
通知设置 新通知
Elasticsearch 分片交互过程详解
数据库 Ansible 发表了文章 1 个评论 6283 次浏览 2015-06-18 01:40

一、Elasticseach如何将数据存储到分片中
问题:当我们要在ES中存储数据的时候,数据应该存储在主分片和复制分片中的哪一个中去;当我们在ES中检索数据的时候,又是怎么判断要查询的数据是属于哪一个分片。
数据存储到分片的过程是一定规则的,并不是随机发生的。
规则:shard = hash(routing) % number_of_primary_shards
Routing值可以是一个任意的字符串,默认情况下,它的值为存数数据对应文档 _id 值,也可以是用户自定义的值。Routing这个字符串通过一个hash的函数处理,并返回一个数值,然后再除以索引中主分片的数目,所得的余数作为主分片的编号,取值一般在0到number_of_primary_shards - 1的这个范围中。通过这种方法计算出该数据是存储到哪个分片中。
正是这种路由机制,导致了主分片的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索。
二、主分片与复制分片如何交互
为了说明这个问题,我用一个例子来说明。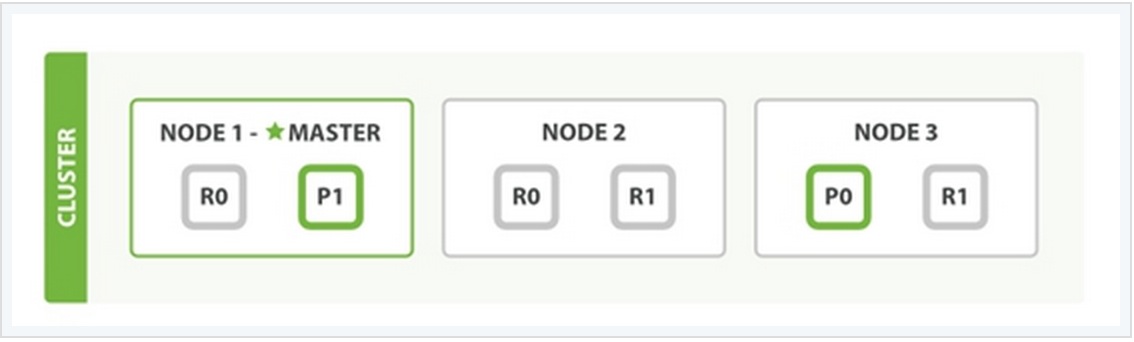
在上面这个例子中,有三个ES的node,其中每一个index中包含两个primary shard,每个primary shard拥有2个replica shard。下面从几种常见的数据操作来说明二者之间的交互情况。
1、索引与删除一个文档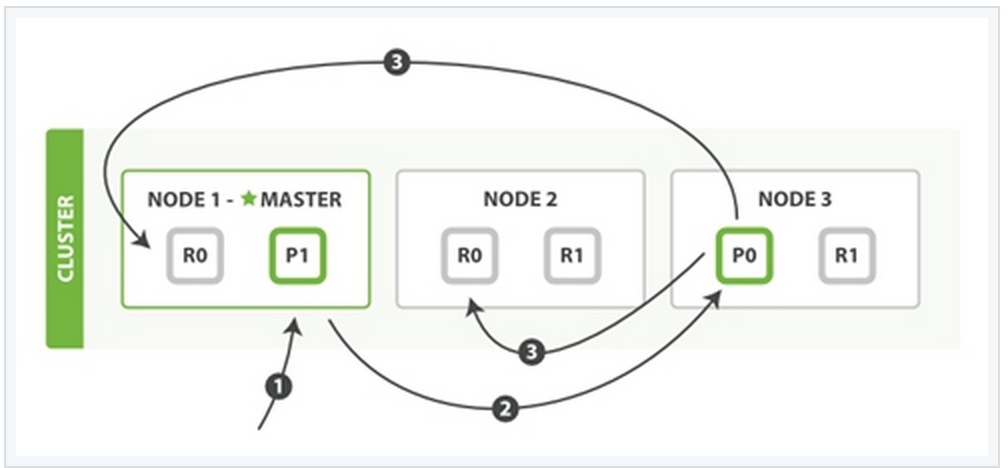
这两种过程均可以分为三个过程来描述:
阶段1:客户端发送了一个索引或者删除的请求给node 1。
阶段2:node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3在shard 0 的primary shard上执行请求。如果请求执行成功,它node 3将并行地将该请求发给shard 0的其余所有replica shard上,也就是存在于node 1和node 2中的replica shard。如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
2、更新一个文档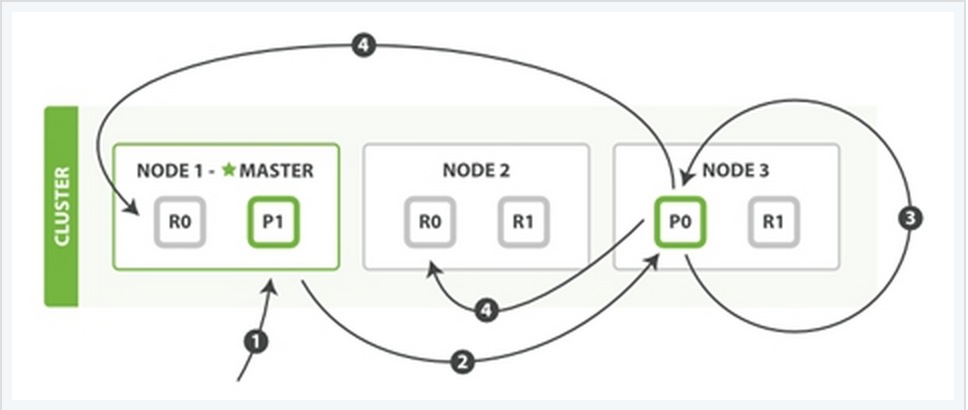
该过程可以分为四个阶段来描述:
阶段1:客户端向node 1发送一个文档更新的请求。
阶段2:同样的node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。
阶段3:node 3从文档所在的primary shard中获取到它的JSON文件,并修改其中的_source中的内容,之后再重新索引该文档到其primary shard中。
阶段4:如果node 3成功地更新了文档,node 3将会把文档新的版本并行地发给其余所有的replica shard所在node中。这些node也同样重新索引新版本的文档,执行后则向node 3确认成功,当node 3接收到所有的成功确认之后,再向客户端发送一个更新成功的信息。
3、检索文档
CRUD这些操作的过程中一般都是结合一些唯一的标记例如:_index,_type,以及routing的值,这就意味在执行操作的时候都是确切的知道文档在集群中的哪个node中,哪个shard中。
而检索过程往往需要更多的执行模式,因为我们并不清楚所要检索的文档具体位置所在, 它们可能存在于ES集群中个任何位置。因此,一般情况下,检索的执行不得不去询问index中的每一个shard。
但是,找到所有匹配检索的文档仅仅只是检索过程的一半,在向客户端返回一个结果列表之前,必须将各个shard发回的小片的检索结果,拼接成一个大的已排好序的汇总结果列表。正因为这个原因,检索的过程将分为查询阶段与获取阶段(Query Phase and Fetch Phase)。
Query Phase
在最初的查询过程中,查询请求会广播到index中的每一个primary shard和replica shard中,每一个shard会在本地执行检索,并建立一个优先级队列(priority queue)。这个优先级队列是一个根据文档匹配度这个指标所排序列表,列表的长度由分页参数from和size两个参数所决定。例如: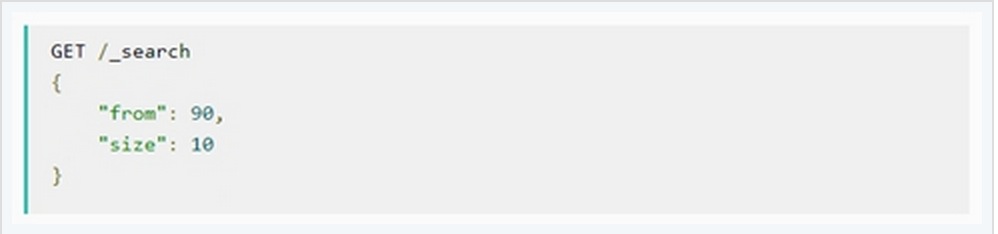
下面从一个例子中说明这个过程:
Query Phase阶段可以再细分成3个小的子阶段:
子阶段1:客户端发送一个检索的请求给node 3,此时node 3会创建一个空的优先级队列并且配置好分页参数from与size。
子阶段2:node 3将检索请求发送给该index中个每一个shard(这里的每一个意思是无论它是primary还是replica,它们的组合可以构成一个完整的index数据)。每个shard在本地执行检索,并将结果添加到本地优先级队列中。
子阶段3:每个shard返回本地优先级序列中所记录的_id与sort值,并发送node 3。Node 3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
Fetch PhaseQuery Phase主要定位了所要检索数据的具体位置,但是我们还必须取回它们才能完成整个检索过程。而Fetch Phase阶段的任务就是将这些定位好的数据内容取回并返回给客户端。
同样也用一个例子来说明这个过程: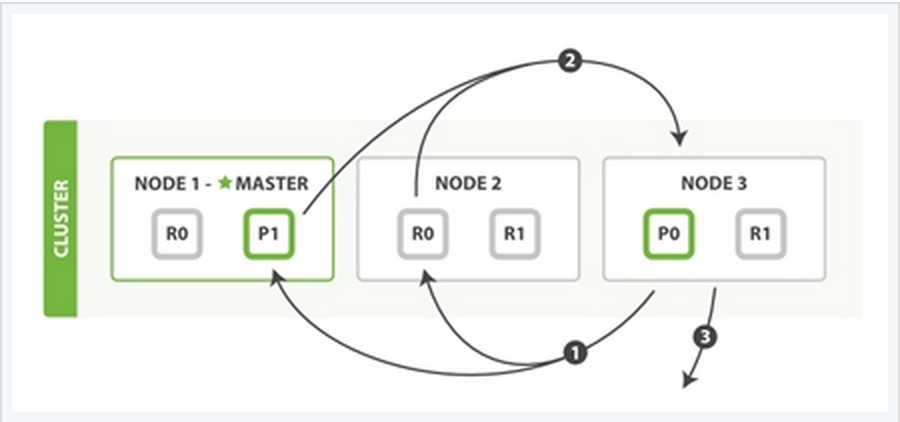
Fetch Phase过程可以分为三个子过程来描述:
子阶段1:node 3获取了所有待检索数据的定位之后,发送一个mget的请求给与数据相关的shard。
子阶段2:每个收到node 3的get请求的shard将读取相关文档_source中的内容,并将它们返回给node 3。
子阶段3:当node 3获取到了所有shard返回的文档后,node 3将它们合并成一条汇总的结果,返回给客户端。
Elasticsearch 集群版本升级步骤及注意事项
数据库 Ansible 发表了文章 0 个评论 3881 次浏览 2015-06-17 23:03

Elasticsearch 自从1.0.7版本之后,集群各节点的滚动式升级已不需要重启集群,相比之前的升级模式来看,可以非常平滑的渡过升级过程。这里将叙述集群滚动式升级及其注意事项。
1、升级前的准备工作
从Elasticsearch 的官方网站 https://www.elastic.co/downloads/elasticsearch 下载最新版本的Elasticsearch,为了线上方便对数据包的管理,一版选择 .gz.tar 格式或者 .zip 格式文件。
解压缩最新版本文件压缩包到指定目录,备份 config 目录中的 elasticsearch.yml 文件(可以简单更名,为elasticsearch.yml.bak即可)。然后复制当前版本Elasticsearch 中配置文件 elasticsearch.yml 文件的内容,到最新版本的 config 目录中。
检查系统中Java 环境是否正常,目前Elasticsearch 的版本必须使用Java 1.7.0及以上版本才能正常启动 Elasticsearch。
修改 bin 目录中 elasticsearch.in.sh 文件,关于Elasticsearch JVM 内存配置大小: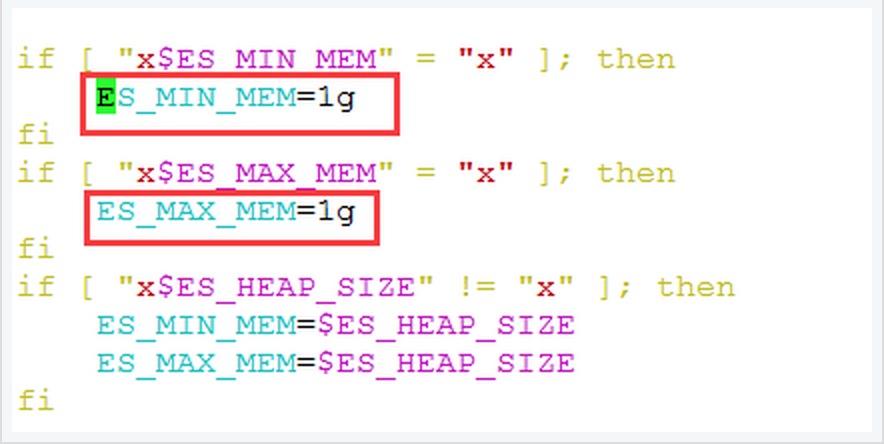
此处可以根据机器硬件配置情况作出适当的调整,一般情况下,此处的内存分配大小为机器物理内存的一半,同时将 ES_MIN_MEM 与 ES_MAX_MEM 配置成相同的值,这样的好处在于ES JVM大小固定,不会上下浮动,从实践效果上看可以提高 node 性能。
检查系统允许 Elasticsearch 打开的最大文件数
查看 /etc/security/limits.conf,如果没有指定的话,默认是4096。这里应该添加如下两行:
这个值可以根据需要适当的调整的更大。如此,当 Elasticsearch 中存在很多 index 的时候不会出现 Too many open files 的错误:
此外,由于ES集群一般都是在内部网络环境中,且节点之间相互通信使用的是 TCP 9300端口,节点与客户端通信则是通过 TCP 9200端口。因此检查 iptalbes 以及SElinux 中是否开启,以及确定这些端口是否被绑定安全策略等等。
数据备份:
在进行升级之前,我们首先要做的就是备份好目前系统中已经存在数据,防止在升级的过程中出现问题后可以方便的恢复原有的数据。例如,在升级的过程中,如果版本差别过大,可能会涉及到底层Lucene libraries的升级,这必将会影响到已存在的index数据,有时升级后的节点无法加入原有版本的集群中。
幸运的是Elasitcsearch的备份工作十分的简单,备份将用到Elasticsearch的snapshot功能,关于备份和恢复的详细过程我会单独详细阐述。
如果有必要的话,可以在最后的上线之前可以再做一次最后的测试,在测试之前,先修改Elasticsearch 中的配置文件,即是elasticsearch.yml 中的 cluster.name 参数的名称,避免加入了线上集群中。并利用 curl -XGET localhost:9201 来测试新版本的 Elasticsearch 进程是否正常。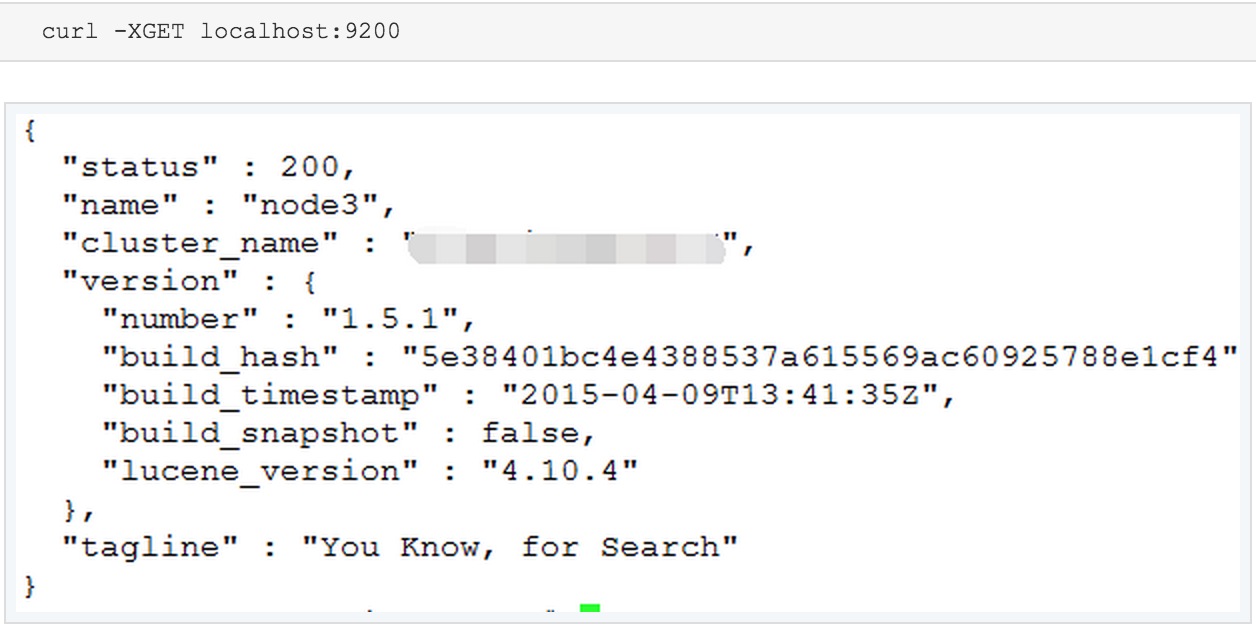
如果看到了以上内容,则表明新版本的Elasticsearch 可以正常运行。接下来,就准备更换节点ES版本了。
2、集群滚动升级
滚动升级(Rolling upgrade)
Rolling upgrade的备份过程可以让用户在一个时间内只升级集群中的某一个特定的节点。由于Elasticsearch集群具有非常优秀的容灾机制,因此,在删除集群中的某一个节点时,数据并不会丢失,而是可以由其余节点上的拷贝恢复。
不建议在一个集群中长时间的运行多个版本的Elasticsearch实例,因为当删除的节点恢复时,将来自多个版本实例的数据汇聚到同一个节点会有可能会导致节点无法工作。
接下来来叙述Rolling upgrade升级的操作步骤:
关闭shard 的实时分配选项,这样做的目的在于当集群shutdown之后可以快速的启动。这个参数默认是开启的,默认情况下当实例启动时,会尝试从其他节点实例上拷贝相关的shard副本至本地,这样会浪费大量的时间和耗费高额的IO资源。如果实时分配选项关闭了,那么当新的实例启动,尝试加入集群的时候,它不会从其他实例上拷贝shard副本。当实例完全启动之后,则应该再将该选项开启,以提供长期的容灾。
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : { "cluster.routing.allocation.enable" : "none"
}
}'
关闭所要升级版本的节点实例,并将其移除集群
curl -XPOST 'http://localhost:9200/_cluster/nodes/_local/_shutdown'
移除节点之后,等待剩余节点数据转移完成,直到确定所有的shard都被正确地分配。
升级节点的Elasticsearch版本,最简单和最安全的办法就是下载一个全新的Elasticsearch版本到本地,并将原来Elasticsearch的配置文件复制到新的版本中,最好能建立一个Elasticsearch的软连接到最新版本文件所在的目录,这样可以方便将来使用。
启动已经升级好的节点ES实例,并检查其是否正确地加入到集群中。
重新开启shard reallocation选项(实时分配选项)
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : { "cluster.routing.allocation.enable" : "all"
}
}'
检查所有的shard是否正确地被分配,并观察集群是否有执行负载均衡(也是就说每个节点被分配相等数目的shard)
重复以上过程至集群中的每个节点,直至这个集群中所有节点完成版本升级。
说明:因为目前Elasticsearch的版本都逐渐成熟,曾经的遗留版本基本上很少见到了,因此从1.0版本之前升级到1.0版本之后的步骤就不一一说明了,这个过程将不得不重启整个集群系统才能完成整个版本升级的过程,这里不再详细阐述,如有兴趣可参看:https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-upgrade.html
Docker插件无法删除CREATE_FAILED状态容器资源
大数据 空心菜 发表了文章 0 个评论 3335 次浏览 2015-06-16 22:42
docker_dbserver:如果一个容器命名为"dbserver"已经存在,则创建失败:
type: "DockerInc::Docker::Container"
properties:
image: mysql
port_specs:
- 3306
port_bindings:
3306: 3306
env:
- MYSQL_ROOT_PASSWORD=secret
name: dbserver
409 Client Error: Conflict ("Conflict, The name dbserver is already assigned to ff7791c42f29. You have to delete (or rename) that container to be able to assign dbserver to a container again.")这迫使容器变成CREATE_FAILED状态:$ heat resource-list local试图删除该堆栈将导致一个新的错误:
+-----------------+------------------------------+-----------------+----------------------+
| resource_name | resource_type | resource_status | updated_time |
+-----------------+------------------------------+-----------------+----------------------+
| docker_dbserver | DockerInc::Docker::Container | CREATE_FAILED | 2014-09-01T13:49:58Z |
+-----------------+------------------------------+-----------------+----------------------+
APIError: 404 Client Error: Not Found ("No such container: None")
此时,唯一的选择就是"heat stack-abandon". make[1]: *** [objs/addon/nginx_tcp_proxy_module-master/ngx_tcp_upstream.o] Error 1
运维 OpenSkill 发表了文章 0 个评论 6720 次浏览 2015-06-16 21:28
patch -p1 < /path/to/nginx_tcp_proxy_module/tcp.patch
sh: phpize: command not found ERROR: `phpize' failed
编程 OpenSkill 发表了文章 0 个评论 5944 次浏览 2015-06-16 21:26
[root@cjlx src]# pecl install SeasLogCentos 解决如下:
WARNING: channel "pecl.php.net" has updated its protocols, use "pecl channel-update pecl.php.net" to update
downloading SeasLog-1.1.8.tgz ...
Starting to download SeasLog-1.1.8.tgz (48,686 bytes)
.............done: 48,686 bytes
21 source files, building
running: phpize
sh: phpize: command not found
ERROR: `phpize' failed
# yum install php-devel





