

DevOps
什么是CICD
运维 OS小编 发表了文章 0 个评论 2428 次浏览 2021-05-15 15:27

传统的应用发布模式

如果你经历体验过传统的应用发布,你可能就会觉得CICD有足够吸引你的地方,反之亦然。一般一个研发体系中都会存在多个角色:开发、测试、运维。当时我们的应用发布模式可以能是这样的:
- 开发团队在开发环境中完成软件开发,单元测试,测试通过,提交到代码版本管理库;
- 开发同学通知运维同学项目可以发布了,然后运维同学下载代码进行打包和构建,生成应用制品;
- 运维同学使用部署脚本将生成的制品部署到测试环境,并提示测试同学可以进行产品的测试;
- 测试同学开始进行手动、自动化测试,测试完成后提醒运维同学可以进行预生产环境部署;
- 运维同学开始进行预生产环境部署,然后测试同学进行测试,测试完成后,开始部署生产环境。
当然我描述的可能只是其中的一部分,手动操作很多、出现的问题很多。上面看似很流畅的过程,其实每次构建或发布都可能会出现问题。未对每次提交验证、构建环境不一致:开发人员本地测试成功后提交代码,运维同学下载代码进行编译却出现了错误。
存在的问题:
- 错误发现不及时: 很多错误在项目的早期可能就存在,到最后集成的时候才发现问题;
- 人工低级错误发生: 产品和服务交付中的关键活动全都需要手动操作;
- 团队工作效率低: 需要等待他人的工作完成后才能进行自己的工作;
- 开发运维对立: 开发人员想要快速更新,运维人员追求稳定,各自的针对的方向不同。
经过上述问题我们需要作出改变,如何改变?
什么是CICD

软件开发的连续方法基于自动执行脚本,以最大程度地减少在开发应用程序时引入错误的机会。从开发新代码到部署新代码,他们几乎不需要人工干预,甚至根本不需要干预。
它涉及到在每次小的迭代中就不断地构建,测试和部署代码更改,从而减少了基于错误或失败的先前版本开发新代码的机会。
此方法有三种主要方法,每种方法都将根据最适合您的策略的方式进行应用。
持续集成 CI(Continuous Integration)

在传统软件开发过程中,集成通常发生在每个人都完成了各自的工作之后。在项目尾声阶段,通常集成还要痛苦的花费数周或者数月的时间来完成。持续集成是一个将集成提前至开发周期的早期阶段的实践方式,让构建、测试和集成代码更经常反复地发生。
开发人员通常使用一种叫做CI Server的工具来做构建和集成。持续集成要求史蒂夫和安妮能够自测代码。分别测试各自代码来保证它能够正常工作,这些测试通常被称为单元测试(Unit tests)。
代码集成以后,当所有的单元测试通过,史蒂夫和安妮就得到了一个绿色构建(Green Build)。这表明他们已经成功地集成在一起,代码正按照测试预期地在工作。然而,尽管集成代码能够成功地一起工作了,它仍未为生产做好准备,因为它没有在类似生产的环境中测试和工作。
CI是需要对开发人员每次的代码提交进行构建测试验证。确定每次提交的代码都是可以正常编译测试通过的。在没有持续集成服务器的时候,我们可以写一个程序来监听版本控制系统的状态,当出现了push动作则触发相应的脚本运行编译构建等步骤。现在有了专业的持续集成服务器后,我们借助持续集成服务器来实现版本控制系统中代码提交触发构建测试等验证步骤。
持续合并开发人员正在开发编写的所有代码的一种做法。通常一天内进行多次合并和提交代码,从存储库或生产环境中进行构建和自动化测试,以确保没有集成问题并及早发现任何问题。
开发人员提交代码的时候一般先在本地测试验证,只要开发人员提交代码到版本控制系统就会触发一条提交流水线,对本次提交进行验证。
持续交付 CD (Continuous Delivery)
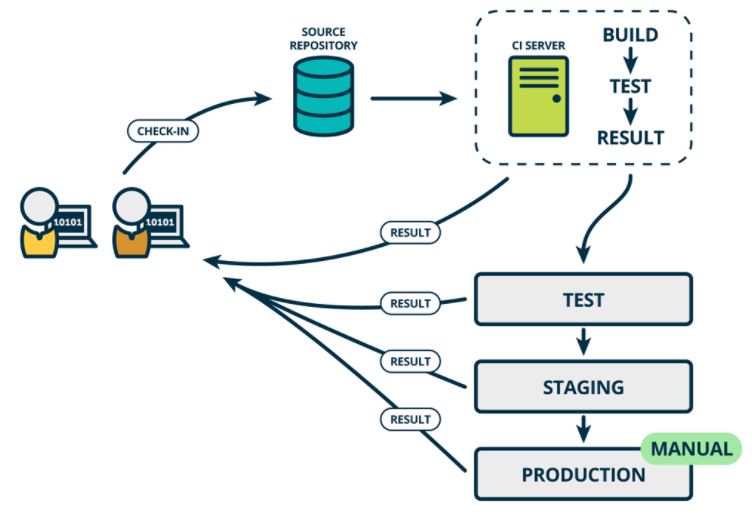
Continuous Delivery (CD) 持续交付是持续集成的延伸,将集成后的代码部署到类生产环境,确保可以以可持续的方式快速向客户发布新的更改。如果代码没有问题,可以继续手工部署到生产环境中。
持续交付CD:是基于持续集成的基础上,将集成后的代码自动化的发布到各个环境中测试(DEV TEST UAT STAG),确定可以发布生产版本。这里我们可以借用制品库实现制品的管理,根据环境类型创建对应的制品库。一次构建,到处运行。
- 开发环境发布:我们可以将开发环境产出的制品部署进行测试,没有问题后上传到测试环境的制品库中。
- 测试环境发布:此时通知测试人员可以进行测试环境发布测试,获取测试环境制品库中的制品,发布到测试环境验证。验证通过将制品上传到预生产环境制品库。
- 预生产环境发布:获取预生产环境制品,进行部署测试。测试成功后可以将制品上传到生产库中。
- 手动部署生产环境。
持续交付是超越持续集成的一步。不仅会在推送到代码库的每次代码更改时都进行构建和测试,而且,作为附加步骤,即使部署是手动触发的,它也可以连续部署。此方法可确保自动检查代码,但需要人工干预才能从策略上手动触发更改的部署。
持续部署 CD(Continuous Deploy)
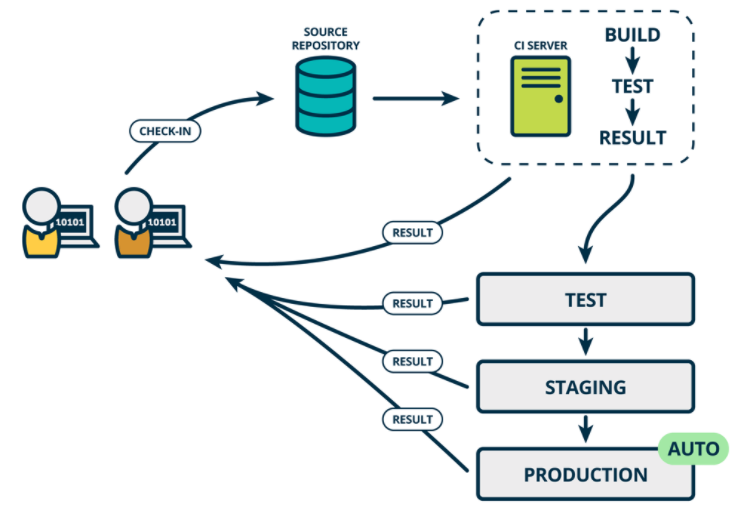
如果真的想获得持续交付的好处,应该尽早部署到生产环境,以确保可以小批次发布,在发生问题时可以轻松排除故障。于是有了持续部署。
通常可以通过将更改自动推送到发布系统来随时将软件发布到生产环境中。持续部署 会更进一步,并自动将更改推送到生产中。类似于持续交付,持续部署也是超越持续集成的进一步。不同之处在于,您无需将其手动部署,而是将其设置为自动部署。部署您的应用程序完全不需要人工干预。
持续部署CD:是基于持续交付的基础上,将在各个环境经过测试的应用自动化部署到生产环境。其实各个环境的发布过程都是一样的。应用发布到生产环境后,我们需要对应用进行健康检查、添加应用的监控项、 应用日志管理。
我们通常将这个在不同环境发布和测试的过程叫做部署流水线, 持续部署是在持续交付的基础上,把部署到生产环境的过程自动化。
参考:
https://blog.csdn.net/weixin_40046357/article/details/107478696
http://www.idevops.site/gitlabci/chapter01/01/
https://www.jianshu.com/p/654505d42180
敏捷为什么要使用Scrum而不是瀑布?
编程 星物种 发表了文章 0 个评论 2959 次浏览 2021-05-06 11:14

Scrum方法需要改变传统方法的思维方式。中心焦点已经从瀑布方法的范围转变为在Scrum中实现最大的商业价值。
在瀑布中,改变成本和进度以确保达到预期的范围,在Scrum中,可以改变质量和约束以实现获得最大商业价值的主要目标。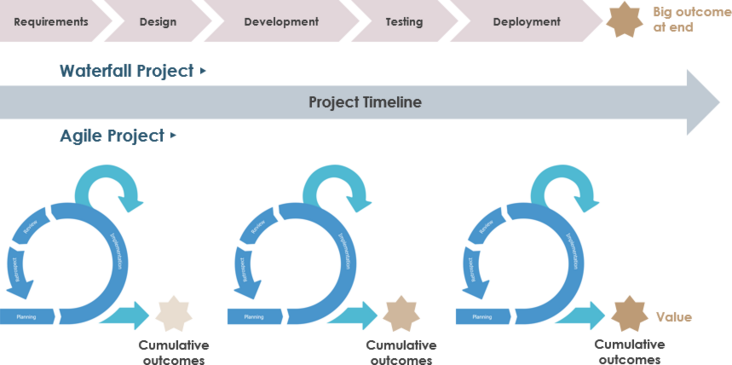
瀑布模型适用于有序和可预测的项目,其中所有要求都明确定义并且可以准确估计,并且在大多数行业中,此类项目正在减少。客户需求的变化导致企业适应和改变其交付方式的压力增大。
Scrum方法在当前市场中更为成功,其特点是不可预测性和波动性。Scrum方法基于inspect-adapt循环,而不是Waterfall方法的命令和控制结构。
Scrum项目以迭代方式完成,其中首先完成具有最高业务价值的功能。各个跨职能团队在Sprint中并行工作,以便在每个Sprint结束时提供潜在的可交付解决方案。
因为每次迭代都会产生可交付的解决方案(这是整个产品的一部分),所以团队必须实现可衡量的目标。这可确保团队正在进行,项目将按时完成。传统方法没有提供这种及时的检查,因此导致团队可能会下班并最终完成大量工作。
当客户定期与团队互动时,定期审查完成的工作; 因此,可以确保进度符合客户的要求。然而,在瀑布中没有这样的交互,因为工作是在筒仓中进行的,并且在项目结束之前没有可用的功能。
在复杂的项目中,客户不清楚他们在最终产品中需要什么,并且功能需求不断变化,迭代模型可以更灵活地确保在项目完成之前可以包含这些更改。
但是,当完成具有明确定义的功能的简单项目,并且当团队具有完成此类项目的先前经验(因此,估计将是准确的)时,瀑布方法可以是成功的。
敏捷 Vs 瀑布
下面是一个表格,可以更好地了解Scrum和瀑布的差异。
敏捷还是瀑布?
Standish Group的最新报告涵盖了他们在2013年至2017年期间研究的项目。在这段时间内,敏捷和瀑布的成功,挑战和失败的整体突破如下所示,敏捷项目成功的可能性大约是后者的2倍,失败的可能性降低1/3。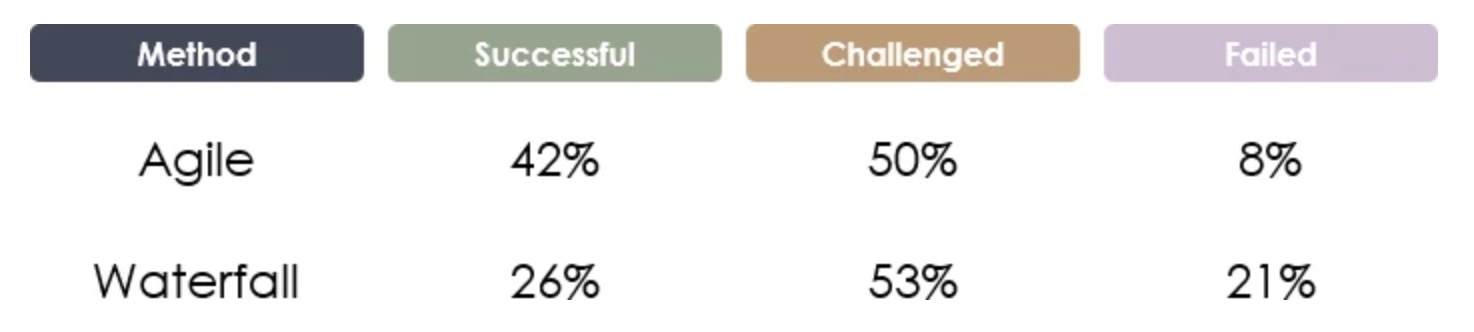
来源:vitalitychicago.com - 比较瀑布和敏捷项目成功率
每个伟大的产品需要一个伟大的ScrumMaster
编程 星物种 发表了文章 1 个评论 2254 次浏览 2021-05-04 10:31

摘要
产品负责人和ScrumMaster是两个相互补充的独立敏捷角色。 为了出色地完成工作,产品所有者需要在他们身边强大的ScrumMaster。
不幸的是,我发现通常缺少可以支持产品所有者的ScrumMaster。 有时角色之间会混淆,或者根本没有ScrumMaster。
这篇文章解释了这两个角色之间的区别,产品所有者应该从他们的ScrumMaster中获得什么,以及ScrumMasters从他们中可以期待什么。
产品负责人与ScrumMaster
产品负责人和ScrumMaster是相互补充的两个不同角色。 如果其中一个位置不正确,则另一个会受到影响。 作为产品负责人 ,您应对产品的成功负责-创造一种对用户和客户的工作都非常出色并满足其业务目标的产品。 因此,您可以与用户和客户以及内部利益相关者,开发团队和ScrumMaster进行交互,如下图所示。
上图中的灰色圆圈描述了由产品所有者,ScrumMaster和跨功能开发团队组成的Scrum团队。
ScrumMaster负责流程的成功 -帮助产品负责人和团队使用正确的流程来创建成功的产品,并促进组织变革和建立敏捷的工作方式。 因此,ScrumMaster与产品所有者和开发团队以及受Scrum影响的高级管理层,人力资源(HR)和业务组合作,如下图所示:
要成功成为产品负责人,需要正确的技能,时间,精力和重点。 扮演ScrumMaster角色也是如此。 将这两个角色(甚至是部分角色)组合在一起不仅非常具有挑战性,而且意味着忽略了某些职责。 如果您是产品所有者,请不要承担ScrumMaster的职责!
产品负责人对ScrumMaster的期望
作为产品所有者,您应该从以下几种方面受益于ScrumMaster的工作。 ScrumMaster应该指导团队,以便团队成员可以构建出色的产品,促进组织变革,以便组织利用Scrum并帮助您完成出色的工作:
下表详细说明了您应该从ScrumMaster获得的支持:
ScrumMaster支持您作为产品所有者,因此您可以专注于自己的工作-确保创建具有正确用户体验(UX)和正确功能的正确产品。 如果您的ScrumMaster不提供或无法提供此支持,请与个人联系,并找出问题所在。 不要介入并接管ScrumMaster的工作。 如果您没有ScrumMaster,请将上面的列表显示给您的高级管理层赞助商或老板,以解释为什么您需要身边有合格的ScrumMaster。
ScrumMaster应该对产品负责人有什么期望
Tango花了两个时间,ScrumMaster对您作为产品所有者的工作抱有期望,这是公平的。 下图说明了其中的一些: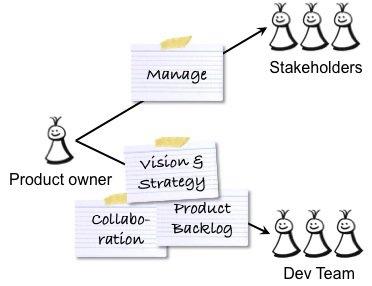
下表更详细地描述了ScrumMaster的期望:
Scrum是一个用于开发和维护复杂产品的框架
编程 星物种 发表了文章 0 个评论 2068 次浏览 2021-05-04 09:30

Scrum是一个用于开发和维护复杂产品的框架 ,是一个增量的、迭代的开发过程。在这个框架中,整个开发过程由若干个短的迭代周期组成,一个短的迭代周期称为一个Sprint,每个Sprint的建议长度是2到4周(互联网产品研发可以使用1周的Sprint)。
在Scrum中,使用产品Backlog来管理产品的需求,产品backlog是一个按照商业价值排序的需求列表,列表条目的体现形式通常为用户故事。Scrum团队总是先开发对客户具有较高价值的需求。在Sprint中,Scrum团队从产品Backlog中挑选最高优先级的需求进行开发。
挑选的需求在Sprint计划会议上经过讨论、分析和估算得到相应的任务列表,我们称它为Sprint backlog。在每个迭代结束时,Scrum团队将递交潜在可交付的产品增量。 Scrum起源于软件开发项目,但它适用于任何复杂的或是创新性的项目。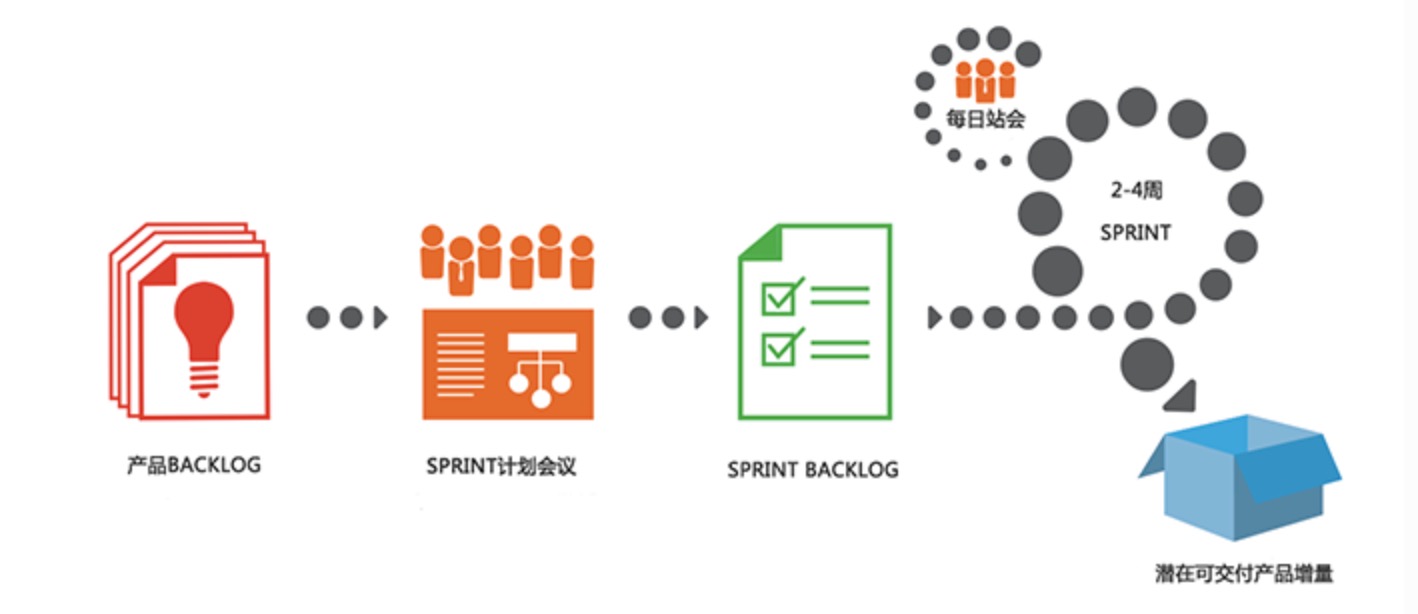
SCRUM框架包括3个角色、3个工件、5个事件、5个价值
3个角色
- 产品负责人(Product Owner)
- Scrum Master
- 开发团队
3个工件
- 产品Backlog(Product Backlog)
- SprintBacklog
- 产品增量(Increment)
5个事件
- Sprint(Sprint本身是一个事件,包括了如下4个事件)
- Sprint计划会议(Sprint Planning Meeting)
- 每日站会(Daily Scrum Meeting)
- Sprint评审会议(Sprint Review Meeting)
- Sprint回顾会议(Sprint Retrospective Meeting)
5个价值
- 承诺 – 愿意对目标做出承诺
- 专注– 把你的心思和能力都用到你承诺的工作上去
- 开放– Scrum 把项目中的一切开放给每个人看
- 尊重– 每个人都有他独特的背景和经验
- 勇气– 有勇气做出承诺,履行承诺,接受别人的尊重
SCRUM理论基础
Scrum以经验性过程控制理论(经验主义)做为理论基础的过程。经验主义主张知识源于经验, 以及基于已知的东西做决定。Scrum 采用迭代、增量的方法来优化可预见性并控制风险。
Scrum 的三大支柱支撑起每个经验性过程控制的实现:透明性、检验和适应。Scrum的三大支柱如下:
第一:透明性(Transparency)
透明度是指,在软件开发过程的各个环节保持高度的可见性,影响交付成果的各个方面对于参与交付的所有人、管理生产结果的人保持透明。管理生产成果的人不仅要能够看到过程的这些方面,而且必须理解他们看到的内容。也就是说,当某个人在检验一个过程,并确信某一个任务已经完成时,这个完成必须等同于他们对完成的定义。
第二:检验(Inspection)
开发过程中的各方面必须做到足够频繁地检验,确保能够及时发现过程中的重大偏差。在确定检验频率时,需要考虑到检验会引起所有过程发生变化。当规定的检验频率超出了过程检验所能容许的程度,那么就会出现问题。幸运的是,软件开发并不会出现这种情况。另一个因素就是检验工作成果人员的技能水平和积极性。
第三:适应(Adaptation)
如果检验人员检验的时候发现过程中的一个或多个方面不满足验收标准,并且最终产品是不合格的,那么便需要对过程或是材料进行调整。调整工作必须尽快实施,以减少进一步的偏差。
Scrum中通过三个活动进行检验和适应:每日例会检验Sprint目标的进展,做出调整,从而优化次日的工作价值;Sprint评审和计划会议检验发布目标的进展,做出调整,从而优化下一个Sprint的工作价值;Sprint回顾会议是用来回顾已经完成的Sprint,并且确定做出什么样的改善可以使接下来的Sprint更加高效、更加令人满意,并且工作更快乐。
全文阅读:https://www.scrumcn.com/agile/scrum-knowledge-library/scrum.html
什么是Serverless?
DevOps 星物种 发表了文章 1 个评论 1799 次浏览 2021-04-24 22:29

1. 无服务器(Serverless)计算是什么
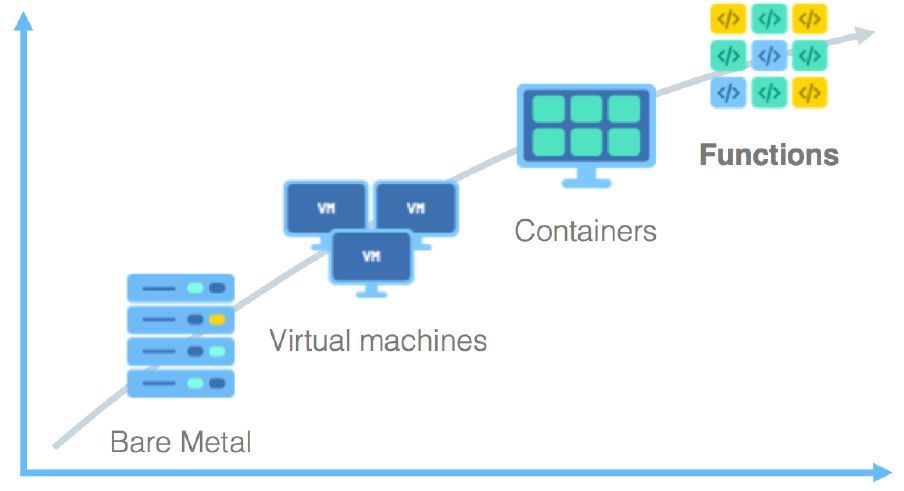
云计算涌现出很多改变传统IT架构和运维方式的新技术,比如虚拟机、容器、微服务,无论这些技术应用在哪些场景,降低成本、提升效率是云服务永恒的主题。
过去十年来,我们已经把应用和环境中很多通用的部分变成了服务。Serverless的出现,带来了跨越式变革。Serverless把主机管理、操作系统管理、资源分配、扩容,甚至是应用逻辑的全部组件都外包出去,把它们看作某种形式的商品——厂商提供服务,我们掏钱购买。
过去是“构建一个框架运行在一台服务器上,对多个事件进行响应”,Serverless则变为“构建或使用一个微服务或微功能来响应一个事件”,做到当访问时,调入相关资源开始运行,运行完成后,卸载所有开销,真正做到按需按次计费。这是云计算向纵深发展的一种自然而然的过程。
Serverless是一种构建和管理基于微服务架构的完整流程,允许你在服务部署级别而不是服务器部署级别来管理你的应用部署。它与传统架构的不同之处在于,完全由第三方管理,由事件触发,存在于无状态(Stateless)、暂存(可能只存在于一次调用的过程中)计算容器内。构建无服务器应用程序意味着开发者可以专注在产品代码上,而无须管理和操作云端或本地的服务器或运行时。Serverless真正做到了部署应用无需涉及基础设施的建设,自动构建、部署和启动服务。
国内外的各大云厂商 Amazon、微软、Google、IBM、阿里云、腾讯云、华为云相继推出Serverless产品,Serverless也从概念、愿景逐步走向落地,在各企业、公司应用开来。
2. 理解Serverless技术 - FaaS和BaaS
Serverless由开发者实现的服务端逻辑运行在无状态的计算容器中,它由事件触发, 完全被第三方管理,其业务层面的状态则被开发者使用的数据库和存储资源所记录。Serverless涵盖了很多技术,分为两类:FaaS和BaaS。
2.1 FaaS(Function as a Service,函数即服务)
FaaS意在无须自行管理服务器系统或自己的服务器应用程序,即可直接运行后端代码。其中所指的服务器应用程序,是该技术与容器和PaaS(平台即服务)等其他现代化架构最大的差异。
FaaS可以取代一些服务处理服务器(可能是物理计算机,但绝对需要运行某种应用程序),这样不仅不需要自行供应服务器,也不需要全时运行应用程序。
FaaS产品不要求必须使用特定框架或库进行开发。在语言和环境方面,FaaS函数就是常规的应用程序。例如AWS Lambda的函数可以通过Javascript、Python以及任何JVM语言(Java、Clojure、Scala)等实现。然而Lambda函数也可以执行任何捆绑有所需部署构件的进程,因此可以使用任何语言,只要能编译为Unix进程即可。FaaS函数在架构方面确实存在一定的局限,尤其是在状态和执行时间方面。
在迁往FaaS的过程中,唯一需要修改的代码是“主方法/启动”代码,其中可能需要删除顶级消息处理程序的相关代码(“消息监听器接口”的实现),但这可能只需要更改方法签名即可。在FaaS的世界中,代码的其余所有部分(例如向数据库执行写入的代码)无须任何变化。
相比传统系统,部署方法会有较大变化 – 将代码上传至FaaS供应商,其他事情均可由供应商完成。目前这种方式通常意味着需要上传代码的全新定义(例如上传zip或JAR文件),随后调用一个专有API发起更新过程。
FaaS中的函数可以通过供应商定义的事件类型触发。对于亚马逊AWS,此类触发事件可以包括S3(文件)更新、时间(计划任务),以及加入消息总线的消息(例如Kinesis)。通常你的函数需要通过参数指定自己需要绑定到的事件源。
大部分供应商还允许函数作为对传入Http请求的响应来触发,通常这类请求来自某种该类型的API网关(例如AWS API网关、Webtask)。
2.2 BaaS(Backend as a Service,后端即服务)
BaaS(Backend as a Service,后端即服务)是指我们不再编写或管理所有服务端组件,可以使用领域通用的远程组件(而不是进程内的库)来提供服务。理解BaaS,需要搞清楚它与PaaS的区别。
首先BaaS并非PaaS,它们的区别在于:PaaS需要参与应用的生命周期管理,BaaS则仅仅提供应用依赖的第三方服务。典型的PaaS平台需要提供手段让开发者部署和配置应用,例如自动将应用部署到Tomcat容器中,并管理应用的生命周期。BaaS不包含这些内容,BaaS只以API的方式提供应用依赖的后端服务,例如数据库和对象存储。BaaS可以是公共云服务商提供的,也可以是第三方厂商提供的。其次从功能上讲,BaaS可以看作PaaS的一个子集,即提供第三方依赖组件的部分。
BaaS服务还允许我们依赖其他人已经实现的应用逻辑。对于这点,认证就是一个很好的例子。很多应用都要自己编写实现注册、登录、密码管理等逻辑的代码,而对于不同的应用这些代码往往大同小异。完全可以把这些重复性的工作提取出来,再做成外部服务,而这正是Auth0和Amazon Cognito等产品的目标。它们能实现全面的认证和用户管理,开发团队再也不用自己编写或者管理实现这些功能的代码。
3. 无服务器(Serverless)计算如何工作?
与使用虚拟机或一些底层的技术来部署和管理应用程序相比,无服务器计算提供了一种更高级别的抽象。因为它们有不同的抽象和“触发器”的集合。
拿计算来讲,这种抽象有一个特定函数和抽象的触发器,它通常是一个事件。以数据库为例,这种抽象也许是一个表,而触发器相当于表的查询或搜索,或者通过在表中做一些事情而生成的事件。
比如一款手机游戏,允许用户在不同的平台上为全球顶级玩家使用高分数表。当请求此信息时,请求从应用程序到API接口。API接口或许会触发AWS的Lambda函数,或者无服务器函数,这些函数再从数据库表中获取到数据流,返回包含前五名分数的一定格式的数据。
一旦构建完成,应用程序的功能就可以在基于移动和基于 Web 的游戏版本中重用。
这跟设置服务器不同,不是必须要有Amazon EC2实例或服务器,然后等待请求。环境由事件触发,而响应事件所需的逻辑只在响应时执行。这意味着,运行函数的资源只有在函数运行时被创建,产生一种非常高效的方法来构建应用程序。
4. 无服务器(Serverless)适用于哪些场景?
在现阶段,Serverless主要应用在以下几个场景。首先在Web及移动端服务中,可以整合API网关和Serverles服务构建Web及移动后端,帮助开发者构建可弹性扩展、高可用的移动或 Web后端应用服务。在IoT场景下可高效的处理实时流数据,由设备产生海量的实时信息流数据,通过Serverles服务分类处理并写入后端处理。另外在实时媒体资讯内容处理场景里,用户上传的音视频到对象存储OBS,通过上传事件触发多个函数,分别完成高清转码、音频转码等功能,满足用户对实时性和并发能力的高要求。无服务器计算还适合于任何事件驱动的各种不同的用例,这包括物联网,移动应用,基于网络的应用程序和聊天机器人等。这里简单说两个场景,方便大家思考。
4.1 场景一:应用负载有显著的波峰波谷
Serverless 应用成功与否的评判标准并不是公司规模的大小,而是其业务背后的具体技术问题,比如业务波峰波谷明显,如何实现削峰填谷。一个公司的业务负载具有波峰波谷时,机器资源要按照峰值需求预估;而在波谷时期机器利用率则明显下降,因为不能进行资源复用而导致浪费。
业界普遍共识是,当自有机器的利用率小于 30%,使用 Serverless 后会有显著的效率提升。对于云服务厂商,在具备了足够多的用户之后,各种波峰波谷叠加后平稳化,聚合之后资源复用性更高。比如,外卖企业负载高峰是在用餐时期,安防行业的负载高峰则是夜间,这是受各个企业业务定位所限的;而对于一个成熟的云服务厂商,如果其平台足够大,用户足够多,是不应该有明显的波峰波谷现象的。
4.2 场景二:典型用例 - 基于事件的数据处理
视频处理的后端系统,常见功能需求如下:视频转码、抽取数据、人脸识别等,这些均为通用计算任务,可由函数计算执行。
开发者需要自己写出实现逻辑,再将任务按照控制流连接起来,每个任务的具体执行由云厂商来负责。如此,开发变得更便捷,并且构建的系统天然高可用、实时弹性伸缩,用户不需要关心机器层面问题。
5. Serverless的问题
对于企业来说,支持Serverless计算的平台可以节省大量时间和成本,同时可以释放员工,让开发者得以开展更有价值的工作,而不是管理基础设施。另一方面可以提高敏捷度,更快速地推出新应用和新服务,进而提高客户满意度。但是Serverless不是完美的,它也存在一些问题,需要慎重应用在生产环境。
5.1 不适合长时间运行应用
Serverless 在请求到来时才运行。这意味着,当应用不运行的时候就会进入 “休眠状态”,下次当请求来临时,应用将会需要一个启动时间,即冷启动时间。如果你的应用需要一直长期不间断的运行、处理大量的请求,那么你可能就不适合采用 Serverless 架构。如果你通过 CRON 的方式或者 CloudWatch 来定期唤醒应用,又会比较消耗资源。这就需要我们对它做优化,如果频繁调用,这个资源将会常驻内存,第一次冷启之后,就可以一直服务,直到一段时间内没有新的调用请求进来,则会转入“休眠”状态,甚至被回收,从而不消耗任何资源。
5.2 完全依赖于第三方服务
当你所在的企业云环境已经有大量的基础设施的时候,Serverless 对于你来说,并不是一个好东西。当我们采用某云服务厂商的 Serverless 架构时,我们就和该服务供应商绑定了,那么我们再将服务迁到别的云服务商上就没有那么容易了。
我们需要修改一下系列的底层代码,能采取的应对方案,便是建立隔离层。这意味着,在设计应用的时候,就需要隔离 API 网关、隔离数据库层,考虑到市面上还没有成熟的 ORM 工具,让你既支持Firebase,又支持 DynamoDB等等。这些也将带给我们一些额外的成本,可能带来的问题会比解决的问题多。
5.3 缺乏调试和开发工具
当我使用 Serverless Framework 的时候,遇到了这样的问题:缺乏调试和开发工具。后来,我发现了 serverless-offline、dynamodb-local 等一系列插件之后,问题有一些改善。然而,对于日志系统来说,这仍然是一个艰巨的挑战。
每次你调试的时候,你需要一遍又一遍地上传代码。而每次上传的时候,你就好像是在部署服务器,并不能总是快速地定位出问题在哪。后来,找了一个类似于 log4j 这样的可以分级别记录日志的 Node.js 库 winston。它可以支持 error、warn、info、verbose、debug、silly 六个不同级别的日志,再结合大数据进行日志分析过滤,才能快速定位问题。
5.4 构建复杂
Serverless 很便宜,但是这并不意味着它很简单。AWS Lambda的 CloudFormation配置是如此的复杂,并且难以阅读及编写(JSON 格式),虽然CloudFomation提供了Template模板,但想要使用它的话,需要创建一个Stack,在Stack中指定你要使用的Template,然后aws才会按照Template中的定义来创建及初始化资源。
而Serverless Framework的配置更加简单,采用的是 YAML 格式。在部署的时候,Serverless Framework 会根据我们的配置生成 CloudFormation 配置。然而这也并非是一个真正用于生产的配置,真实的应用场景远远比这复杂。
6. 总结
云计算经过这么多年的发展,逐渐进化到用户仅需关注业务和所需的资源。比如,通过K8S这类编排工具,用户只要关注自己的计算和需要的资源(CPU、内存等)就行了,不需要操心到机器这一层。
Serverless架构让人们不再操心运行所需的资源,只需关注自己的业务逻辑,并且为实际消耗的资源付费。可以说,随着Serverless架构的兴起,真正的云计算时代才算到来了。
任何新概念新技术的落地,本质上都是要和具体业务去结合,去真正解决具体问题。虽然Serverless很多地方不成熟,亟待完善。不过Serverless自身的优越特性,对于开发者来说,吸引力是巨大的。相信随着技术的飞速发展,Serverless在未来还有无限可能!
作者介绍:孙杰 北京中油瑞飞资深架构师,著名技术博客博主。
fir.im持续集成技术实践
运维 OS小编 发表了文章 0 个评论 2611 次浏览 2017-11-15 21:20
持续集成做什么
持续集成的概念出现在 2001 年,它其实是一个 XP 极限编程的工程实践。那么持续的是什么,集成是什么呢,非常简单就是“一直不停地集成代码”。
持续集成是把代码频繁的合并到主干,通过自动构建的方式验证软件的质量,让团队快速的响应质量,快速的修复问题,快速的给客户解决问题,快速地交付更好的软件质量。
我们为什么要做持续集成
开发人员对下面的软件开发场景很熟悉,比如:
- 场景一:开发了新功能,老功能产生新的 bug;
- 场景二:修好一个 bug,又产生其他 bug,甚至出现连环 bug;
- 场景三:出现的 bug 比较多,修改代码要很谨慎,不熟悉的模块一般不敢动,怕引起问题;
如上面所说,持续集成不能消除 bug ,但能更容易地发现 bug,更快速地修复,提升产品质量。那么,持续集成能给我们带来哪些价值?“Continuous Integration doesn’t get rid of bugs, but it does make them dramatically easier to find and remove.” — Martin Fowler


拿每个产品开发都会遇到的 login 功能开发举例,当填完的用户名和密码传到数据库,做完验证后给用户返回一个结果。那什么是一个原子提交?比如,提交验证一个用户名,这是一个完整的 feature ;验证密码是否符合格式(6位/8位),这也是一个完整的 feature ;当我验证完用户名和密码后再传到数据库之后,查询正确与否,这也是一个完整的 feature ;保证每次提交是一个完整的 feature 或修复了一个 bug,不要代码写成半截。持续集成系统这里讲的是狭义的持续集成系统,通常的 CI 系统收到提交之后会触发构建,构建会有信息返回比如 commit id 、commit 信息、代码变更等,收到代码提交后会触发自动构建,接着安装依赖进行编译,并触发质量保证流程,也就是说自动化测试集。当代码变动你想创建提交时,这个提交应该尽可能的小量,并且包含一个不可分割的特性(feature)、修复(fix)或优化(improved)。



- Trello 看板;
- 三个环境(类生产环境,测试环境,生产环境);
- CI 工具(Jenkins/flow.ci)


整个团队的构建频率可以看下这张图:我们会做代码 review ,当 feature 分支提 pr 到 develop 分支上,这样 develop 分支的构建条件是:当收到 pr 之后,开始跑持续集成。假如部署完成整个测试跑过了产品经理验收之后,没毛病了,终于可以发布了到 master 分支。


- 最初阶段:提交代码-自动部署;
- 一般进阶:提交代码-代码静态分析-自动部署,最简单先再加入代码静态分析;
- 高级进阶:提交代码-代码静态分析-自动化测试集-自动部署;

- 测试异常——不仅仅测试正确情况,也要主动测试异常;
- 减少耦合——保证独立的可测试性;
- 功能分离——单元测试流太长,超过 20 分钟的话要详细想一下如何将功能单独拆开,效率更高;
- 测试=需求——从测试代码看到每个 class 是干什么的,同时出现 bug 时,第一时间是看测试,想想如何从测试中复现;
Step 3. 验收测试
验收测试是端对端的测试,从收到用户名密码到返回结果,是不是我们所期望的一个值,这是验收 Acceptance Test,其实是验收了整个功能。代码静态检查和单元测试,保证了我们如何怎么去写代码,验收测试保证了写正确代码,符合开发需求。
flow.ci 做验收测试比较多,用的是比较流行的框架 Cucumber + Selenium WebDriver,目前支持 3 种数据库,5 种 git 仓库,7 种 开发语言跑在 docker 容器云上,支持 iOS 构建跑在 mac 机器上,要保证这些排列组合正常运行,这是 flow.ci 做验收测试最核心的价值。

其实,持续集成是一个工作流,当 push 代码的时候才会 run 起来,但是 flow.ci 本身系统也有外部依赖的特殊性,会依赖一些第三方的 sevice(比如 GitHub/GitLab 等),验收测试应该一直保持不断地运行,也可以叫持续测试吧。因为我们永远不能保证第三方的 api 会不会改变:)
Step 4. 性能测试
我们的性能测试做的比较简单,主要测试 api.因为 fir.im 做 app 的内测分发,我们需要性能测试保证 app 上传下载的正常稳定。性能测试是单用户的,压力测试是多用户的,这是两者之间的区别。
性能测试会有一些不确定性,有很多系统会产生缓存。flow.ci 的性能测试跑在 docker 上,是一个干净独立的环境,需要让系统预热运行一下。Locust/JMeter/LoadRunner是目前比较流行的性能测试工具。 flow.ci 目前用的是 locust,可以参考一下。
持续集成的可视化、数据分析

说到数据统计分析,整个 ci 流程跑下来产生的很多数据也非常有挖掘的价值。比如,对于代码静态分析有多少 Offence、Risk、Bug,对于单元测试有失败率、测试覆盖率;对于验收测试或性能测试有多少的失败率,这些数据都有可能成为衡量一个程序员的标准。

结语
CI 就像盖楼房的脚手架一样,没有脚手架就没办法盖出一个足够高的楼,没有 CI 就无法交付质量足够好的软件!
理解持续集成、持续交付、持续部署
运维 OS小编 发表了文章 0 个评论 2612 次浏览 2017-11-15 00:14
持续集成

持续集成强调开发人员提交了新代码之后,立刻进行构建、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起。
持续交付

持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」(production-like environments)中。比如,我们完成单元测试后,可以把代码部署到连接数据库的 Staging 环境中更多的测试。如果代码没有问题,可以继续手动部署到生产环境中。
持续部署

持续部署则是在持续交付的基础上,把部署到生产环境的过程自动化。我个人觉得持续集成、持续交付、持续部署非常值得推广。开发过程中最怕集成时遇到问题导致返工,而持续集成、持续交付、持续部署恰恰可以早发现早解决,从而可以避免这个问题。
参考:https://www.mindtheproduct.com/2016/02/what-the-hell-are-ci-cd-and-devops-a-cheatsheet-for-the-rest-of-us/
谈谈持续集成、持续交付、持续部署之间的区别
运维 OS小编 发表了文章 0 个评论 2564 次浏览 2017-11-14 22:50

假如把开发工作流程分为以下几个阶段:
编码 ---> 构建 ---> 集成 ---> 测试 ---> 交付 ---> 部署
正如你在上图中看到,「持续集成(Continuous Integration)」、「持续交付(Continuous Delivery)」和「持续部署(Continuous Deployment)」有着不同的软件自动化交付周期。
持续集成
持续集成是指软件个人研发的部分向软件整体部分交付,频繁进行集成以便更快地发现其中的错误。“持续集成”源自于极限编程(XP),是 XP 最初的 12 种实践之一。

CI 需要具备这些:
- 全面的自动化测试: 这是实践持续集成&持续部署的基础,同时,选择合适的自动化测试工具也极其重要;
- 灵活的基础设施: 容器,虚拟机的存在让开发人员和 QA 人员不必再大费周折;
- 版本控制工具: 如 Git,CVS,SVN 等;
- 自动化的构建和软件发布流程的工具,如 Jenkins,flow.ci;
- 反馈机制: 如构建/测试的失败,可以快速地反馈到相关负责人,以尽快解决达到一个更稳定的版本。
- “快速失败”,在对产品没有风险的情况下进行测试,并快速响应;
- 最大限度地减少风险,降低修复错误代码的成本;
- 将重复性的手工流程自动化,让工程师更加专注于代码;
- 保持频繁部署,快速生成可部署的软件;
- 提高项目的能见度,方便团队成员了解项目的进度和成熟度;
- 增强开发人员对软件产品的信心,帮助建立更好的工程师文化。

- 快速发布。能够应对业务需求,并更快地实现软件价值。
- 编码->测试->上线->交付的频繁迭代周期缩短,同时获得迅速反馈;
- 高质量的软件发布标准。整个交付过程标准化、可重复、可靠,
- 整个交付过程进度可视化,方便团队人员了解项目成熟度;
- 更先进的团队协作方式。从需求分析、产品的用户体验到交互 设计、开发、测试、运维等角色密切协作,相比于传统的瀑布式软件团队,更少浪费。
持续部署
持续部署是指当交付的代码通过评审之后,自动部署到生产环境中。持续部署是持续交付的最高阶段。这意味着,所有通过了一系列的自动化测试的改动都将自动部署到生产环境。它也可以被称为“Continuous Release”。

为什么说持续部署是理想的工作流程?
“开发人员提交代码,持续集成服务器获取代码,执行单元测试,根据测试结果决定是否部署到预演环境,如果成功部署到预演环境,进行整体验收测试,如果测试通过,自动部署到产品环境,全程自动化高效运转。”
实际上,产品在从需求到部署的过程中,会经历若干种不同的环境,例如 QA 环境、各种自动化测试运行环境、生产环境等。这些环境的搭建、配置、管理,产品在不同环 境中的具体部署,状况是比较非常复杂的,从头到尾地全自动持续部署的确困难。那么,如果能做到持续交付,保证代码在模拟环境没问题,也许团队成员做到真正的心理有数。
持续部署的优点:
持续部署主要好处是,可以相对独立地部署新的功能,并能快速地收集真实用户的反馈。
“You build it, you run it”,这是 Amazon 一年可以完成 5000 万次部署,平均每个工程师每天部署超过 50 次的核心秘籍。
最后
「持续集成(Continuous Integration)」、「持续交付(Continuous Delivery)」和「持续部署(Continuous Deployment)」提供了一个优秀的 DevOps 环境,对于整个团队来说,好处与挑战并行。无论如何,频繁部署、快速交付以及开发测试流程自动化都将成为未来软件工程的重要组成部分。
分享阅读链接:http://www.jianshu.com/p/2c6ebe34744a
來源:简书
DevOps详解
运维 OS小编 发表了文章 0 个评论 2555 次浏览 2017-07-18 00:04
这样的看法甚至让我感觉有些气愤。DevOps在我看来极为重要,过去15年来,我一直在大型机构,主要是大型金融机构中从事工程业务。DevOps是一种非常重要的方法论,该方法将解决一些最大型问题的基本原则和实践恰如其分地融为一体,很好地解决了此类机构的软件开发项目中一种最令人感觉悲凉的失败要素:开发者和运维人员之间的混乱之墙。
请不要误会我的这种观点,除了某些XP实践,大部分此类大型机构对敏捷开发方法论的运用还有很长的路要走,同时还有很多其他原因会导致软件开发项目的失败或延误。
但在我看来,混乱之墙目前依然是他们所面临的最令人沮丧、最浪费时间、同时也相当愚蠢的问题。
与其独自生闷气,我觉得不如说点更实在的东西,写一篇尽可能精准的文章,向大家介绍DevOps到底是什么,能为我们带来什么。长话短说,DevOps并不是某一套工具。DevOps是一种方法论,其中包含一系列基本原则和实践,仅此而已。而所用的工具(或者说“工具链”吧,毕竟用于为这些实践提供支持的工具集有着极高的扩展性)只是为了对这样的实践提供支持。
最终来说,这些工具本身并不重要。相比两年前,目前的DevOps工具链已经产生了翻天覆地的变化,可想而知,两年后还会产生更大的差异。不过这并不重要。重要的是能够合理地理解这些基本原则和实践。
本文并不准备介绍某些工具链,甚至完全不会提到这些工具。网上讨论DevOps工具链的文章已经太多了。我想在本文中谈谈最基本的原则和实践,它们的主要目的,毕竟这些才是对我而言最重要的。
DevOps是一种方法论,归纳总结了面临独一无二的机遇和强有力需求的网络巨头们,结合自身业务本质构思出全新工作方式的过程中所采用的实践,而他们的业务需求也很直接:以史无前例的节奏对自己的系统进行演进,有时候可能还需要以天为单位对系统或业务进行扩展。
虽然DevOps对初创公司来说很明显是不可或缺的,但我认为那些有着庞大的老式IT部门的大企业才是能从这些基本原则和实践中获得最大收益的。本文将试图解释得出这个结论的原因和实现方法。
本文的部分内容已发布为Slideshare演示幻灯片,可在这里浏览:http://www.slideshare.net/JrmeKehrli/devops-explained-72091158
目录

1. 简介
DevOps所关注的不是工具本身,也不是对chef或Docker的掌握程度。DevOps是一种方法论,是一系列可以帮助开发者和运维人员在实现各自目标(Goal)的前提下,向自己的客户或用户交付最大化价值及最高质量成果的基本原则和实践。
开发者和运维人员之间最大的问题在于:虽然都是企业中大型IT部门不可或缺的,但他们有着截然不同的目的(Objective)。

开发者和运维人员之间目的上的差异就叫做混乱之墙。下文会介绍这个概念的准确定义,以及为什么我认为这种状况很严峻并且很糟糕。
DevOps是一种融合了一系列基本原则和实践的方法论(并从这些实践中派生出了各种工具),意在帮助这些人员向着一个统一的共同目的努力:尽可能为公司提供更多价值。
令人惊奇的是,这个问题竟然有一个非常简单的“银子弹”:让生产端变得敏捷起来!
而这恰恰正是DevOps所要达成的唯一目标!
但在进一步讨论这一点之前,首先需要谈谈其他几件事。
1.1 管理信条
喜欢 | 作者 Jerome Kehrli ,译者 大愚若智 发布于 2017年4月24日. 估计阅读时间: 1 分钟 | 智能化运维、Serverless、DevOps......2017年有哪些最新运维技术趋势?CNUTCon即将为你揭秘!1 讨论分享到:微博微信FacebookTwitter有道云笔记邮件分享
稍后阅读
我的阅读清单
最近我阅读了很多有关DevOps的文章,其中一些非常有趣,然而一些内容也很欠考虑。貌似很多人越来越坚定地在DevOps与chef、puppet或Docker容器的熟练运用方面划了等号。对此我有不同看法。DevOps的范畴远远超过puppet或Docker等工具。
这样的看法甚至让我感觉有些气愤。DevOps在我看来极为重要,过去15年来,我一直在大型机构,主要是大型金融机构中从事工程业务。DevOps是一种非常重要的方法论,该方法将解决一些最大型问题的基本原则和实践恰如其分地融为一体,很好地解决了此类机构的软件开发项目中一种最令人感觉悲凉的失败要素:开发者和运维人员之间的混乱之墙。
请不要误会我的这种观点,除了某些XP实践,大部分此类大型机构对敏捷开发方法论的运用还有很长的路要走,同时还有很多其他原因会导致软件开发项目的失败或延误。
相关厂商内容
聊聊容器编排与管理的挑战
智能化运维技术详解
机器学习模型训练的Kubernetes实践
京东物流系统自动化运维平台技术揭密
基于资产配置业务场景下的全链路监控平台
相关赞助商
CNUTCon全球运维技术大会,9月10日-9月11日,上海·光大会展中心大酒店,精彩内容抢先看
但在我看来,混乱之墙目前依然是他们所面临的最令人沮丧、最浪费时间、同时也相当愚蠢的问题。
与其独自生闷气,我觉得不如说点更实在的东西,写一篇尽可能精准的文章,向大家介绍DevOps到底是什么,能为我们带来什么。长话短说,DevOps并不是某一套工具。DevOps是一种方法论,其中包含一系列基本原则和实践,仅此而已。而所用的工具(或者说“工具链”吧,毕竟用于为这些实践提供支持的工具集有着极高的扩展性)只是为了对这样的实践提供支持。
最终来说,这些工具本身并不重要。相比两年前,目前的DevOps工具链已经产生了翻天覆地的变化,可想而知,两年后还会产生更大的差异。不过这并不重要。重要的是能够合理地理解这些基本原则和实践。
本文并不准备介绍某些工具链,甚至完全不会提到这些工具。网上讨论DevOps工具链的文章已经太多了。我想在本文中谈谈最基本的原则和实践,它们的主要目的,毕竟这些才是对我而言最重要的。
DevOps是一种方法论,归纳总结了面临独一无二的机遇和强有力需求的网络巨头们,结合自身业务本质构思出全新工作方式的过程中所采用的实践,而他们的业务需求也很直接:以史无前例的节奏对自己的系统进行演进,有时候可能还需要以天为单位对系统或业务进行扩展。
虽然DevOps对初创公司来说很明显是不可或缺的,但我认为那些有着庞大的老式IT部门的大企业才是能从这些基本原则和实践中获得最大收益的。本文将试图解释得出这个结论的原因和实现方法。
本文的部分内容已发布为Slideshare演示幻灯片,可在这里浏览:http://www.slideshare.net/JrmeKehrli/devops-explained-72091158
目录1. 简介 1.1 管理信条 1.2 一个典型的IT组织 1.3 运维人员测挫败感 1.4 基础架构自动化 1.5 DevOps:仅此一次,一颗神奇的银子弹 2. 基础架构即代码 2.1 概述 2.2 DevOps工具链 2.3 收益 3. 持续交付 3.1 从实践中学习 3.2 自动化 3.3 更频繁的部署 3.4 持续交付的前提需求 3.5 零停机部署 4. 协作 4.1 混乱之墙 4.2 软件开发流程 4.3 共享工具 4.4 协同工作 5. 结论1. 简介
DevOps所关注的不是工具本身,也不是对chef或Docker的掌握程度。DevOps是一种方法论,是一系列可以帮助开发者和运维人员在实现各自目标(Goal)的前提下,向自己的客户或用户交付最大化价值及最高质量成果的基本原则和实践。
开发者和运维人员之间最大的问题在于:虽然都是企业中大型IT部门不可或缺的,但他们有着截然不同的目的(Objective)。
开发者和运维人员之间目的上的差异就叫做混乱之墙。下文会介绍这个概念的准确定义,以及为什么我认为这种状况很严峻并且很糟糕。
DevOps是一种融合了一系列基本原则和实践的方法论(并从这些实践中派生出了各种工具),意在帮助这些人员向着一个统一的共同目的努力:尽可能为公司提供更多价值。
令人惊奇的是,这个问题竟然有一个非常简单的“银子弹”:让生产端变得敏捷起来!
而这恰恰正是DevOps所要达成的唯一目标!
但在进一步讨论这一点之前,首先需要谈谈其他几件事。
1.1 管理信条
IT管理这场战争的原动力到底是什么?换句话说,在软件开发项目中,管理工作首要的,以及最重要的目的是什么?
有什么想法吗?
我来提供一个线索吧:在建立一家初创公司时,最重要的事情是什么?
当然是要加快上市时间(TTM)!
上市时间(即TTM)是指一件产品从最初的构思到最终可供用户使用或购买这一过程所需要的时间。对于产品很快会过时的行业,TTM是一个非常重要的概念。
在软件工程方面,所采用的方法、业务,以及具体技术几乎每年都会变化,因而TTM就成了一个非常重要的KPI(关键绩效指标)。
TTM通常也会被叫做前置时间(Lead Time)。
第一个问题在于,(很多人认为)在开发过程中TTM和产品质量是两个对立的属性。在下文可以看到,改善质量(进而提高稳定性)是运维人员的目的,而开发者的目的在于降低前置时间(进而提高TTM)。
请容我来解释一下。
IT组织或部门通常会通过两个关键的KPI进行评估:软件本身的质量,因而需要尽可能减少缺陷的数量;此外还有TTM,因而需要将业务构想(通常由业务用户提供)变为最终成果,并以尽可能快的速度提供给用户或客户。
这里的问题在于,大部分情况下这两个截然不同的目的是由两个不同团队提供支持的:负责构建软件的开发者,以及负责运行软件的运维人员。
1.2 一个典型的IT组织
在组织内部负责管理重要IT部门的典型IT组织通常看起来是这样的:

主要由于历史的原因(大部分运维人员来自硬件和电信业务领域),运维人员和开发者分属不同的组织结构分支。开发者属于研发部门,而运维人员大部分时候属于基础架构部门(或专门的运维部门)。
别忘了,他们有着不同的目的:

此外作为旁注,这两个团队有时候会使用不同的预算来运营。开发团队使用构建(Build)预算,运维团队使用运营(Run)预算。不同的预算,对控制权越来越高的需求,以及企业IT成本的缩水,这些因素结合在一起会进一步放大两个团队各自目的的对立性。
(依本人愚见,时至今日,随着人与人之间无时无刻随时随地进行的交互,以及由不同目的推动着企业和社会进行数字化转型,IT预算方面古老的“规划/构建/运行”框架已经不那么合理了,不过这又是另一回事了。)
1.3 运维人员测挫败感
接下来看看运维人员,一起看看典型的运维团队把大部分时间都花在哪里了:

来源:Study from Deepak Patil [Microsoft Global Foundation Services] in 2006, via James Hamilton [Amazon Web Services
生产团队有将近一半(47%)的时间花在了与部署有关的工作中:
- 执行实际的部署工作,或修复与部署工作有关的问题

- 只需手工运行5条命令的情况下,成功部署的概率就已跌至86%。
- 如需手工运行55条命令,成功部署的概率将跌至22%。
- 如需手工运行100条命令,成功部署的概率将趋近于0(仅2%)!

- Facebook有数千名开发和运维人员,成千上万台服务器。平均来说一位运维人员负责500台服务器(还认为自动化是可选的吗?)他们每天部署两次(环式部署,Deployment ring的概念)。
- Flickr每天部署10次。
- Netflix明确针对失败进行各种设计!他们的软件按照设计从最底层即可容忍系统失败,他们会在生产环境中进行全面的测试:每天通过随机关闭虚拟机的方式在生产环境中执行65000次失败测试…… 并确保这种情况下一切依然可以正常工作。



- 编码:代码开发和审阅,版本控制工具、代码合并工具
- 构建:持续集成工具、构建状态统计工具
- 测试:通过测试和结果确定绩效的工具
- 打包:成品仓库、应用程序部署前暂存
- 发布:变更管理、发布审批、发布自动化
- 配置:基础架构配置和部署,基础架构即代码工具
- 监视:应用程序性能监视、最终用户体验
- 可重复性与可靠性:时至今日,构建生产用计算机只需要运行脚本或必要的puppet命令即可。通过恰当地使用Docker容器或Vagrant虚拟机,只需运行一条命令即可配置好包含操作系统层以及所需软件和配置的生产用计算机。当然,随着各种变更或软件开发、持续集成,并自动测试,这套构建脚本或机制也会进行持续集成。
- 生产力:一键部署,一键供应,一键创建新环境……整个生产环境可以通过一条命令或一键点击的方式创建。这样的一条命令也许会运行长达数小时,但在这过程中运维人员可以从事其他更有趣的工作,而无需等待一条命令执行完毕后继续输入下一条命令,毕竟这样的过程有时候可能需要花费几天时间才能完成……
- 恢复时间:一键点击即可恢复生产环境,就是这么简单。
- 确保基础架构的同质:彻底避免运维人员每次构建环境或安装软件时最终获得的结果与预期有所差异,这是确保基础架构绝对同质(Homogeneous)并且可再现的唯一可行方法。以此为基础,通过对脚本或Puppet配置文件使用版本控制机制,我们甚至可以重建出与上周、上个月,或软件特定版本发布时完全一致的生产环境。
- 维持整齐划一的标准:基础架构标准甚至可以不复存在,代码本身就是标准。
- 让开发者自行完成大部分工作:如果开发者自己突然可以在自己的基础架构上一键点击重建生产环境,他们也就可以自行完成很多与生产环境有关的任务,例如更好地理解生产失败,提供更恰当的配置,实现部署脚本等。
- 部署越频繁,对部署流程就会越熟悉,自动化机制就能获得更好的结果。如果同一件事每天需要执行3次,很快你将变的无比娴熟,但很快也会因为日复一日解决同样的问题而感到厌烦。
- 部署越频繁,所部属的变更集就越微不足道,而这些微不足道的内容最有可能出错,甚至可能导致丢失对整个变更集的控制力。
- 部署越频繁,TTR(修复/解决所需时间)指标就会越出色,从业务用户处获得有关功能的各类反馈的速度越快,作出改进以便完美满足对方需求的过程也会越简单(这方面TTR与TTM其实非常相似)。

- 从实践中学习
- 自动化
- 更频繁的部署

- 首先,随着要做的工作量逐渐增加,这些任务也会变的愈加困难,但如果能拆解为小块,则会变的相对容易些。以数据库迁移为例:一些涉及大量表的大规模数据库迁移工作很麻烦,容易出错。但如果一次只迁移一部分,则可以相对较容易地成功完成整个迁移任务。此外还可以轻松地将多个小规模的迁移任务安排成一定的序列,在将一个艰难的大任务拆解为一系列容易实现的小目标后,处理起来就简单多了。(这也是数据库重构的本质)
- 第二个原因在于反馈。大部分敏捷思维关注的是设置反馈环路,借此让我们更快速地学习了解。反馈已经是极限编程(Extreme Programming)中一个非常重要,蕴含巨大价值的概念。在诸如软件开发等复杂流程中,我们需要更频繁地检查自己的最新进展,并进行必要的纠正。为此我们必须尽一切可能创建反馈环路,并提高反馈的频率,这样才能更快速地酌情做出调整。
- 第三个原因是实践。对于任何活动,越频繁地从事就越能获得完善。实践可以帮助我们理清整个流程,让我们更熟悉代表有事情出错的征兆。只要认真琢磨自己从事的工作,就能提炼出近一步完善所需的实践。对于软件开发,也有可能实现一定程度的自动化。一旦有人将某件事做了多次,就可以更容易地确定该如何进行自动化,更重要的是,这样的人在对这些事情实现自动化方面将有更大的动机。此时自动化尤为重要,因为可以加快速度并降低出错的概率。

- 对软件组件的开发和平台的供应和设置进行持续集成。
- TDD - 测试驱动的开发。这一点还有待商榷……但始终还是需要面对:TDD是目前唯一能通过单元测试对代码和分支进行可接受程度覆盖的方法(单元测试使得问题的修复过程比集成测试或功能测试容易很多)。
- 代码审阅!至少要进行代码审阅……如果能进行结对编程(Pair programming)当然就更好了。
- 软件的持续审计 - 例如使用Sonar。
- 在生产级环境实现功能测试的自动化。
- 更强大的非功能测试自动化(性能、可用性等)。
- 独立于目标环境的自动化打包和部署。
- 功能开关(Feature Flipping)
- 摸黑启动(Dark launch)
- 蓝/绿部署(Blue/Green Deployment)
- 金丝雀发布(Canari release)
功能开关
功能开关可供我们在软件运行过程中启用/禁用相应的功能。这种技术其实非常容易理解和使用:为生产版本提供一个能彻底禁用某项功能的配置,并只在对应功能彻底完工可以正常工作后才将该属性激活。
举例来说,若要将某个应用程序内的一个功能全局禁用或激活:
if Feature.isEnabled('new_awesome_feature')
# Do something new, cool and awesome
else
# Do old, same as always stuff
end或者如果要真对具体用户实现类似目的:if Feature.isEnabled('new_awesome_feature', current_user)
# Do something new, cool and awesome
else
# Do old, same as always stuff
end 摸黑启动摸黑启动的目的在于通过生产环境进行负载模拟!
在测试环境中,通常很难为软件模拟出成百上千万用户规模的负载。
如果不进行切实的负载测试,就无法知道基础架构能否承受住最终面临的压力。
此时并不需要模拟负载,而是可以实际部署这样的功能,然后看看在不影响可用性的前提下到底会发生什么。
Facebook将这种做法称之为功能的“摸黑启动”。
假设我们要将一个有5亿用户使用的静态搜索字段变成一个包含自动补全功能的字段,借此让用户可以更快速获得搜索结果。为该功能构建一个Web服务,并且希望模拟所有用户同时输入文字,向该Web服务生成大量请求的场景。
此时即可通过摸黑启动策略为现有表单添加一个隐藏的后台进程,通过该进程将输入的搜索关键字发送给新增的自动补全服务,并自动发送多次。
就算新增的Web服务彻底崩溃了,也不会造成任何实质损害。网页上可以完全忽略服务器错误。而就算该服务崩溃了,我们至少还可以对该服务进行优化和完善,直到能承受如此大量的负载。
这就等于在现实世界中进行了一次负载测试。
蓝/绿部署
蓝/绿部署是指为下一版产品构建另一个完整的生产环境。开发和运维团队可以在这个单独的生产环境中放心地构建下一版产品。
当下一版产品全部完成后,可以修改负载均衡器的配置,以透明的方式将用户自动重定向至新发布的下一版。
随后可将上一版的生产环境回收,用于构建下下一
浅谈开源工具自动化运维阶段
运维 Rock 发表了文章 1 个评论 6987 次浏览 2016-01-02 00:48
前言
随着各种业务对IT的依赖性渐重以及云计算技术的普及,企业平均的IT基础架构规模正不断扩张。
有些Web 2.0企业可能会需要在两个星期内增加上千台服务器,因此对运维而言,通过手动来一个一个搭建的方法不仅麻烦、效率低下,而且非常不利于维护和扩展。
即使是在传统的企业当中,日常的备份、服务器状态监控和日志,通过手动的方式来进行的效率也很低,是一种人力的浪费。因此,自动化早已是每个运维都必须掌握的看家本领。
在不同的企业中,自动化的规模、需求与实现方式都各不相同,因此在技术细节层面,运维之间很难将别的企业的方法整个套用过来。然而在很多情况下,自动化的思路是有共通之处的。
运维自动化前三阶段
- []纯手工阶段:手工操作重复地进行软件部署和运维;[/][]脚本阶段:通过编写脚本、方便地进行软件部署和运维;[/][]工具阶段:借助第三方工具高效、方便地进行软件部署和运维。[/]
这几个阶段是随着运维知识、经验、教训不断积累而不断演进的。而且,第2个阶段和第3个阶段可以说是齐头并进,Linux下的第三方工具虽说已经不少了,但是Linux下的脚本编写对运维工作的促进作用是绝对不可以忽视的。在DevOps出现之前,运维工作者在工作中还是以这两种方式为主。
1、预备类工具:KickstartLinux下好用的开源工具
kickstart安装是redhat开创的按照你设计好的方式全自动安装系统的方式。安装方式可以分为光盘、硬盘、和网络。Cobbler
Cobbler是一个快速网络安装linux的服务,而且在经过调整也可以支持网络安装windows。该工具使用python开发,小巧轻便(才15k行代码),使用简单的命令即可完成PXE网络安装环境的配置,同时还可以管理DHCP,DNS,以及yum包镜像。OpenQRM
openQRM提供开放的插件管理架构,你可用很轻松的将现有的数据中心应用程序集成到其中,比如Nagios和VMware。openQRM的自动化数据中心操作不但可用帮助你提高可用性,同时还可以降低您企业级数据中心的管理费用。针对数据中心管理的开源平台,针对设备的部署、监控等多个方面通过可插拔式架构实现自动化的目的,尤其面向云计算/基于虚拟化的业务。Spacewalk
Spacewalk可管理Fedora、红帽、CentOS、SUSE与Debian Linux服务器。当你的数据中心拥有多台Linux服务器时,手动管理将不再是一个好的选择。Spacewalk就可以管理补丁、登录、更新。
[b]在自动化运维和大数据云计算时代实现预设自动化安装服务器环境、应用环境等不仅可以提高运维效率,而且还能大大减少运维的工作任务及出错概率。尤其是对于在服务器数量按几百台、几千台增加的公司而言,单单是装系统,如果不通过自动化来完成,其工作量和周期不可想象。[/b]2、配置管理类工具:前浪:Chef
Chef是一个系统集成框架,可以用Ruby等代码完成服务器的管理配置并编写自己的库。ControlTier
ControlTier是一个完全开放源码系统的自动化服务管理活动的多个服务器和多个应用层(代码,数据,配置和内容) 。共同使用的ControlTier包括部署应用程序,控制它们的状态,并运行按需行政工作在多个服务器上。ControlTier是跨平台和工程同样的物理服务器,虚拟机,或云计算基础设施。Func
Func是由红帽子公司以Fedora统一网络控制器Func,目的是为了解决这一系列统一管理监控问题而设计开发的系统管理基础框架,它是一个能有效的简化我们众多服务器系统管理工作的工具,其具备容易学习,容易使用,更容易扩展;功能强大而且配置简单等优点。Puppet
puppet是一个开源的软件自动化配置和部署工具,它使用简单且功能强大,正得到了越来越多地关注,现在很多大型IT公司均在使用puppet对集群中的软件进行管理和部署。后浪SaltStack
Salt一种全新的基础设施管理方式,部署轻松,在几分钟内可运行起来,扩展性好,很容易管理上万台服务器,速度够快,服务器之间秒级通讯。Ansible
Ansible是新出现的运维工具是基于Python研发的糅合了众多老牌运维工具的优点实现了批量操作系统配置、批量程序的部署、批量运行命令等功能。
[b]在进行大规模部署时,手工配置服务器环境是不现实的,这时必须借助于自动化部署工具。[/b]3、监控类工具Nagios
Nagios是一款免费的开源IT基础设施监控系统,其功能强大,灵活性强,能有效监控 Windows 、Linux、VMware 和 Unix 主机状态,交换机、路由器等网络设置等。一旦主机或服务状态出现异常时,会发出邮件或短信报警第一时间通知 IT 运营人员,在状态恢复后发出正常的邮件或短信通知。OpenNMS
OpenNMS是一个网络管理应用平台,可以自动识别网络服务,事件管理与警报,性能测量等任务。Cacti
Cacti是一套基于PHP、MySQL、SNMP及RRDTool开发的网络流量监测图形分析工具。它通过snmpget来获取数据,使用 RRDtool绘画图形,它的界面非常漂亮,能让你根本无需明白rrdtool的参数能轻易的绘出漂亮的图形。而且你完全可以不需要了解RRDtool复杂的参数。它提供了非常强大的数据和用户管理功能,可以指定每一个用户能查看树状结 构、host以及任何一张图,还可以与LDAP结合进行用户验证,同时也能自己增加模板,让你添加自己的snmp_query和script!功能非常强大完善,界面友好。Zenoss Core
一个基于Zope应用服务器的应用/服务器/网络管理平台,提供了Web管理界面,可监控可用性、配置、性能和各种事件。Zabbix
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。用于监控网络上的服务器/服务以及其他网络设备状态的网络管理系统,后台基于C,前台由PHP编写,可与多种数据库搭配使用。提供各种实时报警机制。Ganglia
Ganglia是一个针对高性能分布式系统(例如,集群、网格、云计算等)所设计的可扩展监控系统。该系统基于一个分层的体系结构,并能够支持2000个节点的集群。它允许用户能够远程监控系统的实时或历史统计数据,包括:CPU负载均衡、网络利用率等。Ganglia依赖于一个基于组播的监听/发布协议来监控集群的状态。Ganglia系统的实现综合了多种技术,包括:XML(数据描述)、XDR(紧凑便携式数据传输)、RRDtool(数据存储和可视化)等。
[b]数据监控和业务监控非常关键,及时发现问题,及时解决问题,监控系统主要包括:服务应用监控、主机监控、网络设备监控、网络连通性监控、网络访问质量监控、分布式系统监控、报警预设、监控图形化与历史数据等。[/b]

自动化对运维的意义
自动化就是运维为了减少重复枯燥的工作而建立的流程方法,而除此之外,自动化还能够带来减少人为错误、及时报警与故障恢复、提高业务可用性等好处。
运维工作自动化确实包含上述2个方面,归纳总结来其实就是:把零碎的工作集中化,把复杂的工作简单有序化,把流程规范化,最大化地解放生产力,也就是解放运维人员。自动化的技能/意识对于运维工作至关重要。运维工作不是简单的使用工具,这里面还有很多技巧和意识。具体的技巧/意识包括:[list=1][]如何驾驭这些琳琅满目的工具为己所用;[/][]如何根据不同的应用环境来选用不同的工具;[/][]如何根据应用来组合使用工具等等等等。[/]
一定要记住一点:工具只是利用帮助人进行运维的,这中间还需要人的干预和决策,工具不能完全代替全部运维工作。还需要结合实际业务逻辑和业务场景,就像架构一样,并不是淘宝、百度等大公司的架构,一定适合任何公司和业务。
自动化运维范畴
- []安装自动化[/][]部署自动化[/][]监控自动化[/][]发布自动化[/][]升级自动化[/][]安全管控自动化[/][]优化自动化[/][]数据备份自动化[/]
前阶段在自动化管理和安全方面的技术实现,比如说HP和IBM出品的一些ITIL和ITSM产品等,比如HP Openview,IBM Tivoli等等。这些工具都有Linux的版本,与其他同类工具相比的优势应该在于他们的商业应用成熟度,都是老品牌。现阶段有自动化的一些工具git、svn、Jenkins等等,一些开源的软件!
工具选择
针对不同规模的架构,一个小规模的网站,到百万量级、千万量级的网站,我们选择的工具就有不同。
在选择上对于百万量级、千万量级的网站,我们应该考虑选择成熟的工具、性能高的工具、熟悉的工具。而对于小规模的网站,我们应该考虑选择一些开源的、免费的工具。
这个原则就是以应用为导向,百万量级、千万量级的网站牵涉的面广、要求高,不成熟的工具往往很难说服领导和公司使用,所以主要是在成熟度方面。
自动化运维规划
自动化的实现不是单纯学习几个工具就能够做好的,甚至于规划不好的情况,自动化不仅没有节省人力,反而带来了更多的问题。所以运维人员在考虑自动化流程的过程中应该考虑如下几点原则:[list=1][]根据应用选择工具;[/][]对于关键应用,选择成熟度高的工具;[/][]不能过分依赖一种工具,需要进行对比和分析;[/][]对工具的特性做到精通;[/][]是人驾驭工具,人要监督工具,而不是工具来驾驭人;[/][]善于利用脚本实现定制化场景。[/]
[list=1][]经常逛逛一些不错的IT媒体网站和看看这方面的文章,可以多多涉猎和学习;[/][]针对公司业务场景,选择一些自动化工具,登陆到官网学习和熟悉工作原理;[/][]经常参加一些线下自动化运维的活动和媒体活动,多和一些自动化方面的大拿和资深人士交流。[/]自动化经验积累
10个强大的DevOps基础设施自动化工具
运维 空心菜 发表了文章 0 个评论 8011 次浏览 2015-12-07 01:45

Devops基础设施自动化的工具
有许多工具用于基础设施自动化。决定使用哪个工具的体系结构和基础设施的需求。下面我们列出了一些伟大的工具,受到不同类别配置管理、编制、持续集成、监控、等。
1、Chef

Chef是一个基于ruby开发的配置管理工具。你可能会遇到“基础设施代码”这个词,这意味着配置管理。厨师烹饪书的概念,你的代码基础设施DSL(领域特定语言)和一个小的编程。chef规定和配置虚拟机根据规则中提到的食谱。代理将会运行在所有的服务器配置。代理将chef主服务器的cookbooks,在服务器上运行这些配置来达到理想的状态。
2、Puppet

Puppet也基于ruby编写的配置管理工具跟chef一样。配置代码编写使用puppet DSL和封装在模块。而chef更以开发人员为中心,puppet是由系统管理员控制为中心。puppet proxy运行在所有服务器配置,它把编译模块从puppet服务器和安装所需要的软件包中指定模块。

Saltstack是一个基于python打开配置管理工具。不像chef和puppet,Saltstack支持远程执行的命令。通常在chef和puppet,配置的代码将从服务器,在Saltstack,代码可以同时被推到许多节点。编译的代码和配置是Saltstack非常快。
4、Ansible

Ansible是一个缺少代理配置管理以及编制工具。在Ansible配置模块中被称为“剧本”。剧本都写在YAML格式和它相对容易写相比其他配置管理工具。像其他工具,Ansible可用于云配置。
5、Juju

Juju是由典型的基于Python的编排工具。它已经在你的云环境应用程序的伟大的UI。你也可以使用命令行界面来完成所有的业务流程的任务。你可以配置,部署和使用且具规模的应用。
6、 Jenkins

Jenkins是一个基于java的持续集成工具更快的应用程序。Jenkins必须关联到一个版本控制系统如github或SVN。每当新代码被推到代码库,詹金斯服务器将构建和测试新代码和通知团队的结果和变化。
7、 Vagrant

vagrant是一个伟大的工具为开发环境配置虚拟机。vagrant的上面运行的VM虚拟框和流浪的解决方案。它使用一个配置文件叫做Vagrantfile,其中包含所需的所有配置VM。一旦创建了一个虚拟机,它可以与其他开发人员共享相同的开发环境。vagrant有云配置插件,配置管理工具(chef、puppet等)和docker。
8、Docker

Docker是一个自动化工具之上的Linux容器(LXC)。它工作在流程级别虚拟化的概念。Docker创造了孤立的环境称为应用程序容器。这些容器可以运往其他服务器无需更改应用程序。Docker被认为是虚拟化的下一步。码头工人有一个巨大的开发者社区,它是获得巨大的声望在Devops从业者和云计算的先驱。

New relic的基于云的解决方案(SaaS)应用程序监视。它支持各种应用程序的监控像Php、Ruby、Java、NodeJS等等。它给你实时的见解关于您的运行应用程序中。new relic的代理应该配置在应用程序中获得实时数据。New relic使用各种指标提供有价值的见解关于应用程序监控。
10、Sensu

Sensu是一个开放源码监视框架用Ruby编写的。Sensu是一个监控工具专门建立云环境。它可以很容易地部署使用工具如chef和puppet。Sensu也有一个企业版的监控。英文原文链接:http://devopscube.com/devops-tools-for-infrastructure-automation/
什么是CICD
运维 OS小编 发表了文章 0 个评论 2428 次浏览 2021-05-15 15:27
传统的应用发布模式
如果你经历体验过传统的应用发布,你可能就会觉得CICD有足够吸引你的地方,反之亦然。一般一个研发体系中都会存在多个角色:开发、测试、运维。当时我们的应用发布模式可以能是这样的:
- 开发团队在开发环境中完成软件开发,单元测试,测试通过,提交到代码版本管理库;
- 开发同学通知运维同学项目可以发布了,然后运维同学下载代码进行打包和构建,生成应用制品;
- 运维同学使用部署脚本将生成的制品部署到测试环境,并提示测试同学可以进行产品的测试;
- 测试同学开始进行手动、自动化测试,测试完成后提醒运维同学可以进行预生产环境部署;
- 运维同学开始进行预生产环境部署,然后测试同学进行测试,测试完成后,开始部署生产环境。
当然我描述的可能只是其中的一部分,手动操作很多、出现的问题很多。上面看似很流畅的过程,其实每次构建或发布都可能会出现问题。未对每次提交验证、构建环境不一致:开发人员本地测试成功后提交代码,运维同学下载代码进行编译却出现了错误。
存在的问题:
- 错误发现不及时: 很多错误在项目的早期可能就存在,到最后集成的时候才发现问题;
- 人工低级错误发生: 产品和服务交付中的关键活动全都需要手动操作;
- 团队工作效率低: 需要等待他人的工作完成后才能进行自己的工作;
- 开发运维对立: 开发人员想要快速更新,运维人员追求稳定,各自的针对的方向不同。
经过上述问题我们需要作出改变,如何改变?
什么是CICD
软件开发的连续方法基于自动执行脚本,以最大程度地减少在开发应用程序时引入错误的机会。从开发新代码到部署新代码,他们几乎不需要人工干预,甚至根本不需要干预。
它涉及到在每次小的迭代中就不断地构建,测试和部署代码更改,从而减少了基于错误或失败的先前版本开发新代码的机会。
此方法有三种主要方法,每种方法都将根据最适合您的策略的方式进行应用。
持续集成 CI(Continuous Integration)
在传统软件开发过程中,集成通常发生在每个人都完成了各自的工作之后。在项目尾声阶段,通常集成还要痛苦的花费数周或者数月的时间来完成。持续集成是一个将集成提前至开发周期的早期阶段的实践方式,让构建、测试和集成代码更经常反复地发生。
开发人员通常使用一种叫做CI Server的工具来做构建和集成。持续集成要求史蒂夫和安妮能够自测代码。分别测试各自代码来保证它能够正常工作,这些测试通常被称为单元测试(Unit tests)。
代码集成以后,当所有的单元测试通过,史蒂夫和安妮就得到了一个绿色构建(Green Build)。这表明他们已经成功地集成在一起,代码正按照测试预期地在工作。然而,尽管集成代码能够成功地一起工作了,它仍未为生产做好准备,因为它没有在类似生产的环境中测试和工作。
CI是需要对开发人员每次的代码提交进行构建测试验证。确定每次提交的代码都是可以正常编译测试通过的。在没有持续集成服务器的时候,我们可以写一个程序来监听版本控制系统的状态,当出现了push动作则触发相应的脚本运行编译构建等步骤。现在有了专业的持续集成服务器后,我们借助持续集成服务器来实现版本控制系统中代码提交触发构建测试等验证步骤。
持续合并开发人员正在开发编写的所有代码的一种做法。通常一天内进行多次合并和提交代码,从存储库或生产环境中进行构建和自动化测试,以确保没有集成问题并及早发现任何问题。
开发人员提交代码的时候一般先在本地测试验证,只要开发人员提交代码到版本控制系统就会触发一条提交流水线,对本次提交进行验证。
持续交付 CD (Continuous Delivery)
Continuous Delivery (CD) 持续交付是持续集成的延伸,将集成后的代码部署到类生产环境,确保可以以可持续的方式快速向客户发布新的更改。如果代码没有问题,可以继续手工部署到生产环境中。
持续交付CD:是基于持续集成的基础上,将集成后的代码自动化的发布到各个环境中测试(DEV TEST UAT STAG),确定可以发布生产版本。这里我们可以借用制品库实现制品的管理,根据环境类型创建对应的制品库。一次构建,到处运行。
- 开发环境发布:我们可以将开发环境产出的制品部署进行测试,没有问题后上传到测试环境的制品库中。
- 测试环境发布:此时通知测试人员可以进行测试环境发布测试,获取测试环境制品库中的制品,发布到测试环境验证。验证通过将制品上传到预生产环境制品库。
- 预生产环境发布:获取预生产环境制品,进行部署测试。测试成功后可以将制品上传到生产库中。
- 手动部署生产环境。
持续交付是超越持续集成的一步。不仅会在推送到代码库的每次代码更改时都进行构建和测试,而且,作为附加步骤,即使部署是手动触发的,它也可以连续部署。此方法可确保自动检查代码,但需要人工干预才能从策略上手动触发更改的部署。
持续部署 CD(Continuous Deploy)
如果真的想获得持续交付的好处,应该尽早部署到生产环境,以确保可以小批次发布,在发生问题时可以轻松排除故障。于是有了持续部署。
通常可以通过将更改自动推送到发布系统来随时将软件发布到生产环境中。持续部署 会更进一步,并自动将更改推送到生产中。类似于持续交付,持续部署也是超越持续集成的进一步。不同之处在于,您无需将其手动部署,而是将其设置为自动部署。部署您的应用程序完全不需要人工干预。
持续部署CD:是基于持续交付的基础上,将在各个环境经过测试的应用自动化部署到生产环境。其实各个环境的发布过程都是一样的。应用发布到生产环境后,我们需要对应用进行健康检查、添加应用的监控项、 应用日志管理。
我们通常将这个在不同环境发布和测试的过程叫做部署流水线, 持续部署是在持续交付的基础上,把部署到生产环境的过程自动化。
参考:
https://blog.csdn.net/weixin_40046357/article/details/107478696
http://www.idevops.site/gitlabci/chapter01/01/
https://www.jianshu.com/p/654505d42180
fir.im持续集成技术实践
运维 OS小编 发表了文章 0 个评论 2611 次浏览 2017-11-15 21:20
持续集成做什么
持续集成的概念出现在 2001 年,它其实是一个 XP 极限编程的工程实践。那么持续的是什么,集成是什么呢,非常简单就是“一直不停地集成代码”。
持续集成是把代码频繁的合并到主干,通过自动构建的方式验证软件的质量,让团队快速的响应质量,快速的修复问题,快速的给客户解决问题,快速地交付更好的软件质量。
我们为什么要做持续集成
开发人员对下面的软件开发场景很熟悉,比如:
- 场景一:开发了新功能,老功能产生新的 bug;
- 场景二:修好一个 bug,又产生其他 bug,甚至出现连环 bug;
- 场景三:出现的 bug 比较多,修改代码要很谨慎,不熟悉的模块一般不敢动,怕引起问题;
如上面所说,持续集成不能消除 bug ,但能更容易地发现 bug,更快速地修复,提升产品质量。那么,持续集成能给我们带来哪些价值?“Continuous Integration doesn’t get rid of bugs, but it does make them dramatically easier to find and remove.” — Martin Fowler
拿每个产品开发都会遇到的 login 功能开发举例,当填完的用户名和密码传到数据库,做完验证后给用户返回一个结果。那什么是一个原子提交?比如,提交验证一个用户名,这是一个完整的 feature ;验证密码是否符合格式(6位/8位),这也是一个完整的 feature ;当我验证完用户名和密码后再传到数据库之后,查询正确与否,这也是一个完整的 feature ;保证每次提交是一个完整的 feature 或修复了一个 bug,不要代码写成半截。持续集成系统这里讲的是狭义的持续集成系统,通常的 CI 系统收到提交之后会触发构建,构建会有信息返回比如 commit id 、commit 信息、代码变更等,收到代码提交后会触发自动构建,接着安装依赖进行编译,并触发质量保证流程,也就是说自动化测试集。当代码变动你想创建提交时,这个提交应该尽可能的小量,并且包含一个不可分割的特性(feature)、修复(fix)或优化(improved)。
- Trello 看板;
- 三个环境(类生产环境,测试环境,生产环境);
- CI 工具(Jenkins/flow.ci)
整个团队的构建频率可以看下这张图:我们会做代码 review ,当 feature 分支提 pr 到 develop 分支上,这样 develop 分支的构建条件是:当收到 pr 之后,开始跑持续集成。假如部署完成整个测试跑过了产品经理验收之后,没毛病了,终于可以发布了到 master 分支。
- 最初阶段:提交代码-自动部署;
- 一般进阶:提交代码-代码静态分析-自动部署,最简单先再加入代码静态分析;
- 高级进阶:提交代码-代码静态分析-自动化测试集-自动部署;
- 测试异常——不仅仅测试正确情况,也要主动测试异常;
- 减少耦合——保证独立的可测试性;
- 功能分离——单元测试流太长,超过 20 分钟的话要详细想一下如何将功能单独拆开,效率更高;
- 测试=需求——从测试代码看到每个 class 是干什么的,同时出现 bug 时,第一时间是看测试,想想如何从测试中复现;
Step 3. 验收测试
验收测试是端对端的测试,从收到用户名密码到返回结果,是不是我们所期望的一个值,这是验收 Acceptance Test,其实是验收了整个功能。代码静态检查和单元测试,保证了我们如何怎么去写代码,验收测试保证了写正确代码,符合开发需求。
flow.ci 做验收测试比较多,用的是比较流行的框架 Cucumber + Selenium WebDriver,目前支持 3 种数据库,5 种 git 仓库,7 种 开发语言跑在 docker 容器云上,支持 iOS 构建跑在 mac 机器上,要保证这些排列组合正常运行,这是 flow.ci 做验收测试最核心的价值。
其实,持续集成是一个工作流,当 push 代码的时候才会 run 起来,但是 flow.ci 本身系统也有外部依赖的特殊性,会依赖一些第三方的 sevice(比如 GitHub/GitLab 等),验收测试应该一直保持不断地运行,也可以叫持续测试吧。因为我们永远不能保证第三方的 api 会不会改变:)
Step 4. 性能测试
我们的性能测试做的比较简单,主要测试 api.因为 fir.im 做 app 的内测分发,我们需要性能测试保证 app 上传下载的正常稳定。性能测试是单用户的,压力测试是多用户的,这是两者之间的区别。
性能测试会有一些不确定性,有很多系统会产生缓存。flow.ci 的性能测试跑在 docker 上,是一个干净独立的环境,需要让系统预热运行一下。Locust/JMeter/LoadRunner是目前比较流行的性能测试工具。 flow.ci 目前用的是 locust,可以参考一下。
持续集成的可视化、数据分析
说到数据统计分析,整个 ci 流程跑下来产生的很多数据也非常有挖掘的价值。比如,对于代码静态分析有多少 Offence、Risk、Bug,对于单元测试有失败率、测试覆盖率;对于验收测试或性能测试有多少的失败率,这些数据都有可能成为衡量一个程序员的标准。
结语
CI 就像盖楼房的脚手架一样,没有脚手架就没办法盖出一个足够高的楼,没有 CI 就无法交付质量足够好的软件!
理解持续集成、持续交付、持续部署
运维 OS小编 发表了文章 0 个评论 2612 次浏览 2017-11-15 00:14
持续集成
持续集成强调开发人员提交了新代码之后,立刻进行构建、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起。
持续交付
持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」(production-like environments)中。比如,我们完成单元测试后,可以把代码部署到连接数据库的 Staging 环境中更多的测试。如果代码没有问题,可以继续手动部署到生产环境中。
持续部署
持续部署则是在持续交付的基础上,把部署到生产环境的过程自动化。我个人觉得持续集成、持续交付、持续部署非常值得推广。开发过程中最怕集成时遇到问题导致返工,而持续集成、持续交付、持续部署恰恰可以早发现早解决,从而可以避免这个问题。
参考:https://www.mindtheproduct.com/2016/02/what-the-hell-are-ci-cd-and-devops-a-cheatsheet-for-the-rest-of-us/
谈谈持续集成、持续交付、持续部署之间的区别
运维 OS小编 发表了文章 0 个评论 2564 次浏览 2017-11-14 22:50
假如把开发工作流程分为以下几个阶段:
编码 ---> 构建 ---> 集成 ---> 测试 ---> 交付 ---> 部署
正如你在上图中看到,「持续集成(Continuous Integration)」、「持续交付(Continuous Delivery)」和「持续部署(Continuous Deployment)」有着不同的软件自动化交付周期。
持续集成
持续集成是指软件个人研发的部分向软件整体部分交付,频繁进行集成以便更快地发现其中的错误。“持续集成”源自于极限编程(XP),是 XP 最初的 12 种实践之一。
CI 需要具备这些:
- 全面的自动化测试: 这是实践持续集成&持续部署的基础,同时,选择合适的自动化测试工具也极其重要;
- 灵活的基础设施: 容器,虚拟机的存在让开发人员和 QA 人员不必再大费周折;
- 版本控制工具: 如 Git,CVS,SVN 等;
- 自动化的构建和软件发布流程的工具,如 Jenkins,flow.ci;
- 反馈机制: 如构建/测试的失败,可以快速地反馈到相关负责人,以尽快解决达到一个更稳定的版本。
- “快速失败”,在对产品没有风险的情况下进行测试,并快速响应;
- 最大限度地减少风险,降低修复错误代码的成本;
- 将重复性的手工流程自动化,让工程师更加专注于代码;
- 保持频繁部署,快速生成可部署的软件;
- 提高项目的能见度,方便团队成员了解项目的进度和成熟度;
- 增强开发人员对软件产品的信心,帮助建立更好的工程师文化。
- 快速发布。能够应对业务需求,并更快地实现软件价值。
- 编码->测试->上线->交付的频繁迭代周期缩短,同时获得迅速反馈;
- 高质量的软件发布标准。整个交付过程标准化、可重复、可靠,
- 整个交付过程进度可视化,方便团队人员了解项目成熟度;
- 更先进的团队协作方式。从需求分析、产品的用户体验到交互 设计、开发、测试、运维等角色密切协作,相比于传统的瀑布式软件团队,更少浪费。
持续部署
持续部署是指当交付的代码通过评审之后,自动部署到生产环境中。持续部署是持续交付的最高阶段。这意味着,所有通过了一系列的自动化测试的改动都将自动部署到生产环境。它也可以被称为“Continuous Release”。
为什么说持续部署是理想的工作流程?
“开发人员提交代码,持续集成服务器获取代码,执行单元测试,根据测试结果决定是否部署到预演环境,如果成功部署到预演环境,进行整体验收测试,如果测试通过,自动部署到产品环境,全程自动化高效运转。”
实际上,产品在从需求到部署的过程中,会经历若干种不同的环境,例如 QA 环境、各种自动化测试运行环境、生产环境等。这些环境的搭建、配置、管理,产品在不同环 境中的具体部署,状况是比较非常复杂的,从头到尾地全自动持续部署的确困难。那么,如果能做到持续交付,保证代码在模拟环境没问题,也许团队成员做到真正的心理有数。
持续部署的优点:
持续部署主要好处是,可以相对独立地部署新的功能,并能快速地收集真实用户的反馈。
“You build it, you run it”,这是 Amazon 一年可以完成 5000 万次部署,平均每个工程师每天部署超过 50 次的核心秘籍。
最后
「持续集成(Continuous Integration)」、「持续交付(Continuous Delivery)」和「持续部署(Continuous Deployment)」提供了一个优秀的 DevOps 环境,对于整个团队来说,好处与挑战并行。无论如何,频繁部署、快速交付以及开发测试流程自动化都将成为未来软件工程的重要组成部分。
分享阅读链接:http://www.jianshu.com/p/2c6ebe34744a
來源:简书
DevOps详解
运维 OS小编 发表了文章 0 个评论 2555 次浏览 2017-07-18 00:04
这样的看法甚至让我感觉有些气愤。DevOps在我看来极为重要,过去15年来,我一直在大型机构,主要是大型金融机构中从事工程业务。DevOps是一种非常重要的方法论,该方法将解决一些最大型问题的基本原则和实践恰如其分地融为一体,很好地解决了此类机构的软件开发项目中一种最令人感觉悲凉的失败要素:开发者和运维人员之间的混乱之墙。
请不要误会我的这种观点,除了某些XP实践,大部分此类大型机构对敏捷开发方法论的运用还有很长的路要走,同时还有很多其他原因会导致软件开发项目的失败或延误。
但在我看来,混乱之墙目前依然是他们所面临的最令人沮丧、最浪费时间、同时也相当愚蠢的问题。
与其独自生闷气,我觉得不如说点更实在的东西,写一篇尽可能精准的文章,向大家介绍DevOps到底是什么,能为我们带来什么。长话短说,DevOps并不是某一套工具。DevOps是一种方法论,其中包含一系列基本原则和实践,仅此而已。而所用的工具(或者说“工具链”吧,毕竟用于为这些实践提供支持的工具集有着极高的扩展性)只是为了对这样的实践提供支持。
最终来说,这些工具本身并不重要。相比两年前,目前的DevOps工具链已经产生了翻天覆地的变化,可想而知,两年后还会产生更大的差异。不过这并不重要。重要的是能够合理地理解这些基本原则和实践。
本文并不准备介绍某些工具链,甚至完全不会提到这些工具。网上讨论DevOps工具链的文章已经太多了。我想在本文中谈谈最基本的原则和实践,它们的主要目的,毕竟这些才是对我而言最重要的。
DevOps是一种方法论,归纳总结了面临独一无二的机遇和强有力需求的网络巨头们,结合自身业务本质构思出全新工作方式的过程中所采用的实践,而他们的业务需求也很直接:以史无前例的节奏对自己的系统进行演进,有时候可能还需要以天为单位对系统或业务进行扩展。
虽然DevOps对初创公司来说很明显是不可或缺的,但我认为那些有着庞大的老式IT部门的大企业才是能从这些基本原则和实践中获得最大收益的。本文将试图解释得出这个结论的原因和实现方法。
本文的部分内容已发布为Slideshare演示幻灯片,可在这里浏览:http://www.slideshare.net/JrmeKehrli/devops-explained-72091158
目录
1. 简介
DevOps所关注的不是工具本身,也不是对chef或Docker的掌握程度。DevOps是一种方法论,是一系列可以帮助开发者和运维人员在实现各自目标(Goal)的前提下,向自己的客户或用户交付最大化价值及最高质量成果的基本原则和实践。
开发者和运维人员之间最大的问题在于:虽然都是企业中大型IT部门不可或缺的,但他们有着截然不同的目的(Objective)。
开发者和运维人员之间目的上的差异就叫做混乱之墙。下文会介绍这个概念的准确定义,以及为什么我认为这种状况很严峻并且很糟糕。
DevOps是一种融合了一系列基本原则和实践的方法论(并从这些实践中派生出了各种工具),意在帮助这些人员向着一个统一的共同目的努力:尽可能为公司提供更多价值。
令人惊奇的是,这个问题竟然有一个非常简单的“银子弹”:让生产端变得敏捷起来!
而这恰恰正是DevOps所要达成的唯一目标!
但在进一步讨论这一点之前,首先需要谈谈其他几件事。
1.1 管理信条
喜欢 | 作者 Jerome Kehrli ,译者 大愚若智 发布于 2017年4月24日. 估计阅读时间: 1 分钟 | 智能化运维、Serverless、DevOps......2017年有哪些最新运维技术趋势?CNUTCon即将为你揭秘!1 讨论分享到:微博微信FacebookTwitter有道云笔记邮件分享
稍后阅读
我的阅读清单
最近我阅读了很多有关DevOps的文章,其中一些非常有趣,然而一些内容也很欠考虑。貌似很多人越来越坚定地在DevOps与chef、puppet或Docker容器的熟练运用方面划了等号。对此我有不同看法。DevOps的范畴远远超过puppet或Docker等工具。
这样的看法甚至让我感觉有些气愤。DevOps在我看来极为重要,过去15年来,我一直在大型机构,主要是大型金融机构中从事工程业务。DevOps是一种非常重要的方法论,该方法将解决一些最大型问题的基本原则和实践恰如其分地融为一体,很好地解决了此类机构的软件开发项目中一种最令人感觉悲凉的失败要素:开发者和运维人员之间的混乱之墙。
请不要误会我的这种观点,除了某些XP实践,大部分此类大型机构对敏捷开发方法论的运用还有很长的路要走,同时还有很多其他原因会导致软件开发项目的失败或延误。
相关厂商内容
聊聊容器编排与管理的挑战
智能化运维技术详解
机器学习模型训练的Kubernetes实践
京东物流系统自动化运维平台技术揭密
基于资产配置业务场景下的全链路监控平台
相关赞助商
CNUTCon全球运维技术大会,9月10日-9月11日,上海·光大会展中心大酒店,精彩内容抢先看
但在我看来,混乱之墙目前依然是他们所面临的最令人沮丧、最浪费时间、同时也相当愚蠢的问题。
与其独自生闷气,我觉得不如说点更实在的东西,写一篇尽可能精准的文章,向大家介绍DevOps到底是什么,能为我们带来什么。长话短说,DevOps并不是某一套工具。DevOps是一种方法论,其中包含一系列基本原则和实践,仅此而已。而所用的工具(或者说“工具链”吧,毕竟用于为这些实践提供支持的工具集有着极高的扩展性)只是为了对这样的实践提供支持。
最终来说,这些工具本身并不重要。相比两年前,目前的DevOps工具链已经产生了翻天覆地的变化,可想而知,两年后还会产生更大的差异。不过这并不重要。重要的是能够合理地理解这些基本原则和实践。
本文并不准备介绍某些工具链,甚至完全不会提到这些工具。网上讨论DevOps工具链的文章已经太多了。我想在本文中谈谈最基本的原则和实践,它们的主要目的,毕竟这些才是对我而言最重要的。
DevOps是一种方法论,归纳总结了面临独一无二的机遇和强有力需求的网络巨头们,结合自身业务本质构思出全新工作方式的过程中所采用的实践,而他们的业务需求也很直接:以史无前例的节奏对自己的系统进行演进,有时候可能还需要以天为单位对系统或业务进行扩展。
虽然DevOps对初创公司来说很明显是不可或缺的,但我认为那些有着庞大的老式IT部门的大企业才是能从这些基本原则和实践中获得最大收益的。本文将试图解释得出这个结论的原因和实现方法。
本文的部分内容已发布为Slideshare演示幻灯片,可在这里浏览:http://www.slideshare.net/JrmeKehrli/devops-explained-72091158
目录1. 简介 1.1 管理信条 1.2 一个典型的IT组织 1.3 运维人员测挫败感 1.4 基础架构自动化 1.5 DevOps:仅此一次,一颗神奇的银子弹 2. 基础架构即代码 2.1 概述 2.2 DevOps工具链 2.3 收益 3. 持续交付 3.1 从实践中学习 3.2 自动化 3.3 更频繁的部署 3.4 持续交付的前提需求 3.5 零停机部署 4. 协作 4.1 混乱之墙 4.2 软件开发流程 4.3 共享工具 4.4 协同工作 5. 结论1. 简介
DevOps所关注的不是工具本身,也不是对chef或Docker的掌握程度。DevOps是一种方法论,是一系列可以帮助开发者和运维人员在实现各自目标(Goal)的前提下,向自己的客户或用户交付最大化价值及最高质量成果的基本原则和实践。
开发者和运维人员之间最大的问题在于:虽然都是企业中大型IT部门不可或缺的,但他们有着截然不同的目的(Objective)。
开发者和运维人员之间目的上的差异就叫做混乱之墙。下文会介绍这个概念的准确定义,以及为什么我认为这种状况很严峻并且很糟糕。
DevOps是一种融合了一系列基本原则和实践的方法论(并从这些实践中派生出了各种工具),意在帮助这些人员向着一个统一的共同目的努力:尽可能为公司提供更多价值。
令人惊奇的是,这个问题竟然有一个非常简单的“银子弹”:让生产端变得敏捷起来!
而这恰恰正是DevOps所要达成的唯一目标!
但在进一步讨论这一点之前,首先需要谈谈其他几件事。
1.1 管理信条
IT管理这场战争的原动力到底是什么?换句话说,在软件开发项目中,管理工作首要的,以及最重要的目的是什么?
有什么想法吗?
我来提供一个线索吧:在建立一家初创公司时,最重要的事情是什么?
当然是要加快上市时间(TTM)!
上市时间(即TTM)是指一件产品从最初的构思到最终可供用户使用或购买这一过程所需要的时间。对于产品很快会过时的行业,TTM是一个非常重要的概念。
在软件工程方面,所采用的方法、业务,以及具体技术几乎每年都会变化,因而TTM就成了一个非常重要的KPI(关键绩效指标)。
TTM通常也会被叫做前置时间(Lead Time)。
第一个问题在于,(很多人认为)在开发过程中TTM和产品质量是两个对立的属性。在下文可以看到,改善质量(进而提高稳定性)是运维人员的目的,而开发者的目的在于降低前置时间(进而提高TTM)。
请容我来解释一下。
IT组织或部门通常会通过两个关键的KPI进行评估:软件本身的质量,因而需要尽可能减少缺陷的数量;此外还有TTM,因而需要将业务构想(通常由业务用户提供)变为最终成果,并以尽可能快的速度提供给用户或客户。
这里的问题在于,大部分情况下这两个截然不同的目的是由两个不同团队提供支持的:负责构建软件的开发者,以及负责运行软件的运维人员。
1.2 一个典型的IT组织
在组织内部负责管理重要IT部门的典型IT组织通常看起来是这样的:
主要由于历史的原因(大部分运维人员来自硬件和电信业务领域),运维人员和开发者分属不同的组织结构分支。开发者属于研发部门,而运维人员大部分时候属于基础架构部门(或专门的运维部门)。
别忘了,他们有着不同的目的:
此外作为旁注,这两个团队有时候会使用不同的预算来运营。开发团队使用构建(Build)预算,运维团队使用运营(Run)预算。不同的预算,对控制权越来越高的需求,以及企业IT成本的缩水,这些因素结合在一起会进一步放大两个团队各自目的的对立性。
(依本人愚见,时至今日,随着人与人之间无时无刻随时随地进行的交互,以及由不同目的推动着企业和社会进行数字化转型,IT预算方面古老的“规划/构建/运行”框架已经不那么合理了,不过这又是另一回事了。)
1.3 运维人员测挫败感
接下来看看运维人员,一起看看典型的运维团队把大部分时间都花在哪里了:
来源:Study from Deepak Patil [Microsoft Global Foundation Services] in 2006, via James Hamilton [Amazon Web Services
生产团队有将近一半(47%)的时间花在了与部署有关的工作中:
- 执行实际的部署工作,或修复与部署工作有关的问题
- 只需手工运行5条命令的情况下,成功部署的概率就已跌至86%。
- 如需手工运行55条命令,成功部署的概率将跌至22%。
- 如需手工运行100条命令,成功部署的概率将趋近于0(仅2%)!
- Facebook有数千名开发和运维人员,成千上万台服务器。平均来说一位运维人员负责500台服务器(还认为自动化是可选的吗?)他们每天部署两次(环式部署,Deployment ring的概念)。
- Flickr每天部署10次。
- Netflix明确针对失败进行各种设计!他们的软件按照设计从最底层即可容忍系统失败,他们会在生产环境中进行全面的测试:每天通过随机关闭虚拟机的方式在生产环境中执行65000次失败测试…… 并确保这种情况下一切依然可以正常工作。
- 编码:代码开发和审阅,版本控制工具、代码合并工具
- 构建:持续集成工具、构建状态统计工具
- 测试:通过测试和结果确定绩效的工具
- 打包:成品仓库、应用程序部署前暂存
- 发布:变更管理、发布审批、发布自动化
- 配置:基础架构配置和部署,基础架构即代码工具
- 监视:应用程序性能监视、最终用户体验
- 可重复性与可靠性:时至今日,构建生产用计算机只需要运行脚本或必要的puppet命令即可。通过恰当地使用Docker容器或Vagrant虚拟机,只需运行一条命令即可配置好包含操作系统层以及所需软件和配置的生产用计算机。当然,随着各种变更或软件开发、持续集成,并自动测试,这套构建脚本或机制也会进行持续集成。
- 生产力:一键部署,一键供应,一键创建新环境……整个生产环境可以通过一条命令或一键点击的方式创建。这样的一条命令也许会运行长达数小时,但在这过程中运维人员可以从事其他更有趣的工作,而无需等待一条命令执行完毕后继续输入下一条命令,毕竟这样的过程有时候可能需要花费几天时间才能完成……
- 恢复时间:一键点击即可恢复生产环境,就是这么简单。
- 确保基础架构的同质:彻底避免运维人员每次构建环境或安装软件时最终获得的结果与预期有所差异,这是确保基础架构绝对同质(Homogeneous)并且可再现的唯一可行方法。以此为基础,通过对脚本或Puppet配置文件使用版本控制机制,我们甚至可以重建出与上周、上个月,或软件特定版本发布时完全一致的生产环境。
- 维持整齐划一的标准:基础架构标准甚至可以不复存在,代码本身就是标准。
- 让开发者自行完成大部分工作:如果开发者自己突然可以在自己的基础架构上一键点击重建生产环境,他们也就可以自行完成很多与生产环境有关的任务,例如更好地理解生产失败,提供更恰当的配置,实现部署脚本等。
- 部署越频繁,对部署流程就会越熟悉,自动化机制就能获得更好的结果。如果同一件事每天需要执行3次,很快你将变的无比娴熟,但很快也会因为日复一日解决同样的问题而感到厌烦。
- 部署越频繁,所部属的变更集就越微不足道,而这些微不足道的内容最有可能出错,甚至可能导致丢失对整个变更集的控制力。
- 部署越频繁,TTR(修复/解决所需时间)指标就会越出色,从业务用户处获得有关功能的各类反馈的速度越快,作出改进以便完美满足对方需求的过程也会越简单(这方面TTR与TTM其实非常相似)。
- 从实践中学习
- 自动化
- 更频繁的部署
- 首先,随着要做的工作量逐渐增加,这些任务也会变的愈加困难,但如果能拆解为小块,则会变的相对容易些。以数据库迁移为例:一些涉及大量表的大规模数据库迁移工作很麻烦,容易出错。但如果一次只迁移一部分,则可以相对较容易地成功完成整个迁移任务。此外还可以轻松地将多个小规模的迁移任务安排成一定的序列,在将一个艰难的大任务拆解为一系列容易实现的小目标后,处理起来就简单多了。(这也是数据库重构的本质)
- 第二个原因在于反馈。大部分敏捷思维关注的是设置反馈环路,借此让我们更快速地学习了解。反馈已经是极限编程(Extreme Programming)中一个非常重要,蕴含巨大价值的概念。在诸如软件开发等复杂流程中,我们需要更频繁地检查自己的最新进展,并进行必要的纠正。为此我们必须尽一切可能创建反馈环路,并提高反馈的频率,这样才能更快速地酌情做出调整。
- 第三个原因是实践。对于任何活动,越频繁地从事就越能获得完善。实践可以帮助我们理清整个流程,让我们更熟悉代表有事情出错的征兆。只要认真琢磨自己从事的工作,就能提炼出近一步完善所需的实践。对于软件开发,也有可能实现一定程度的自动化。一旦有人将某件事做了多次,就可以更容易地确定该如何进行自动化,更重要的是,这样的人在对这些事情实现自动化方面将有更大的动机。此时自动化尤为重要,因为可以加快速度并降低出错的概率。
- 对软件组件的开发和平台的供应和设置进行持续集成。
- TDD - 测试驱动的开发。这一点还有待商榷……但始终还是需要面对:TDD是目前唯一能通过单元测试对代码和分支进行可接受程度覆盖的方法(单元测试使得问题的修复过程比集成测试或功能测试容易很多)。
- 代码审阅!至少要进行代码审阅……如果能进行结对编程(Pair programming)当然就更好了。
- 软件的持续审计 - 例如使用Sonar。
- 在生产级环境实现功能测试的自动化。
- 更强大的非功能测试自动化(性能、可用性等)。
- 独立于目标环境的自动化打包和部署。
- 功能开关(Feature Flipping)
- 摸黑启动(Dark launch)
- 蓝/绿部署(Blue/Green Deployment)
- 金丝雀发布(Canari release)
功能开关
功能开关可供我们在软件运行过程中启用/禁用相应的功能。这种技术其实非常容易理解和使用:为生产版本提供一个能彻底禁用某项功能的配置,并只在对应功能彻底完工可以正常工作后才将该属性激活。
举例来说,若要将某个应用程序内的一个功能全局禁用或激活:
if Feature.isEnabled('new_awesome_feature')
# Do something new, cool and awesome
else
# Do old, same as always stuff
end或者如果要真对具体用户实现类似目的:if Feature.isEnabled('new_awesome_feature', current_user)
# Do something new, cool and awesome
else
# Do old, same as always stuff
end 摸黑启动摸黑启动的目的在于通过生产环境进行负载模拟!
在测试环境中,通常很难为软件模拟出成百上千万用户规模的负载。
如果不进行切实的负载测试,就无法知道基础架构能否承受住最终面临的压力。
此时并不需要模拟负载,而是可以实际部署这样的功能,然后看看在不影响可用性的前提下到底会发生什么。
Facebook将这种做法称之为功能的“摸黑启动”。
假设我们要将一个有5亿用户使用的静态搜索字段变成一个包含自动补全功能的字段,借此让用户可以更快速获得搜索结果。为该功能构建一个Web服务,并且希望模拟所有用户同时输入文字,向该Web服务生成大量请求的场景。
此时即可通过摸黑启动策略为现有表单添加一个隐藏的后台进程,通过该进程将输入的搜索关键字发送给新增的自动补全服务,并自动发送多次。
就算新增的Web服务彻底崩溃了,也不会造成任何实质损害。网页上可以完全忽略服务器错误。而就算该服务崩溃了,我们至少还可以对该服务进行优化和完善,直到能承受如此大量的负载。
这就等于在现实世界中进行了一次负载测试。
蓝/绿部署
蓝/绿部署是指为下一版产品构建另一个完整的生产环境。开发和运维团队可以在这个单独的生产环境中放心地构建下一版产品。
当下一版产品全部完成后,可以修改负载均衡器的配置,以透明的方式将用户自动重定向至新发布的下一版。
随后可将上一版的生产环境回收,用于构建下下一
详解微服务实践从架构到部署
运维 OS小编 发表了文章 0 个评论 2497 次浏览 2017-07-17 22:08
前言
前段时间公司事情多,这篇长文写了放、放了写…耽搁了一些进度。各个自媒体的更新也慢了很多,这里给大家说句抱歉了。
现如今“微服务”遍地开花,已经成软件架构领域最受欢迎的热门话题之一。网上和书籍中都有很多关于微服务基础和优势的学习材料,但是我们可能会发现这东西在现实世界企业场景中似乎好像没那么普及,真正能跑的微服务资源其实也不是很多,大多是停留在概念和摸索阶段。
在这篇文章里,我打算讲讲微服务架构(MSA)的关键架构概念,以及如何在实践中将这些架构原理应用起来。

前因:单片结构
企业应用,因为服务于众多业务需求,因此会有些特定的软件应用提供许多功能,而一般惯例是把这些功能都堆在单个单片应用中。例如,ERP,CRM和其他各种软件系统被规划构建为具有数百个功能的整体。这种带坑应用一经部署,在往后的故障排除、扩展和升级场景中就是一场接一场的恶梦了。
面向服务架构(SOA)旨在通过引入“服务”的概念来克服以上的限制,“服务”是从应用程序提供的类似功能中提取出来的聚合和分组。因此,使用SOA,软件应用程序就会被设计为“粗粒度”服务的组合。然而,SOA中服务的范围非常广泛,这又引出了复杂而庞大的服务与一大堆操作(功能)以及复杂无比的消息格式和标准(如WS *标准)。

多数情况下,SOA中的服务彼此独立,只不过它们与所有其他服务一起部署在相同的运行时间里(只需考虑将部署到同一个Tomcat实例中的多个Web应用)。和单片软件应用类似,这些服务通过积累各种功而具有随时间推移的习惯。图1是一个非常好的一个单片架构的例子,显示了包括多个服务的零售软件应用,所有这些服务都能部署到同一应用程序。
说了那么多,大家是不是有点不明所以?我总结了一些重点,以下就是基于单片架构的应用程序的一些特性归纳:
- 单片应用程序被设计、开发和部署为单个单元。
- 单片应用相对复杂,导致维护,升级和新特性困难重重。
- 难以用单片架构来实践敏捷开发和交付方法。
- 想更新某部分,很可能要重新部署整个应用。
- 规模需求冲突的情况下,若想做单点扩展,要做好多倍资源甚至推倒重来的准备(例如,想给A服务更多CPU,B服务可能要重做,也可能要补两三倍memory)
- 可靠性:一个不稳定的服务可以拖慢整个应用性能。
- 难创新:采用新技术和框架非常困难,因为所有的功能必须建立在均匀的技术/框架上。
微服务架构(MSA)的基础是将单片应用作为一套小型和独立服务来开发,这些服务都在自己的空间独立开发、部署和运行。在微服务体系结构的大多数定义中,它普遍被解释为将巨大的可用服务隔离成一套独立服务的过程。不过我对这些有自己的理解,微服务的逻辑不仅是将整个大容量服务分为独立服务,关键在于通过查看从整体提供的功能,我们就可以确定所需的业务能力。而这些业务能力可以具体实现为各自独立的细粒度和自包含(微)服务。它们可能在一个技术堆栈上实现,每个服务都处理一个非常具体和有限的业务范围。因此,上面解释的在线零售系统场景可以通过如图2的微服务架构实现。通过微服务架构,零售软件应用程序被规整为一套微服务。而且从图2最底下一层可以看出,根据业务需求,还多了一个从原始服务组合中额外创建的一个微服务。换句话说,想跟进微服务,要有超大容量服务可能会分裂的准备,不过我相信相比于进步,这点麻烦值得付出。后果:微服务架构

通过Microservices Architecture可以从头开始构建软件应用或改造现有应用程序/服务…无论是哪种方法,正确判定Microservices的大小,范围和功能,都至关重要。我感觉,这可能是在Microservices Architecture实践最初(对的,“最初”这个词用的没错)最难的事了。现在聊聊关于微服务的规模、范围和功能的关键实践问题和对一些坊间误解的辟谣。[list=1]设计微服务:大小,范围和功能
[list=1]微服务设计指南
在单片应用中,使用函数调用或语言级方法调用不同处理器/组件的业务功能。在SOA中,这种转移趋向于更为松散耦合的Web服务级别消息传递,主要基于不同协议(如HTTP,JMS)之上的SOAP。而具有数十种操作和复杂消息模式的Web服务是Web服务普及的关键阻力。对于Microservices架构,它需要简单而轻量的消息传递机制就行。微服务中的消息传递
对于同步消息传递(客户端期望从服务及时得到响应并等待到达),在微服务体系结构中,REST是主流标配,因为它提供了基于资源API风格的HTTP请求响应实现的简单消息传递方式。因此,大多数微服务实现都使用HTTP以及基于资源API的风格(每个功能都以资源和在这些资源之上执行的操作来表示)。同步消息 - REST,Thrift

对于某些需要使用异步消息传递技术(客户端不期望立即响应或根本不接受响应)的微服务场景。多看看诸如AMQP, STOMP或MQTT之类的异步消息协议就好了。异步消息 - AMQP,STOMP,MQTT
决定微服务最适合的消息格式是另一个关键因素。传统单片应用使用二进制格式(习惯了,表示还好不算复杂);基于SOA / Web服务的应用使用基于复杂消息格式(SOAP)和模式(xsd)的文本消息。而在大多数基于微服务器的应用中,简单基于文本的消息格式即可,如JSON和XML,反正就是基于HTTP资源API风格跑起来。在我们需要二进制消息格式的情况下(文本消息在某些用例中可能会变冗长),微服务可以利用二进制消息格式,如Thrift,ProtoBuf或Avro…消息格式 - JSON,XML,Thrift,ProtoBuf,Avro
若你把业务能力实现为服务,就需要定义和发布服务合同。传统单片应用几乎找不到这样的功能来定义应用的业务功能。在SOA/Web服务的世界里,WSDL用于定义服务合同。不过众所周知,WSDL不是用于定义微服务合同的理想解决方案,因为WSDL非常复杂且与SOAP紧密耦合。由于我们在REST架构风格之上构建微服务器,所以我们可以使用相同的REST API定义技术来定义微服务器的合同。因此,微服务更多情况下用标准的REST API定义语言(如Swagger和RAML) 来定义服务契约。对于不基于HTTP/REST(如Thrift)的其他微服务实现,可以用协议级别的“接口定义语言(IDL)”(如Thrift IDL)。服务合同 - 定义服务接口 - Swagger, RAML, Thrift IDL
在微服务架构中,软件应用程序被构建为一套独立的服务。因此,为了实现业务用例,需要在不同的微服务/流程之间建立通信结构。这就是为什么微服务之间的服务间/过程通信至关重要的原因。 在SOA实现中,服务之间的服务间通信通过企业服务总线(ESB)来实现,大部分业务逻辑都位于中间层(消息路由,转换和业务流程)中。然而,微服务架构促进消除中央消息总线/ESB,并将“智能”或业务逻辑移至服务和客户端(称为“智能端点”)。由于微服务使用诸如HTTP,JSON等标准协议,因此在微服务之间的通信中,与不同协议集成的要求是最小的。Microservice通信中的另一种替代方法是使用轻量级的消息总线或网关,它们有最小的路由功能,并且仅用作在网关上实现业务逻辑的“dumb pipe”。基于这些风格,在微服务架构中不可避免的出现了几种通信模式。集成微服务(Inter-service / process communication)
以点对点的形式,消息路由逻辑的整体跑在每个端点之上,服务可以直接通信。这里每个微服务器都暴露一个REST API,一个给定的微服务器或外部客户端可以通过对应的REST API调用另一个微服务器。点到点风格 - 直接调用服务

- 须在每个微服务级别实现终端用户认证,限制,监控等非功能性要求。
- 由于不可避免的复制一些常用功能,每个微服务实现可能会变得复杂。
- 服务和客户端之间的所有通信都无法控制(哪怕只是监控,跟踪或过滤)。
- 通常直接沟通风格被认为是用于大规模微服务实现的微服务反向模式。
API网关风格背后的关键思想是使用轻量级消息网关作为所有客户端/消费者的主要入口点,并在Gateway级别实现常见的非功能需求。通常,API网关允许通过REST/HTTP使用受管API。因此,在这里,我们可以将通过API-GW实现作为微服务的业务功能公开为管理API。Microservices架构和API管理的组合,这个算是最佳选择了。API网关样式

- 能够在现有微服务的网关级别提供所需的抽象。例如,API网关可以为每个客户端提供不同的API,而不是提一个所有类型的API。
- 网关级、轻量级消息路由/转换。
- 非功能性功能(如安全性,监控和调节)的应用能如臂指使。
- API-GW模式让非功能性要求在Gateway级别实现,微服务得以瘦身。
微服务还可以和异步消息的场景集成,比如队列或主题的单向请求以及订阅。给定的微服务可以做消息生成,并且它可以异步地将消息发送到队列或主题。那么消费的微服务器可以消耗来自队列或主题的消息。这种风格将消息生成与消息消费分离,中间消息代理缓冲直到消费处理。Message Broker风格

单片架构中,应用将数据存储在单个和集中的数据库中,以实现应用的各种功能/功能。分散式数据管理


- 每个微服务器都可以有一个私有数据库来保存实现从其提供的业务功能所需的数据。
- 给定的微服务器只能访问专用私有数据库,而不能访问其他微服务器的数据库。
- 某些业务场景中,可能单个事务需要更新多个数据库。在这种情况,其他微服务器的数据库应仅通过其服务API进行更新,而非直接访问。
微服务架构倾向于分散治理。一般来说,SOA治理指导了可重用服务的开发,建立如何设计和开发服务以及这些服务随时间的变化。它确定了服务提供商和这些服务的消费者之间的协议,告诉消费者他们期望什么以及提供者有义务提供什么。在SOA治理中,共有两种类型的治理:权力下放的治理思维
- 设计时治理 - 定义和控制服务策略的服务创建,设计和实施;
- 运行时管理 - 执行期间执行服务策略的能力;
- 在微服务架构中,管理不需要集中设计。
- 微服务器可以因地制宜,决定其设计和实现。
- 微服务架构促进了共享/可重用服务的共享。
- 一些运行时管理方面,如SLA,节流,监控,常见安全要求和服务发现可以在API-GW级别实现。
在微服务架构中,需要处理的微服务器数量相当高。而且,由于微服务的快速和敏捷的开发/部署性质,他们的位置一般来说也会动态变化。因此,你需要在运行时间内找到微服务器的位置。解决此问题的方法是使用Service Registry。 服务注册表:服务注册表保存微服务实例及其位置。Microservice实例在启动时注册到服务注册表,并在关机时注销。消费者可以通过服务注册表找到可用的微服务及其位置。 服务发现:要找到可用的微服务及其位置,我们要一个服务发现机制。有两种类型的服务发现机制,客户端发现和服务器端发现,来看看这些服务发现机制各原理如何。 客户端发现:在这种方法中,客户端或API-GW通过查询服务注册表来获取服务实例的位置。服务注册和服务发现


在微服务架构方面,微服务的部署同样起着至关重要的作用,关键要求如下:部署
- 能够独立于其他微服务部署/部署。
- 必须能在每个微服务级别做扩展(给定的服务可能比其他服务获得更多的流量)。
- 快速构建和部署。
- 一个微服务的故障不得影响任何其他服务。
- 将微服务作为(Docker)容器镜像打包。
- 将每个服务实例部署为容器。
- 基于更改容器实例的数量来进行缩放。
- 构建,部署和启动微服务将会快得多,因为我们使用Docker容器(这比常规VM快得多)

现实很骨感,无论是不是微服务都应当得到安全方面的保护。在进入微服务安全性篇章之前,我们先快速过一下如何在单片应用层面实现安全。安全
- 在典型的单片应用程序中,安全性是关于发现“谁是呼叫者”,“呼叫者可以做什么”,以及“我们如何传播该信息”。
- 这通常在位于请求处理链的开始处的公共安全组件中实现,该组件使用底层用户存储库(或用户存储)填充所需的信息。
- OAuth2 - 是访问委派协议。客户端使用授权服务器进行身份验证,并获取称为“访问令牌”的不透明令牌。Access令牌具有关于用户/客户端的零信息。它仅引用只能由授权服务器检索的用户信息。因此,这被称为“副参考令牌”,即使在公共网络/互联网中也可以安全地使用该令牌。
- OpenID Connect的行为与OAuth类似,但是除了访问令牌之外,授权服务器还会发出一个包含用户信息的ID令牌。这通常由JWT(JSON Web令牌)实现,并由授权服务器签名。因此,可以确保授权服务器与客户端之间的信任。因此,JWT令牌被称为“副值令牌”,因为它包含用户的信息,显然不能在内部网络之外使用它。

- 将身份验证保留到OAuth和OpenID Connect服务器(授权服务器),以便microservices成功提供访问权限,因为有人有权使用数据。
- 使用API-GW样式,其中所有客户端请求都有一个入口。
- 客户端连接到授权服务器并获取访问令牌(按引用令牌)。然后将访问令牌与请求一起发送到API-GW。
- 网关上的令牌翻译:API-GW提取访问令牌,并将其发送到授权服务器以通过值令牌来检索JWT。
- GW将该JWT与请求一起传递到微服务层。
- JWT包含有助于存储用户会话等的必要信息。如果每个服务都可以了解JSON - Web令牌,那么已经分发了你的身份机制,那你就被允许在整个系统中传输身份。
- 在每个微服务层,我们可以有一个处理JWT的组件,这是一个非常简单的实现。
交易
微服务中的交易支持如何?其实,支持跨多个微服务的分布式事务是一个非常复杂的任务。
微服务架构本身鼓励服务之间的无事务协调。这个想法是给定的服务是完全独立,基于单一的责任原则。跨多个微服务器分布式事务的需要通常是微服务体系结构设计缺陷的症状,通常可以通过重构微服务器的范围进行整理。
然而,如果强制性要求跨多个服务进行分布式交易,则可以通过在每个微服务级别引入“补偿操作”来实现这种情况。关键思想是,给定的微服务是基于单一责任原则,如果给定的微服务器未能执行给定的操作,那么我们可以认为这是整个微服务的失败。
设计失败
Microservice架构引入了一系列分散的服务,与单片设计相比,增加了在每个服务级别发生故障的可能性。由于网络问题,基础资源不可用,给定的微服务可能会失败。不可用或无响应的微服务器不应玩砸了整个基于微服务器的应用。因此,微服务应该有容错余地,能够在可能的情况下恢复,客户端也必须妥善处理。
此外,由于服务可能随时失败,因此能够快速检测(实时监控)故障,并尽可能自动恢复服务(故障自愈)很重要。在微服务玩家的眼里,处理错误有几种常用模式。
断路器
当你对微服务器进行外部呼叫,就可以在每次调用时配置故障监视器组件,并且当故障达到某个阈值时该组件将停止对服务的任何进一步调用(跳闸电路)。在打开状态(可以配置)的一定数量的请求后,将电路更换回关闭状态。
这种模式对于避免不必要的资源消耗,由于超时引起的请求延迟是非常有用,也让我们有机会更积极的监控系统(基于活动的开路状态)。
隔板
基于微服务器的应用的一部分的故障不应影响其他应用,隔板模式是关于隔离应用的不同部分,以便应用的某个部分的服务失败不会影响任何其他服务。
超时
超时是一种主观加入的合理机制,当你认为结果无法返回,则允许停止响应。
模式这里叨叨完。那么,我们在哪里和如何使用这些模式与微服务?大多数情况下这些模式都适用于Gateway级别,这意味着当微服务不可用或没有响应时,在网关级别,我们可以决定是否使用断路器或超时模式将请求发送到微服务。此外,在Gateway级别实现诸如隔板之类模式也很重要,因为它是所有客户端请求的单个入口点,也因此发送服务中的故障不应影响其他微服务器的调用。
另外,Gateway可以作为中心点,我们可以通过Gateway调用每个微服务来获取每个微服务器的状态和监视。
微服务,企业集成,API管理和遐(瞎)想
我们专门研究过微服务架构的各种特点,以及如何在现代企业IT环境中实现它们。但是,我们应该记住,微服务不是灵丹妙药。流行语概念的盲目适应不会解决“真实”企业IT问题。
它微服务是有很多优势,我们也应该充分利用。但是我们还必须记住,解决所有企业IT问题与微服务之间联系不一定就是强相关。例如,Microservices架构促进消除ESB作为中央总线,但是当涉及到现实世界的IT时,现在有很多不是基于Microservices的应用程序/服务。所以,整合是避不开的解决思路,要做集成。
所以,理想情况下,Microservices和其他企业架构概念(如Integration)的混合方法将更为现实。以后再聊了,这个能写的太多。 希望这能让你更清楚地了解如何在企业中使用Microservices。
分享阅读原文: http://dwz.cn/6iVsiQ
不仅是 Linux 运维最佳实践
运维 OS小编 发表了文章 0 个评论 2576 次浏览 2017-06-30 00:07
@xufengnju(胥峰),资深运维专家,有 10 年运维经验,在业界颇具威望和影响力。也是盛大游戏高级研究员,2006 年毕业于南京大学,2011 年加入盛大游戏,工作至今,曾参与盛大游戏多款大型端游和手游的上线运维,主导运维自动化平台的功能设计和实施。拥有工信部认证高级信息系统项目管理师资格。
自动化运维在近几年一直都是很火热的话题,技术也一直在进步,因此对于技术人员来说,最重要的思维上、思想上的适应与转变。毕竟技术不是运维的终极追求,思想才是运维人员应该毕生修炼的目标!本次高手问答的高手嘉宾对运维服务体系有着深度的思考,因此问答中产生的内容也是十分有质量。
本文从多个角度整理了与运维相关的内容,包括工具的选择、运维中遇到的问题、自动化运维相关等等。
Q&A
一、工欲善其事必先利其器,如何选择工具?
1. 对服务器安全和监控,可以推荐一些开源工具吗?监控好像也就 nagios, cacti, zabbix,还有其他可以推荐的吗?安全方面如何监控?
监控工具各有侧重点,zabbix 同时支持 snmp 和自己的 agent,也支持自定义模板,在大部分场景下都是不错的选择。
另外,不要把 zabbix 视为只能监控服务器信息,通过自定义模板,也可以监控业务层面的指标。安全监控分为主动检测,如 Tenable Nessus,以及 IDS、IPS。
2. Linux 运维中,服务器版本都用什么版本?CentOS 5 还是 CentOS 6、Ubuntu?为什么选择这个版本?有做哪些测试?
目前我们以 CentOS6.X 为主。不同 Linux 分支各有特点,比如 Ubuntu 新版本发布较快,如果追求内核版本升级速度的话,可以考虑。CentOS 一直是我们的主要 Linux 发行版,主要是考虑到它的稳定性以及熟悉程度最高。
3. 对于使用缓存有什么推荐吗?一般就 Redis, Codis。还有那些比较好用的开源软件?
对于类似 session-id 这样的可以非持久存储的数据,可以考虑 memcached,使用一致性哈希算法分布式存储。
4. 做自动化发布,除了 Jenkins 持续集成工具,还有那些好用的工具呢?
目前我所知道的,一般都是 Hudson 或者 Jenkins,后者是前者分支出来的。这些工具都有丰富的插件,灵活使用这些插件是关键所在。
5. 问个 MySQL 问题,三个版本(MySQL(官方版本)、Percona Server 、MariaDB)您建议使用哪个版本,原因是?
我们团队一般使用的是官方版本。主要是考虑到支持和生态。
6. 服务器日志收集和分析有什么好工具推荐吗?ELK 貌似有点复杂,不太会用,有其他的推荐么?
ELK 确实是目前使用比较广泛的日志收集和分析的工具。虽然有些学习成本,但还是值得去研究和尝试的。
7. 书里有开源出一些工具和脚本吗,哪里可以下载到?
书上的脚本我正在整理,其中一部分通过 git 可以下载 https://github.com/xufengnju/books.git
8. 请问你们现在运维都是基于 Ansible 吗?我们之前都是用 chef puppt 来管理。最近感觉 Ansible 很火,还没实践用过,请问这个用起来差别大吗?
各种不同的批量管理工具各具特点,根据自己的熟悉程度和实际业务需要选择一个完全掌握即可
目前 IaaS 平台是自研的,基于 KVM
二、绝知此事要躬行,运维中遇到问题?1. LVS 和 HAPROXY 后端服务器规模可以到什么程度,比如有多少个应用,多少台后端服务器?
这个取决于应用的类型,在实际的业务场景下,需要关注 LVS 等负载均衡器本身的连接数、PPS 数据以及延迟。如果后端吞吐量比较大,可以考虑 LVS 的 DR 模式。一般情况下,负载均衡器不太会成为瓶颈。
负载均衡器本身的连接数、PPS 数据以及延迟如何进行计算和统计?
通过开源的 Zabbix 模板或者自定义模板,这些都不难实现。有没有相关的命令集进行统计,或者详细的统计实例?
针对 HAProxy 建议参考咱们书中 P76 页最佳实践 29 HAProxy 监控的内容。Zabbix 模板技术,建议参考下咱们书中第 12 章的内容。可以使用的命令包括 ipvsadm,netstat 等。
2. 对于涉及多个平台(Unix, Linux, Windows)的统一管理(认证,配置,服务)有什么好的解决方案或者思路么?
先说下认证这一块吧。Unix、Linux 都支持 OpenLDAP 认证,可以考虑,这个和 Windows 下的 AD 是兼容的。配置和服务可以考虑下开源的通用产品,比如 Ansible 或者 Salt。目前我们用的自研系统,思路和 Ansible 类似。
3. 如何监控服务,业务运行状态监控你是怎么做的?
我们的监控系统是自研的,对游戏来说,很重要的一个业务指标是在线人数,它是通过监控系统周期性轮询游戏服务器来进行收集和绘制图表的。
4. 你们是如何批量管理各个业务模块的机器系统及配置的。我们目录使用 Ansible 使用批量命令和脚本,业务上使用上线平台 SVN 管理业务程序及配置。是否开发了 CMDB 平台?
我们批量管理服务器的方式是 ssh,思路和 Ansible 类似。CMDB 提供基础数据的管理,是自研的。
5. 请问有使用过流量镜像吗?就是把线上的流量镜像一份,引到测试环境,用真实的用户数据测试,想了解下从 0 开始实施的过程。
关于流量镜像的原理,可以参考《Linux 运维最佳实践》第 15 章中网卡混杂模式和 RawSocket 技术。看了这一部分后,你应该可以自己写一套。我没有亲自实践过,你可以自己关注下 tcpcopy 这个项目。
6. CentOS 6 要如何做系统和网络优化?/etc/sysctl.conf 中的这个参数
net.ipv4.tcp_max_tw_buckets = 6000要如何设置,是越多越好吗?设置成 16000?
net.ipv4.tcp_max_tw_buckets = 16000
对于系统优化来说,要有针对性。tcp_max_tw_buckets 针对的是 time wait bucket,如系统中 timewait 状态较多,可以考虑 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_tw_recycle 这 2 个值调整。另外,如果使用长连接对于减少该状态的连接数有效。
7. 如果有 100 多台服务器,大部分都是在提供业务的服务器,如何升级呢?除了停机维护,现在有什么比较好的解决方案吗?
如果本身业务切分比较好,例如采用无状态的微服务等架构,可以通过前端负载均衡器进行灰度升级。如果应用做的不好,只有单台的这种,或者集中数据库,就比较麻烦了。
8. LVS 和 HAPROXY 分别能支持多少类似 FARM 的概念?
你说的 FARM 应该是某硬件负载均衡设备的专有名词,应该是负载均衡组的概念。在 LVS 和 HAProxy 里面,负载均衡组的数量上没有硬限制,但实践中一般不会配置太多,因为这涉及到维护成本以及 HA 环境下主备切换时的开销。
9. 系统是 CentOS release 6.5 (Final), 系统没有自动回收内存,16G,我自己写了个 Shell 脚本,每次执行判断小于 1G 的时候回收内存
可以关注下 sysctl 中 swap 以及 swappiness 的一些配置
10. 请问如果是有很多 ECS/VPS,系统一般是 CentOS。目前很多堡垒机也有类似的 SSH 同步密钥下发命令等功能,但是如果还有 Win的堡垒机支持很少。有别的开源工具或者办法来混合管理所有的 Linux, Windows 机器吗?
在我的这个演讲里面讲到了异构系统的批量管理方法,你可以参考下。
http://www.build.net/greatops/453250.html 。另外,你可以参考下 Ansible 或者 salt。
三、自动化运维相关,工程师思维?
1. 可以说下什么是自动化运维,如何才算服务器做了自动化运维?包括哪些?自动化发布,有问题可以回滚?
运维自动化是一个仁者见仁智者见智的概念。我的理解是,运维自动化要打通从代码开发完到正式上线的所有环节,包括版本构建、打通自动测试、自动化上线以及自动化监控。
在这个大命题下,可以根据自己工作环境和自动化水平的不同,选择一两个痛点开始进行自动化实践。最后形成完整体系。
2. 想请问一下自动化运维怎么做的?需要从那些方面考虑?我所考虑到的有实施运维,日常巡检维护,以及故障自动化处理,和提醒。除了这些请问还要注意那些方面?另外,随着 IT 技术的日新月异,涌现了很多新的应用,请问该如果有一个基本的路子来做运维,或者规律,流程来达到运维需求?例如现在比较火的OpenStack Docker 大数据。这些技术实现功能只是很小的一步,更多的是上线后的运维。更多是想要一种思路,能列举大家遇到过的问题,以及问题如何处理?
你的问题很好,但这个话题比较大。我先说下我的理解吧。传统的运维服务流程 ITIL 还有一定的价值,但需要结合一些 DevOps 思想来进行适当的改造,融合两者的长处。从拥抱变化开始,以一种开放的态度来进行运维。但不变的一点是,以为业务创造价值为最终目标,这就是运维的目标。
3. 实现运维自动化,最主要就是配置管理、状态管理和变更管理,其中配置管理要如何来做,有什么好的方法分享下吗?
对配置管理,我认为应该分为“基础架构资源配置管理”和“软件/应用配置管理”。
前者是一般意义上的 CMDB 的范畴,这个可以根据自己业务特点在开源 CMDB 方案的基础上做一定的适配;
对于后者,一方面是系统(例如版本控制系统的结合),一方面是流程(例如和变更管理挂钩)。在我们的实践中,这 2 个方面都有涉及。
4. 请问你主导运维自动化平台的功能设计和实施,是通过 Python 开发管理工具吗?另外,你们是重新开发,还是根据 Saltstack 之类的进行二次开发。
底层使用 SSH 协议建立服务器管理通道,上层使用 PHP 开发管理界面以及封装一些常用操作,比如密码修改、脚本下发和执行等。完全自主开发。
四、做好安全措施很重要,安全相关的问题1. 运维离不开安全,服务器的安全也很重要,书中有讲运维安全这块吗,如何把控安全这块?
书中有安全主题。安全是一个庞大的体系,书中主要讲了保障 Linux 系统安全的一些措施。其他安全主题,比如社会工程和入侵检测,可能需要看更专业的书。你可以先看看咱们《Linux 运维最佳实践》是否能满足你的基本安全需求。谢谢支持。
2. Web 安全监控有开源解决方案吗,能否做到在接入层就把一些可能的漏洞拦掉?Suricata?
Suricata 没有研究和实践过。《Linux 运维最佳实践》中第 11 章 Web 服务器安全部分提到了几个工具,你可以参考下。但 ModSecurity 规则在上线前要进行严格详细测试,不要出现误判。另外,建议对生产环境进行定期的安全扫描,例如使用 Tenable Nessus 工具等。安全专家的人工渗透测试也是必须的。
五、Docker 很火热,在运维中结合使用?1. 在网易游戏运维中是否用到了最近很火的 Docker 技术以及应用在哪,存在什么问题,如何解决?
目前我们在调研 Docker 技术,只有少量游戏测试使用。需要根据不同的业务模型选择对应的网络模型和存储方案。Docker 技术会改变传统的运维方式,要考虑和原有运维系统整合以及运维习惯的调整所带来的挑战。另外,我不是网易公司的,我目前在盛大游戏工作。
2. Docker 化对运维影响深远吗?
Docker 化对运维有影响,它带来的影响包括:持续交付、微服务以及 DevOps 理念的冲击。作为运维,我们要拥抱这个变化,通过不断学习和实践来迎接这些挑战。
3. 为何国内没有一家成熟的 Docker 方案公布细节呢?
Docker 还是一个新生事物,各家使用的场景和模式有所不同,而且会有一些二次开发的管理系统和调度系统。
六、不是所有对比都会产生伤害,工程师想的只是最优方案1. 游戏服务器运维和网站服务器运维以及 APP 服务器运维,有哪些不同点和相同点?
这个问题很有代表性。不同点是,网站和 APP 运维接触的通用开源软件比较多,游戏运维接触的大部分都是自研的程序。
共同点是,都需要掌握操作系统知识、软件硬件以及网络知识,还有排查问题的思路和容量规划等。两者都需要引入运维自动化的思维和体系。《Linux 运维最佳实践》最后 2 章描述了游戏运维的相关体系和技术。
2. 作为运维人员,Python 这样的脚本在进行系统管理和监控的时候相比 Shell 有怎样的优势呢?
作为高级编程语言,Python 有非常丰富的库,包括核心库和第三方库,很多时候不需要自己造轮子;
相比 Shell,它有更好的控制力、重试机制,比如对 Socket 设置超时等等。
3. CentOS 比起 Ubuntu 来说有啥优势?为什么服务器大多用 CentOS?
不同 Linux 分支各有特点,比如 Ubuntu 新版本发布较快,如果追求内核版本升级速度的话,可以考虑。CentOS 一直是我们的主要 Linux 发行版,稳定性以及熟悉程度最高。
选择某个发行版时,要考虑它的生态,比如上下游的支持,还有一点,就是运维人员招聘的方便程度,国内熟悉 CentOS 的稍多一些。
4. 想问下只有一台服务器,有多个应用,是用 LVS 做负载好还是 Nginx?差别大吗?
你说的后端应用是基于 HTTP 或者 HTTPS 的吗?如果是的话,并且吞吐量不大的情况下,使用 Nginx 即可;如果非 HTTP 或者 HTTPS 的 TCP 应用,建议使用 LVS;如果 HTTP 或者 HTTPS 吞吐量特别大的情况下,使用 LVS DR 模式。
七、You Need Backup,与备份相关的一些问题1. 1000 台机器规模,备份系统应该要做到什么程度?
1000 台服务器,要区分业务类型,如果类型单一,备份就比较好做。如果类型多,那么要考虑的地方包括:数据库更新的频率(全备+增量备份?还是只使用全备)、数据备份的大小、数据集中归档的要求。
2. 备份是怎么做的?上百 T 的图片、附件有什么高雅的备份方案?
在线备份这一块,可以考虑使用 erasure coding 算法,在增加一定可靠性的能力下,不至于导致备份存储的成本过高。同时要考虑离线备份,比如磁带。
八、路漫漫其修远兮,运维工程师的职业生涯1. 你觉得在未来,运维的核心会是什么,自动化,预判或是其他?
我觉得,未来的运维应该是智能化的。把现在需要人做的容量规划、扩缩容、排障全部实现智能化。运维的任务就是编程,把自己的能力灌输到机器上。当然,理想很丰满,现实很骨感。这需要我们的不懈努力。
2. 作为工作 4 年多的测试工作者,在运维方面也是有一定的涉猎,在公司维护自己的测试环境,有时候也需要一定运维功底,从 Windows Server 到 Linux,学习很多,也总结了很多。上家公司着手 Docker 部署的时候刚好离开公司了。真是有点遗憾,后续工作也没时间去实践,目前使用的是 ng 负载,采用 Tomcat 部署方案,工作实在比较忙,很想在运维方面也有一定的提升!不知道从何入手好,求大神指教。
从你的描述来看,目前是兼职运维。我建议是否可以考虑,在搭建环境之外,多多研究下其中的原理,同时用自动化脚本维护这些环境呢。相信你也有一些编程经验,这些对于你后续实践运维也是有帮助的。另外,就是可以多看看别人总结的运维案例,少走一些弯路。
3. 运维技术挺杂的,如何看待这种杂?给人感觉好像什么都会点,对于工作 5-6 年的运维来说,有什么好的学习建议?
4. 由于运维系统有全面的数据收集、自动处理、报警和自动恢复的机制,我们这里将运维和 BI 结合在一起。扩展运维工具和架构,将已成熟的 BI 接入运维体系,解放业务专员的工作,常规的业务分析、报表、数据监控都可依赖这套运维系统。在我们这里,运维从一层平台逐渐变成一种框架,有需要的场景都可以套用。技术一直在变,但最重要的不是技术,而是用技术提供服务的思想。 除了和 BI 结合,运维思维还可以和哪些相关业务场景结合,可以在新的方向上产生价值呢?
如你所说,运维技术要求范围确实蛮广的。我觉得,对于工作了一定时间的运维同学来说,可以考虑的方向有以下几个:
- DevOps 实践(加强自己的编程能力,系统学习一门高级编程语言,运维自动化)
- 对自己的技术薄弱点重点学习,比如系统学习网络知识
- 看一些比较好的运维技术书籍,学习别人的干货
5. Devops 对运维有那些改变,能简单说下嘛?我很赞同你的想法和实践,“用技术提供服务的思想”。我个人认为,运维的终极目标可能是“没有运维工程师的”自运维,或者叫智能运维,是 AI 在运维领域的深度融合和实践。容量规划算法的不断优化、基于公有云的资源自动调度都应该是智能化的。当然,实现这个目标还有很长的路要走。
6. 现在哪个版本的 Linux 使用最广泛,还有 Linux 运维,我们需要学习一些语言吗,比如 Python 之类,这样才能算是一个真正的好运维?Devops 从概念提出到现在已经有一段比较长的时间了,总体来说,我认为它带来的变化是:持续交付能力需要打通研发、测试和部署运维的整个链路,它对运维自动化的能力要求更高了。我们必须通过掌握一些运维自动化框架加上一定的编程能力才能根据业务场景来应对这种变化。另外,对运维来说,就是要拥抱变化,以开放的态度进行协作。
7. 请问您写书,是怎么坚持写下来的?是把平时工作重点的问题,记录下来,每天写一点,再总结吗?写书有什么工具软件吗,还是只是用 Word 来写?能分享下写运维书籍的方法吗?不要犹豫了,立即开始学习编程吧,不管 Perl 还是 Python,熟悉哪一种都行。在这里,我不对比 Perl 和 Python 的优缺点。坚持用自己的代码(加上别人的框架和库)来解决重复的运维问题,你会成长的更快。CentOS 用的比较多。《Linux 运维最佳实践》第 18 章是使用 Perl 进行系统自动化编程的内容,你可以先看看。如果感兴趣的话,立即开始吧。
这个问题非常好,也是我想分享的。写书的素材依赖于平时的积累,建议大家平时多写写标准的文档,word 格式可以参考咱们这本书的编排。比较重要的 3 点是:
- visio 图要保留下来,不能只存图片,因为可能还要调整排版
- 有些故障现场,尽量记录详细,现象和分析过程、辅助的日志和抓包文件等,建议都保留下来
- 脚本按照分类保存下来,以便查找
有关 Linux 运维最佳实践的问答内容至此结束,各位读者可以转到原帖浏览更多内容。
原文:运维技术干货 — 不仅是 Linux 运维最佳实践 。
基于CMDB与SALTSTACK的运维自动化之路
运维 OS小编 发表了文章 0 个评论 3940 次浏览 2017-06-29 01:10
作者介绍
张延礼,现苏州蜗牛高级运维经理,就职于腾讯多年,熟悉基础架构运维及业务运维,在运维技术实施、流程及标准化体系建设、运维自动化架构设计及实现,运维支撑体系规划和执行团队管理等方面具有丰富经验。
正文
本文基于蜗牛从零开始建设运维自动化的一些实践,总结自动化建设过程中涉及的体系规划、实施路线、产品设计及架构设计等方面的经验。
一、自动化体系规划
1、自动化要解决什么问题
运维层面的工作可以归结为如下三大块

服务管理层面主要是从运维总体支撑的角度来管理运维质量、规范、成本等等,处在运维工作的最高层;技术决策主要是为实现管理目标去制定总体方案,实施路径;技术执行则是落地的最后一环,这一环工作往往呈现零散、杂乱、重复、频繁变更的特点,承接的需求量最多,但价值体现却是较低的一环。
当前运维自动化的首要目标还是在解决”技术执行”这一层面的问题:将大量重复低价值含量的人力实施变成自动化执行,最大化地降低人力依赖,提升运维效率及业务支撑能力。
2、自动化建设思路
对于如何建设自动化运维,个人认为首要的是要有建设思路与方法论,以下供参考:


3、自动化建设总体框架
自动化的建设水平在行业内差异化还是明显的,如果处于运维自动化起步的阶段,建议是组建运维开发团队,从整体规划,基于ESB思想,分层建设,让支撑平台从业务逻辑中解耦。比如就业务运维而言,整个操作工作面无非就是对业务运营环境的各种操作、配置,以及对业务应用程序的管理,简单来说就是OS层和应用层。

要做自动化实施首先得有准确对称的数据,然后需要一个统一的管控平台,能并发的控制和操作远程大量主机,这解决了OS层面的操作问题,但需要管理应用层面的东西还需要与应用的研发人员规范相关接口,这对于开源组件应用而言一般不会有什么问题。因此如果是从零开始做自动化,个人认为CMDB、管控平台、业务进程管理工具这三部分是地基。在此基础之上,可以针对运维各类场景和业务逻辑去做相应的垂直功能系统,再上一层,可以使用流程引擎之类的组件来实现业务运维流程的纵向整合,最终实现运维各类业务流程的纯线上自动化。
二、自动化实施路线
业务发展往往带来运维块面的应用形态、运营环境、、部署结构、基础架构规模及组织流程等多样化、复杂化;如无统一的标准及规范,运维支撑工作将异常混乱,自动化也难以实施。因此自动化有一个基础:标准化,标准化是将一切杂乱无章、千头万绪的运维工作变得有序及可控,流程规范与执行标准的落地是自动化的一大基石。结合我司实际运维现状及需求,基于以上自动化体系建设思路,前期规划的建设线路如下

1、信息的标准化管理:CMDB
在运维工作中,信息的管理往往是难点,运维侧涉及的信息太多,且也与其他职能部门多点关联,信息流转于整个流程的多个职能部门、多个环节

中小型企业中,手工线下记录的方式居多,线上线下信息一致性保持、内部外部信息传递、共享、同步等均存在较大问题,经常出现:
- 线下表格有,实际位置找不到,或信息不对称
- 不清楚设备状态,不清楚哪个业务在使用
- 一个部门做了变更,其他部门不知情
- 变更一条上联链路,无法及时判断影响范围及程度



- CI及属性需要贴合实际环境,同时考虑长期的运维规划
- 管理的不仅是CI及其属性,还有CI之间的关系,状态流转机制等等
- 充分考虑扩展性及灵活性,如引入自定义属性来满足未来或暂时不可预见的需求


- 良好的scale-up/scale-out,灵活扩展,支持复杂网络结构
- 轻量级、高效的后端通信机制,成千上万的管理规模
- 跨平台,支持windows、unix-like多平台,无需重复开发
- 全网统一的一套基于web的用户界面,将所有操作逻辑通过web层来调用salt-api,web前端提供与直接登录机器操作一样的灵活性和自由度,运维人员在web上完成所有操作。
- 对运维操作进行建模,将其分解为几大原子操作类型,一切复杂的序列化操作逻辑可通过原子的自由组合来实现,给用户提供自由灵活的操作方式
- 基于以上逻辑,再给salt加一层应用接口,便于后续其他系统平台可直接调用或整合UJOBS以建设更高层次的平台。

后端salt的逻辑这里不赘述,由于实际网络环境的特殊性,我们采用了二层架构,即master-syndic-minion,公网与内网相结合的方式最大限度提升系统性能。
权限控制、执行对象等等与CMDB打通,可以非常灵活的适应各类业务,各种场景。
如运维人员可以在界面定义好一个版本发布作业:xx业务发布,分解整个发布流程中到每一步骤,并写脚本或调用外部接口来实现具体的操作,最终线上操作只需在页面点击开始执行就可:

当然用户自定义作业可以复用,通过传参的方式实现实例化,避免必要每次发布都建作业。
3、建设过程中的问题总结
做好产品设计及架构设计
充分解析运维内部需求,各具体平台或产品业务区分明确,产品定位一定要清晰,不要想着让微波炉具备电冰箱的功能,自动化整个体系不是一个产品能解决所有问题,需要自顶向下分层设计,产品之间相互解耦且又对外提供接口,能方便的整合与被整合。
组建运维内部开发团队
运维自动化的建设,最好是组建运维内部团队来进行开发,直接丢给业务研发部门往往做出来的东西不是运维侧想要的,因其不易理解运维侧的需求场景、痛点,操作方式等等;如实在没有运维开发团队,那就找个深度理解运维场景的PM去跟开发团队吧。
推动业务开发侧的标准化
其实产品开发团队的研发管理水平及标准化程度直接决定了运维人员爽与不爽,绝大多数研发人员往往只考虑产品功能实现,而很少关注可维护性设计,导致业务给运维人员带来很大的无价值工作量,更有甚者直接是将运维人员当成代码逻辑的一部分。让运维人员参与产品研发的可维护性设计是很多必要的,运维侧需形成可维护性标准规范,推动业务开发遵循将非常利于运维自动化的建设。
文章来源:微信订阅号"运维帮"
地址:http://dwz.cn/6c2Yqz
一个成熟的自动化运维系统应具备哪些功能?
运维 Nock 发表了文章 0 个评论 3526 次浏览 2017-04-15 16:47
一、支持混合云的CMDB
现在越来越多的服务器都转到了云上,而主流的公有云、私有云平台都拥有比较完备的资源管理的API,这些API也就是构建一个自动化CMDB的基础。
新一代的自动化运维平台应该是可以基于这些API来自动维护和管理相关的服务器、存储、网络、负载均衡的资源的。
通过API对资源的操作都应该被作为操作日志记录下来,以备作为后续操作审计的基础数据。
CMDB这个东西听上去是老生常谈,但这个确实是所有运维工具的基础设施。而基于开源工具做运维平台最大的麻烦,就是如何在各个工具之间把CMDB统一起来。CMDB不统一起来,就意味着一旦要增加一台服务器,可能要在各个运维工具里面都要同步一下,这个还是非常折腾滴。
二、比较完备的监控+应用性能分析(APM)
能支持对平台的可用性、服务器的性能、各种服务(web服务、应用服务、数据库服务)的性能进行监控。做的好一些应该能进行更深入、或者关联性的性能分析。
现在市面上一般都会将资源性能监控和应用性能监控(APM)混合着讲,这里面的产品确实也有很多都是重叠的,两方面都会涉及到。
开源的性能监控系统主流有的Zabbix、Nagios,国产的开源监控平台有小米OpenFalcon,但这些基本都只是做基本的资源监控(服务器,磁盘、网络等)和简单的服务软件的性能监控(中间件,数据库等)。
而市面上的APM系统更主打的功能是应用性能分析,比如能精确定位到某个应用的URL的访问速度快慢,某些SQL执行速度的快慢,这些对于开发人员和运维人员快速定位问题还是很有帮助的。
APM这方面的商业工具,国外比较主流的有New Reclic、Dynatrace,国内的也就是透视宝、Oneapm、听云等,他们也提供了API进行集成。
APM这方面的开源工具有pinpoint(一个韩国团队开源的),zipkin(twitter开源),cat(大众点评开源)。
三、有一个还不错UI的批量运维工具
在业务发展比较快的情况下,从几台服务器,到几十台服务器,再到几百台服务器,批量运维的需求很自然就产生了,老板也希望越少的人干越多的活。
现在也有不少开源的批量运维工具,也都比较成熟了,比如puppet、chef、ansible、saltstack。
puppet和chef都是ruby做的,实话实说,ruby的熟手市面上很少,比python不是难招一点。
我个人比较推荐使用ansible或者saltstack,这两个系统都是python写的,代码质量和社区活跃度都挺不错的。
ansible有官方的web ui——Tower,但实话实说不好用,所以我们也在重新做一套自己用起来更顺手的WEB UI。
四、日志集中分析工具
线上系统最常规的问题定位方式,就是日志分析了。
随着服务器的增多,日志的分析定位也成为一个难点和痛点(想象一下,系统出故障之后,要去几十甚至数百个节点去上去查日志,是有多折腾)。
国内有一家叫日志易的公司,是专门做日志分析方面的运维工具的。
另外还有一家log insight,也是做这个领域,但产品好像还处于beta阶段。
日志分析这个领域现在是一个热点,现在的开源方案也比较多了,比如著名的ELKStack,还有Flume+Kafka+Storm的体系。
上面这两个方案相对重一些,部署比较复杂,网上介绍的文章也不少。
比较轻量级的开源日志集中采集方案有python做的Sentry,他是通过改造各种语言的日志采集框架来实现日志的集中采集,各种主流的开发语言的日志框架都支持得很完整了,比如java的log4j和logpack。
Sentry的官网在此:Sentry - Track exceptions with modern error logging for JavaScript, Python, Ruby, Java, and Node.js.
五、持续集成和发布工具
这方面其实比较难有统一的需求,很多公司集成发布的做法都差异挺大的。持续集成方面,一般用jekins的比较多,这方面网上介绍的文章也很多。
而如何把打好的包发布至各台服务器,则可以通过批量运维工具或者脚本来完成了。版本发布的过程涉及到很多细节,包括了版本文件的上传、分发、版本管理、回滚等各种操作。
对于一般不太复杂的项目,我比较推荐的做法是把打包好的文件上传到svn or git上,然后通过脚本在各台服务器上进行发布操作就行了,这样其实是利用了SVN or GIT来完成文件的上传、分发、版本管理、回滚等各种操作。
六、安全漏洞扫描工具
现在一个稍微有点知名度的系统,都会遭受各种各样的安全攻击的折磨。
一般的公司不太可能请得起专职的安全工程师,所以运维工程师最好能自己借助一些安全扫描工具来发现自己系统的漏洞。
安全工具方面我了解不多,不太熟这个领域的开源工具。
之前乌云网推出过一个SaaS化的漏扫平台——唐朝巡航,有对外提供漏洞扫描的API,不过最近乌云网一直在升级,所以也就暂时无法调用了。个人觉得,如果上述功能都有了,基本上大部分中小规模企业的日常运维工作的高频操作都覆盖到了。
如果是比较大的互联网企业,或者还有一些特殊的业务需求,那就具体问题具体分析了。
作者:刀把五
链接:https://www.zhihu.com/question/23228213/answer/116940889
来源:知乎
部署管理工具:Chef vs Puppet vs Ansible vs SaltStack vs Fabric
运维 OS小编 发表了文章 0 个评论 8958 次浏览 2016-12-28 16:09

Chef,Puppet,Ansible,SaltStack和Fabric的利弊是什么?
今天的生产经常意味着连续部署和分布在世界各地的环境。 当您的基础架构是分散式和基于云的,并且您正在处理在大部分相同的服务器上频繁部署大致相同的服务时,有一种方法来自动化配置和维护一切都是一大福音。 部署管理工具和配置管理工具是为此目的而设计的。 它们使您能够使用配方,剧本,模板或任何术语来简化环境中的自动化和编排,以提供标准,一致的部署。
在此空间中选择工具时,请记住几个注意事项。 一个是工具的模型。 一些需要主客户端模型,其使用集中控制点来与分布式机器通信,而其他人可以或者在更多本地级别上操作。 另一个考虑是你的环境的组成。 一些工具以不同的语言编写,并且对特定操作系统或设置的支持可以不同。 确保您选择的工具与您的环境和您的团队的特殊技能很好地融合在一起可以为您节省很多头痛。
1、Ansible

Ansible是用于在可重复的方式将应用程序部署到远程节点和配置服务器的开源工具。 它为您提供了使用推送模型设置推送多层应用程序和应用程序工件的通用框架,但如果愿意,您可以将其设置为主客户端。 Ansible是建立在playbooks,你可以应用于各种各样的系统部署你的应用程序。

这是Ansible Tower仪表板。
何时使用:如果起床和快速运行,方便地对你很重要,你不想安装在远程节点或托管服务器代理商,考虑Ansible。 如果你的需要或焦点更多在系统管理员方面,这是很好。 Ansible专注于精简和快速,所以如果这些是你的关键问题,给它一个镜头。
价格:有免费的开源版本,付费的Ansible Tower在$ 5,000每年(它给你多达100个节点)支付计划。
优点:
- 基于SSH,因此不需要在远程节点上安装任何代理。
- 使用YAML语法易于学习。
- Playbook结构简单,结构清晰。
- 具有可变注册功能,可使任务为以后的任务注册变量
- 比一些其他工具更加精简的代码库
- 不如基于其他编程语言的工具强大。
- 它的逻辑通过它的DSL,这意味着检查文档经常,直到你学习它
- 即使是基本功能,也需要变量注册,这使得更简单的任务更复杂
- 内省很差。 很难看到playbooks里的变量的价值
- 输入,输出和配置文件的格式之间不一致
- 性能和速度有待加强
2、chef


- 丰富的模块和配置配方集合。
- 代码驱动的方法为您的配置提供更多的控制和灵活性。
- 围绕Git提供强大的版本控制功能。
- “Knife”工具(使用SSH从工作站部署代理)减轻了安装负担。
- 如果你还不熟悉Ruby和过程编码,学习曲线是很陡峭的。
- 这不是一个简单的工具,这可能导致大的代码库和复杂的环境。
- 不支持推送功能。
3、Fabric

- 擅长部署以任何语言编写的应用程序。 它不依赖于系统架构,而是OS和包管理器。
- 比这个领域的其他工具更简单,更容易部署
- 与SSH进行广泛集成,实现基于脚本的精简
- Fabric是单点故障设置(通常是您运行部署的机器)
- 使用推模型,因此不太适合连续部署模型作为这个空间中的一些其他工具
- 虽然它是用于在大多数语言中部署应用程序的一个很好的工具,但它需要Python运行,因此您的Fabric环境中必须至少有一个Python。
4、Puppet


- 通过Puppet Labs建立良好的支持社区。
- 它有最成熟的接口,几乎在每个操作系统上运行。
- 简单的安装和初始设置。
- 在这个空间中最完整的Web UI。
- 强大的报告功能。
- 对于更高级的任务,您将需要使用基于Ruby的CLI(这意味着您必须理解Ruby)。
- 支持纯Ruby版本(而不是使用Puppet的定制DSL)正在缩减。
- 由于DSL和一个不专注于简单性的设计,Puppet代码库可能会变得庞大,笨重,难以在更高规模的组织中接纳新用户。
- 与代码驱动方法相比,模型驱动方法意味着更少的控制。
5、SaltStack

- 一旦您完成设置阶段,即可轻松组织和使用。
- 他们的DSL是功能丰富,并不是逻辑和状态所必需的。
- 输入,输出和配置非常一致 - 所有YAML。
- 内省是非常好的。 很容易看到Salt内发生了什么。
- 强大的社区。
- 在主模型中具有minions和层级层次的高可扩展性和弹性。
- 很难设置和挑选新用户。
- 文档在介绍层面很难理解。
- Web UI比空间中的其他工具的Web UI更新,更不完整。
- 对非Linux操作系统不是很大的支持。
SaltStack介绍视频:https://www.youtube.com/watch?v=TQjE2I8CrzQ
Ansible vs. Chef vs. Fabric vs. Puppet vs. SaltStack
使用哪种配置管理或部署自动化工具将取决于您的环境的需求和首选项。 Chef和Puppet是一些较老的,更成熟的选择,使它们适合于那些重视成熟度和稳定性而不是简单性的大型企业和环境。 Ansible和SaltStack是那些寻求快速和简单的解决方案,而在不需要支持quirky功能或大量的操作系统的环境中工作的人的好选择。 面料是小型环境和那些寻求更低升力和入门级解决方案的好工具。
英文原文:http://blog.takipi.com/deployment-management-tools-chef-vs-puppet-vs-ansible-vs-saltstack-vs-fabric/

