.com/questions/22926/where-do-executables-look-for-shared-objects-at-runtime
http://www.sco.com/developers/gabi/latest/ch5.pheader.html
https://greek0.net/elf.html
https://en.wikipedia.org/wiki/Rpath
http://blog.lxgcc.net/?tag=dt_rpath
https://cs.nyu.edu/~xiaojian/bookmark/linux/ld_so%20%20Dynamic-Link%20Library%20support.htm
http://unix.stackexchange.com/questions/101467/how-does-the-passwd-command-gain-root-user-permissions
http://nairobi-embedded.org/004_elf_format.html
银河麒麟4.0.2 SP3系统可执行文件报权限不够
运维 chris 发表了文章 1 个评论 22565 次浏览 2021-02-01 11:31

现象
root@Kylin:~# cat aa.sh
echo 1
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# ls -l aa.sh
-rw-r--r-- 1 root root 7 2月 1 10:14 aa.sh
root@Kylin:~# chmod +x aa.sh
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# cat aa.sh
echo 1
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# ls -l aa.sh
-rw-r--r-- 1 root root 7 2月 1 10:14 aa.sh
root@Kylin:~# chmod +x aa.sh
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
如上所示,写了一个简单的Shell脚本,直接bash解释报权限错误,一般权限错误是没有执行权限什么的,但是如上给了权限还是报错。
因为也没有怎么深入使用过银河麒麟的操作系统,然后就上网查询了一下,是因为默认有个Kysec麒麟安全管理工具。
解决方案
方案一 : 通过图形桌面关闭执行控制
方案二: 通过命令设置麒麟系统安全状态为Softmode
root@Kylin:~# getstatus
KySec status: Normal
exec control: on
file protect: on
kmod protect: on
three admin : off
root@Kylin:~# setstatus Softmode
root@Kylin:~# getstatus
KySec status: Softmode
exec control: on
file protect: on
kmod protect: on
three admin : off
root@Kylin:~# bash aa.sh
1
设置开机启动设置:
root@Kylin:~# echo "setstatus Softmode" >> /lib/lsb/init-functions
方案三: 单独设置个别文件权限
oot@Kylin:~# setstatus Normal
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# kysec_set -n exectl -v trusted aa.sh
root@Kylin:~# bash aa.sh
1
kysec_set man手册
kysec_set(8) System Manager's Manual kysec_set(8)
NAME
kysec_set - set kysec label for specfied path(s)
SYNOPSIS
kysec_set [ -n part ] [ -r ] -v value path1 ..
DESCRIPTION
kysec_set set the kysec label of specified files or directories to
value. Kysec label is composed of three parts: identify part, pro‐
tect part and exectl part.
when not used with -n option, kysec label should be in such format:
"identify:protect:exectl". Set the new value to 'none' to clear the
corresponding part of kysec label.
for identify part, these values are valid:
secadm commands for secadm
audadm commands for auditadm
for exectl part, these values are valid:
unknown unknown files
original original system files
verified verified 3rd party files
kysoft software installer
trusted trusted files
for protect part, only readonly is valid.
OPTIONS
-n set specified part of kysec labels. part can be exectl,
userid or protect.
-r process labels recursively, only usable for directories.
-v the new label value
EE ALSO
getstatus(8), setstatus(8), kysec_get(8)
kysec_set(8)
Raid级别结构知识浅析
运维 Ansible 发表了文章 1 个评论 6293 次浏览 2015-11-27 01:15
一、Raid介绍
RAID是(Redundent Array of Inexpensive Disks)的缩写,直译为“廉价冗余磁盘阵列”,也简称为“磁盘阵列”。后来RAID中的字母I被改作了Independent,RAID就成了“独立冗余磁盘阵列”,但这只是名称的变化,实质性的内容并没有改变。可以把RAID理解成一种使用磁盘驱动器的方法,它将一组磁盘驱动器用某种逻辑方式联系起来,作为逻辑上的一个磁盘驱动器来使用。
RAID 包含一组或者一个集合甚至一个阵列。使用一组磁盘结合驱动器组成 RAID 阵列或 RAID 集。将至少两个磁盘连接到一个 RAID 控制器,而成为一个逻辑卷,也可以将多个驱动器放在一个组中。一组磁盘只能使用一个 RAID 级别。使用 RAID 可以提高服务器的性能。不同 RAID 的级别,性能会有所不同。它通过容错和高可用性来保存我们的数据。RAID的优点:
- []传输速率高。在部分RAID模式中,可以让很多磁盘驱动器同时传输数据,而这些磁盘驱动器在逻辑上又是一个磁盘驱动器,所以使用RAID可以达到单个的磁盘驱动器几倍的速率。因为CPU的速度增长很快,而磁盘驱动器的数据传输速率无法大幅提高,所以需要有一种方案解决二者之间的矛盾。[/][]更高的安全性。相较于普通磁盘驱动器很多RAID模式都提供了多种数据修复功能,当RAID中的某一磁盘驱动器出现严重故障无法使用时,可以通过RAID中的其他磁盘驱动器来恢复此驱动器中的数据,而普通磁盘驱动器无法实现,这是使用RAID的第二个原因。[/]
二、Raid概念
软件 RAID 和硬件 RAID
软件 RAID 的性能较低,因为其使用主机的资源。 需要加载 RAID 软件以从软件 RAID 卷中读取数据。在加载 RAID 软件前,操作系统需要引导起来才能加载 RAID 软件。在软件 RAID 中无需物理硬件。零成本投资。
硬件 RAID 的性能较高。他们采用 PCI Express 卡物理地提供有专用的 RAID 控制器。它不会使用主机资源。他们有 NVRAM 用于缓存的读取和写入。缓存用于 RAID 重建时,即使出现电源故障,它会使用后备的电池电源保持缓存。对于大规模使用是非常昂贵的投资。硬件 RAID 卡如下所示:

几个重要Raid概念:
- []校验方式用在 RAID 重建中从校验所保存的信息中重新生成丢失的内容。 RAID 5,RAID 6 基于校验。[/][]条带化是将切片数据随机存储到多个磁盘。它不会在单个磁盘中保存完整的数据。如果我们使用2个磁盘,则每个磁盘存储我们的一半数据。[/][]镜像被用于 RAID 1 和 RAID 10。镜像会自动备份数据。在 RAID 1 中,它会保存相同的内容到其他盘上。[/][]热备份只是我们的服务器上的一个备用驱动器,它可以自动更换发生故障的驱动器。在我们的阵列中,如果任何一个驱动器损坏,热备份驱动器会自动用于重建 RAID。[/][]块是 RAID 控制器每次读写数据时的最小单位,最小 4KB。通过定义块大小,我们可以增加 I/O 性能。[/]
RAID有不同的级别,下面列举比较常用的模式:三、Raid级别
- []RAID0 = 条带化[/][]RAID1 = 镜像[/][]RAID5 = 单磁盘分布式奇偶校验[/][]RAID6 = 双磁盘分布式奇偶校验[/][]RAID10 = 镜像 + 条带。(嵌套RAID)[/]

RAID 0,无冗余无校验的磁盘阵列。数据同时分布在各个磁盘上,没有容错能力,读写速度在RAID中最快,但因为任何一个磁盘损坏都会使整个RAID系统失效,所以安全系数反倒比单个的磁盘还要低。一般用在对数据安全要求不高,但对速度要求很高的场合,如:大型游戏、图形图像编辑等。此种RAID模式至少需要2个磁盘,而更多的磁盘则能提供更高效的数据传输。
条带化有很好的性能。在RAID0(条带化)中数据将使用切片的方式被写入到磁盘。一半的内容放在一个磁盘上,另一半内容将被写入到另一个磁盘。
假设我们有2个磁盘驱动器,例如,如果我们将数据“TECMINT”写到逻辑卷中,“T”将被保存在第一盘中,“E”将保存在第二盘,'C'将被保存在第一盘,“M”将保存在第二盘,它会一直继续此循环过程。(LCTT 译注:实际上不可能按字节切片,是按数据块切片的。)
在这种情况下,如果驱动器中的任何一个发生故障,我们就会丢失数据,因为一个盘中只有一半的数据,不能用于重建 RAID。不过,当比较写入速度和性能时,RAID 0 是非常好的。创建 RAID 0(条带化)至少需要2个磁盘。如果你的数据是非常宝贵的,那么不要使用此 RAID 级别。特点:
- []高性能。[/][]RAID 0 中容量零损失。[/][]零容错。[/][]写和读有很高的性能。[/]

RAID 1,镜象磁盘阵列。每一个磁盘都有一个镜像磁盘,镜像磁盘随时保持与原磁盘的内容一致。RAID1具有最高的安全性,但只有一半的磁盘空间被用来存储数据。主要用在对数据安全性要求很高,而且要求能够快速恢复被损坏的数据的场合。此种RAID模式每组仅需要2个磁盘。
镜像可以对我们的数据做一份相同的副本。假设我们有两个2TB的硬盘驱动器,我们总共有4TB,但在镜像中,但是放在RAID控制器后面的驱动器形成了一个逻辑驱动器,我们只能看到这个逻辑驱动器有2TB。
当我们保存数据时,它将同时写入这两个2TB驱动器中。创建 RAID 1(镜像化)最少需要两个驱动器。如果发生磁盘故障,我们可以通过更换一个新的磁盘恢复 RAID 。如果在 RAID 1 中任何一个磁盘发生故障,我们可以从另一个磁盘中获取相同的数据,因为另外的磁盘中也有相同的数据。所以是零数据丢失。特点:
- []良好的性能。[/][]总容量丢失一半可用空间。[/][]完全容错。[/][]重建会更快。[/][]写性能变慢。[/][]读性能变好。[/][]能用于操作系统和小规模的数据库[/]

RAID 5, 无独立校验盘的奇偶校验磁盘阵列。同样采用奇偶校验来检查错误,但没有独立的校验盘,而是使用了一种特殊的算法,可以计算出任何一个带区校验块的存放位置。这样就可以确保任何对校验块进行的读写操作都会在所有的RAID磁盘中进行均衡,既提高了系统可靠性也消除了产生瓶颈的可能,对大小数据量的读写都有很好的性能。为了能跨越数组里的所有磁盘来写入数据及校验码信息,RAID 5设定最少需要三个磁盘,因此在这种情况下,会有1/3的磁盘容量会被备份校验码占用而无法使用,当有四个磁盘时,则需要1/4的容量作为备份,才能让最坏情况的发生率降到最低。当磁盘的数目增多时,每个磁盘上被备份校验码占用的磁盘容量就会降低,但是磁盘故障的风险率也同时增加了,一但同时有两个磁盘故障,则无法进行数据恢复。
RAID 5多用于企业级。 RAID 5的以分布式奇偶校验的方式工作。奇偶校验信息将被用于重建数据。它从剩下的正常驱动器上的信息来重建。在驱动器发生故障时,这可以保护我们的数据。
假设我们有4个驱动器,如果一个驱动器发生故障而后我们更换发生故障的驱动器后,我们可以从奇偶校验中重建数据到更换的驱动器上。奇偶校验信息存储在所有的4个驱动器上,如果我们有4个 1TB 的驱动器。奇偶校验信息将被存储在每个驱动器的256G中,而其它768GB是用户自己使用的。单个驱动器故障后,RAID 5依旧正常工作,如果驱动器损坏个数超过1个会导致数据的丢失。特点:
- []性能卓越[/][]读速度将非常好。[/][]写速度处于平均水准,如果我们不使用硬件 RAID 控制器,写速度缓慢。[/][]从所有驱动器的奇偶校验信息中重建。[/][]完全容错。[/][]1个磁盘空间将用于奇偶校验。[/][]可以被用在文件服务器,Web服务器,非常重要的备份中。[/]

RAID 6和RAID 5相似但它有两个分布式奇偶校验。大多用在大数量的阵列中。我们最少需要4个驱动器,即使有2个驱动器发生故障,我们依然可以更换新的驱动器后重建数据。
它比RAID 5慢,因为它将数据同时写到4个驱动器上。当我们使用硬件 RAID 控制器时速度就处于平均水准。如果我们有6个的1TB驱动器,4个驱动器将用于数据保存,2个驱动器将用于校验。特点:
- []性能不佳。[/][]读的性能很好。[/][]如果我们不使用硬件 RAID 控制器写的性能会很差。[/][]从两个奇偶校验驱动器上重建。[/][]完全容错。[/][]2个磁盘空间将用于奇偶校验。[/][]可用于大型阵列。[/][]用于备份和视频流中,用于大规模。[/]

RAID 10可以被称为1 + 0或0 +1。它将做镜像+条带两个工作。在 RAID 10中首先做镜像然后做条带。在 RAID 01上首先做条带,然后做镜像。RAID 10比RAID 01好。
假设,我们有4个驱动器。当我逻辑卷上写数据时,它会使用镜像和条带的方式将数据保存到4个驱动器上。如果我在 RAID 10 上写入数据“TECMINT”,数据将使用如下方式保存。首先将“T”同时写入两个磁盘,“E”也将同时写入另外两个磁盘,所有数据都写入两块磁盘。这样可以将每个数据复制到另外的磁盘。同时它将使用 RAID 0 方式写入数据,遵循将“T”写入第一组盘,“E”写入第二组盘。再次将“C”写入第一组盘,“M”到第二组盘。特点:
- []良好的读写性能。[/][]总容量丢失一半的可用空间。[/][]容错。[/][]从副本数据中快速重建。[/][]由于其高性能和高可用性,常被用于数据库的存储中。[/]
下面附录几张参考表:
针对不同RAID 模式在实际运用中可以使用的磁盘空间分别有多少,在用列表举例说明:

所有Raid级别的一些特性:

Centos系统进入单用户修改root用户密码
运维 OS小编 发表了文章 0 个评论 1309 次浏览 2022-05-16 17:15
1. 重启系统,在选择进入系统界面按字母e
2. 在rhgb前添加’rw’ ,在行末添加 ‘init=/bin/sh’ ,按 ‘Ctrl+x’ 进入系统
进入系统后,修改密码
echo "www.baidu.com | passwd --stdin root
touch /.autorelabel
exec /sbin/init
等待一会,点击回车,进入重启。
cmake编译程序设置动态链接库加载路径
编程 OS小编 发表了文章 3 个评论 14550 次浏览 2021-05-06 10:42
编译运行的程序需要链接到程序所在路径下的某些个动态库,为方便移植,必须设置链接库的相对路径,比如./lib等等。默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定; - 通过配置
LD_LIBRARY_PATH来指定; - 在
/lib和/usr/lib中查找;
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
为了方便移植运行一些编译安装的应用程序,在编译的时候需要设置链接库读取的相对路径目录, 比如../lib 或者./lib。
默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定rpath; - 通过配置
LD_LIBRARY_PATH来指定,运行加载; - 在
/lib和/usr/lib等系统默认动态库路径中查找。
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
以下两种方式都可以用来配置rpath路径。
1、使用gcc编译选项:
add_definitions(-std=c++11)
SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g -ggdb -Wl,-rpath=./:./lib") #-Wl,-rpath=./
SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wl,-rpath=./:./lib") #-Wall
2、使用cmake配置
set(CMAKE_SKIP_BUILD_RPATH FALSE)
set(CMAKE_BUILD_WITH_INSTALL_RPATH TRUE)
set(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
set(CMAKE_INSTALL_RPATH "./lib")
或者
SET(CMAKE_SKIP_BUILD_RPATH FALSE)
SET(CMAKE_BUILD_WITH_INSTALL_RPATH FALSE)
SET(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib:$ORIGIN/lib")
SET(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
其中RPATH可以使用"./lib"或"./"配置,有可以使用"$ORIGIN/lib"或"\${ORIGIN}/lib",这里必须加上\符号,否则无法识别。
还可以同时定义多个RPATH,比如:"$ORIGIN:$ORIGIN/lib",中间使用:分割。
参考:https://blog.csdn.net/wh8_2011/article/details/79519293
CMAKE和RPATH:https://blog.csdn.net/zhangzq86/article/details/80718559
CMAKE中RPATH的用法:https://blog.csdn.net/z296671124/article/details/86699720
Linux C编程使用相对路径加载动态库: https://blog.csdn.net/dreamcs/article/details/52138229
了解共享库动态加载
运维 OS小编 发表了文章 1 个评论 2206 次浏览 2021-04-30 15:59
在本文中,我将尝试解释在Linux系统中动态加载共享库的内部工作原理。
这边文章不是一个如何引导,尽管它确实展示了如何编译和调试共享库和可执行文件。为了解动态加载的内部工作方式进行了优化。写这篇文章是为了消除我在该主题上的知识欠缺,以便成为一名更好的程序员。我希望它也能帮助您变得更好。
什么是共享库
库是一个包含编译后的代码和数据的文件。一般来说,库非常有用,因为它们可以缩短编译时间(在编译应用程序时不必编译依赖关系的所有源代码)和模块化开发过程。
静态库链接到已编译的可执行文件(或另一个库)中。编译后,新组件将包含静态库的内容。
共享库在运行时由可执行文件(或其他共享库)加载。这让它们变得更加复杂,通常大家对这个领域可能存在认知障碍,我们将在这篇文章中讨论。
示例设置
为了探索共享库的世界,我们将在本文中使用一个示例。我们将从三个源文件开始:
main.cpp是我们定义的可执行文件的主文件, 它不会做太多, 只是从我们将要编译的随机库random调用一个函数:
$ vi main.cpp
#include "random.h"
int main() {
return get_random_number();
}
头文件random.h将定义一个简单的函数:
$ vi random.h
int get_random_number();
它将在其源文件中提供一个简单的实现, random.cpp:
$ vi random.cpp
#include "random.h"
int get_random_number(void) {
return 4;
}
Note: 所有示例均在Ubuntu 14.04系统上运行
编译共享库
在编译实际库之前,我们将从random.cpp创建一个目标文件:
$ clang++ -o random.o -c random.cpp
通常,一切正常后,构建工具不会打印到标准输出。以下是所有解释的参数:
-o random.o: 将输出文件名定义为random.-c: 不尝试任何链接(只编译)random.cpp: 输入文件
接下来,我们将目标文件编译到共享库中:
$ clang++ -shared -o librandom.so random.o
参数-shared用于指定应该构建共享库的标志。
注意:
librandom.so称为共享库。这不是随心所欲的, 呗调用的共享库应该以lib<name>.so使它们以后正确链接(如我们在下面的链接部分中所见)。
编译和链接动态可执行文件
首先,我们将为main.cpp创建一个共享对象:
$ clang++ -o main.o -c main.cpp
与之前完全相同random.o。
现在,我们将尝试创建一个可执行文件:
$ clang++ -o main main.o
main.o: In function `main':
main.cpp:(.text+0x10): undefined reference to `get_random_number()'
clang: error: linker command failed with exit code 1 (use -v to see invocation)
好吧,看来我们需要告诉clang我们要使用librandom.so:
$ clang++ -o main main.o -lrandom
/usr/bin/ld: cannot find -lrandom
clang: error: linker command failed with exit code 1 (use -v to see invocation)
注意: 我们选择动态链接
librandom.so到main。可以静态地执行此操作-并将random库中的所有符号直接加载到main可执行文件中。
我们告诉编译器我们要使用librandom文件。由于它是动态加载的,为什么我们在编译时需要它?好吧,原因是我们需要确保依赖的库包含可执行文件所需的所有符号。还要注意,我们指定random的是库的名称,而不是librandom.so。还记得关于库文件命名的约定吗?这是使用它的地方。
因此,我们需要让我们clang知道在哪里搜索共享库。我们用-L参数来做到这一点。请注意,由指定的路径-L仅在链接时影响搜索路径,而不会在运行时影响。我们将指定当前目录:
$ clang++ -o main main.o -lrandom -L.
现在它可以运行了,但是:
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
当找不到依赖项时,这是我们得到的错误。这将在我们的应用程序甚至运行一行代码之前发生,因为共享库是在可执行文件中的符号之前加载的。
到这就需要面对如下几个问题:
- main它怎么知道依赖
librandom.so? - main在哪里查找
librandom.so? - 要这么告诉main在当前目录查找
librandom.so?
要回答这些问题,我们将不得不更深入地研究这些文件的结构。
ELF - 可执行和可链接的格式
共享库和可执行文件格式称为ELF(可执行和可链接格式)。如果您查看Wikipedia文章,您会发现它是一团糟,因此我们不会一一列举。总之,ELF文件包含:
- ELF Header
- 文件数据,可能包含:
- 程序头表(段头列表)
- 段头表(列表章节标题)
- 以上两个标题指向的数据
ELF标头指定程序标头表中段的大小和数量,以及节标头表中段的大小和数量。每个这样的表都由固定大小的条目组成(我使用该条目在适当的表中描述段标题或节标题)。条目是标题,并且包含指向该段或节的实际主体位置的指针(文件中的偏移量)。该主体存在于文件的数据部分中。更复杂的是-每个部分都是一个段的一部分,一个段可以包含许多段。
实际上,相同的数据要么作为段的一部分引用,要么作为段的一部分引用,这取决于当前上下文。链接时使用分段,执行时使用分段。
我们将使用readelf命令读取ELF。让我们从查看以下内容的ELF标头开始分析main:
$ readelf -h main
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x4005e0
Start of program headers: 64 (bytes into file)
Start of section headers: 4584 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 9
Size of section headers: 64 (bytes)
Number of section headers: 30
Section header string table index: 27
我们可以看到,这是Unix上的ELF文件(64位), 其类型为EXEC,这是一个可执行文件-符合预期。它有9个程序标头(意味着有9个segment)和30个节标头(即section)。
下一步-程序头(program headers):
$ readelf -l main
Elf file type is EXEC (Executable file)
Entry point 0x4005e0
There are 9 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x000000000000089c 0x000000000000089c R E 200000
LOAD 0x0000000000000dd0 0x0000000000600dd0 0x0000000000600dd0
0x0000000000000270 0x0000000000000278 RW 200000
DYNAMIC 0x0000000000000de8 0x0000000000600de8 0x0000000000600de8
0x0000000000000210 0x0000000000000210 RW 8
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x0000000000000774 0x0000000000400774 0x0000000000400774
0x0000000000000034 0x0000000000000034 R 4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x0000000000000dd0 0x0000000000600dd0 0x0000000000600dd0
0x0000000000000230 0x0000000000000230 R 1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .dynamic .got
同样,我们看到我们有9个程序标头。它们的类型LOAD(有2个),DYNAMIC,NOTE等等。我们也可以看到各段的部分所有权。
最后-节标题(section headers):
$ readelf -S main
There are 30 section headers, starting at offset 0x11e8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000400238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000400254 00000254
0000000000000020 0000000000000000 A 0 0 4
[..]
[21] .dynamic DYNAMIC 0000000000600de8 00000de8
0000000000000210 0000000000000010 WA 6 0 8
[..]
[28] .symtab SYMTAB 0000000000000000 00001968
0000000000000618 0000000000000018 29 45 8
[29] .strtab STRTAB 0000000000000000 00001f80
000000000000023d 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), l (large)
I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
为了简洁起见,我对此进行了修剪。我们看到列出的30个部分带有各种名称(例如.note.ABI-tag)和类型(例如SYMTAB)。
您现在可能会感到困惑, 不用担心一般不会考这方面的东西。在他们的:因为我们感兴趣的是这个文件的特定部分,我解释这个程序头表,ELF文件可以有(和共享特别库必须具有)段头一个描述段型的PT_DYNAMIC。该部分拥有一个名为的部分.dynamic,其中包含有用的信息以了解动态依赖性。
直接依赖
我们可以使用readelf实用工具来进一步探索.dynamic可执行文件的部分。
特别是,本节包含我们ELF文件的所有动态依赖项。我们仅将其指定librandom.so为依赖项,因此我们希望列出main的依赖项:
$ readelf -d main | grep NEEDED
0x0000000000000001 (NEEDED) Shared library: [librandom.so]
0x0000000000000001 (NEEDED) Shared library: [libstdc++.so.6]
0x0000000000000001 (NEEDED) Shared library: [libm.so.6]
0x0000000000000001 (NEEDED) Shared library: [libgcc_s.so.1]
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
objdump可执行文件可以提供类似的结果。在这种情况下,例如:objdump -p librandom.so | grep NEEDED将打印非常相似的输出。
我们可以看到librandom.so我们指定的,但是我们还得到了四个我们没有想到的额外依赖项。这些依赖性似乎出现在所有已编译的共享库中。这些是什么呢?
libstdc++: 标准C++库libm: 包含基本数学函数的库libgcc_s: GCC(GNU编译器集合)运行时库libc: C库:它定义了系统调用和其他基础设施如库open,malloc,printf,exit等。
好的, 我们已经知道main依赖于librandom.so, 那么,为什么在运行时main找不到librandom.so ?
运行时搜索路径
ldd是一个工具,使我们可以查看递归共享库的依赖关系。这意味着我们可以看到程序在运行时需要的所有共享库的完整列表。这也让我们看到了在那里这些依赖所在。让我们继续运行main,看看会发生什么:
$ ldd main
linux-vdso.so.1 => (0x00007fff889bd000)
librandom.so => not found
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f07c55c5000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f07c52bf000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f07c50a9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f07c4ce4000)
/lib64/ld-linux-x86-64.so.2 (0x00007f07c58c9000)
如上,我们看到了文件librandom.so依赖的动态链接库文件,但是提示是not found。
我们还可以看到,我们还有两个附加的库(vdso和ld-linux-x86-64)。它们是间接依赖关系, 更重要的是,我们看到ldd报告了库的位置。比如libstdc++ldd报告其位置为/usr/lib/x86_64-linux-gnu/libstdc++.so.6, 这是怎么知道的呢?
我们的依赖项中的每个共享库都按顺序在以下位置进行搜索:
- 可执行文件
rpath中列出的目录; LD_LIBRARY_PATH环境变量中的目录,该变量包含以冒号分隔的目录列表(例如:/path/to/libdir:/another/path);- 可执行文件
runpath中列出的目录; - 文件
/etc/ld.so.conf中包含的文件目录列表; - 默认系统库-通常为
/lib和/usr/lib(设置-z nodefaultlib参数编译时可跳过)
修复我们的可执行文件
好的, 我们验证了librandom.so是列出的依赖项,但找不到。我们知道在哪里搜索依赖项,ldd再次使用以下命令,确保目录实际上不在搜索路径中:
$ LD_DEBUG=libs ldd main
[..]
3650: find library=librandom.so [0]; searching
3650: search cache=/etc/ld.so.cache
3650: search path=/lib/x86_64-linux-gnu/tls/x86_64:/lib/x86_64-linux-gnu/tls:/lib/x86_64-linux-gnu/x86_64:/lib/x86_64-linux-gnu:/usr/lib/x86_64-linux-gnu/tls/x86_64:/usr/lib/x86_64-linux-gnu/tls:/usr/lib/x86_64-linux-gnu/x86_64:/usr/lib/x86_64-linux-gnu:/lib/tls/x86_64:/lib/tls:/lib/x86_64:/lib:/usr/lib/tls/x86_64:/usr/lib/tls:/usr/lib/x86_64:/usr/lib (system search path)
3650: trying file=/lib/x86_64-linux-gnu/tls/x86_64/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/tls/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/x86_64/librandom.so
3650: trying file=/lib/x86_64-linux-gnu/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/tls/x86_64/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/tls/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/x86_64/librandom.so
3650: trying file=/usr/lib/x86_64-linux-gnu/librandom.so
3650: trying file=/lib/tls/x86_64/librandom.so
3650: trying file=/lib/tls/librandom.so
3650: trying file=/lib/x86_64/librandom.so
3650: trying file=/lib/librandom.so
3650: trying file=/usr/lib/tls/x86_64/librandom.so
3650: trying file=/usr/lib/tls/librandom.so
3650: trying file=/usr/lib/x86_64/librandom.so
3650: trying file=/usr/lib/librandom.so
[..]
我剪裁了输出。难怪找不到我们的共享库-所在目录librandom.so不在搜索路径中!解决此问题的最特别的方法是使用LD_LIBRARY_PATH:
$ LD_LIBRARY_PATH=. ./main
它可以工作,但不是很轻便。我们不想每次运行程序时都指定lib目录。更好的方法是将依赖项放入文件中, 这就需要设置rpath和runpath。
rpath和runpath
rpath并且runpath是我们的运行时搜索路径“清单”中最复杂的项目。可执行文件或共享库的rpath和runpath在.dynamic我们前面介绍的部分中是可选条目。它们都是要搜索的目录列表。
rpath的类型为
DT_RPATH, runpath的类型为DT_RUNPATH。
rpath和runpath之间的唯一区别是搜索它们的顺序。具体来说,它们与LD_LIBRARY_PATH的顺序: rpath在LD_LIBRARY_PATH之前搜索,而runpath在LD_LIBRARY_PATH之后搜索。这意味着rpath不能用环境变量动态改变,而runpath可以。
设置rpath,看看是否可以让main工作:
$ clang++ -o main main.o -lrandom -L. -Wl,-rpath,.
参数-Wl与-rpath逗号分隔将.标志传递给链接器。要进行设置runpath,我们还必须通过--enable-new-dtags参数设置(-Wl,--enable-new-dtags,-rpath,.)。让我们检查一下结果:
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [.]
$ ./main
可执行文件可以运行,但是已将其添加.到rpath当前的工作目录中。这意味着它将无法从其他目录运行:
$ cd /tmp
$ ~/code/shared_lib_demo/main
/home/nurdok/code/shared_lib_demo/main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
我们有几种解决方法。最简单的方法是复制librandom.so到搜索路径中的目录(例如/lib)。显然,更复杂的方法是我们要执行的操作-指定rpath相对于可执行文件的位置。
$ORIGIN
rpath和runpath中的路径可以是相对于当前工作目录的绝对路径(例如/path/to/my/libs/),但它们也可以是相对于可执行文件的。这是通过使用rpath定义中的$ORIGIN变量来实现的:
$ clang++ -o main main.o -lrandom -L. -Wl,-rpath,"\$ORIGIN"
注意,
$ORIGIN不是一个环境变量。如果你设置ORIGIN=/path,它将不起作用。它总是放置可执行文件的目录。
请注意,我们需要对美元符号进行转义(或使用单引号),以便我们的shell不会尝试对其进行扩展。结果是main可以在每个目录下工作并librandom.so正确找到:
$ ./main
$ cd /tmp
$ ~/code/shared_lib_demo/main
让我们使用我们的工具包来确保:
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [$ORIGIN]
$ ldd main
linux-vdso.so.1 => (0x00007ffe13dfe000)
librandom.so => /home/nurdok/code/shared_lib_demo/./librandom.so (0x00007fbd0ce06000)
[..]
运行时搜索目录之安全性
如果您从命令行更改了Linux用户密码,则可能使用了该passwd实用程序:
$ passwd
Changing password for nurdok.
(current) UNIX password:
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
密码被哈希之后存储在受root保护的文件/etc/shadow中,所以问题来了,非root用户如何更改此文件?
答案是passwd程序设置了setuid位,你可以通过ls看到:
$ ls -l `which passwd`
-rwsr-xr-x 1 root root 39104 2009-12-06 05:35 /usr/bin/passwd
# ^--- This means that the "setuid" bit is set for user execution.
这是s(该行的第四个字符)。设置了此权限位的所有程序均以该程序的所有者身份运行。在此示例中,用户是root(该行的第三个单词)。
这与共享库有什么关系? 我们举个例子.
现在我们在libs目录下有了librandom.so,并且我们将main程序的rpath设置为$ORIGIN/libs:
$ ls
libs main
$ ls libs
librandom.so
$ readelf -d main | grep path
0x000000000000000f (RPATH) Library rpath: [$ORIGIN/libs]
正常我们是可以运行main的,但是我们给它设置setuid位,并设置属主为root:
$ sudo chown root main
$ sudo chmod a+s main
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
好吧,rpath行不通。让我们尝试设置LD_LIBRARY_PATH:
$ LD_LIBRARY_PATH=./libs ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
还是不行,这里发生了什么?
出于安全考虑,使用提升的权限运行可执行文件(例如,当setuid,setgid特殊功能等)的搜索路径不同于正常:LD_LIBRARY_PATH被忽略,以及任何路径rpath或runpath包含$ORIGIN。
原因是使用这些搜索路径允许利用提升的特权可执行文件以as身份运行root。有关此漏洞利用的详细信息,请参见此处。
基本上,它允许您使提升特权的可执行文件加载您自己的库,该库将以root用户(或其他用户)身份运行。以root身份运行自己的代码几乎可以使您完全控制所使用的计算机。
如果您的可执行文件需要提升的特权,则需要在绝对路径中指定依赖项,或将其放置在默认位置(例如/lib)。
这里要注意的重要行为是,对于此类应用程序,ldd我们必须面对:
$ ldd main
linux-vdso.so.1 => (0x00007ffc2afd2000)
librandom.so => /home/nurdok/code/shared_lib_demo/libs/librandom.so (0x00007f1f666ca000)
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f1f663c6000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f1f660c0000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f1f65eaa000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1f65ae5000)
/lib64/ld-linux-x86-64.so.2 (0x00007f1f668cc000)
ldd不在乎setuid,它会$ORIGIN在搜索我们的依赖项时扩展。在调试对setuid应用程序的依赖项时,这可能是一个陷阱。
调试备忘单
如果在运行可执行文件时遇到此错误:
$ ./main
./main: error while loading shared libraries: librandom.so: cannot open shared object file: No such file or directory
您可以尝试执行以下操作:
- 找出缺少哪些依赖项
ldd <executable>; - 如果您不能识别它们,则可以通过运行来检查它们是否是直接依赖项
readelf -d <executable> | grep NEEDED; - 确保依赖项确实存在。也许您忘了编译它们或将它们移动到libs目录中?
- 找出使用来搜索依赖项的位置
LD_DEBUG=libs ldd <executable>; - 如果您需要在搜索中添加目录:
临时:将目录添加到LD_LIBRARY_PATH环境变量
嵌入文件中:将目录添加到可执行文件或共享库的目录中,rpath或runpath通过传递-Wl,-rpath,<dir>(for rpath)或-Wl,--enable-new-dtags,-rpath,<dir>(for runpath)。使用$ORIGIN相对于可执行文件的路径。
- 如果ldd显示没有依赖项丢失,请查看您的应用程序是否具有提升的特权。如果是这样,ldd可能会撒谎。请参阅上面的安全问题。
原文: https://amir.rachum.com/blog/2016/09/17/shared-libraries/#debugging-cheat-sheet
参考:
https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
https://docs.oracle.com/cd/E23824_01/html/819-0690/chapter6-42444.html
https://www.gnu.org/software/libc/
http://tldp.org/HOWTO/Program-Library-HOWTO/shared-libraries.html
http://unix.stackexchange.com/questions/22926/where-do-executables-look-for-shared-objects-at-runtime
http://www.sco.com/developers/gabi/latest/ch5.pheader.html
https://greek0.net/elf.html
https://en.wikipedia.org/wiki/Rpath
http://blog.lxgcc.net/?tag=dt_rpath
https://cs.nyu.edu/~xiaojian/bookmark/linux/ld_so%20%20Dynamic-Link%20Library%20support.htm
http://unix.stackexchange.com/questions/101467/how-does-the-passwd-command-gain-root-user-permissions
http://nairobi-embedded.org/004_elf_format.html
银河麒麟4.0.2 SP3系统可执行文件报权限不够
运维 chris 发表了文章 1 个评论 22565 次浏览 2021-02-01 11:31
现象
root@Kylin:~# cat aa.sh
echo 1
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# ls -l aa.sh
-rw-r--r-- 1 root root 7 2月 1 10:14 aa.sh
root@Kylin:~# chmod +x aa.sh
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# cat aa.sh
echo 1
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# ls -l aa.sh
-rw-r--r-- 1 root root 7 2月 1 10:14 aa.sh
root@Kylin:~# chmod +x aa.sh
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
如上所示,写了一个简单的Shell脚本,直接bash解释报权限错误,一般权限错误是没有执行权限什么的,但是如上给了权限还是报错。
因为也没有怎么深入使用过银河麒麟的操作系统,然后就上网查询了一下,是因为默认有个Kysec麒麟安全管理工具。
解决方案
方案一 : 通过图形桌面关闭执行控制
方案二: 通过命令设置麒麟系统安全状态为Softmode
root@Kylin:~# getstatus
KySec status: Normal
exec control: on
file protect: on
kmod protect: on
three admin : off
root@Kylin:~# setstatus Softmode
root@Kylin:~# getstatus
KySec status: Softmode
exec control: on
file protect: on
kmod protect: on
three admin : off
root@Kylin:~# bash aa.sh
1
设置开机启动设置:
root@Kylin:~# echo "setstatus Softmode" >> /lib/lsb/init-functions
方案三: 单独设置个别文件权限
oot@Kylin:~# setstatus Normal
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# kysec_set -n exectl -v trusted aa.sh
root@Kylin:~# bash aa.sh
1
kysec_set man手册
kysec_set(8) System Manager's Manual kysec_set(8)
NAME
kysec_set - set kysec label for specfied path(s)
SYNOPSIS
kysec_set [ -n part ] [ -r ] -v value path1 ..
DESCRIPTION
kysec_set set the kysec label of specified files or directories to
value. Kysec label is composed of three parts: identify part, pro‐
tect part and exectl part.
when not used with -n option, kysec label should be in such format:
"identify:protect:exectl". Set the new value to 'none' to clear the
corresponding part of kysec label.
for identify part, these values are valid:
secadm commands for secadm
audadm commands for auditadm
for exectl part, these values are valid:
unknown unknown files
original original system files
verified verified 3rd party files
kysoft software installer
trusted trusted files
for protect part, only readonly is valid.
OPTIONS
-n set specified part of kysec labels. part can be exectl,
userid or protect.
-r process labels recursively, only usable for directories.
-v the new label value
EE ALSO
getstatus(8), setstatus(8), kysec_get(8)
kysec_set(8)
ext4文件系统的delalloc选项造成单次写延迟增加的分析
运维 OS小编 发表了文章 0 个评论 3232 次浏览 2017-04-18 09:30
这篇文章是淘宝内核组的刘峥同学在内部技术论坛上发表的一篇文章,但是由于刘峥同学目前没有blog,征得本人同意,贴在我的blog上,如果大家喜欢,请去新浪微博关注他。:)
日前线上在升级到Ext4文件系统后出现应用写操作延迟开销增大的问题。造成这一问题的根源目前已经查明,是由于Ext4文件系统的一个新特性——Delay Allocation造成的。(后面简称delalloc)
在详细分析这一问题之前,先来介绍一下Ext4文件系统的delalloc特性。这一特性简要概括起来就是将以前在buffer IO中每次写操作都会涉及的磁盘块分配过程推迟到数据回写时再进行。我们知道,在进行Buffer Write时,系统的实际操作仅仅是为这些数据在操作系统内分配内存页(page cache)并保存这些数据,等待用户调用fsync等操作强制刷新或者等待系统触发定时回写过程。在数据拷贝到page cache这一过程中,系统会为这些数据在磁盘上分配对应的磁盘块。
而在使用delalloc后,上面的流程会略有不同,在每次Buffer Write时,数据会被保存到page cache中,但是系统并不会为这些数据分配相应的磁盘块,仅仅会查询是否有已经为这些数据分配过磁盘块,以便决定后面是否需要为这些数据分配磁盘块。在用户调用fsync或者系统触发回写过程时,系统会尝试为标记需要分配磁盘块的这些数据分配磁盘块。这样,文件系统可以为这些属于同一个文件的数据分配尽量连续的磁盘空间,从而优化后续文件的访问性能(因为传统机械硬盘顺序读写的性能要比随机读写好很多)。
了解完delalloc特性的工作过程后,我们开始分析线上遇到的问题。线上应用的I/O模式可以简化为一个单线程追加写操作的程序,每秒写入2、3M数据,写操作后等待系统自动将数据回写到磁盘。在使用delalloc后,每次Buffer Write操作,系统都会去查询数据是否分配了磁盘块,这一过程需要获得一把读锁 (i_data_sem)。由于这时还没有触发回写操作,因此可以顺利获取i_data_sem,系统完成数据拷贝工作,并返回。由于仅仅是内存拷贝的过程,所以这一操作速度相当快。当系统开始进行回写操作时,系统会成批为数据分配磁盘块,这一过程同样需要获取i_data_sem,并且需要加写锁以保证数据的一致性。由于使用delalloc后,需要分配的磁盘块比nodelalloc情况下多很多(nodelalloc情况下每5秒文件系统会提交日志触发回写;delalloc情况下,系统会在约每30秒左右触发一次回写),因此这一延迟时间较长。如果这时应用程序进行一次Buffer Write,则该操作在尝试获得i_data_sem时会等待上述磁盘块分配完成。由此造成写操作等待很长时间,从而影响应用程序的响应延迟。
在上面的分析中已经提到,delalloc是将多次磁盘块分配的过程合并到一次中来进行,那么是否真如预想的那样,delalloc的平均延迟会小于nodelalloc的情况呢?我们使用fio来做如下测试:设置bs=4k,单线程每秒追加写入5M,程序运行3分钟,我们来看一下最后fio对延迟的统计结果:
delalloc:从上面的统计结果看,写操作的平均延迟:打开delalloc后为5.86us,关闭delalloc后为7.00us;最小延迟delalloc为2us,nodelalloc为3us;但是最大延迟delalloc为193.466ms,nodelalloc下仅为16.388ms。可见delalloc确实将多个写操作请求集中到了一起来进行。因此在提供较低平均延迟的情况下,会造成某次写操作的延迟较大。
lat (usec): min=2 , max=193466 , avg= 5.86, stdev=227.91
nodelalloc:
lat (usec): min=3 , max=16388 , avg= 7.00, stdev=28.92
通过上面的分析可以看到,目前会受到Ext4的delalloc特性影响的应用必须具备如下条件:
- Buffer IO
- 写操作过程中会涉及磁盘块的分配,主要是记录日志这类追加写操作;
- 每次写操作后没有刷新数据,而是等待系统自动进行回写;
- 对延迟有较高要求。
解决方法:关闭delalloc
1、mount -t ext4 -o remount,nodelalloc /${dev} /${mnt};
2、编辑/etc/fstab中相关mount项,添加nodelalloc挂载参数企业OpenVPN部署认证实战
运维 欺壹世 发表了文章 0 个评论 6841 次浏览 2017-01-04 17:57

相关概念
1、vpn 介绍
vpn 虚拟专用网络,是依靠isp和其他的nsp,在公共网络中建立专用的数据通信网络的技术。在vpn中任意两点之间的链接并没有传统的专网所需的端到端的物理链路,而是利用公共网络资源动态组成的,可以理解为通过私有的隧道技术在公共数据网络上模拟出来的和专网有相同功能的点到点的专线技术,所谓虚拟是指不需要去拉实际的长途物理线路,而是借用公共的Internet网络实现。
2、vpn 作用
vpn可以帮助公司用的远程用户(出差,家里)公司的分之机构、商业合作伙伴及供应商等公司和自己的公司内部网络之间建立可信的安全连接或者局域网连接,确保数据的加密安全传输和业务访问,对于运维工程师来说,还可以连接不同的机房为局域网,处理相关的业务流。
3、常见vpn功能的开源产品
3.1 pptp vpn
最大优势在于无需在windows客户端单独安装vpn客户端软件,windows默认就支持pptp vpn拨号功能。他是属于点对点的方式应用,比较适合远程企业用户拨号到企业进行办公等应用,缺点很多小区及网络设备不支持pptp导致无法访问。
3.2 SSL VPN(openvpn)
PPTP主要为常在外面移动或者家庭办公的用户考虑的,而OpenVpn不但可以使用与PPTP的场景,还是和针对企业异地两地总分公司之间的vpn不间断按需链接,例如:ERP,OA及时通讯工具等在总分公司企业中的应用,缺点:需要单独安装客户端软件。
3.3 IPSEC VPN
IPSEC VPN 也适合针对企业异地两地中分公司或者多个IDC机房之间的VPN的不间断按需链接,并且在部署使用上更简单方便。IPSEC Vpn的开源产品openswan.
4、openvpn通讯原理
openvpn所有的通讯都基于一个单一的ip端口(默认1194),默认使用udp协议,同时也支持tcp。openvpn能通过大多数的代理服务器,并且能在NAT的环境很好的工作。openvpn服务端具有客户端“推送”某些网络配置信息的功能,这些信息包括,ip地址,路由设置等。 OPenvpn提供了2个虚拟网络接口:通过TUN/Tap驱动,通过他们,可以建立三层IP隧道,或者虚拟二层以太网,后者可以传送任何类型的二层以太网数据。传送的数据可通过LZO算法压缩。openvpn2.0以后版本每个进程可以同时管理数个并发的隧道。
5、openvpn协议选择
在选择协议的时候,需要注意2个加密隧道支架你的网络状况,如果高延迟或者丢包较多的情况下,请选择TCP协议作为底层协议,UDP协议由于存在无连接和重传机制,导致隧道上层的协议进行重传,效率非常低下,这里建议用tcp协议方式。
6、openvpn的依赖及核心技术
openvpn依赖Openssl,可以使用预设的私钥,第三方证书,用户名密码等进行身份验证。openvpn的技术核心是虚拟网卡,其次是SSL协议实现。
服务器端安装部署
相关软件:lzo压缩模块,可加快传输速度,openvpn 主程序。
安装环境:centos6.4 x64 下安装
1、安装lzo
# cd /usr/local/src/2、安装openvpn
# wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.03.tar.gz
# tar zxf lzo-2.06.tar.gz
# cd lzo-2.06
# ./configure
# make
# make install
# yum install -y openssl* -y && cd /usr/local/src/
# wget http://www.openvpn.net/release/openvpn-2.2.2.tar.gz
# tar zxf openvpn-2.2.2.tar.gz
# cd openvpn-2.2.2
# ./configure --with-lzo-headers=/usr/local/include --with-lzo-lib=/usr/local/lib
# make
# make install
安装环境:ubuntu 12.04 x64 下安装
1、主程序安装
# aptitude install openvpn2、检查安装
# aptitude install libpam-dev libpam-mysql libmysql++-dev sasl2-bin
# ls /usr/share/doc/|grep openvpn3、生成证书
openvpn ##发现已经存在。
#cd /usr/share/doc/openvpn/examples/easy-rsa/2.0/4、建立给server用的certificate & key
# . ./vars ##### 重成环境变量 以下生成的文件都在/usr/share/doc/openvpn/examples/easy-rsa/2.0/keys 下
# ./clean-all ###用来清除之前生成的所有的key
# ./build-ca ####生成ca.crt ca.key
#./build-key-server server5、建立给client用的certificate & key(可以建立多个client)
##“Common Name” 设成 “server”
##会产生以下文件
01.pem
server.crt
server.csr
server.key
## “Common Name” 设成 “clinet1” 以此类推6、建立 Diffie Hellman parameters 和 ta.key
# ./build-key client1
##生成
client1.crt
client1.csr
client1.key
# ./build-key client2
# ./build-key client3
##当然,你也可以只生成一个client,我就是这样做的
# ./build-dh #建立 Diffie Hellman parameters 会生成dh{n}.pem。
# openvpn --genkey --secret ta.key #生成ta.key,防止ddos攻击,client和server同时存储7、拷贝相关文件至/etc/openvpn下。# mv keys/* /etc/openvpn/8、建立配置文件/etc/openvpn/server.conf
# mv ta.key /etc/openvpn/ #不要遗漏
local 10.0.9.10 ###本机IP,这是一个内网IP,不过在路由上已经做了IP 的映射到一个外网ip9、开启操作系统的IP转发设置。
port 1194##指定端口
proto tcp #制定协议
dev tun
;tls-server
ca ca.crt
cert server.crt
key server.key
tls-auth ta.key 0
dh dh1024.pem
server 10.8.0.0 255.255.255.0#拨入后的ip段及网关
ifconfig-pool-persist ipp.txt
#push “redirect-gateway” # 自動將 client 的 default gateway 設成經由 VPN server 出去
keepalive 10 120 # 保持連線,每 10 秒 ping 一次,若是 120 秒未收到封包,即認定 client 斷線
comp-lzo #启用压缩
max-clients 20 # 最多同時只能有十個 client
user nobody
group nogroup # vpn daemon 執行時的身份(在非 Windows 平台中使用)
persist-key #当vpn超时后,当重新启动vpn后,保持上一次使用的私钥,而不重新读取私钥。
persist-tun #通过keepalive检测vpn超时后,当重新启动vpn后,保持tun或者tap设备自动链接状态。
status /etc/openvpn/easy-rsa/keys/openvpn-status.log #日志状态信息
log /var/log/openvpn.log #日志文件
verb 3 ## 日志文件冗余。
# 以下二行是將 vpn server 內部的虛擬 ip 機器開放給 client 使用
push "route 10.0.1.0 255.255.255.0"
push "route 10.0.2.0 255.255.255.0"
push "route 10.0.3.0 255.255.255.0"
plugin ./openvpn-auth-pam.so /usr/sbin/openvpn ###这个是用来mysql 认证的,如不需要可注释掉
# echo 1 > /proc/sys/net/ipv4/ip_forward10、建立mysql认证文件。
# iptables -t nat -A POSTROUTING -s 10.8.0.0/24 -o eth0 -j MASQUERADE
# vi /etc/pam.d/openvpn11、创建vpn库、授权、建表
auth sufficient pam_mysql.so user=vpn passwd=vpnjkb host=127.0.0.1:3306 db=vpn \
table=vpnuser usercolumn=name passwdcolumn=password \
where=active=1 sqllog=0 crypt=2 verbose=1
account required pam_mysql.so user=vpn passwd=vpnjkb host=127.0.0.1:3306 db=vpn \
table=vpnuser usercolumn=name passwdcolumn=password \
where=active=1 sqllog=0 crypt=2 verbose=1
mysql> create database vpn;##创建数据库vpn。12、拷贝文件
mysql> GRANT ALL ON vpn.* TO vpn@localhost IDENTIFIED BY ‘vpnjkb‘;##授权localhost上的用户vpn(密码vpn123)有对数据库vpn的所有操作权限。
mysql> flush privileges;##更新sql数据库的权限设置。
mysql> use vpn;##使用刚创建的的vpn数据库。
mysql> CREATE TABLE vpnuser (
-> name char(20) NOT NULL,
-> password char(128) default NULL,
-> active int(10) NOT NULL DEFAULT 1,
-> PRIMARY KEY (name)
-> );
mysql> insert into vpnuser (name,password) values(’soai’,password(’soai’));
##命令解释:
#创建vpn用户,对vpn这个database有所有操作权限,密码为vpn123
#active不为1,无权使用VPN
# cp /usr/lib/openvpn/openvpn-auth-pam.so /etc/openvpn/13、可选配置
#client-cert-not-required #不请求客户的CA证书,使用User/Pass验证14、下载相关文件给客户端用
#username-as-common-name #使用客户提供的UserName作为Common Name
#client-to-client #如果让Client之间可以相互看见,去掉本行的注释掉,否则Client之间无法相互访问
#duplicate-cn #是否允许一个User同时登录多次,去掉本行注释后可以使用同一个用户名登录多次
##下载下列文件
client.crt clinet.key ca.crt ta.key
客户端配置
1、客户端下载地址:
http://swupdate.openvpn.org/community/releases/openvpn-2.2.2-install.exe ##windows
http://swupdate.openvpn.org/community/releases/openvpn-2.2.2.tar.gz ##linux or mac
2、创建client.ovpn文件
client3、把client.ovpn加上之前client.crt clinet.key ca.crt ta.key 放入一个config文件夹,并移动至vpn安装的主目录
dev tun
proto tcp
remote 8.8.8.8 1194 #公网ip 和 端口
nobind
persist-key
persist-tun
ca ca.crt
cert client.crt
key client.key
tls-auth ta.key 1
;comp-lzo
verb 3
auth-user-pass
4、启动客户端,输入用户名密码即可。#用户名密码在服务器端,mysql中添加的用户密码。
其他
1、关于auto认证相关可参考:http://b.gkp.cc/2010/08/08/setup-openvpn-with-mysql-auth/
2、后期维护
a、如果后期重新添加key的话
source varsb、后期客户端的吊销
./build-key
source vars检查keys/index.txt,发现被吊销的用户前面有个R
./revoke-full xiaowang #-->会生成crl.pem文件
怎么使吊销的生效呢,就是在server.conf里面加上 #crl-verify /etc/openvpn/keys/crl.pem,然后重启openvpn服务生效。
关于Linux平台下/tmp下文件被清理探索
运维 being 发表了文章 0 个评论 7172 次浏览 2016-07-22 09:31
2016-07-21 14:25:59,580 INFO [main] zookeeper.ZooKeeper: Client environment:user.dir=/home/chris/hbase-0.98.7-hadoop2/bin从日记中很容易看出来,no pid file /tmp/hbase-root-regionserver.pid没有这个pid文件(默认如果不在hbase-env.sh文件中指定pid文件存放目录的话,默认是在/tmp下):
2016-07-21 14:25:59,581 INFO [main] zookeeper.ZooKeeper: Initiating client connection, connectString=10.0.41.94:2181,10.0.55.56:2181,10.0.59.225:2181 sessionTimeout=90000 watcher=hconnection-0x661261ba, quorum=10.0.41.94:2181,10.0.55.56:2181,10.0.59.225:2181, baseZNode=/hbase
2016-07-21 14:25:59,603 INFO [main-SendThread(10.0.59.225:2181)] zookeeper.ClientCnxn: Opening socket connection to server 10.0.59.225/10.0.59.225:2181. Will not attempt to authenticate using SASL (unknown error)
2016-07-21 14:25:59,610 INFO [main-SendThread(10.0.59.225:2181)] zookeeper.ClientCnxn: Socket connection established to 10.0.59.225/10.0.59.225:2181, initiating session
2016-07-21 14:25:59,617 INFO [main-SendThread(10.0.59.225:2181)] zookeeper.ClientCnxn: Session establishment complete on server 10.0.59.225/10.0.59.225:2181, sessionid = 0x3500747e7e6841d, negotiated timeout = 40000
RuntimeError: Server bighad1:60020 not online
stripServer at /home/chris/hbase-0.98.7-hadoop2/bin/region_mover.rb:225
unloadRegions at /home/chris/hbase-0.98.7-hadoop2/bin/region_mover.rb:336
(root) at /home/chris/hbase-0.98.7-hadoop2/bin/region_mover.rb:515
2016-07-21T06:26:00 Unloaded bighad1 region(s)
2016-07-21T06:26:00 Stopping regionserver
no regionserver to stop because no pid file /tmp/hbase-root-regionserver.pid
2016-07-21T06:26:00 Restoring balancer state to
# The directory where pid files are stored. /tmp by default.现在问题很显而易见,就是hbase reregionserver node的pid文件被删除了。那为什么会被删除呢?下面给大家介绍一下/tmp目录,以及在Linux下的清理机制。
# export HBASE_PID_DIR=/var/hadoop/pids
这是hbase-env.sh默认的设置。
Linux下/tmp目录,通常被大家叫做临时目录,而且文件夹里面的文件会被清空,那系统默认多长时间清空的,是怎么清空的呢,下面给大家介绍一下,也记录一下我的这次学习过程。
在Centos/RHEL/Fedora系统下存在清理机制(Ubuntu下没有,我的系统是Centos6.5)
有时候开发习惯性的将一些临时文件放在tmp目录下,让其自然删除。同时,为了保证tmp目录不爆满,系统默认情况下每日会处理一次tmp目录文件,原理就是使用了tmpwatch。然后可能好多开源的应用程序如Mysql、HDFS、HBSE的开发者,也有这种习惯。其实如果开发者对系统有这种机制概念的话,我想他不会把一些PID文件目录默认设置到/tmp下面,然后很多开源的软件程序都是由国外的开发者发起的,并且Ubuntu系统在国外深受开发者喜欢,所以可能这个问题在他们那就ok了。如果你是在Centos下最小化安装的,默认是没有tmpwatch命令的。
安装:
yum install tmpwatch
tmpwatch命令,他的作用就是删除一段时间内不使用的文件(removes files which haven’t been accessed for a period of time)。
安装后会在/etc/cron.daily/目录下生成一个tmpwatch文件。内容如下:
#! /bin/sh从脚本中可看出,tmp目录会删除10天未访问过的文件。
flags=-umc
/usr/sbin/tmpwatch "$flags" -x /tmp/.X11-unix -x /tmp/.XIM-unix \
-x /tmp/.font-unix -x /tmp/.ICE-unix -x /tmp/.Test-unix \
-X '/tmp/hsperfdata_*' 10d /tmp
/usr/sbin/tmpwatch "$flags" 30d /var/tmp
for d in /var/{cache/man,catman}/{cat?,X11R6/cat?,local/cat?}; do
if [ -d "$d" ]; then
/usr/sbin/tmpwatch "$flags" -f 30d "$d"
fi
done
我们看看/usr/sbin/tmpwatch "$flags" 30d /var/tmp这一行,关键的是这个30d,就是30天的意思,这个就决定了30天清理/var/tmp下不访问的文件。如果说,你想一天一清理的话,就把这个30d改成1d。可以DIY!
但有个问题需要注意,如果你设置更短的时间来清理的话,比如说是30分钟、10秒等等,你可以在这个文件中设置,但你会发现重新电脑,他不清理/tmp文件夹里面的内容,这是为什么呢?这就是tmpwatch他所在的位置决定的,他的上层目录是/etc/cron.daily/,而这个目录是第天执行一次计划任务,所以说,你设置了比一天更短的时间,他就不起作用了。
所以结论是:在Centos6中,系统自动清理/tmp文件夹的默认时限是30天,其他系统待考证!
在Debian\Ubuntu系统中(Ubuntu 12.04.2 LTS 为实验环境)
上面我说到在Ubuntu下没有tmpwatch清理机制,但是在Ubuntu系统中,在/tmp文件夹里面的内容,每次开机都会被清空,如果不想让他自动清理的话,只需要更改rcS文件中的TMPTIME的值。
修改:
# sudo vi /etc/default/rcS把 TMPTIME=0修改成 TMPTIME=-1或者是无限大,改成这样的话,系统在重新启动的时候就不会清理你的/tmp目录了。 依些类推,如果说要限制多少时间来更改的话,就可以改成相应的数字(本人没有测试,我是这么理解的)
TMPTIME=0
#change set -1
TMPTIME=-1或者是无限大
所以结论是:在Ubuntu中,系统自动清理/tmp文件夹的时限默认每次启动
tmpwatch工具介绍
tmpwatch工具从指定的目录中递归地搜索并删除指定的目录中一段时间未访问的文件。
tmpwatch参数说明:
-u, --atime 基于访问时间来删除文件,默认的。对于Mysql、HDFS、HBASE等应用,如果将pid和socket文件创建在tmp目录下,要将这两个文件排除在外,否则mysql重启或使用socket文件登录时,提示找不到文件。
-m, --mtime 基于修改时间来删除文件。
-c, --ctime 基于创建时间来删除文件,对于目录,基于mtime。
-M, --dirmtime 删除目录基于目录的修改时间而不是访问时间。
-a, --all 删除所有的文件类型,不只是普通文件,符号链接和目录。
-d, --nodirs 不尝试删除目录,即使是空目录。
-d, --nosymlinks 不尝试删除符号链接。
-f, --force 强制删除。
-q, --quiet 只报告错误信息。
-s, --fuser 如果文件已经是打开状态在删除前,尝试使用“定影”命令。默认不启用。
-t, --test 仅作测试,并不真的删除文件或目录。
-U, --exclude-user=user 不删除属于谁的文件。
-v, --verbose 打印详细信息。
-x, --exclude=path 排除路径,如果路径是一个目录,它包含的所有文件被排除了。如果路径不存在,它必须是一个绝对路径不包含符号链接。
-X, --exclude-pattern=pattern 排除某规则下的路径。
常用Linux系统Debug命令
运维 Geek小A 发表了文章 0 个评论 3238 次浏览 2016-07-09 13:06
netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
netstat -n | awk '/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}'
netstat -n | awk '/^tcp/ {++state[$NF]}; END {for(key in state) print key,"\t",state[key]}'
netstat -n | awk '/^tcp/ {++arr[$NF]};END {for(k in arr) print k,"\t",arr[k]}'
netstat -n |awk '/^tcp/ {print $NF}'|sort|uniq -c|sort -rn
netstat -ant | awk '{print $NF}' | grep -v '[a-z]' | sort | uniq -cnetstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
netstat -n | awk '/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}'
netstat -n | awk '/^tcp/ {++state[$NF]}; END {for(key in state) print key,"\t",state[key]}'
netstat -n | awk '/^tcp/ {++arr[$NF]};END {for(k in arr) print k,"\t",arr[k]}'
netstat -n |awk '/^tcp/ {print $NF}'|sort|uniq -c|sort -rn
netstat -ant | awk '{print $NF}' | grep -v '[a-z]' | sort | uniq -c 2、查找请求80端口最多的20个IP连接
netstat -anlp|grep 80|grep tcp|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -n20
netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A,i}' |sort -rn|head -n20tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1"."$2"."$3"."$4}' | sort | uniq -c | sort -nr |head -n 203、查找较多time_wait连接
netstat -n|grep TIME_WAIT|awk '{print $5}'|sort|uniq -c|sort -rn|head -n204、找查较多的SYN连接
netstat -an | grep SYN | awk '{print $5}' | awk -F: '{print $1}' | sort | uniq -c | sort -nr | more5、根据端口列进程
netstat -ntlp | grep 80 | awk '{print $7}' | cut -d/ -f16、获取Web访问前10位的ip地址
cat access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -n 10
cat access.log|awk '{counts[$(11)]+=1}; END {for(url in counts) print counts[url], url}'7、访问次数最多的文件或页面,取前20
cat access.log|awk '{print $11}'|sort|uniq -c|sort -nr|head -n 208、列出传输最大的几个rar文件
cat access.log|awk '{print $11}'|sort|uniq -c|sort -nr|head -n 209、列出输出大于200000byte(约200kb)的rar文件以及对应文件发生次数
cat access.log |awk '($10 > 200000 && $7~/\.rar/){print $7}'|sort -n|uniq -c|sort -nr|head -n 10010、如果日志最后一列记录的是页面文件传输时间,则有列出到客户端最耗时的页面
cat access.log |awk '($7~/\.php/){print $NF " " $1 " " $4 " " $7}'|sort -nr|head -n 100
cat access.log |awk '($7~/\.php/){print $NF " " $1 " " $4 " " $7}'|sort -nr|head -n 100
11、列出最最耗时的页面(超过60秒的)的以及对应页面发生次数
cat access.log |awk '($NF > 60 && $7~/\.php/){print $7}'|sort -n|uniq -c|sort -nr|head -n 10012、列出传输时间超过 30 秒的文件
cat access.log |awk '($NF > 30){print $7}'|sort -n|uniq -c|sort -nr|head -n 2013、统计网站流量(G)
cat access.log |awk '{sum+=$10} END {print sum/1024/1024/1024}'14、统计404的连接
awk '($9 ~/404/)' access.log | awk '{print $9,$7}' | sort15、统计http status
cat access.log |awk '{counts[$(9)]+=1}; END {for(code in counts) print code, counts[code]}'
cat access.log |awk '{print $9}'|sort|uniq -c|sort -rn16、查看是哪些爬虫在抓取内容
tcpdump -i eth0 -l -s 0 -w - dst port 80 | strings | grep -i user-agent | grep -i -E 'bot|crawler|slurp|spider'
17、查看数据库执行的sql语句
tcpdump -i eth0 -s 0 -l -w - dst port 3306 | strings | egrep -i 'SELECT|UPDATE|DELETE|INSERT|SET|COMMIT|ROLLBACK|CREATE|DROP|ALTER|CALL'
18、按域统计流量
zcat squid_access.log.tar.gz| awk '{print $10,$7}' |awk 'BEGIN{FS="[ /]"}{trfc[$4]+=$1}END{for(domain in trfc){printf "%s\t%d\n",domain,trfc[domain]}}'19、调试命令
strace -p pid
20、磁盘性能
iostat -x 1 10
Linux下iptables允许指定IP访问某应用端口
运维 being 发表了文章 0 个评论 11371 次浏览 2016-07-03 22:15
开启网段10.0.0.0/8可以访问80端口,和允许公网IP123.125.65.82可以访问80端口
# iptables -I INPUT -p tcp --dport 80 -j DROP以上示例的意思是我先把所有请求80端口的tcp链接都drop掉,然后在插入你想针对开放访问的网段和IP地址。
# iptables -I INPUT -s 10.0.0.0/8 -p tcp --dport 80 -j ACCEPT
# iptables -I INPUT -s 123.125.65.82 -p tcp --dport 80 -j ACCEPT
如果开启NAT转发的话,如下设置:
iptables -I FORWARD -p tcp --dport 80 -j DROP
iptables -I FORWARD -s 10.0.0.0/8 -p tcp --dport 80 -j ACCEPT
下面我再介绍一些常用的iptables规则
1、邮件系统设置,只能收发邮件,其他的都DROP。
iptables -I Filter -m mac --mac-source 00:0F:wc:35:31:57 -j DROP通过MAC地址控制。
iptables -I Filter -m mac --mac-source 00:0F:wc:35:31:57 -p udp --dport 53 -j ACCEPT
iptables -I Filter -m mac --mac-source 00:0F:wc:35:31:57 -p tcp --dport 25 -j ACCEPT
iptables -I Filter -m mac --mac-source 00:0F:wc:35:31:57 -p tcp --dport 110 -j ACCEPT
IPSEC NAT 策略
iptables -I PFWanPriv -d 192.168.100.2 -j ACCEPT
iptables -t nat -A PREROUTING -p tcp --dport 80 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.2:80
iptables -t nat -A PREROUTING -p tcp --dport 1723 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.2:1723
iptables -t nat -A PREROUTING -p udp --dport 1723 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.2:1723
iptables -t nat -A PREROUTING -p udp --dport 500 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.2:500
iptables -t nat -A PREROUTING -p udp --dport 4500 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.2:4500
FTP服务器的NAT
iptables -I PFWanPriv -p tcp --dport 21 -d 192.168.100.200 -j ACCEPT
iptables -t nat -A PREROUTING -p tcp --dport 21 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.200:21
只允许访问指定网址
iptables -A Filter -p udp --dport 53 -j ACCEPT
iptables -A Filter -p tcp --dport 53 -j ACCEPT
iptables -A Filter -d www.3322.org -j ACCEPT
iptables -A Filter -d img.cn99.com -j ACCEPT
iptables -A Filter -j DROP
开放一个IP的一些端口,其它都封闭
iptables -A Filter -p tcp --dport 80 -s 192.168.100.200 -d www.pconline.com.cn -j ACCEPT
iptables -A Filter -p tcp --dport 25 -s 192.168.100.200 -j ACCEPT
iptables -A Filter -p tcp --dport 109 -s 192.168.100.200 -j ACCEPT
iptables -A Filter -p tcp --dport 110 -s 192.168.100.200 -j ACCEPT
iptables -A Filter -p tcp --dport 53 -j ACCEPT
iptables -A Filter -p udp --dport 53 -j ACCEPT
iptables -A Filter -j DROP
多个端口
iptables -A Filter -p tcp -m multiport --destination-port 22,53,80,110 -s 192.168.20.3 -j REJECT
连续端口
iptables -A Filter -p tcp -m multiport --source-port 22,53,80,110 -s 192.168.20.3 -j REJECT iptables -A Filter -p tcp --source-port 2:80 -s 192.168.20.3 -j REJECT
指定时间上网
iptables -A Filter -s 10.10.10.253 -m time --timestart 6:00 --timestop 11:00 --days Mon,Tue,Wed,Thu,Fri,Sat,Sun -j DROP
iptables -A Filter -m time --timestart 12:00 --timestop 13:00 --days Mon,Tue,Wed,Thu,Fri,Sat,Sun -j ACCEPT
iptables -A Filter -m time --timestart 17:30 --timestop 8:30 --days Mon,Tue,Wed,Thu,Fri,Sat,Sun -j ACCEPT
禁止多个端口服务
iptables -A Filter -m multiport -p tcp --dport 21,23,80 -j ACCEPT
将WAN 口NAT到PC
iptables -t nat -A PREROUTING -i $INTERNET_IF -d $INTERNET_ADDR -j DNAT --to-destination 192.168.0.1
将WAN口8000端口NAT到192.168.100.200的80端口
iptables -t nat -A PREROUTING -p tcp --dport 8000 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.200:80
MAIL服务器要转的端口
iptables -t nat -A PREROUTING -p tcp --dport 110 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.200:110
iptables -t nat -A PREROUTING -p tcp --dport 25 -d $INTERNET_ADDR -j DNAT --to-destination 192.168.100.200:25
基于MAC,只能收发邮件,其它都拒绝
iptables -I Filter -m mac --mac-source 00:0A:EB:97:79:A1 -j DROP
iptables -I Filter -m mac --mac-source 00:0A:EB:97:79:A1 -p tcp --dport 25 -j ACCEPT
iptables -I Filter -m mac --mac-source 00:0A:EB:97:79:A1 -p tcp --dport 110 -j ACCEPT
只允许PING 202.96.134.133 其它公网IP都不许PING
iptables -A Filter -p icmp -s 192.168.100.200 -d 202.96.134.133 -j ACCEPT
iptables -A Filter -p icmp -j DROP
禁止某个MAC地址访问internet:
iptables -I Filter -m mac --mac-source 00:20:18:8F:72:F8 -j DROP参考:http://cnzhx.net/blog/common-iptables-cli/#11
Centos下NTP时间服务器配置详解
运维 Rock 发表了文章 0 个评论 5019 次浏览 2016-03-27 03:10
NTP简介
NTP(Network Time Protocol,网络时间协议)是用来使网络中的各个计算机时间同步的一种协议。它的用途是把计算机的时钟同步到世界协调时UTC,其精度在局域网内可达0.1ms,在互联网上绝大多数的地方其精度可以达到1-50ms。
NTP服务器就是利用NTP协议提供时间同步服务的。
NTP服务器安装
# 系统自带ntp软件包
[root@node ~]# rpm -qa ntp
ntp-4.2.6p5-5.el6.centos.x86_64
# 如果没有就安装
[root@node ~]# yum -y install ntp
配置NTP服务
[root@node ~]# vim /etc/ntp.conf
# restrict default kod nomodify notrap nopeer noquery
restrict default nomodify
# nomodify客户端可以同步
# 将默认时间同步源注释改用可用源
# server 0.centos.pool.ntp.org iburst
# server 1.centos.pool.ntp.org iburst
# server 2.centos.pool.ntp.org iburst
# server 3.centos.pool.ntp.org iburst
server ntp1.aliyun.com #阿里时间服务器
server s2m.time.edu.cn #北京教育网时间服务器
启动NTP服务器
# 如果计划任务有时间同步,先注释,两种用法会冲突。
[root@node ~]# crontab -e
# time sync cron
#[i]/3 [/i] [i] [/i] * /usr/sbin/ntpdate ntp1.aliyun.com >/dev/null 2>&1
[root@node ~]# /etc/init.d/ntpd start
Starting ntpd: [ OK ]
[root@node ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*ntp1.aliyun.com 10.137.38.86 2 u 22 64 1 525.885 -42.367 0.000
[root@node ~]# ntpstat
synchronised to NTP server (110.75.186.247) at stratum 3
time correct to within 4257 ms
polling server every 64 s
客户机时间同步
客户机要等几分钟再与新启动的ntp服务器进行时间同步,否则会提示no server suitable for synchronization found错误。
[root@node ~]# ntpdate 10.0.1.110 (ntp_server_ip)
27 Mar 18:40:16 ntpdate[1453]: step time server 10.0.1.110 offset 40.880807 sec
# 将命令放入计划任务即可。

