

Python
Python的发展趋势
编程 空心菜 发表了文章 0 个评论 2977 次浏览 2021-08-08 21:47

一、Python发展历史
Python是一种计算机程序设计语言。你可能在之前听说过很多编程语言,比如难学的C语言(语法和实现难度),非常流行的JAVA语言(尤其是现在分布式存储和服务),非常有争议的PHP(常见 WordPress 大多网站),前端HTML、JavaScripts、Node.JS、还有最近随着容器风行的Golang等等。那Python是What?
- 1989年,Python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
- 1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
- 1992年,Python之父发布了Python的web框架Zope1.
- Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
- Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
- Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
- Python 2.5 - September 19, 2006
- Python 2.6 - October 1, 2008
- Python 2.7 - July 3, 2010
- In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to Python 3.4+ as soon as possible
- Python 3.0 - December 3, 2008
- Python 3.1 - June 27, 2009
- Python 3.2 - February 20, 2011
- Python 3.3 - September 29, 2012
- Python 3.4 - March 16, 2014
- Python 3.5 - September 13, 2015
最新参考:https://www.python.org/downloads/release
二、Python的前景
最新的TIOBE( https://www.tiobe.com/tiobe-index/ )排行榜,Python赶超JAVA占据第二名了, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。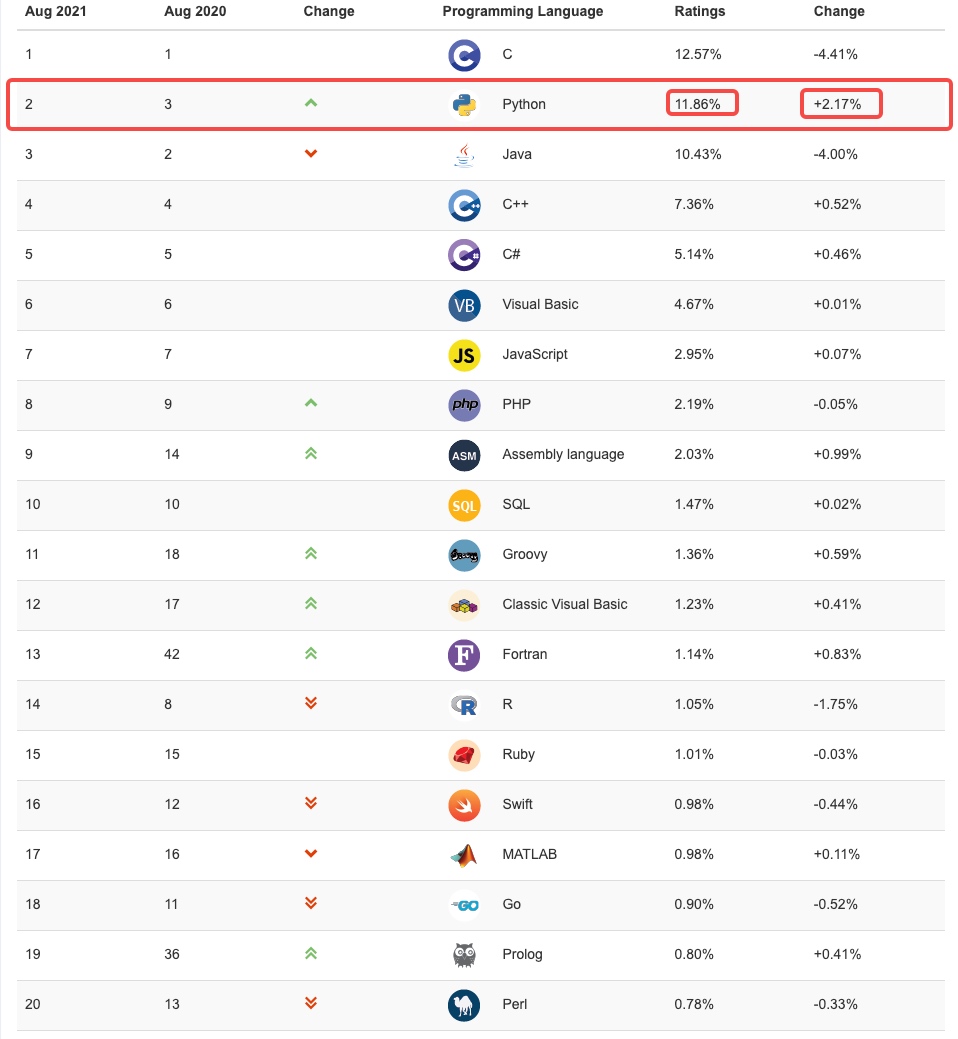
我们看看17年Python的排名: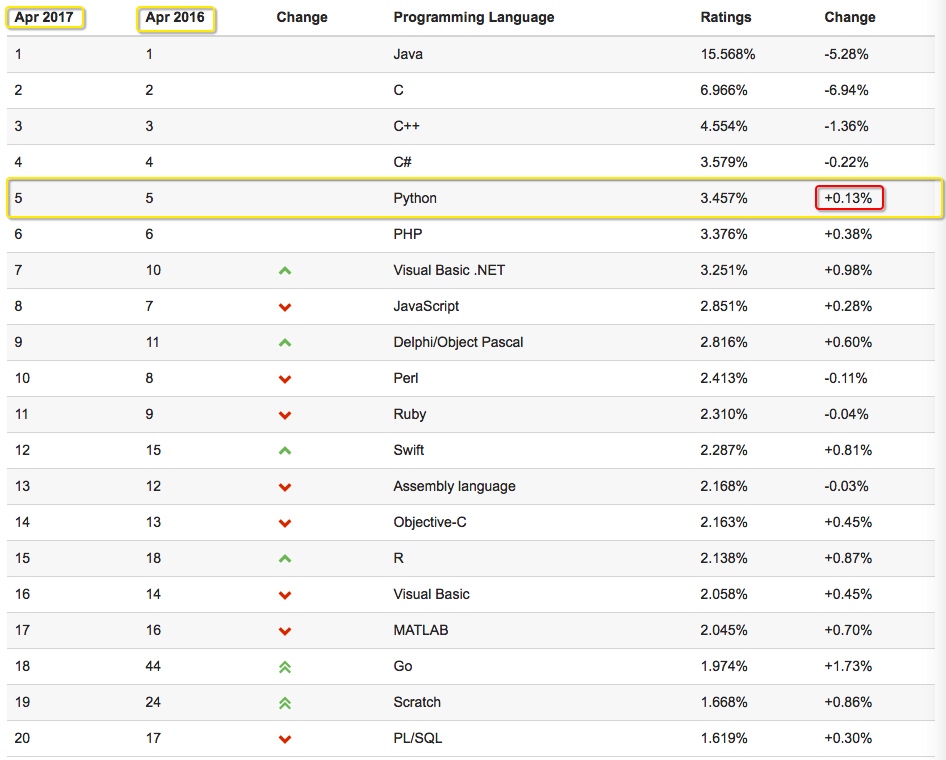
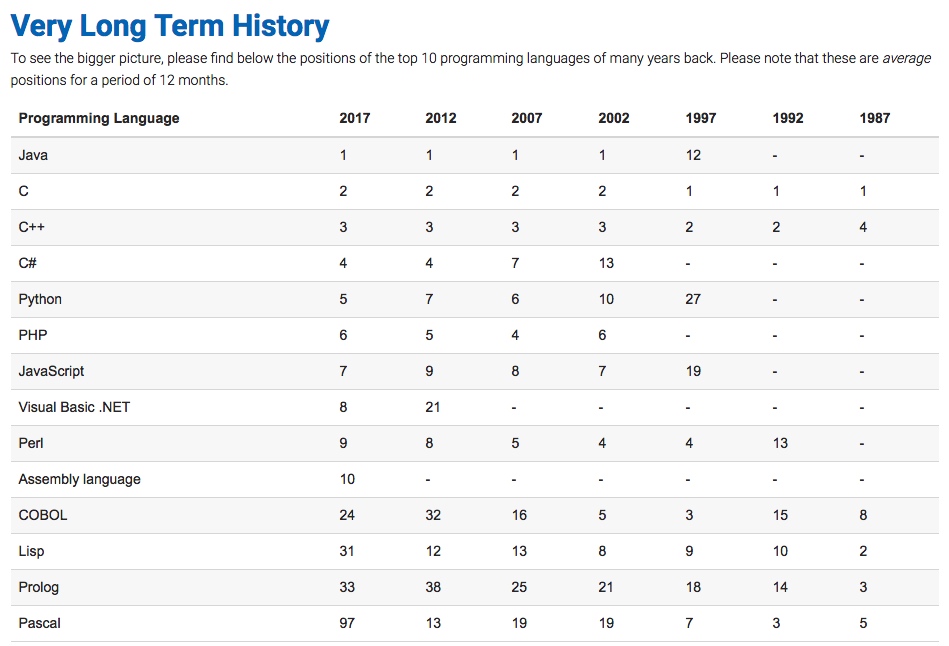
由上图17年预测可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到大家的认知和认可,影响度也越来越大,在国内Python开发招聘的岗位也越来越多,我们来看看2017年100offer统计情况: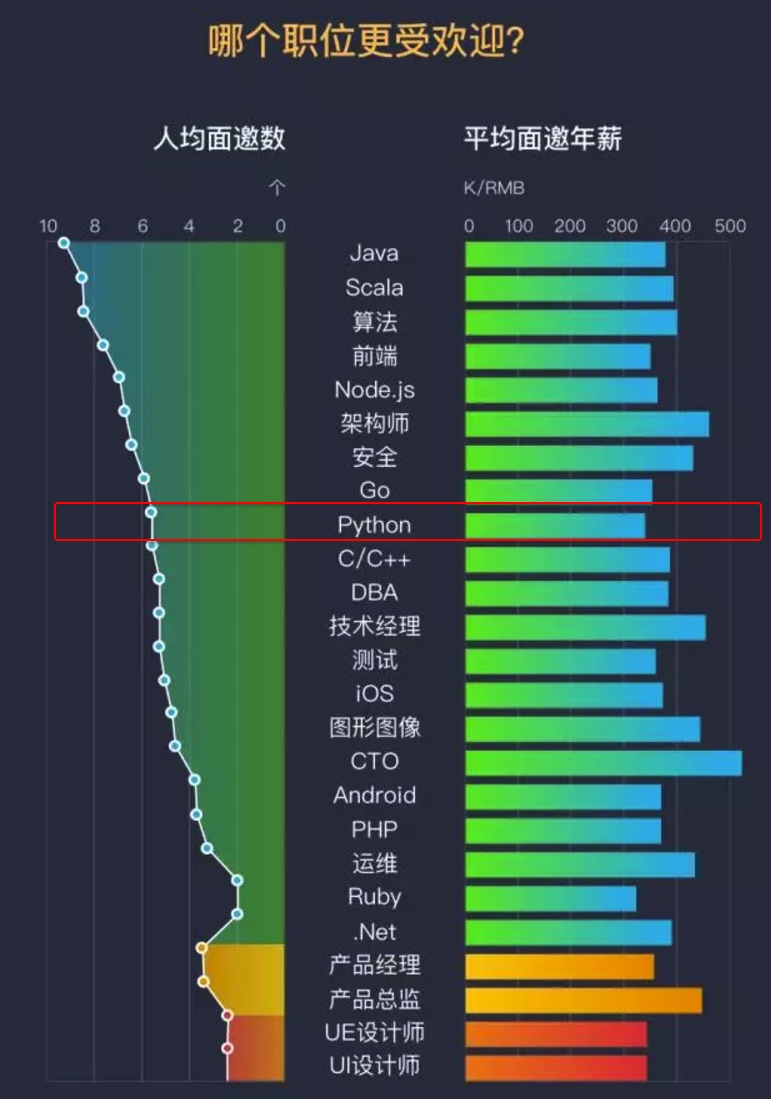
从上图我们可以看出Python的人均面邀数为6,整体年薪在34w左右,在职位招聘排行榜前十名,应该还算不错的表现哦。
三、Python的应用领域
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。
目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、阿里、百度、腾讯、汽车之家、美团等。
目前Python主要的应用领域
云计算: 在云计算领域Python可谓有一席之地, 典型应用OpenStack这个大体量的开源云计算产品就是居于Python开发的。
WEB开发: 已有众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣, 知乎等…., Python也有许多Web开发框架,典型WEB框架有Django、Pylons,还有Tornado、Bottle、Flask等。
系统运维: 从国内的趋势来看,掌握一门编程语言已经成为了必然的结果,Python在国内已经成为了首选,不管是做自动化运维还是业务运维现在Python在运维领域已经应用极广。
金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
图形GUI: PyQT, WxPython, TkInter, PySide等在图形用户接口领域都有广泛被应用。
哪些公司在用Python
谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发。
CIA: 美国中情局网站就是用Python开发的。
NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算。
YouTube:世界上最大的视频网站YouTube就是用Python开发的。
Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载。
Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发。
Facebook:大量的基础库均通过Python实现的
Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
豆瓣: 公司几乎所有的业务均是通过Python开发完成的。
知乎: 国内最大的问答社区,通过Python开发(国外Quora)
春雨医生:国内知名的在线医疗网站是用Python开发的
除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务, 互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
为什么是Python而不是其他语言呢?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python和C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
Python和PHP相比
Python提供了丰富的数据结构,非常容易和c集成。相比较而言,php集中专注在web上。 php大多只提供了系统api的简单封装,但是python标准包却直接提供了很多实用的工具。python的适用性更为广泛,php在web更加专业,php的简单数据类型,完全是为web量身定做。
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。语言是死的,每个语言的诞生都有它的道理,所以选择你喜欢的,开心的玩起来。
Pyhton列表去重方法总结
编程 Ansible 发表了文章 0 个评论 1549 次浏览 2020-11-02 00:22

Python列表去重在Python应用编程中,是一种非常常见的应用技巧,有些场景下需要统计出来的列表中去重,避免重复统计。
1. 通过字典去重
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = {}.fromkeys(job).keys()
print(list(jobs))
结果:
['Sale', 'Dev', 'OPS', 'Presale', 'Test']
解释:
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
语法:
dict.fromkeys(seq[, value])
- seq - 字典键值列表。
- value - 可选参数, 设置键序列(seq)的值。
该方法返回一个新字典, .keys 函数以列表返回一个字典所有的键。
2. 通过集合去重
大家都知道在Python数据结构中集合是天生去重的,所以我们可以利用这一特性来达到列表去重的效果。
格式: list(set(mylist))
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = list(set(job))
由于采用集合,会导致原有的列表排序发生变化,此时可通过如下方法,保持列表原有顺序:
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = list(set(job))
jobs.sort(key=job.index)
3. 使用itertools模块
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
import itertools
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
job.sort()
job_group = itertools.groupby(job)
jobs = []
for k, g in job_group:
jobs.append(k)
print(jobs)
groupby 根据key(v)值分组的迭代器, 将key函数作用于原循环器的各个元素。根据key函数结果,将拥有相同函数结果的元素分到一个新的循环器。每个新的循环器以函数返回结果为标签。
4. 通过列表推导式去重
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = []
[ jobs.append(i) for i in job if i not in jobs]
通过列表推导式,判断在不在新列表中的元素则添加到新列表中。
5. 利用lambda匿名函数和 reduce 函数处理
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
from functools import reduce
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
func = lambda x,y:x if y in x else x + [y]
jobs = reduce(func, [[], ] + job)
Python下判断文件是否为二进制文件的三种方法
编程 OpenSkill 发表了文章 0 个评论 5343 次浏览 2020-09-18 18:27

常用的有两种方法判断文件是否为二进制文件,最准确的就是把这两种方法结合起来更加准确点.
方法1利用codecs模块
它首先检查文件是否以BOM开始,如果不在初始8192字节内查找零字节:
import codecs
file_path = "/home/ubuntu/zgd/ztest/_gs418_510txp_v6.6.2.7.stk.extracted/test"
#: BOMs to indicate that a file is a text file even if it contains zero bytes.
_TEXT_BOMS = (
codecs.BOM_UTF16_BE,
codecs.BOM_UTF16_LE,
codecs.BOM_UTF32_BE,
codecs.BOM_UTF32_LE,
codecs.BOM_UTF8,
)
def is_binary_file(file_path):
with open(file_path, 'rb') as file:
initial_bytes = file.read(8192)
file.close()
return not any(initial_bytes.startswith(bom) for bom in _TEXT_BOMS) and b'\0' in initial_bytes
if __name__ == "__main__":
print is_binary_file(file_path)
上面is_binary_file()函数也可以改成下面的方式:
def is_binary_file(file_path):
with open(file_path, 'rb') as file:
initial_bytes = file.read(8192)
file.close()
for bom in _TEXT_BOMS:
if initial_bytes.startswith(bom):
continue
else:
if b'\0' in initial_bytes:
return True
return False
方法2利用magic模块
安装模块: pip install python-magic
def getFileType(ff):
mime_kw = 'x-executable|x-sharedlib|octet-stream|x-object' ###可执行文件、链接库、动态流、对象
try:
magic_mime = magic.from_file(ff, mime=True)
magic_hit = re.search(mime_kw, magic_mime, re.I)
if magic_hit:
return True
else:
return False
except Exception, e:
print e.message
最好的方法是对两种类型同时进行处理:
# -*- coding:utf-8 -*-
# @Author:zgd
# @time:2019/6/21
# @File:operateSystem.py
import magic
import re
import codecs
def is_binary_file_1(ff):
'''
根据text文件数据类型判断是否是二进制文件
:param ff: 文件名(含路径)
:return: True或False,返回是否是二进制文件
'''
TEXT_BOMS = (
codecs.BOM_UTF16_BE,
codecs.BOM_UTF16_LE,
codecs.BOM_UTF32_BE,
codecs.BOM_UTF32_LE,
codecs.BOM_UTF8,
)
with open(file_path, 'rb') as file:
CHUNKSIZE = 8192
initial_bytes = file.read(CHUNKSIZE)
file.close()
#: BOMs to indicate that a file is a text file even if it contains zero bytes.
return not any(initial_bytes.startswith(bom) for bom in TEXT_BOMS) and b'\0' in initial_bytes
def is_binwary_file_2(ff):
'''
根据magic文件的魔术判断是否是二进制文件
:param ff: 文件名(含路径)
:return: True或False,返回是否是二进制文件
'''
mime_kw = 'x-executable|x-sharedlib|octet-stream|x-object' ###可执行文件、链接库、动态流、对象
try:
magic_mime = magic.from_file(ff, mime=True)
magic_hit = re.search(mime_kw, magic_mime, re.I)
if magic_hit:
return True
else:
return False
except Exception, e:
return False
if __name__ == "__main__":
file_path = "/home/ubuntu/zgd/ztest/_gs418_510txp_v6.6.2.7.stk.extracted/D0"
print is_binary_file_1(file_path)
print is_binwary_file_2(file_path)
print any((is_binary_file_1(file_path), is_binwary_file_2(file_path)))
方法3判断是否有ELF头
根据文件中是否有ELF头进行判断文件是否为二进制文件
# 判断文件是否是elf文件
def is_ELFfile(filepath):
if not os.path.exists(filepath):
logger.info('file path {} doesnot exits'.format(filepath))
return False
# 文件可能被损坏,捕捉异常
try:
FileStates = os.stat(filepath)
FileMode = FileStates[stat.ST_MODE]
if not stat.S_ISREG(FileMode) or stat.S_ISLNK(FileMode): # 如果文件既不是普通文件也不是链接文件
return False
with open(filepath, 'rb') as f:
header = (bytearray(f.read(4))[1:4]).decode(encoding="utf-8")
# logger.info("header is {}".format(header))
if header in ["ELF"]:
# print header
return True
except UnicodeDecodeError as e:
# logger.info("is_ELFfile UnicodeDecodeError {}".format(filepath))
# logger.info(str(e))
pass
return False
分享Python基础入门到精通视频教程5套
编程 alber1986 发表了文章 0 个评论 3370 次浏览 2017-12-16 11:32

分享Python基础入门到精通视频教程5套:
第一套:Python14期VIP视频
第二套 python全栈开发工程师1期
第三套 2017年老男孩全栈第二期103天完整
第四套 Python视频课程就业班
第五套 Python自动化开发12期完整版
http://www.sucaihuo.com/video/194.html
Python的发展趋势
编程 空心菜 发表了文章 0 个评论 2977 次浏览 2021-08-08 21:47
一、Python发展历史
Python是一种计算机程序设计语言。你可能在之前听说过很多编程语言,比如难学的C语言(语法和实现难度),非常流行的JAVA语言(尤其是现在分布式存储和服务),非常有争议的PHP(常见 WordPress 大多网站),前端HTML、JavaScripts、Node.JS、还有最近随着容器风行的Golang等等。那Python是What?
- 1989年,Python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
- 1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
- 1992年,Python之父发布了Python的web框架Zope1.
- Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
- Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
- Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
- Python 2.5 - September 19, 2006
- Python 2.6 - October 1, 2008
- Python 2.7 - July 3, 2010
- In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to Python 3.4+ as soon as possible
- Python 3.0 - December 3, 2008
- Python 3.1 - June 27, 2009
- Python 3.2 - February 20, 2011
- Python 3.3 - September 29, 2012
- Python 3.4 - March 16, 2014
- Python 3.5 - September 13, 2015
最新参考:https://www.python.org/downloads/release
二、Python的前景
最新的TIOBE( https://www.tiobe.com/tiobe-index/ )排行榜,Python赶超JAVA占据第二名了, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。
我们看看17年Python的排名:
由上图17年预测可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到大家的认知和认可,影响度也越来越大,在国内Python开发招聘的岗位也越来越多,我们来看看2017年100offer统计情况:
从上图我们可以看出Python的人均面邀数为6,整体年薪在34w左右,在职位招聘排行榜前十名,应该还算不错的表现哦。
三、Python的应用领域
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。
目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、阿里、百度、腾讯、汽车之家、美团等。
目前Python主要的应用领域
云计算: 在云计算领域Python可谓有一席之地, 典型应用OpenStack这个大体量的开源云计算产品就是居于Python开发的。
WEB开发: 已有众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣, 知乎等…., Python也有许多Web开发框架,典型WEB框架有Django、Pylons,还有Tornado、Bottle、Flask等。
系统运维: 从国内的趋势来看,掌握一门编程语言已经成为了必然的结果,Python在国内已经成为了首选,不管是做自动化运维还是业务运维现在Python在运维领域已经应用极广。
金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
图形GUI: PyQT, WxPython, TkInter, PySide等在图形用户接口领域都有广泛被应用。
哪些公司在用Python
谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发。
CIA: 美国中情局网站就是用Python开发的。
NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算。
YouTube:世界上最大的视频网站YouTube就是用Python开发的。
Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载。
Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发。
Facebook:大量的基础库均通过Python实现的
Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
豆瓣: 公司几乎所有的业务均是通过Python开发完成的。
知乎: 国内最大的问答社区,通过Python开发(国外Quora)
春雨医生:国内知名的在线医疗网站是用Python开发的
除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务, 互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
为什么是Python而不是其他语言呢?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python和C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
Python和PHP相比
Python提供了丰富的数据结构,非常容易和c集成。相比较而言,php集中专注在web上。 php大多只提供了系统api的简单封装,但是python标准包却直接提供了很多实用的工具。python的适用性更为广泛,php在web更加专业,php的简单数据类型,完全是为web量身定做。
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。语言是死的,每个语言的诞生都有它的道理,所以选择你喜欢的,开心的玩起来。
图解Python 集合
编程 空心菜 发表了文章 2 个评论 4611 次浏览 2016-08-10 23:41
集合基本功能
集合是一个无序的,不重复的数据组合,用{}表示,它的主要作用如下:
- 去重,把一个列表变成集合,就会自动去重
- 关系测试,测试两组数据之前的交集、差集、并集、子集等关系
集合创建:
>>> set_job = set(['DEV', 'OPS', 'DBA', 'QA', 'Sales'])
>>> set_man = set(('lucky', 'jack', 'andy', 'tom', 'andy', 'jim'))
>>> print(set_job, type(set_job))
{'DEV', 'OPS', 'Sales', 'QA', 'DBA'}
>>> print(set_man, type(set_man)) # 天生去重,只有一个andy了
{'andy', 'jack', 'lucky', 'tom', 'jim'}
元素添加:
>>> set_job = set(['DEV', 'OPS', 'DBA', 'QA', 'Sales'])
>>> set_job.add('HR') # add方法只能添加一个
>>> print(set_job)
{'QA', 'HR', 'Sales', 'DEV', 'OPS', 'DBA'}
>>> set_job.update(['FD', 'MD', 'MD'])
>>> print(set_job)
{'QA', 'HR', 'Sales', 'DEV', 'MD', 'OPS', 'FD', 'DBA'}
>>> set_job.update(('AD', 'PD')) # update方法可以添加是列表或者元组,去重,如果添加的为一个单独字符串,则把字符串拆成字母添加到集合中
>>> print(set_job)
{'QA', 'HR', 'PD', 'Sales', 'DEV', 'MD', 'OPS', 'AD', 'FD', 'DBA'}
元素删除:
>>> set_job = {'QA', 'HR', 'PD', 'Sales', 'DEV', 'MD', 'OPS', 'AD', 'FD', 'DBA'}
>>> set_job.remove('PD') # 删除指定元素
>>> set_job.remove('xx') # 元素不存在则报错 KeyError
Traceback (most recent call last):
File "", line 1, in
KeyError: 'xx'
>>> print(set_job)
{'QA', 'HR', 'MD', 'DEV', 'Sales', 'OPS', 'AD', 'FD', 'DBA'}
>>> set_job.pop() # 随机删除一个元素
'QA'
>>> print(set_job)
{'HR', 'MD', 'DEV', 'Sales', 'OPS', 'AD', 'FD', 'DBA'}
>>> set_job.discard('OPS') # 指定删除
>>> set_job.discard('xxx') # 不存在返回None,不会报KeyError
>>> print(set_job)
{'HR', 'MD', 'DEV', 'Sales', 'AD', 'FD', 'DBA'} 其他:
>>> set_job = {'QA', 'HR', 'PD', 'Sales', 'DEV', 'MD', 'OPS', 'AD', 'FD', 'DBA'}
>>> len(set_job) # 集合长度
10
>>> 'QA' in set_job # 判断是否在集合中
True
>>> 'XXX' not in set_job # 不在集合中
True
>>> for i in set_job: # 循环
... print(i)
集合关系测试
交集:

>>> set_a = {5, 6, 7, 8, 9, 10}
>>> set_b = {1, 2, 3, 4, 5, 6}
>>> print(set_a.intersection(set_b)) # 常规方式
{5, 6}
>>> print(set_a & set_b) # 运算符(&)方式
{5, 6}并集

>>> set_a = {5, 6, 7, 8, 9, 10}
>>> set_b = {1, 2, 3, 4, 5, 6}
>>> set_c = set_a.union(set_b) # 关键字union做并集运算 先后顺序无关,谁并谁都可以
>>> print(set_c)
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
>>>
>>> set_c = set_a | set_b # 运算符关键符 | 做并集运算 先后顺序无关,谁并谁都可以
>>> print(set_c)
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
差集

>>> set_a = {5, 6, 7, 8, 9, 10}
>>> set_b = {1, 2, 3, 4, 5, 6}
>>> set_c = set_a - set_b # a集合跟b集合做差集 关键符 -
>>> print(set_c)
{8, 9, 10, 7}
>>> set_d = set_b - set_a # b集合跟a集合做差集 关键符 -
>>> print(set_d)
{1, 2, 3, 4}
>>> set_c = set_a.difference(set_b) # a集合跟b集合做差集 关键字difference
>>> print(set_c)
{8, 9, 10, 7}
>>> set_d = set_b.difference(set_a) # b集合跟a集合做差集 关键字difference
>>> print(set_d)
{1, 2, 3, 4}子集父集

拿苹果来打比方就是,把苹果掰开,然后掰开的一小部分就是子集,然后整个苹果就是父集
>>> set_a = {5, 6, 7, 8, 9, 10}
>>> set_b = {1, 2, 3, 4, 5, 6}
>>> set_c = {7, 8, 9, 10}
>>> set_d = {1, 2, 3, 4}
>>> set_e = {5, 6}
>>> set_f = {11, 12, 13, 14, 15, 16}
>>> set_c.issubset(set_a) # 测试集合c是否是集合a的子集 放回布尔值 关键字issubset
True
>>> set_d.issubset(set_b) # 测试集合d是否是集合b的子集 返回布尔值 issubset
True
>>> set_e.issubset(set_a)
True
>>> set_e.issubset(set_b)
True
>>> set_e <= set_a # 测试集合e是否是集合a的子集 关键符 <=
True
>>> set_e <= set_b
True
>>> set_f.issuperset(set_a) # 测试f集合是否是a集合的父集
False
>>> set_a.issuperset(set_e) # 测试a集合是否是集合e的父集 关键字issuperset
True
>>> set_b >= set_e # 测试集合b是否是集合e的父集 关键符 >=
True
>>> set_b >= set_d
True对称差集
对称差集就是两个集合去掉相同的部分,然后剩下的所有元素组成的集合

>>> set_a = {5, 6, 7, 8, 9, 10}
>>> set_b = {1, 2, 3, 4, 5, 6}
>>> set_c = set_a.symmetric_difference(set_b) # 集合a和集合b做对称差集 关键字symmetric_difference
>>> print(set_c)
{1, 2, 3, 4, 7, 8, 9, 10}
>>> set_c = set_a ^ set_b # 集合a和集合b做对称差集 关键符 ^
>>> print(set_c)
{1, 2, 3, 4, 7, 8, 9, 10}
>>> set_c = set_b ^ set_a
>>> print(set_c)
{1, 2, 3, 4, 7, 8, 9, 10}所有方法:
class set(object):
"""
set() -> new empty set object
set(iterable) -> new set object
Build an unordered collection of unique elements.
"""
def add(self, *args, **kwargs): # real signature unknown
"""
Add an element to a set.
This has no effect if the element is already present.
"""
pass
def clear(self, *args, **kwargs): # real signature unknown
""" Remove all elements from this set. """
pass
def copy(self, *args, **kwargs): # real signature unknown
""" Return a shallow copy of a set. """
pass
def difference(self, *args, **kwargs): # real signature unknown
"""
Return the difference of two or more sets as a new set.
(i.e. all elements that are in this set but not the others.)
"""
pass
def difference_update(self, *args, **kwargs): # real signature unknown
""" Remove all elements of another set from this set. """
pass
def discard(self, *args, **kwargs): # real signature unknown
"""
Remove an element from a set if it is a member.
If the element is not a member, do nothing.
"""
pass
def intersection(self, *args, **kwargs): # real signature unknown
"""
Return the intersection of two sets as a new set.
(i.e. all elements that are in both sets.)
"""
pass
def intersection_update(self, *args, **kwargs): # real signature unknown
""" Update a set with the intersection of itself and another. """
pass
def isdisjoint(self, *args, **kwargs): # real signature unknown
""" Return True if two sets have a null intersection. """
pass
def issubset(self, *args, **kwargs): # real signature unknown
""" Report whether another set contains this set. """
pass
def issuperset(self, *args, **kwargs): # real signature unknown
""" Report whether this set contains another set. """
pass
def pop(self, *args, **kwargs): # real signature unknown
"""
Remove and return an arbitrary set element.
Raises KeyError if the set is empty.
"""
pass
def remove(self, *args, **kwargs): # real signature unknown
"""
Remove an element from a set; it must be a member.
If the element is not a member, raise a KeyError.
"""
pass
def symmetric_difference(self, *args, **kwargs): # real signature unknown
"""
Return the symmetric difference of two sets as a new set.
(i.e. all elements that are in exactly one of the sets.)
"""
pass
def symmetric_difference_update(self, *args, **kwargs): # real signature unknown
""" Update a set with the symmetric difference of itself and another. """
pass
def union(self, *args, **kwargs): # real signature unknown
"""
Return the union of sets as a new set.
(i.e. all elements that are in either set.)
"""
pass
def update(self, *args, **kwargs): # real signature unknown
""" Update a set with the union of itself and others. """
pass
Python菜鸟之路基础篇(一)
编程 空心菜 发表了文章 3 个评论 5016 次浏览 2016-07-26 00:55
Hello World
学习任何一门语言,我想大家写的以一句就是hello world吧,下面我们来看看Python的hello world
创建一个hello.py的文件:
print ("Hello World")然后执行命令:python hello.py ,输出crh:Python crh$ python3 hello.py
Hello World
Python执行过程为: 把代码读到内存 ---->词法语法分析 ---->放到编译器 ----> 生成字节码 ---->执行字节码 ---->生成机器码---->CPU执行,图示如下:

指定解释器
在上面情况,我们指定Python3 来执行hello.py
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
crh:Python crh$ cat hello.py像上面这样,然后给hello.py文件添加执行权限(chmod +x hello.py)就可以像执行shell脚本一样./hello.py 即可。
#!/usr/bin/env python3
print ("Hello World")
***像上面是利用Linux env命令通过环境变量去找到你想用的Python命令,如果你指定用某个Python版本的话一可以写绝对路径,比如:/usr/bin/python or /usr/local/bin/python3
在交互器中执行
除了把程序写在文件里,还可以直接调用python自带的交互器运行代码,进行调试和测试
crh:Python crh$ python3
Python 3.5.1 (default, Dec 26 2015, 18:08:53)
[GCC 4.2.1 Compatible Apple LLVM 7.0.2 (clang-700.1.81)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
[quote]>> print ("Hello World")
Hello World
>>>
变量
在一个计算机程序中引用变量是用来存储信息和操作的。他们还提供一种标签数据与一个描述性的名称,所以我们的程序可以被读者和我们自己更清楚地理解。它有助于认为变量保存信息的容器。他们的唯一目的是标签和数据存储在内存中。这些数据可以通过使用程序引用。
声明变量
#_[i]_coding:utf-8_[/i]_如上面所示声明了一个变量name,他的值是"Lucky chen"
name = "Lucky chen"
我们再来看一组连续赋值的过程:
>>> name = "crh"如上所示,为什么name1 = name 当后续把name变量的值改变了,为什么name1的值没有随着改变呢,如下看看你就明白了:
>>> name1 = name
>>> print (name,name1)
crh crh
>>> name = "Lucky"
>>> print (name1,name)
crh Lucky
>>> name = "crh" #首先在内存中打开一块内存空间存储name变量值如上所示,我们可以看出,nama1其实就是借助name变量做一个变量的赋值,通过name变量得到值所在内存中的内存地址后,从而变成了一个正常的赋值过程。而不换随着name变量的内存空间地址的改变而改变。示意图如下:
>>> id(name) #查看变量name的内存地址
4412833952
>>> name1 = name #把我们把name赋值给name1变量
>>> id(name1) #然后查看name1变量的内存地址 (跟name变量的内存地址一样)
4412833952
>>> name = "lucky" #重新打开一个内存空间存储name的变量值
>>> id(name) #查看新的name变量值的内存地址
4412834176
>>> id(name1) #查看name1变量内存地址
4412833952

交互输入
用户输入就是程序和用户的交互,程序等待用户输入一个参数然后重新继续进行:
#!/usr/bin/env python3
#Authe: Lucky.chen
#_[i]_coding:utf-8_[/i]_
name = input("Please enter your name:")
print ("[size=16]#",name,"[/size]#")

如上图所示,默认Python3下的input函数用户输入的所有东西都当做字符串处理,所以你输入的年龄希望它是整数类型,还需要int()一下。
在python2中input这个函数,用户默认输入的是什么格式的参数,Python就当作是什么类型处理,Python2中获取用户输入参数的函数还有一个叫做raw_input(),这个函数默认也是字符串处理。可以看出Python3为了简洁统一,在Python3中已经不存在了raw_input()函数,input()一个函数完全可以做到所有使用。
平常如果我们用针对密码、密码串之类的交互的话,一般用户的输入时隐藏或者*****的,输入密码时,在Python下如果你需要你输入的东西不可见,可以利用getpass 模块中的 getpass方法来处理:
#!/usr/bin/env python3[/size]
#Authe: Lucky.chen
#_[i]_coding:utf-8_[/i]_[/quote]
#导入getpass模块
import getpass
# 将用户输入的内容赋值给 name 变量
pwd = getpass.getpass("请输入密码:")
# 打印输入的内容
print("Password is [size=16]",pwd,"***print end")[/size]
#比如我输入110119,执行过程和结果如下:
请输入密码:
Password is [size=16] 110119 ***print end
注释和拼接
注释:
单行注释:# 开头就好,跟shell一样
多行注释:成对的三个单引号 ''' 注释内容 ''' 或者 成对的三个双引号 """ 注释内容 """
>>> ''' My name is lucky '''
' My name is lucky '
[quote]>> """ My age is 23 """
' My age is 23 '
>>> # Good Idea
...
>>> msg = """ My info is :
... age: 23
... name: lucky
... job: IT"""
>>> print (msg)
My info is :
age: 23
name: lucky
job: IT
>>>
拼接:
1、难受的 "+"
>>> name = "lucky"如上所示 "+"拼接只能是字符串,如果是整型、或者是浮点都会报错。
>>> age = 23
>>> job = "IT"
>>>
>>> msg = """ Info of """ +name + """
... Name:""" +name + """
... Age:""" +age + """
... Job:""" +job
Traceback (most recent call last):
File "", line 4, in
TypeError: Can't convert 'int' object to str implicitly
>>>
>>> name = "lucky"
>>> age = "23"
>>> job = "IT"
>>> msg = """ Info of """ +name + """
... Name:""" +name + """
... Age:""" +age + """
... Job:""" +job
>>> print (msg)
Info of lucky
Name:lucky
Age:23
Job:IT
>>>
2、百分号(%)
Code:
#!/usr/bin/env python3.5Result:
#auther: lucky.chen[/quote]
name = input("Please input your name: ")
age = input("Please input your age:")
job = input("Please input your job:")
salary = input("Please input your salary:")
msg = """------------ info of %s
Name: %s
Age: %s
Job: %s
Salary: %s
""" % (name,name,age,job,salary)
print (msg)
Please input your name: lucky
Please input your age:23
Please input your job:IT
Please input your salary:40000
------------ info of lucky
Name: lucky
Age: 23
Job: IT
Salary: 40000
3、使用format函数
情况一:使用变量格式化
Code:
#!/usr/bin/env python3.5Result:
#auther: lucky.chen
name = input("Please input your name: ")
age = input("Please input your age:")
job = input("Please input your job:")
salary = input("Please input your salary:")
msg = """------------ info of {_Name}
Name: {_Name}
Age: {_Age}
Job: {_Job}
Salary: {_Salary}
""".format(_Name=name,_Age=age,_Job=job,_Salary=salary)
print (msg)
Please input your name: crh情况二:使用下脚标
Please input your age:23
Please input your job:IT
Please input your salary:45000
------------ info of crh
Name: crh
Age: 23
Job: IT
Salary: 45000
#!/usr/bin/env python3.5Result:
#auther: lucky.chen
name = input('please input your name:')
age = input('please input your age:')
job = input('please input your job:')
salary = input('please input your salary:')
msg = '''
------------info of {0}-----------
Name: {0}
Age: {1}
Job: {2}
Salary: {3}
'''.format(name,age,job,salary)
print (msg)
please input your name:chenronghuaformat是比较好的方式,有时候我们必须使用format方法,所以掌握了format就好。
please input your age:23
please input your job:OPS
please input your salary:50000
------------info of chenronghua-----------
Name: chenronghua
Age: 23
Job: OPS
Salary: 50000
流程控制
一、流程控制这里先介绍 if ...... else and if ...... elif ..... else
1、if ..... else(用户认证登录)
Code:
#!/usr/bin/env python3.5Result:
#auther: lucky.chen
name = input("Please input your name:")
passwd = input("Please input your password:")
if name == "crh" and passwd == "123456":
print (" \033[32mWelcome login OPS Management platform\033[0m ")
else:
print ("\033[31mYour UserName or Password Error\033[0m")
Please input your name:crh
Please input your password:34
Your UserName or Password Error
2、if ..... elfi ...... else
Code:
#!/usr/bin/env python3.5Result:
#auther: lucky.chen
age = int(input("Pleast input your age:"))
if age < 18:
print (" \033[32m You're too young \033[0m ")
elif age > 18 and age < 30:
print ("\033[31m You still have many chance comes at a time when youth waiting for you \033[0m")
else:
print ("\033[33m Before you is too old to do \033[0m")
Pleast input your age:23
You still have many chance comes at a time when youth waiting for you
二、for 循环遍历
#!/usr/bin/env python3.5range函数也可以设置步长值,比如我们要打印出1-10中的所有偶数(默认步长为1)
#auther: lucky.chen
for num in range(5):
print ("loop is:",num)
# Result is:
loop is: 0
loop is: 1
loop is: 2
loop is: 3
loop is: 4
#!/usr/bin/env python3.5除掉range函数我们还可以使用xrange函数,为什么要这里要介绍xrange呢,因为xrange相对于range来说性能比较优越,因为xrange不需要一上来就开辟一块很大的内存空间,具体可以参考我之前发布的文章:Python中xrange和range的异同 ,但是好像Python3.*中没有了xrange函数。
#auther: lucky.chen
for num in range(0,11,2):
print ("loop is:",num)
# Result
loop is: 0
loop is: 2
loop is: 4
loop is: 6
loop is: 8
loop is: 10
for...else...循环介绍,不止if中有else,在for循环中也是可以用else的,在for循环中的else就是当前面的循环正常执行完后,没有跳出,后面的else代码将被执行。
crh:Python crh$ cat for.py
#!/usr/bin/env python3
#Auther: lucky.chen
for num in range(4):
print ("Loop is:",num)
else:
print ("normal")
crh:Python crh$ ./for.py
Loop is: 0
Loop is: 1
Loop is: 2
Loop is: 3
normal
crh:Python crh$
crh:Python crh$ cat for.py三、while循环遍历
#!/usr/bin/env python3
#Auther: lucky.chen
for num in range(4):
if num > 2:
break
print ("Loop is:",num)
else:
print ("normal")
crh:Python crh$ ./for.py
Loop is: 0
Loop is: 1
Loop is: 2
crh:Python crh$
while 循环它的原理是:当条件为真的时候运行,当条件为假的时候停止!没有一个规定次数,不设置条件就永远循环下去。
#!/usr/bin/env python3.5
#auther: lucky.chen
import time
count = 0
while True:
count +=1
print ("loop",count)
time.sleep(3)
#这个循环3秒钟自+1后,无线循环只要这个条件为”真“,就无限循环下去
#!/usr/bin/env python3.5While ...... else
#auther: lucky.chen
import time
num = 0
while num < 3:
num +=1
print ("Num is:",num)
time.sleep(3)
#这个循环每3秒循环一次,当条件num < 3的时候为真(自己设置的条件),当num不小于3的时候为假(false)循环停止.
#!/usr/bin/env python3.5
#auther: lucky.chen
while 1:
if num == 4:
print ("I think stop")
break
print (num)
num += 1
else:
print ("stop")
四、break和continue介绍
break在循环中的作用是跳出所在的循环体,不在进行循环,而continue是跳出所在循环体中的本次循环,后续没有完的循环继续。Code:
#!/usr/bin/env python3.5Result:
#auther: lucky.chen
num = 1
print ("test break for loop start")
for n in range(5):
if n == num:
break
print (n)
print ("\n")
print ("test continue for loop start")
for n in range(5):
if n == num:
continue
print (n)
test break for loop start
0
test continue for loop start
0
2
3
4
猜数字游戏:
#!/usr/bin/env python3.5Result:
#auther: lucky.chen
#load module (random)
import random
TryNum = 0
RandNum = random.randrange(10)
print (RandNum)
while TryNum < 3:
GuessNum = int(input("请猜测从0到9之间的一个中奖数字:"))
if GuessNum >= 10:
print ("你输入的数字不在中奖号码范围内,请重新输入!")
continue
if GuessNum == RandNum:
print ("恭喜你猜对了,你将获得小米电视一台!")
break
elif GuessNum > RandNum:
print ("你猜的数字太大了可以再往小了猜")
else:
print ("你猜的数字太小了可以往大了猜")
TryNum += 1
else:
print ("不好意思你三次机会用完了,Game over!")
#先随机到0-9中筛选出以为数字,然后用户三次机会猜测一个中奖号码,如果用户输入的数字不在范围内,则让用户再次输入.
4
请猜测从0到9之间的一个中奖数字:11
你输入的数字不在中奖号码范围内,请重新输入!
请猜测从0到9之间的一个中奖数字:11
你输入的数字不在中奖号码范围内,请重新输入!
请猜测从0到9之间的一个中奖数字:11
你输入的数字不在中奖号码范围内,请重新输入!
请猜测从0到9之间的一个中奖数字:11
你输入的数字不在中奖号码范围内,请重新输入!
请猜测从0到9之间的一个中奖数字:2
你猜的数字太小了可以往大了猜
请猜测从0到9之间的一个中奖数字:5
你猜的数字太大了可以再往小了猜
请猜测从0到9之间的一个中奖数字:4
恭喜你猜对了,你将获得小米电视一台!
五、嵌套循环
While for:
#!/usr/bin/env python3.5Result:
#auther: lucky.chen
count = 1
while count < 4:
print("count var lt 4")
print ("#########################[size=16]#")[/size]
for n in range(3):
print ("for num is:",n)
print ("****************************")
count += 1
count var lt 4
#########################[size=16]#[/size]
for num is: 0
for num is: 1
for num is: 2
****************************
count var lt 4
#########################[size=16]#[/size]
for num is: 0
for num is: 1
for num is: 2
****************************
count var lt 4
#########################[size=16]#[/size]
for num is: 0
for num is: 1
for num is: 2
****************************
死循环:
#!/usr/bin/env python3.5如上我们给出了一个死循环的例子,但是如果如果我们需要跳出循环应该怎么做,如果用break可以做到吗?
#auther: lucky.chen
import time
while True:
print ("One Loop")
time.sleep(1)
while True:
print ("Two Loop")
time.sleep(1)
while True:
print ("Three Loop")
time.sleep(1)
#这是一个死循环,第一次执行这段code的时候,依次往下执行,单到了第三个while的时候,就一直是true,所以一直在执行第三个while下的code.
#结果如下:
One Loop
Two Loop
Three Loop
Three Loop
Three Loop
Three Loop
..........
..........
1、第一个while后加break分析

2、第二个while后加break分析

3、第三个while后加break分析

既然存在这种死循环的那我们有什么办法可以跳出呢?那就是打标志,标志位
Code:
#!/usr/bin/env python3.5分析和结果:
#auther: lucky.chen
count = 0
while True:
print ("我是第一层")
jump_1_flag = False
while True:
print ("我是第二层")
jump_2_flag = False
while True:
count += 1
print ("我是第三层")
if count > 3:
jump_2_flag = True
break
if jump_2_flag:
print ("第三层跳到我这里来了,我也要跳到第一层")
jump_1_flag = True
break
if jump_1_flag:
print ("第二层和第三层跳到第一层了,我也要跳")
break

Python input和raw_input的区别
编程 空心菜 发表了文章 1 个评论 4341 次浏览 2015-12-14 23:18
纯数字输入
当输入为纯数字时
- []input返回的是数值类型,如int,float[/][]raw_inpout返回的是字符串类型,string类型[/]

输入字符串为表达式
input会计算在字符串中的数字表达式,而raw_input不会。
如输入 "57 + 3":
input会得到整数60
raw_input会得到字符串"57 + 3"

输入字符串结果如下:

通过上面的实验我们知道input它会根据用户输入变换相应的类型,而且如果要输入字符和字符串的时候必须要用引号包起来,而raw_input则是不管用户输入什么类型的都会转变成字符型.
python input的实现
看python input的文档,你可以发现input其实是通过raw_input来实现的,原理很简单,就下面一行代码:
def input(prompt):
return (eval(raw_input(prompt)))
为什么越来越多人喜欢全栈式开发语言 – Python
编程 push 发表了文章 1 个评论 6040 次浏览 2015-11-29 20:12

前段时间,ThoughtWorks在深圳举办一次社区活动上,有一个演讲主题叫做“Fullstack JavaScript”,是关于用JavaScript进行前端、服务器端,甚至数据库(MongoDB)开发,一个Web应用开发人员,只需要学会一门语言,就可以实现整个应用。
受此启发,我发现Python可以称为大数据全栈式开发语言。因为Python在云基础设施,DevOps,大数据处理等领域都是炙手可热的语言。

就像只要会JavaScript就可以写出完整的Web应用,只要会Python,就可以实现一个完整的大数据处理平台。
云基础设施
这年头,不支持云平台,不支持海量数据,不支持动态伸缩,根本不敢说自己是做大数据的,顶多也就敢跟人说是做商业智能(BI)。
云平台分为私有云和公有云。私有云平台如日中天的OpenStack,就是Python写的。曾经的追赶者CloudStack,在刚推出时大肆强调自己是Java写的,比Python有优势。结果,搬石砸脚,2015年初,CloudStack的发起人Citrix宣布加入OpenStack基金会,CloudStack眼看着就要寿终正寝。
如果嫌麻烦不想自己搭建私有云,用公有云,不论是AWS,GCE,Azure,还是阿里云,青云,在都提供了Python SDK,其中GCE只提供Python和JavaScript的SDK,而青云只提供Python SDK。可见各家云平台对Python的重视。
提到基础设施搭建,不得不提Hadoop,在今天,Hadoop因为其MapReduce数据处理速度不够快,已经不再作为大数据处理的首选,但是HDFS和Yarn——Hadoop的两个组件——倒是越来越受欢迎。Hadoop的开发语言是Java,没有官方提供Python支持,不过有很多第三方库封装了Hadoop的API接口(pydoop,hadoopy等等)。
Hadoop MapReduce的替代者,是号称快上100倍的Spark,其开发语言是Scala,但是提供了Scala,Java,Python的开发接口,想要讨好那么多用Python开发的数据科学家,不支持Python,真是说不过去。HDFS的替代品,比如GlusterFS,Ceph等,都是直接提供Python支持。Yarn的替代者,Mesos是C++实现,除C++外,提供了Java和Python的支持包。
DevOps
DevOps有个中文名字,叫做开发自运维。互联网时代,只有能够快速试验新想法,并在第一时间,安全、可靠的交付业务价值,才能保持竞争力。DevOps推崇的自动化构建/测试/部署,以及系统度量等技术实践,是互联网时代必不可少的。
自动化构建是因应用而易的,如果是Python应用,因为有setuptools, pip, virtualenv, tox, flake8等工具的存在,自动化构建非常简单。而且,因为几乎所有Linux系统都内置Python解释器,所以用Python做自动化,不需要系统预安装什么软件。
自动化测试方面,基于Python的Robot Framework企业级应用最喜欢的自动化测试框架,而且和语言无关。Cucumber也有很多支持者,Python对应的Lettuce可以做到完全一样的事情。Locust在自动化性能测试方面也开始受到越来越多的关注。
自动化配置管理工具,老牌的如Chef和Puppet,是Ruby开发,目前仍保持着强劲的势头。不过,新生代Ansible和SaltStack——均为Python开发——因为较前两者设计更为轻量化,受到越来越多开发这的欢迎,已经开始给前辈们制造了不少的压力。
在系统监控与度量方面,传统的Nagios逐渐没落,新贵如Sensu大受好评,云服务形式的New Relic已经成为创业公司的标配,这些都不是直接通过Python实现的,不过Python要接入这些工具,并不困难。
除了上述这些工具,基于Python,提供完整DevOps功能的PaaS平台,如Cloudify和Deis,虽未成气候,但已经得到大量关注。
网络爬虫
大数据的数据从哪里来?除了部分企业有能力自己产生大量的数据,大部分时候,是需要靠爬虫来抓取互联网数据来做分析。
网络爬虫是Python的传统强势领域,最流行的爬虫框架Scrapy,HTTP工具包urlib2,HTML解析工具beautifulsoup,XML解析器lxml,等等,都是能够独当一面的类库。
不过,网络爬虫并不仅仅是打开网页,解析HTML这么简单。高效的爬虫要能够支持大量灵活的并发操作,常常要能够同时几千甚至上万个网页同时抓取,传统的线程池方式资源浪费比较大,线程数上千之后系统资源基本上就全浪费在线程调度上了。Python由于能够很好的支持协程(Coroutine)操作,基于此发展起来很多并发库,如Gevent,Eventlet,还有Celery之类的分布式任务框架。被认为是比AMQP更高效的ZeroMQ也是最早就提供了Python版本。有了对高并发的支持,网络爬虫才真正可以达到大数据规模。
抓取下来的数据,需要做分词处理,Python在这方面也不逊色,著名的自然语言处理程序包NLTK,还有专门做中文分词的Jieba,都是做分词的利器。
数据处理
万事俱备,只欠东风。这东风,就是数据处理算法。从统计理论,到数据挖掘,机器学习,再到最近几年提出来的深度学习理论,数据科学正处于百花齐放的时代。数据科学家们都用什么编程?
如果是在理论研究领域,R语言也许是最受数据科学家欢迎的,但是R语言的问题也很明显,因为是统计学家们创建了R语言,所以其语法略显怪异。而且R语言要想实现大规模分布式系统,还需要很长一段时间的工程之路要走。所以很多公司使用R语言做原型试验,算法确定之后,再翻译成工程语言。
Python也是数据科学家最喜欢的语言之一。和R语言不同,Python本身就是一门工程性语言,数据科学家用Python实现的算法,可以直接用在产品中,这对于大数据初创公司节省成本是非常有帮助的。正式因为数据科学家对Python和R的热爱,Spark为了讨好数据科学家,对这两种语言提供了非常好的支持。
Python的数据处理相关类库非常多。高性能的科学计算类库NumPy和SciPy,给其他高级算法打了非常好的基础,matploglib让Python画图变得像Matlab一样简单。Scikit-learn和Milk实现了很多机器学习算法,基于这两个库实现的Pylearn2,是深度学习领域的重要成员。Theano利用GPU加速,实现了高性能数学符号计算和多维矩阵计算。当然,还有Pandas,一个在工程领域已经广泛使用的大数据处理类库,其DataFrame的设计借鉴自R语言,后来又启发了Spark项目实现了类似机制。
对了,还有iPython,这个工具如此有用,以至于我差点把他当成标准库而忘了介绍。iPython是一个交互式Python运行环境,能够实时看到每一段Python代码的结果。默认情况下,iPython运行在命令行,可以执行ipython notebook在网页中运行。用matplotlib绘制的图可以直接嵌入式的显示在iPython Notebook中。
iPython Notebook的笔记本文件可以共享给其他人,这样其他人就可以在自己的环境中重现你的工作成果;如果对方没有运行环境,还可以直接转换成HTML或者PDF。

为什么是Python
正是因为应用开发工程师、运维工程师、数据科学家都喜欢Python,才使得Python成为大数据系统的全栈式开发语言。
对于开发工程师而言,Python的优雅和简洁无疑是最大的吸引力,在Python交互式环境中,执行import this,读一读Python之禅,你就明白Python为什么如此吸引人。Python社区一直非常有活力,和NodeJS社区软件包爆炸式增长不同,Python的软件包增长速度一直比较稳定,同时软件包的质量也相对较高。有很多人诟病Python对于空格的要求过于苛刻,但正是因为这个要求,才使得Python在做大型项目时比其他语言有优势。OpenStack项目总共超过200万行代码,证明了这一点。
对于运维工程师而言,Python的最大优势在于,几乎所有Linux发行版都内置了Python解释器。Shell虽然功能强大,但毕竟语法不够优雅,写比较复杂的任务会很痛苦。用Python替代Shell,做一些复杂的任务,对运维人员来说,是一次解放。
对于数据科学家而言,Python简单又不失强大。和C/C++相比,不用做很多的底层工作,可以快速进行模型验证;和Java相比,Python语法简洁,表达能力强,同样的工作只需要1/3代码;和Matlab,Octave相比,Python的工程成熟度更高。不止一个编程大牛表达过,Python是最适合作为大学计算机科学编程课程使用的语言——MIT的计算机入门课程就是使用的Python——因为Python能够让人学到编程最重要的东西——如何解决问题。
顺便提一句,微软参加2015年PyCon,高调宣布提高Python在Windows上的编程体验,包括Visual Studio支持Python,优化Python的C扩展在Windows上的编译等等。脑补下未来Python作为Windows默认组件的场景。
内容来源:ThoughtWorks洞见
分享阅读:http://insights.thoughtworkers.org/full-stack-python/
Python的发展趋势
编程 空心菜 发表了文章 0 个评论 2977 次浏览 2021-08-08 21:47
一、Python发展历史
Python是一种计算机程序设计语言。你可能在之前听说过很多编程语言,比如难学的C语言(语法和实现难度),非常流行的JAVA语言(尤其是现在分布式存储和服务),非常有争议的PHP(常见 WordPress 大多网站),前端HTML、JavaScripts、Node.JS、还有最近随着容器风行的Golang等等。那Python是What?
- 1989年,Python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
- 1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
- 1992年,Python之父发布了Python的web框架Zope1.
- Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
- Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
- Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
- Python 2.5 - September 19, 2006
- Python 2.6 - October 1, 2008
- Python 2.7 - July 3, 2010
- In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to Python 3.4+ as soon as possible
- Python 3.0 - December 3, 2008
- Python 3.1 - June 27, 2009
- Python 3.2 - February 20, 2011
- Python 3.3 - September 29, 2012
- Python 3.4 - March 16, 2014
- Python 3.5 - September 13, 2015
最新参考:https://www.python.org/downloads/release
二、Python的前景
最新的TIOBE( https://www.tiobe.com/tiobe-index/ )排行榜,Python赶超JAVA占据第二名了, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。
我们看看17年Python的排名:
由上图17年预测可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到大家的认知和认可,影响度也越来越大,在国内Python开发招聘的岗位也越来越多,我们来看看2017年100offer统计情况:
从上图我们可以看出Python的人均面邀数为6,整体年薪在34w左右,在职位招聘排行榜前十名,应该还算不错的表现哦。
三、Python的应用领域
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。
目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、阿里、百度、腾讯、汽车之家、美团等。
目前Python主要的应用领域
云计算: 在云计算领域Python可谓有一席之地, 典型应用OpenStack这个大体量的开源云计算产品就是居于Python开发的。
WEB开发: 已有众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣, 知乎等…., Python也有许多Web开发框架,典型WEB框架有Django、Pylons,还有Tornado、Bottle、Flask等。
系统运维: 从国内的趋势来看,掌握一门编程语言已经成为了必然的结果,Python在国内已经成为了首选,不管是做自动化运维还是业务运维现在Python在运维领域已经应用极广。
金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
图形GUI: PyQT, WxPython, TkInter, PySide等在图形用户接口领域都有广泛被应用。
哪些公司在用Python
谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发。
CIA: 美国中情局网站就是用Python开发的。
NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算。
YouTube:世界上最大的视频网站YouTube就是用Python开发的。
Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载。
Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发。
Facebook:大量的基础库均通过Python实现的
Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
豆瓣: 公司几乎所有的业务均是通过Python开发完成的。
知乎: 国内最大的问答社区,通过Python开发(国外Quora)
春雨医生:国内知名的在线医疗网站是用Python开发的
除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务, 互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
为什么是Python而不是其他语言呢?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python和C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
Python和PHP相比
Python提供了丰富的数据结构,非常容易和c集成。相比较而言,php集中专注在web上。 php大多只提供了系统api的简单封装,但是python标准包却直接提供了很多实用的工具。python的适用性更为广泛,php在web更加专业,php的简单数据类型,完全是为web量身定做。
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。语言是死的,每个语言的诞生都有它的道理,所以选择你喜欢的,开心的玩起来。
Pyhton列表去重方法总结
编程 Ansible 发表了文章 0 个评论 1549 次浏览 2020-11-02 00:22
Python列表去重在Python应用编程中,是一种非常常见的应用技巧,有些场景下需要统计出来的列表中去重,避免重复统计。
1. 通过字典去重
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = {}.fromkeys(job).keys()
print(list(jobs))
结果:
['Sale', 'Dev', 'OPS', 'Presale', 'Test']
解释:
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
语法:
dict.fromkeys(seq[, value])
- seq - 字典键值列表。
- value - 可选参数, 设置键序列(seq)的值。
该方法返回一个新字典, .keys 函数以列表返回一个字典所有的键。
2. 通过集合去重
大家都知道在Python数据结构中集合是天生去重的,所以我们可以利用这一特性来达到列表去重的效果。
格式: list(set(mylist))
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = list(set(job))
由于采用集合,会导致原有的列表排序发生变化,此时可通过如下方法,保持列表原有顺序:
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = list(set(job))
jobs.sort(key=job.index)
3. 使用itertools模块
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
import itertools
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
job.sort()
job_group = itertools.groupby(job)
jobs = []
for k, g in job_group:
jobs.append(k)
print(jobs)
groupby 根据key(v)值分组的迭代器, 将key函数作用于原循环器的各个元素。根据key函数结果,将拥有相同函数结果的元素分到一个新的循环器。每个新的循环器以函数返回结果为标签。
4. 通过列表推导式去重
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = []
[ jobs.append(i) for i in job if i not in jobs]
通过列表推导式,判断在不在新列表中的元素则添加到新列表中。
5. 利用lambda匿名函数和 reduce 函数处理
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
from functools import reduce
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
func = lambda x,y:x if y in x else x + [y]
jobs = reduce(func, [[], ] + job)
Python下判断文件是否为二进制文件的三种方法
编程 OpenSkill 发表了文章 0 个评论 5343 次浏览 2020-09-18 18:27
常用的有两种方法判断文件是否为二进制文件,最准确的就是把这两种方法结合起来更加准确点.
方法1利用codecs模块
它首先检查文件是否以BOM开始,如果不在初始8192字节内查找零字节:
import codecs
file_path = "/home/ubuntu/zgd/ztest/_gs418_510txp_v6.6.2.7.stk.extracted/test"
#: BOMs to indicate that a file is a text file even if it contains zero bytes.
_TEXT_BOMS = (
codecs.BOM_UTF16_BE,
codecs.BOM_UTF16_LE,
codecs.BOM_UTF32_BE,
codecs.BOM_UTF32_LE,
codecs.BOM_UTF8,
)
def is_binary_file(file_path):
with open(file_path, 'rb') as file:
initial_bytes = file.read(8192)
file.close()
return not any(initial_bytes.startswith(bom) for bom in _TEXT_BOMS) and b'\0' in initial_bytes
if __name__ == "__main__":
print is_binary_file(file_path)
上面is_binary_file()函数也可以改成下面的方式:
def is_binary_file(file_path):
with open(file_path, 'rb') as file:
initial_bytes = file.read(8192)
file.close()
for bom in _TEXT_BOMS:
if initial_bytes.startswith(bom):
continue
else:
if b'\0' in initial_bytes:
return True
return False
方法2利用magic模块
安装模块: pip install python-magic
def getFileType(ff):
mime_kw = 'x-executable|x-sharedlib|octet-stream|x-object' ###可执行文件、链接库、动态流、对象
try:
magic_mime = magic.from_file(ff, mime=True)
magic_hit = re.search(mime_kw, magic_mime, re.I)
if magic_hit:
return True
else:
return False
except Exception, e:
print e.message
最好的方法是对两种类型同时进行处理:
# -*- coding:utf-8 -*-
# @Author:zgd
# @time:2019/6/21
# @File:operateSystem.py
import magic
import re
import codecs
def is_binary_file_1(ff):
'''
根据text文件数据类型判断是否是二进制文件
:param ff: 文件名(含路径)
:return: True或False,返回是否是二进制文件
'''
TEXT_BOMS = (
codecs.BOM_UTF16_BE,
codecs.BOM_UTF16_LE,
codecs.BOM_UTF32_BE,
codecs.BOM_UTF32_LE,
codecs.BOM_UTF8,
)
with open(file_path, 'rb') as file:
CHUNKSIZE = 8192
initial_bytes = file.read(CHUNKSIZE)
file.close()
#: BOMs to indicate that a file is a text file even if it contains zero bytes.
return not any(initial_bytes.startswith(bom) for bom in TEXT_BOMS) and b'\0' in initial_bytes
def is_binwary_file_2(ff):
'''
根据magic文件的魔术判断是否是二进制文件
:param ff: 文件名(含路径)
:return: True或False,返回是否是二进制文件
'''
mime_kw = 'x-executable|x-sharedlib|octet-stream|x-object' ###可执行文件、链接库、动态流、对象
try:
magic_mime = magic.from_file(ff, mime=True)
magic_hit = re.search(mime_kw, magic_mime, re.I)
if magic_hit:
return True
else:
return False
except Exception, e:
return False
if __name__ == "__main__":
file_path = "/home/ubuntu/zgd/ztest/_gs418_510txp_v6.6.2.7.stk.extracted/D0"
print is_binary_file_1(file_path)
print is_binwary_file_2(file_path)
print any((is_binary_file_1(file_path), is_binwary_file_2(file_path)))
方法3判断是否有ELF头
根据文件中是否有ELF头进行判断文件是否为二进制文件
# 判断文件是否是elf文件
def is_ELFfile(filepath):
if not os.path.exists(filepath):
logger.info('file path {} doesnot exits'.format(filepath))
return False
# 文件可能被损坏,捕捉异常
try:
FileStates = os.stat(filepath)
FileMode = FileStates[stat.ST_MODE]
if not stat.S_ISREG(FileMode) or stat.S_ISLNK(FileMode): # 如果文件既不是普通文件也不是链接文件
return False
with open(filepath, 'rb') as f:
header = (bytearray(f.read(4))[1:4]).decode(encoding="utf-8")
# logger.info("header is {}".format(header))
if header in ["ELF"]:
# print header
return True
except UnicodeDecodeError as e:
# logger.info("is_ELFfile UnicodeDecodeError {}".format(filepath))
# logger.info(str(e))
pass
return False
分享Python基础入门到精通视频教程5套
编程 alber1986 发表了文章 0 个评论 3370 次浏览 2017-12-16 11:32
分享Python基础入门到精通视频教程5套:
第一套:Python14期VIP视频
第二套 python全栈开发工程师1期
第三套 2017年老男孩全栈第二期103天完整
第四套 Python视频课程就业班
第五套 Python自动化开发12期完整版
http://www.sucaihuo.com/video/194.html
Python操作各种数据库
编程 空心菜 发表了文章 1 个评论 3264 次浏览 2017-04-27 17:54
一、操作mysql
python3中操作mysql数据需要安装一个第三方模块,pymysql,使用pip install pymysql安装即可,在python2中是MySQLdb模块,在python3中没有MySQLdb模块了,所以使用pymysql。
import pymysql上面的操作,获取到的返回结果都是元组,如果想获取到的结果是一个字典类型的话,可以使用下面这样的操作
# 创建连接,指定数据库的ip地址,账号、密码、端口号、要操作的数据库、字符集
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='data',charset='utf8')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
effect_row = cursor.execute("update students set name = 'niuhy' where id = 1;")
# 执行SQL,并返回受影响行数
#effect_row = cursor.execute("update students set name = 'niuhy' where id = %s;", (1,))
# 执行SQL,并返回受影响行数
effect_row = cursor.executemany("insert into students (name,age) values (%s,%s); ", [("hangyang",18),("12345",20)])
#执行select语句
cursor.execute("select * from students;")
#获取查询结果的第一条数据,返回的是一个元组
row_1 = cursor.fetchone()
# 获取前n行数据
row_2 = cursor.fetchmany(3)
# 获取所有数据
row_3 = cursor.fetchall()
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 获取最新自增ID
new_id = cursor.lastrowid
print(new_id)
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
import pymysql
# 创建连接,指定数据库的ip地址,账号、密码、端口号、要操作的数据库、字符集
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='data',charset='utf8')
# 创建游标
cursor = conn.cursor()
cursor = coon.cursor(cursor=pymysql.cursors.DictCursor)#需要指定游标的类型,字典类型
# 执行SQL
cursor.execute("select * from user;")
#获取返回结果,这个时候返回结果是一个字典
res = cursor.fetchone()#返回一条数据,如果结果是多条的话
print(res)
res2 = cursor.fetchall()#所有的数据一起返回
二、操作redis
redis是一个nosql类型的数据库,数据都存在内存中,有很快的读写速度,python操作redis使用redis模块,pip安装即可
import redis
r = redis.Redis(host='127.0.0.1',port=6379,db=0)#指定连接redis的端口和ip以及哪个数据库
r.set('name', 'value')#set string类型的值
r.setnx('name2', 'value')#设置的name的值,如果name不存在的时候才会设置
r.setex('name3', 'value', 3)#设置的name的值,和超时时间,过了时间key就会自动失效
r.mset(k1='v1',k2='v2')#批量设置值
r.get('name')#获取值
print(r.mget('k1','k2'))#批量获取key
r.delete('name')#删除值
r.delete('k1','k2')#批量删除
#======下面是操作哈希类型的
r.hset('hname', 'key', 'value')#set 哈希类型的值
r.hset('hname', 'key1', 'value2')#set 哈希类型的值
r.hsetnx('hname','key2','value23')#给name为hname设置key和value,和上面的不同的是key不存在的时候
#才会set
r.hmset('hname',{'k1':'v1','k2':'v2'})#批量设置哈希类型的key和value
r.hget('name', 'key')#获取哈希类型的值
print(r.hgetall('hname'))#获取这个name里所有的key和value
r.hdel('hname','key')#删除哈希类型的name里面指定的值
print(r.keys())#获取所有的key
三、操作mongodb
mongodb和redis一样,也是一个nosql类型的数据库,它和redis的区别是,redis把整个数据都放在内存,而mongodb是把数据放在磁盘上的。 python操作mongodb使用pymongo模块,pip安装即可,操作如下:
import pymongo分享转载原文:牛牛杂货铺。
conn = pymongo.MongoClient(host='211.149.218.16',port=27017)#连接mongodb
db = conn.szz#选择哪个数据库
db.authenticate('admin','123456')#如果有账号密码的话,指定账号密码
collection = db.stus#使用数据库里面哪个集合,就相当于mysql里面的表
collection.drop()#删除指定的集合,也就是删除这个表
stu={
'name':'牛牛',
'age':38,
'sex':'男'
}
stus = [
{'name':'python',
'addr':'北京',
'sex':'未知',
'age':38
},
{
'name':'mongodb',
'addr':'USA',
'money':18.01,
'age':20
}
]
collection.save(stu)#插入单条数据
collection.insert(stus)#插入单条和多条,如果是多条的话,传入的就是一个list
=====比较操作符=======
# $lt
# 小于
# $lte
# 小于等于
# $gt
# 大于
# $gte
# 大于等于
# $ne
# 不等于
$set 获取前面的结果集
collection.update({'name':'牛牛'},{'name':'niuhy','age':20})#更新数据
collection.update({'name':'牛牛'},{'$set':{'addr':'河南'}})#在原来数据的基础上修改
collection.update({'name':'牛牛'},
{'$set':{'addr':'河南'}},
multi=True)#multi参数的作用是如果有多个结果的话,是否全部修改
collection.remove({'name':'牛牛'})#删除指定的数据,如果不传入参数,删除的是全部的数据
collection.remove()#删除全部数据
data = collection.find({'name':'mongodb'})#查询指定的数据
all_data = collection.find()#不写参数就是查询所有的数据
my_data = collection.find({'age':{'$gte':18}})#查询大于18岁的
for d in my_data:#获取数据,所有查询数据都需要使用循环来获取
print(d)#每个元素都是一个字典
Python字符串反转方法小记
编程 空心菜 发表了文章 1 个评论 3213 次浏览 2017-04-09 15:29
No.1 切片方式
字符串的切片跟列表是一样的,主要是利用切片的扩展语法-1来实现
def rev1(cont):切片详细语法查看:https://docs.python.org/2/whatsnew/2.3.html#extended-slices
return cont[::-1]
No.2 列表reverse实现
利用列表的reverse()方法这个特性,可以先将字符串转换成列表,利用reverse()方法进行反转后,再处理成字符串。
def rev2(cont):
result = list(cont)
result.reverse()
return ''.join(result)
No.3 内置函数reversed实现
def rev3(cont):
return ''.join(reversed(cont))
No.4 递归方法
def rev4(cont):
if cont == "":
return cont
else:
return rev4(cont[1:])+cont[0]
# 在Python 3里,reduce()内置函数已经被从全局名字空间里移除了,它现在被放置在fucntools模块里
from functools import reduce
def rev5(cont):
return reduce(lambda x, y : y + x, cont)
No.5 字符串拼接
def rev6(cont):
new_string = ''
index = len(cont)
while index:
index -= 1 # index = index - 1
new_string += cont[index] # new_string = new_string + character
return new_string
def rev7(cont):
new_strings =
index = len(cont)
while index:
index -= 1
new_strings.append(cont[index])
return ''.join(new_strings)
如上几种方法效率比较:
#!/usr/bin/env python3时间结果如下:
# Author: nock
from functools import reduce
import timeit
cont = 'kcon' * 20
def rev1(cont):
return cont[::-1]
def rev2(cont):
result = list(cont)
result.reverse()
return ''.join(result)
def rev3(cont):
return ''.join(reversed(cont))
def rev4(cont):
if cont == "":
return cont
else:
return rev4(cont[1:])+cont[0]
def rev5(cont):
return reduce(lambda x, y : y + x, cont)
def rev6(cont):
new_string = ''
index = len(cont)
while index:
index -= 1 # index = index - 1
new_string += cont[index] # new_string = new_string + character
return new_string
def rev7(cont):
new_strings =
index = len(cont)
while index:
index -= 1
new_strings.append(cont[index])
return ''.join(new_strings)
if __name__ == '__main__':
print("rev1 run time is: %s" % min(timeit.repeat(lambda: rev1(cont))))
print("rev2 run time is: %s" % min(timeit.repeat(lambda: rev2(cont))))
print("rev3 run time is: %s" % min(timeit.repeat(lambda: rev3(cont))))
print("rev4 run time is: %s" % min(timeit.repeat(lambda: rev4(cont))))
print("rev5 run time is: %s" % min(timeit.repeat(lambda: rev5(cont))))
print("rev6 run time is: %s" % min(timeit.repeat(lambda: rev6(cont))))
print("rev7 run time is: %s" % min(timeit.repeat(lambda: rev7(cont))))
rev1 run time is: 0.45436444599181414所以如上可以看出,还是用切片的方法最好,所以记住切片步长为-1就可反转就好。
rev2 run time is: 2.3974227079888806
rev3 run time is: 2.633627591014374
rev4 run time is: 3.0160443240310997
rev5 run time is: 16.342944753996562
rev6 run time is: 12.666344199969899
rev7 run time is: 14.762871471000835
Python生成器解析式和Zip函数介绍
编程 空心菜 发表了文章 0 个评论 3256 次浏览 2017-03-23 17:31
生成器解析式
对列表解析来说,只需要简单的把中括号换成小括号就可以了,生成器解析式是按需计算的或者说延迟计算的或者叫惰性求值。
#!/usr/bin/env python3
# Author: nock
def inc(x):
print('inc {0}'.format(x))
return x + 1
# 生成一个迭代器对象
obj = (inc(x) for x in range(10))
print(obj)
Result:
at 0x107d87678>
#!/usr/bin/env python3Result:
# Author: nock
# 生成一个迭代器对象
obj = (x for x in range(10))
l = [x for x in range(10)]
print(next(obj))
print(next(obj))
print(next(obj))
print(l[4])
try:
print(obj[1])
except Exception as e:
print("Exception is: {0}".format(e))
print(next(obj))
0生成器无下标获取。
1
2
4
Exception is: 'generator' object is not subscriptable
3
Zip

zip 函数用于合并多个可迭代对象,合并后的长度等于最短的可迭代对象的长度
解锁Python集合推导式和字典推导式
编程 空心菜 发表了文章 0 个评论 3698 次浏览 2017-03-19 22:23
集合推导式
集合推导式(set comprehensions)跟列表推导式也是类似的, 唯一的区别在于它们使用大括号{}表示。
Code:
sets = {x for x in range(10)}
Result:
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}

集合解析把列表解析中的中括号变成大括号,返回集合。
下面我们来个应用场景,一直一个列表中有很多元素,我们做到快速去重。
Code:集合推导式生成内容,结果要是可hash的:
heavy = {x for x in [2, 3, 5, 3, 5, 2, 6]}
print(heavy)
Result:
{2, 3, 5, 6}

字典推导式
字典推导式(dict comprehensions)和列表推导的使用方法也是类似的。

字典解析也是使用大括号包围,并且需要两个表达式,一个生成key, 一个生成value 两个表达式之间使用冒号分割,返回结果是字典.
说了这么多推导式,为什么没有元组推导式呢,元组和列表的操作几乎是一样的,除了不可变特性以外
Code:
tuple([x for x in range(10)])
Result:
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
Python使用类来写装饰器
编程 空心菜 发表了文章 0 个评论 2465 次浏览 2017-03-19 17:37
示例代码如下:
class Foo:运行结果:
def __call__(self, *args, **kwargs):
print('call....')
def test(self):#
print('test....')
if __name__ == '__main__':
t = Foo()#实例化类
t.test()#正常调用实例方法
t()#直接调用实例化之后的对象
>>>test.... #这个是调用test方法的时候输出的理解了上面的之后,就可以使用class来写一个装饰器了,计算程序的运行时间,当然思想和以前用函数写装饰器是一样的
>>>call....#这个是执行调用这个实例化之后的方法输出的
class Fuck(object):运行结果:
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
import time
start_time = time.time()
res = self.func(*args, **kwargs)
end_time = time.time()
print('the function "%s" run time is %s' % (self.func.__name__,
(end_time - start_time)))
return res
@Fuck
def run(name):
import time
time.sleep(1)
return 'sb_%s' % name
print(run('hyf'))
>>>the function "run" run time is 1.0001001358032227#这个是装饰器帮我们计算的函数运行时间原文地址:http://www.nnzhp.cn/blog/2017/01/16/1/
>>>sb_hyf#这个是正常运行run函数的时候,返回的值
解锁Python列表推导式
编程 空心菜 发表了文章 0 个评论 2787 次浏览 2017-03-18 00:28
列表推导式
定义:
列表推导式(又称列表解析式)提供了一种简明扼要的方法来创建列表。
它的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是0个或多个for或者if语句。那个表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以if和for语句为上下文的表达式运行完成之后产生。
列表解析的一般形式:
[expr for item in itratorable]Code: [2 ** n for n in range(10)]
Result: [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]

列表解析返回的是列表, 列表的内容是表达式执行的结果.
[expr for item in iterable if cond]
[x ** 0.5 for x in range(10) if x % 2 == 0]
[0.0, 1.4142135623730951, 2.0, 2.449489742783178, 2.8284271247461903]
[expr for item in iterable if cond1 if cond2]
[x for x in range(10) if x % 2 == 0 if x > 1]
[2, 4, 6, 8]
[expr for item1 in iterable1 for item2 in iterable2]
[(x, y) for x in range(10) for y in range(10) if (x+y) %2 == 0]


列表解析用于对可迭代对象做过滤和转换,返回值是列表.
特性一:代码变短,可读性更好

从上图代码示例中我们明显可以看出,列表推导式相比常规方法,写出来的代码更加符合pythonic,更加简短,可读性更好。
有些人甚至更喜欢使用它而不是filter函数生成列表,但是当你使用列表推导式效果会更加,列表推导式在有些情况下超赞,特别是当你需要使用for循环来生成一个新列表.
特征二:推导式速度更快
#!/usr/bin/env python3结果:
# author: nock
import timeit
lst = list(range(10))
# 常规方法
def origin(lst):
plus_one = []
for i in lst:
plus_one.append(i + 1)
return plus_one
# 列表推导式
def fast(lst):
return [ x + 1 for x in lst ]
otime = timeit.timeit('origin(range(10))', globals=globals())
print("func origin exec time is {0}".format(otime))
ftime = timeit.timeit('fast(range(10))', globals=globals())
print("func origin exec time is {0}".format(ftime))
func origin exec time is 2.1059355960023822
func origin exec time is 1.6507169340038672
如果你使用map或者filter结合lambda生成列表,也是没有列表推导式速度快的,有兴趣的可以自己Coding一下。

