Nacos注册中心的设计原理详解
前言
服务发现是一个古老的话题,当应用开始脱离单机运行和访问时,服务发现就诞生了。目前的网络架构是每个主机都有一个独立的 IP 地址,那么服务发现基本上都是通过某种方式获取到服务所部署的 IP 地址。DNS 协议是最早将一个网络名称翻译为网络 IP 的协议,在最初的架构选型中,DNS+LVS+Nginx 基本可以满足所有的 RESTful 服务的发现,此时服务的 IP 列表通常配置在 nginx 或者 LVS。后来出现了 RPC 服务,服务的上下线更加频繁,人们开始寻求一种能够支持动态上下线并且推送 IP 列表变化的注册中心产品。
互联网软件行业普遍热捧开源产品,因为开源产品代码透明、可以参与共建、有社区进行交流和学习,当然更重要的是它们是免费的。个人开发者或者中小型公司往往会将开源产品作为选型首选。Zookeeper 是一款经典的服务注册中心产品(虽然它最初的定位并不在于此),在很长一段时间里,它是国人在提起 RPC 服务注册中心时心里想到的唯一选择,这很大程度上与 Dubbo 在中国的普及程度有关。Consul 和 Eureka 都出现于 2014 年,Consul 在设计上把很多分布式服务治理上要用到的功能都包含在内,可以支持服务注册、健康检查、配置管理、Service Mesh 等。而 Eureka 则借着微服务概念的流行,与 SpringCloud 生态的深度结合,也获取了大量的用户。去年开源的 Nacos,则携带着阿里巴巴大规模服务生产经验,试图在服务注册和配置管理这个市场上,提供给用户一个新的选择。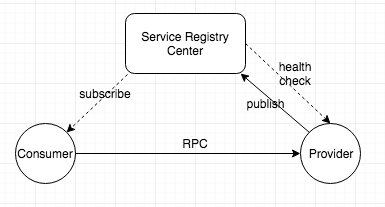
开源产品的一个优势是开发人员可以去阅读源代码,理解产品的功能设计和架构设计,同时也可以通过本地部署来测试性能,随之而来的是各种产品的对比文章。不过当前关于注册中心的对比,往往停留在表面的功能对比上,对架构或者性能并没有非常深入的探讨。
另一个现象是服务注册中心往往隐藏在服务框架背后,作为默默支持的产品。优秀的服务框架往往会支持多种配置中心,但是注册中心的选择依然强关联与服务框架,一种普遍的情况是一种服务框架会带一个默认的服务注册中心。这样虽然免去了用户在选型上的烦恼,但是单个注册中心的局限性,导致用户使用多个服务框架时,必须部署多套完全不同的注册中心,这些注册中心之间的数据协同也是一个问题。
本文从各个角度深度介绍 Nacos 注册中心的设计原理,并试图从我们的经验和调研中总结和阐述服务注册中心产品设计上应该去遵循和考虑的要点。由于作者水平有限,文中的错误还希望大家多多指正。
数据模型
注册中心的核心数据是服务的名字和它对应的网络地址,当服务注册了多个实例时,我们需要对不健康的实例进行过滤或者针对实例的一些特征进行流量的分配,那么就需要在实例上存储一些例如健康状态、权重等属性。随着服务规模的扩大,渐渐的又需要在整个服务级别设定一些权限规则、以及对所有实例都生效的一些开关,于是在服务级别又会设立一些属性。再往后,我们又发现单个服务的实例又会有划分为多个子集的需求,例如一个服务是多机房部署的,那么可能需要对每个机房的实例做不同的配置,这样又需要在服务和实例之间再设定一个数据级别。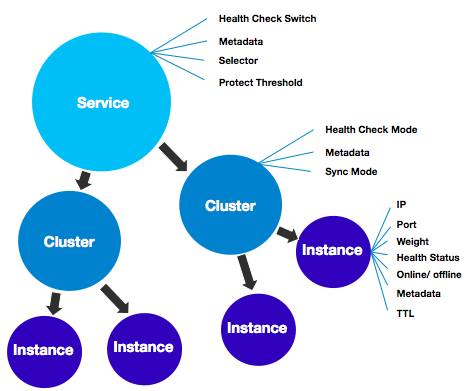
Nacos 的数据模型虽然相对复杂,但是它并不强制你使用它里面的所有数据,在大多数场景下,你可以选择忽略这些数据属。
另外一个需要考虑的是数据的隔离模型,作为一个共享服务型的组件,需要能够在多个用户或者业务方使用的情况下,保证数据的隔离和安全,这在稍微大一点的业务场景中非常常见。另一方面服务注册中心往往会支持云上部署,此时就要求服务注册中心的数据模型能够适配云上的通用模型。Nacos 一开始就考虑到如何让用户能够以多种维度进行数据隔离,同时能够平滑的迁移到阿里云上对应的商业化产品。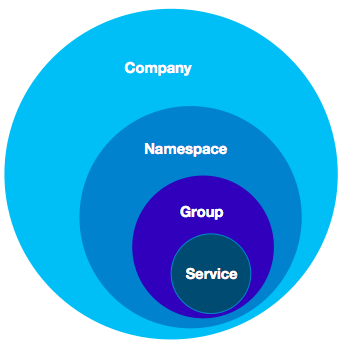
Nacos 提供了四层的数据逻辑隔离模型,用户账号对应的可能是一个企业或者独立的个体,这个数据一般情况下不会透传到服务注册中心。一个用户账号可以新建多个命名空间,每个命名空间对应一个客户端实例,这个命名空间对应的注册中心物理集群是可以根据规则进行路由的,这样可以让注册中心内部的升级和迁移对用户是无感知的,同时可以根据用户的级别,为用户提供不同服务级别的物理集群。再往下是服务分组和服务名组成的二维服务标识,可以满足接口级别的服务隔离。
Nacos 1.0.0 介绍的另外一个新特性是:临时实例和持久化实例。在定义上区分临时实例和持久化实例的关键是健康检查的方式。临时实例使用客户端上报模式,而持久化实例使用服务端反向探测模式。临时实例需要能够自动摘除不健康实例,而且无需持久化存储实例,那么这种实例就适用于类 Gossip 的协议。右边的持久化实例使用服务端探测的健康检查方式,因为客户端不会上报心跳,那么自然就不能去自动摘除下线的实例。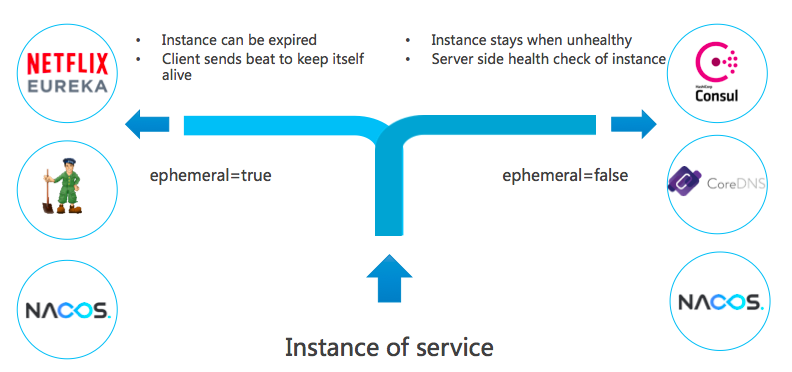
在大中型的公司里,这两种类型的服务往往都有。一些基础的组件例如数据库、缓存等,这些往往不能上报心跳,这种类型的服务在注册时,就需要作为持久化实例注册。而上层的业务服务,例如微服务或者 Dubbo 服务,服务的 Provider 端支持添加汇报心跳的逻辑,此时就可以使用动态服务的注册方式。
数据一致性
数据一致性是分布式系统永恒的话题,Paxos 协议的艰深更让数据一致性成为程序员大牛们吹水的常见话题。不过从协议层面上看,一致性的选型已经很长时间没有新的成员加入了。目前来看基本可以归为两家:一种是基于 Leader 的非对等部署的单点写一致性,一种是对等部署的多写一致性。当我们选用服务注册中心的时候,并没有一种协议能够覆盖所有场景,例如当注册的服务节点不会定时发送心跳到注册中心时,强一致协议看起来是唯一的选择,因为无法通过心跳来进行数据的补偿注册,第一次注册就必须保证数据不会丢失。而当客户端会定时发送心跳来汇报健康状态时,第一次的注册的成功率并不是非常关键(当然也很关键,只是相对来说我们容忍数据的少量写失败),因为后续还可以通过心跳再把数据补偿上来,此时 Paxos 协议的单点瓶颈就会不太划算了,这也是 Eureka 为什么不采用 Paxos 协议而采用自定义的 Renew 机制的原因。
这两种数据一致性协议有各自的使用场景,对服务注册的需求不同,就会导致使用不同的协议。Nacos 因为要支持多种服务类型的注册,并能够具有机房容灾、集群扩展等必不可少的能力,在 1.0.0 正式支持 AP 和 CP 两种一致性协议并存。1.0.0 重构了数据的读写和同步逻辑,将与业务相关的 CRUD 与底层的一致性同步逻辑进行了分层隔离。然后将业务的读写(主要是写,因为读会直接使用业务层的缓存)抽象为 Nacos 定义的数据类型,调用一致性服务进行数据同步。在决定使用 CP 还是 AP 一致性时,使用一个代理,通过可控制的规则进行转发。
目前的一致性协议实现,一个是基于简化的 Raft 的 CP 一致性,一个是基于自研协议 Distro 的 AP 一致性。Raft 协议不必多言,基于 Leader 进行写入,其 CP 也并不是严格的,只是能保证一半所见一致,以及数据的丢失概率较小。Distro 协议则是参考了内部 ConfigServer 和开源 Eureka,在不借助第三方存储的情况下,实现基本大同小异。Distro 重点是做了一些逻辑的优化和性能的调优。
负载均衡
负载均衡严格的来说,并不算是传统注册中心的功能。一般来说服务发现的完整流程应该是先从注册中心获取到服务的实例列表,然后再根据自身的需求,来选择其中的部分实例或者按照一定的流量分配机制来访问不同的服务提供者,因此注册中心本身一般不限定服务消费者的访问策略。
在阿里巴巴集团内部,却是使用的相反的思路。服务消费者往往并不关心所访问的服务提供者的负载均衡,它们只关心以最高效和正确的访问服务提供者的服务。而服务提供者,则非常关注自身被访问的流量的调配,这其中的第一个原因是,阿里巴巴集团内部服务访问流量巨大,稍有不慎就会导致流量异常压垮服务提供者的服务。因此服务提供者需要能够完全掌控服务的流量调配,并可以动态调整。
服务端的负载均衡,给服务提供者更强的流量控制权,但是无法满足不同的消费者希望使用不同负载均衡策略的需求。而不同负载均衡策略的场景,确实是存在的。而客户端的负载均衡则提供了这种灵活性,并对用户扩展提供更加友好的支持。但是客户端负载均衡策略如果配置不当,可能会导致服务提供者出现热点,或者压根就拿不到任何服务提供者。
抛开负载均衡到底是在服务提供者实现还是在服务消费者实现,我们看到目前的负载均衡有基于权重、服务提供者负载、响应时间、标签等策略。其中 Ribbon 设计的客户端负载均衡机制,主要是选择合适现有的 IRule、ServerListFilter 等接口实现,或者自己继承这些接口,实现自己的过滤逻辑。这里 Ribbon 采用的是两步负载均衡,第一步是先过滤掉不会采用的服务提供者实例,第二步是在过滤后的服务提供者实例里,实施负载均衡策略。Ribbon 内置的几种负载均衡策略功能还是比较强大的,同时又因为允许用户去扩展,这可以说是一种比较好的设计。
基于标签的负载均衡策略可以做到非常灵活,Kubernetes 和 Fabio 都已经将标签运用到了对资源的过滤中,使用标签几乎可以实现任意比例和权重的服务流量调配。但是标签本身需要单独的存储以及读写功能,不管是放在注册中心本身或者对接第三方的 CMDB。
在 Nacos 0.7.0 版本中,我们除了提供基于健康检查和权重的负载均衡方式外,还新提供了基于第三方 CMDB 的标签负载均衡器,具体可以参考 CMDB 功能介绍文章。使用基于标签的负载均衡器,目前可以实现同标签优先访问的流量调度策略,实际的应用场景中,可以用来实现服务的就近访问,当您的服务部署在多个地域时,这非常有用。使用这个标签负载均衡器,可以支持非常多的场景,这不是本文要详细介绍的。虽然目前 Nacos 里支持的标签表达式并不丰富,不过我们会逐步扩展它支持的语法。除此以外,Nacos 定义了 Selector,作为负载均衡的统一抽象。关于 Selector,由于篇幅关系,我们会有单独的文章进行介绍。
理想的负载均衡实现应该是什么样的呢?不同的人会有不同的答案。Nacos 试图做的是将服务端负载均衡与客户端负载均衡通过某种机制结合起来,提供用户扩展性,并给予用户充分的自主选择权和轻便的使用方式。负载均衡是一个很大的话题,当我们在关注注册中心提供的负载均衡策略时,需要注意该注册中心是否有我需要的负载均衡方式,使用方式是否复杂。如果没有,那么是否允许我方便的扩展来实现我需求的负载均衡策略。
健康检查
Zookeeper 和 Eureka 都实现了一种 TTL 的机制,就是如果客户端在一定时间内没有向注册中心发送心跳,则会将这个客户端摘除。Eureka 做的更好的一点在于它允许在注册服务的时候,自定义检查自身状态的健康检查方法。这在服务实例能够保持心跳上报的场景下,是一种比较好的体验,在 Dubbo 和 SpringCloud 这两大体系内,也被培养成用户心智上的默认行为。Nacos 也支持这种 TTL 机制,不过这与 ConfigServer 在阿里巴巴内部的机制又有一些区别。Nacos 目前支持临时实例使用心跳上报方式维持活性,发送心跳的周期默认是 5 秒,Nacos 服务端会在 15 秒没收到心跳后将实例设置为不健康,在 30 秒没收到心跳时将这个临时实例摘除。
不过正如前文所说,有一些服务无法上报心跳,但是可以提供一个检测接口,由外部去探测。这样的服务也是广泛存在的,而且以我们的经验,这些服务对服务发现和负载均衡的需求同样强烈。服务端健康检查最常见的方式是 TCP 端口探测和 HTTP 接口返回码探测,这两种探测方式因为其协议的通用性可以支持绝大多数的健康检查场景。在其他一些特殊的场景中,可能还需要执行特殊的接口才能判断服务是否可用。例如部署了数据库的主备,数据库的主备可能会在某些情况下切换,需要通过服务名对外提供访问,保证当前访问的库是主库。此时的健康检查接口,可能就是一个检查数据库是否是主库的 MYSQL 命令了。
客户端健康检查和服务端健康检查有一些不同的关注点。客户端健康检查主要关注客户端上报心跳的方式、服务端摘除不健康客户端的机制。而服务端健康检查,则关注探测客户端的方式、灵敏度及设置客户端健康状态的机制。从实现复杂性来说,服务端探测肯定是要更加复杂的,因为需要服务端根据注册服务配置的健康检查方式,去执行相应的接口,判断相应的返回结果,并做好重试机制和线程池的管理。这与客户端探测,只需要等待心跳,然后刷新 TTL 是不一样的。同时服务端健康检查无法摘除不健康实例,这意味着只要注册过的服务实例,如果不调用接口主动注销,这些服务实例都需要去维持健康检查的探测任务,而客户端则可以随时摘除不健康实例,减轻服务端的压力。
Nacos 既支持客户端的健康检查,也支持服务端的健康检查,同一个服务可以切换健康检查模式。我们认为这种健康检查方式的多样性非常重要,这样可以支持各种类型的服务,让这些服务都可以使用到 Nacos 的负载均衡能力。Nacos 下一步要做的是实现健康检查方式的用户扩展机制,不管是服务端探测还是客户端探测。这样可以支持用户传入一条业务语义的请求,然后由 Nacos 去执行,做到健康检查的定制。
性能与容量
虽然大部分用户用到的性能不高,但是他们仍然希望选用的产品的性能越高越好。影响读写性能的因素很多:一致性协议、机器的配置、集群的规模、存量数据的规模、数据结构及读写逻辑的设计等等。在服务发现的场景中,我们认为读写性能都是非常关键的,但是并非性能越高就越好,因为追求性能往往需要其他方面做出牺牲。
在对容量的评估时,不仅要针对企业现有的服务规模进行评估,也要对未来 3 到 5 年的扩展规模进行预测。阿里巴巴的中间件在内部支撑着集团百万级别服务实例,在容量上遇到的挑战可以说不会小于任何互联网公司。这个容量不仅仅意味着整体注册的实例数,也同时包含单个服务的实例数、整体的订阅者的数目以及查询的 QPS 等。阿里巴巴之所以字研 Nacos,容量是一个非常重要的因素。
Nacos 在开源版本中,服务实例注册的支撑量约为 100 万,服务的数量可以达到 10 万以上。在实际的部署环境中,这个数字还会因为机器、网络的配置与 JVM 参数的不同,可能会有所差别。图 9 展示了 Nacos 在使用 1.0.0 版本进行压力测试后的结果总结,针对容量、并发、扩展性和延时等进行了测试和统计。
完整的测试报告可以参考 Nacos 官网:
https://nacos.io/en-us/docs/nacos-naming-benchmark.html
https://nacos.io/en-us/docs/nacos-config-benchmark.html
易用性
易用性也是用户比较关注的一块内容。产品虽然可以在功能特性或者性能上做到非常先进,但是如果用户的使用成本极高,也会让用户望而却步。易用性包括多方面的工作,例如 API 和客户端的接入是否简单,文档是否齐全易懂,控制台界面是否完善等。对于开源产品来说,还有一块是社区是否活跃。
Nacos 提供了官方的控制台来查询服务注册情况,且目前依然在建设中,除了目前支持的易用性特性以外,后续还会继续增强控制台的能力,增加控制台登录和权限的管控,监控体系和 Metrics 的暴露,持续通过官网等渠道完善使用文档,多语言 SDK 的开发等。
集群扩展性
集群扩展性和集群容量以及读写性能关系紧密。当使用一个比较小的集群规模就可以支撑远高于现有数量的服务注册及访问时,集群的扩展能力暂时就不会那么重要。
集群扩展性的另一个方面是多地域部署和容灾的支持。当讲究集群的高可用和稳定性以及网络上的跨地域延迟要求能够在每个地域都部署集群的时候,我们现有的方案有多机房容灾、异地多活、多数据中心等。
Nacos 支持两种模式的部署,一种是和 Eureka 一样的 AP 协议的部署,这种模式只支持临时实例,并支持机房容灾。另一种是支持持久化实例的 CP 模式,这种情况下不支持双机房容灾。
在谈到异地多活时,很巧的是,很多业务组件的异地多活正是依靠服务注册中心和配置中心来实现的,这其中包含流量的调度和集群的访问规则的修改等。机房容灾是异地多活的一部分,但是要让业务能够在访问服务注册中心时,动态调整访问的集群节点,这需要第三方的组件来做路由。异地多活往往是一个包含所有产品线的总体方案,很难说单个产品是否支持异地多活。
多数据中心其实也算是异地多活的一部分。Nacos 基于阿里巴巴内部的使用经验,提供的解决方案是才有 Nacos-Sync 组件来做数据中心之间的数据同步,这意味着每个数据中心的 Nacos 集群都会有多个数据中心的全量数据。Nacos-Sync 是 Nacos 生态组件里的重要一环,不仅会承担 Nacos 集群与 Nacos 集群之间的数据同步,也会承担 Nacos 集群与 Eureka、Zookeeper、Kubernetes 及 Consul 之间的数据同步。
用户扩展性
在框架的设计中,扩展性是一个重要的设计原则。Spring、Dubbo、Ribbon 等框架都在用户扩展性上做了比较好的设计。这些框架的扩展性往往由面向接口及动态类加载等技术,来运行用户扩展约定的接口,实现用户自定义的逻辑。在 Server 的设计中,用户扩展是比较审慎的。因为用户扩展代码的引入,可能会影响原有 Server 服务的可用性,同时如果出问题,排查的难度也是比较大的。设计良好的 SPI 是可能的,但是由此带来的稳定性和运维的风险是需要仔细考虑的。在开源软件中,往往通过直接贡献代码的方式来实现用户扩展,好的扩展会被很多人不停的更新和维护,这也是一种比较好的开发模式。
那么这样的扩展性是否是有必要的呢?举一个上文提到过的例子,假如要添加一种新的健康检查方式,连接数据库执行一条 MySQL 命令,通常的方式是在代码里增加 MySQL 类型的健康检查方法、构建、测试然后最终发布。但是如果允许用户上传一个 jar 包放到 Server 部署目录下的某个位置,Server 就会自动扫描并识别到这张新的健康检查方式呢?这样不仅更酷,也让整个扩展的流程与 Server 的代码解耦,变得非常简单。所以对于系统的一些功能,如果能够通过精心的设计开放给用户在运行时去扩展,那么为什么不做呢?毕竟增加扩展的支持并不会让原有的功能有任何损失。
所有产品都应该尽量支持用户运行时扩展,这需要 Server 端 SPI 机制设计的足够健壮和容错。Nacos 在这方面已经开放了对第三方 CMDB 的扩展支持,后续很快会开放健康检查及负载均衡等核心功能的用户扩展。目的就是为了能够以一种解耦的方式支持用户各种各样的需求。
尾声
本文并不是一篇介绍 Nacos 功能的文章,因此 Nacos 的一些特色功能并没有在文中涉及,这些特色功能其实也是 Nacos 区别与其他注册中心的重要方面,包括 Nacos 支持的 DNS 协议,打自定义标等能力。
Nacos 已经在 4 月 10 号发布 GA 版本,后续将会以和社区共建的方式,持续输出新的功能,在服务发现和配置管理这两大领域继续深耕,期待与大家一起建设出最好用的服务发现和配置管理平台。
作者简介: 朱鹏飞,Github ID: nkorange,Nacos 注册中心等模块主要贡献者,阿里巴巴中间件高级开发工程师
分享阅读原文: https://henduan.com/K3lIt
Go交叉编译的那些事
最近两个月,一直在搞项目的国产化移植,把golang开发好的程序,运行在国产化平台上,操作系统基本都是基于Linux,但是CPU架构除了x86,还有ARM和MIPS,我们平时的Golang都是运行于x86 && x64 架构的CPU上,因此移植过程中遇到了好多坑,记录于此。
Golang交叉编译
交叉编译
在X64上的ubuntu 16.04系统上编译出其他平台的可执行程序, 查看Golang支持的平台和版本:
go tool dist list
此命令会列出所有go语言支持的操作系统和cpu架构
aix/ppc64
android/386
android/amd64
android/arm
android/arm64
darwin/amd64
darwin/arm64
dragonfly/amd64
freebsd/386
freebsd/amd64
freebsd/arm
freebsd/arm64
illumos/amd64
js/wasm
linux/386
linux/amd64
linux/arm
linux/arm64
linux/mips
linux/mips64
linux/mips64le
linux/mipsle
linux/ppc64
linux/ppc64le
linux/riscv64
linux/s390x
netbsd/386
netbsd/amd64
netbsd/arm
netbsd/arm64
openbsd/386
openbsd/amd64
openbsd/arm
openbsd/arm64
plan9/386
plan9/amd64
plan9/arm
solaris/amd64
windows/386
windows/amd64
windows/arm
其实go的交叉编译非常简单,只需要在编译前指定系统和CPU架构,基本不会有任何问题,编译出来将文件拷贝到对应平台就能跑:
GOOS=linux GOARCH=arm64 go build xxx.go
# 有时候需要加上CGO_ENABLE=0
CGO_ENABLE=0 GOOS=linux GOARCH=arm64 go build xxx.go
go语言的交叉编译支持非常好,只要按照上述步骤基本不会出什么问题。坑,主要就坑在cgo, CGO_ENABLED=0 关闭cgo。
采用cgo的交叉编译
使用cgo,就必须指定CGO_ENABLE=1。并且必须指定CC参数为对应架构的gcc的交叉编译器。
假设我们编译64位ARM平台的程序,就要提前下载aarch64版本的c++交叉编译工具
CGO_ENABLED=1 GOOS=linux GOARCH=arm64 CC=./aarch64-unknown-linux-gnueabi-5.4.0-2.23-4.4.6/bin/aarch64-unknown-linux-gnueabi-gcc go build xxx.go
如果调用的CGO调用的C程序中依赖各种库,那么这个编译过程会报错各种依赖的库not found,各种基本的函数未定义。而且都是系统中最基本的库如libglibc、libgstream等。
解决方案是必须在编译时,加上链接库的参数,而链接的库必须是交叉编译出的目标平台的系统库而不是当前系统的。
这个在下载交叉编译工具链的时候,一般都会附带,我这里放到系统根目录下,然后通过C++编译时链接库的语法将库链接进去:
主要是三个参数:-I , -isystem , -L, -l
下面命令是个例子,假设项目中用到了phnono、curl、protobuf等组件:
CGO_ENABLED=1 GOOS=linux GOARCH=arm64 CC=./aarch64-unknown-linux-gnueabi-5.4.0-2.23-4.4.6/bin/aarch64-unknown-linux-gnueabi-gcc -Wall -std=c++11 -Llib -isystem/aarch64/usr/include -L/aarch64/lib -ldl -lpthread -Wl,-rpath-link,/aarch64/lib -L/aarch64/lib/aarch64-linux-gnu -L/aarch64/usr/lib -I/aarch64/usr/include -L/aarch64/usr/lib/aarch64-linux-gnu -ldl -lpthread -Wl,-rpath-link,/aarch64/usr/lib/aarch64-linux-gnu -lphonon -lcurl -lprotobuf go build xxx.go
到这一步,就基本解决了无法编译的坑。
平台差异的问题
在编译ARM版本的代码时,报错好几个系统调用找不到:
- undefined: syscall.Dup2
- undefined: syscall.SYS_FORK
解决方案:对比golang源码实现:go/src/syscall/zsyscall_linux_amd64.go和go/src/syscall/zsyscall_linux_arm64.go,发现arm平台未实现Dup2但是提供了Dup3,参数略有差异,解决办法是修改调用的地方:
// - syscall.Dup2(oldfd, newfd) 修改为:
syscall.Dup3(oldfd,newfd,0)
而SYS_FORK的调用,查找之下发现golang的ARM实现根本没有实现fork的系统调用,没有SYS_FORK这个宏或替代品。
无奈只能修改项目代码,将fork的系统调用改为别的方式实现。
MIPS的大小端问题
报错:go.o: compiled for a big endian system and target is little endian
主要体现在大小端字节序的问题,这是我在交叉编译Mips版本发现的一个问题,仔细查看了我的编译命令发现:
CGO_ENABLED=1 GOOS=linux GOARCH=mips64 CC=./mips64el-unknown-linux-gnu-5.4.0-2.12-2.6.32/bin/mips64el-unknown-linux-gnu-gcc go build xxx.go
这里的命令中:CC指定的是mips64el的编译器,el代表小端字节序,而GOARCH=mips64这是大端字节序,前后不一致导致编译的报错,
解决方案:go和gcc保持统一、以目标平台为准(龙芯是小端字节序)
- 将GOARCH指定为mips64le(注意是le不是el)
- 最好加上LDFLAG=-EL
CGO_ENABLED=1 GOOS=linux GOARCH=mips64le CC=./mips64el-unknown-linux-gnu-5.4.0-2.12-2.6.32/bin/mips64el-unknown-linux-gnu-gcc LDFLAGS=-EL go build xxx.go
总结经验:
1. golang程序开发少用原生的系统调用syscall
2. 能用go解决的,尽可能不要用cgo
3. 如果有模块必须通过C/C++调用,推荐C++和golang分离,C++和Golang程序间使用socket等方式进行进程间通信
分享阅读原文:https://henduan.com/wNyCI
收起阅读 »Elasticsearch启动常见问题
启动内存问题
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error='Cannot allocate memory' (errno=12)
分析: 默认分配的JVM内存为2g,所以当小内存的机器,默认启动的话,会报如上错误。
解决: 修改Eleasticsearch启动JVM内存参数, 修改文件: config/jvm.options
-Xms2g
-Xmx2g
修改为
-Xms1g
-Xmx1g
对于内存较低的云主机和虚拟机,你要测试Elasticsearch的基本功能,没有太大性能要求的话,这时候就需要修改启动内存。
启动用户问题
don't run elasticsearch as root
分析: 程序设计者,出于系统安全考虑设置的条件, 由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,如果获取root权限了,那问题就打了,所以默认官方是建议创建一个单独的用户用来运行ElasticSearch。
解决:添加单独的用户运行
groupadd es
useradd es -g es
更改elasticsearch文件夹及内部文件的所属用户及组为es:es
chown -R es:es elasticsearch
切换到es用户启动:
su - es
./bin/elasticsearch -d
# 或者root下
su es -c "/opt/elasticsearch/bin/elasticsearch -d"
Tips: ES5版本之前,还可以修改
ES_JAVA_OPTS启动参数,加上-Des.insecure.allow.root=true可以使用root启动,但是不推荐这么玩。
最大虚拟内存区域问题
max virtual memory areas vm.max_map_count [256000] is too low, increase to at least [262144]
什么是VMA(virtual memory areas):
This file contains the maximum number of memory map areas a process may have. Memory map areas are used as a side-effect of calling malloc, directly by mmap and mprotect, and also when loading shared libraries.
While most applications need less than a thousand maps, certain programs, particularly malloc debuggers, may consume lots of them, e.g., up to one or two maps per allocation.
The default value is 65536
max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
解决:
# 临时设置
sysctl -w vm.max_map_count=262144
# 永久设置
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
虚拟内存最大大小问题
max size virtual memory [67108864] for user [es] is too low, increase to [unlimited]
分析:引用官网的说法
The segment files that are the components of individual shards and the translog generations that are components of the translog can get large (exceeding multiple gigabytes). On systems where the max size of files that can be created by the Elasticsearch process is limited, this can lead to failed writes. Therefore, the safest option here is that the max file size is unlimited and that is what the max file size bootstrap check enforces. To pass the max file check, you must configure your system to allow the Elasticsearch process the ability to write files of unlimited size.
解决:
echo "* - as unlimited" >> /etc/security/limits.conf
echo "root - as unlimited" >> /etc/security/limits.conf
参考: https://stackoverflow.com/questions/42510873/vm-max-map-count-is-too-low
最大文件描述符问题
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
分析:elasticsearch启动bootstrap checks要求系统打开最大系统文件描述符为65536
解决:
# 临时 ulimit -f unlimited
echo "* soft nofile 65536" >> /etc/security/limits.conf
echo "* hard nofile 65536" >> /etc/security/limits.conf
确认:
ulimit -Hn
ulimit -Sn
最大线程数问题
max number of threads [3818] for user [es] is too low, increase to at least [4096]
分析:elasticsearch启动bootstrap checks要求打开最大线程数最低为4096
解决:
echo "* soft nproc 65535" >> /etc/security/limits.conf
echo "* hard nproc 65535" >> /etc/security/limits.conf
注意:修改这里,普通用户
max user process值是不生效的,需要修改/etc/security/limits.d/20-nproc.conf文件中的值。Centos6系统的是是90-nproc.conf文件。
修改 /etc/security/limits.d/20-nproc.conf
* soft nproc 65535
系统总限制
其实上面的 max user processes 65535 的值也只是表象,普通用户最大进程数无法达到65535 ,因为用户的max user processes的值,最后是受全局的kernel.pid_max的值限制。
也就是说kernel.pid_max=1024 ,那么你用户的max user processes的值是65535 ,用户能打开的最大进程数还是1024。
# 临时生效
echo 65535 > /proc/sys/kernel/pid_max
sysctl -w kernel.pid_max=65535
# 永久生效
echo "kernel.pid_max = 65535" >> /etc/sysctl.conf
sysctl -p
然后重启机器生效。
参考: https://www.cnblogs.com/xidianzxm/p/11820706.html
确认:
ulimit -Hu
ulimit -Su
运行目录权限问题
Exception in thread "main" java.nio.file.AccessDeniedException: /opt/elasticsearch-6.2.2-1/config/jvm.options
分析: es用户没有该文件夹的权限
解决:
chown es.es /opt/elasticsearch-6.2.2-1 -R
如果还有碰到其他问题的同学,可以留言补充。
收起阅读 »各大行业龙头股合理买入价格?
各大行业龙头股合理买入价格!昨天反弹,今天回调,再强调一次!
腾讯控股:550 ,极限500
贵州茅台:1600,比较安全,1800反弹
五粮液:160,非常安全
万科A: 现价分批
海天味业:135,确定性较高企业
宁德时代:250
恒瑞医药:85
泰格医药:105
药明康德:105
中国中免:225-230
迈瑞医疗:300-320
通策医疗:160
晨光文具:60
长春高新:380
东方财富:23
山西汾酒:160(波动非常大,
200会到,能到160就满分)
阳光电源:60
伊利股份:35
隆基股份:80(这股补跌
,需要调整,高于高瓴买入价格)
东方雨虹:40
美的集团:70
长江电力:18
比亚迪:160(这个都快到了,极限120,看着分批建仓就好,新能源产业链看整体走势,不纯看估值)
爱尔眼科:50(一直高估值)
恒立液压:65(涨了10倍,也该回归合理估值)
欧普康视:60
海尔智家:22
科沃斯:80
凯莱英:200以内,能到180就满分
三一重工:30
恒力石化:25
荣盛石化:23
同花顺:100,极限80
立讯精密:40内再看
平安银行:20内分批
招商银行:45内分批
作者:常春藤投资
链接原文: https://henduan.com/Rthe7
来源:雪球
修改MySQL5.7.31用户登录密码
默认一般安装完成MySQL数据库root用户的密码为空,一般需要设置好root的密码,要不会造成不安全的情况发生。然而登录MySQL数据库后发现5.7版本跟5.6版本User表结构发生了变化,原本的password字段没有了,这就导致在5.7下面修改用户密码的方式跟之前的版本不同,下面会介绍2种修改方式。
1. 使用set password语句
这种方法跟以前的版本修改密码是一致的,需要登录到MySQL后使用:
set password for root@localhost = password("123.com");
2. 直接更新user表
由于MySQL版本的升级,User表的结构改变了,好多网上使用的UPDATE语句不适用新版本的表结构,在这里我通过DESC语句来查看User表的结构,结果如图:
mysql> desc User;
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Host | char(60) | NO | PRI | | |
| User | char(32) | NO | PRI | | |
| Select_priv | enum('N','Y') | NO | | N | |
| Insert_priv | enum('N','Y') | NO | | N | |
| Update_priv | enum('N','Y') | NO | | N | |
| Delete_priv | enum('N','Y') | NO | | N | |
| Create_priv | enum('N','Y') | NO | | N | |
| Drop_priv | enum('N','Y') | NO | | N | |
| Reload_priv | enum('N','Y') | NO | | N | |
| Shutdown_priv | enum('N','Y') | NO | | N | |
| Process_priv | enum('N','Y') | NO | | N | |
| File_priv | enum('N','Y') | NO | | N | |
| Grant_priv | enum('N','Y') | NO | | N | |
| References_priv | enum('N','Y') | NO | | N | |
| Index_priv | enum('N','Y') | NO | | N | |
| Alter_priv | enum('N','Y') | NO | | N | |
| Show_db_priv | enum('N','Y') | NO | | N | |
| Super_priv | enum('N','Y') | NO | | N | |
| Create_tmp_table_priv | enum('N','Y') | NO | | N | |
| Lock_tables_priv | enum('N','Y') | NO | | N | |
| Execute_priv | enum('N','Y') | NO | | N | |
| Repl_slave_priv | enum('N','Y') | NO | | N | |
| Repl_client_priv | enum('N','Y') | NO | | N | |
| Create_view_priv | enum('N','Y') | NO | | N | |
| Show_view_priv | enum('N','Y') | NO | | N | |
| Create_routine_priv | enum('N','Y') | NO | | N | |
| Alter_routine_priv | enum('N','Y') | NO | | N | |
| Create_user_priv | enum('N','Y') | NO | | N | |
| Event_priv | enum('N','Y') | NO | | N | |
| Trigger_priv | enum('N','Y') | NO | | N | |
| Create_tablespace_priv | enum('N','Y') | NO | | N | |
| ssl_type | enum('','ANY','X509','SPECIFIED') | NO | | | |
| ssl_cipher | blob | NO | | NULL | |
| x509_issuer | blob | NO | | NULL | |
| x509_subject | blob | NO | | NULL | |
| max_questions | int(11) unsigned | NO | | 0 | |
| max_updates | int(11) unsigned | NO | | 0 | |
| max_connections | int(11) unsigned | NO | | 0 | |
| max_user_connections | int(11) unsigned | NO | | 0 | |
| plugin | char(64) | NO | | mysql_native_password | |
| authentication_string | text | YES | | NULL | |
| password_expired | enum('N','Y') | NO | | N | |
| password_last_changed | timestamp | YES | | NULL | |
| password_lifetime | smallint(5) unsigned | YES | | NULL | |
| account_locked | enum('N','Y') | NO | | N | |
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
45 rows in set (0.00 sec)
如上发现了一些疑似用来认证的字段,根据字段类型推断authentication_string应该是存储的用户密码,之后就开始尝试修改这一字段:
update user set authentication_string = password('123.com') where user='root' and host='localhost';
更改后退出发现依然不会生效,通过查阅资料发现,还需要把plugin字段的值改为mysql_native_password。个人感觉这个字段影响的是验证方式,更改之后就可以在登录的时候使用刚刚设置的密码来验证。修改语句如下:
update user set plugin = 'mysql_native_password' where user='root' and host='localhost';
后来了解到mysql_native_password和caching_sha2_password是MySQL的两种加密认证方式,一般MySQL 5默认使用前者,而8以后的版本使用后者,在这里虽然笔者使用的是5.7.31,但我确实是在更改了这个字段值以后才能正常用密码登录的。
unzip 6.0编译安装
下载安装包
wget https://downloads.sourceforge.net/infozip/unzip60.tar.gz
wget http://www.linuxfromscratch.org/patches/blfs/svn/unzip-6.0-consolidated_fixes-1.patch
打patch
tar xf unzip60.tar.gz
cd unzip60
patch -Np1 -i ../unzip-6.0-consolidated_fixes-1.patch
编译安装
make -f unix/Makefile generic
make prefix=/opt/unzip MANDIR=/usr/share/man/man1 -f unix/Makefile install
参考: http://www.linuxfromscratch.org/blfs/view/svn/general/unzip.html
收起阅读 »银河麒麟4.0.2 SP3系统可执行文件报权限不够
现象
root@Kylin:~# cat aa.sh
echo 1
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# ls -l aa.sh
-rw-r--r-- 1 root root 7 2月 1 10:14 aa.sh
root@Kylin:~# chmod +x aa.sh
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# cat aa.sh
echo 1
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# ls -l aa.sh
-rw-r--r-- 1 root root 7 2月 1 10:14 aa.sh
root@Kylin:~# chmod +x aa.sh
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
如上所示,写了一个简单的Shell脚本,直接bash解释报权限错误,一般权限错误是没有执行权限什么的,但是如上给了权限还是报错。
因为也没有怎么深入使用过银河麒麟的操作系统,然后就上网查询了一下,是因为默认有个Kysec麒麟安全管理工具。
解决方案
方案一 : 通过图形桌面关闭执行控制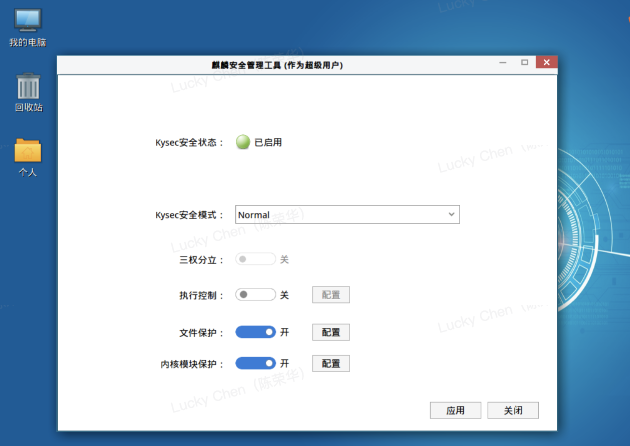
方案二: 通过命令设置麒麟系统安全状态为Softmode
root@Kylin:~# getstatus
KySec status: Normal
exec control: on
file protect: on
kmod protect: on
three admin : off
root@Kylin:~# setstatus Softmode
root@Kylin:~# getstatus
KySec status: Softmode
exec control: on
file protect: on
kmod protect: on
three admin : off
root@Kylin:~# bash aa.sh
1
设置开机启动设置:
root@Kylin:~# echo "setstatus Softmode" >> /lib/lsb/init-functions
方案三: 单独设置个别文件权限
oot@Kylin:~# setstatus Normal
root@Kylin:~# bash aa.sh
bash: aa.sh: 权限不够
root@Kylin:~# kysec_set -n exectl -v trusted aa.sh
root@Kylin:~# bash aa.sh
1
kysec_set man手册
kysec_set(8) System Manager's Manual kysec_set(8)
NAME
kysec_set - set kysec label for specfied path(s)
SYNOPSIS
kysec_set [ -n part ] [ -r ] -v value path1 ..
DESCRIPTION
kysec_set set the kysec label of specified files or directories to
value. Kysec label is composed of three parts: identify part, pro‐
tect part and exectl part.
when not used with -n option, kysec label should be in such format:
"identify:protect:exectl". Set the new value to 'none' to clear the
corresponding part of kysec label.
for identify part, these values are valid:
secadm commands for secadm
audadm commands for auditadm
for exectl part, these values are valid:
unknown unknown files
original original system files
verified verified 3rd party files
kysoft software installer
trusted trusted files
for protect part, only readonly is valid.
OPTIONS
-n set specified part of kysec labels. part can be exectl,
userid or protect.
-r process labels recursively, only usable for directories.
-v the new label value
EE ALSO
getstatus(8), setstatus(8), kysec_get(8)
kysec_set(8)
Centos下升级OpenSSL版本
1. 安装依赖
yum -y install perl perl-devel gcc gcc-c++
2. 升级
查看当前版本:
[root@centos7 src]$ openssl version
OpenSSL 1.0.2k-fips
下载新版本
当前最新版本是OpenSSL_1_1_1c(2019年7月5日),请到下面页面下载。
官网下载地址: https://www.openssl.org/source/
Github地址:https://github.com/openssl/openssl/releases
这里下载到/usr/local/src目录:
[root@centos7 ~]$ cd /usr/local/src
[root@centos7 src]$ wget https://github.com/openssl/openssl/archive/OpenSSL_1_1_1c.tar.gz
[root@centos7 src]$ tar xzvf ./OpenSSL_1_1_1c.tar.gz
[root@centos7 src]$ cd openssl-OpenSSL_1_1_1c/
接下来执行编译操作:
[root@centos7 src]$ ./config
如果没有安装Perl 5,执行config会有提示没有安装,需要先进行安装,执行yum install perl。
接下来依次执行下面的命令:
[root@centos7 src]$ make
[root@centos7 src]$ make test
[root@centos7 src]$ sudo make install
替换新旧版本:
[root@centos7 src]$ mv /usr/bin/openssl /usr/bin/oldopenssl
[root@centos7 src]$ ln -s /usr/local/bin/openssl /usr/bin/openssl
如果执行openssl version报下面错误:
[root@localhost openssl-OpenSSL_1_1_1c]$ openssl version
openssl: error while loading shared libraries: libssl.so.1.1: cannot open shared object file: No such file or directory
则执行下面命令解决:
[root@centos7 src]$ sudo ln -s /usr/local/lib64/libssl.so.1.1 /usr/lib64/
[root@centos7 src]$ sudo ln -s /usr/local/lib64/libcrypto.so.1.1 /usr/lib64/
然后查看当前版本:
[root@centos7 openssl-OpenSSL_1_1_1c]$ openssl version
OpenSSL 1.1.1c 28 May 2019
常见错误
错误:begin failed–compilation aborted at .././test/run_tests.pl
解决:sudo yum install perl-devel
错误:Parse errors: No plan found in TAP output
解决:yum install perl-Test-Simple
Centos系统下升级git命令版本
有些软件的自动安装依赖于git的版本,而且大多数Centos服务器上的git要么是1.7.1或者就是1.8.x,如果要大面积升级的话,还是用yum包管理器直接升级比较方便.
1. 获取安装源
1.1 Centos6
wget http://opensource.wandisco.com/centos/6/git/x86_64/wandisco-git-release-6-1.noarch.rpm
rpm -ivh wandisco-git-release-6-1.noarch.rpm
1.2 Centos7
wget http://opensource.wandisco.com/centos/7/git/x86_64/wandisco-git-release-7-1.noarch.rpm
rpm -ivh wandisco-git-release-7-1.noarch.rpm
# 或者
wget http://opensource.wandisco.com/centos/7/git/x86_64/wandisco-git-release-7-2.noarch.rpm
rpm -ivh wandisco-git-release-7-2.noarch.rpm
2. 安装git 2.x
yum install git -y
3. 验证
[root@linux-chromium rock]# git --version
git version 2.22.0
可以看到git已经升级到2.22.0的版本了, Centos6还可以利用如下源升级:
wget https://centos6.iuscommunity.org/ius-release.rpm
rpm -ivh ius-release.rpm
yum install git2u -y