
Git工作流程最佳实践总结
Git工作流的最佳实践方案包括如下四个步骤:
1. 根据task创建对应的branch
当我们开始针对一个task编码之前,首先第一步应该要创建一个新的branch,然后checkout到这个新的branch上开始编码。我们不应该直接在master上进行新的task的编码工作,尤其是在团队成员较多的情况下。团队的每个成员都应工作于自己新创建的branch上,而不会操作master分支,这样做的好处在于master始终处于一种“干净”的状态,不会因为多人的同时操作而造成过多的冲突,同时也降低了master被误操作的可能性。具体的操作如下:
//切换到master分支;
git checkout master
//拉取master远程分支的代码;
git pull origin master
//创建新的分支并切换到新的分支上。
git checkout -b
2. 在新建的分支上编码,push代码到远程分支上
分支创建完毕之后,我们就可以开始在branch上进行编码了。这是我们完成task的最主要的阶段,绝大部分的工作在此阶段完成,同时它应该也是持续时间最长的阶段。它的主要任务就是完成task的编码工作,并最终将代码push到当前分支对应的远程分支上去。
首先看一下这个阶段Git工作的命令流,示例如下:
//创建新的branch后的第一天工作结束时,首先将改动的代码放入index区;
git add .
//然后提交代码到本地仓库;
git commit -m "The first commit message"
//第二天开始工作前,切换到master分支;
git checkout master
//从master的远程分支拉取代码;
git pull origin master
//切换到task所在的本地分支;
git checkout
//将master上的最新的代码合并到当前分支上,这里的-i的作用是将我们 当前分支之前的commit压缩成为一个commit,这样做的好处在于当我们之后创建pull request并进行相应的code review的时候,代码的改动会集中在一个commit,使得code review更直观方便;
git rebase -i master
//第二天工作结束之后,将第二天的改动放入index区;
git add .
//提交代码到当前branch的本地仓库;
git commit -m "The second commit message"
//第三天开始工作前,..........
git checkout master //同上第二天
git pull origin master //同上第二天
git checkout //同上第二天
git rebase -i master //同上第二天
//第三天工作结束之后,
git add . //同上第二天
git commit -m "The third commit message" //同上第二天
//最后,当task的所有编码完成之后,将代码push到远程分支。通过以上的工作流可以看出,我们在完成task期间所有的代码都始终存放在我们新创建的branch的本地仓库上。只有当所有的编码工作完成之后,才会将最终的代码push到当前分支的远程仓库。这样做的好处在于,我们push到远程的代码,也就是之后会通过pull request被code review的代码,始终是针对一个单独task的完整代码,这将有利于之后code review的执行。不过这样做同时可能会存在一个缺点,那就是最终一次push的代码可能会非常庞大,这就要求我们对于task粒度的把握应该更合适。我们不应针对一个非常大的task创建branch,完成编码,而是应该尽可能的将task分解成一个个粒度较小的子task,进而针对子task创建branch完成编码的工作。这是一项非常有技巧的工作,需要丰富的实践经验,它也不是本节要讨论的内容,不再赘述。
git push --set-upstream origin
3. 创建pull request, 进行code review
当所有的代码都已经被push到远程分支后,这时我们还不可以将代码合并到master上去,我们应该要做的是创建pull request。pull request的作用在于它可以使得代码在merge到master分支之前,能够被团队成员code review,从而提高代码的质量以及降低出错的概率。实际项目中我们使用jira来帮助我们创建相应的pull request,当然Github本身就具备创建pull request的功能。创建pull request的操作非常简单,无非就是点击创建pull request的按钮,填写comment信息,并输入可以进行code review的成员名称。当pull request创建完成之后,所有可以进行code review的团队成员都会收到邮件通知,并通过相应的pull request的链接查看代码的改动,从而完成code review的工作。这个步骤没有实际的Git指令的操作。
4. 合并代码到master,并删除之前创建的branch
当所有的reviewer都结束了code review,且都已经将pull request标注为approved状态的时候,我们就可以将branch合并到master上去,并最终push到远程master分支。示例如下:
git checkout master //切换到master分支;经过以上四个步骤之后,一个task的 Git的工作流就结束了。之后,我们可以愉快的开始下一个task了~~
git merge//合并之前创建的分支的代码到master分支上;
git push origin master//将master的代码push到master的远程分支;
git branch -d//删除之前创建的分支。
文/Ifdef_Max(简书作者)
原文链接:http://www.jianshu.com/p/202de00f267f 收起阅读 »
Elasticsearch Recovery详解
基础知识点
在Eleasticsearch中recovery指的就是一个索引的分片分配到另外一个节点的过程;一般在快照恢复、索引副本数变更、节点故障、节点重启时发生。由于master保存整个集群的状态信息,因此可以判断出哪些shard需要做再分配,以及分配到哪个结点,例如:
- 如果某个shard主分片在,副分片所在结点挂了,那么选择另外一个可用结点,将副分片分配(allocate)上去,然后进行主从分片的复制;
- 如果某个shard的主分片所在结点挂了,副分片还在,那么将副分片升级为主分片,然后做主从分片复制;
- 如果某个shard的主副分片所在结点都挂了,则暂时无法恢复,等待持有相关数据的结点重新加入集群后,从该结点上恢复主分片,再选择另外的结点复制副分片。
正常情况下,我们可以通过ES的health的API接口,查看整个集群的健康状态和整个集群数据的完整性:
状态及含义如下:
- green: 所有的shard主副分片都是正常的;
- yellow: 所有shard的主分片都完好,部分副分片没有或者不完整,数据完整性依然完好;
- red: 某些shard的主副分片都没有了,对应的索引数据不完整。
ecovery过程要消耗额外的资源,CPU、内存、结点之间的网络带宽等等。 这些额外的资源消耗,有可能会导致集群的服务性能下降,或者一部分功能暂时不可用。了解一些recovery的过程和相关的配置参数,对于减小recovery带来的资源消耗,加快集群恢复过程都是很有帮助的。
减少集群Full Restart造成的数据来回拷贝
ES集群可能会有整体重启的情况,比如需要升级硬件、升级操作系统或者升级ES大版本。重启所有结点可能带来的一个问题: 某些结点可能先于其他结点加入集群, 先加入集群的结点可能已经可以选举好master,并立即启动了recovery的过程,由于这个时候整个集群数据还不完整,master会指示一些结点之间相互开始复制数据。
那些晚到的结点,一旦发现本地的数据已经被复制到其他结点,则直接删除掉本地“失效”的数据。 当整个集群恢复完毕后,数据分布不均衡,显然是不均衡的,master会触发rebalance过程,将数据在节点之间挪动。
整个过程无谓消耗了大量的网络流量;合理设置recovery相关参数则可以防范这种问题的发生。
gateway.expected_nodes
gateway.expected_master_nodes
gateway.expected_data_nodes
以上三个参数是说集群里一旦有多少个节点就立即开始recovery过程。 不同之处在于,第一个参数指的是master或者data节点都算在内,而后面两个参数则分指master和data node。
在期待的节点数条件满足之前, recovery过程会等待gateway.recover_after_time (默认5分钟) 这么长时间,一旦等待超时,则会根据以下条件判断是否启动:
gateway.recover_after_nodes
gateway.recover_after_master_nodes
gateway.recover_after_data_nodes
举例来说,对于一个有10个data node的集群,如果有以下的设置:
gateway.expected_data_nodes: 10
gateway.recover_after_time: 5m
gateway.recover_after_data_nodes: 8
那么集群5分钟以内10个data node都加入了,或者5分钟以后8个以上的data node加入了,都会立即启动recovery过程。
减少主副本之间的数据复制
如果不是full restart,而是重启单个data node,仍然会造成数据在不同结点之间来回复制。为避免这个问题,可以在重启之前,先关闭集群的shard allocation:
然后在节点重启完成加入集群后,再重新打开: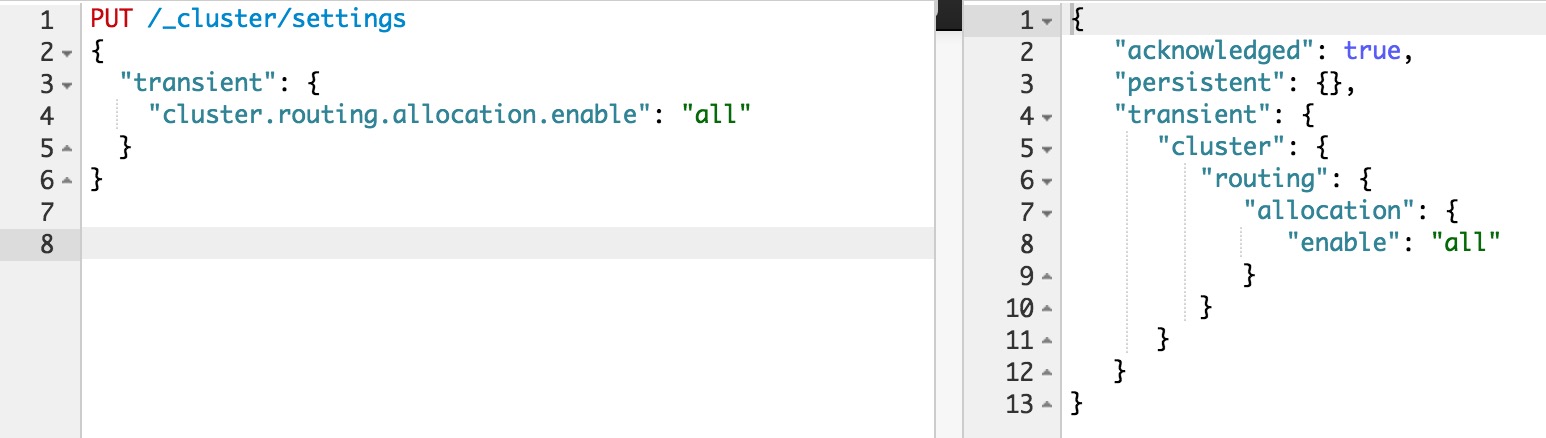
这样在节点重启完成后,尽量多的从本地直接恢复数据。
但是在ES1.6版本之前,即使做了以上措施,仍然会发现有大量主副本之间的数据拷贝。从表面去看,这点很让人不能理解。 主副本数据完全一致,ES应该直接从副本本地恢复数据就好了,为什么要重新从主片再复制一遍呢? 原因在于recovery是简单对比主副本的segment file来判断哪些数据一致可以本地恢复,哪些不一致需要远端拷贝的。而不同节点的segment merge是完全独立运行的,可能导致主副本merge的深度不完全一样,从而造成即使文档集完全一样,产生的segment file却不完全一样。
为了解决这个问题,ES1.6版本以后加入了synced flush的新特性。 对于5分钟没有更新过的shard,会自动synced flush一下,实质是为对应的shard加了一个synced flush ID。这样当重启节点的时候,先对比一下shard的synced flush ID,就可以知道两个shard是否完全相同,避免了不必要的segment file拷贝,极大加快了冷索引的恢复速度。
需要注意的是synced flush只对冷索引有效,对于热索引(5分钟内有更新的索引)没有作用。 如果重启的结点包含有热索引,那么还是免不了大量的文件拷贝。因此在重启一个结点之前,最好按照以下步骤执行,recovery几乎可以瞬间完成:
- 暂停数据写入程序
- 关闭集群shard allocation
- 手动执行POST /_flush/synced
- 重启节点
- 重新开启集群shard allocation
- 等待recovery完成,集群health status变成green
- 重新开启数据写入程序
特大热索引为何恢复慢
对于冷索引,由于数据不再更新,利用synced flush特性,可以快速直接从本地恢复数据。 而对于热索引,特别是shard很大的热索引,除了synced flush派不上用场需要大量跨节点拷贝segment file以外,translog recovery是导致慢的更重要的原因。
从主片恢复数据到副片需要经历3个阶段:
- 对主片上的segment file做一个快照,然后拷贝到复制片分配到的结点。数据拷贝期间,不会阻塞索引请求,新增索引操作记录到translog里;
- 对translog做一个快照,此快照包含第一阶段新增的索引请求,然后重放快照里的索引操作。此阶段仍然不阻塞索引请求,新增索引操作记录到translog里;
- 为了能达到主副片完全同步,阻塞掉新索引请求,然后重放阶段二新增的translog操作。
可见,在recovery完成之前,translog是不能够被清除掉的(禁用掉正常运作期间后台的flush操作)。如果shard比较大,第一阶段耗时很长,会导致此阶段产生的translog很大。重放translog比起简单的文件拷贝耗时要长得多,因此第二阶段的translog耗时也会显著增加。等到第三阶段,需要重放的translog可能会比第二阶段还要多。 而第三阶段是会阻塞新索引写入的,在对写入实时性要求很高的场合,就会非常影响用户体验。 因此,要加快大的热索引恢复速度,最好的方式是遵从上一节提到的方法: 暂停新数据写入,手动sync flush,等待数据恢复完成后,重新开启数据写入,这样可以将数据延迟影响可以降到最低。
万一遇到Recovery慢,想知道进度怎么办呢? CAT Recovery API可以显示详细的recovery各个阶段的状态。 这个API怎么用就不在这里赘述了,参考: CAT Recovery。
其他Recovery相关的专家级设置
还有其他一些专家级的设置(参考: recovery)可以影响recovery的速度,但提升速度的代价是更多的资源消耗,因此在生产集群上调整这些参数需要结合实际情况谨慎调整,一旦影响应用要立即调整回来。 对于搜索并发量要求高,延迟要求低的场合,默认设置一般就不要去动了。 对于日志实时分析类对于搜索延迟要求不高,但对于数据写入延迟期望比较低的场合,可以适当调大indices.recovery.max_bytes_per_sec,提升recovery速度,减少数据写入被阻塞的时长。
最后要说的一点是ES的版本迭代很快,对于Recovery的机制也在不断的优化中。 其中有一些版本甚至引入了一些bug,比如在ES1.4.x有严重的translog recovery bug,导致大的索引trans log recovery几乎无法完成 (issue #9926) 。因此实际使用中如果遇到问题,最好在Github的issue list里搜索一下,看是否使用的版本有其他人反映同样的问题。
分享阅读参考: https://henduan.com/rCWPD
收起阅读 »支撑互联网时代的7大开源软件
最伟大的互联网开源系统Linux

Linux是一款免费的操作系统,诞生于1991年,用户可以通过网络或其他途径免费获得,并可以任意修改其源代码。
它能运行主要的UNIX工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳 定的多用户网络操作系统。这个系统是由全世界各地的成千上万的程序员设计和实现的。其目的是建立不受任何商品化软件的版权制约的、全世界都能自由使用的 Unix兼容产品。
Linux可以说是已经无处不在,像Android手机就是以Linux为基础开发的,世界上大多的超级计算机也都采用的Linux系统,大多数的 数据中心使用Linux作为其支撑操作系统。谷歌、百度、淘宝等都通过Linux提供了我们每天用的互联网服务。Linux在航空控制系统中也扮演着重要角色,而且现在互联网的程序员和运维工作人员等,每天基本都是和Linux系统打交道。
加密互联网的安全协议OpenSSL

OpenSSL是套开放源代码的软件库包,实现了SSL与TLS协议。OpenSSL可以说是一个基于密码学的安全开发包,囊括了主要的密码算法、常用的密钥和证书封装管理功能以及SSL协议,并提供了丰富的应用程序供测试或其它目的使用。
也可以说OpenSSL是网络通信提供安全及数据完整性的一种安全协议,SSL可以在Internet上提供秘密性传输,能使用户/服务器应用之间的通信不被攻击者窃听。OpenSSL被网银、在线支付、电商网站、门户网站、电子邮件等重要网站广泛使用。
去年OpenSSL爆出安全漏洞,因为其应用如此之广,该漏洞爆出让整个互联网都为之震颤。
数据仓库大王--MySQL

MySQL是一个开源的小型的数据库管理系统,原开发者为瑞典的MySQL AB公司,该公司于2008年被Sun公司收购。2009年,甲骨文公司(Oracle)收购Sun公司,MySQL成为Oracle旗下产品。
很多信息都是存在数据库里面的,很多工程师在开发一些的小型项目时都会采用这个MySQL数据库。MySQL为C、C++、JAVA、PHP等多重 编程语言提供了API接口。而且支持windows、Mac、Linux等多种系统。这种广泛的支持使其得到更多开发者的青睐,MySQL是开发者需要掌 握的数据库之一。
Mysql最初为小型应用而开发,但现在的Mysql已经不是一个小型数据库了。基本上所有的互联网公司都会使用这个数据库系统,一些金融交易也会 采用Mysql作为数据库引擎。Mysql通过相应的调优既可以支撑大规模的访问,又可以保证数据安全性,已经成为威胁传统商业数据库系统的重要力量。
万能开发工具Eclipse

Eclipse 是一个开放源代码的、基于Java的可扩展开发平台。Eclipse最初由OTI和IBM两家公司的IDE产品开发组创建,起始于1999年4月。目前由 IBM牵头,围绕着Eclipse项目已经发展成为了一个庞大的Eclipse联盟,有150多家软件公司参与到Eclipse项目中,其中包括 Borland、Rational Software、Red Hat及Sybase等。
就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境。很多Java编程软件都是在Eclipse平台开发的,还有包括 Oracle在内的许多大公司也纷纷加入了该项目,并宣称Eclipse将来能成为可进行任何语言开发的IDE集大成者,使用者只需下载各种语言的插件即可。
Eclipse并不是一个直接服务于消费者的产品,它更像一个工匠手中万用工具,用Eclipse开发者可以打造出各种充满创造性的服务来满足最终用户的需求。
互联网的门卫Apache

Apache HTTP Server(简称Apache)是Apache软件基金会的一个开放源码的网页服务器,可以在大多数计算机操作系统中运行,由于其多平台和安全性被广泛 使用,也是最流行的Web服务器端软件之一,市场占有率达60%左右。它快速、可靠并且可通过简单的API扩展,它可以和各种解释器配合使用,包括 PHP/Perl/Python等。
Apache就像一个负责的门卫,管理着服务器数据的进出。每当你在你的地址栏里输入http://xxoo.com 的时候,在遥远的远端,很有可能正是一台跑着Apache的服务器,将你需要的信息传输给浏览器。
大数据的心脏Hadoop

Hadoop 是一个能够对大量数据进行分布式处理的软件框架,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。Hadoop 一 直帮助解决各种问题,包括超大型数据集的排序和大文件的搜索。它还是各种搜索引擎的核心,比如 Amazon 的 A9 和用于查找酒信息 的 Able Grape 垂直搜索引擎。阿里巴巴集团在商品推荐、用户行为分析、信用计算领域也都有hadoop的应用。
在“大数据”已经成为潮流的当下,Hadoop已经成为最主要的一项技术。可以毫不夸张的说,没有Hadoop,就没有大多数的大数据应用。可以说对一个不知道Hadoop的程序员而言,你已经out了。
互联网的“排版引擎”WebKit

说是浏览器内核,其实“排版引擎”更容易理解一些。通过服务器传输给浏览器的信息只是一串乱糟糟的文本。要看到我们平时看到精美的网友,需要浏览器内核对这些文本进行解析,将枯燥的描述“画”成美丽的浏览界面。
WebKit 是一个开源的浏览器引擎,与之相应的引擎有Gecko(Mozilla Firefox 等使用的排版引擎)和Trident(也称为MSHTML,IE 使用的排版引擎)。根据StatCounter的浏览器市场份额调查,于2012年11月,Webkit市占超过了40%,它已经成为拥有最大市场份额的 排版引擎,超越了Internet Explorer所使用的Trident及Firefox所使用的Gecko引擎,并且WebKit份额正在逐年增加。
目前几乎所有网站和网银已经逐渐支持WebKit。WebKit 内核在手机上的应用也十分广泛,例如苹果的Safari、谷歌的Chrome浏览器都是基于这个框架来开发的。
总结
很多人可能尚未意识到,我们使用的电脑中运行有开源软件,手机中运行有开源软件,家里的电视也运行有开源软件,甚至小小的数码产品中也运行有开源软件,尤其是互联网服务器端软件,几乎全部是开源软件。毫不夸张地说,开源软件已经渗透到了我们日常生活的方方面面。
只有真正的开源软件产品才会做得更好,做得更有历史,会让使用的人由衷的感觉自由和快乐,只有这样才会像民族英雄一样,永远被传唱,被继承和传播,开源软件最大的意义就是众家参与,大家快乐,共同享受,为那些开源的极客们和开源企业致敬! 收起阅读 »
Linux的net.ipv4.tcp_timestamps参数
原因就是net.ipv4.tcp_timestamps=1,启用了时间戳,原理如下:
问题出在了 tcp 三次握手,如果有一个用户的时间戳大于这个链接发出的syn中的时间戳,服务器上就会忽略掉这个syn,不返会syn-ack消息,表现为用户无法正常完成tcp3次握手,从而不能打开web页面。在业务闲时,如果用户nat的端口没有被使用过时,就可以正常打开;业务忙时,nat端口重复使用的频率高,很难分到没有被使用的端口,从而产生这种问题。
解决:
net.ipv4.tcp_timestamps = 0收起阅读 »
然后syctlp -p生效即可。
Kafka入门简介
Kafka背景
Kafka它本质上是一个消息系统,由当时从LinkedIn出来创业的三人小组开发,他们开发出了Apache Kafka实时信息队列技术,该技术致力于为各行各业的公司提供实时数据处理服务解决方案。Kafka为LinkedIn的中枢神经系统,管理从各个应用程序的汇聚,这些数据经过处理后再被分发到其他地方。Kafka不同于传统的企业信息队列系统,它是以近乎实时的方式处理流经一个公司的所有数据,目前已经服务于LinkedIn、Netflix、Uber以及Verizon,并为此建立了实时信息处理平台。
流水数据是所有站点对其网站使用情况做报表时都要用到的数据中最常用的一部分,流水数据包括PV,浏览内容信息以及搜索记录等。这些数据通常是先以日志文件的形式存在,然后有周期的去对这些日志文件进行统计分析处理,然后获得需要的KPI指标结果。
Kafka应用场景
我们在接触一门新技术或是新语言时,得明白这门技术(或是语言)的应用场景,也就说要明白它能做什么,服务的对象是谁,下面用一个图来说明,如下图所示:

首先,Kafka可以应用于消息系统,比如,当下较为热门的消息推送,这些消息推送系统的消息源,可以使用Kafka作为系统的核心组建来完成消息的生产和消息的消费。然后是网站的行迹,我们可以将企业的Portal,用户的操作记录等信息发送到Kafka中,按照实际业务需求,可以进行实时监控,或者做离线处理等。最后,一个是日志收集,类似于Flume套件这样的日志收集系统,但Kafka的设计架构采用push/pull,适合异构集群,Kafka可以批量提交消息,对Producer来说,在性能方面基本上是无消耗的,而在Consumer端中,我们可以使用HDFS这类的分布式文件存储系统进行存储。
Kafka架构原理
Kafka的设计之初是希望做一个统一的信息收集平台,能够实时的收集反馈信息,并且具有良好的容错能力。Kafka中我们最直观的感受就是它的消费者与生产者,如下图所示:
Producer And Consumer:

这里Kafka对消息的保存是根据Topic进行归类的,由消息生产者(Producer)和消息消费者(Consumer)组成,另外,每一个Server称为一个Broker。对于Kafka集群而言,Producer和Consumer都依赖于ZooKeeper来保证数据的一致性。
Topic:
在每条消息输送到Kafka集群后,消息都会由一个Type,这个Type被称为一个Topic,不同的Topic的消息是分开存储的。如下图所示:

一个Topic会被归类为一则消息,每个Topic可以被分割为多个Partition,在每条消息中,它在文件中的位置称为Offset,用于标记唯一一条消息。在Kafka中,消息被消费后,消息仍然会被保留一定时间后在删除,比如在配置信息中,文件信息保留7天,那么7天后,不管Kafka中的消息是否被消费,都会被删除;以此来释放磁盘空间,减少磁盘的IO消耗。
在Kafka中,一个Topic的多个分区,被分布在Kafka集群的多个Server上,每个Server负责分区中消息的读写操作。另外,Kafka还可以配置分区需要备份的个数,以便提高可用行。由于用到来ZK来协调,每个分区都有一个Server为Leader状态,服务对外响应(如读写操作),若该Leader宕机,会由其他的Follower来选举出新的Leader来保证集群的高可用性。
总结
kafka是一个非常强悍的消息队列系统,他支持持久化和数据偏移,从而实现多个消费者同时消费一份数据是没有问题的。简单的来说他就是一个生产者消费模型的架构,居于zookeeper来管理每个Topic的信息记录和偏移量,从而达到高效和多复用的概念,消息不会消失,除非过期。 收起阅读 »
京东咚咚架构演进

咚咚是什么?咚咚之于京东相当于旺旺之于淘宝,它们都是服务于买家和卖家的沟通。 自从京东开始为第三方卖家提供入驻平台服务后,咚咚也就随之诞生了。 我们首先看看它诞生之初是什么样的。
1.0 诞生(2010 - 2011)
为了业务的快速上线,1.0 版本的技术架构实现是非常直接且简单粗暴的。 如何简单粗暴法?请看架构图,如下: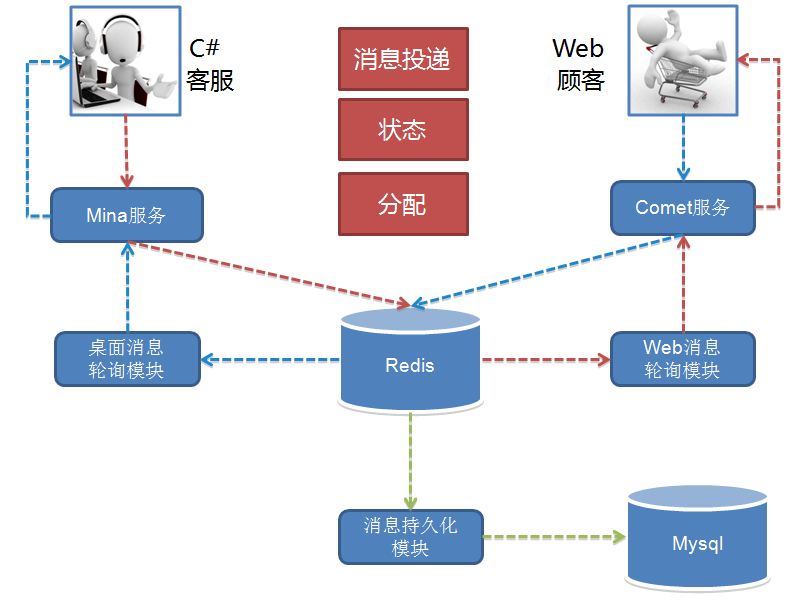
1.0 的功能十分简单,实现了一个 IM 的基本功能,接入、互通消息和状态。 另外还有客服功能,就是顾客接入咨询时的客服分配,按轮询方式把顾客分配给在线的客服接待。 用开源 Mina 框架实现了 TCP 的长连接接入,用 Tomcat Comet 机制实现了 HTTP 的长轮询服务。 而消息投递的实现是一端发送的消息临时存放在 Redis 中,另一端拉取的生产消费模型。
这个模型的做法导致需要以一种高频率的方式来轮询 Redis 遍历属于自己连接的关联会话消息。 这个模型很简单,简单包括多个层面的意思:理解起来简单;开发起来简单;部署起来也简单。 只需要一个 Tomcat 应用依赖一个共享的 Redis,简单的实现核心业务功能,并支持业务快速上线。
但这个简单的模型也有些严重的缺陷,主要是效率和扩展问题。 轮询的频率间隔大小基本决定了消息的延时,轮询越快延时越低,但轮询越快消耗也越高。 这个模型实际上是一个高功耗低效能的模型,因为不活跃的连接在那做高频率的无意义轮询。 高频有多高呢,基本在 100 ms 以内,你不能让轮询太慢,比如超过 2 秒轮一次,人就会在聊天过程中感受到明显的会话延迟。 随着在线人数增加,轮询的耗时也线性增长,因此这个模型导致了扩展能力和承载能力都不好,一定会随着在线人数的增长碰到性能瓶颈。
1.0 的时代背景正是京东技术平台从 .NET 向 Java 转型的年代,我也正是在这期间加入京东并参与了京东主站技术转型架构升级的过程。 之后开始接手了京东咚咚,并持续完善这个产品,进行了三次技术架构演进。
2.0 成长(2012)
我们刚接手时 1.0 已在线上运行并支持京东 POP(开放平台)业务,之后京东打算组建自营在线客服团队并落地在成都。 不管是自营还是 POP 客服咨询业务当时都起步不久,1.0 架构中的性能和效率缺陷问题还没有达到引爆的业务量级。 而自营客服当时还处于起步阶段,客服人数不足,服务能力不够,顾客咨询量远远超过客服的服务能力。 超出服务能力的顾客咨询,当时我们的系统统一返回提示客服繁忙,请稍后咨询。 这种状况导致高峰期大量顾客无论怎么刷新请求,都很可能无法接入客服,体验很差。 所以 2.0 重点放在了业务功能体验的提升上,如下图所示: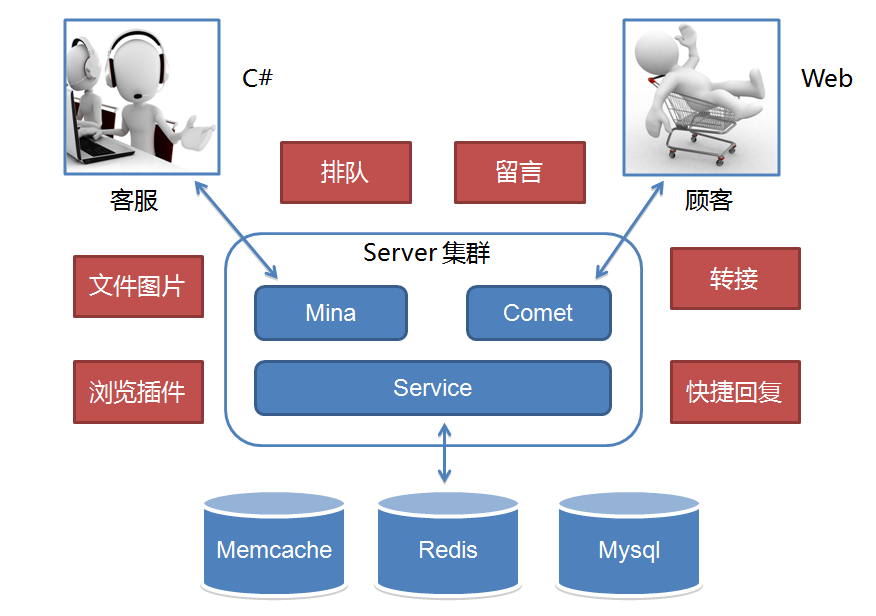
针对无法及时提供服务的顾客,可以排队或者留言。 针对纯文字沟通,提供了文件和图片等更丰富的表达方式。 另外支持了客服转接和快捷回复等方式来提升客服的接待效率。 总之,整个 2.0 就是围绕提升客服效率和用户体验。 而我们担心的效率问题在 2.0 高速发展业务的时期还没有出现,但业务量正在逐渐积累,我们知道它快要爆了。 到 2012 年末,度过双十一后开始了 3.0 的一次重大架构升级。
3.0 爆发(2013 - 2014)
经历了 2.0 时代一整年的业务高速发展,实际上代码规模膨胀的很快。 与代码一块膨胀的还有团队,从最初的 4 个人到近 30 人。 团队大了后,一个系统多人开发,开发人员层次不一,规范难统一,系统模块耦合重,改动沟通和依赖多,上线风险难以控制。 一个单独 tomcat 应用多实例部署模型终于走到头了,这个版本架构升级的主题就是服务化。
服务化的第一个问题如何把一个大的应用系统切分成子服务系统。 当时的背景是京东的部署还在半自动化年代,自动部署系统刚起步,子服务系统若按业务划分太细太多,部署工作量很大且难管理。 所以当时我们不是按业务功能分区服务的,而是按业务重要性级别划分了 0、1、2 三个级别不同的子业务服务系统。 另外就是独立了一组接入服务,针对不同渠道和通信方式的接入端,见下图。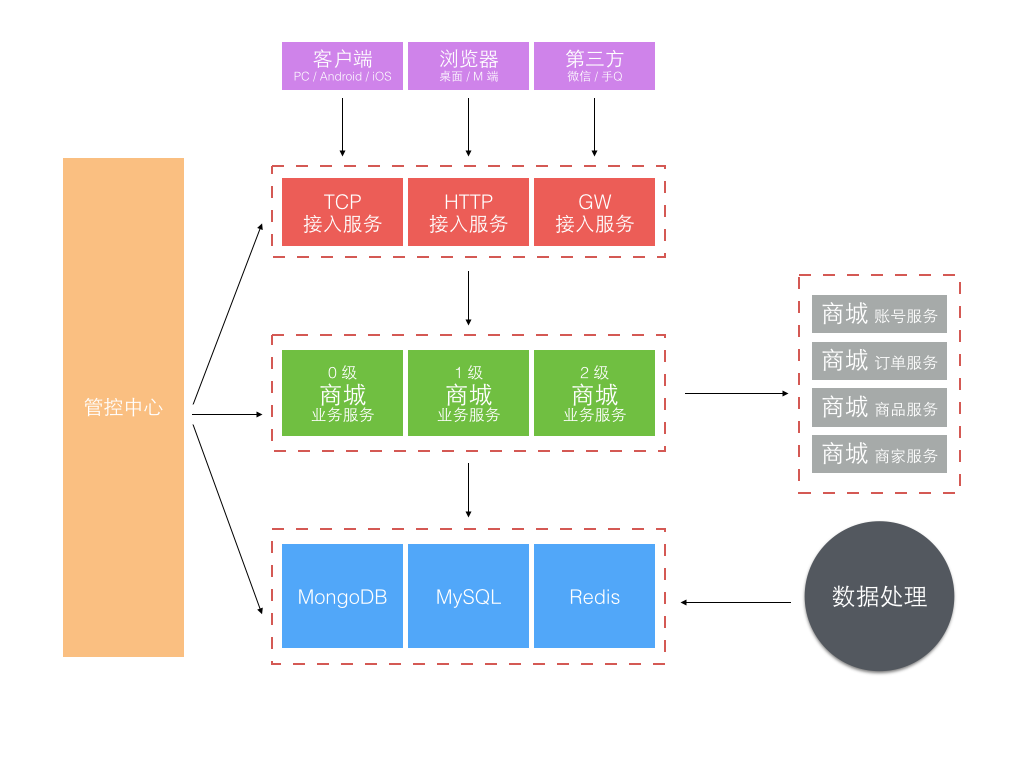
更细化的应用服务和架构分层方式可见下图: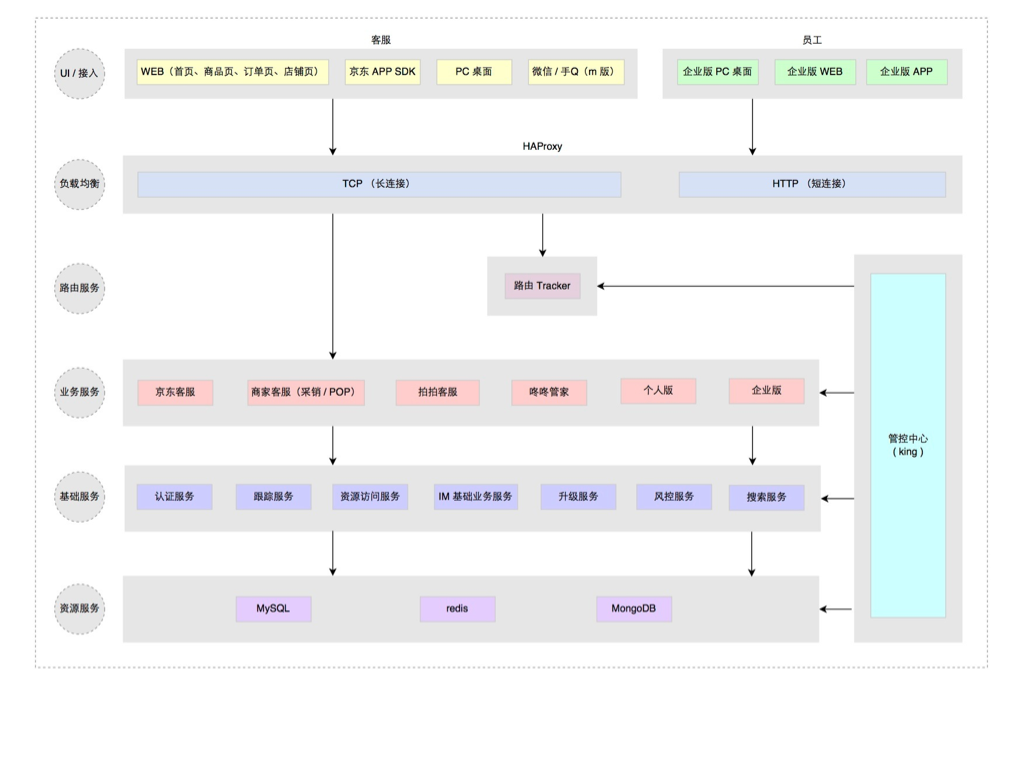
这次大的架构升级,主要考虑了三个方面:稳定性、效率和容量。 做了下面这些事情:
- 业务分级、核心、非核心业务隔离;
- 多机房部署,流量分流、容灾冗余、峰值应对冗余;
- 读库多源,失败自动转移;
- 写库主备,短暂有损服务容忍下的快速切换;
- 外部接口,失败转移或快速断路;
- Redis 主备,失败转移;
- 大表迁移,MongoDB 取代 MySQL 存储消息记录;
- 改进消息投递模型
前 6 条基本属于考虑系统稳定性、可用性方面的改进升级。 这一块属于陆续迭代完成的,承载很多失败转移的配置和控制功能在上面图中是由管控中心提供的。
第 7 条主要是随着业务量的上升,单日消息量越来越大后,使用了 MongoDB 来单独存储量最大的聊天记录。 第 8 条是针对 1.0 版本消息轮询效率低的改进,改进后的投递方式如下图所示: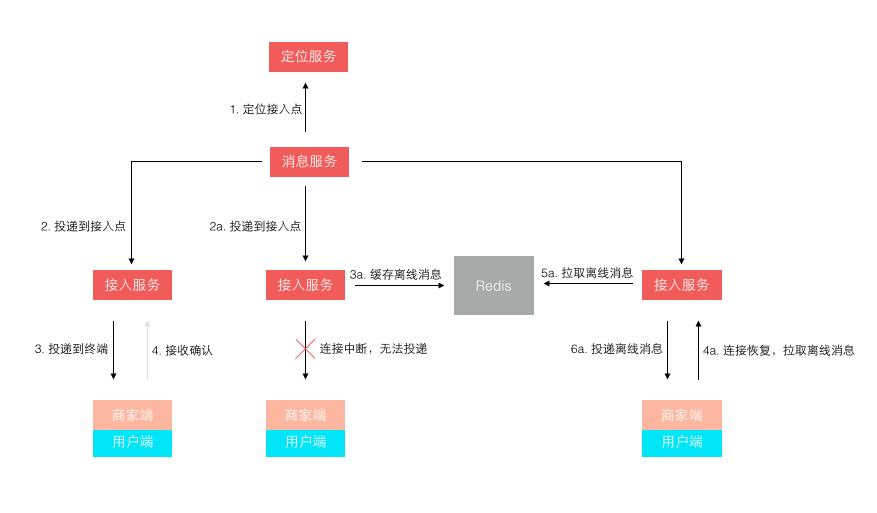
不再是轮询了,而是让终端每次建立连接后注册接入点位置,消息投递前定位连接所在接入点位置再推送过去。 这样投递效率就是恒定的了,而且很容易扩展,在线人数越多则连接数越多,只需要扩展接入点即可。 其实,这个模型依然还有些小问题,主要出在离线消息的处理上,可以先思考下,我们最后再讲。
3.0 经过了两年的迭代式升级,单纯从业务量上来说还可以继续支撑很长时间的增长。 但实际上到 2014 年底我们面对的不再是业务量的问题,而是业务模式的变化。 这直接导致了一个全新时代的到来。
4.0 涅槃(2015 至今 )
2014 年京东的组织架构发生了很大变化,从一个公司变成了一个集团,下设多个子公司。 原来的商城成为了其中一个子公司,新成立的子公司包括京东金融、京东智能、京东到家、拍拍、海外事业部等。 各自业务范围不同,业务模式也不同,但不管什么业务总是需要客服服务。 如何复用原来为商城量身订做的咚咚客服系统并支持其他子公司业务快速接入成为我们新的课题。
最早要求接入的是拍拍网,它是从腾讯收购的,所以是完全不同的账户和订单交易体系。 由于时间紧迫,我们把为商城订做的部分剥离,基于 3.0 架构对接拍拍又单独订做了一套,并独立部署,像下面这样。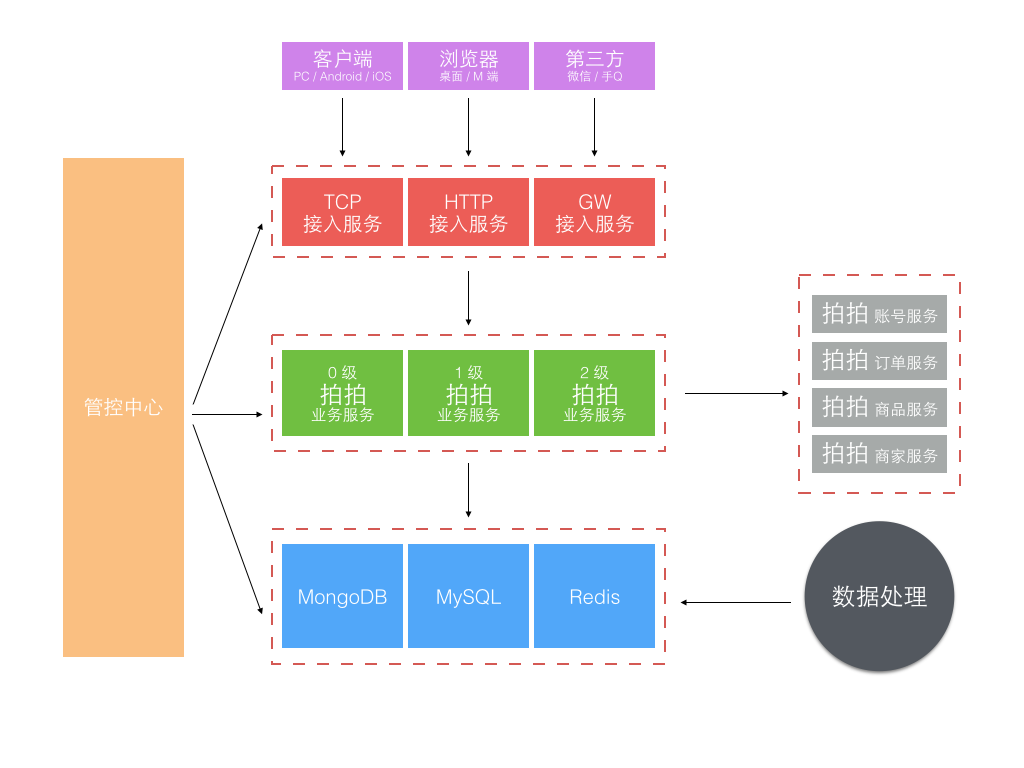
虽然在业务要求的时间点前完成了上线,但这样做也带来了明显的问题:
- 复制工程,定制业务开发,多套源码维护成本高
- 独立部署,至少双机房主备外加一个灰度集群,资源浪费大
以前我们都是面向业务去架构系统,如今新的业务变化形势下我们开始考虑面向平台去架构,在统一平台上跑多套业务,统一源码,统一部署,统一维护。 把业务服务继续拆分,剥离出最基础的 IM 服务,IM 通用服务,客服通用服务,而针对不同的业务特殊需求做最小化的定制服务开发。 部署方式则以平台形式部署,不同的业务方的服务跑在同一个平台上,但数据互相隔离。 服务继续被拆分的更微粒化,形成了一组服务矩阵(见下图)
而部署方式,只需要在双机房建立两套对等集群,并另外建一个较小的灰度发布集群即可,所有不同业务都运行在统一平台集群上,如下图: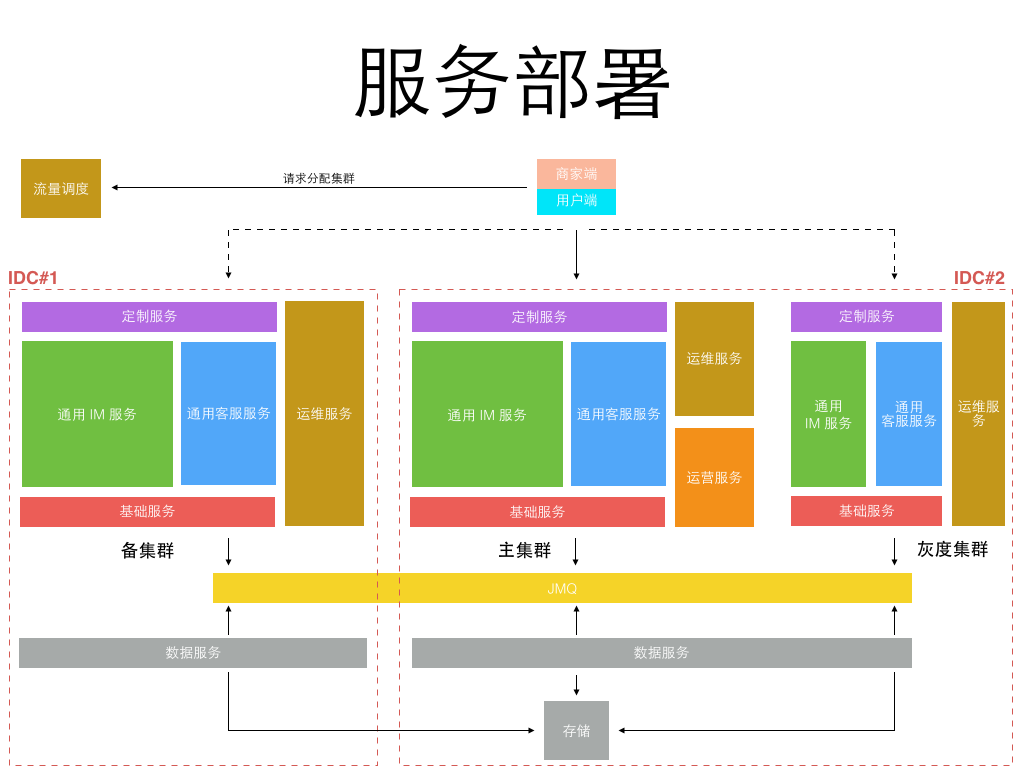
更细粒度的服务意味着每个服务的开发更简单,代码量更小,依赖更少,隔离稳定性更高。 但更细粒度的服务也意味着更繁琐的运维监控管理,直到今年公司内部弹性私有云、缓存云、消息队列、部署、监控、日志等基础系统日趋完善, 使得实施这类细粒度划分的微服务架构成为可能,运维成本可控。 而从当初 1.0 的 1 种应用进程,到 3.0 的 6、7 种应用进程,再到 4.0 的 50+ 更细粒度的不同种应用进程。 每种进程再根据承载业务流量不同分配不同的实例数,真正的实例进程数会过千。 为了更好的监控和管理这些进程,为此专门定制了一套面向服务的运维管理系统,见下图: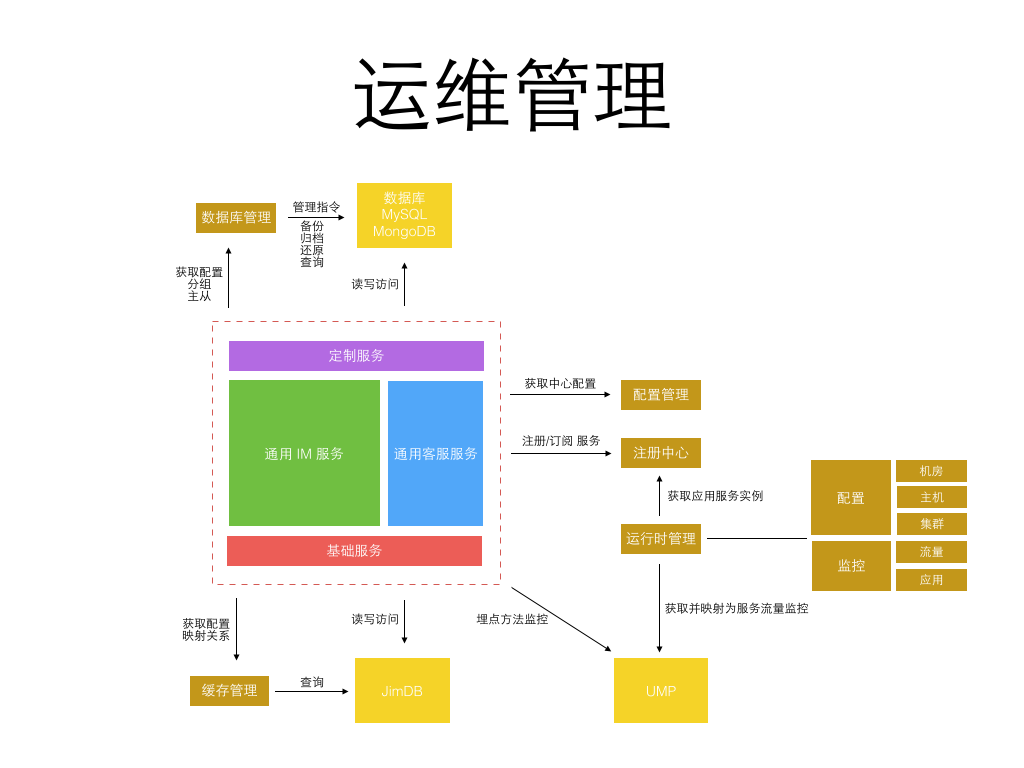
统一服务运维提供了实用的内部工具和库来帮助开发更健壮的微服务。 包括中心配置管理,流量埋点监控,数据库和缓存访问,运行时隔离,如下图所示是一个运行隔离的图示: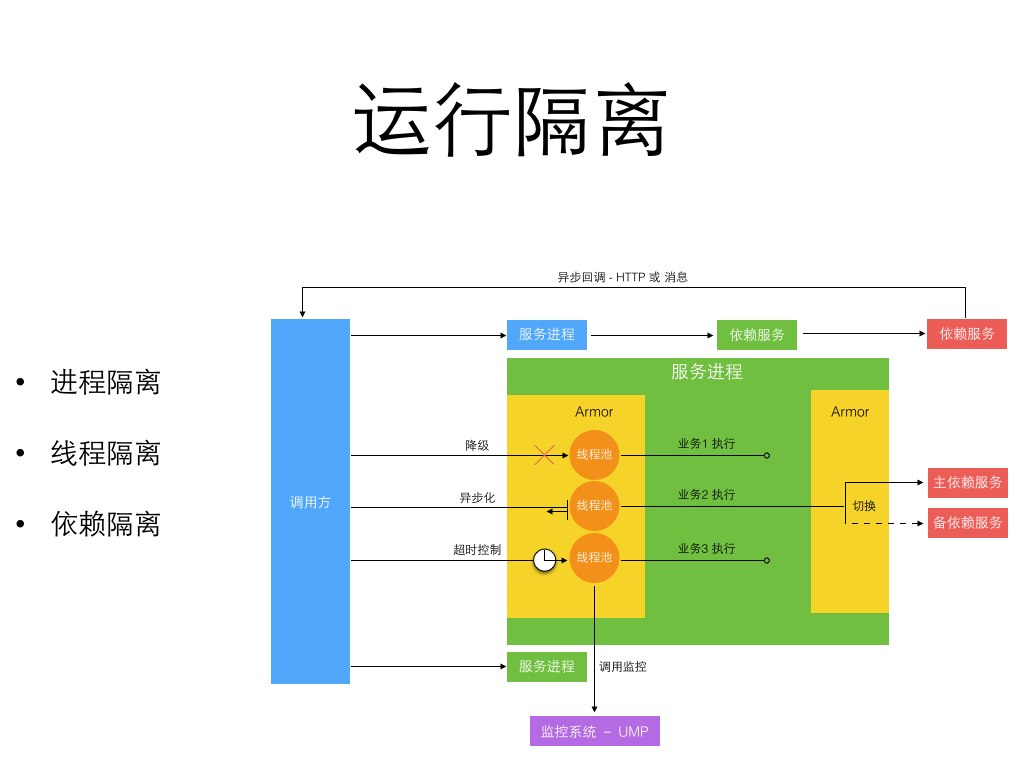
细粒度的微服务做到了进程间隔离,严格的开发规范和工具库帮助实现了异步消息和异步 HTTP 来避免多个跨进程的同步长调用链。 进程内部通过切面方式引入了服务增强容器 Armor 来隔离线程, 并支持进程内的单独业务降级和同步转异步化执行。而所有这些工具和库服务都是为了两个目标:
- 让服务进程运行时状态可见
- 让服务进程运行时状态可被管理和改变
最后我们回到前文留下的一个悬念,就是关于消息投递模型的缺陷。 一开始我们在接入层检测到终端连接断开后,消息无法投递,再将消息缓存下来,等终端重连接上来再拉取离线消息。 这个模型在移动时代表现的很不好,因为移动网络的不稳定性,导致经常断链后重连。 而准确的检测网络连接断开是依赖一个网络超时的,导致检测可能不准确,引发消息假投递成功。 新的模型如下图所示,它不再依赖准确的网络连接检测,投递前待确认消息 id 被缓存,而消息体被持久存储。 等到终端接收确认返回后,该消息才算投妥,未确认的消息 id 再重新登陆后或重连接后作为离线消息推送。 这个模型不会产生消息假投妥导致的丢失,但可能导致消息重复,只需由客户终端按消息 id 去重即可。
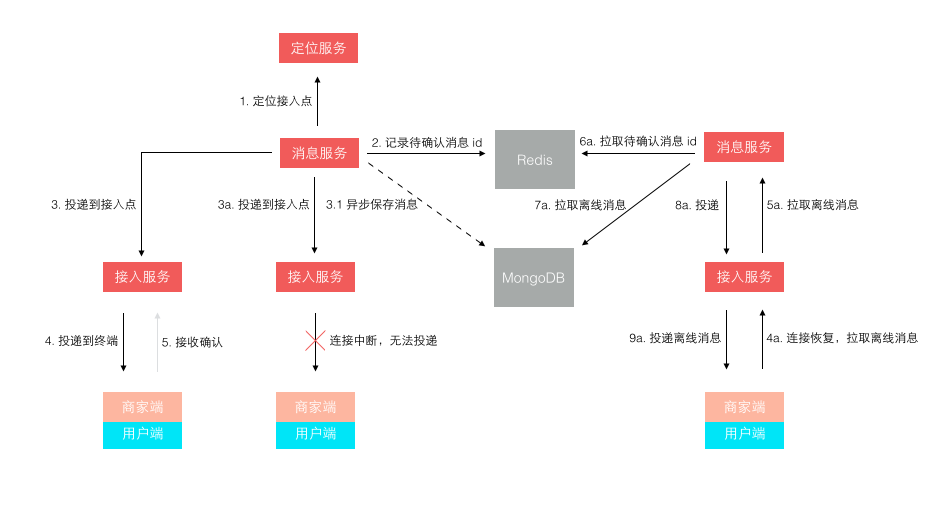
京东咚咚诞生之初正是京东技术转型到 Java 之时,经历这些年的发展,取得了很大的进步。 从草根走向专业,从弱小走向规模,从分散走向统一,从杂乱走向规范。 本文主要重心放在了几年来咚咚架构演进的过程,技术架构单独拿出来看我认为没有绝对的好与不好, 技术架构总是要放在彼时的背景下来看,要考虑业务的时效价值、团队的规模和能力、环境基础设施等等方面。 架构演进的生命周期适时匹配好业务的生命周期,才可能发挥最好的效果。
分享阅读原文:https://henduan.com/LWnMz
运维监控平台之Ganglia
Ganglia简介
Ganglia 是一款为 HPC(高性能计算)集群而设计的可扩展的分布式监控系统,它可以监视和显示集群中的节点的各种状态信息,它由运行在各个节点上的 gmond 守护进程来采集 CPU 、内存、硬盘利用率、 I/O 负载、网络流量情况等方面的数据,然后汇总到gmetad守护进程下,使用rrdtool 存储数据,最后将历史数据以曲线方式通过 PHP 页面呈现。
Ganglia 的特点如下:
- 良好的扩展性,分层架构设计能够适应大规模服务器集群的需要
- 负载开销低,支持高并发
- 广泛支持各种操作系统( UNIX 等)和 cpu 架构,支持虚拟
Ganglia 监控系统有三部分组成,分别是 gmond、 gmetad、 webfrontend,作用如下。Ganglia组成
- gmond: 即为 ganglia monitoring daemon,是一个守护进程,运行在每一个需要监测的节点上,用于收集本节点的信息并发送到其他节点,同时也接收其他节点发过了的数据,默认的监听端口为 8649。
- gmetad: 即为 ganglia meta daemon,是一个守护进程,运行在一个数据汇聚节点上,定期检查每个监测节点的 gmond 进程并从那里获取数据,然后将数据指标存储在本地 RRD 存储引擎中。
- webfrontend: 是一个基于 web 的图形化监控界面,需要和 Gmetad 安装在同一个节点上,它从 gmetad 取数据,并且读取 RRD 数据库,通过

Ganglia的安装
[root@centos02 tools]# wget wget [root@centos02 tools]# rpm -ivh epel-release-6-8.noarch.rpm [root@centos02 tools]# yum install ganglia-gmetad.x86_64 ganglia-gmond.x86_64 ganglia-gmond-python.x86_64 -y 修改服务端配置文件[root@centos02 tools]# vim /etc/ganglia/gmetad.conf data_source "my cluster" 172.16.80.117 172.16.80.116gridname "MyGrid" ganglia web的安装(基于LNMP环境)[root@centos02 tools]# tar xf ganglia-web-3.7.2.tar.gz [root@centos02 tools]# mv ganglia-web-3.7.2 /application/nginx/html/ganglia 修改ganglia web的php配置文件[root@centos02 tools]# vim /application/nginx/html/ganglia/conf_default.php$conf['gweb_confdir'] = "/application/nginx/html/ganglia"; nginx配置[root@centos02 ganglia]# cat /application/nginx/conf/nginx.confworker_processes 2;events { worker_connections 1024;}http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; server { listen 80; server_name www.martin.com martin.com; location / { root html/zabbix; index index.php index.html index.htm; } location ~ .*\.(php|php5)?$ { root html/zabbix; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; include fastcgi.conf; } access_log logs/access_zabbix.log main; } server { listen 80; server_name ganglia.martin.com; location / { root html/ganglia; index index.php index.html index.htm; } location ~ .*\.(php|php5)?$ { root html/ganglia; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; include fastcgi.conf; } access_log logs/access_bbs.log main; } ###status server{ listen 80; server_name status.martin.org; location / { stub_status on; access_log off; } } } 访问测试,报错如下Fatal error:Errors were detected in your configuration.DWOO compiled templates directory '/application/nginx/html/ganglia/dwoo/compiled' is not writeable.Please adjust $conf['dwoo_compiled_dir'].DWOO cache directory '/application/nginx/html/ganglia/dwoo/cache' is not writeable.Please adjust $conf['dwoo_cache_dir'].in /application/nginx-1.6.3/html/ganglia/eval_conf.php on line 126 解决办法:[root@centos02 tools]# mkdir /application/nginx/html/ganglia/dwoo/compiled[root@centos02 tools]# mkdir /application/nginx/html/ganglia/dwoo/cache [root@centos02 tools]# chmod 777 /application/nginx/html/ganglia/dwoo/compiled[root@centos02 tools]# chmod 777 /application/nginx/html/ganglia/dwoo/cache[root@centos02 html]# chmod -R 777 /var/lib/ganglia/rrds 修改客户端配置文件(所有的客户端都需要做)[root@centos02 tools]# vim /etc/ganglia/gmond.conf cluster { name = "my cluster" #这个名字要和服务器端定义的data_source后面的名字一样 owner = "unspecified" latlong = "unspecified" url = "unspecified"} udp_send_channel { #bind_hostname = yes # Highly recommended, soon to be default. # This option tells gmond to use a source address # that resolves to the machine's hostname. Without # this, the metrics may appear to come from any # interface and the DNS names associated with # those IPs will be used to create the RRDs.# mcast_join = 239.2.11.71 host = 172.16.80.117 #这里我们采用单播方式,默认是组播 port = 8649# ttl = 1} udp_recv_channel {# mcast_join = 239.2.11.71 port = 8649# bind = 239.2.11.71 retry_bind = true # Size of the UDP buffer. If you are handling lots of metrics you really # should bump it up to e.g. 10MB or even higher. # buffer = 10485760}
访问测试



默认安装完成的 Ganglia 仅向我们提供基础的系统监控信息,通过 Ganglia 插件可以实现两种扩展 Ganglia 监控功能的方法。 [list=1]扩展 Ganglia 监控功能的方法
在 Ganglia3.1.x 版本以后,增加了 C 或 Python 接口,通过这个接口可以自定义数据收集模块,并且可以将这些模块直接插入到 gmond 中以监控用户自定义的应用。
这里我们举例通过带外扩展的方式 来监控nginx的运行状态
配置 ganglia 客户端,收集 nginx_status 数据完成上面的所有步骤后,重启 Ganglia 客户端 gmond 服务,在客户端通过“ gmond–m”命令可以查看支持的模板,最后就可以在 Ganglia web 界面查看 Nginx 的运行状态
[root@centos02 nginx_status]# pwd
/tools/gmond_python_modules-master/nginx_status
[root@centos02 nginx_status]# cp conf.d/nginx_status.pyconf /etc/ganglia/conf.d/
[root@centos02 nginx_status]# cp python_modules/nginx_status.py /usr/lib64/ganglia/python_modules/
[root@centos02 nginx_status]# cp graph.d/nginx_* /application/nginx/html/ganglia/graph.d/
[root@centos02 mysql]# cat /etc/ganglia/conf.d/nginx_status.pyconf
#
modules {
module {
name = 'nginx_status'
language = 'python'
param status_url {
value = 'http://status.martin.org/'
}
param nginx_bin {
value = '/application/nginx/sbin/nginx'
}
param refresh_rate {
value = '15'
}
}
}
collection_group {
collect_once = yes
time_threshold = 20
metric {
name = 'nginx_server_version'
title = "Nginx Version"
}
}
collection_group {
collect_every = 10
time_threshold = 20
metric {
name = "nginx_active_connections"
title = "Total Active Connections"
value_threshold = 1.0
}
metric {
name = "nginx_accepts"
title = "Total Connections Accepted"
value_threshold = 1.0
}
metric {
name = "nginx_handled"
title = "Total Connections Handled"
value_threshold = 1.0
}
metric {
name = "nginx_requests"
title = "Total Requests"
value_threshold = 1.0
}
metric {
name = "nginx_reading"
title = "Connections Reading"
value_threshold = 1.0
}
metric {
name = "nginx_writing"
title = "Connections Writing"
value_threshold = 1.0
}
metric {
name = "nginx_waiting"
title = "Connections Waiting"
value_threshold = 1.0
}
}


阅读分享授权转载:http://huaxin.blog.51cto.com/903026/1841208 收起阅读 »
Python3中异常处理常用的三种方法
try:但是你并不知道"语句1至语句N"哪个会出现什么样的错误,但你还要做异常处理,且想把出现的异常打印出来,并不停止程序的运行,所以在"except ......"语句就起作用了。
语句1
语句2
.
.
语句N
except ........ :
do something .......
方法一:捕获所有异常
Python2如下:例子如下:
try:
语句1
语句2
.....
语句N
except Exception,e:
print Exception,":",e
Python3如下:
try:
语句1
语句2
.....
语句N
except Exception as e:
print(Exception, ":", e)
try:
a = 1
b = a
c = w
except Exception as e:
print(Exception, ":", e)
结果为:
: name 'w' is not defined
方法二:采用sys模块回溯最后的异常
sys.exc_info() 会返回一个3值元表,其中包含调用该命令时捕获的异常。
这个元表的内容为 (type, value, traceback) ,其中:
- type 从获取到的异常中得到类型名称,它是BaseException 的子类;
- value 是捕获到的异常实例;
- traceback 是一个 traceback 对象,下面会详述。
import systry: w = abs(-1) list.append(w)except: info = sys.exc_info() print(info[0], ":", info[1]) # 结果如下:sys.last_traceback 包含的内容与 sys.exc_info() 相同,但它主要用于调试,并不总是被定义。 三、采用traceback模块查看异常trackback 模块用来精确模仿 python3 解析器的 stack trace 行为。在程序中应该尽量使用这个模块。traceback.print_exc() 可以直接打印当前的异常。: descriptor 'append' requires a 'list' object but received a 'int'
import tracebacktry: raiseexcept: traceback.print_exc()traceback.print_tb() 用来打印上面提到的 trackback 对象。
import sys,tracebacktry: raiseexcept: t,v,tb = sys.exc_info() traceback.print_tb(tb)traceback.print_exception() 可以直接打印 sys.exc_info()提供的元表。
import sys,tracebacktry: raiseexcept: traceback.print_exception(*sys.exc_info())其实,下面两句是等价的:
- traceback.print_exc()
- traceback.print_exception(*sys.exc_info())
traceback 提供的参数可以将 print 的内容写入到文件中
import traceback参考:
try:
a=b
b=c
except:
f=open("log.txt",'a')
traceback.print_exc(file=f)
f.flush()
f.close()
https://docs.python.org/3/library/traceback.html?highlight=print_tb#traceback.print_exc
https://docs.python.org/3/tutorial/errors.html 收起阅读 »
FFMpeg和Zabbix暴露的漏洞
一、FFMpeg缓冲区溢出高危漏洞安全预警
FFMpeg发布新版本,修复了之前版本存在的高危漏洞,请您及时修补。
影响范围:
FFMpeg <=3.1.1,且使用了swf解析模块。
修复方案:
升级到版本FFMpeg 3.1.2
漏洞详情:
FFMpeg在解码swf文件时存在一个缓冲区溢出高危漏洞(CVE-2016-6671)。漏洞主要存在于在对swf文件进行raw解码时,计算解码后的数据大小存在错误,导致写入数据的大小超过申请内存空间的大小,造成缓冲区内存溢出。该漏洞在一定条件下能导致任意代码执行。
参考:http://seclists.org/oss-sec/2016/q3/271
二、zabbix的SQL注入高危漏洞
近日,zabbix被爆出两个高危SQL注入漏洞,zabbix的jsrpc的profileIdx2参数存在insert方式的SQL注入漏洞,攻击者无需授权登陆即可登陆zabbix管理系统,也可通过script等功能轻易直接获取zabbix服务器的操作系统权限。
影响范围:
攻击成本:低
危害程度:高
是否登陆:不需要
影响范围:2.2.x, 3.0.0-3.0.3。(其他版本未经测试)
漏洞测试:
在zabbix的访问地址后面加上如下url:
/jsrpc.php?sid=0bcd4ade648214dc&type=9&method=screen.get&tim输出结果,出现如下图黄色关键字表示漏洞存在:
estamp=1471403798083&mode=2&screenid=&groupid=&hostid=0&pageFile=hi
story.php&profileIdx=web.item.graph&profileIdx2=2'3297&updateProfil
e=true&screenitemid=&period=3600&stime=20160817050632&resourcetype=
17&itemids%5B23297%5D=23297&action=showlatest&filter=&filter_task=&
mark_color=1

补充:
- 以上为仅为漏洞验证测试方式。
- 攻击者可以通过进一步构造语句进行错误型sql注射,无需获取和破解加密的管理员密码。
- 有经验的攻击者可以直接通过获取admin的sessionid来根据结构算法构造sid,替换cookie直接以管理员身份登陆。
修复方案:升级到最新版吧,据说3.0.4版本已经修补,但是我发现并没有,所以如果你是nginx,可以在server段加下面试试,然后打开日志,看看有没有误判,这是临时暴力解决方案
if ($request_uri ~ ^(.+\.php)(.*)$) {
set $req $2;
}
if ($req ~* "union[+|(%20)]") {
return 503;
}
if ($req ~* "and[+|(%20)]") {
return 503;
}
if ($req ~* "select[+|(%20)]") {
return 503;
}漏洞详情:
zabbix jsrpc.php的profileIdx2参数和latest.php的toggle_ids参数均存在SQL注入,属于高危漏洞。在开启Guest或者无用户的情况下不需要登录即可实现注入(默认开启Guest,且Guest默认密码为空);未开启Guest和有用户的情况下则需要鉴权通过方可实现注入。攻击者可以完全获取数据库中信息,获取管理员身份,甚至控制服务器权限。更多详情见:http://seclists.org/fulldisclosure/2016/Aug/82 收起阅读 »
MySQL Server has gone away报错分析
一、MySQL 服务宕了
判断是否属于这个原因的方法很简单,执行以下命令,查看mysql的运行时长
$ mysql -uroot -p -e "show global status like 'uptime';"或者查看MySQL的报错日志,看看有没有重启的信息
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Uptime | 68928 |
+---------------+-------+
1 row in set (0.04 sec)
$ tail /var/log/mysql/error.log如果uptime数值很大,表明mysql服务运行了很久了。说明最近服务没有重启过。 如果日志没有相关信息,也说明mysql服务最近没有重启过,可以继续检查下面几项内容。
130101 22:22:30 InnoDB: Initializing buffer pool, size = 256.0M
130101 22:22:30 InnoDB: Completed initialization of buffer pool
130101 22:22:30 InnoDB: highest supported file format is Barracuda.
130101 22:22:30 InnoDB: 1.1.8 started; log sequence number 63444325509
130101 22:22:30 [Note] Server hostname (bind-address): '127.0.0.1'; port: 3306
130101 22:22:30 [Note] - '127.0.0.1' resolves to '127.0.0.1';
130101 22:22:30 [Note] Server socket created on IP: '127.0.0.1'.
130101 22:22:30 [Note] Event Scheduler: Loaded 0 events
130101 22:22:30 [Note] /usr/sbin/mysqld: ready for connections.
Version: '5.5.28-cll' socket: '/var/lib/mysql/mysql.sock' port: 3306 MySQL Community Server (GPL)
二、连接超时
如果程序使用的是长连接,则这种情况的可能性会比较大。 即,某个长连接很久没有新的请求发起,达到了server端的timeout,被server强行关闭。 此后再通过这个connection发起查询的时候,就会报错server has gone away
$ mysql -uroot -p -e "show global variables like '%timeout';"
+----------------------------+----------+
| Variable_name | Value |
+----------------------------+----------+
| connect_timeout | 30 |
| delayed_insert_timeout | 300 |
| innodb_lock_wait_timeout | 50 |
| innodb_rollback_on_timeout | OFF |
| interactive_timeout | 28800 |
| lock_wait_timeout | 31536000 |
| net_read_timeout | 30 |
| net_write_timeout | 60 |
| slave_net_timeout | 3600 |
| wait_timeout | 28800 |
+----------------------------+----------+
mysql> SET SESSION wait_timeout=5;
# Wait 10 seconds
mysql> SELECT NOW();
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
Connection id: 132361
Current database: *** NONE ***
+---------------------+
| NOW() |
+---------------------+
| 2013-01-02 11:31:15 |
+---------------------+
1 row in set (0.00 sec)
三、进程在server端被主动kill
这种情况和情况2相似,只是发起者是DBA或者其他job。发现有长时间的慢查询执行kill xxx导致。
$ mysql -uroot -p -e "show global status like 'com_kill'"
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_kill | 0 |
+---------------+-------+
四、Your SQL statement was too large.
当查询的结果集超过 max_allowed_packet 也会出现这样的报错。定位方法是打出相关报错的语句。 用select * into outfile 的方式导出到文件,查看文件大小是否超过max_allowed_packet ,如果超过则需要调整参数,或者优化语句。
mysql> show global variables like 'max_allowed_packet';英文原文:http://ronaldbradford.com/blog/sqlstatehy000-general-error-2006-mysql-server-has-gone-away-2013-01-02/ 收起阅读 »
+--------------------+---------+
| Variable_name | Value |
+--------------------+---------+
| max_allowed_packet | 1048576 |
+--------------------+---------+
1 row in set (0.00 sec)
# 修改参数:
mysql> set global max_allowed_packet=1024*1024*16;
mysql> show global variables like 'max_allowed_packet';
+--------------------+----------+
| Variable_name | Value |
+--------------------+----------+
| max_allowed_packet | 16777216 |
+--------------------+----------+
1 row in set (0.00 sec)





