
通知设置 新通知
代码的艺术
编程 OS小编 发表了文章 0 个评论 1761 次浏览 2022-05-18 14:46

作者简介:章淼,章博士,清华大学计算机博士,百度云前端技术负责人,百度 Golang & Python 技术委员会成员。
笔记
对比Google的工程师,国内的工程师写代码的占用时间显然过多了,而不太注重提前设计 ;Google 工程师们在开始实现某一模块或功能时,会事先在代码库中搜索是否已经有可重用的代码,并且代码库中的代码具有完整的注释和文档。
提前设计的重要性
尽可能地提前完成两个文档
- 需求分析文档
- 系统设计文档
原因:在未启动实现细节代码之前构思设计时发现问题的修改,对比后期真正已经开始Coding的时候,对比发现问题进行修改,成本要低很多。文档一般只写主要逻辑,而代码涉及更多细节。
笔者备注:但这不是绝对的,修改是正常的,不要惧怕修改,反复尝试积累经验。
- 需求分析文档:主要是在定义黑盒状态,描述外在,描述
WHAT要做什么? - 系统设计文档:主要实在定义白盒状态,描述内在,描述
HOW怎么做?
两者要有区分,不要混淆 ,也不要混在一起写!
需求分析文档的误区:
不要过早提前构想实现细节,我们的大脑会下意识地在我们构想如何实现时遇到的各种难题,而将原本的需求分析的思考挂起;举例:导弹 vs 炸弹,两者都有摧毁目标的能力,但是很明显导弹的价值更高,重要的是制导的功能,而不是爆炸本身。
系统设计文档的误区:
主要要写定义系统的架构、模块、接口、数据、关键算法、设计思路等等得过程记录。
系统架构要写什么以及方法
概念、模型、视图等等。
- 静:系统静态的样子,功能模块如何划分等
- 动:系统运转起来,各模块联动起来的样子
- 细:不同角度,不同层次去描述
- 每一个组件(模块、函数)保证单一性, Single purpose. 只做一件事!
- 轻耦合,低内聚(避免全局变量(多处操作难以控制))
- 当前系统设计所受到的约束(当前设计的瓶颈在哪?比如网络、吞吐量、占用 CPU 或文件位置资源等)
- 需求分析是系统设计的来源
- 模型和抽象的思维能力很重要(涉及概念:模型、数据结构、算法等等)
设计接口(Interface)要注意什么?
- 接口定义系统外在的功能
- 接口定义当前系统与外部系统之间的关系
接口Interface定义了系统对外的接口,往往比系统实现内部细节代码更重要,不要过于草率,因为一旦定义了接口,提供出去给调用方使用,想修改就太难了。所以设计接口有重要原则,站在使用者的角度考虑问题!
两点细节:
- 向前兼容(尽量不要接口已升级,老接口全不能用,那就不是好的接口设计)
- 使用方便(让调用者可以一目了然知道接口的作用,简化传参,说明返回值等等)
如何写代码?
代码是一种表达的方式。是写给人看的,要有编程规范 。
拥有编程规范的理想状态:
- 看别人代码就像看自己代码一样易懂;
- 看代码主要看逻辑,不要过多注重细节;
- 代码尽可能地不要让人去多想。
Don’t make me think!
Moudle模块
紧内聚,低耦合。单一功能。反例,定义一个 utils.py 内部包含诸多方法,不易懂。
模块一般可以分为两类:
- 数据类的模块(1. 主要完成对数据的封装; 2. 对外提供的数据接口)
- 过程类的模块(1. 不要包含数据,可以是调用数据类的模块或者调用其他过程类模块; 2. 具备操作性质的模块)
模块的重要性:
- 降低维护成本;
- 更好地复用
Class类和Function函数
两者是不同的模型,各自有各自适用的范围。
推荐方法: 和类的成员无关的函数,尽量独立出去单独一个函数,不建议作为类的成员函数。
面向对象思想的讨论:多态和继承,需要谨慎适用,作为Python的工程师,不太推崇Java中继承和多态,因为系统是逐渐长起来的,并不是从一开始就是一个成熟的样子,所以很难凭空去设计一个继承的关系。
模块的构成
文件头(注释)
- 模块的说明,简要功能
- 修改历史(时间、修改人,修改的内容)
- 其他特殊细节的说明
函数(重要性仅次于模块)
- 描述功能
- 传入参数的描述(含义、类型、限制条件等等)
返回值得描述(有足够明确的语义说明)
逻辑判断型 check is XXX
操作型(成功 or 失败)
数据获取型(状态 + 数据)
异常如何处理(是抛出?还是内部catch?要明确)
- 明确单入口和单出口(多线程开发时尤为重要)
函数要尽可能的规模小,足够短(BUG 往往出现在非常长的一个函数里)
代码块的分段也很重要,分段背后是划分和逻辑表达。
代码是一种表达能力的体现,也算是文科的范畴! 注释不是补出来的!
命名的重要性:要准确、易懂、可读性强,尽量做到 望名生义 。
互联网时代的系统是运营出来的。
可检测性也是尤其重要的。(埋点、监控等等)
没有数据的收集,等于系统没有上线。
监控不单单只有传统意义上的内存、CPU、网络、崩溃率的监控,还应有线上真实数据监控,需要有足够多的状态记录。
日志是很有限的一种监控手段,并且采集日志也是一种资源耗费。推荐的手段:可以使用埋点,对外提供接口,有单独的系统调用接口进行有针对性的采集。
修身
好的程序员,与工作年限无关,与学历无关
学习-思考-实践
学习:主观意愿地学习,途径也有很多,例如书籍、开源代码、社区。忌讳夜郎自大、井底之蛙。注重培养自己学习吸收的能力,多读多看但是数量不是最终目的。
Stay Hungry, Stay Foolish. – Steve Jobs
思考:学习需要经过思考,形成自己的思维。
实践:《卓有成效的时间管理者 - 德鲁克》推荐阅读
知识-方法-精神
知识过时会非常快!
方法:分析问题、解决问题的能力尤其重要(定义问题、识别问题、定义关键问题)
精神:决定型,要做就要坚持做
前进的道路上不能永远都是鲜花和掌声。
基础乃治学之根本。
数据结构、软件工程、逻辑思维能力、研究能力,需要5-8年时间磨炼。
kvm虚拟机启动报错Unable to find security driver for model selinux
运维 OS小编 发表了文章 0 个评论 2103 次浏览 2022-05-17 15:46

好久没用kvm虚拟话了,之前有台物理机配置比较高,就借助kvm虚拟化技术虚拟了几台虚拟机做实验完,但是今天启动报如下错误:
[root@kvm-labs kvm]# virsh start centos7-lab-node1
error: Failed to start domain centos7-lab-node1
error: unsupported configuration: Unable to find security driver for model selinux
根据错误提示,怀疑是系统selinux的问题,但是发现selinux是disabled,难道要强制用selinux,不合理啊。重新梳理逻辑,kvm虚拟机是可被定义的,是不是定义的配置文件中有selinux相关定义,那是不是可以去掉,经过实验还真ok,解决步骤如下。
1. 进入虚拟机配置文件目录
cd /etc/libvirt/qemu/
# 如果你构建环境修改过默认路径,根据实际情况进入
2. 编辑虚拟机配置文件
vim centos7-lab-node1.xml
.....................
<input type='tablet' bus='usb'>
<address type='usb' bus='0' port='1'/>
</input>
<input type='mouse' bus='ps2'/>
<input type='keyboard' bus='ps2'/>
<graphics type='vnc' port='-1' autoport='yes' listen='0.0.0.0'>
<listen type='address' address='0.0.0.0'/>
</graphics>
<video>
<model type='cirrus' vram='16384' heads='1' primary='yes'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/>
</video>
<memballoon model='virtio'>
<address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/>
</memballoon>
<rng model='virtio'>
<backend model='random'>/dev/urandom</backend>
<address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/>
</rng>
</devices>
<seclabel type='dynamic' model='selinux' relabel='yes'/>
</domain>
如上,删除<seclabel type='dynamic' model='selinux' relabel='yes'/> , 然后保存退出。
3. 重新定义配置文件
virsh define ./centos7-lab-node1.xml
然后重新执行virsh start centos7-lab-node1 就可以了。
如果想迁移虚拟机的存储路径也可以关机,修改配置文件下的存储路径,并将.qcow2文件移动到相应的目录下即可.
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/data/kvmdata/centos7-lab-node1.qcow2'/>
<target dev='vda' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>
</disk>
修改完成后,然后重新定义配置文件,重启虚拟机即可。
Centos系统进入单用户修改root用户密码
运维 OS小编 发表了文章 0 个评论 1627 次浏览 2022-05-16 17:15

1. 重启系统,在选择进入系统界面按字母e
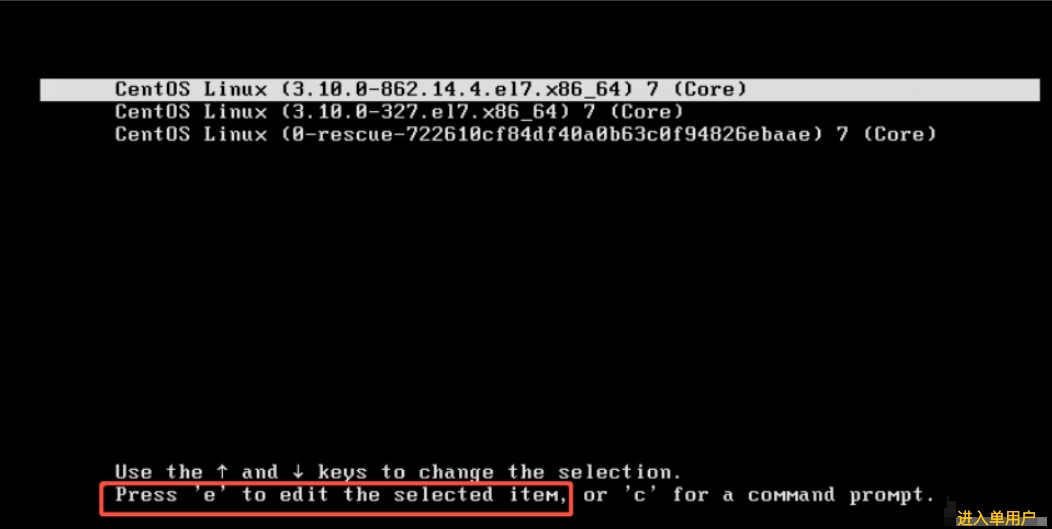
2. 在rhgb前添加’rw’ ,在行末添加 ‘init=/bin/sh’ ,按 ‘Ctrl+x’ 进入系统
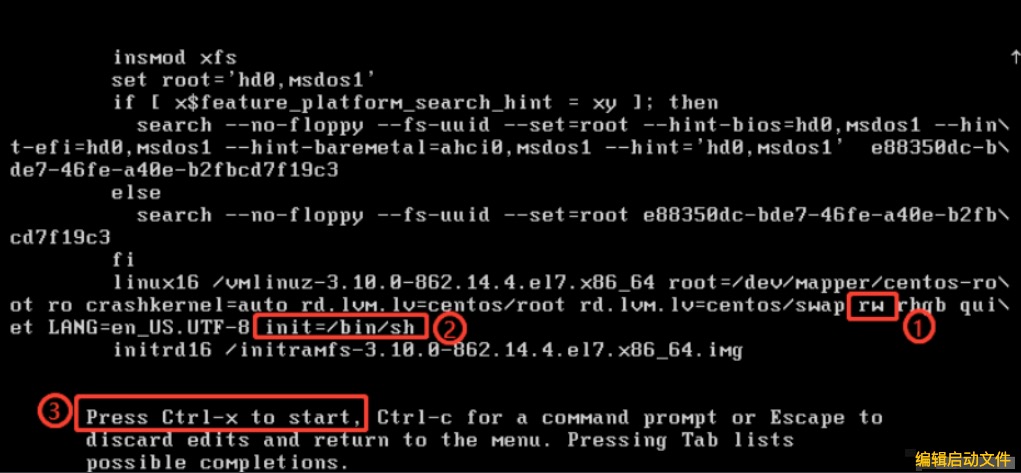
进入系统后,修改密码
echo "www.baidu.com | passwd --stdin root
touch /.autorelabel
exec /sbin/init
等待一会,点击回车,进入重启。





