
通知设置 新通知
Prometheus配置文件热加载
运维 push 发表了文章 0 个评论 4446 次浏览 2020-11-05 16:36

Promtheus的TSDB时序数据库在存储了大量的数据后,每次重启Prometheus进程的时间会越来越慢, 而且日常运维工作中会经常调整Prometheus的配置文件信息,比如一些静态配置,实际上Prometheus提供了在运行时热加载配置信息的功能,在这里介绍一下。
Prometheus配置热加载提供了2种方法:
- kill -HUP pid 发送SIGHUP信号方法
- 通过Prometheus服务API接口,发送发送一个POST请求到
/-/reload
Tips: 从 Prometheus2.0 开始,热加载功能是默认关闭的,如需开启,需要在启动 Prometheus 的时候,添加
--web.enable-lifecycle参数。
我个人更倾向于采用curl -XPOST http://localhost:9090/-/reload 的方式,因为每次reload过后, pid会改变,使用kill方式需要找到当前进程号。
如果配置热加载成功,Prometheus会打印出下面的log:
... msg="Loading configuration file" filename=prometheus.yml ...
下面我们来看看这两种方式内部实现原理。
第一种方法: 通过 kill 命令的 HUP (hang up) 参数实现
首先Prometheus在 cmd/promethteus/main.go 中实现了对进程系统调用监听,如果收到syscall.SIGHUP信号,将执行reloadConfig函数。
代码类似如下:
{
// Reload handler.
// Make sure that sighup handler is registered with a redirect to the channel before the potentially
// long and synchronous tsdb init.
hup := make(chan os.Signal, 1)
signal.Notify(hup, syscall.SIGHUP)
cancel := make(chan struct{})
g.Add(
func() error {
<-reloadReady.C
for {
select {
case <-hup:
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
}
case rc := <-webHandler.Reload():
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
rc <- err
} else {
rc <- nil
}
case <-cancel:
return nil
}
}
},
func(err error) {
// Wait for any in-progress reloads to complete to avoid
// reloading things after they have been shutdown.
cancel <- struct{}{}
},
)
}
第二种:通过 web 模块的 /-/reload请求实现:
首先 Prometheus 在 web(web/web.go) 模块中注册了一个 POST 的 http 请求 /-/reload, 它的 handler 是 web.reload 函数,该函数主要向 web.reloadCh chan 里面发送一个 error。
其次在Prometheus 的cmd/promethteus/main.go中有个单独的 goroutine 来监听web.reloadCh,当接受到新值的时候会执行 reloadConfig 函数。
func() error {
<-reloadReady.C
for {
select {
case <-hup:
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
}
case rc := <-webHandler.Reload():
if err := reloadConfig(cfg.configFile, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
rc <- err
} else {
rc <- nil
}
case <-cancel:
return nil
}
}
},
Prometheus内部提供了成熟的hot reload方案,这大大方便配置文件的修改和重新加载,在Prometheus生态中,很多Exporter也采用类似约定的实现方式。
企业不同时期的运维规划
运维 OS小编 发表了文章 0 个评论 1492 次浏览 2020-11-02 22:32

企业创业期
企业创业初期,人员少,业务流量不大,服务器数量相对较少,系统复杂度不高。对于日常的业务管理操作,因人员少,吼一声,大家就登录服务器进行手工操作,属于各自为战,每个人都有自己的操作方式,权限管理混乱、编写代码的风格各异,缺少必要的操作标准、流程机制,比如业务目录环境都是各式各样的。在这个阶段建议建立如下规范:
- 统一权限管理:应用程序、操作员、管理员权限分离。
- 制定完善的操作流程:先开发环境验证、测试环境验证、预生产环境、生产环境的基础操作流程,最小操作权限、最小化的目录权限为准则。
- 制定代码发布流程和机制:以开发环境、测试环境发布为先,在预生产环境、生产环境发布制定相应的审核。
- 制定代码编写规范:制定排版、注释、标识命名、异常处理等相关规范,避免出现个性化的代码。
- 使用云商自有监控做基础监控,主要是cpu、内存、网络等。
- 强化系统、业务基线安全。
企业高速发展期
在企业发展期,拿到融资后,业务快速发展,随着服务器规模、系统复杂度的增加,全人工的操作方式已经不能满足业务的快速发展需要。因此,运维人员逐渐开始使用批量化的操作工具,针对不同操作类型出现了不同的脚本程序。
但各团队都有自己的工具,每次操作需求发生变化时都需要调整工具。这主要是因为对于环境、操作的规范不够,导致可程序化处理能力较弱。此时,虽然效率提升了一部分,但很快又遇到了瓶颈。在这个阶段建议建立如下规范:
- 制定运维相关脚本的编写标准:如统一相关备份空间、相关备份执行计划,制定相关脚本的执行人员、执行权限、执行时间。
- 统一同类工具的使用:如数据连接工具、备份工具、数据同步工具等。
- 确认相关的操作人,减少或者避免开发和测试在服务器上的相关操作。
- 部署监控平台进一步的监管数据库、进程、日志等。
- 使用第三方应用性能管理对应用性能做应用分析和优化。
企业稳定发展时期
在企业稳定期,在这个阶段,对于运维效率和误操作率有了更高的要求,我们决定开始建设运维平台,通过平台承载标准、流程,进而解放人力和提高质量。
这个时候对服务的变更动作进行了抽象,形成了操作方法、服务目录环境、服务运行方式等统一的标准。通过平台来约束操作流程。
在平台中强制需要运维人员填写相应的检查项,然后才可以继续执行后续的部署动作。在这个阶段建议建立如下运维平台:
- 统一运维操作和管理平台:操作管理、权限管理、资源。
- 统一日志平台:统一日志收集标准、日志收集接口,查询方式,查询授权。
- 统一监控平台:强化监控,从系统、数据库、缓存、中间件、接口、业务性能等。
- 统一发布平台:细化发布项目、发布权限、发布审核、回滚、备份等。
- 加强安全防护:上线前做安全加固、安全评估、渗透测试等。
- 统一开发规范:统一接口、数据库、配置文件等规范。
企业集团化、规模化发展时期
更大规模的服务数量、更复杂的服务关联关系、各个运维平台的林立,原有的将批量操作转化成平台操作的方式已经不再适合,需要对服务变更进行更高一层的抽象。比如智能告警、故障自愈、运营辅助决策等。
这个阶段需要大量的运维数据支持,做相应的数据分析、测试,才能使用,不然因误报或错误的故障自愈决策造成大规模的故障。
分享阅读原文: http://m6z.cn/6sGPLO
四大CPU体系架构介绍
科技前沿 koyo 发表了文章 0 个评论 2708 次浏览 2020-11-02 00:54

RISC(reduced instruction set computer,精简指令集计算机) 是一种执行较少类型计算机指令的微处理器,起源于80年代的MIPS主机(即RISC机),RISC机中采用的微处理器统称RISC处理器。这样一来,它能够以更快的速度执行操作(每秒执行更多百万条指令,即MIPS)。因为计算机执行每个指令类型都需要额外的晶体管和电路元件,计算机指令集越大就会使微处理器更复杂,执行操作也会更慢。
性能特点一:由于指令集简化后,流水线以及常用指令均可用硬件执行;
性能特点二:采用大量的寄存器,使大部分指令操作都在寄存器之间进行,提高了处理速度;
性能特点三:采用缓存—主机—外存三级存储结构,使取数与存数指令分开执行,使处理器可以完成尽可能多的工作,且不因从存储器存取信息而放慢处理速度。
RISC平台的发展已经有长达几十年的历史了。其最早诞生于80年代的MIPS主机,随着技术的不断发展,RISC平台的应用领域逐步扩展,小到手机, 大到工控设备都可以见到他的身影。随着RISC平台的发展还诞生了与之相适应的应用软件,最终组成了现在人们较为熟知的嵌入式系统。当前桌面级消费者最为 熟知的Atom凌动平台便是嵌入式代表之一。但是与今天我们所要谈到的两位主角相比,intel的凌动平台就是小巫见大巫了。这正是诞生了RISC平台的 MIPS和当前RISC领域中最为强大的ARM。
MIPS是世界上很流行的一种RISC处理器。MIPS的意思”无内部互锁流水级的微处理器”(Microprocessor without interlocked piped stages),其机制是尽量利用软件办法避免流水线中的数据相关问题。它最早是在80年代初期由斯坦福(Stanford)大学Hennessy教授领导的研究小组研制出来的。MIPS公司的R系列就是在此基础上开发的RISC工业产品的微处理器。这些系列产品为很多计算机公司采用构成各种工作站和计算机系统。MIPS技术公司是美国著名的芯片设计公司,它采用精简指令系统计算结构(RISC)来设计芯片。和英特尔采用的复杂指令系统计算结构(CISC)相比,RISC具有设计更简单、设计周期更短等优点,并可以应用更多先进的技术,开发更快的下一代处理器。MIPS是出现最早的商业RISC架构芯片之一,新的架构集成了所有原来MIPS指令集,并增加了许多更强大的功能。
MIPS处理器是八十年代中期RISC CPU设计的一大热点。MIPS是卖的最好的RISC CPU,可以从任何地方,如Sony,Nintendo的游戏机,Cisco的路由器和SGI超级计算机,看见MIPS产品在销售。目前随着RISC体系结构遭到x86芯片的竞争,MIPS有可能是起初RISC CPU设计中唯一的一个在本世纪盈利的。和英特尔相比,MIPS的授权费用比较低,也就为除英特尔外的大多数芯片厂商所采用。MIPS的系统结构及设计理念比较先进,其指令系统经过通用处理器指令体系MIPS I、MIPS II、MIPS III、MIPS IV到MIPS V,嵌入式指令体系MIPS16、MIPS32到MIPS64的发展已经十分成熟。在设计理念上MIPS强调软硬件协同提高性能,同时简化硬件设计。
中国龙芯2和前代产品采用的都是64位MIPS指令架构,它与大家平常所知道的X86指令架构互不兼容,MIPS指令架构由MIPS公司所创,属于RISC体系。过去,MIPS架构的产品多见于工作站领域,索尼PS2游戏机所用的”Emotion Engine”也采用MIPS指令,这些MIPS处理器的性能都非常强劲,而龙芯2也属于这个阵营,在软件方面与上述产品完全兼容。普通用户关注MIPS主要还是因为我国所谓的”龙芯”。龙芯一开始抄袭MIPS,后来购买到了授权。倒也并非龙芯不想发展X86架构的桌面CPU市场或者ARM架构的移动设备市场,是因为这两家的授权太过于苛刻。X86的授权Intel已然不可能再授权。ARM是一家芯片设计公司,只能给出使用授权,不会同意让龙芯自行设计。只有MIPS才可行,MIPS的授权说白了就是随便抄随便改。很多龙芯的支持者提出了MIPS在理论上有诸多的领先,但不要忘了ARM是一家商业公司,市场占有率高,竞争意识也非常强。几乎所有的智能手机都是ARM架构,就是最有力的证明。
从某些方面来看,MIPS和ARM非常相似,都是采用精简指令集,都是针对低功耗应用设计,而且都是采用第三方授权方式生产;但实际上两者也有几大的不同,学院派的MIPS允许第三方对CPU架构进行大幅修改,而ARM只允许全球极少的几家半导体公司修改CPU架构(包括高通、苹果、NVIDIA和三星,全是半导体大拿),其他生产ARM芯片的公司都是直接采用ARM公版设计,而不能做任何修改(例如华为海思)。ARM的这项策略显然很适合商业推广,对第三方公司的技术要求也有所降低,开发的周期也会大大缩短,只需要照着ARM公版的CPU和GPU架构找芯片代工厂下单、流片、生产即可。
其中ARM/MIPS/PowerPC均是基于精简指令集机器处理器的架构;X86则是基于复杂指令集的架构,Atom是x86或者是x86指令集的精简版。
根据各种新闻,Android在支持各种处理器的现状:
ARM+Android最早发展、完善的支持,主要在手机市场、上网本、智能等市场;
X86+Android有比较完善的发展。有atom+Android的上网本,且支持Atom+Android和 Atom+Window7双系统;
MIPS+Android目前在移植、完善过程中;
Powpc+Android目前在移植、完善过程中。
当今处理器一共有三个最强大的架构,其中之一是以intel和AMD为代表的x86架构,另外一个是手机,平板处理器所使用的ARM架构,最后一个便是我国龙芯处理器所选择的MIPS架构。这三大处理器架构中,x86和ARM是商业化进程最为优秀的两大架构。也正是因为这两大架构的商业化进程太为出色,所以我国的龙芯处理器才被很多人批判为最严重的选择性失误。龙芯处理器的架构选择并没有错误,相反的如果龙芯要想得到更好的发展,选择MIPS才是最为正确的道路。x86架构的拥有者intel可以算作是技术合作上最抠门儿的一位,在推出x86架构之后,intel就只将这一架构授权给过AMD和VIA等几个芯片公司。而在VIA退出x86架构处理器竞争之后,intel便不再给任何公司x86架构授权。所以从x86架构上入手,龙芯处理器显然是行不通的。 intel的x86架构行不通,那么ARM架构是否就能行得通呢?答案当然也是否定的。
ARM
ARM架构,过去称作进阶精简指令集机器(Advanced RISC Machine,更早称作:Acorn
RISC Machine),是一个32位精简指令集(RISC)处理器架构,其广泛地使用在许多嵌入式系统设计。由于节能的特点,ARM处理器非常适用于行动通讯领域,符合其主要设计目标为低耗电的特性。
在今日,ARM家族占了所有32位嵌入式处理器75%的比例,使它成为占全世界最多数的32位架构之一。ARM处理器可以在很多消费性电子产品上看到,从可携式装置(PDA、移动电话、多媒体播放器、掌上型电子游戏,和计算机)到电脑外设(硬盘、桌上型路由器)甚至在导弹的弹载计算机等军用设施中都有他的存在。在此还有一些基于ARM设计的派生产品,重要产品还包括Marvell的XScale架构和德州仪器的OMAP系列。
优势:价格低;能耗低;
ARM授权方式:ARM公司本身并不靠自有的设计来制造或出售 CPU,而是将处理器架构授权给有兴趣的厂家。ARM提供了多样的授权条款,包括售价与散播性等项目。对于授权方来说,ARM提供了 ARM内核的整合硬件叙述,包含完整的软件开发工具(编译器、debugger、SDK),以及针对内含 ARM CPU 硅芯片的销售权。对于无晶圆厂的授权方来说,其希望能将 ARM内核整合到他们自行研发的芯片设计中,通常就仅针对取得一份生产就绪的智财核心技术(IP Core)认证。对这些客户来说,ARM会释出所选的 ARM核心的闸极电路图,连同抽象模拟模型和测试程式,以协助设计整合和验证。需求更多的客户,包括整合元件制造商(IDM)和晶圆厂家,就选择可合成的RTL(暂存器转移层级,如 Verilog)形式来取得处理器的智财权(IP)。借着可整合的 RTL,客户就有能力能进行架构上的最佳化与加强。这个方式能让设计者完成额外的设计目标(如高震荡频率、低能量耗损、指令集延伸等)而不会受限于无法更动的电路图。虽然ARM 并不授予授权方再次出售 ARM架构本身,但授权方可以任意地出售制品(如芯片元件、评估板、完整系统等)。商用晶圆厂是特殊例子,因为他们不仅授予能出售包含 ARM内核的硅晶成品,对其它客户来讲,他们通常也保留重制 ARM内核的权利。
生产厂商:TI(德州仪器)/Samsung(三星)/Freescale(飞思卡尔)/Marvell(马维尔)/Nvidia(英伟达)
ARM公司是一家非常优秀的芯片设计公司,但自身并不生产处理器,而是将自身的设计licensing卖给需要处理器的公司,而后交给他们生产或者是找人代工。也许有人要问了,既然ARM向外卖出架构设计,那么为何龙芯不去选择ARM架构呢?其实不然,ARM之所以能够发展成为一家非常成功的商业性公司,靠的就是芯片的架构设计,倘若架构设计被别人夺走了,那么自己就丢掉了赖以生存的饭碗。所以ARM虽然对外进行licensing授权,却不允许购买者进行任何对ARM架构有更改的设计。倘若个更改了设计,那么这便违反了合作协定,ARM便有权撤回licensing授权。我国的龙芯要是选择了ARM架构的话,那么基本上也就被捆住了脚步,无法发展出属于自己的高性能处理器了。
考虑到市场发展的问题ARM也对外妥协过。目前高通,苹果和NVIDIA这三家公司便是ARM体系中较为特殊的几个。因为这三家公司在芯片设计领域的特殊地位,ARM为了能够拉拢他们站立在自己的阵营中,对这三家公司开出了特别通行证。在其他芯片公司只能使用 licensing去生产芯片的时候,高通,苹果和NVIDIA却能够自行设计基于ARM架构的处理器。也正是拉拢到了高通,苹果和NVIDIA,才使得ARM拥有了更多的支持者。但即便这样,我们也不得不佩服ARM的老狐狸作风,在给出架构授权后,ARM依然会通过升级下一代架构为由让高通,苹果和 NVIDIA再掏一回钱购买架构授权。这样ARM就可以再赚一把。
x86系列或Atom处理器
x86或80x86是Intel首先开发制造的一种微处理器体系结构的泛称。x86架构是重要地可变指令长度的CISC(复杂指令集电脑,Complex
Instruction Set Computer)。
Intel Atom(中文:凌动,开发代号:Silverthorne)是Intel的一个超低电压处理器系列。处理器采用45纳米工艺制造,集成4700万个晶体管。L2缓存为512KB,支持SSE3指令集,和VT虚拟化技术(部份型号)。
现时,Atom处理器系列有6个型号,全部都是属于Z500系列。它们分别是Z500、Z510、Z520、Z530、Z540和Z550。最低端的Z500内核频率是800MHz,FSB则是400MHz。而最高速的Z550,内核频率则有2.0GHz,FSB则是533MHz。从Z520开始,所有的处理器都支持超线程技术,但只增加了不到10%的耗电。双内核版本为N系列,依然采用945GC芯片组。双内核版本仍会支持超线程技术,所以系统会显示出有4个逻辑处理器。这个版本的两个内核并非采用本地设计,只是简单的将两个单内核封装起来。
MIPS系列
MIPS是世界上很流行的一种RISC处理器。MIPS的意思是“无内部互锁流水级的微处理器”(Microprocessor without interlockedpipedstages),其机制是尽量利用软件办法避免流水线中的数据相关问题。它最早是在80年代初期由斯坦福(Stanford)大学Hennessy教授领导的研究小组研制出来的。MIPS公司的R系列就是在此基础上开发的RISC工业产品的微处理器。这些系列产品为很多计算机公司采用构成各种工作站和计算机系统。
MIPS技术公司是美国著名的芯片设计公司,它采用精简指令系统计算结构(RISC)来设计芯片。和英特尔采用的复杂指令系统计算结构(CISC)相比,RISC具有设计更简单、设计周期更短等优点,并可以应用更多先进的技术,开发更快的下一代处理器。MIPS是出现最早的商业RISC架构芯片之一,新的架构集成了所有原来MIPS指令集,并增加了许多更强大的功能。MIPS自己只进行CPU的设计,之后把设计方案授权给客户,使得客户能够制造出高性能的CPU。
1984年,MIPS计算机公司成立,开始设计RISC处理器;
1986年推出R2000处理器。
1992年,SGI收购了MIPS计算机公司。
1988年推R3000处理器。
1991年推出第一款64位商用微处器R4000;之后又陆续推出R8000(于1994年)、R10000(于1996年)和R12000(于1997年)等型号。
1998年,MIPS脱离SGI,成为MIPS技术公司;随后,MIPS公司的战略发生变化,把重点放在嵌入式系统;1998年-MIPS科技股票在美国纳斯达克股票交易所公开上市。
1999年,MIPS公司发布MIPS32和MIPS64架构标准,为未来MIPS处理器的开发奠定了基础。新的架构集成了所有原来NIPS指令集,并且增加了许多更强大的功能。MIPS公司陆续开发了高性能、低功耗的32位处理器内核(core)MIPS324Kc与高性能64位处理器内核MIPS645Kc。
2000年,MIPS公司发布了针对MIPS32 4Kc的版本以及64位MIPS 64 20Kc处理器内核。
2007年8月16日-MIPS科技宣布,中科院计算机研究所的龙芯中央处理器获得其处理器IP的全部专利和总线、指令集授权。
2007年12月20日-MIPS科技宣布,扬智科技已取得其针对先进多媒体所设计的可定制化系统单芯片(SoC)核心“MIPS32 24KEcPro”授权。
…..
MIPS和ARM虽然都是对外进行架构授权的公司,但意义完全不同。ARM对外出售的是设计方案授权 (licensing),与ARM的商业化相比,MIPS倒像是学院派的公司。MIPS的架构授权,并不限制任何对MIPS架构的更改。换句话说,就是 MIPS公司给授权者一张白纸,而白纸上仅仅写着一行字,MIPS公司同意你设计生产MIPS架构处理器,至于你设计成什么样,性能有多高,经过多少代更改,MIPS一概不管,只要你不把架构彻底改变就行了。与ARM相比,MIPS是一个完全开放的架构,对龙芯未来的发展没有任何的限制,这与intel给 AMD x86架构授权,而不是给设计图纸的道理是完全一样的。在加上MIPS本身经过几十年的发展,已经拥有了众多的应用软件,综合考虑来看,MIPS是最为适合龙芯处理器发展的架构选择。RISC平台是诞生于MIPS早先产品的,也正是RISC平台的诞生,才最终发展成为了我们现在的智能手机与平板机这样强大的产品。然而作为RISC系统的创始人,MIPS的商业化发展并非一帆风顺,也许是受公司前身是大学科学实验室的影响。公司高层对商业化发展嗤之以鼻, 这才令本身技术要落后于MIPS的ARM得到了发展时机。
PowerPC系列
PowerPC是一种精简指令集(RISC)架构的中央处理器(CPU),其基本的设计源自IBM(国际商用机器公司)的IBMPowerPC601 微处理器POWER(PerformanceOptimized With Enhanced RISC;《IBM Connect电子报》2007年8月号译为“增强RISC性能优化”)架构。
二十世纪九十年代,IBM(国际商用机器公司)、Apple(苹果公司)和Motorola(摩托罗拉)公司开发PowerPC芯片成功,并制造出基于PowerPC的多处理器计算机。
PowerPC架构的特点是可伸缩性好、方便灵活。
PowerPC处理器有广泛的实现范围,包括从诸如 Power4那样的高端服务器CPU到嵌入式CPU市场(任天堂Gamecube使用了 PowerPC)。PowerPC处理器有非常强的嵌入式表现,因为它具有优异的性能、较低的能量损耗以及较低的散热量。除了象串行和以太网控制器那样的集成 I/O,该嵌入式处理器与“台式机”CPU存在非常显著的区别。
Pyhton列表去重方法总结
编程 Ansible 发表了文章 0 个评论 1548 次浏览 2020-11-02 00:22

Python列表去重在Python应用编程中,是一种非常常见的应用技巧,有些场景下需要统计出来的列表中去重,避免重复统计。
1. 通过字典去重
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = {}.fromkeys(job).keys()
print(list(jobs))
结果:
['Sale', 'Dev', 'OPS', 'Presale', 'Test']
解释:
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
语法:
dict.fromkeys(seq[, value])
- seq - 字典键值列表。
- value - 可选参数, 设置键序列(seq)的值。
该方法返回一个新字典, .keys 函数以列表返回一个字典所有的键。
2. 通过集合去重
大家都知道在Python数据结构中集合是天生去重的,所以我们可以利用这一特性来达到列表去重的效果。
格式: list(set(mylist))
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = list(set(job))
由于采用集合,会导致原有的列表排序发生变化,此时可通过如下方法,保持列表原有顺序:
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = list(set(job))
jobs.sort(key=job.index)
3. 使用itertools模块
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
import itertools
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
job.sort()
job_group = itertools.groupby(job)
jobs = []
for k, g in job_group:
jobs.append(k)
print(jobs)
groupby 根据key(v)值分组的迭代器, 将key函数作用于原循环器的各个元素。根据key函数结果,将拥有相同函数结果的元素分到一个新的循环器。每个新的循环器以函数返回结果为标签。
4. 通过列表推导式去重
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
jobs = []
[ jobs.append(i) for i in job if i not in jobs]
通过列表推导式,判断在不在新列表中的元素则添加到新列表中。
5. 利用lambda匿名函数和 reduce 函数处理
#!/usr/bin/env python3
# _*_coding:utf-8_*_
# Description: List to heavy
from functools import reduce
job = ['Sale', 'Dev', 'OPS', 'Sale', 'Presale', 'Sale', 'Dev', 'Test', 'OPS']
func = lambda x,y:x if y in x else x + [y]
jobs = reduce(func, [[], ] + job)
交叉编译详解概念篇
运维 OS小编 发表了文章 0 个评论 2008 次浏览 2020-11-01 01:53

1、交叉编译简介
1.1 什么是交叉编译
对于没有做过嵌入式编程的人, 可能不太理解交叉编译的概念, 那么什么是交叉编译?它有什么作用?
在解释什么是交叉编译之前,先要明白什么是本地编译。
本地编译:
本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台(CPU和系统)下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译:
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序:
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
1.2 为什么会有交叉编译
之所以要有交叉编译,主要原因是:
- Speed: 目标平台的运行速度往往比当前编译主机慢得多,许多专用的嵌入式硬件被设计为低成本和低功耗,没有太高的性能;
- Capability: 整个编译过程是非常消耗资源的,嵌入式系统往往没有足够的内存或磁盘空间;
- Availability: 即使目标平台资源很充足,可以本地编译,但是第一个在目标平台上运行的本地编译器总需要通过交叉编译获得;
- Flexibility: 一个完整的Linux编译环境需要很多支持包,交叉编译使我们不需要花时间将各种支持包移植到目标机器上。
1.3 为什么交叉编译比较困难
交叉编译的困难点在于两个方面:
不同的体系架构拥有不同的机器特性
- Word size: 是64位还是32位系统
- Endianness: 是大端还是小端系统
- Alignment: 是否必修按照4字节对齐方式进行访问
- Default signedness: 默认数据类型是有符号还是无符号
- NOMMU: 是否支持MMU
交叉编译时的主机环境与目标环境不同
- Configuration issues:具有单独配置步骤(标准./configure make make install)的软件包通常会测试字节序或页面大小等内容,以便在本地编译时可移植。交叉编译时,这些值在主机系统和目标系统之间会有所不同,因此在主机系统上运行测试会给出错误的答案。当目标没有该程序包或版本不兼容时,配置还可以检测主机上是否存在该程序包并包括对该程序包的支持;
- HOSTCC vs TARGETCC:许多构建过程需要编译内容才能在主机系统上运行,例如上述配置测试或生成代码的程序(例如创建.h文件的C程序,然后在主构建过程中#include )。仅用目标编译器替换主机编译器就会破坏需要构建在构建本身中运行的事物的软件包。这样的软件包需要访问主机和目标编译器,并且需要教它们何时使用它们;
- Toolchain Leaks:配置不正确的交叉编译工具链可能会将主机系统的某些位泄漏到已编译的程序中,从而导致通常易于检测但难以诊断和纠正的故障。工具链可能#include错误的头文件,或在链接时搜索错误的库路径。共享库通常依赖于其他共享库,这些共享库也可能潜入对主机系统的意外链接时引用;
- Libraries:动态链接的程序必须在编译时访问适当的共享库。需要将与目标系统共享的库添加到交叉编译工具链中,以便程序可以针对它们进行链接;
- Testing:在本机版本上,开发系统提供了便利的测试环境。交叉编译时,确认”hello world”构建成功可能需要配置(至少)引导加载程序,内核,根文件系统和共享库。
更详细的对比可以参看这篇文章,已经写的很详细了,在这就不细说了:Introduction to cross-compiling for Linux
2、交叉编译链
2.1 什么是交叉编译链
明白了什么是交叉编译,那我们来看看什么是交叉编译链。
首先编译过程是按照不同的子功能,依照先后顺序组成的一个复杂的流程,如下图: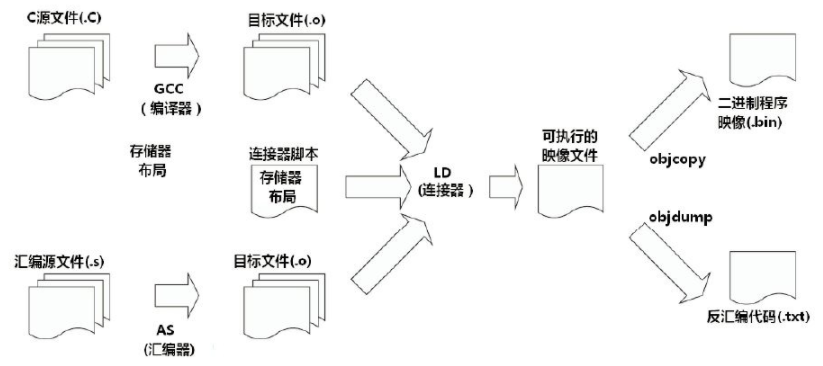
那么编译过程包括了预处理、编译、汇编、链接等功能。既然有不同的子功能,那每个子功能都是一个单独的工具来实现,它们合在一起形成了一个完整的工具集。
同时编译过程又是一个有先后顺序的流程,它必然牵涉到工具的使用顺序,每个工具按照先后关系串联在一起,这就形成了一个链式结构。
因此,交叉编译链就是为了编译跨平台体系结构的程序代码而形成的由多个子工具构成的一套完整的工具集。同时,它隐藏了预处理、编译、汇编、链接等细节,当我们指定了源文件(.c)时,它会自动按照编译流程调用不同的子工具,自动生成最终的二进制程序映像(.bin)。
注意: 严格意义上来说,交叉编译器,只是指交叉编译的gcc,但是实际上为了方便,我们常说的交叉编译器就是交叉工具链。本文对这两个概念不加以区分,都是指编译链。
2.2 交叉编译链的命名规则
我们使用交叉编译链时,常常会看到这样的名字:
arm-none-linux-gnueabi-gcc
arm-cortex_a8-linux-gnueabi-gcc
mips-malta-linux-gnu-gcc
其中,对应的前缀为:
arm-none-linux-gnueabi-
arm-cortex_a8-linux-gnueabi-
mips-malta-linux-gnu-
这些交叉编译链的命名规则似乎是通用的,有一定的规则:
arch-core-kernel-system
- arch: 用于哪个目标平台;
- core: 使用的是哪个CPU Core,如Cortex A8,但是这一组命名好像比较灵活,在其它厂家提供的交叉编译链中,有以厂家名称命名的,也有以开发板命名的,或者直接是none或cross的;
- kernel: 所运行的OS,见过的有Linux,uclinux,bare(无OS);
- system: 交叉编译链所选择的库函数和目标映像的规范,如gnu,gnueabi等。其中gnu等价于glibc+oabi、gnueabi等价于glibc+eabi。
注意: 这个规则是一个猜测,并没有在哪份官方资料上看到过。而且有些编译链的命名确实没有按照这个规则,也不清楚这是不是历史原因造成的。如果有谁在资料上见到过此规则的详细描述,欢迎指出错误。
3、包含的工具
Binutils是GNU工具之一,它包括链接器、汇编器和其他用于目标文件和档案的工具,它是二进制代码的处理维护工具。
Binutils工具包含的子程序如下:
- ld - GNU链接器;
- as - GNU汇编器;
- gold - 一个新的,更快的ELF链接器;
- addr2line - 把地址转换成文件名和所在的行数;
- ar - 用于创建,修改和提取档案的实用程序;
- c ++ filt-过滤以解编码编码的C ++符号;
- dlltool-创建用于构建和使用DLL的文件;
- elfedit-允许更改ELF格式文件;
- gprof-显示分析信息;
- nlmconv-将目标代码转换为NLM;
- nm-列出目标文件中的符号;
- objcopy-复制并转换目标文件;
- objdump-显示目标文件中的信息;
- ranlib-生成指向档案内容的索引;
- readelf-显示来自任何ELF格式对象文件的信息;
- size -列出的对象或归档文件的部分的尺寸;
- strings -列出文件中的可打印字符串;
- strip - 丢弃的符号;
- windmc -Windows兼容的消息编译器。
- windres -Windows资源文件的编译器。
binutils介绍 binutils详解 详细页面。
3.2 GCC
GNU编译器套件,支持C, C++, Java, Ada, Fortran, Objective-C等众多语言。
3.3 Glibc
Linux上通常使用的C函数库为glibc。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现。
因为嵌入式环境的资源及其紧张,所以现在除了glibc外,还有uClibc和eglibc可以选择,三者的关系可以参见这两篇文章:
3.4 GDB
GDB用于调试程序
4、如何得到交叉编译链
既然明白了交叉编译链的功能,那么在针对嵌入式系统开发时,我们需要的交叉编译链从哪儿得到?
主要有三个方式可以获取
4.1 下载已经做好的交叉编译链
使用其他人针对某些CPU平台已经编译好的交叉编译链。我们只需要找到合适的,下载下来使用即可。
常见的交叉编译链下载地址:
在 http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/ 下载已经编译好的交叉编译链
在 http://www.denx.de/en/Software/WebHome 下载已经编译好的交叉编译链
在https://launchpad.net/gcc-arm-embedded下载已经编译好的交叉编译链
一些制作交叉编译链的工具中,包含了已经制作好的交叉编译链,可以直接拿来使用。如crosstool-NG
如果购买了某个芯片或开发板,一般厂商会提供对应的整套开发软件,其中就包含了交叉编译链。
厂家提供的工具一般是经过了严格的测试,并打入了一些必要的补丁,所以这种方式往往是最可靠的工具来源。
4.2 使用工具定制交叉编译链
使用现存的制作工具,以简化制作交叉编译链这个事情的复杂度。我们只需要了解有哪些工具可以实现,并选个合适的工具,搞懂它的操作步骤即可。
- crosstool-NG
- Buildroot
- Embedded Linux Development Kit (ELDK)
工具还有很多,各有各的优势和劣势,大家可以慢慢研究,在这就不细说了。
4.3 从零开始构建交叉编译链
这个是最困难也最耗时间的,毕竟制作交叉编译链这样的事情,需要对嵌入式的编译原理了解的比较透彻,至少要知道出了问题要往哪个方面去翻阅资料。而且,也是最考耐心和细心的地方,配错一个选项或是一个步骤,都可能出现以前从来没见过的问题,而且这些问题往往还无法和这个选项或步骤直接联系起来。
当然如果搭建出来,肯定也是收获最大的,至少对于编译的流程和依赖都比较清楚了,细节上的东西可能还需要去翻看相应的协议或标准,但至少骨架会比较清楚。
详细的搭建过程可以参看后续的文章,这里面有详细的参数和步骤:
交叉编译详解 二 从零制作交叉编译链
为了方便大家搭建交叉编译链,我写了一个一键生成的脚本(包括源码下载和自动编译)。如果大家自己一直搭建不成功,不妨试试这个脚本,然后对比下自己的流程是否一致,参数是否有差异,也许能帮大家迈过这个障碍:
交叉编译详解 三 使用脚本自动生成交叉编译链
4.4 对比三种构建方式
| 项目 | 使用已有交叉编译链 | 自己制作交叉编译链 |
|---|---|---|
| 安装 | 一般提供压缩包 | 需要自己打包 |
| 源码版本 | 一般使用较老的稳定版本,对于一些新的GCC特性不支持 | 可以使用自己需要的GCC特性的版本 |
| 补丁 | 一般都会打上修复补丁 | 普通开发者很难辨别需要打上哪些补丁,资深开发者可以针对自己的需求合入补丁 |
| 源码溯源 | 可能不清楚源码版本和补丁情况 | 一切都可以定制 |
| 升级 | 一般不会升级 | 可以随时升级 |
| 优化 | 一般已经针对特定CPU特性和性能进行优化 | 一般无法做到比厂家优化的更好,除非自己设计的CPU |
| 技术支持 | 可以通过FAE进行支持,可能需要收费 | 只能通过社区支持,免费 |
| 可靠性验证 | 已经通过了完善的验证 | 自己验证,肯定没有专业人士验证的齐全 |
参考资料
1、Introduction to cross-compiling for Linux
4、 uclibc eglibc glibc之间的区别和联系
5、 Glibc vs uClibc Differences
6、交叉编译链下载地址
- http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/
- http://www.denx.de/en/Software/WebHome
- https://launchpad.net/gcc-arm-embedded
分享原文: http://m6z.cn/6tdD7y
前哨大会2020: 让我们与未来接轨
科技前沿 星物种 发表了文章 0 个评论 1550 次浏览 2020-10-29 22:48

2020年10月28号,前哨大会2020在青岛举办。王煜全在四个小时的演讲中,带大家理清现状,剖析科技背后的规律,让迷茫的未来变得清晰,与大家一起探索未来趋势,坚定信念,一起行动。
2020不能被忽略的三个理由:
2020年是社会发展的重要转折,思想、文化、观念都出现了重大转变;
2020年是科技价值的集中表达,IT和信息技术、生物技术正在显露出价值;
2020年是未来趋势的清晰展现,让我们更清楚地看见未来。
王煜全在《前哨大会2020》都讲了啥?本文分享演讲中的精华内容。
一年看变化
1. 科技公司想方设法让大家做到的事,结果都很难做到,一次百年难遇的疫情却做到了。科技改变世界,今天很多的不确定因素恰恰推动了科技创新加速。在美国,百年历史老店纷纷申请破产保护,伴随着的是线上产业的激增:2020年的电子商务占到零售总额的16%,大大超过了往年。数据显示预测,2030年之前,美国在远程办公领域创造4.5万亿的市值。
2. 从电商优势到配送优势,适应变化、接受新事物,对中国人来说是再正常不过的事情。与美国不同,中国人早就习惯了电商的线上购物。在中国,几乎听不到任何反对新技术的声音,上上下下对创新高度认同。前哨大会的听众从五湖四海奔赴青岛,都离不开一个app或小程序里“健康码”。这是我们司空见惯的事物,在海外人士看来却是不可思议。

3. 警惕外卖小哥的“内卷化风险”:今天的优势很有可能变成明天的劣势。 美国的信用卡很先进,所以没有诞生出支付宝和微信支付;中国的人力配送系统过于成熟,太多的外卖小哥又便宜又好用,所以在无人机、无人车的配送自动化领域,很可能落后于美国。
未来一定是无人配送。中国也不是没有机会,那就是从现在开始,用硬件制造优势抢占国外的配送市场。不要只盯着国内的市场需求,而要着眼全世界的市场。当你拥有全世界的时候,本地的竞争对手就不再是威胁。
4. 引领和跟随最大的区别,就是需要看清未来。以前,抗风险股票从来都不是科技股。而今年科技股是资本市场最抗风险的股票。苹果、亚马逊、谷歌、Facebook逆势上涨,奇怪的是Intel却没有跟着涨。背后的推手就是大资本,大资本做了很深的研究,准确判断那些是最优秀的公司,可以提前兑现未来价值。
中国A股市场有个说法就是“板块”,要涨一起涨,要跌一起跌。结果大家都炒作科技股去了,成为韭菜们炒作科技股的题材,所以这类群体有一个新说法,叫做科技韭菜。
5. 科技产业生态的繁荣,主要不是技术问题。芯片是一个全球协作的复杂产业生态。中国芯片要发展,核心根本不是技术,而是考验的产业协调能力,需要整个生态一起努力。
6. 引入特斯拉并不能真正带动中国的电动车产业,因为特斯拉不是电动车产业的核心。虽然表面上说100%国产化,但其实真正的核心技术特斯拉是不会开放给你的:那就是电池管理系统、FSD芯片和软件。
电动车产业的核心是电池技术,我们出现了很优秀的电池公司宁德时代,围绕宁德时代打造一个电动车生态,才是中国发展电动车产业的关键。
7. 科技最发达的国家,选出了一个最不相信科技的总统。至今还有很多人对特朗普当选深信不疑。如今很多中国人都觉得自己专业的只有两件事:中国足球和美国大选。
《经济学人》10月27号的数据,特朗普的胜率是4%,拜登高达96%。另一家预测数据是538网站,特朗普和拜登胜率比例是12:87。如果你能看清背后的规则,背后大资本的逻辑,你就应该知道拜登基本锁定胜局了。
8. 中美冲突,不是全球化问题,而是利益问题。真实世界是一张网络,里面没有谁替代掉谁的问题,只有贡献大小的问题,贡献大小决定了话语权。贸易本是封锁式思维,是替代与不替代的关系,而科技产业需要双方合作共赢。
9. 在你没注意到的时候,中国的改变正在悄悄发生。过去一年,约有2000亿美元从海外进入中国资本市场。截至2020年6月,海外公司持有的中国股票和债券分别增长了50%和28%。门在慢慢打开,钱在慢慢涌入。大量资本往中国涌入,因为中国提供了眼下世界其它地方最罕见的两样东西:GDP增长和高于零的利率。
所以,巨变之下,更要看懂世界运行的大规律。
百年看规律
1. 群体与技术的相互选择中,生产者也是消费者,每一轮的新技术满足新需求,达成更大规模的新平衡。其中遵循三条规律:
一、技术进步就是对人类需求满足的深化。从福特T型车到五颜六色的定制汽车,从银行存储到私人理财,每次技术革命过程中,人的需求都存在从批量供应到个性化满足的转变。
二、技术对社会的影响是链式反应。汽车刚出来的时候,人的活动范围大了,这是行为改变;更大的活动范围催生了交通、旅游、家电、超市和娱乐产业,这是环境带来的系统改变;家庭规模缩小,个人意识扩大,这是观念改变。
三、每次颠覆式创新进入社会,都会带来社会动荡,经历一段具有破坏性的阵痛期。特斯拉作为新物种出现的时候,遭到经销商以“禁止直销”为由的抵制,至今也有近一半的州买不到特斯拉,要在线下店买车只能去那些有销售许可的州。
2. 中国成为科技制造强国的秘密是能力圈层。从天南海北汇聚到深圳的创业者们,不是以宗亲关系建立圈子,而是以产业关系建立圈子,以经营实力建立层次。它继承了中国传统的圈层社会,也融合了欧美开放的信用体系,这是中国成为科技制造强国的秘密,我把这种为了顺应科技创新的需求,建立起新的基于产业和能力的圈层关系,叫做“能力圈层”。
3. 未来社会的心理需求,一定越来越童年化。成人是追求社会认同,然后追求自我实现。而儿童追求探索,进而追求挑战。顺应时代发展、满足社会需求的技术,将催生下一个巨无霸企业,催生出下一个推动社会进步的巨大产业。
十年看趋势
1. 芯片产业正在发生一场巨变。上一轮的芯片产业是由Intel和AMD主导的,但随着人工智能浪潮的到来,Intel被落下已成定局,未来属于NVIDIA和AMD。这是技术更替带来的结果,也向我们揭示了:企业一旦停止前沿技术布局,就注定跟不上这个时代。
2. 我们正在迎来虚实融合的世界。iphone 12的激光雷达是一项了不起的技术进步,因为它进一步完善了“激光雷达家谱”:手机激光雷达能测几米远,工业级3D相机能测量几十米;自动驾驶的激光雷达能做到200米;大疆无人机的激光雷达能做到450米。未来诞生上千米测距的激光雷达只是时间问题,虚实融合、数字化的世界正在加速到来。
3. 未来是对数据的争夺,大数据正在变现。利用已有的人工智能技术去和各个行业领域的专业数据结合,提供专业领域的行业服务,是人工智能技术实现收入利润的关键。
4. AI医疗是正在到来的下一个大风口。今年开始已经有好几家的人工智能医疗产品获得了药监局的批准,其中就有AI医疗企业Airdoc,通过对眼底的观察来判断并筛查早期糖尿病。随着这些公司的发展壮大,他们将会很快上市,中国的股市上将会出现AI医疗赛道。
5. 机器人正在走出车间,走出工厂。世界顶级的高校正在利用机器人没日没夜地做实验,实验成果发表在《Nature》上;十年之内,每个家庭都会有机器臂。如影科技的机械臂正在走进家庭,相信很快,足不出户让你享受世界级的大师咖啡。
6. 企业logo将会过时,每个企业都将有自己的专属形象。通过logo来辨认公司将成为过去,代表公司形象的或许将是Sophia这样的美女机器人。顺便提一句,网红机器人Sophia正在进行量产前阶段,合作方是一家中国的OEM企业。
7. 无人机将掀起又一场从坦克到闪电战的战争理论革命。未来战争规则会发生巨变,这些投入巨额经费、研发高顶尖导弹的专家们可能没意识到,未来打败他们的是一堆廉价无人机的机海战术。
8. 3D打印正在成为新的制造方式。德国EOS的金属3D打印技术在很多方面相比传统制造更有优势,3D打印独角兽Desktop Metal、Carbon 3D的产品设备正在走进市场,中国正在迎来新的创业机会。
9. 新的智能制造技术不只是3D打印,还有印刷技术。印刷术本来是中国古代的四大发明之一,但现在TCL也在用印刷技术来制造显示屏幕。印刷原理虽然简单,但制造里面有大量的高科技,有非常多的know-how在里面,这也是中国制造优势的体现。
10. 中国制造的隐忧。特斯拉宣布:三年内电动车价格降到25,000美元。中国制造既然那么先进,为什么没人敢站出来应战,说自己可以做到24999美元呢?
制造就是高科技,也要前瞻性布局,提前预埋下一轮新技术。中国要开始警醒,别以为过去三十年制造业领先,未来也会一直领先。
11. 中国不是简单的制造代工,我们还能超越制造。我们投资的Wicab盲人眼镜在明年年中之前就能做完所有的试验,完成全部申报。第一批产品将造福中国五百万盲人。未来我们希望能把这个平台打开,把它当作认知科学的通用工具,提供给各个学术机构。我们不光要把技术产品化造福人类,更要用技术能力反哺科研,让科研在技术推动下产生更多认知科学领域的革命性成果。
12. 生物技术正在经历一场产业变革,生物学的世纪已经开始。生物技术正在经历一场产业变革:化学药→生物药→生物治疗。在PD-1和CART两个领域,涌现出了大量通过FDA审批的新药。
13. 基因编辑正在兴起。站在前沿的科学家们正在推进技术应用。其中有诺贝尔化学奖得主Charpentier和Doudna,以及张峰、George Church这些科学家,他们名下都有把基因编辑技术进行产业化的公司。未来会有公司成功把基因编辑技术推向市场,让大量的患者真正从中受益。
14. 百岁人生已经近在眼前。就在不远的未来,每个人都不需要花费很多资金,可以通过健康管理,利用科技的手段活过100岁。我们要用实际行动来迎接这个长寿时代的到来。
15. 今天看到的人造肉并不是真的人造肉。Beyond Meat、Impossible Food这样的公司只是利用豆制品模仿肉的口感。真正的基于合成生物学的人造肉是实验室培养的培育肉。未来的合成生物学,利用细胞或基因这样的底层物质来进行组合,把真肉培养出来,这才是人造肉的未来方向。
16. 能源焦虑并不成立,我们正在迎来清洁能源时代。未来的终极解决方案是可燃冰和核聚变,目前页岩气和太阳能可以大大缓解今天的能源危机。最终解还没出现的时候,临时解可以极大缓解能源焦虑,能源在未来不再是问题。
未来十年,技术与社会相互影响的发展趋势?
1. 资本正在推动全球化的隐性回归。未来十年,科技的全球化是大概率事件,逆全球化声音还会一直存在,但只是全球化浪潮中的一股逆流。
2. 技术企业分化,考验的是企业面向未来的战略能力。能不能实现科技的前瞻性布局,持续的科技升级,是下一个成功企业的关键。
3. 创新产业带动经济发展,需要创新产业生态布局能力。像当年的深圳一样,有一批走在前沿的人先做出来,成功了再推广到其它地方。青岛有望成为下一个创新产业繁荣生态的城市。
- 全球视角、全球信用。中国的企业家、创业者们要从全球角度看科技产业,懂得全球化的商业合作规则,建立全球化的信用。

最后,One more thing!王煜全希望跟大家一起来做件事情。从今年开始,每年做未来十年的预测,也希望在不断反馈和修正当中成长。同时,也希望你来发布你自己的预测,人人都做前瞻者,一起来预测未来。关注微博@王煜全,留言发布自己的预测。
欢迎加入科技特训营,面向未来的科技产业社群。每一位学员都有属于自己的标签,这个特训营里有三类面向未来的人:前瞻者,行动者,连接者。他们对应了未来需要具备的三种能力:领导力,创造力,协同力。
马云在最近的一场演讲中反复谈及“面向未来”:相比与国际接轨,更该思考如何与未来接轨。今天的前哨大会2020,就是带领大家一起,看见未来,一起行动。
2020年,是中国重新启动全球化的一年。十年后看今天,未来那辉煌的起点,从今天开始
分享阅读原文: http://m6z.cn/6ddoav
王煜全前哨大会2020十大科技趋势预测
科技前沿 星物种 发表了文章 0 个评论 2825 次浏览 2020-10-29 01:18

前哨大会2020,10月28号在青岛举办。今年我做了一个科技未来十大趋势预测,发布在这里,可以留言,说说你对未来的预测,我们一起与未来接轨!
1. 人工智能进入收获期
人工智能算法的突破会逐渐趋缓,异构计算架构造成计算能力增强,是人工智能进入各个行业领域的最佳时期,也有很多领域进入收获期了。如AI医疗,明年会有几个公司陆陆续续上市。
人工智能只有和行业结合才能发挥最大效能。
2. 大数据变现
做大数据分析的Palantir公司为政府做大数据抓获本拉登,公司现如今已经悄悄上市了。大数据就像石油,人工智能和计算方法就像炼油。有大数据的地方就会机会,比如车、手机都是大数据的源头。车要每天采集庞大的道路信息,手机要对人的健康数据检测,所以苹果公司未来也会是一个健康数据公司 - 手机采集数据,手表实时监测。
美国一家做基因分析的公司,Twenty-three and Me公司,因为收集了很多基因信息成为了美国最大的基因库,很多医药公司和它合作就是看重了他背后的大数据。我们投资的中智达信公司的手术室自动化项目中,手术室也是个大数据。将手术室的环境和整个手术数据化,还可以对接其他系统,这就是大数据变现。
3. 无所不在的智能
未来智能的需求非常广泛,这是大规模化个性化服务的前提。有了云计算和5G,智能化可以无所不
在。
要形成整合的解决方案,越来越多的数据需要在云端处理,但是要做到协同服务,就要有越来越多的智能处理单元,在我们所处的环境中,这样就能形成一个无所不在智能的解决方案。
4. 云上的战争
为人工智能提供平台的云平台将会有激烈战争。大的公有云已经拉开差距,如中国的HAT,美国的谷歌、微软等。云上的功能方案(如snowflake做数据库)和云上的行业方案(如云上物联网)都是可行的。
大平台的战争已经进入尾声,不过小平台的机会刚刚兴起 - 云上的服务才是机会。因为有了人工智能,下一个规模化、个性化、高质量的服务就在云端。
5. 规模化的服务提供
云+人工智能,能做到远程全覆盖的服务。人工智能其实就是固化人的经验,而给人提供服务需要的就是经验的固化。所以这样就能给海量的人提供相对个性化的服务。
6. 虚实结合的世界
核心一方面是虚拟现实和增强现实,如苹果的激光雷达,车载激光雷达,大疆无人机激光雷达,都能数字化现实,再和虚拟结合另一方面就是大量设备,如AR和VR的应用。
VR的应用要晚于AR,因为技术要求更高,带宽要求也更高。AR是2B先于2C,往往用于工作,带宽要求没那么高,起步也更快。当设备、数据采集、应用和网络都具备时,市场就起来了。虽然2B先于2C,AR先于VR,但未来2C和VR的市场巨大。
7. 自动驾驶和机器人的普及
自动驾驶已经开始上路试用了,但完全实现无人驾驶和无人出租车可能还很远,5~10年内可能都还是试点,卡车可能更早实现自动驾驶,还有就是特种车辆,比如一定区域内的工程车,或小的街头送货车。初期来看,未来两年会有商用机器人的潮流,五年后会有家用机器臂的潮流。十年之后,基本每家都会有机器臂。
8. 清洁能源时代来临
电动车、太阳能、和页岩气的普及,代表着清洁能源时代的来临。在未来十年内,能源的危机就不是问题了,大家会更多的在意保护环境和使用清洁能源。随着对电动车的更多关注和青睐,电池的持续量产使得当太阳能储能方案解决时便会迎来一波发展的高峰。
9. 生命科学推动健康长寿产业
原因在于一方面是医药产业的进展,比如药物会从化学药到大分子生物药,再到生物治疗;还有医疗器械小型化、健康可穿戴、人工智能和数字化,都使我们对人的了解达到了空前的水平。以后不可治愈的病都会慢慢变成慢性病,比如癌症。我们对疾病的管理也会变成对健康的管理,让没生病的人变得更健康。未来,百岁人生将会成为更多人的现实。
10. 合成生物学的曙光
现在的人造肉其实只是豆腐,口感像肉而已。我们现在吃肉,就像是盖摩天大楼然后拆它的砖用,只为了吃蛋白,却养了构造那么精密的动物,实在是得不偿失。我们可以直接用生物合成的手段生成蛋白,也就是肉,就省时省力很多了。未来大量工厂不会再是养动物,而是用合成生物的方法来生产肉。在未来,越来越多的工厂会像实验室,而越来越多实验室会更像工厂 - 机器人会在实验室内被广泛应用,形成实验室自动化。
这是我基于近期科技发展的判断,以及长期科技如何与社会结合,如何推动社会的整体规律的把握而做的趋势预测。
煜全老师微博: https://weibo.com/wangyuquan
2020青岛前哨大会视频回放地址: http://m6z.cn/5ChYqk





