

Zookeeper
Zookeeper新手指南
云原生 空心菜 发表了文章 0 个评论 2269 次浏览 2021-03-27 22:41

目标
今天,我们将开始迈向Apache ZooKeeper的新旅程。在这个ZooKeeper教程中,我们将看到Apache ZooKeeper的含义以及ZooKeeper的流行度。此外,我们将了解ZooKeeper 的功能,优点,应用和用例。此外,我们将讨论不同的术语,如ZooKeeper Client,ZooKeeper Cluster,ZooKeeper WebUI。除此之外,Apache ZooKeeper教程将为使用ZooKeeper的原因提供答案。此外,我们将看到使用ZooKeeper的公司。最后,我们将看到Apache ZooKeeper架构。
由于ZooKeeper本质上是分布式的,因此在进一步研究之前,了解分布式应用程序的一两件事非常重要。因此,首先,我们将看到ZooKeeper讨论,快速介绍分布式应用程序。
那么,让我们开始Apache ZooKeeper教程。
什么是分布式应用程序?
为了以快速有效的方式完成特定任务,分布式应用程序可以在给定时间(同时)在网络中的多个系统上运行。它们可以通过中间协调来实现。此外,我们可以说,通过使用所涉及的所有系统的计算能力,复杂且耗时的任务(需要数小时才能完成非分布式应用程序(在单个系统中运行))可以在几分钟内通过帮助完成分布式应用程序。
此外,通过将分布式应用程序配置为在更多系统上运行,可以进一步减少完成任务的时间。有一个集群,它基本上是一组运行分布式应用程序的系统。在集群中有机器在运行,那些在集群中运行的机器就是我们所说的节点。
通常,服务器和客户端应用程序是分布式应用程序的两个部分。定义两者:
服务器端应用
具有通用接口的分布式应用程序就是我们所说的服务器端应用程序。基本上,它确保客户端可以连接到群集中的任何服务器并获取相同的结果。
客户端应用
有助于与分布式应用程序交互的工具就是我们所说的客户端应用程序。
分布式应用的好处
a.可靠性
如果一个或几个系统发生故障,则不会使整个系统失效。
b.可伸缩性
通过添加更多的机器,只需对应用程序的配置进行少量更改,而无需停机,就可以根据需要提高性能。
c.透明度
这仅仅意味着它隐藏了系统的复杂性。而且,它显示自己是一个单独的实体/应用程序。
分布式应用程序的挑战
1.竞争条件
有时有两个或更多的机器试图执行一个特定的任务,即使当任务实际上只需要在任何给定的时间由一台机器来完成。
2.死锁
为了无限期地完成,两个或多个操作等待彼此。
3.不一致
这意味着数据部分失效。
什么是ZooKeeper?
我们称之为ZooKeeper的分布式协调服务也有助于管理大量主机。由于特别是在分布式环境中管理和协调服务是一个复杂的过程,因此ZooKeeper由于其简单的架构和API而解决了这个问题。ZooKeeper是最好的,不用担心应用程序的分布式特性,它允许开发人员专注于核心应用程序逻辑。
最初,为了以简单而强大的方式访问应用程序,ZooKeeper框架最初是在“Yahoo!”上构建的。但在此之后,为了组织Hadoop,HBase和其他分布式框架所使用的服务,Apache ZooKeeper成为了标准。例如,要跟踪分布式数据的状态,Apache HBase使用ZooKeeper。
此外,它们还可以轻松支持大型Hadoop集群。为了检索信息,每个客户机与其中一个服务器通信。但是,在过去,大多数工作都需要在实现分布式应用程序时修复错误。虽然我们可以说,实现中的这些各种困难是创建ZooKeeper背后的主要原因。因为它简明扼要地关注整个集群的同步和协调。
Zookeeper受众
那些希望通过使用ZooKeeper框架在大数据分析领域开展事业的专业人士可以参考这个Zookeeper序列文章。因为这个Apache ZooKeeper序列教程文章将详细介绍如何使用ZooKeeper创建分布式集群。
Zookeeper运行先决条件
虽然,在继续使用这个ZooKeeper教程之前,必须对Java有一个很好的理解,因为它的服务器运行在JVM,分布式进程以及Linux环境中。
Zookeeper的功能
有一些最好的Apache ZooKeeper功能,这使它从人群中脱颖而出:
简单
在共享的分层命名空间的帮助下,它进行协调。
可靠性
即使多个节点发生故障,系统也会继续运行。
速度
在“读取”更常见的情况下,它以10:1的比例运行。
可扩展性
通过部署更多集群节点,可以提高性能。
ZooKeeper教程设计
下面,我们将讨论Apache ZooKeeper的一些设计目标: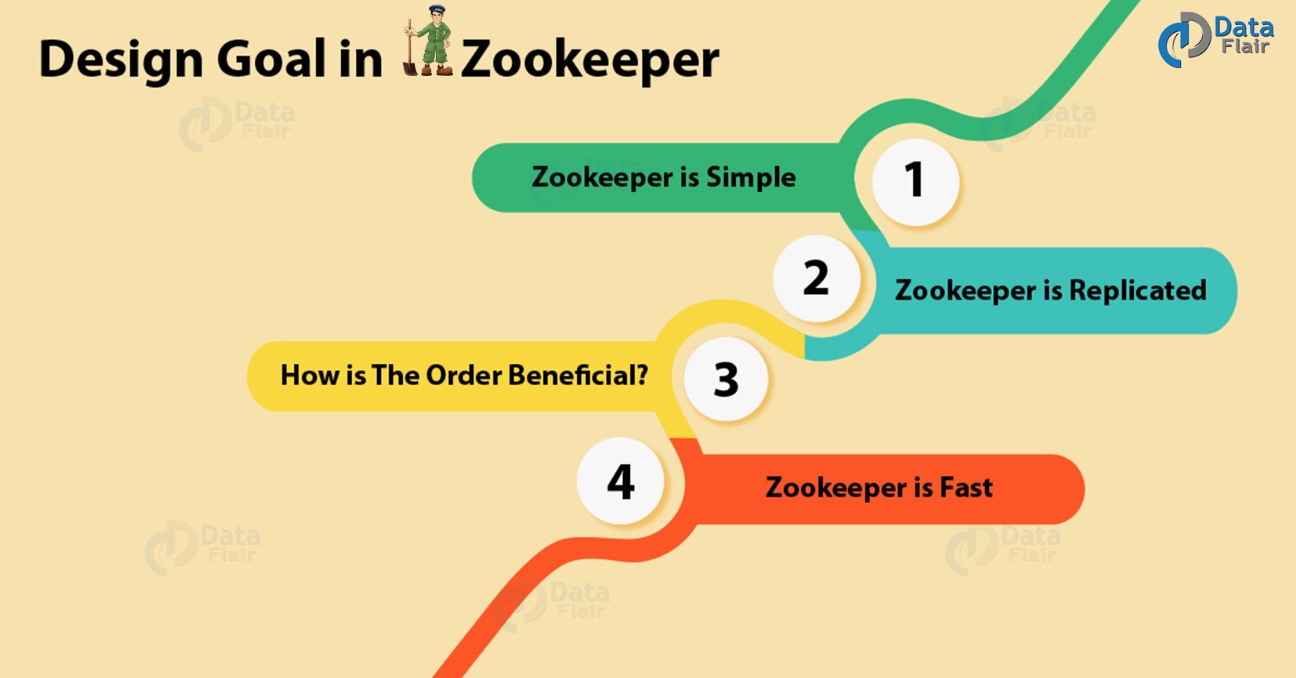
a. Zookeeper是简单的
在使用ZooKeeper时,所有分布式进程都可以相互协调。这种协调可以通过共享的分层命名空间实现。但是,它的组织方式与标准文件系统相同。这里的命名空间由数据寄存器组成,我们称之为znodes,用ZooKeeper的说法。但是,这些与文件和目录相同。此外,ZooKeeper数据保留在内存中,因为它实现了高吞吐量和低延迟数量。
b. Zookeeper支持复制
Apache ZooKeeper本身旨在通过一组称为集合的主机进行复制,就像它协调的分布式进程一样。
c. 如何让Zookeeper顺序一致性更有效?
为了实现更高级别的抽象(同步原语,后续操作),需要使用顺序一致性。
d. Zookeepr很快
特别是,在“读取占优势”的工作负载中,ZooKeeper的工作速度非常快。
Apache ZooKeeper架构
在这个Apache ZooKeeper教程的下面,给出了ZooKeeper架构的几个组成部分,例如:
- 服务器端应用程序:通过通用接口,这些应用程序便于与客户端应用程序进
- 客户端应用程序:有几种工具可以帮助与分布式应用程序进行交互。
- ZooKeeper节点:这些是集群运行的系统。
- Znode:通过集群中的任何节点,我们都可以更新或修改Znode。
我们可以通过一组机器轻松地通过Hadoop ZooKeeper的架构复制ZooKeeper服务。但是,每个都维护一个内存数据树的映像以及事务日志。此外,客户端应用程序联系到单个服务器并且还建立TCP链接。因此,通过他们,他们发送请求,接收回复,观看事件等等。
为什么选择Apache ZooKeeper?
基本上,为了在(节点组)之间进行协调并使用强大的同步技术维护共享数据,集群使用 Apache ZooKeeper。但是,对于编写分布式应用程序,ZooKeeper本身就是一个提供多种服务的分布式应用程序。所以,我们在这里列出了ZooKeeper提供的常用服务,例如: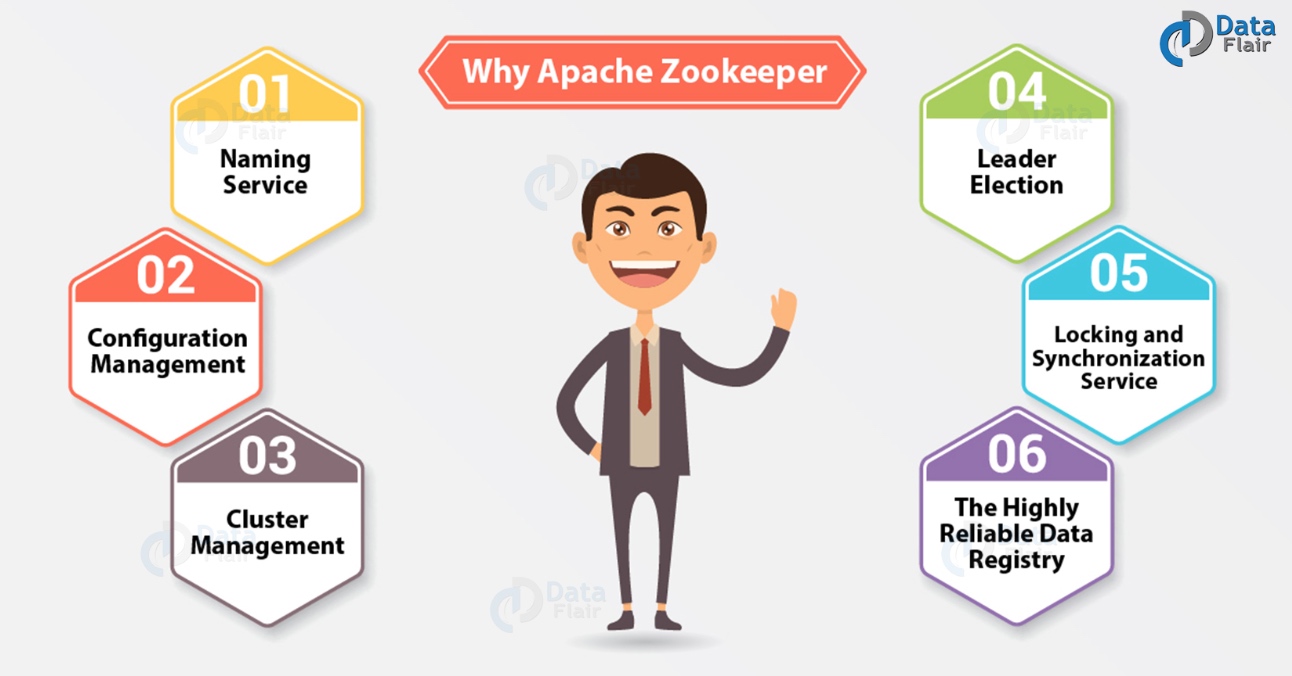
a. 命名服务
在群集中,按名称标识节点。
b. 配置管理
对于加入节点,系统的最新和最新配置信息。
c. 集群管理
实时地,在群集和节点状态中加入/下架节点。
d. Leader选举
出于协调目的,选择一个节点作为领导者。
e. 锁定和同步服务
在修改它时,锁定数据。在连接其他分布式应用程序(如Apache HBase)时,此机制可帮助我们自动进行故障恢复。
f. 高度可靠的数据注册表
即使一个或几个节点关闭 了数据的可用性。
由于分布式应用程序也提供了很少的复杂和难以破解的挑战,因此,为了克服所有挑战,ZooKeeper框架提供了一个完整的机制。此外,使用故障安全同步方法,我们可以处理竞争条件和死锁。此外,ZooKeeper解决了数据与原子性的不一致性。
使用Docker容器化ZooKeeper
通过使用Docker容器化ZooKeeper。因此,作为一个很大的好处,可以按需添加和删除节点。但是,只能通过在Docker镜像中添加ZooKeeper并在集群的每个主服务器上使用它来运行容器。
此外,它应该独立地创建一个集群,或者它应该能够在启动容器期间连接到现有集群并成为其一部分。因此,它允许使用Docker容器化动态重新配置整个Hadoop集群,这是使用Docker容器的好处。
什么是ZooKeeper客户端?
与所有分布式应用程序一样,Zookeeper分布式应用程序也包含服务器和客户端。它有一个集中的界面,客户端可以通过该界面连接到服务。但是,这些客户端可以是命令行或GUI客户端。基本上,可用于与ZooKeeper分布式应用程序交互的工具就是我们所说的ZooKeeper客户端应用程序。
什么是Zookeeper群集?
因为我们需要在集群模式下拥有ZooKeeper基础架构,以便在我们大规模运行Apache ZooKeeper时使系统处于最佳值。我们还将ZooKeeper集群称为集合体。但是,如果ZooKeeper集群必须成功运行,请确保大多数集群节点始终需要启动并运行。
ZooKeeper WebUI
基本上,要使用ZooKeeper资源管理,ZooKeeper WebUI或Web用户界面是一种更简单的方法。因此,WebUI允许使用Web用户界面使用ZooKeeper,而不是使用命令行与ZooKeeper应用程序进行交互。因此,我们可以说它使工作变得更加容易和有效。
Apache ZooKeeper应用程序
简而言之,为了大规模创建高度可用的分布式系统,它已成为最受欢迎的选择之一。因此,Apache基金会最成功的项目之一是ZooKeeper项目。
点击链接了解有关ZooKeeper Applications的更多信息
Apache ZooKeeper通过为实现不同的大数据工具提供坚实的基础,使公司能够在大数据世界中顺利运行。因此,它是大规模实施的最优选应用之一,因为它能够一次提供多种益处。
使用ZooKeeper的公司
现在,在这个Apache ZooKeeper教程中,我们提供了一个使用ZooKeeper的公司列表:
- Yahoo
- 易趣
- eBay
- Netflix
- Netflix
- Zynga
- Nutanix
- 百度
- 腾讯
- 阿里
- 携程
- 京东
- 小米
Apache ZooKeeper的好处
有各种ZooKeeper的好处,例如: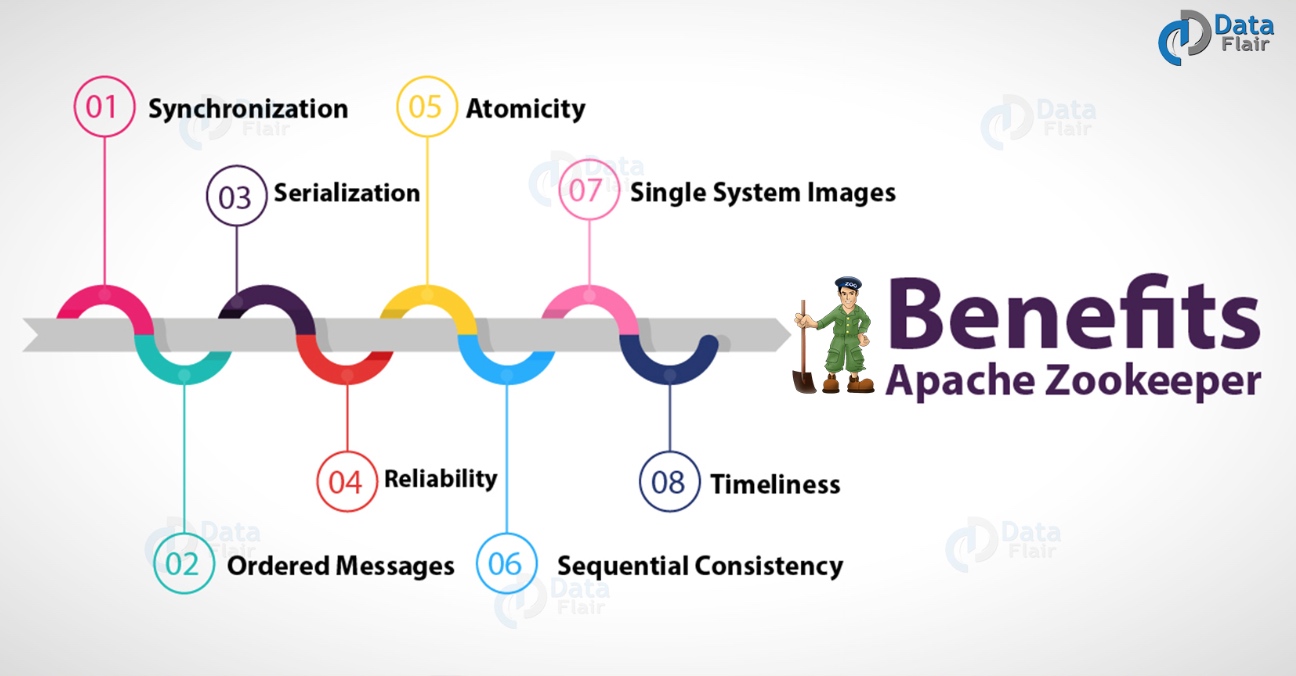
a. 同步
它允许互斥以及服务器进程之间的协作。因此,这有助于Apache HBase,用于配置管理
b. 有序消息
通过用表示其顺序的数字标记每个更新,它会跟踪。
c. 序列化
它确保我们的应用程序一致运行。要协调队列以执行正在运行的线程,可以在MapReduce中使用此方法。
d. 可靠性
应用更新后,它将从该时间开始持续,直到客户端覆盖更新。
e. 原子性
没有事务是部分的,数据传输成功或完全失败。
f. 顺序一致性
按照发送它们的顺序,它应用来自客户端的更新。
g. 单系统镜像
无论它连接到哪个服务器,客户端都会看到相同的服务视图。
h. 及时性
在一定的时间范围内,客户端对系统的视图是最新的。
ZooKeeper用例
Apache ZooKeeper教程中ZooKeeper的一些最突出的用例是:
- 管理配置
- 命名服务
- 选择Leader
- 对消息进行排队
- 管理通知系统
- 同步
通过使用ZooKeeper CLI,我们还可以与ZooKeeper集合进行通信。基本上,这为我们提供了使用各种选项的功能。此外,为了调试,还依赖于命令行界面。
教程英文原文: https://henduan.com/igCAR
Zookeepr参数详解
大数据 Rock 发表了文章 0 个评论 3992 次浏览 2017-05-24 21:47
1.tickTime:Client-Server通信心跳时间
tickTime=20002.initLimit:Leader-Follower初始通信时限
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
initLimit=53.syncLimit:Leader-Follower同步通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
syncLimit=24.dataDir:数据文件目录
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
dataDir=/data/zookeeper/data5.clientPort:客户端连接端口
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
clientPort=21816.服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
这个配置项的书写格式比较特殊,规则如下:
server.N=YYY:A:B
server.1=zk1:2888:38887.ZK为什么设置为奇数个?
server.2=zk2:2888:3888
server.3=zk3:2888:3888
zookeeper有这样一个特性:集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。也就是说如果有2个zookeeper,那么只要有1个死了zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1;同理你多列举几个:2 -> 0; 3 -> 1; 4 - >1; 5 -> 2; 6 -> 2会发现一个规律,2n和2n-1的容忍度是一样的,都是n-1,所以为了更加高效,何必增加那一个不必要的zookeeper呢。增加处理能力,哈哈。。。
Zookeeper日志设置和清理
大数据 push 发表了文章 0 个评论 10230 次浏览 2017-04-11 15:38
一、日志设置
第一步:修改log4j.properties, 这个应该是大家都会去改改, 加粗处是我修改的, 但是只改这个文件后来发现还是不生效
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO,ROLLINGFILE
zookeeper.console.threshold=INFO
zookeeper.log.dir=.
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=.
zookeeper.tracelog.file=zookeeper_trace.log
#
# ZooKeeper Logging Configuration
#
# Format is "(, )+
# DEFAULT: console appender only
log4j.rootLogger=${zookeeper.root.logger}
# Example with rolling log file
#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE
# Example with rolling log file and tracing
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
#
# Log INFO level and above messages to the console
#
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender //按天日记轮转
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
# Max log file size of 10MB
#log4j.appender.ROLLINGFILE.MaxFileSize=10MB
# uncomment the next line to limit number of backup files
#log4j.appender.ROLLINGFILE.MaxBackupIndex=10
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add TRACEFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
log4j.appender.TRACEFILE.Threshold=TRACE
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
### Notice we are including log4j's NDC here (%x)
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
第二步:还需要改${zkhome}/bin/zkEnv.sh, 注意加粗处, 这时日志已经可以成功按照你设置的目录进行输出了
#!/usr/bin/env bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script should be sourced into other zookeeper
# scripts to setup the env variables
# We use ZOOCFGDIR if defined,
# otherwise we use /etc/zookeeper
# or the conf directory that is
# a sibling of this script's directory
ZOOBINDIR="${ZOOBINDIR:-/usr/bin}"
ZOOKEEPER_PREFIX="${ZOOBINDIR}/.."
if [ "x$ZOOCFGDIR" = "x" ]
then
if [ -e "${ZOOKEEPER_PREFIX}/conf" ]; then
ZOOCFGDIR="$ZOOBINDIR/../conf"
else
ZOOCFGDIR="$ZOOBINDIR/../etc/zookeeper"
fi
fi
if [ -f "${ZOOCFGDIR}/zookeeper-env.sh" ]; then
. "${ZOOCFGDIR}/zookeeper-env.sh"
fi
if [ "x$ZOOCFG" = "x" ]
then
ZOOCFG="zoo.cfg"
fi
ZOOCFG="$ZOOCFGDIR/$ZOOCFG"
if [ -f "$ZOOCFGDIR/java.env" ]
then
. "$ZOOCFGDIR/java.env"
fi
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/data/zookeeper/outlogs/"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
if [ "$JAVA_HOME" != "" ]; then
JAVA="$JAVA_HOME/bin/java"
else
JAVA=java
fi
#add the zoocfg dir to classpath
CLASSPATH="$ZOOCFGDIR:$CLASSPATH"
for i in "$ZOOBINDIR"/../src/java/lib/*.jar
do
CLASSPATH="$i:$CLASSPATH"
done
#make it work in the binary package
#(use array for LIBPATH to account for spaces within wildcard expansion)
if [ -e "${ZOOKEEPER_PREFIX}"/share/zookeeper/zookeeper-*.jar ]; then
LIBPATH=("${ZOOKEEPER_PREFIX}"/share/zookeeper/*.jar)
else
#release tarball format
for i in "$ZOOBINDIR"/../zookeeper-*.jar
do
CLASSPATH="$i:$CLASSPATH"
done
LIBPATH=("${ZOOBINDIR}"/../lib/*.jar)
fi
for i in "${LIBPATH[@]}"
do
CLASSPATH="$i:$CLASSPATH"
done
#make it work for developers
for d in "$ZOOBINDIR"/../build/lib/*.jar
do
CLASSPATH="$d:$CLASSPATH"
done
#make it work for developers
CLASSPATH="$ZOOBINDIR/../build/classes:$CLASSPATH"
case "`uname`" in
CYGWIN*) cygwin=true ;;
*) cygwin=false ;;
esac
if $cygwin
then
CLASSPATH=`cygpath -wp "$CLASSPATH"`
fi
#echo "CLASSPATH=$CLASSPATH"
第三步:设置zookeeper.out
zookeeper.out由nohup的输出,也就是zookeeper的stdout和stdeer输出,修改bin/zkServer.sh 文件:
_ZOO_DAEMON_OUT="$ZOO_LOG_DIR/zookeeper.out"
case $1 in
start)
echo -n "Starting zookeeper ... "
if [ -f $ZOOPIDFILE ]; then
if kill -0 `cat $ZOOPIDFILE` > /dev/null 2>&1; then
echo $command already running as process `cat $ZOOPIDFILE`.
exit 0
fi
fi
nohup $JAVA "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
第四步:快照事物日志
在使用zookeeper过程中,我们知道,会有dataDir和dataLogDir两个目录,分别用于snapshot和事务日志的输出(默认情况下只有dataDir目录,snapshot和事务日志都保存在这个目录中),通过zoo.cfg配置文件可配置:
#snapshot file dir
dataDir=/data/zookeeper/data
#tran log dir
dataLogDir=/data/zookeeper/log
二、日志清理
正常运行过程中,ZK会不断地把快照数据和事务日志输出到这两个目录,并且如果没有人为操作的话,ZK自己是不会清理这些文件的,需要管理员来清理,这里介绍4种清理日志的方法。在这4种方法中,推荐使用第一种方法,对于运维人员来说,将日志清理工作独立出来,便于统一管理也更可控。毕竟zk自带的一些工具并不怎么给力,这里是社区反映的两个问题:
https://issues.apache.org/jira/browse/ZOOKEEPER-957
http://zookeeper-user.578899.n2.nabble.com/PurgeTxnLog-td6304244.html
第一种,也是运维人员最常用的,写一个删除日志脚本,每天定时执行即可:
#!/bin/bash以上这个脚本定义了删除对应三个目录中的文件,保留最新的60个文件,可以将他写到crontab中,设置为每天凌晨2点执行一次就可以了。
#snapshot file dir
dataDir=/data/zookeeper/data/version-2
#tran log dir
dataLogDir=/data/zookeeper/log/version-2
#zk log dir
logDir=/data/zookeeper/outlog/
#Leave 60 files
count=60
count=$[$count+1]
ls -t $dataLogDir/log.* | tail -n +$count | xargs rm -f
ls -t $dataDir/snapshot.* | tail -n +$count | xargs rm -f
ls -t $logDir/zookeeper.log.* | tail -n +$count | xargs rm -f
第二种,使用ZK的工具类PurgeTxnLog,它的实现了一种简单的历史文件清理策略,可以在这里看一下他的使用方法:http://zookeeper.apache.org/doc/r3.4.3/api/index.html ,可以指定要清理的目录和需要保留的文件数目,简单使用如下:
java -cp zookeeper.jar:lib/slf4j-api-1.6.1.jar:lib/slf4j-log4j12-1.6.1.jar:lib/log4j-1.2.15.jar:conf org.apache.zookeeper.server.PurgeTxnLog第三种,对于上面这个Java类的执行,ZK自己已经写好了脚本,在bin/zkCleanup.sh中,所以直接使用这个脚本也是可以执行清理工作的。-n
第四种,从3.4.0开始,zookeeper提供了自动清理snapshot和事务日志的功能,通过配置 autopurge.snapRetainCount 和 autopurge.purgeInterval 这两个参数能够实现定时清理了。这两个参数都是在zoo.cfg中配置的:
autopurge.purgeInterval: 24*2autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
autopurge.snapRetainCount: 2
autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。
参考:http://nileader.blog.51cto.com/1381108/932156
Python可用的分布式协调系统(ZooKeeper,Consul, etcd)介绍
大数据 push 发表了文章 0 个评论 8404 次浏览 2016-06-19 22:52
在对分布式的应用做协调的时候,主要会碰到以下的应用场景:
- []业务发现(service discovery)[/]
- []名字服务 (name service)[/]
- []配置管理 (configuration management)[/]
- []故障发现和故障转移 (failure detection and failover)[/]
- []领导选举(leader election)[/]
- []分布式的锁 (distributed exclusive lock)[/]
- []消息和通知服务 (message queue and notification)[/]
Zookeeper 是使用最广泛,也是最有名的解决分布式服务的协调问题的开源软件了,它最早和Hadoop一起开发,后来成为了Apache的顶级项目,很多开源的项目都在使用ZooKeeper,例如大名鼎鼎的Kafka。 Zookeeper本身是一个分布式的应用,通过对共享的数据的管理来实现对分布式应用的协调。ZooKeeper使用一个树形目录作为数据模型,这个目录和文件目录类似,目录上的每一个节点被称作ZNodes。ZooKeeper

from kazoo.client import KazooClientimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Ensure a path, create if necessaryzk.ensure_path("/test/zk1")# Create a node with datazk.create("/test/zk1/node", b"a test value")# Determine if a node existsif zk.exists("/test/zk1"): print "the node exist"# Print the version of a node and its datadata, stat = zk.get("/test/zk1")print("Version: %s, data: %s" % (stat.version, data.decode("utf-8")))# List the childrenchildren = zk.get_children("/test/zk1")print("There are %s children with names %s" % (len(children), children))zk.stop()通过对ZNode的操作,我们可以完成一些分布式服务协调的基本需求,包括名字服务,配置服务,分组等等。 故障检测(Failure Detection)在分布式系统中,一个最基本的需求就是当某一个服务出问题的时候,能够通知其它的节点或者某个管理节点。ZooKeeper提供ephemeral Node的概念,当创建该Node的服务退出或者异常中止的时候,该Node会被删除,所以我们就可以利用这种行为来监控服务运行状态。以下是worker的代码from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Ensure a path, create if necessaryzk.ensure_path("/test/failure_detection")# Create a node with datazk.create("/test/failure_detection/worker", value=b"a test value", ephemeral=True)while True: print "I am alive!" time.sleep(3)zk.stop()以下的monitor 代码,监控worker服务是否运行。from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Determine if a node existswhile True: if zk.exists("/test/failure_detection/worker"): print "the worker is alive!" else: print "the worker is dead!" break time.sleep(3)zk.stop()领导选举Kazoo直接提供了领导选举的API,使用起来非常方便。from kazoo.client import KazooClientimport timeimport uuidimport logginglogging.basicConfig()my_id = uuid.uuid4()def leader_func(): print "I am the leader {}".format(str(my_id)) while True: print "{} is working! ".format(str(my_id)) time.sleep(3)zk = KazooClient(hosts='127.0.0.1:2181')zk.start()election = zk.Election("/electionpath")# blocks until the election is won, then calls# leader_func()election.run(leader_func)zk.stop()你可以同时运行多个worker,其中一个会获得Leader,当你杀死当前的leader后,会有一个新的leader被选出。 分布式锁锁的概念大家都熟悉,当我们希望某一件事在同一时间只有一个服务在做,或者某一个资源在同一时间只有一个服务能访问,这个时候,我们就需要用到锁。from kazoo.client import KazooClientimport timeimport uuidimport logginglogging.basicConfig()my_id = uuid.uuid4()def work(): print "{} is working! ".format(str(my_id))zk = KazooClient(hosts='127.0.0.1:2181')zk.start()lock = zk.Lock("/lockpath", str(my_id))print "I am {}".format(str(my_id))while True: with lock: work() time.sleep(3) zk.stop()当你运行多个worker的时候,不同的worker会试图获取同一个锁,然而只有一个worker会工作,其它的worker必须等待获得锁后才能执行。 监视ZooKeeper提供了监视(Watch)的功能,当节点的数据被修改的时候,监控的function会被调用。我们可以利用这一点进行配置文件的同步,发消息,或其他需要通知的功能。from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()@zk.DataWatch('/path/to/watch')def my_func(data, stat): if data: print "Data is %s" % data print "Version is %s" % stat.version else : print "data is not available"while True: time.sleep(10)zk.stop()除了我们上面列举的内容外,Kazoo还提供了许多其他的功能,例如:计数,租约,队列等等,大家有兴趣可以参考它的文档。 Consul 是用Go开发的分布式服务协调管理的工具,它提供了服务发现,健康检查,Key/Value存储等功能,并且支持跨数据中心的功能。Consul提供ZooKeeper类似的功能,它的基于HTTP的API可以方便的和各种语言进行绑定。自然Python也在列。与Zookeeper有所差异的是Consul通过基于Client/Server架构的Agent部署来支持跨Data Center的功能。Consul

import consulc = consul.Consul()# set data for key fooc.kv.put('foo', 'bar')# poll a key for updatesindex = Nonewhile True: index, data = c.kv.get('foo', index=index) print data['Value'] c.kv.delete('foo')这里和ZooKeeper对Znode的操作几乎是一样的。 服务发现(Service Discovery)和健康检查(Health Check) Consul的另一个主要的功能是用于对分布式的服务做管理,用户可以注册一个服务,同时还提供对服务做健康检测的功能。首先,用户需要定义一个服务。{ "service": { "name": "redis", "tags": ["master"], "address": "127.0.0.1", "port": 8000, "checks": [ { "script": "/usr/local/bin/check_redis.py", "interval": "10s" } ] }}其中,服务的名字是必须的,其它的字段可以自选,包括了服务的地址,端口,相应的健康检查的脚本。当用户注册了一个服务后,就可以通过Consul来查询该服务,获得该服务的状态。 Consul支持三种Check的模式:- []调用一个外部脚本(Script),在该模式下,consul定时会调用一个外部脚本,通过脚本的返回内容获得对应服务的健康状态。[/][]调用HTTP,在该模式下,consul定时会调用一个HTTP请求,返回2XX,则为健康;429 (Too many request)是警告。其它均为不健康[/][]主动上报,在该模式下,服务需要主动调用一个consul提供的HTTP PUT请求,上报健康状态。[/]
- []Consul.Agent.Service[/][]Consul.Agent.Check[/]
import consulimport timec = consul.Consul()s = c.session.create(name="worker",behavior='delete',ttl=10)print "session id is {}".format(s)while True: c.session.renew(s) print "I am alive ..." time.sleep(3)Moniter代码用于监控worker相关联的session的状态,但发现worker session已经不存在了,就做出响应的处理。import consulimport timedef is_session_exist(name, sessions): for s in sessions: if s['Name'] == name: return True return Falsec = consul.Consul()while True: index, sessions = c.session.list() if is_session_exist('worker', sessions): print "worker is alive ..." else: print 'worker is dead!' break time.sleep(3)这里注意,因为是基于ttl(最小10秒)的检测,从业务中断到被检测到,至少有10秒的时延,对应需要实时响应的情景,并不适用。Zookeeper使用ephemeral Node的方式时延相对短一点,但也非实时。 领导选举和分布式的锁 无论是Consul本身还是Python客户端,都不直接提供Leader Election的功能,但是这篇文档介绍了如何利用Consul的KV存储来实现Leader Election,利用Consul的KV功能,可以很方便的实现领导选举和锁的功能。当对某一个Key做put操作的时候,可以创建一个session对象,设置一个acquire标志为该 session,这样就获得了一个锁,获得所得客户则是被选举的leader。代码如下:import consulimport timec = consul.Consul()def request_lead(namespace, session_id): lock = c.kv.put(leader_namespace,"leader check", acquire=session_id) return lockdef release_lead(session_id): c.session.destroy(session_id)def whois_lead(namespace): index,value = c.kv.get(namespace) session = value.get('Session') if session is None: print 'No one is leading, maybe in electing' else: index, value = c.session.info(session) print '{} is leading'.format(value['ID'])def work_non_block(): print "working"def work_block(): while True: print "working" time.sleep(3)leader_namespace = 'leader/test'[size=16] initialize leader key/value node[/size]leader_index, leader_node = c.kv.get(leader_namespace)if leader_node is None: c.kv.put(leader_namespace,"a leader test")while True: whois_lead(leader_namespace) session_id = c.session.create(ttl=10) if request_lead(leader_namespace,session_id): print "I am now the leader" work_block() release_lead(session_id) else: print "wait leader elected!" time.sleep(3)利用同样的机制,可以方便的实现锁,信号量等分布式的同步操作。 监视Consul的Agent提供了Watch的功能,然而Python客户端并没有相应的接口。 Etcd 是另一个用GO开发的分布式协调应用,它提供一个分布式的Key/Value存储来进行共享的配置管理和服务发现。 同样的etcd使用基于HTTP的API,可以灵活的进行不同语言的绑定,我们用的是这个客户端https://github.com/jplana/python-etcd 基本操作Etcd
import etcdclient = etcd.Client() client.write('/nodes/n1', 1)print client.read('/nodes/n1').valueetcd对节点的操作和ZooKeeper类似,不过etcd不支持ZooKeeper的ephemeral Node的概念,要监控服务的状态似乎比较麻烦。 分布式锁etcd支持分布式锁,以下是一个例子。import syssys.path.append("../../")import etcdimport uuidimport timemy_id = uuid.uuid4()def work(): print "I get the lock {}".format(str(my_id))client = etcd.Client() lock = etcd.Lock(client, '/customerlock', ttl=60)with lock as my_lock: work() lock.is_locked() # True lock.renew(60)lock.is_locked() # False老版本的etcd支持leader election,但是在最新版该功能被deprecated了,参见https://coreos.com/etcd/docs/0.4.7/etcd-modules/ 其它 我们针对分布式协调的功能讨论了三个不同的开源应用,其实还有许多其它的选择,我这里就不一一介绍,大家有兴趣可以访问以下的链接:- []eureka https://github.com/Netflix/eureka [/]
- []curator http://curator.apache.org/[/]
- []doozerd https://github.com/ha/doozerd[/]
- []openreplica http://openreplica.org/[/]
- []serf http://www.serfdom.io/[/]
- []noah https://github.com/lusis/Noah[/]
- []copy cat https://github.com/kuujo/copycat[/]
基于日志的分布式协调的框架,使用Java开发
总结
ZooKeeper无疑是分布式协调应用的最佳选择,功能全,社区活跃,用户群体很大,对所有典型的用例都有很好的封装,支持不同语言的绑定。缺点是,整个应用比较重,依赖于Java,不支持跨数据中心。
Consul作为使用Go语言开发的分布式协调,对业务发现的管理提供很好的支持,他的HTTP API也能很好的和不同的语言绑定,并支持跨数据中心的应用。缺点是相对较新,适合喜欢尝试新事物的用户。
etcd是一个更轻量级的分布式协调的应用,提供了基本的功能,更适合一些轻量级的应用来使用。
参考
如果大家对于分布式系统的协调想要进行更多的了解,可以阅读一下的链接:
http://stackoverflow.com/questions/6047917/zookeeper-alternatives-cluster-coordination-service
http://txt.fliglio.com/2014/05/encapsulated-services-with-consul-and-confd/
http://txt.fliglio.com/2013/12/service-discovery-with-docker-docker-links-and-beyond/
http://www.serfdom.io/intro/vs-zookeeper.html
http://devo.ps/blog/zookeeper-vs-doozer-vs-etcd/
https://www.digitalocean.com/community/articles/how-to-set-up-a-serf-cluster-on-several-ubuntu-vps
http://www.slideshare.net/JyrkiPulliainen/taming-pythons-with-zoo-keeper-ep2013?qid=e1267f58-090d-4147-9909-ec673525e76b&v=qf1&b=&from_search=8
http://muratbuffalo.blogspot.com/2014/09/paper-summary-tango-distributed-data.html
https://developer.yahoo.com/blogs/hadoop/apache-zookeeper-making-417.html
http://www.knewton.com/tech/blog/2014/12/eureka-shouldnt-use-zookeeper-service-discovery
http://codahale.com/you-cant-sacrifice-partition-tolerance/
原文地址:http://my.oschina.net/taogang/blog/410864
基于Zookeeper的服务注册与发现案例分析
大数据 空心菜 发表了文章 0 个评论 4239 次浏览 2016-03-16 17:22
背景
大多数系统都是从一个单一系统开始起步的,随着公司业务的快速发展,这个单一系统变得越来越庞大,带来几个问题:
- []随着访问量的不断攀升,纯粹通过提升机器的性能来已经不能解决问题,系统无法进行有效的水平扩展[/][]维护这个单一系统,变得越来越复杂[/][]同时,随着业务场景的不同以及大研发的招兵买马带来了不同技术背景的工程师,在原有达达Python技术栈的基础上,引入了Java技术栈。[/]
如何来解决这些问题?业务服务化是个有效的手段来解决大规模系统的性能瓶颈和复杂性。通过系统拆分将原有的单一庞大系统拆分成小系统,它带来了如下好处:
- []原来系统的压力得到很好的分流,有效地解决了原先系统的瓶颈,同时带来了更好的扩展性[/][]独立的代码库,更少的业务逻辑,系统的维护性得到极大的增强[/]
同时,也带来了一系列问题:
- []随着系统服务的越来越多,如何来管理这些服务?[/][]如何分发请求到提供同一服务的多台主机上(负载均衡如何来做)[/][]如果提供服务的Endpoint发生变化,如何将这些信息通知服务的调用方?[/]
Linkedin的创始人里德霍夫曼曾经说过:最初的解决方案
成立一家初创公司就像把自己从悬崖上扔下来,在降落过程中去组装一架飞机。这对于初创公司达达也是一样的,业务在以火箭般的速度发展着。技术在业务发展中作用就是保障业务的稳定运行,快速地“组装一架飞机”。所以,在业务服务化的早期,我们采用了Nginx+本地hosts文件的方式进行内部服务的注册与发现,架构图如下:

- []最明显的问题是Nginx存在单点故障(SPOF),同时随着访问量的提升,会成为一个性能瓶颈[/][]随着内部服务的越来越多,不同的服务消费方需要配置不同的hosts,很容易在增加新的主机时忘记配置hosts导致服务不能调用问题,增加了运维负担[/][]服务的配置信息分散在各个主机hosts中,难以保持一致性,不便于服务的管理[/][]服务主机的发布和下线需要手工的修改Nginx upstream配置,修改的配置需要上线,不利于服务的快速部署[/]
在谈如何来解决之前,现梳理一下服务注册与发现的目标:如何解决
- []服务的注册信息应该统一保存,方便于服务的管理[/][]自动通过服务的名称去发现服务,而不必了解这个服务提供的end-point到底是哪台主机[/][]支持服务的负载均衡及fail-over[/][]增加或移除某个服务的end-point时,对于服务的消费者来说是透明的[/][]支持Python和Java[/]
DNS作为服务注册发现的一种方案,它比较简单。只要在DNS服务上,配置一个DNS名称与IP对应关系即可。定位一个服务只需要连接到DNS服务器上,随机返回一个IP地址即可。由于存在DNS缓存,所以DNS服务器本身不会成为一个瓶颈。
这种基于Pull的方式不能及时获取服务的状态的更新(例如:服务的IP更新等)。如果服务的提供者出现故障,由于DNS缓存的存在,服务的调用方会仍然将请求转发给出现故障的服务提供方;反之亦然。备选方案二:DubboDubbo是阿里巴巴推出的分布式服务框架,致力于解决服务的注册与发现,编排,治理。它的优点如下:[list=1][]功能全面,易于扩展[/][]支持各种序列化协议(JSON,Hession,java序列化等)[/][]支持各种RPC协议(HTTP,Java RMI,Dubbo自身的RPC协议等)[/][]支持多种负载均衡算法[/][]其他高级特性:服务编排,服务治理,服务监控等[/]缺点如下:[list=1][]只支持Java,对于Python没有相应的支持[/][]虽然已经开源,但是没有成熟的社区来运营和维护,未来升级可能是个麻烦[/][]重量级的解决方案带来新的复杂性[/]备选方案三:ZookeeperZookeeper是什么?按照Apache官网的描述是:
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.参照官网的定义,它能够做:[list=1][]作为配置信息的存储的中心服务器[/][]命名服务[/][]分布式的协调[/][]Mater选举等[/]在定义中特别提到了命名服务。在调研之后,Zookeeper作为服务注册与发现的解决方案;它有如下优点:[list=1][]它提供的简单API[/][]已有互联网公司(例如:Pinterest,Airbnb)使用它来进行服务注册与发现[/][]支持多语言的客户端[/][]通过Watcher机制实现Push模型,服务注册信息的变更能够及时通知服务消费方[/]缺点是:[list=1][]引入新的Zookeeper组件,带来新的复杂性和运维问题[/][]需自己通过它提供的API来实现服务注册与发现逻辑(包含Python与Java版本)[/]针对对上述几个方案的优缺点权衡之后,决定采用了基于Zookeeper实现自己的服务注册与发现。
基于Zookeeper的服务注册与发现架构

- []隶属于哪个系统[/][]服务的IP,端口[/][]服务的请求URL[/][]服务的权重等等[/]
服务消费者只在自己初始化以及服务变更时会依赖服务注册中心,在此阶段的单点故障通过Zookeeper集群来进行保障。在整个服务调用过程中,服务消费者不依赖于任何第三方服务。
Zookeeper数据模型介绍在整个服务注册与发现的设计中,最重要是如何来存储服务的注册信息。在设计基于Zookeeper的服务注册结构之前,我们先来看一下Zookeeper的数据模型。Zookeeper的数据模型如下图所示:实现机制介绍

Zookeeper数据模型结构与Unix文件系统很类似,是一个树状层次结构。每个节点叫做Znode,节点可以拥有子节点,同时允许将少量数据存储在该节点下。客户端可以通过监听节点的数据变更和子节点变更来实时获取Znode的变更(Wather机制)。服务注册结构

- []/dada来标示公司名称dada,同时能方便与其它应用的目录区分开(例如:Kafka的brokers注册信息放置在/brokers下)[/][]/dada/services将所有服务提供者都放置该目录下[/][]/dada/services/category1目录定义具体的服务提供者的id:category1,同时该Znode节点中允许存放该服务提供者的一些元数据信息,例如:名称,服务提供者的Owner,上下文路径(Java Web项目),健康检查路径等。该信息可以根据实际需要进行自由扩展。[/][]/dada/services/category1/helloworld节点定义了服务提供者category1下的一个服务:helloworld。其中helloworld为该服务的ID,同时允许将该服务的元数据信息存储在该Znode下,例如图中标示的:服务名称,服务描述,服务路径,服务的调用的schema,服务的调用的HTTP METHOD等。该信息可以根据实际需要进行自由扩展。[/][]/dada/services/category1/helloworld/providers节点定义了服务提供者的父节点。在这里其实可以将服务提供者的IP和端口直接放置在helloworld节点下,在这里单独放一个节点,是为了将来可以将服务消费者的消息挂载在helloworld节点下,进行一些扩展,例如命名为:/dada/services/category1/helloworld/consumers。[/][]/dada/services/category__1/helloworld/providers/192.168.1.1:8080该节点定义了服务提供者的IP和端口,同时在节点中定义了该服务提供者的权重。[/]
由于目前服务注册通过我们的服务注册中心UI来进行注册,这部分逻辑比较简单,即通过UI界面来构造上述定义的服务注册结构。下面着重介绍一下我们的服务发现是如何工作的:实现机制

LoadBalanceStrategy定义了根据服务提供者的信息返回对应的服务Host和IP,即决定由那台主机+端口来提供服务。
RoundRobinStrategy和RandomStrategy分别实现了Round-Robin和随机的负载均衡算法
未来展望
目前达达基于Zookeeper的服务注册与发现的架构还处于初期,很多功能还未完善,例如:服务的路由功能,与部署平台的集成,服务的监控等等。
当然基于Zookeeper还能做其它许多事情,例如:实时动态配置系统。目前,我们已经基于Zookeeper实现了实时动态配置系统。
分享原文地址:https://tech.imdada.cn/2015/12/03/service-registry-and-discovery-with-zk/
作者:杨 骏 达达CTO
ZooKeeper架构设计及其应用
运维 chris 发表了文章 0 个评论 8962 次浏览 2016-03-11 23:45
ZooKeeper是一个开源的分布式服务框架,它是Apache Hadoop项目的一个子项目,主要用来解决分布式应用场景中存在的一些问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置管理等,它支持Standalone模式和分布式模式,在分布式模式下,能够为分布式应用提供高性能和可靠地协调服务,而且使用ZooKeeper可以大大简化分布式协调服务的实现,为开发分布式应用极大地降低了成本。
总体架构
ZooKeeper分布式协调服务框架的总体架构,如图所示:

ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower。当客户端Client连接到ZooKeeper集群,并且执行写请求时,这些请求会被发送到Leader节点上,然后Leader节点上数据变更会同步到集群中其他的Follower节点。
Leader节点在接收到数据变更请求后,首先将变更写入本地磁盘,以作恢复之用。当所有的写请求持久化到磁盘以后,才会将变更应用到内存中。
ZooKeeper使用了一种自定义的原子消息协议,在消息层的这种原子特性,保证了整个协调系统中的节点数据或状态的一致性。Follower基于这种消息协议能够保证本地的ZooKeeper数据与Leader节点同步,然后基于本地的存储来独立地对外提供服务。
当一个Leader节点发生故障失效时,失败故障是快速响应的,消息层负责重新选择一个Leader,继续作为协调服务集群的中心,处理客户端写请求,并将ZooKeeper协调系统的数据变更同步(广播)到其他的Follower节点。
设计要点
ZooKeeper是基于如下4个目标来进行权衡和设计的,我们从设计及其特性的角度来详细说明:
- []简单[/]

在ZooKeeper中每个命名空间(Namespace)被称为ZNode,你可以这样理解,每个ZNode包含一个路径和与之相关的元数据,以及继承自该节点的孩子列表。与传统文件系统不同的是,ZooKeeper中的数据保存在内存中,实现了分布式同步服务的高吞吐和低延迟。[list=1][]在上图示例的ZooKeeper的数据模型中,有如下要点:[/][list=1][]每个节点(ZNode)中存储的是同步相关的数据(这是ZooKeeper设计的初衷,数据量很小,大概B到KB量级),例如状态信息、配置内容、位置信息等。[/][]一个ZNode维护了一个状态结构,该结构包括:版本号、ACL变更、时间戳。每次ZNode数据发生变化,版本号都会递增,这样客户端的读请求可以基于版本号来检索状态相关数据。[/][]每个ZNode都有一个ACL,用来限制是否可以访问该ZNode。[/][]在一个命名空间中,对ZNode上存储的数据执行读和写请求操作都是原子的。[/][]客户端可以在一个ZNode上设置一个监视器(Watch),如果该ZNode数据发生变更,ZooKeeper会通知客户端,从而触发监视器中实现的逻辑的执行。[/][]每个客户端与ZooKeeper连接,便建立了一次会话(Session),会话过程中,可能发生CONNECTING、CONNECTED和CLOSED三种状态。[/][]ZooKeeper支持临时节点(Ephemeral Nodes)的概念,它是与ZooKeeper中的会话(Session)相关的,如果连接断开,则该节点被删除。[/]
- []冗余[/]
ZooKeeper被设计为复制集群架构,每个节点的数据都可以在集群中复制传播,使集群中的每个节点数据同步一致,从而达到服务的可靠性和可用性。前面说到,ZooKeeper将数据放在内存中来提高性能,为了避免发生单点故障(SPOF),支持数据的复制来达到冗余存储,这是必不可少的。
- []有序[/]
ZooKeeper使用时间戳来记录导致状态变更的事务性操作,也就是说,一组事务通过时间戳来保证有序性。基于这一特性。ZooKeeper可以实现更加高级的抽象操作,如同步等。
- []快速[/]
ZooKeeper包括读写两种操作,基于ZooKeeper的分布式应用,如果是读多写少的应用场景(读写比例大约是10:1),那么读性能更能够体现出高效。
数据模型
ZooKeeper有一个分层的命名空间,结构类似文件系统的目录结构,非常简单而直观。其中,ZNode是最重要的概念,前面我们已经描述过。另外,有ZNode有关的还包括Watches、ACL、临时节点、序列节点(Sequence Node)。
- []ZNode结构[/]
- []Watches(监视)[/]
ZooKeeper中的Watch是只能触发一次。也就是说,如果客户端在指定的ZNode设置了Watch,如果该ZNode数据发生变更,ZooKeeper会发送一个变更通知给客户端,同时触发设置的Watch事件。如果ZNode数据又发生了变更,客户端在收到第一次通知后没有重新设置该ZNode的Watch,则ZooKeeper就不会发送一个变更通知给客户端。
ZooKeeper异步通知设置Watch的客户端。但是ZooKeeper能够保证在ZNode的变更生效之后才会异步地通知客户端,然后客户端才能够看到ZNode的数据变更。由于网络延迟,多个客户端可能会在不同的时间看到ZNode数据的变更,但是看到变更的顺序是能够保证有序一致的。
ZNode可以设置两类Watch,一个是Data Watches(该ZNode的数据变更导致触发Watch事件),另一个是Child Watches(该ZNode的孩子节点发生变更导致触发Watch事件)。调用getData()和exists() 方法可以设置Data Watches,调用getChildren()方法可以设置Child Watches。调用setData()方法触发在该ZNode的注册的Data Watches。调用create()方法创建一个ZNode,将触发该ZNode的Data Watches;调用create()方法创建ZNode的孩子节点,则触发ZNode的Child Watches。调用delete()方法删除ZNode,则同时触发Data Watches和Child Watches,如果该被删除的ZNode还有父节点,则父节点触发一个Child Watches。
另外,如果客户端与ZooKeeper Server断开连接,客户端就无法触发Watches,除非再次与ZooKeeper Server建立连接。
- []Sequence Nodes(序列节点)[/]
qn-0000000001, qn-0000000002, qn-0000000003, qn-0000000004, qn-0000000005, qn-0000000006, qn-0000000007
- []ACLs(访问控制列表)[/]
- []ZooKeeper Session[/]
当客户端连接到ZooKeeper集群时,建立了会话。会话过程中的状态变迁,如图所示:

建立连接过程中,会话状态为CONNECTING;当连接建立成功后,会话状态变为CONNECTED。会话过程中,如果正常的话,会话的状态只能是CONNECTING和CONNECTED二者之一。如果在会话过程中连接断开,则变为CLOSED状态。
应用陷阱
并非任何分布式应用都适合使用ZooKeeper来构建协调服务,我们根据ZooKeeper提供的文档,给出哪些情况下使用会出现问题,又是如何应对这种问题的。总结如下:
1、丢失ZNode上的变更通知
客户端连接到ZooKeeper Server以后,会维护一个TCP连接。在CONNECTED状态下,客户端设置了某个ZNode的Watch监听器,可以收到来自该节点变更的通知(后续会触发一定的逻辑执行流程)。但是,如果由于网络异常,客户端断开了与ZooKeeper Server的连接,在断开的过程中,是无法收到ZooKeeper在ZNode上发送的节点数据变更通知的。
所以,如果使用ZooKeeper的Watch,必须要寻找保持CONNECTED的Watch,才能保证不会丢失该Watch监控的ZNode上的数据变更通知。2、无效ZooKeeper集群节点列表
与ZooKeeper集群交互时,一般情况下客户端会持有一个ZooKeeper集群节点的列表,或者列表的子集,那么会存在如下两种情况:
一种情况是,如果客户端持有的列表或者列表子集,其中节点都处于Active状态,能够提供协调服务,那么客户端访问ZooKeeper集群没有任何问题。
另一种情况,客户端持有ZooKeeper集群节点列表或列表子集,如果列表中的某些节点因为故障退出了集群,如果客户端再次连接这一类失效的节点,就无法获取服务。
所以,我们在应用中使用ZooKeeper集群时,一定要明确这一点,或者跳过无效的节点,或者重新寻找有效的节点继续业务处理,或者检查ZooKeeper集群,使整个集群恢复正常。3、配置导致的性能问题
如果设置Java堆内存(Heap)不合理,会导致ZooKeeper内存不足,会在内存与文件系统之间进行数据交换,导致ZooKeeper的性能极大地下降,从而可能会影响应用程序。
为了避免Swapping问题的出现,主要考虑设置足够的Java堆内存,同时减少被操作系统和Cache使用的内存,尽量避免在内存与文件系统之间发生数据交换,或者可以将交换限制在一定的范围之内。4、事务日志存储设备性能
ZooKeeper会同步事务到存储设备,如果存储设备不是专用的,而是和其他I/O密集型应用共享同一磁盘,会导致ZooKeeper的效率。因为客户端请求ZNode数据变更而发生的事务,ZooKeeper会在响应之前将事务日志写入存储设备,如果存储设备是专用的,那么整个服务以至外部应用都会获得极大地性能提升。5、ZNode存储大量数据导致性能问题
ZooKeeper的设计初衷是,每个ZNode只存放少量的同步数据,如果存储了大量数据,导致ZooKeeper每次节点发生变更时需要将事务写入存储设备,同时还要在集群内部复制传播,这将导致不可避免的延迟和性能问题。
所以,如果需要与大量的数据相关,可以将大量数据存储在其他设备中,而只是在ZooKeeper中存储一个简单的映射,如指针、引用等等。
参考链接:
http://zookeeper.apache.org/
http://zookeeper.apache.org/doc/r3.3.4/zookeeperOver.html
http://wiki.apache.org/hadoop/ZooKeeper/PoweredBy
http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
http://zookeeper.apache.org/doc/r3.3.4/recipes.html
http://zookeeper.apache.org/doc/r3.3.4/zookeeperProgrammers.html
Zookeeper基本概念详解
大数据 空心菜 发表了文章 0 个评论 5081 次浏览 2016-03-02 01:31

根据如上思维导图,我们来展开对Zookeeper的基本的一些概念解释。
一、集群角色
Leader
Leader服务器是整个Zookeeper集群工作机制中的核心Follower
Follower服务器是Zookeeper集群状态的跟随者Observer
Observer服务器充当一个观察者的角色
Leader,Follower 设计模式;Observer 观察者设计模式
二、会话
会话是指客户端和ZooKeeper服务器的连接,ZooKeeper中的会话叫Session,客户端靠与服务器建立一个TCP的长连接;
来维持一个Session,客户端在启动的时候首先会与服务器建立一个TCP连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能向ZK服务器发送请求并获得响应。
三、数据节点
Zookeeper中的节点有两类:
- []集群中的一台机器称为一个节点[/][]数据模型中的数据单元Znode,分为持久节点和临时节点[/]
Zookeeper的数据模型是一棵树,树的节点就是Znode,Znode中可以保存信息。如下图所示:

ZK大致数据结构跟上图是一致的,如上图所示这个图就像一棵树,这个树有个根节点,然后其下有些子节点,然后每个子节点其下又可以有子节点,大多数的开发就是跟zk的这些数据节点打交道,来读写这些数据节点,来完成任务。
四、版本
ZK中的版本,是用来记录节点数据或者是节点的子节点列表或者是权限信息的修改次数,注意是这里是修改次数。如果一个节点的version是1,那就代表说这个节点从创建以来被修改了一次,那么这个版本怎么用呢,典型的我们可以利用版本来实现分布式的锁服务。我们知道在数据库中,一般有两种锁,一种是悲观锁一种是乐观锁。悲观锁
悲观锁又叫悲观并发锁,是数据库中一种非常严格的锁策略,具有强烈的排他性,能够避免不同事务对同一数据并发更新造成的数据不一致性,在上一个事务没有完成之前,下一个事务不能访问相同的资源,适合数据更新竞争非常激烈的场景;乐观锁
相比悲观锁,乐观锁使用的场景会更多,悲观锁认为事务访问相同数据的时候一定会出现相互的干扰,所以简单粗暴的使用排他访问的方式,而乐观锁认为不同事务访问相同资源是很少出现相互干扰的情况,因此在事务处理期间不需要进行并发控制,当然乐观锁也是锁,它还是会有并发的控制!对于数据库我们通常的做法是在每个表中增加一个version版本字段,事务修改数据之前先读出数据,当然版号也顺势读取出来,然后把这个读取出来的版本号加入到更新语句的条件中,比如,读取出来的版本号是1,我们修改数据的语句可以这样写,update 某某表 set 字段一=某某值 where id=1 and version=1,那如果更新失败了说明以后其他事务已经修改过数据了,那系统需要抛出异常给客户端,让客户端自行处理,客户端可以选择重试。
锁,ZK中版本有类式的作用。ZK的版本类型有三种:version cversion aversion

五、Watcher
Watcher我们可以理解为他是一个事件监听器
ZooKeeper允许用户在指定节点上注册一些Watcher,当数据节点发生变化的时候,ZooKeeper服务器会把这个变化的通知发送给感兴趣的客户端。

两个客户端都在zookeeper集群中注册了watcher(事件监听器),那么当zk中的节点数据发生变化的时候,zk会把这一变化的通知发送给客户端,当客户端收到这个变化通知的时候,它可以再回到zk中,去取得这个数据的详细信息。
六、ACL权限控制
ACL是Access Control Lists 的简写, ZooKeeper采用ACL策略来进行权限控制,有以下权限:
- []CREATE: 创建子节点的权限[/][]READ: 获取节点数据和子节点列表的权限[/][]WRITE: 更新节点数据的权限[/][]DELETE: 删除子节点的权限[/][]ADMIN: 设置节点ACL的权限[/]
上面的权限有点类似我们信息系统的权限管理,我们在开发系统的时候一般也会对数据做这些权限管理,一个zk集群可能会服务很多的业务,尤其是一些大公司,zk集群的节点中会保存重要的信息,那么这些信息通常只能对一部分的访问者开放,通过acl我们可以对某些节点的访问进行授权,从而来保证数据的安全。
Zookeeper新手指南
云原生 空心菜 发表了文章 0 个评论 2269 次浏览 2021-03-27 22:41
目标
今天,我们将开始迈向Apache ZooKeeper的新旅程。在这个ZooKeeper教程中,我们将看到Apache ZooKeeper的含义以及ZooKeeper的流行度。此外,我们将了解ZooKeeper 的功能,优点,应用和用例。此外,我们将讨论不同的术语,如ZooKeeper Client,ZooKeeper Cluster,ZooKeeper WebUI。除此之外,Apache ZooKeeper教程将为使用ZooKeeper的原因提供答案。此外,我们将看到使用ZooKeeper的公司。最后,我们将看到Apache ZooKeeper架构。
由于ZooKeeper本质上是分布式的,因此在进一步研究之前,了解分布式应用程序的一两件事非常重要。因此,首先,我们将看到ZooKeeper讨论,快速介绍分布式应用程序。
那么,让我们开始Apache ZooKeeper教程。
什么是分布式应用程序?
为了以快速有效的方式完成特定任务,分布式应用程序可以在给定时间(同时)在网络中的多个系统上运行。它们可以通过中间协调来实现。此外,我们可以说,通过使用所涉及的所有系统的计算能力,复杂且耗时的任务(需要数小时才能完成非分布式应用程序(在单个系统中运行))可以在几分钟内通过帮助完成分布式应用程序。
此外,通过将分布式应用程序配置为在更多系统上运行,可以进一步减少完成任务的时间。有一个集群,它基本上是一组运行分布式应用程序的系统。在集群中有机器在运行,那些在集群中运行的机器就是我们所说的节点。
通常,服务器和客户端应用程序是分布式应用程序的两个部分。定义两者:
服务器端应用
具有通用接口的分布式应用程序就是我们所说的服务器端应用程序。基本上,它确保客户端可以连接到群集中的任何服务器并获取相同的结果。
客户端应用
有助于与分布式应用程序交互的工具就是我们所说的客户端应用程序。
分布式应用的好处
a.可靠性
如果一个或几个系统发生故障,则不会使整个系统失效。
b.可伸缩性
通过添加更多的机器,只需对应用程序的配置进行少量更改,而无需停机,就可以根据需要提高性能。
c.透明度
这仅仅意味着它隐藏了系统的复杂性。而且,它显示自己是一个单独的实体/应用程序。
分布式应用程序的挑战
1.竞争条件
有时有两个或更多的机器试图执行一个特定的任务,即使当任务实际上只需要在任何给定的时间由一台机器来完成。
2.死锁
为了无限期地完成,两个或多个操作等待彼此。
3.不一致
这意味着数据部分失效。
什么是ZooKeeper?
我们称之为ZooKeeper的分布式协调服务也有助于管理大量主机。由于特别是在分布式环境中管理和协调服务是一个复杂的过程,因此ZooKeeper由于其简单的架构和API而解决了这个问题。ZooKeeper是最好的,不用担心应用程序的分布式特性,它允许开发人员专注于核心应用程序逻辑。
最初,为了以简单而强大的方式访问应用程序,ZooKeeper框架最初是在“Yahoo!”上构建的。但在此之后,为了组织Hadoop,HBase和其他分布式框架所使用的服务,Apache ZooKeeper成为了标准。例如,要跟踪分布式数据的状态,Apache HBase使用ZooKeeper。
此外,它们还可以轻松支持大型Hadoop集群。为了检索信息,每个客户机与其中一个服务器通信。但是,在过去,大多数工作都需要在实现分布式应用程序时修复错误。虽然我们可以说,实现中的这些各种困难是创建ZooKeeper背后的主要原因。因为它简明扼要地关注整个集群的同步和协调。
Zookeeper受众
那些希望通过使用ZooKeeper框架在大数据分析领域开展事业的专业人士可以参考这个Zookeeper序列文章。因为这个Apache ZooKeeper序列教程文章将详细介绍如何使用ZooKeeper创建分布式集群。
Zookeeper运行先决条件
虽然,在继续使用这个ZooKeeper教程之前,必须对Java有一个很好的理解,因为它的服务器运行在JVM,分布式进程以及Linux环境中。
Zookeeper的功能
有一些最好的Apache ZooKeeper功能,这使它从人群中脱颖而出:
简单
在共享的分层命名空间的帮助下,它进行协调。
可靠性
即使多个节点发生故障,系统也会继续运行。
速度
在“读取”更常见的情况下,它以10:1的比例运行。
可扩展性
通过部署更多集群节点,可以提高性能。
ZooKeeper教程设计
下面,我们将讨论Apache ZooKeeper的一些设计目标:
a. Zookeeper是简单的
在使用ZooKeeper时,所有分布式进程都可以相互协调。这种协调可以通过共享的分层命名空间实现。但是,它的组织方式与标准文件系统相同。这里的命名空间由数据寄存器组成,我们称之为znodes,用ZooKeeper的说法。但是,这些与文件和目录相同。此外,ZooKeeper数据保留在内存中,因为它实现了高吞吐量和低延迟数量。
b. Zookeeper支持复制
Apache ZooKeeper本身旨在通过一组称为集合的主机进行复制,就像它协调的分布式进程一样。
c. 如何让Zookeeper顺序一致性更有效?
为了实现更高级别的抽象(同步原语,后续操作),需要使用顺序一致性。
d. Zookeepr很快
特别是,在“读取占优势”的工作负载中,ZooKeeper的工作速度非常快。
Apache ZooKeeper架构
在这个Apache ZooKeeper教程的下面,给出了ZooKeeper架构的几个组成部分,例如:
- 服务器端应用程序:通过通用接口,这些应用程序便于与客户端应用程序进
- 客户端应用程序:有几种工具可以帮助与分布式应用程序进行交互。
- ZooKeeper节点:这些是集群运行的系统。
- Znode:通过集群中的任何节点,我们都可以更新或修改Znode。
我们可以通过一组机器轻松地通过Hadoop ZooKeeper的架构复制ZooKeeper服务。但是,每个都维护一个内存数据树的映像以及事务日志。此外,客户端应用程序联系到单个服务器并且还建立TCP链接。因此,通过他们,他们发送请求,接收回复,观看事件等等。
为什么选择Apache ZooKeeper?
基本上,为了在(节点组)之间进行协调并使用强大的同步技术维护共享数据,集群使用 Apache ZooKeeper。但是,对于编写分布式应用程序,ZooKeeper本身就是一个提供多种服务的分布式应用程序。所以,我们在这里列出了ZooKeeper提供的常用服务,例如:
a. 命名服务
在群集中,按名称标识节点。
b. 配置管理
对于加入节点,系统的最新和最新配置信息。
c. 集群管理
实时地,在群集和节点状态中加入/下架节点。
d. Leader选举
出于协调目的,选择一个节点作为领导者。
e. 锁定和同步服务
在修改它时,锁定数据。在连接其他分布式应用程序(如Apache HBase)时,此机制可帮助我们自动进行故障恢复。
f. 高度可靠的数据注册表
即使一个或几个节点关闭 了数据的可用性。
由于分布式应用程序也提供了很少的复杂和难以破解的挑战,因此,为了克服所有挑战,ZooKeeper框架提供了一个完整的机制。此外,使用故障安全同步方法,我们可以处理竞争条件和死锁。此外,ZooKeeper解决了数据与原子性的不一致性。
使用Docker容器化ZooKeeper
通过使用Docker容器化ZooKeeper。因此,作为一个很大的好处,可以按需添加和删除节点。但是,只能通过在Docker镜像中添加ZooKeeper并在集群的每个主服务器上使用它来运行容器。
此外,它应该独立地创建一个集群,或者它应该能够在启动容器期间连接到现有集群并成为其一部分。因此,它允许使用Docker容器化动态重新配置整个Hadoop集群,这是使用Docker容器的好处。
什么是ZooKeeper客户端?
与所有分布式应用程序一样,Zookeeper分布式应用程序也包含服务器和客户端。它有一个集中的界面,客户端可以通过该界面连接到服务。但是,这些客户端可以是命令行或GUI客户端。基本上,可用于与ZooKeeper分布式应用程序交互的工具就是我们所说的ZooKeeper客户端应用程序。
什么是Zookeeper群集?
因为我们需要在集群模式下拥有ZooKeeper基础架构,以便在我们大规模运行Apache ZooKeeper时使系统处于最佳值。我们还将ZooKeeper集群称为集合体。但是,如果ZooKeeper集群必须成功运行,请确保大多数集群节点始终需要启动并运行。
ZooKeeper WebUI
基本上,要使用ZooKeeper资源管理,ZooKeeper WebUI或Web用户界面是一种更简单的方法。因此,WebUI允许使用Web用户界面使用ZooKeeper,而不是使用命令行与ZooKeeper应用程序进行交互。因此,我们可以说它使工作变得更加容易和有效。
Apache ZooKeeper应用程序
简而言之,为了大规模创建高度可用的分布式系统,它已成为最受欢迎的选择之一。因此,Apache基金会最成功的项目之一是ZooKeeper项目。
点击链接了解有关ZooKeeper Applications的更多信息
Apache ZooKeeper通过为实现不同的大数据工具提供坚实的基础,使公司能够在大数据世界中顺利运行。因此,它是大规模实施的最优选应用之一,因为它能够一次提供多种益处。
使用ZooKeeper的公司
现在,在这个Apache ZooKeeper教程中,我们提供了一个使用ZooKeeper的公司列表:
- Yahoo
- 易趣
- eBay
- Netflix
- Netflix
- Zynga
- Nutanix
- 百度
- 腾讯
- 阿里
- 携程
- 京东
- 小米
Apache ZooKeeper的好处
有各种ZooKeeper的好处,例如:
a. 同步
它允许互斥以及服务器进程之间的协作。因此,这有助于Apache HBase,用于配置管理
b. 有序消息
通过用表示其顺序的数字标记每个更新,它会跟踪。
c. 序列化
它确保我们的应用程序一致运行。要协调队列以执行正在运行的线程,可以在MapReduce中使用此方法。
d. 可靠性
应用更新后,它将从该时间开始持续,直到客户端覆盖更新。
e. 原子性
没有事务是部分的,数据传输成功或完全失败。
f. 顺序一致性
按照发送它们的顺序,它应用来自客户端的更新。
g. 单系统镜像
无论它连接到哪个服务器,客户端都会看到相同的服务视图。
h. 及时性
在一定的时间范围内,客户端对系统的视图是最新的。
ZooKeeper用例
Apache ZooKeeper教程中ZooKeeper的一些最突出的用例是:
- 管理配置
- 命名服务
- 选择Leader
- 对消息进行排队
- 管理通知系统
- 同步
通过使用ZooKeeper CLI,我们还可以与ZooKeeper集合进行通信。基本上,这为我们提供了使用各种选项的功能。此外,为了调试,还依赖于命令行界面。
教程英文原文: https://henduan.com/igCAR
Zookeepr参数详解
大数据 Rock 发表了文章 0 个评论 3992 次浏览 2017-05-24 21:47
1.tickTime:Client-Server通信心跳时间
tickTime=20002.initLimit:Leader-Follower初始通信时限
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
initLimit=53.syncLimit:Leader-Follower同步通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
syncLimit=24.dataDir:数据文件目录
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
dataDir=/data/zookeeper/data5.clientPort:客户端连接端口
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
clientPort=21816.服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
这个配置项的书写格式比较特殊,规则如下:
server.N=YYY:A:B
server.1=zk1:2888:38887.ZK为什么设置为奇数个?
server.2=zk2:2888:3888
server.3=zk3:2888:3888
zookeeper有这样一个特性:集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。也就是说如果有2个zookeeper,那么只要有1个死了zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1;同理你多列举几个:2 -> 0; 3 -> 1; 4 - >1; 5 -> 2; 6 -> 2会发现一个规律,2n和2n-1的容忍度是一样的,都是n-1,所以为了更加高效,何必增加那一个不必要的zookeeper呢。增加处理能力,哈哈。。。
Zookeeper日志设置和清理
大数据 push 发表了文章 0 个评论 10230 次浏览 2017-04-11 15:38
一、日志设置
第一步:修改log4j.properties, 这个应该是大家都会去改改, 加粗处是我修改的, 但是只改这个文件后来发现还是不生效
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO,ROLLINGFILE
zookeeper.console.threshold=INFO
zookeeper.log.dir=.
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=.
zookeeper.tracelog.file=zookeeper_trace.log
#
# ZooKeeper Logging Configuration
#
# Format is "(, )+
# DEFAULT: console appender only
log4j.rootLogger=${zookeeper.root.logger}
# Example with rolling log file
#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE
# Example with rolling log file and tracing
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
#
# Log INFO level and above messages to the console
#
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender //按天日记轮转
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
# Max log file size of 10MB
#log4j.appender.ROLLINGFILE.MaxFileSize=10MB
# uncomment the next line to limit number of backup files
#log4j.appender.ROLLINGFILE.MaxBackupIndex=10
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add TRACEFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
log4j.appender.TRACEFILE.Threshold=TRACE
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
### Notice we are including log4j's NDC here (%x)
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
第二步:还需要改${zkhome}/bin/zkEnv.sh, 注意加粗处, 这时日志已经可以成功按照你设置的目录进行输出了
#!/usr/bin/env bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script should be sourced into other zookeeper
# scripts to setup the env variables
# We use ZOOCFGDIR if defined,
# otherwise we use /etc/zookeeper
# or the conf directory that is
# a sibling of this script's directory
ZOOBINDIR="${ZOOBINDIR:-/usr/bin}"
ZOOKEEPER_PREFIX="${ZOOBINDIR}/.."
if [ "x$ZOOCFGDIR" = "x" ]
then
if [ -e "${ZOOKEEPER_PREFIX}/conf" ]; then
ZOOCFGDIR="$ZOOBINDIR/../conf"
else
ZOOCFGDIR="$ZOOBINDIR/../etc/zookeeper"
fi
fi
if [ -f "${ZOOCFGDIR}/zookeeper-env.sh" ]; then
. "${ZOOCFGDIR}/zookeeper-env.sh"
fi
if [ "x$ZOOCFG" = "x" ]
then
ZOOCFG="zoo.cfg"
fi
ZOOCFG="$ZOOCFGDIR/$ZOOCFG"
if [ -f "$ZOOCFGDIR/java.env" ]
then
. "$ZOOCFGDIR/java.env"
fi
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/data/zookeeper/outlogs/"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
if [ "$JAVA_HOME" != "" ]; then
JAVA="$JAVA_HOME/bin/java"
else
JAVA=java
fi
#add the zoocfg dir to classpath
CLASSPATH="$ZOOCFGDIR:$CLASSPATH"
for i in "$ZOOBINDIR"/../src/java/lib/*.jar
do
CLASSPATH="$i:$CLASSPATH"
done
#make it work in the binary package
#(use array for LIBPATH to account for spaces within wildcard expansion)
if [ -e "${ZOOKEEPER_PREFIX}"/share/zookeeper/zookeeper-*.jar ]; then
LIBPATH=("${ZOOKEEPER_PREFIX}"/share/zookeeper/*.jar)
else
#release tarball format
for i in "$ZOOBINDIR"/../zookeeper-*.jar
do
CLASSPATH="$i:$CLASSPATH"
done
LIBPATH=("${ZOOBINDIR}"/../lib/*.jar)
fi
for i in "${LIBPATH[@]}"
do
CLASSPATH="$i:$CLASSPATH"
done
#make it work for developers
for d in "$ZOOBINDIR"/../build/lib/*.jar
do
CLASSPATH="$d:$CLASSPATH"
done
#make it work for developers
CLASSPATH="$ZOOBINDIR/../build/classes:$CLASSPATH"
case "`uname`" in
CYGWIN*) cygwin=true ;;
*) cygwin=false ;;
esac
if $cygwin
then
CLASSPATH=`cygpath -wp "$CLASSPATH"`
fi
#echo "CLASSPATH=$CLASSPATH"
第三步:设置zookeeper.out
zookeeper.out由nohup的输出,也就是zookeeper的stdout和stdeer输出,修改bin/zkServer.sh 文件:
_ZOO_DAEMON_OUT="$ZOO_LOG_DIR/zookeeper.out"
case $1 in
start)
echo -n "Starting zookeeper ... "
if [ -f $ZOOPIDFILE ]; then
if kill -0 `cat $ZOOPIDFILE` > /dev/null 2>&1; then
echo $command already running as process `cat $ZOOPIDFILE`.
exit 0
fi
fi
nohup $JAVA "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
第四步:快照事物日志
在使用zookeeper过程中,我们知道,会有dataDir和dataLogDir两个目录,分别用于snapshot和事务日志的输出(默认情况下只有dataDir目录,snapshot和事务日志都保存在这个目录中),通过zoo.cfg配置文件可配置:
#snapshot file dir
dataDir=/data/zookeeper/data
#tran log dir
dataLogDir=/data/zookeeper/log
二、日志清理
正常运行过程中,ZK会不断地把快照数据和事务日志输出到这两个目录,并且如果没有人为操作的话,ZK自己是不会清理这些文件的,需要管理员来清理,这里介绍4种清理日志的方法。在这4种方法中,推荐使用第一种方法,对于运维人员来说,将日志清理工作独立出来,便于统一管理也更可控。毕竟zk自带的一些工具并不怎么给力,这里是社区反映的两个问题:
https://issues.apache.org/jira/browse/ZOOKEEPER-957
http://zookeeper-user.578899.n2.nabble.com/PurgeTxnLog-td6304244.html
第一种,也是运维人员最常用的,写一个删除日志脚本,每天定时执行即可:
#!/bin/bash以上这个脚本定义了删除对应三个目录中的文件,保留最新的60个文件,可以将他写到crontab中,设置为每天凌晨2点执行一次就可以了。
#snapshot file dir
dataDir=/data/zookeeper/data/version-2
#tran log dir
dataLogDir=/data/zookeeper/log/version-2
#zk log dir
logDir=/data/zookeeper/outlog/
#Leave 60 files
count=60
count=$[$count+1]
ls -t $dataLogDir/log.* | tail -n +$count | xargs rm -f
ls -t $dataDir/snapshot.* | tail -n +$count | xargs rm -f
ls -t $logDir/zookeeper.log.* | tail -n +$count | xargs rm -f
第二种,使用ZK的工具类PurgeTxnLog,它的实现了一种简单的历史文件清理策略,可以在这里看一下他的使用方法:http://zookeeper.apache.org/doc/r3.4.3/api/index.html ,可以指定要清理的目录和需要保留的文件数目,简单使用如下:
java -cp zookeeper.jar:lib/slf4j-api-1.6.1.jar:lib/slf4j-log4j12-1.6.1.jar:lib/log4j-1.2.15.jar:conf org.apache.zookeeper.server.PurgeTxnLog第三种,对于上面这个Java类的执行,ZK自己已经写好了脚本,在bin/zkCleanup.sh中,所以直接使用这个脚本也是可以执行清理工作的。-n
第四种,从3.4.0开始,zookeeper提供了自动清理snapshot和事务日志的功能,通过配置 autopurge.snapRetainCount 和 autopurge.purgeInterval 这两个参数能够实现定时清理了。这两个参数都是在zoo.cfg中配置的:
autopurge.purgeInterval: 24*2autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
autopurge.snapRetainCount: 2
autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。
参考:http://nileader.blog.51cto.com/1381108/932156
Python可用的分布式协调系统(ZooKeeper,Consul, etcd)介绍
大数据 push 发表了文章 0 个评论 8404 次浏览 2016-06-19 22:52
在对分布式的应用做协调的时候,主要会碰到以下的应用场景:
- []业务发现(service discovery)[/]
- []名字服务 (name service)[/]
- []配置管理 (configuration management)[/]
- []故障发现和故障转移 (failure detection and failover)[/]
- []领导选举(leader election)[/]
- []分布式的锁 (distributed exclusive lock)[/]
- []消息和通知服务 (message queue and notification)[/]
Zookeeper 是使用最广泛,也是最有名的解决分布式服务的协调问题的开源软件了,它最早和Hadoop一起开发,后来成为了Apache的顶级项目,很多开源的项目都在使用ZooKeeper,例如大名鼎鼎的Kafka。 Zookeeper本身是一个分布式的应用,通过对共享的数据的管理来实现对分布式应用的协调。ZooKeeper使用一个树形目录作为数据模型,这个目录和文件目录类似,目录上的每一个节点被称作ZNodes。ZooKeeper
from kazoo.client import KazooClientimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Ensure a path, create if necessaryzk.ensure_path("/test/zk1")# Create a node with datazk.create("/test/zk1/node", b"a test value")# Determine if a node existsif zk.exists("/test/zk1"): print "the node exist"# Print the version of a node and its datadata, stat = zk.get("/test/zk1")print("Version: %s, data: %s" % (stat.version, data.decode("utf-8")))# List the childrenchildren = zk.get_children("/test/zk1")print("There are %s children with names %s" % (len(children), children))zk.stop()通过对ZNode的操作,我们可以完成一些分布式服务协调的基本需求,包括名字服务,配置服务,分组等等。 故障检测(Failure Detection)在分布式系统中,一个最基本的需求就是当某一个服务出问题的时候,能够通知其它的节点或者某个管理节点。ZooKeeper提供ephemeral Node的概念,当创建该Node的服务退出或者异常中止的时候,该Node会被删除,所以我们就可以利用这种行为来监控服务运行状态。以下是worker的代码from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Ensure a path, create if necessaryzk.ensure_path("/test/failure_detection")# Create a node with datazk.create("/test/failure_detection/worker", value=b"a test value", ephemeral=True)while True: print "I am alive!" time.sleep(3)zk.stop()以下的monitor 代码,监控worker服务是否运行。from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()# Determine if a node existswhile True: if zk.exists("/test/failure_detection/worker"): print "the worker is alive!" else: print "the worker is dead!" break time.sleep(3)zk.stop()领导选举Kazoo直接提供了领导选举的API,使用起来非常方便。from kazoo.client import KazooClientimport timeimport uuidimport logginglogging.basicConfig()my_id = uuid.uuid4()def leader_func(): print "I am the leader {}".format(str(my_id)) while True: print "{} is working! ".format(str(my_id)) time.sleep(3)zk = KazooClient(hosts='127.0.0.1:2181')zk.start()election = zk.Election("/electionpath")# blocks until the election is won, then calls# leader_func()election.run(leader_func)zk.stop()你可以同时运行多个worker,其中一个会获得Leader,当你杀死当前的leader后,会有一个新的leader被选出。 分布式锁锁的概念大家都熟悉,当我们希望某一件事在同一时间只有一个服务在做,或者某一个资源在同一时间只有一个服务能访问,这个时候,我们就需要用到锁。from kazoo.client import KazooClientimport timeimport uuidimport logginglogging.basicConfig()my_id = uuid.uuid4()def work(): print "{} is working! ".format(str(my_id))zk = KazooClient(hosts='127.0.0.1:2181')zk.start()lock = zk.Lock("/lockpath", str(my_id))print "I am {}".format(str(my_id))while True: with lock: work() time.sleep(3) zk.stop()当你运行多个worker的时候,不同的worker会试图获取同一个锁,然而只有一个worker会工作,其它的worker必须等待获得锁后才能执行。 监视ZooKeeper提供了监视(Watch)的功能,当节点的数据被修改的时候,监控的function会被调用。我们可以利用这一点进行配置文件的同步,发消息,或其他需要通知的功能。from kazoo.client import KazooClientimport timeimport logginglogging.basicConfig()zk = KazooClient(hosts='127.0.0.1:2181')zk.start()@zk.DataWatch('/path/to/watch')def my_func(data, stat): if data: print "Data is %s" % data print "Version is %s" % stat.version else : print "data is not available"while True: time.sleep(10)zk.stop()除了我们上面列举的内容外,Kazoo还提供了许多其他的功能,例如:计数,租约,队列等等,大家有兴趣可以参考它的文档。 Consul 是用Go开发的分布式服务协调管理的工具,它提供了服务发现,健康检查,Key/Value存储等功能,并且支持跨数据中心的功能。Consul提供ZooKeeper类似的功能,它的基于HTTP的API可以方便的和各种语言进行绑定。自然Python也在列。与Zookeeper有所差异的是Consul通过基于Client/Server架构的Agent部署来支持跨Data Center的功能。Consul
import consulc = consul.Consul()# set data for key fooc.kv.put('foo', 'bar')# poll a key for updatesindex = Nonewhile True: index, data = c.kv.get('foo', index=index) print data['Value'] c.kv.delete('foo')这里和ZooKeeper对Znode的操作几乎是一样的。 服务发现(Service Discovery)和健康检查(Health Check) Consul的另一个主要的功能是用于对分布式的服务做管理,用户可以注册一个服务,同时还提供对服务做健康检测的功能。首先,用户需要定义一个服务。{ "service": { "name": "redis", "tags": ["master"], "address": "127.0.0.1", "port": 8000, "checks": [ { "script": "/usr/local/bin/check_redis.py", "interval": "10s" } ] }}其中,服务的名字是必须的,其它的字段可以自选,包括了服务的地址,端口,相应的健康检查的脚本。当用户注册了一个服务后,就可以通过Consul来查询该服务,获得该服务的状态。 Consul支持三种Check的模式:- []调用一个外部脚本(Script),在该模式下,consul定时会调用一个外部脚本,通过脚本的返回内容获得对应服务的健康状态。[/][]调用HTTP,在该模式下,consul定时会调用一个HTTP请求,返回2XX,则为健康;429 (Too many request)是警告。其它均为不健康[/][]主动上报,在该模式下,服务需要主动调用一个consul提供的HTTP PUT请求,上报健康状态。[/]
- []Consul.Agent.Service[/][]Consul.Agent.Check[/]
import consulimport timec = consul.Consul()s = c.session.create(name="worker",behavior='delete',ttl=10)print "session id is {}".format(s)while True: c.session.renew(s) print "I am alive ..." time.sleep(3)Moniter代码用于监控worker相关联的session的状态,但发现worker session已经不存在了,就做出响应的处理。import consulimport timedef is_session_exist(name, sessions): for s in sessions: if s['Name'] == name: return True return Falsec = consul.Consul()while True: index, sessions = c.session.list() if is_session_exist('worker', sessions): print "worker is alive ..." else: print 'worker is dead!' break time.sleep(3)这里注意,因为是基于ttl(最小10秒)的检测,从业务中断到被检测到,至少有10秒的时延,对应需要实时响应的情景,并不适用。Zookeeper使用ephemeral Node的方式时延相对短一点,但也非实时。 领导选举和分布式的锁 无论是Consul本身还是Python客户端,都不直接提供Leader Election的功能,但是这篇文档介绍了如何利用Consul的KV存储来实现Leader Election,利用Consul的KV功能,可以很方便的实现领导选举和锁的功能。当对某一个Key做put操作的时候,可以创建一个session对象,设置一个acquire标志为该 session,这样就获得了一个锁,获得所得客户则是被选举的leader。代码如下:import consulimport timec = consul.Consul()def request_lead(namespace, session_id): lock = c.kv.put(leader_namespace,"leader check", acquire=session_id) return lockdef release_lead(session_id): c.session.destroy(session_id)def whois_lead(namespace): index,value = c.kv.get(namespace) session = value.get('Session') if session is None: print 'No one is leading, maybe in electing' else: index, value = c.session.info(session) print '{} is leading'.format(value['ID'])def work_non_block(): print "working"def work_block(): while True: print "working" time.sleep(3)leader_namespace = 'leader/test'[size=16] initialize leader key/value node[/size]leader_index, leader_node = c.kv.get(leader_namespace)if leader_node is None: c.kv.put(leader_namespace,"a leader test")while True: whois_lead(leader_namespace) session_id = c.session.create(ttl=10) if request_lead(leader_namespace,session_id): print "I am now the leader" work_block() release_lead(session_id) else: print "wait leader elected!" time.sleep(3)利用同样的机制,可以方便的实现锁,信号量等分布式的同步操作。 监视Consul的Agent提供了Watch的功能,然而Python客户端并没有相应的接口。 Etcd 是另一个用GO开发的分布式协调应用,它提供一个分布式的Key/Value存储来进行共享的配置管理和服务发现。 同样的etcd使用基于HTTP的API,可以灵活的进行不同语言的绑定,我们用的是这个客户端https://github.com/jplana/python-etcd 基本操作Etcd
import etcdclient = etcd.Client() client.write('/nodes/n1', 1)print client.read('/nodes/n1').valueetcd对节点的操作和ZooKeeper类似,不过etcd不支持ZooKeeper的ephemeral Node的概念,要监控服务的状态似乎比较麻烦。 分布式锁etcd支持分布式锁,以下是一个例子。import syssys.path.append("../../")import etcdimport uuidimport timemy_id = uuid.uuid4()def work(): print "I get the lock {}".format(str(my_id))client = etcd.Client() lock = etcd.Lock(client, '/customerlock', ttl=60)with lock as my_lock: work() lock.is_locked() # True lock.renew(60)lock.is_locked() # False老版本的etcd支持leader election,但是在最新版该功能被deprecated了,参见https://coreos.com/etcd/docs/0.4.7/etcd-modules/ 其它 我们针对分布式协调的功能讨论了三个不同的开源应用,其实还有许多其它的选择,我这里就不一一介绍,大家有兴趣可以访问以下的链接:- []eureka https://github.com/Netflix/eureka [/]
- []curator http://curator.apache.org/[/]
- []doozerd https://github.com/ha/doozerd[/]
- []openreplica http://openreplica.org/[/]
- []serf http://www.serfdom.io/[/]
- []noah https://github.com/lusis/Noah[/]
- []copy cat https://github.com/kuujo/copycat[/]
基于日志的分布式协调的框架,使用Java开发
总结
ZooKeeper无疑是分布式协调应用的最佳选择,功能全,社区活跃,用户群体很大,对所有典型的用例都有很好的封装,支持不同语言的绑定。缺点是,整个应用比较重,依赖于Java,不支持跨数据中心。
Consul作为使用Go语言开发的分布式协调,对业务发现的管理提供很好的支持,他的HTTP API也能很好的和不同的语言绑定,并支持跨数据中心的应用。缺点是相对较新,适合喜欢尝试新事物的用户。
etcd是一个更轻量级的分布式协调的应用,提供了基本的功能,更适合一些轻量级的应用来使用。
参考
如果大家对于分布式系统的协调想要进行更多的了解,可以阅读一下的链接:
http://stackoverflow.com/questions/6047917/zookeeper-alternatives-cluster-coordination-service
http://txt.fliglio.com/2014/05/encapsulated-services-with-consul-and-confd/
http://txt.fliglio.com/2013/12/service-discovery-with-docker-docker-links-and-beyond/
http://www.serfdom.io/intro/vs-zookeeper.html
http://devo.ps/blog/zookeeper-vs-doozer-vs-etcd/
https://www.digitalocean.com/community/articles/how-to-set-up-a-serf-cluster-on-several-ubuntu-vps
http://www.slideshare.net/JyrkiPulliainen/taming-pythons-with-zoo-keeper-ep2013?qid=e1267f58-090d-4147-9909-ec673525e76b&v=qf1&b=&from_search=8
http://muratbuffalo.blogspot.com/2014/09/paper-summary-tango-distributed-data.html
https://developer.yahoo.com/blogs/hadoop/apache-zookeeper-making-417.html
http://www.knewton.com/tech/blog/2014/12/eureka-shouldnt-use-zookeeper-service-discovery
http://codahale.com/you-cant-sacrifice-partition-tolerance/
原文地址:http://my.oschina.net/taogang/blog/410864
基于Zookeeper的服务注册与发现案例分析
大数据 空心菜 发表了文章 0 个评论 4239 次浏览 2016-03-16 17:22
背景
大多数系统都是从一个单一系统开始起步的,随着公司业务的快速发展,这个单一系统变得越来越庞大,带来几个问题:
- []随着访问量的不断攀升,纯粹通过提升机器的性能来已经不能解决问题,系统无法进行有效的水平扩展[/][]维护这个单一系统,变得越来越复杂[/][]同时,随着业务场景的不同以及大研发的招兵买马带来了不同技术背景的工程师,在原有达达Python技术栈的基础上,引入了Java技术栈。[/]
如何来解决这些问题?业务服务化是个有效的手段来解决大规模系统的性能瓶颈和复杂性。通过系统拆分将原有的单一庞大系统拆分成小系统,它带来了如下好处:
- []原来系统的压力得到很好的分流,有效地解决了原先系统的瓶颈,同时带来了更好的扩展性[/][]独立的代码库,更少的业务逻辑,系统的维护性得到极大的增强[/]
同时,也带来了一系列问题:
- []随着系统服务的越来越多,如何来管理这些服务?[/][]如何分发请求到提供同一服务的多台主机上(负载均衡如何来做)[/][]如果提供服务的Endpoint发生变化,如何将这些信息通知服务的调用方?[/]
Linkedin的创始人里德霍夫曼曾经说过:最初的解决方案
成立一家初创公司就像把自己从悬崖上扔下来,在降落过程中去组装一架飞机。这对于初创公司达达也是一样的,业务在以火箭般的速度发展着。技术在业务发展中作用就是保障业务的稳定运行,快速地“组装一架飞机”。所以,在业务服务化的早期,我们采用了Nginx+本地hosts文件的方式进行内部服务的注册与发现,架构图如下:
- []最明显的问题是Nginx存在单点故障(SPOF),同时随着访问量的提升,会成为一个性能瓶颈[/][]随着内部服务的越来越多,不同的服务消费方需要配置不同的hosts,很容易在增加新的主机时忘记配置hosts导致服务不能调用问题,增加了运维负担[/][]服务的配置信息分散在各个主机hosts中,难以保持一致性,不便于服务的管理[/][]服务主机的发布和下线需要手工的修改Nginx upstream配置,修改的配置需要上线,不利于服务的快速部署[/]
在谈如何来解决之前,现梳理一下服务注册与发现的目标:如何解决
- []服务的注册信息应该统一保存,方便于服务的管理[/][]自动通过服务的名称去发现服务,而不必了解这个服务提供的end-point到底是哪台主机[/][]支持服务的负载均衡及fail-over[/][]增加或移除某个服务的end-point时,对于服务的消费者来说是透明的[/][]支持Python和Java[/]
DNS作为服务注册发现的一种方案,它比较简单。只要在DNS服务上,配置一个DNS名称与IP对应关系即可。定位一个服务只需要连接到DNS服务器上,随机返回一个IP地址即可。由于存在DNS缓存,所以DNS服务器本身不会成为一个瓶颈。
这种基于Pull的方式不能及时获取服务的状态的更新(例如:服务的IP更新等)。如果服务的提供者出现故障,由于DNS缓存的存在,服务的调用方会仍然将请求转发给出现故障的服务提供方;反之亦然。备选方案二:DubboDubbo是阿里巴巴推出的分布式服务框架,致力于解决服务的注册与发现,编排,治理。它的优点如下:[list=1][]功能全面,易于扩展[/][]支持各种序列化协议(JSON,Hession,java序列化等)[/][]支持各种RPC协议(HTTP,Java RMI,Dubbo自身的RPC协议等)[/][]支持多种负载均衡算法[/][]其他高级特性:服务编排,服务治理,服务监控等[/]缺点如下:[list=1][]只支持Java,对于Python没有相应的支持[/][]虽然已经开源,但是没有成熟的社区来运营和维护,未来升级可能是个麻烦[/][]重量级的解决方案带来新的复杂性[/]备选方案三:ZookeeperZookeeper是什么?按照Apache官网的描述是:
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.参照官网的定义,它能够做:[list=1][]作为配置信息的存储的中心服务器[/][]命名服务[/][]分布式的协调[/][]Mater选举等[/]在定义中特别提到了命名服务。在调研之后,Zookeeper作为服务注册与发现的解决方案;它有如下优点:[list=1][]它提供的简单API[/][]已有互联网公司(例如:Pinterest,Airbnb)使用它来进行服务注册与发现[/][]支持多语言的客户端[/][]通过Watcher机制实现Push模型,服务注册信息的变更能够及时通知服务消费方[/]缺点是:[list=1][]引入新的Zookeeper组件,带来新的复杂性和运维问题[/][]需自己通过它提供的API来实现服务注册与发现逻辑(包含Python与Java版本)[/]针对对上述几个方案的优缺点权衡之后,决定采用了基于Zookeeper实现自己的服务注册与发现。
基于Zookeeper的服务注册与发现架构
- []隶属于哪个系统[/][]服务的IP,端口[/][]服务的请求URL[/][]服务的权重等等[/]
服务消费者只在自己初始化以及服务变更时会依赖服务注册中心,在此阶段的单点故障通过Zookeeper集群来进行保障。在整个服务调用过程中,服务消费者不依赖于任何第三方服务。
Zookeeper数据模型介绍在整个服务注册与发现的设计中,最重要是如何来存储服务的注册信息。在设计基于Zookeeper的服务注册结构之前,我们先来看一下Zookeeper的数据模型。Zookeeper的数据模型如下图所示:实现机制介绍
Zookeeper数据模型结构与Unix文件系统很类似,是一个树状层次结构。每个节点叫做Znode,节点可以拥有子节点,同时允许将少量数据存储在该节点下。客户端可以通过监听节点的数据变更和子节点变更来实时获取Znode的变更(Wather机制)。服务注册结构
- []/dada来标示公司名称dada,同时能方便与其它应用的目录区分开(例如:Kafka的brokers注册信息放置在/brokers下)[/][]/dada/services将所有服务提供者都放置该目录下[/][]/dada/services/category1目录定义具体的服务提供者的id:category1,同时该Znode节点中允许存放该服务提供者的一些元数据信息,例如:名称,服务提供者的Owner,上下文路径(Java Web项目),健康检查路径等。该信息可以根据实际需要进行自由扩展。[/][]/dada/services/category1/helloworld节点定义了服务提供者category1下的一个服务:helloworld。其中helloworld为该服务的ID,同时允许将该服务的元数据信息存储在该Znode下,例如图中标示的:服务名称,服务描述,服务路径,服务的调用的schema,服务的调用的HTTP METHOD等。该信息可以根据实际需要进行自由扩展。[/][]/dada/services/category1/helloworld/providers节点定义了服务提供者的父节点。在这里其实可以将服务提供者的IP和端口直接放置在helloworld节点下,在这里单独放一个节点,是为了将来可以将服务消费者的消息挂载在helloworld节点下,进行一些扩展,例如命名为:/dada/services/category1/helloworld/consumers。[/][]/dada/services/category__1/helloworld/providers/192.168.1.1:8080该节点定义了服务提供者的IP和端口,同时在节点中定义了该服务提供者的权重。[/]
由于目前服务注册通过我们的服务注册中心UI来进行注册,这部分逻辑比较简单,即通过UI界面来构造上述定义的服务注册结构。下面着重介绍一下我们的服务发现是如何工作的:实现机制
LoadBalanceStrategy定义了根据服务提供者的信息返回对应的服务Host和IP,即决定由那台主机+端口来提供服务。
RoundRobinStrategy和RandomStrategy分别实现了Round-Robin和随机的负载均衡算法
未来展望
目前达达基于Zookeeper的服务注册与发现的架构还处于初期,很多功能还未完善,例如:服务的路由功能,与部署平台的集成,服务的监控等等。
当然基于Zookeeper还能做其它许多事情,例如:实时动态配置系统。目前,我们已经基于Zookeeper实现了实时动态配置系统。
分享原文地址:https://tech.imdada.cn/2015/12/03/service-registry-and-discovery-with-zk/
作者:杨 骏 达达CTO
ZooKeeper架构设计及其应用
运维 chris 发表了文章 0 个评论 8962 次浏览 2016-03-11 23:45
ZooKeeper是一个开源的分布式服务框架,它是Apache Hadoop项目的一个子项目,主要用来解决分布式应用场景中存在的一些问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置管理等,它支持Standalone模式和分布式模式,在分布式模式下,能够为分布式应用提供高性能和可靠地协调服务,而且使用ZooKeeper可以大大简化分布式协调服务的实现,为开发分布式应用极大地降低了成本。
总体架构
ZooKeeper分布式协调服务框架的总体架构,如图所示:
ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower。当客户端Client连接到ZooKeeper集群,并且执行写请求时,这些请求会被发送到Leader节点上,然后Leader节点上数据变更会同步到集群中其他的Follower节点。
Leader节点在接收到数据变更请求后,首先将变更写入本地磁盘,以作恢复之用。当所有的写请求持久化到磁盘以后,才会将变更应用到内存中。
ZooKeeper使用了一种自定义的原子消息协议,在消息层的这种原子特性,保证了整个协调系统中的节点数据或状态的一致性。Follower基于这种消息协议能够保证本地的ZooKeeper数据与Leader节点同步,然后基于本地的存储来独立地对外提供服务。
当一个Leader节点发生故障失效时,失败故障是快速响应的,消息层负责重新选择一个Leader,继续作为协调服务集群的中心,处理客户端写请求,并将ZooKeeper协调系统的数据变更同步(广播)到其他的Follower节点。
设计要点
ZooKeeper是基于如下4个目标来进行权衡和设计的,我们从设计及其特性的角度来详细说明:
- []简单[/]
在ZooKeeper中每个命名空间(Namespace)被称为ZNode,你可以这样理解,每个ZNode包含一个路径和与之相关的元数据,以及继承自该节点的孩子列表。与传统文件系统不同的是,ZooKeeper中的数据保存在内存中,实现了分布式同步服务的高吞吐和低延迟。[list=1][]在上图示例的ZooKeeper的数据模型中,有如下要点:[/][list=1][]每个节点(ZNode)中存储的是同步相关的数据(这是ZooKeeper设计的初衷,数据量很小,大概B到KB量级),例如状态信息、配置内容、位置信息等。[/][]一个ZNode维护了一个状态结构,该结构包括:版本号、ACL变更、时间戳。每次ZNode数据发生变化,版本号都会递增,这样客户端的读请求可以基于版本号来检索状态相关数据。[/][]每个ZNode都有一个ACL,用来限制是否可以访问该ZNode。[/][]在一个命名空间中,对ZNode上存储的数据执行读和写请求操作都是原子的。[/][]客户端可以在一个ZNode上设置一个监视器(Watch),如果该ZNode数据发生变更,ZooKeeper会通知客户端,从而触发监视器中实现的逻辑的执行。[/][]每个客户端与ZooKeeper连接,便建立了一次会话(Session),会话过程中,可能发生CONNECTING、CONNECTED和CLOSED三种状态。[/][]ZooKeeper支持临时节点(Ephemeral Nodes)的概念,它是与ZooKeeper中的会话(Session)相关的,如果连接断开,则该节点被删除。[/]
- []冗余[/]
ZooKeeper被设计为复制集群架构,每个节点的数据都可以在集群中复制传播,使集群中的每个节点数据同步一致,从而达到服务的可靠性和可用性。前面说到,ZooKeeper将数据放在内存中来提高性能,为了避免发生单点故障(SPOF),支持数据的复制来达到冗余存储,这是必不可少的。
- []有序[/]
ZooKeeper使用时间戳来记录导致状态变更的事务性操作,也就是说,一组事务通过时间戳来保证有序性。基于这一特性。ZooKeeper可以实现更加高级的抽象操作,如同步等。
- []快速[/]
ZooKeeper包括读写两种操作,基于ZooKeeper的分布式应用,如果是读多写少的应用场景(读写比例大约是10:1),那么读性能更能够体现出高效。
数据模型
ZooKeeper有一个分层的命名空间,结构类似文件系统的目录结构,非常简单而直观。其中,ZNode是最重要的概念,前面我们已经描述过。另外,有ZNode有关的还包括Watches、ACL、临时节点、序列节点(Sequence Node)。
- []ZNode结构[/]
- []Watches(监视)[/]
ZooKeeper中的Watch是只能触发一次。也就是说,如果客户端在指定的ZNode设置了Watch,如果该ZNode数据发生变更,ZooKeeper会发送一个变更通知给客户端,同时触发设置的Watch事件。如果ZNode数据又发生了变更,客户端在收到第一次通知后没有重新设置该ZNode的Watch,则ZooKeeper就不会发送一个变更通知给客户端。
ZooKeeper异步通知设置Watch的客户端。但是ZooKeeper能够保证在ZNode的变更生效之后才会异步地通知客户端,然后客户端才能够看到ZNode的数据变更。由于网络延迟,多个客户端可能会在不同的时间看到ZNode数据的变更,但是看到变更的顺序是能够保证有序一致的。
ZNode可以设置两类Watch,一个是Data Watches(该ZNode的数据变更导致触发Watch事件),另一个是Child Watches(该ZNode的孩子节点发生变更导致触发Watch事件)。调用getData()和exists() 方法可以设置Data Watches,调用getChildren()方法可以设置Child Watches。调用setData()方法触发在该ZNode的注册的Data Watches。调用create()方法创建一个ZNode,将触发该ZNode的Data Watches;调用create()方法创建ZNode的孩子节点,则触发ZNode的Child Watches。调用delete()方法删除ZNode,则同时触发Data Watches和Child Watches,如果该被删除的ZNode还有父节点,则父节点触发一个Child Watches。
另外,如果客户端与ZooKeeper Server断开连接,客户端就无法触发Watches,除非再次与ZooKeeper Server建立连接。
- []Sequence Nodes(序列节点)[/]
qn-0000000001, qn-0000000002, qn-0000000003, qn-0000000004, qn-0000000005, qn-0000000006, qn-0000000007
- []ACLs(访问控制列表)[/]
- []ZooKeeper Session[/]
当客户端连接到ZooKeeper集群时,建立了会话。会话过程中的状态变迁,如图所示:
建立连接过程中,会话状态为CONNECTING;当连接建立成功后,会话状态变为CONNECTED。会话过程中,如果正常的话,会话的状态只能是CONNECTING和CONNECTED二者之一。如果在会话过程中连接断开,则变为CLOSED状态。
应用陷阱
并非任何分布式应用都适合使用ZooKeeper来构建协调服务,我们根据ZooKeeper提供的文档,给出哪些情况下使用会出现问题,又是如何应对这种问题的。总结如下:
1、丢失ZNode上的变更通知
客户端连接到ZooKeeper Server以后,会维护一个TCP连接。在CONNECTED状态下,客户端设置了某个ZNode的Watch监听器,可以收到来自该节点变更的通知(后续会触发一定的逻辑执行流程)。但是,如果由于网络异常,客户端断开了与ZooKeeper Server的连接,在断开的过程中,是无法收到ZooKeeper在ZNode上发送的节点数据变更通知的。
所以,如果使用ZooKeeper的Watch,必须要寻找保持CONNECTED的Watch,才能保证不会丢失该Watch监控的ZNode上的数据变更通知。2、无效ZooKeeper集群节点列表
与ZooKeeper集群交互时,一般情况下客户端会持有一个ZooKeeper集群节点的列表,或者列表的子集,那么会存在如下两种情况:
一种情况是,如果客户端持有的列表或者列表子集,其中节点都处于Active状态,能够提供协调服务,那么客户端访问ZooKeeper集群没有任何问题。
另一种情况,客户端持有ZooKeeper集群节点列表或列表子集,如果列表中的某些节点因为故障退出了集群,如果客户端再次连接这一类失效的节点,就无法获取服务。
所以,我们在应用中使用ZooKeeper集群时,一定要明确这一点,或者跳过无效的节点,或者重新寻找有效的节点继续业务处理,或者检查ZooKeeper集群,使整个集群恢复正常。3、配置导致的性能问题
如果设置Java堆内存(Heap)不合理,会导致ZooKeeper内存不足,会在内存与文件系统之间进行数据交换,导致ZooKeeper的性能极大地下降,从而可能会影响应用程序。
为了避免Swapping问题的出现,主要考虑设置足够的Java堆内存,同时减少被操作系统和Cache使用的内存,尽量避免在内存与文件系统之间发生数据交换,或者可以将交换限制在一定的范围之内。4、事务日志存储设备性能
ZooKeeper会同步事务到存储设备,如果存储设备不是专用的,而是和其他I/O密集型应用共享同一磁盘,会导致ZooKeeper的效率。因为客户端请求ZNode数据变更而发生的事务,ZooKeeper会在响应之前将事务日志写入存储设备,如果存储设备是专用的,那么整个服务以至外部应用都会获得极大地性能提升。5、ZNode存储大量数据导致性能问题
ZooKeeper的设计初衷是,每个ZNode只存放少量的同步数据,如果存储了大量数据,导致ZooKeeper每次节点发生变更时需要将事务写入存储设备,同时还要在集群内部复制传播,这将导致不可避免的延迟和性能问题。
所以,如果需要与大量的数据相关,可以将大量数据存储在其他设备中,而只是在ZooKeeper中存储一个简单的映射,如指针、引用等等。
参考链接:
http://zookeeper.apache.org/
http://zookeeper.apache.org/doc/r3.3.4/zookeeperOver.html
http://wiki.apache.org/hadoop/ZooKeeper/PoweredBy
http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
http://zookeeper.apache.org/doc/r3.3.4/recipes.html
http://zookeeper.apache.org/doc/r3.3.4/zookeeperProgrammers.html
Zookeeper基本概念详解
大数据 空心菜 发表了文章 0 个评论 5081 次浏览 2016-03-02 01:31
根据如上思维导图,我们来展开对Zookeeper的基本的一些概念解释。
一、集群角色
Leader
Leader服务器是整个Zookeeper集群工作机制中的核心Follower
Follower服务器是Zookeeper集群状态的跟随者Observer
Observer服务器充当一个观察者的角色
Leader,Follower 设计模式;Observer 观察者设计模式
二、会话
会话是指客户端和ZooKeeper服务器的连接,ZooKeeper中的会话叫Session,客户端靠与服务器建立一个TCP的长连接;
来维持一个Session,客户端在启动的时候首先会与服务器建立一个TCP连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能向ZK服务器发送请求并获得响应。
三、数据节点
Zookeeper中的节点有两类:
- []集群中的一台机器称为一个节点[/][]数据模型中的数据单元Znode,分为持久节点和临时节点[/]
Zookeeper的数据模型是一棵树,树的节点就是Znode,Znode中可以保存信息。如下图所示:
ZK大致数据结构跟上图是一致的,如上图所示这个图就像一棵树,这个树有个根节点,然后其下有些子节点,然后每个子节点其下又可以有子节点,大多数的开发就是跟zk的这些数据节点打交道,来读写这些数据节点,来完成任务。
四、版本
ZK中的版本,是用来记录节点数据或者是节点的子节点列表或者是权限信息的修改次数,注意是这里是修改次数。如果一个节点的version是1,那就代表说这个节点从创建以来被修改了一次,那么这个版本怎么用呢,典型的我们可以利用版本来实现分布式的锁服务。我们知道在数据库中,一般有两种锁,一种是悲观锁一种是乐观锁。悲观锁
悲观锁又叫悲观并发锁,是数据库中一种非常严格的锁策略,具有强烈的排他性,能够避免不同事务对同一数据并发更新造成的数据不一致性,在上一个事务没有完成之前,下一个事务不能访问相同的资源,适合数据更新竞争非常激烈的场景;乐观锁
相比悲观锁,乐观锁使用的场景会更多,悲观锁认为事务访问相同数据的时候一定会出现相互的干扰,所以简单粗暴的使用排他访问的方式,而乐观锁认为不同事务访问相同资源是很少出现相互干扰的情况,因此在事务处理期间不需要进行并发控制,当然乐观锁也是锁,它还是会有并发的控制!对于数据库我们通常的做法是在每个表中增加一个version版本字段,事务修改数据之前先读出数据,当然版号也顺势读取出来,然后把这个读取出来的版本号加入到更新语句的条件中,比如,读取出来的版本号是1,我们修改数据的语句可以这样写,update 某某表 set 字段一=某某值 where id=1 and version=1,那如果更新失败了说明以后其他事务已经修改过数据了,那系统需要抛出异常给客户端,让客户端自行处理,客户端可以选择重试。
锁,ZK中版本有类式的作用。ZK的版本类型有三种:version cversion aversion
五、Watcher
Watcher我们可以理解为他是一个事件监听器
ZooKeeper允许用户在指定节点上注册一些Watcher,当数据节点发生变化的时候,ZooKeeper服务器会把这个变化的通知发送给感兴趣的客户端。
两个客户端都在zookeeper集群中注册了watcher(事件监听器),那么当zk中的节点数据发生变化的时候,zk会把这一变化的通知发送给客户端,当客户端收到这个变化通知的时候,它可以再回到zk中,去取得这个数据的详细信息。
六、ACL权限控制
ACL是Access Control Lists 的简写, ZooKeeper采用ACL策略来进行权限控制,有以下权限:
- []CREATE: 创建子节点的权限[/][]READ: 获取节点数据和子节点列表的权限[/][]WRITE: 更新节点数据的权限[/][]DELETE: 删除子节点的权限[/][]ADMIN: 设置节点ACL的权限[/]
上面的权限有点类似我们信息系统的权限管理,我们在开发系统的时候一般也会对数据做这些权限管理,一个zk集群可能会服务很多的业务,尤其是一些大公司,zk集群的节点中会保存重要的信息,那么这些信息通常只能对一部分的访问者开放,通过acl我们可以对某些节点的访问进行授权,从而来保证数据的安全。
Zookeeper介绍
大数据 空心菜 发表了文章 0 个评论 5073 次浏览 2016-02-28 18:32

根据如上思维导图,我来展开对Zookeeper的介绍
一、Zookeeper背景
随着互联网技术的高速发展,企业对计算机系统的计算、存储能力要求越来越高,最简单的证明就是出现了一些诸如:高并发,海量存储这样的词汇。在这样的背景下,单纯依靠少量高性能主机来完成计算任务也就不能满足现有大部分企业的需求了,企业的IT架构逐步从集中式向分布式过度,所谓的分布式是指:把一个计算任务分解成若干个计算单元,并且分配到若干不同的计算机中去执行,然后汇总计算结果的过程。
这好比公司里面的某个团队,接到公司派发的任务,首先团队的主管,要把任务进行拆分,然后安排下去,划分给团队中不同的人去完成,并随时跟进任务的进展。如果团队主管离职了,那我们可能就会在团队中挑选一个对业务比较熟悉的人来接管主管位置。最后各个组员把任务完成,主管进行汇总,并上报给公司。在团队内部需要制定多个工作流程,来保证工作的有序开展。在分布式系统中同样需要设置这么一个协作规范。zookeeper可以很好的帮助我们来实现这个目的。
二、Zookeeper是什么?
ZooKeeper是一个开放源码的分布式协调服务,由知名互联网公司雅虎创建,是基于Google Chubby开源实现。(Google chubby是google公司开源的一个锁服务。)
ZooKeeper是一个高性能的分布式数据一致性解决方案,它将那些复杂的、容易出错的分布式一致性服务封装起来了,构成了一个高效可靠的源语集,并提供一系列简单易用的接口给用户。
ZooKeeper致力于提供一个高性能、高可用、且具有严格的顺序访问控制能力的分布式协调服务。分布式应用可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知,集群管理、Master 选举、分布式锁和分布式队列等功能。Zookeeper知识点:
1、源代码开放
开源意味着我们可以免费的获取和使用zk,并且可以深入研究zk的源代码,甚至可以根据自己业务特性和要求进行二次开发修改。2、是分布式协调服务,它解决分布式数据一致性问题
A、顺序一致性
所谓的顺序一致性是指从一个客户端发起一个请求,最终会严格按照发起的顺序应用到zk中。B、原子性
原子性是指所有事物请求的处理结果在整个集群的所有机器上的应用情况是一致的。C、单一视图
单一视图是指无任客户端连接到哪个zk的服务器,它看到的服务端数据都是一致的。D、可靠性
可靠性是指一旦服务端成功的应用了一个事物并完成了对客户端的响应,那么这个事物所引起的服务端状态的变更会一直保留下来,除非有另外一个事物又对它进行了修改。E、实时性
实时性是指zk保证在一段时间内客户端一定能从服务端读取最新的数据状态。3、高性能
zk具有很高的吞吐量,一个三台服务器的集群可以达到12w-13w的QPS。4、我们可以通过调用zk提供的接口解决一些分布式易用中的实际问题。
三、Zookeeper的典型应用场景
Zookeeper包括但不限于如下应用场景
3.1、数据发布/订阅
顾名思义就是一方把数据发布出来,另一方通过某种方式可以得到这些数据;
通常数据订阅有两种方式:推送模式和拉取模式
推送模式一般是服务器主动向客户端推送信息, 拉取模式是客户端主动去服务器获取数据(通常是采用定时轮询的方式),ZK采用两种方式相结合;
发布者将数据发布到ZK集群节点上,订阅者通过一定的方法告诉服务器,我对哪个节点的数据感兴趣,那服务器在这些节点的数据发生变化时,就通知客户端,客户端得到通知后可以去服务器获取数据信息。3.2、负载均衡

实现过程:
1、首先DB在启动的时候先把自己在ZK上注册成一个临时节点,ZK的节点后面我们会讲到有两种,一种是永久节点,一类是临时节点临时节点在服务器出现问题的时候,节点会自动的从ZK上删除,那么这样ZK上的服务器列表就是最新的可用的列表。
2、客户端在需要读写数据库的时候首先它去ZooKeeper得到所有可用的DB的连接信息(一张列表),得到可用的数据列表。
3、客户端随机的算法,随机选择一个与之建立连接,每次会跟不同的数据库连接,就达到简单的复杂均衡。
4、当客户端发现连接不可用的时候可再次从ZK上获取可用的DB连接信息,当然也可以在刚获取的那个列表里移除掉不可用的连接后再随机选择一个DB与之连接。3.3、命名服务
顾名思义,就是提供名称的服务,例如数据库表格ID,一般用得比较多的有两种ID,一种是自动增长的ID,一种是UUID(9291d71a-0354-4d8e-acd8-64f7393c64ae),两种ID各自都有缺陷,自动增长的ID局限在单库单表中使用,不能在分布式中使用,UUID可以在分布式中使用但是由于ID没有规律难于理解,我们可以借用ZK来生成一个顺序增长的,可以在集群环境下使用的,命名易于理解的ID。3.4、分布式协调/通知
心跳检测,在分布式系统中,我们常常需要知道某个机器是否可用,传统的开发中,可以通过Ping某个主机来实现,Ping得通说明对方是可用的,相反是不可用的;
ZK中我们让所有的机其都注册一个临时节点,我们判断一个机器是否可用,我们只需要判断这个节点在ZK中是否存在就可以了,不需要直接去连接需要检查的机器 ,降低系统的复杂度。
四、Zookeeper的优势
- []源代码开放[/][]已经被证实是高性能,易用稳定的工业级产品。[/][]有着广泛的应用:Hadoop,HBase,Storm,Solr。[/]
转载请注明来自开源技术社区 : http://openskill.cn/article/281
zookeeper启动失败案例分析
大数据 Ansible 发表了文章 0 个评论 8094 次浏览 2016-02-24 17:54
[root@zk1 bin]# ./zkServer.sh start查看状态如下:
JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@zk1 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
我netstat -anltup |grep 2018,并没有监听,端口没有占用啊?
那只好去看日志了,查看zookeeper的zookeeper.out日志内容如下:
2016-02-24 17:35:22,425 [myid:] - ERROR [main:ZooKeeperServerMain@63] - Unexpected exception, exiting abnormally从日志中"Address already in use"可以看出端口被占用了!
java.net.BindException: Address already in use
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:344)
at sun.nio.ch.Net.bind(Net.java:336)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:199)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:67)
at org.apache.zookeeper.server.NIOServerCnxnFactory.configure(NIOServerCnxnFactory.java:95)
at org.apache.zookeeper.server.ZooKeeperServerMain.runFromConfig(ZooKeeperServerMain.java:110)
at org.apache.zookeeper.server.ZooKeeperServerMain.initializeAndRun(ZooKeeperServerMain.java:86)
at org.apache.zookeeper.server.ZooKeeperServerMain.main(ZooKeeperServerMain.java:52)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:116)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
但我用netstat -lntup是没被使用的,再用 lsof -i:2181,发现了2181端口果然被占用了。其实最好的办法是nc -v -z locahost 2181 探测一些本地2181端口是否监听!
[root@zk1 ~]# nc -v -z localhost 2181好了,端口被占用了,只能修改zk的默认端口,从新启动ok!
Connection to localhost 2181 port [tcp/eforward] succeeded!
[root@zk1 ~]#
zookeepr运维经验分享
大数据 空心菜 发表了文章 0 个评论 3077 次浏览 2015-10-19 23:09
- 集群数量
3台起,如果是虚拟机,必须分散在不同的宿主机上,以实现容灾的目的。如果长远来看(如2-3年)需求会持续增长,可以直接部署5台。ZooKeeper集群扩容是比较麻烦的事情,因此宁可前期稍微浪费一点。
- 客户端配置域名而不是 IP
如果有一天你的 ZooKeeper 集群需要做机房迁移,或者其中几个节点机器挂了,需要更换。让你的用户更新 ZooKeeper 服务器配置不是件轻松的事情,因此一开始就配置好域名,到时候更新 DNS 即可。
- 开启 autopurge.snapRetainCount
ZooKeeper 默认不会自动清理 tx log,所以总会有一天你会收到磁盘报警(如果你有磁盘监控的话)。开启自动清理机制后,就不用担心了,我的配置如下:
autopurge.snapRetainCount=500
autopurge.purgeInterval=24
- 扩容
如果你可以接受停止服务半个小时,那基本随意玩了,但在比较严肃的环境下,还是不能停服务的。我的做法是这样的:
0. 有节点 A, B, C 处于服务状态
server.3=192.168.12.1:2888:38881. 加入节点 D,配置如下:
server.4=192.168.12.2:2888:3888
server.5=192.168.12.3:2888:3888
server.3=192.168.12.1:2888:3888用 4 字命令检查,保证该节点同步完毕集群数据,处于 Follower 状态:
server.4=192.168.12.2:2888:3888
server.5=192.168.12.3:2888:3888
server.6=192.168.12.4:2888:3888
server.7=192.168.12.5:2888:3888
# echo srvr | nc 192.168.12.4 2181需要注意的是,这一步加入的节点的 id,必须大于集群中原有的节点的 id,例如 6 > 3,4,5,我也不知道为什么需要这样。
Zookeeper version: 3.4.5-1392090, built on 09/30/2012 17:52 GMT
Latency min/avg/max: 0/0/13432
Received: ***
Sent: ***
Connections: ***
Outstanding: 0
Zxid: 0x***
Mode: follower
Node count: ***
- 同上一步一样,加入节点 E
- 更新 A B C 的配置如 D 和 E,并依此重启
- 机房迁移
例如要把服务从 X 机房的 A B C 迁移到 Y 机房的 A’ B’ C’。
做法是首先把集群扩容成包含6个节点的集群;然后修改域名指向让用户的连接都转到 A’ B’ C’;最后更新集群配置,把 A B C 从集群摘除。
- 跨机房容灾
由于 ZooKeeper 天生不喜欢偶数(怕脑裂),因此有条件的就三机房部署,但机房之间的网络条件得是类似局域网的条件,否则性能就堪忧了。
双机房做自动容灾基本不可能,加入手动步骤是可以的,和 DB 一样,短时间不可用,立刻启用另外一个机房,平时保证数据同步。
三机房部署,如果一个机房离的比较远,网络延迟较高怎么办?可以 3 + 3 + 1 部署,1 就放在那个网络延迟较高的地方,确保 leader 在 3 + 3 这两个机房中间,那么平时的性能就能保证了。怎么保证 leader 不到 1 呢?目前能想到的办法就是如果发现就重启它

