
通知设置 新通知
Kafka日志设置和清除策略
push 发表了文章 0 个评论 19506 次浏览 2017-04-15 16:00

一、日志设置
1、修改日志级别
config/log4j.properties中日志的级别设置的是TRACE,在长时间运行过程中产生的日志大小吓人,所以如果没有特殊需求,强烈建议将其更改成INFO级别。具体修改方法如下所示,将config/log4j.properties文件中最后的几行中的TRACE改成INFO,修改前如下所示:
log4j.logger.kafka.network.RequestChannel$=TRACE, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=TRACE, requestAppender
#log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=TRACE, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=TRACE, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.state.change.logger=TRACE, stateChangeAppender
log4j.additivity.state.change.logger=false
修改后如下所示:
log4j.logger.kafka.network.RequestChannel$=INFO, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=INFO, requestAppender
#log4j.logger.kafka.server.KafkaApis=INFO, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=INFO, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=INFO, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.state.change.logger=INFO, stateChangeAppender
log4j.additivity.state.change.logger=false
2、修改日志存放位置
还有就是默认Kafka运行的时候都会通过log4j打印很多日志文件,比如server.log, controller.log, state-change.log等,而都会将其输出到$KAFKA_HOME/logs目录下,这样很不利于线上运维,因为经常容易出现打爆文件系统,一般安装的盘都比较小,而数据和日志会指定打到另一个或多个更大空间的分区盘
具体方法是,打开$KAFKA_HOME/bin/kafka-run-class.sh,找到下面标示的位置,并定义一个变量,指定的值为系统日志输出路径,重启broker即可生效。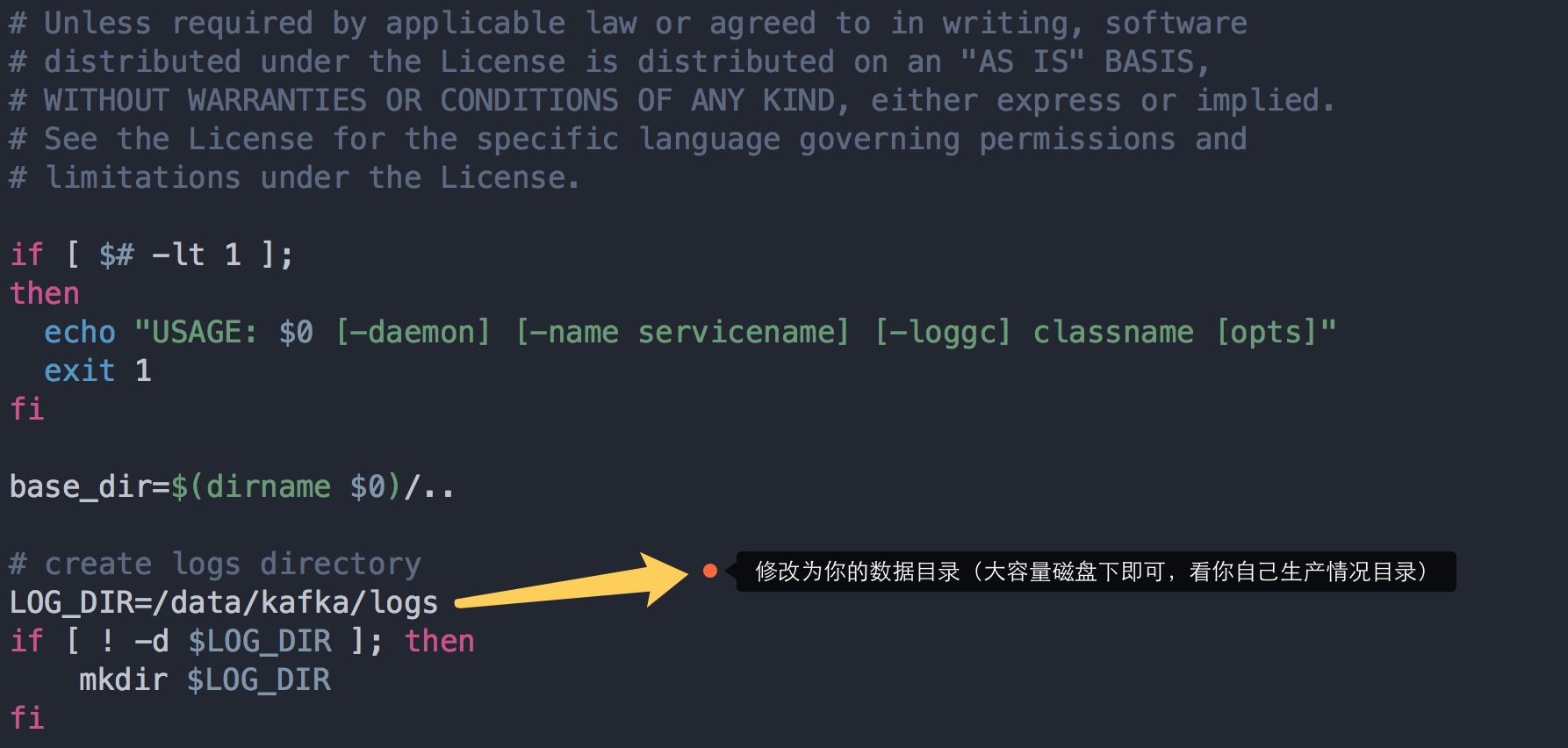
二、日志清理和策略
1、利用Kafka日志管理器
Kafka日志管理器允许定制删除策略。目前的策略是删除修改时间在N天之前的日志(按时间删除),也可以使用另外一个策略:保留最后的N GB数据的策略(按大小删除)。为了避免在删除时阻塞读操作,采用了copy-on-write形式的实现,删除操作进行时,读取操作的二分查找功能实际是在一个静态的快照副本上进行的,这类似于Java的CopyOnWriteArrayList。
Kafka消费日志删除思想:Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用
log.cleanup.policy=delete启用删除策略
直接删除,删除后的消息不可恢复。可配置以下两个策略:
清理超过指定时间清理:
log.retention.hours=16
超过指定大小后,删除旧的消息:
log.retention.bytes=1073741824
2、压缩策略
将数据压缩,只保留每个key最后一个版本的数据。首先在broker的配置中设置log.cleaner.enable=true启用cleaner,这个默认是关闭的。在Topic的配置中设置log.cleanup.policy=compact启用压缩策略。
压缩策略的细节如下:
如上图,在整个数据流中,每个Key都有可能出现多次,压缩时将根据Key将消息聚合,只保留最后一次出现时的数据。这样,无论什么时候消费消息,都能拿到每个Key的最新版本的数据。
压缩后的offset可能是不连续的,比如上图中没有5和7,因为这些offset的消息被merge了,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,比如,当试图获取offset为5的消息时,实际上会拿到offset为6的消息,并从这个位置开始消费。
这种策略只适合特俗场景,比如消息的key是用户ID,消息体是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
压缩策略支持删除,当某个Key的最新版本的消息没有内容时,这个Key将被删除,这也符合以上逻辑。
云安全事故频发,如何应对
OT学习平台 发表了文章 0 个评论 2398 次浏览 2017-04-14 14:44
谁有访问权限?
访问控制确实是一个问题。云身份认证是如何管理的?内部人员攻击是一种持续威胁。任何获得云平台访问权限的人都有可能成为潜在的问题。举一个例子:有一名员工可能离职或被辞退,结果他或她是唯一有访问密码的人。或者说,或许这一名员工是唯一一位负责给云提供商支付费用的人。你必须知道谁有访问权限,他或她是如何交接工作的,以及访问权限是如何中止的?
你是否有审计权限?
这个问题并不是小问题,相反是其中一个最重要的云安全问题。云提供商可能同意在书面上遵守一个审计标准;但是,对于审计人员和评估人员而言,想要评估云计算是否符合法规要求,已经被证明是一件越来越难完成和验证的工作。在IT要面对的诸多法规中,几乎没有专门针对云计算的。审计人员和评估人员可能还不熟悉云计算,也不熟悉某个特定的云服务。
云提供商给员工提供了哪一些培训?
这确实是一个非常值得注意的问题,因为人们在安全面前总是弱势群体。了解云服务商提供了哪些培训。大多数攻击都同时包含技术因素和社会因素。云服务商应该采用措施处理各种来源的社会攻击,包括电子邮件、恶意链接、电话及其他方式,它们都应该在出现在培训和认知项目中。
是否使用了加密手段?
加密手段也应该在考虑范围内。原始数据是否允许离开企业,或者它们应该留在内部,才能符合法规要求?数据在静止和或移动过程中,是否加密?此外,你还应该了解其中所使用的加密类型。要保证自己知道是谁在保管密钥,然后再签合约。加密手段一定要出现在云安全问题清单中。
你的数据与其他人的数据是如何分隔的?
数据位于一台共享服务器还是一个专用系统中?如果使用一个专用服务器,则意味着服务器上只有你的信息。如果在一台共享服务器上,则磁盘空间、处理能力、带宽等资源都是有限的,因为还有其他人一起共享这个设备。你需要确定自己是需要私有云还是公有云,以及谁在管理服务器。如果是共享服务器,那么数据就有可能和其他数据混在一起。
提供商的长期可用性体现有什么保障?
云服务商开展这个业务有多长时间了?过往的业务表现如何?如果它在这个业务上出现问题,你的数据会面临什么问题?是否会以原始格式交回给你?
如果出现安全漏洞会有什么应对措施?
如果发生了安全事故,你可以从云服务商获得哪些支持?虽然许多提供商都宣称自己的服务是万无一失的,但是基于云的服务是极其容易受到黑客攻击的。侧向通道、会话劫持、跨站脚本和分布式拒绝服务等攻击都是云数据经常遇到的攻击方式。
根据预测,未来三年有80%以上的数据中心流量将来自云服务。这意味着,即使你现在还没有做好云迁移,那么到2020年前你也会这样做的。所以,要用这一段时间保证自己采用正确的迁移方法。要提前定义合同要求,然后不能只是复制原来用于本地环境的安全策略。相反,要从迁移的角度去改进它。
OTPUB直播活动又双叒叕来喽!
直播主题
Excel的“天上人间”-“出台”到PPT的动态图表
直播时间
2017年4月25日 14:00-15:00
点击参与报名>>>
Hadoop环境中管理大数据存储技巧
OT学习平台 发表了文章 0 个评论 2551 次浏览 2017-04-12 15:03
目前大数据行业也越来越火爆,从而导致国内大数据人才也极度缺乏,下面介绍一下关于Hadoop环境中管理大数据存储技巧。
在现如今,随着IT互联网信息技术的飞速发展和进步。目前大数据行业也越来越火爆,从而导致国内大数据人才也极度缺乏,下面介绍一下关于Hadoop环境中管理大数据存储技巧。
1、分布式存储
传统化集中式存储存在已有一段时间。但大数据并非真的适合集中式存储架构。Hadoop设计用于将计算更接近数据节点,同时采用了HDFS文件系统的大规模横向扩展功能。
虽然,通常解决Hadoop管理自身数据低效性的方案是将Hadoop数据存储在SAN上。但这也造成了它自身性能与规模的瓶颈。现在,如果你把所有的数据都通过集中式SAN处理器进行处理,与Hadoop的分布式和并行化特性相悖。你要么针对不同的数据节点管理多个SAN,要么将所有的数据节点都集中到一个SAN。
但Hadoop是一个分布式应用,就应该运行在分布式存储上,这样存储就保留了与Hadoop本身同样的灵活性,不过它也要求拥抱一个软件定义存储方案,并在商用服务器上运行,这相比瓶颈化的Hadoop自然更为高效。
2、超融合VS分布式
注意,不要混淆超融合与分布式。某些超融合方案是分布式存储,但通常这个术语意味着你的应用和存储都保存在同一计算节点上。这是在试图解决数据本地化的问题,但它会造成太多资源争用。这个Hadoop应用和存储平台会争用相同的内存和CPU。Hadoop运行在专有应用层,分布式存储运行在专有存储层这样会更好。之后,利用缓存和分层来解决数据本地化并补偿网络性能损失。
3、避免控制器瓶颈(ControllerChokePoint)
实现目标的一个重要方面就是——避免通过单个点例如一个传统控制器来处理数据。反之,要确保存储平台并行化,性能可以得到显著提升。
此外,这个方案提供了增量扩展性。为数据湖添加功能跟往里面扔x86服务器一样简单。一个分布式存储平台如有需要将自动添加功能并重新调整数据。
4、删重和压缩
掌握大数据的关键是删重和压缩技术。通常大数据集内会有70%到90%的数据简化。以PB容量计,能节约数万美元的磁盘成本。现代平台提供内联(对比后期处理)删重和压缩,大大降低了存储数据所需能力。
5、合并Hadoop发行版
很多大型企业拥有多个Hadoop发行版本。可能是开发者需要或是企业部门已经适应了不同版本。无论如何最终往往要对这些集群的维护与运营。一旦海量数据真正开始影响一家企业时,多个Hadoop发行版存储就会导致低效性。我们可以通过创建一个单一,可删重和压缩的数据湖获取数据效率
6、虚拟化Hadoop
虚拟化已经席卷企业级市场。很多地区超过80%的物理服务器现在是虚拟化的。但也仍有很多企业因为性能和数据本地化问题对虚拟化Hadoop避而不谈。
7、创建弹性数据湖
创建数据湖并不容易,但大数据存储可能会有需求。我们有很多种方法来做这件事,但哪一种是正确的?这个正确的架构应该是一个动态,弹性的数据湖,可以以多种格式(架构化,非结构化,半结构化)存储所有资源的数据。更重要的是,它必须支持应用不在远程资源上而是在本地数据资源上执行。
不幸的是,传统架构和应用(也就是非分布式)并不尽如人意。随着数据集越来越大,将应用迁移到数据不可避免,而因为延迟太长也无法倒置。
理想的数据湖基础架构会实现数据单一副本的存储,而且有应用在单一数据资源上执行,无需迁移数据或制作副本。
8、整合分析
分析并不是一个新功能,它已经在传统RDBMS环境中存在多年。不同的是基于开源应用的出现,以及数据库表单和社交媒体,非结构化数据资源(比如,维基百科)的整合能力。关键在于将多个数据类型和格式整合成一个标准的能力,有利于更轻松和一致地实现可视化与报告制作。合适的工具也对分析/商业智能项目的成功至关重要。
OTPUB直播活动又双叒叕来喽!
直播主题
甲骨文第2代企业级IaaS云技术大会
直播时间
2017年4月13日 9:30-17:30
点击参与报名>>>
或者直接进入OTPUB官网
http://www.otpub.com/
Zookeeper日志设置和清理
push 发表了文章 0 个评论 10230 次浏览 2017-04-11 15:38
一、日志设置
第一步:修改log4j.properties, 这个应该是大家都会去改改, 加粗处是我修改的, 但是只改这个文件后来发现还是不生效
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO,ROLLINGFILE
zookeeper.console.threshold=INFO
zookeeper.log.dir=.
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=.
zookeeper.tracelog.file=zookeeper_trace.log
#
# ZooKeeper Logging Configuration
#
# Format is "(, )+
# DEFAULT: console appender only
log4j.rootLogger=${zookeeper.root.logger}
# Example with rolling log file
#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE
# Example with rolling log file and tracing
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
#
# Log INFO level and above messages to the console
#
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender //按天日记轮转
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
# Max log file size of 10MB
#log4j.appender.ROLLINGFILE.MaxFileSize=10MB
# uncomment the next line to limit number of backup files
#log4j.appender.ROLLINGFILE.MaxBackupIndex=10
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add TRACEFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
log4j.appender.TRACEFILE.Threshold=TRACE
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
### Notice we are including log4j's NDC here (%x)
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
第二步:还需要改${zkhome}/bin/zkEnv.sh, 注意加粗处, 这时日志已经可以成功按照你设置的目录进行输出了
#!/usr/bin/env bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script should be sourced into other zookeeper
# scripts to setup the env variables
# We use ZOOCFGDIR if defined,
# otherwise we use /etc/zookeeper
# or the conf directory that is
# a sibling of this script's directory
ZOOBINDIR="${ZOOBINDIR:-/usr/bin}"
ZOOKEEPER_PREFIX="${ZOOBINDIR}/.."
if [ "x$ZOOCFGDIR" = "x" ]
then
if [ -e "${ZOOKEEPER_PREFIX}/conf" ]; then
ZOOCFGDIR="$ZOOBINDIR/../conf"
else
ZOOCFGDIR="$ZOOBINDIR/../etc/zookeeper"
fi
fi
if [ -f "${ZOOCFGDIR}/zookeeper-env.sh" ]; then
. "${ZOOCFGDIR}/zookeeper-env.sh"
fi
if [ "x$ZOOCFG" = "x" ]
then
ZOOCFG="zoo.cfg"
fi
ZOOCFG="$ZOOCFGDIR/$ZOOCFG"
if [ -f "$ZOOCFGDIR/java.env" ]
then
. "$ZOOCFGDIR/java.env"
fi
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/data/zookeeper/outlogs/"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
if [ "$JAVA_HOME" != "" ]; then
JAVA="$JAVA_HOME/bin/java"
else
JAVA=java
fi
#add the zoocfg dir to classpath
CLASSPATH="$ZOOCFGDIR:$CLASSPATH"
for i in "$ZOOBINDIR"/../src/java/lib/*.jar
do
CLASSPATH="$i:$CLASSPATH"
done
#make it work in the binary package
#(use array for LIBPATH to account for spaces within wildcard expansion)
if [ -e "${ZOOKEEPER_PREFIX}"/share/zookeeper/zookeeper-*.jar ]; then
LIBPATH=("${ZOOKEEPER_PREFIX}"/share/zookeeper/*.jar)
else
#release tarball format
for i in "$ZOOBINDIR"/../zookeeper-*.jar
do
CLASSPATH="$i:$CLASSPATH"
done
LIBPATH=("${ZOOBINDIR}"/../lib/*.jar)
fi
for i in "${LIBPATH[@]}"
do
CLASSPATH="$i:$CLASSPATH"
done
#make it work for developers
for d in "$ZOOBINDIR"/../build/lib/*.jar
do
CLASSPATH="$d:$CLASSPATH"
done
#make it work for developers
CLASSPATH="$ZOOBINDIR/../build/classes:$CLASSPATH"
case "`uname`" in
CYGWIN*) cygwin=true ;;
*) cygwin=false ;;
esac
if $cygwin
then
CLASSPATH=`cygpath -wp "$CLASSPATH"`
fi
#echo "CLASSPATH=$CLASSPATH"
第三步:设置zookeeper.out
zookeeper.out由nohup的输出,也就是zookeeper的stdout和stdeer输出,修改bin/zkServer.sh 文件:
_ZOO_DAEMON_OUT="$ZOO_LOG_DIR/zookeeper.out"
case $1 in
start)
echo -n "Starting zookeeper ... "
if [ -f $ZOOPIDFILE ]; then
if kill -0 `cat $ZOOPIDFILE` > /dev/null 2>&1; then
echo $command already running as process `cat $ZOOPIDFILE`.
exit 0
fi
fi
nohup $JAVA "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
第四步:快照事物日志
在使用zookeeper过程中,我们知道,会有dataDir和dataLogDir两个目录,分别用于snapshot和事务日志的输出(默认情况下只有dataDir目录,snapshot和事务日志都保存在这个目录中),通过zoo.cfg配置文件可配置:
#snapshot file dir
dataDir=/data/zookeeper/data
#tran log dir
dataLogDir=/data/zookeeper/log
二、日志清理
正常运行过程中,ZK会不断地把快照数据和事务日志输出到这两个目录,并且如果没有人为操作的话,ZK自己是不会清理这些文件的,需要管理员来清理,这里介绍4种清理日志的方法。在这4种方法中,推荐使用第一种方法,对于运维人员来说,将日志清理工作独立出来,便于统一管理也更可控。毕竟zk自带的一些工具并不怎么给力,这里是社区反映的两个问题:
https://issues.apache.org/jira/browse/ZOOKEEPER-957
http://zookeeper-user.578899.n2.nabble.com/PurgeTxnLog-td6304244.html
第一种,也是运维人员最常用的,写一个删除日志脚本,每天定时执行即可:
#!/bin/bash以上这个脚本定义了删除对应三个目录中的文件,保留最新的60个文件,可以将他写到crontab中,设置为每天凌晨2点执行一次就可以了。
#snapshot file dir
dataDir=/data/zookeeper/data/version-2
#tran log dir
dataLogDir=/data/zookeeper/log/version-2
#zk log dir
logDir=/data/zookeeper/outlog/
#Leave 60 files
count=60
count=$[$count+1]
ls -t $dataLogDir/log.* | tail -n +$count | xargs rm -f
ls -t $dataDir/snapshot.* | tail -n +$count | xargs rm -f
ls -t $logDir/zookeeper.log.* | tail -n +$count | xargs rm -f
第二种,使用ZK的工具类PurgeTxnLog,它的实现了一种简单的历史文件清理策略,可以在这里看一下他的使用方法:http://zookeeper.apache.org/doc/r3.4.3/api/index.html ,可以指定要清理的目录和需要保留的文件数目,简单使用如下:
java -cp zookeeper.jar:lib/slf4j-api-1.6.1.jar:lib/slf4j-log4j12-1.6.1.jar:lib/log4j-1.2.15.jar:conf org.apache.zookeeper.server.PurgeTxnLog第三种,对于上面这个Java类的执行,ZK自己已经写好了脚本,在bin/zkCleanup.sh中,所以直接使用这个脚本也是可以执行清理工作的。-n
第四种,从3.4.0开始,zookeeper提供了自动清理snapshot和事务日志的功能,通过配置 autopurge.snapRetainCount 和 autopurge.purgeInterval 这两个参数能够实现定时清理了。这两个参数都是在zoo.cfg中配置的:
autopurge.purgeInterval: 24*2autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
autopurge.snapRetainCount: 2
autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。
参考:http://nileader.blog.51cto.com/1381108/932156
云计算,你看好哪个时代?
OT学习平台 发表了文章 0 个评论 2062 次浏览 2017-04-11 15:17
云计算的每条技术路线都代表着一个时代
高效、便捷、安全
传统路线 虚拟机云
这是已经被广泛应用的技术路线,从AWS到国内的阿里云,使用者得到的最小单位是虚拟机,需要追加和扩展的资源实际上是整个虚拟机的资源。但每一个虚拟机资源都受到物理机最大资源的限制。例如物理机总共有128G内存,那么任何一台虚拟机的最大内存都不会超过128G。
这种路线特别适合从物理机刚转到云的技术人员,因为所有的操作、配置、管理几乎与物理机一致。
轻量级路线 容器云
随着Docker的出现,容器云开始出现。容器云是以应用为单位进行资源分割的。无论在物理机年代还是虚拟机云上,一个虚拟机/物理机上可以运行多个应用,一个应用可以简单理解为一个或一组程序。在容器云上以应用为最基本单位进行资源(CPU、内存、硬盘)的分配,相对于虚拟机云,容器云资源分割粒度进一步精细化。
虚拟机云是以硬件为基础实施的,例如在阿里云上买一台4核的虚拟机,实际上是独占了物理机上CPU中4核的资源,这部分CPU资源就不能再被其他物理机使用。
在容器云上,可以指定CPU资源,但不能再像虚拟机那样让某一个应用独占CPU资源。使用者只能指定使用哪个CPU,使用的优先级以及CPU资源分配周期。
而出于安全性的考虑,产生了第三条路线:
中间路线 容器+mini kernel路线
这条路线就是容器之间不再共享内核,而是为每一个容器提供一个独立的内核。Intel推出的clear linux项目,就是这种路线的代表。中间路线是前面两条路线的融合,未来容器云路线极有可能向此条路线发展。
三条技术路线,代表着三个时代,虚拟机路线是最早出现且成熟的,因为它符合了技术人员的使用习惯,方便过渡。容器云是目前发展最快的路线,因为它把资源分割粒度做到最小,且使传统的运维工作提升效率。未来有可能是容器+mini kernel路线的天下,更高校、更便捷、更安全,永远是追求的目标。
OTPUB直播活动又双叒叕来喽!
直播主题
甲骨文第2代企业级IaaS云技术大会
直播时间
2017年4月13日 9:30-17:30
点击报名参与>>>
Docker数据将根分区磁盘占满了
push 回复了问题 2 人关注 1 个回复 5357 次浏览 2017-03-23 14:13
设置转发和代理访问阿里MongoDB云数据库
空心菜 发表了文章 0 个评论 5689 次浏览 2017-03-09 21:34

摘要:基于安全原因考虑,阿里云MongoDB云数据库目前只支持从阿里云ECS上访问,无法通过公网直接访问,不方便用户在本地开发环境里直接进行测试,但是开发就是要测试性能,没有办法作为一个运维你必须想办法了,本文介绍能让用户通过公网访问MongoDB云数据库的方案。
环境架构说明
环境说明:
包含公网 + 私网ip的ECS
- 公网IP地址:121.196.197.64
- 内网IP地址:10.0.0.110
- 节点1:s-uf6745fa496c28d4.mongodb.rds.aliyuncs.com:3717(Primary,通过ping域名来获取对应的ip,获取到ip地址10.0.0.119,因域名对应的ip可能发生变化,在生产环境切勿直接指定ip,可以直接用域名)
- 节点2:s-uf624ab1be981c34.mongodb.rds.aliyuncs.com:3717
结构示意图如下:

目标:
通过121.196.197.64:27017能访问到10.0.0.119:3717提供的MongoDB云服务。
方案一:Iptables实现
利用iptables的nat机制,可以方便的实现请求转发,首先需要ECS开启包转发的支持
echo 1 > /proc/sys/net/ipv4/ip_forward配置转发规则
iptables -t nat -A PREROUTING -d 121.196.197.64 -p tcp --dport 27017 -j DNAT --to-destination 10.0.0.119:3717此时你就能在任意能连通公网的机器上连接121.196.197.64:27017访问MongoDB云服务,所有的请求都会转发到10.0.0.119:3717上,如果你需要严格限制,只允许你办公区公网ip地址访问的话,添加第一条规则的时候还可以增加一个 -s 参数,限制访问源!
iptables -t nat -A POSTROUTING -d 10.0.0.119 -p tcp --dport 3717 -j SNAT --to-source 10.0.0.110
需要注意的是,此时访问121.196.197.64:27017只能以单节点的方式直连,而不能按复制集的方式访问。
mongo --host 121.196.197.64:27017 --authenticationDatabase admin -uroot -pxxoo
方案二:Harpoxy四层代理实现
haproxy支持tcp(四层)、http(七层)2种转发模式,类似于iptables,我们也可以利用haproxy来实现公网访问MongoDB云数据库。
修改/etc/haproxy/haproxy.cfg配置文件内容,根据默认的配置文件稍作修改,主要配置tcp转发模式、前端、后端服务的地址信息。(haproxy版本为1.5.4)
global启动haproxy
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
defaults
# 使用tcp转发模式
mode tcp
log global
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
# 前端地址信息, 121.196.197.64:27017
frontend main 121.196.197.64:27017
default_backend app
# 后端地址信息,10.0.0.119:3717
backend app
balance roundrobin
server app1 10.0.0.119:3717 check
haproxy -f /etc/haproxy/haproxy.cfg此时你就能在任意能连通公网的机器上连接121.196.197.64:27017访问MongoDB云服务,所有的请求都会转发到10.0.0.119:3717上。
需要注意的是,此时访问121.196.197.64:27017只能以单节点的方式直连,也不能按复制集的方式访问。
mongo --host 121.196.197.64:27017 --authenticationDatabase admin -uroot -pxxoo以上服务同样适用于RDS、Redis云数据库,但切记仅能用于测试开发环境,生产环境请做好安全心里准备!
为什么Docker使用-d参数后台运行容器退出了?
空心菜 回复了问题 2 人关注 1 个回复 8008 次浏览 2017-03-09 20:35
Docker容器启动过程
Something 发表了文章 0 个评论 4020 次浏览 2017-03-09 15:02
docker run -i -t ubuntu /bin/bash输入上面这行命令,启动一个ubuntu容器时,到底发生了什么?
大致过程可以用下图描述:

首先系统要有一个docker daemon的后台进程在运行,当刚才这行命令敲下时,发生了如下动作:
- docker client(即:docker终端命令行)会调用docker daemon请求启动一个容器,
- docker daemon会向host os(即:linux)请求创建容器
- linux会创建一个空的容器(可以简单理解为:一个未安装操作系统的裸机,只有虚拟出来的CPU、内存等硬件资源)
- docker daemon请检查本机是否存在docker镜像文件(可以简单理解为操作系统安装光盘),如果有,则加载到容器中(即:光盘插入裸机,准备安装操作系统)
- 将镜像文件加载到容器中(即:裸机上安装好了操作系统,不再是裸机状态)
最后,我们就得到了一个ubuntu的虚拟机,然后就可以进行各种操作了。
如果在第4步检查本机镜像文件时,发现文件不存在,则会到默认的docker镜像注册机构(即:docker hub网站)去联网下载,下载回来后,再进行装载到容器的动作,即下图所示:

另外官网有一张图也很形象的描述了这个过程:

原文地址:http://www.cnblogs.com/yjmyzz/p/docker-container-start-up-analysis.html
参考文章:
https://www.gitbook.com/book/joshhu/docker_theory_install/details
https://docs.docker.com/engine/introduction/understanding-docker/
在Docker容器中计划任务不能执行?
空心菜 回复了问题 2 人关注 1 个回复 5513 次浏览 2017-02-24 13:25





