
通知设置 新通知
Python的发展趋势
编程 空心菜 发表了文章 0 个评论 3227 次浏览 2021-08-08 21:47

一、Python发展历史
Python是一种计算机程序设计语言。你可能在之前听说过很多编程语言,比如难学的C语言(语法和实现难度),非常流行的JAVA语言(尤其是现在分布式存储和服务),非常有争议的PHP(常见 WordPress 大多网站),前端HTML、JavaScripts、Node.JS、还有最近随着容器风行的Golang等等。那Python是What?
- 1989年,Python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
- 1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
- 1992年,Python之父发布了Python的web框架Zope1.
- Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
- Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
- Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
- Python 2.5 - September 19, 2006
- Python 2.6 - October 1, 2008
- Python 2.7 - July 3, 2010
- In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to Python 3.4+ as soon as possible
- Python 3.0 - December 3, 2008
- Python 3.1 - June 27, 2009
- Python 3.2 - February 20, 2011
- Python 3.3 - September 29, 2012
- Python 3.4 - March 16, 2014
- Python 3.5 - September 13, 2015
最新参考:https://www.python.org/downloads/release
二、Python的前景
最新的TIOBE( https://www.tiobe.com/tiobe-index/ )排行榜,Python赶超JAVA占据第二名了, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。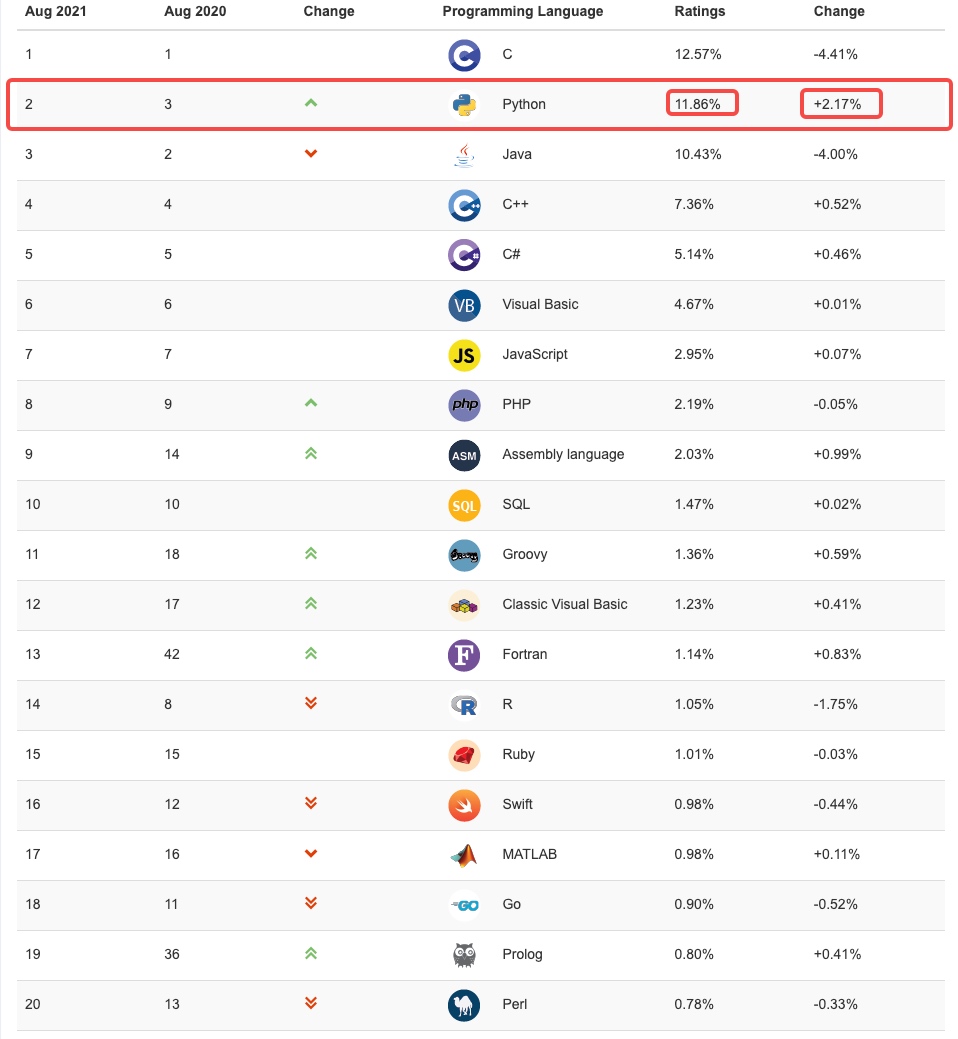
我们看看17年Python的排名: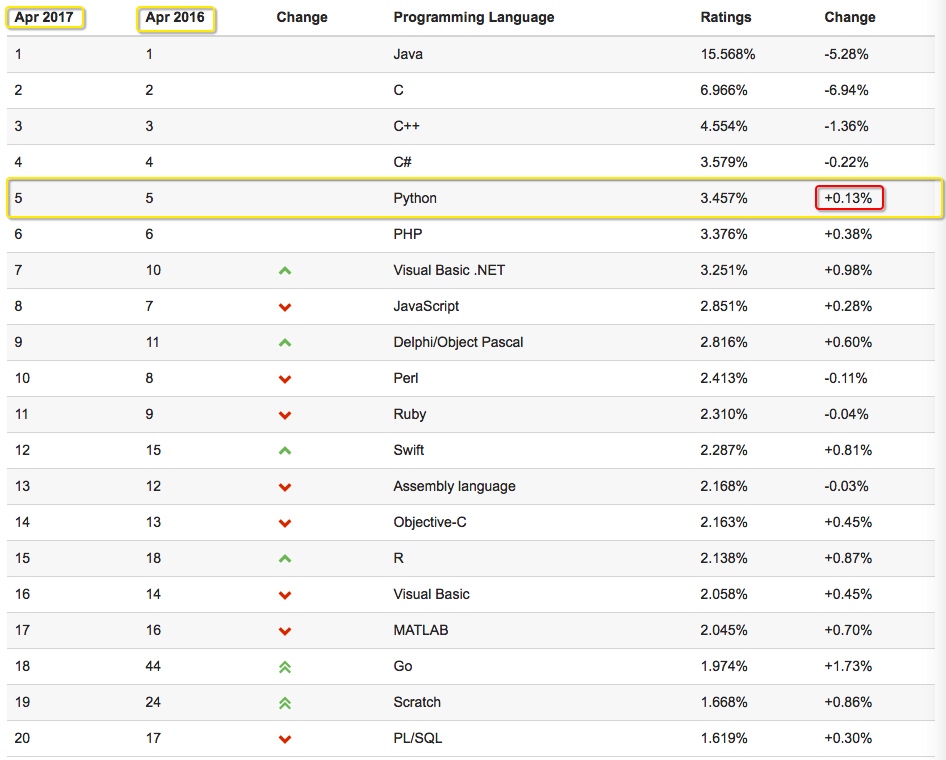
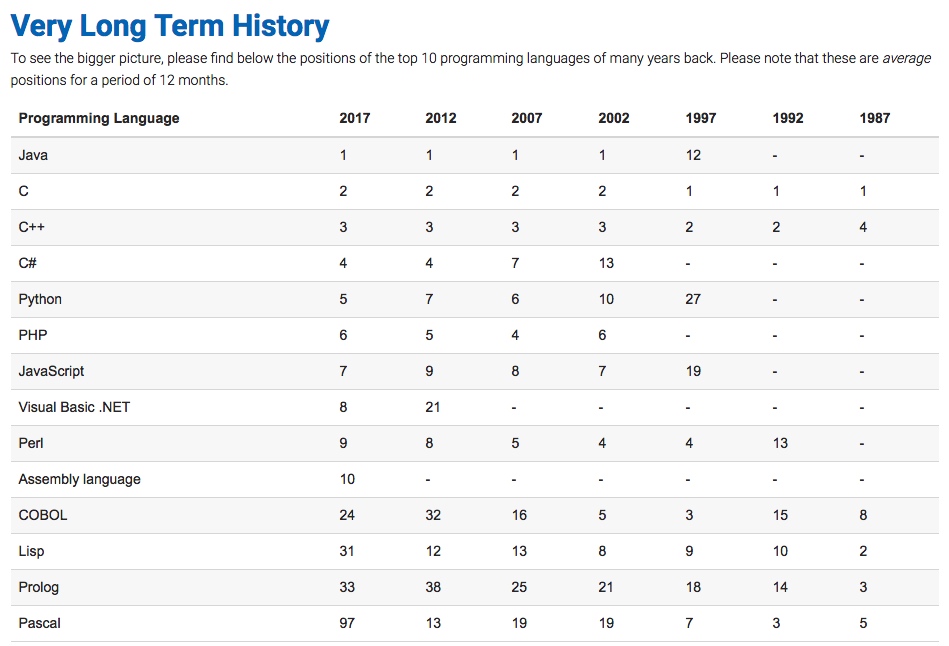
由上图17年预测可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到大家的认知和认可,影响度也越来越大,在国内Python开发招聘的岗位也越来越多,我们来看看2017年100offer统计情况: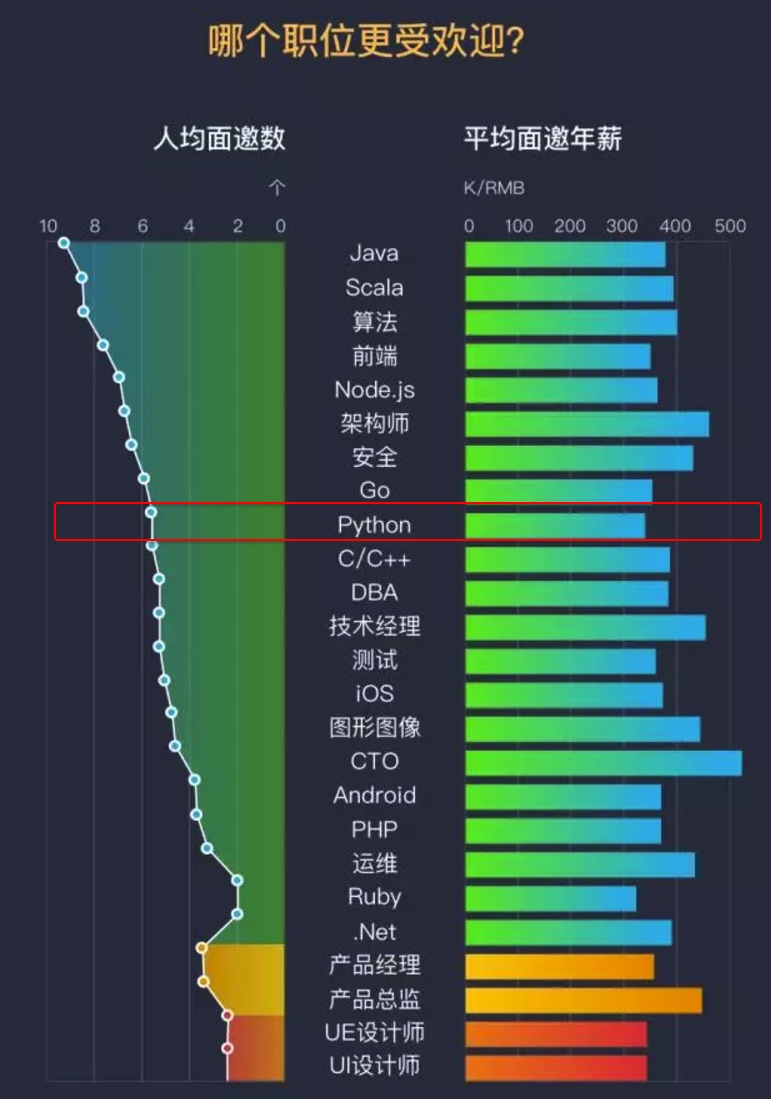
从上图我们可以看出Python的人均面邀数为6,整体年薪在34w左右,在职位招聘排行榜前十名,应该还算不错的表现哦。
三、Python的应用领域
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。
目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、阿里、百度、腾讯、汽车之家、美团等。
目前Python主要的应用领域
云计算: 在云计算领域Python可谓有一席之地, 典型应用OpenStack这个大体量的开源云计算产品就是居于Python开发的。
WEB开发: 已有众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣, 知乎等…., Python也有许多Web开发框架,典型WEB框架有Django、Pylons,还有Tornado、Bottle、Flask等。
系统运维: 从国内的趋势来看,掌握一门编程语言已经成为了必然的结果,Python在国内已经成为了首选,不管是做自动化运维还是业务运维现在Python在运维领域已经应用极广。
金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
图形GUI: PyQT, WxPython, TkInter, PySide等在图形用户接口领域都有广泛被应用。
哪些公司在用Python
谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发。
CIA: 美国中情局网站就是用Python开发的。
NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算。
YouTube:世界上最大的视频网站YouTube就是用Python开发的。
Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载。
Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发。
Facebook:大量的基础库均通过Python实现的
Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
豆瓣: 公司几乎所有的业务均是通过Python开发完成的。
知乎: 国内最大的问答社区,通过Python开发(国外Quora)
春雨医生:国内知名的在线医疗网站是用Python开发的
除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务, 互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
为什么是Python而不是其他语言呢?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python和C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
Python和PHP相比
Python提供了丰富的数据结构,非常容易和c集成。相比较而言,php集中专注在web上。 php大多只提供了系统api的简单封装,但是python标准包却直接提供了很多实用的工具。python的适用性更为广泛,php在web更加专业,php的简单数据类型,完全是为web量身定做。
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。语言是死的,每个语言的诞生都有它的道理,所以选择你喜欢的,开心的玩起来。
yum和apt-get命令对比
运维 星物种 发表了文章 0 个评论 2666 次浏览 2021-06-17 14:21

| 说明 | Redhat系 | Debian系 |
|---|---|---|
| 更新缓存 | yum makecache | apt-get update |
| 更新包 | yum update | apt-get upgrade |
| 检索包 | yum search | apt-cache search |
| 检索包内文件 | yum provides | apt-file search |
| 安装指定的包 | yum install | apt-get install |
| 删除指定的包 | yum remove | apt-get remove |
| 显示指定包的信息 | yum info | apt-cache show |
| 显示包所在组的一览 | yum grouplist | - |
| 显示指定包所在组的信息 | yum groupinfo | - |
| 安装指定的包组 | yum groupinstall | - |
| 删除指定的包组 | yum groupremove | - |
| 参考库的设定文件 | /etc/yum.repos.d/* | /etc/apt/sources.list |
| 安装完的包的列表 | rpm -qa | dpkg-query -l |
| 显示安装完的指定包的信息 | rpm -qi | apt-cache show |
| 安装完的指定包内的文件列表 | rpm -ql | dpkg-query -L |
| 安装完的包的信赖包的列表 | rpm -qR | apt-cache depends |
| 安装完的文件信赖的包 | rpm -qf | dpkg -S |
什么是CICD
运维 OS小编 发表了文章 0 个评论 2597 次浏览 2021-05-15 15:27

传统的应用发布模式

如果你经历体验过传统的应用发布,你可能就会觉得CICD有足够吸引你的地方,反之亦然。一般一个研发体系中都会存在多个角色:开发、测试、运维。当时我们的应用发布模式可以能是这样的:
- 开发团队在开发环境中完成软件开发,单元测试,测试通过,提交到代码版本管理库;
- 开发同学通知运维同学项目可以发布了,然后运维同学下载代码进行打包和构建,生成应用制品;
- 运维同学使用部署脚本将生成的制品部署到测试环境,并提示测试同学可以进行产品的测试;
- 测试同学开始进行手动、自动化测试,测试完成后提醒运维同学可以进行预生产环境部署;
- 运维同学开始进行预生产环境部署,然后测试同学进行测试,测试完成后,开始部署生产环境。
当然我描述的可能只是其中的一部分,手动操作很多、出现的问题很多。上面看似很流畅的过程,其实每次构建或发布都可能会出现问题。未对每次提交验证、构建环境不一致:开发人员本地测试成功后提交代码,运维同学下载代码进行编译却出现了错误。
存在的问题:
- 错误发现不及时: 很多错误在项目的早期可能就存在,到最后集成的时候才发现问题;
- 人工低级错误发生: 产品和服务交付中的关键活动全都需要手动操作;
- 团队工作效率低: 需要等待他人的工作完成后才能进行自己的工作;
- 开发运维对立: 开发人员想要快速更新,运维人员追求稳定,各自的针对的方向不同。
经过上述问题我们需要作出改变,如何改变?
什么是CICD

软件开发的连续方法基于自动执行脚本,以最大程度地减少在开发应用程序时引入错误的机会。从开发新代码到部署新代码,他们几乎不需要人工干预,甚至根本不需要干预。
它涉及到在每次小的迭代中就不断地构建,测试和部署代码更改,从而减少了基于错误或失败的先前版本开发新代码的机会。
此方法有三种主要方法,每种方法都将根据最适合您的策略的方式进行应用。
持续集成 CI(Continuous Integration)

在传统软件开发过程中,集成通常发生在每个人都完成了各自的工作之后。在项目尾声阶段,通常集成还要痛苦的花费数周或者数月的时间来完成。持续集成是一个将集成提前至开发周期的早期阶段的实践方式,让构建、测试和集成代码更经常反复地发生。
开发人员通常使用一种叫做CI Server的工具来做构建和集成。持续集成要求史蒂夫和安妮能够自测代码。分别测试各自代码来保证它能够正常工作,这些测试通常被称为单元测试(Unit tests)。
代码集成以后,当所有的单元测试通过,史蒂夫和安妮就得到了一个绿色构建(Green Build)。这表明他们已经成功地集成在一起,代码正按照测试预期地在工作。然而,尽管集成代码能够成功地一起工作了,它仍未为生产做好准备,因为它没有在类似生产的环境中测试和工作。
CI是需要对开发人员每次的代码提交进行构建测试验证。确定每次提交的代码都是可以正常编译测试通过的。在没有持续集成服务器的时候,我们可以写一个程序来监听版本控制系统的状态,当出现了push动作则触发相应的脚本运行编译构建等步骤。现在有了专业的持续集成服务器后,我们借助持续集成服务器来实现版本控制系统中代码提交触发构建测试等验证步骤。
持续合并开发人员正在开发编写的所有代码的一种做法。通常一天内进行多次合并和提交代码,从存储库或生产环境中进行构建和自动化测试,以确保没有集成问题并及早发现任何问题。
开发人员提交代码的时候一般先在本地测试验证,只要开发人员提交代码到版本控制系统就会触发一条提交流水线,对本次提交进行验证。
持续交付 CD (Continuous Delivery)
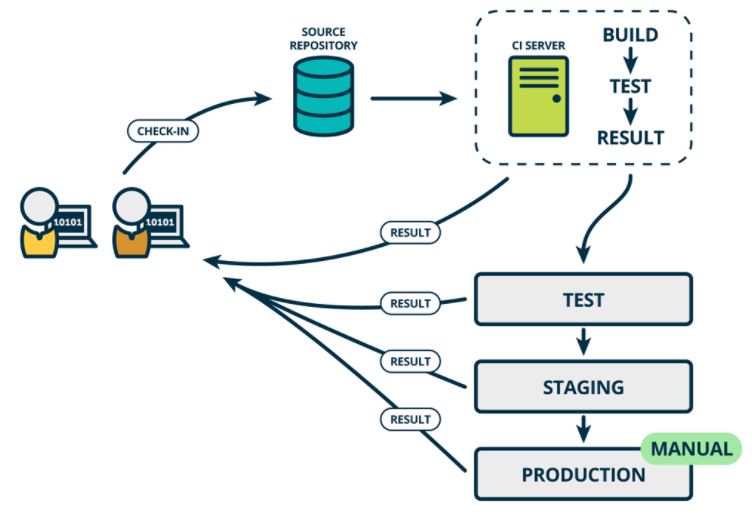
Continuous Delivery (CD) 持续交付是持续集成的延伸,将集成后的代码部署到类生产环境,确保可以以可持续的方式快速向客户发布新的更改。如果代码没有问题,可以继续手工部署到生产环境中。
持续交付CD:是基于持续集成的基础上,将集成后的代码自动化的发布到各个环境中测试(DEV TEST UAT STAG),确定可以发布生产版本。这里我们可以借用制品库实现制品的管理,根据环境类型创建对应的制品库。一次构建,到处运行。
- 开发环境发布:我们可以将开发环境产出的制品部署进行测试,没有问题后上传到测试环境的制品库中。
- 测试环境发布:此时通知测试人员可以进行测试环境发布测试,获取测试环境制品库中的制品,发布到测试环境验证。验证通过将制品上传到预生产环境制品库。
- 预生产环境发布:获取预生产环境制品,进行部署测试。测试成功后可以将制品上传到生产库中。
- 手动部署生产环境。
持续交付是超越持续集成的一步。不仅会在推送到代码库的每次代码更改时都进行构建和测试,而且,作为附加步骤,即使部署是手动触发的,它也可以连续部署。此方法可确保自动检查代码,但需要人工干预才能从策略上手动触发更改的部署。
持续部署 CD(Continuous Deploy)
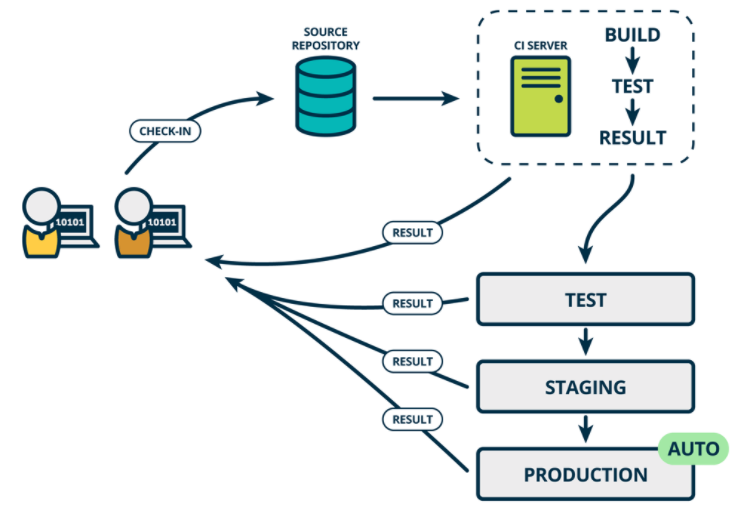
如果真的想获得持续交付的好处,应该尽早部署到生产环境,以确保可以小批次发布,在发生问题时可以轻松排除故障。于是有了持续部署。
通常可以通过将更改自动推送到发布系统来随时将软件发布到生产环境中。持续部署 会更进一步,并自动将更改推送到生产中。类似于持续交付,持续部署也是超越持续集成的进一步。不同之处在于,您无需将其手动部署,而是将其设置为自动部署。部署您的应用程序完全不需要人工干预。
持续部署CD:是基于持续交付的基础上,将在各个环境经过测试的应用自动化部署到生产环境。其实各个环境的发布过程都是一样的。应用发布到生产环境后,我们需要对应用进行健康检查、添加应用的监控项、 应用日志管理。
我们通常将这个在不同环境发布和测试的过程叫做部署流水线, 持续部署是在持续交付的基础上,把部署到生产环境的过程自动化。
参考:
https://blog.csdn.net/weixin_40046357/article/details/107478696
http://www.idevops.site/gitlabci/chapter01/01/
https://www.jianshu.com/p/654505d42180
最全医疗细分赛道龙头
互联网资讯 OS小编 发表了文章 0 个评论 2474 次浏览 2021-05-14 18:47
 今天周末,股大夫一直满仓,最近账户增值不错,我敢于满仓持股不动主要得益于我对医疗的三大逻辑思考:人口老龄化,这个话题前面我已经表格说明过,最近七普人口调查数据大家应该也看了。国产替代,我之前也专题研说过,未来国产替代将是大势所趋,无法阻挡的历史洪流。刚需,医疗作为一种特殊的消费品,中国人口数量仍然世界第一,居民人均可支配收入不断提高,这也是很自然的大趋势客观存在,无法改变。
今天周末,股大夫一直满仓,最近账户增值不错,我敢于满仓持股不动主要得益于我对医疗的三大逻辑思考:人口老龄化,这个话题前面我已经表格说明过,最近七普人口调查数据大家应该也看了。国产替代,我之前也专题研说过,未来国产替代将是大势所趋,无法阻挡的历史洪流。刚需,医疗作为一种特殊的消费品,中国人口数量仍然世界第一,居民人均可支配收入不断提高,这也是很自然的大趋势客观存在,无法改变。今天花时间总结下医疗各赛道龙头公司,每个公司的产品都是自己独特的护城河,或者有的公司有自己的祖传秘方,我们投资的目标就是找寻市场最牛的,最有需求的公司,今天我列举出来,每个人的理解不同,估计还不是很全面。
恒瑞医药:肿瘤创新药龙头,医药总龙头
爱尔眼科:眼科医疗服务龙头
迈瑞医疗:医疗器械总龙头
药明康德:医药CXO龙头
长春高新:生长激素龙头
片仔癀:中药龙头
美年健康:体检医疗服务龙头
云南白药:传统中医药龙头
复星医药:创新药龙头老二,医药综合龙头
乐普医疗:心脏支架系统龙头
新和成:维生素龙头
华兰生物:血液制品龙头
智飞生物:疫苗代理销售龙头
人福医药:麻醉药龙头
科伦药业:大输液龙头
康泰生物:乙肝、肺炎疫苗龙头
我武生物:脱敏药龙头
鱼跃医疗:家用医疗器械龙头
健帆生物:血液灌流器械龙头
健友股份:肝素原料药龙头
华大基因:基因检测龙头
汤臣倍健:保健品龙头
欧普康视:角膜塑形镜龙头
三诺生物:血糖监测仪龙头
安图生物:化学发光试剂龙头
南微医学:微创手术器械龙头
大博医疗:骨科龙头
透景生命:体外试剂诊断龙头
通化东宝:糖尿病药龙头之一
甘李药业:糖尿病药龙头之一
山大华特:新生儿补充剂龙头
司太立: 造影剂龙头
戴维医疗:新生儿医疗器械龙头
沃森生物:肺炎疫苗和HPV疫苗龙头
凯利泰:椎体成形微创介入手术、骨科植入、骨科手术器械龙头。
三友医疗:脊椎类植入耗材、创伤类植入耗材龙头。
楚天科技:医药装备龙头。
华海药业:特色原料药龙头。全球最大的普利类和沙坦类药物提供商。
康美药业:国内中药饮品龙头。
卫宁健康:医疗信息龙头。
英科医疗:专精医用手套世界级龙头。
康龙化成:国内第二、全球第三的临床前CRO企业,次于药明康德。
昭衍新药:临床前CRO安全性评价龙头。
凯莱英:小分子化学制药CDMO龙头
药石科技:药物分子砌块领域CRO龙头
泰格医药:专注定位CRO这个细分市场并成为临床CRO行业龙头
通策医疗:国内口腔医疗龙头,从医生+口碑两个方面加深自己的护城河。
国瓷材料:全资子公司爱尔创在国内高端陶瓷牙用纳米氧化锆市占率第一。
爱美客:注射用玻尿酸龙头,聚焦于医美终端产品。公司研发能力很强,多款产品属于国内首款。
华熙生物:玻尿酸原料龙头,是世界最大的透明质酸生产及销售企业。全产业链布局,在医美和化妆品赛道持续发力。
金域医学:国内第三方医学检验龙头企业,行业核心在于数据积累,数据库越大,检验效率、准确率越高。
万孚生物:即时检测龙头,在POCT领域惟精惟一。
艾德生物:聚焦肿瘤检测。
大参林:国内连锁药店的龙头之一,四大药房中毛利率净利润率排名第一,盈利能力较强,稳扎稳打型。
益丰药房:国内连锁药店的龙头之一。
医疗行业是非常复杂的行业,很多公司都具备自己独特的立身之本,很多小公司靠一两个产品都能稳定于市场之中长期活下去,跟随医疗的上面三大逻辑不断壮大。各位朋友,今天的文章,建议大家收藏,有个大体了解就好。
分享阅读原文: https://henduan.com/Flkgz
敏捷为什么要使用Scrum而不是瀑布?
编程 星物种 发表了文章 0 个评论 3154 次浏览 2021-05-06 11:14

Scrum方法需要改变传统方法的思维方式。中心焦点已经从瀑布方法的范围转变为在Scrum中实现最大的商业价值。
在瀑布中,改变成本和进度以确保达到预期的范围,在Scrum中,可以改变质量和约束以实现获得最大商业价值的主要目标。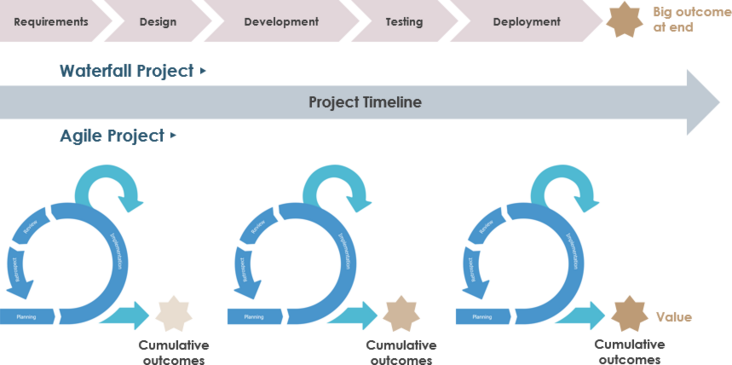
瀑布模型适用于有序和可预测的项目,其中所有要求都明确定义并且可以准确估计,并且在大多数行业中,此类项目正在减少。客户需求的变化导致企业适应和改变其交付方式的压力增大。
Scrum方法在当前市场中更为成功,其特点是不可预测性和波动性。Scrum方法基于inspect-adapt循环,而不是Waterfall方法的命令和控制结构。
Scrum项目以迭代方式完成,其中首先完成具有最高业务价值的功能。各个跨职能团队在Sprint中并行工作,以便在每个Sprint结束时提供潜在的可交付解决方案。
因为每次迭代都会产生可交付的解决方案(这是整个产品的一部分),所以团队必须实现可衡量的目标。这可确保团队正在进行,项目将按时完成。传统方法没有提供这种及时的检查,因此导致团队可能会下班并最终完成大量工作。
当客户定期与团队互动时,定期审查完成的工作; 因此,可以确保进度符合客户的要求。然而,在瀑布中没有这样的交互,因为工作是在筒仓中进行的,并且在项目结束之前没有可用的功能。
在复杂的项目中,客户不清楚他们在最终产品中需要什么,并且功能需求不断变化,迭代模型可以更灵活地确保在项目完成之前可以包含这些更改。
但是,当完成具有明确定义的功能的简单项目,并且当团队具有完成此类项目的先前经验(因此,估计将是准确的)时,瀑布方法可以是成功的。
敏捷 Vs 瀑布
下面是一个表格,可以更好地了解Scrum和瀑布的差异。
敏捷还是瀑布?
Standish Group的最新报告涵盖了他们在2013年至2017年期间研究的项目。在这段时间内,敏捷和瀑布的成功,挑战和失败的整体突破如下所示,敏捷项目成功的可能性大约是后者的2倍,失败的可能性降低1/3。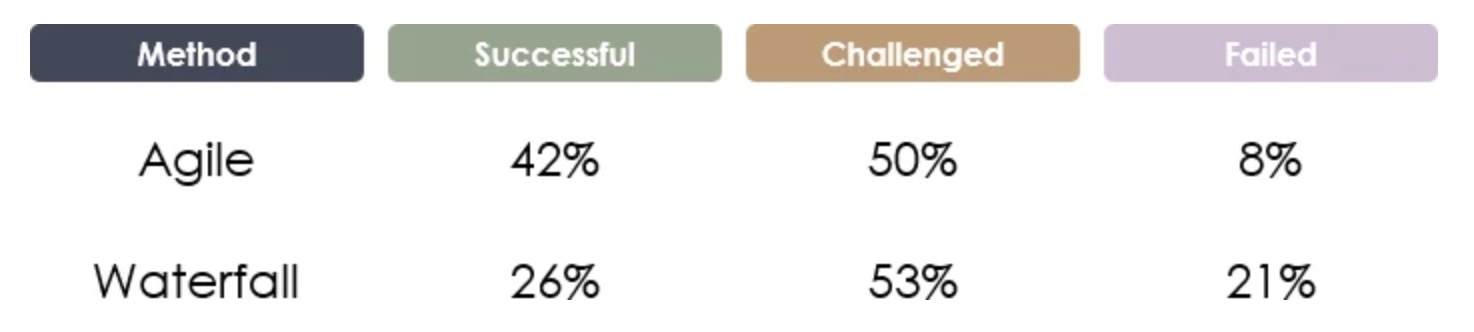
来源:vitalitychicago.com - 比较瀑布和敏捷项目成功率
cmake编译程序设置动态链接库加载路径
编程 OS小编 发表了文章 3 个评论 15243 次浏览 2021-05-06 10:42

编译运行的程序需要链接到程序所在路径下的某些个动态库,为方便移植,必须设置链接库的相对路径,比如./lib等等。默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定; - 通过配置
LD_LIBRARY_PATH来指定; - 在
/lib和/usr/lib中查找;
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
为了方便移植运行一些编译安装的应用程序,在编译的时候需要设置链接库读取的相对路径目录, 比如../lib 或者./lib。
默认在Linux系统下动态库的搜寻路径如下:
- 使用选项
-Wl,-rpath在编译时指定rpath; - 通过配置
LD_LIBRARY_PATH来指定,运行加载; - 在
/lib和/usr/lib等系统默认动态库路径中查找。
其中第一个在gcc编译选项中添加:-Wl,rpath=xxx会将rpath路径写入到程序中保存起来。
以下两种方式都可以用来配置rpath路径。
1、使用gcc编译选项:
add_definitions(-std=c++11)
SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g -ggdb -Wl,-rpath=./:./lib") #-Wl,-rpath=./
SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wl,-rpath=./:./lib") #-Wall
2、使用cmake配置
set(CMAKE_SKIP_BUILD_RPATH FALSE)
set(CMAKE_BUILD_WITH_INSTALL_RPATH TRUE)
set(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
set(CMAKE_INSTALL_RPATH "./lib")
或者
SET(CMAKE_SKIP_BUILD_RPATH FALSE)
SET(CMAKE_BUILD_WITH_INSTALL_RPATH FALSE)
SET(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib:$ORIGIN/lib")
SET(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
其中RPATH可以使用"./lib"或"./"配置,有可以使用"$ORIGIN/lib"或"\${ORIGIN}/lib",这里必须加上\符号,否则无法识别。
还可以同时定义多个RPATH,比如:"$ORIGIN:$ORIGIN/lib",中间使用:分割。
参考:https://blog.csdn.net/wh8_2011/article/details/79519293
CMAKE和RPATH:https://blog.csdn.net/zhangzq86/article/details/80718559
CMAKE中RPATH的用法:https://blog.csdn.net/z296671124/article/details/86699720
Linux C编程使用相对路径加载动态库: https://blog.csdn.net/dreamcs/article/details/52138229
每个伟大的产品需要一个伟大的ScrumMaster
编程 星物种 发表了文章 1 个评论 2415 次浏览 2021-05-04 10:31

摘要
产品负责人和ScrumMaster是两个相互补充的独立敏捷角色。 为了出色地完成工作,产品所有者需要在他们身边强大的ScrumMaster。
不幸的是,我发现通常缺少可以支持产品所有者的ScrumMaster。 有时角色之间会混淆,或者根本没有ScrumMaster。
这篇文章解释了这两个角色之间的区别,产品所有者应该从他们的ScrumMaster中获得什么,以及ScrumMasters从他们中可以期待什么。
产品负责人与ScrumMaster
产品负责人和ScrumMaster是相互补充的两个不同角色。 如果其中一个位置不正确,则另一个会受到影响。 作为产品负责人 ,您应对产品的成功负责-创造一种对用户和客户的工作都非常出色并满足其业务目标的产品。 因此,您可以与用户和客户以及内部利益相关者,开发团队和ScrumMaster进行交互,如下图所示。
上图中的灰色圆圈描述了由产品所有者,ScrumMaster和跨功能开发团队组成的Scrum团队。
ScrumMaster负责流程的成功 -帮助产品负责人和团队使用正确的流程来创建成功的产品,并促进组织变革和建立敏捷的工作方式。 因此,ScrumMaster与产品所有者和开发团队以及受Scrum影响的高级管理层,人力资源(HR)和业务组合作,如下图所示:
要成功成为产品负责人,需要正确的技能,时间,精力和重点。 扮演ScrumMaster角色也是如此。 将这两个角色(甚至是部分角色)组合在一起不仅非常具有挑战性,而且意味着忽略了某些职责。 如果您是产品所有者,请不要承担ScrumMaster的职责!
产品负责人对ScrumMaster的期望
作为产品所有者,您应该从以下几种方面受益于ScrumMaster的工作。 ScrumMaster应该指导团队,以便团队成员可以构建出色的产品,促进组织变革,以便组织利用Scrum并帮助您完成出色的工作:
下表详细说明了您应该从ScrumMaster获得的支持:
ScrumMaster支持您作为产品所有者,因此您可以专注于自己的工作-确保创建具有正确用户体验(UX)和正确功能的正确产品。 如果您的ScrumMaster不提供或无法提供此支持,请与个人联系,并找出问题所在。 不要介入并接管ScrumMaster的工作。 如果您没有ScrumMaster,请将上面的列表显示给您的高级管理层赞助商或老板,以解释为什么您需要身边有合格的ScrumMaster。
ScrumMaster应该对产品负责人有什么期望
Tango花了两个时间,ScrumMaster对您作为产品所有者的工作抱有期望,这是公平的。 下图说明了其中的一些: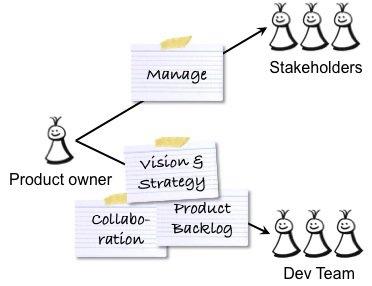
下表更详细地描述了ScrumMaster的期望:
Scrum是一个用于开发和维护复杂产品的框架
编程 星物种 发表了文章 0 个评论 2232 次浏览 2021-05-04 09:30

Scrum是一个用于开发和维护复杂产品的框架 ,是一个增量的、迭代的开发过程。在这个框架中,整个开发过程由若干个短的迭代周期组成,一个短的迭代周期称为一个Sprint,每个Sprint的建议长度是2到4周(互联网产品研发可以使用1周的Sprint)。
在Scrum中,使用产品Backlog来管理产品的需求,产品backlog是一个按照商业价值排序的需求列表,列表条目的体现形式通常为用户故事。Scrum团队总是先开发对客户具有较高价值的需求。在Sprint中,Scrum团队从产品Backlog中挑选最高优先级的需求进行开发。
挑选的需求在Sprint计划会议上经过讨论、分析和估算得到相应的任务列表,我们称它为Sprint backlog。在每个迭代结束时,Scrum团队将递交潜在可交付的产品增量。 Scrum起源于软件开发项目,但它适用于任何复杂的或是创新性的项目。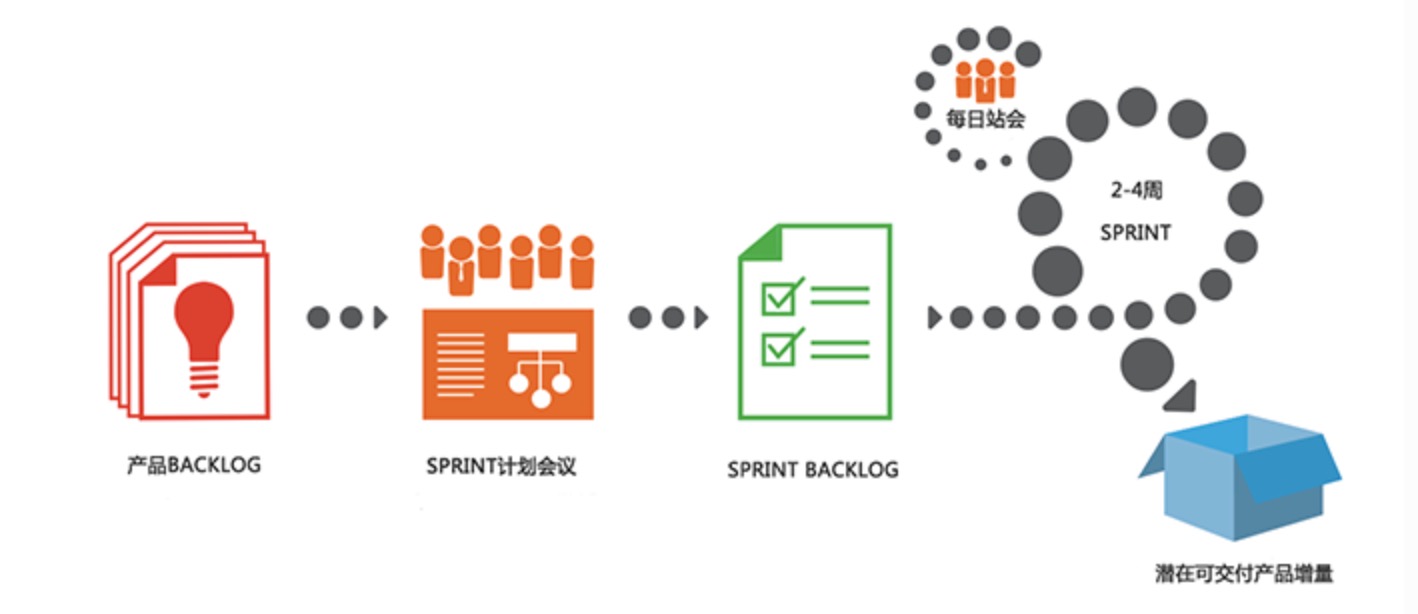
SCRUM框架包括3个角色、3个工件、5个事件、5个价值
3个角色
- 产品负责人(Product Owner)
- Scrum Master
- 开发团队
3个工件
- 产品Backlog(Product Backlog)
- SprintBacklog
- 产品增量(Increment)
5个事件
- Sprint(Sprint本身是一个事件,包括了如下4个事件)
- Sprint计划会议(Sprint Planning Meeting)
- 每日站会(Daily Scrum Meeting)
- Sprint评审会议(Sprint Review Meeting)
- Sprint回顾会议(Sprint Retrospective Meeting)
5个价值
- 承诺 – 愿意对目标做出承诺
- 专注– 把你的心思和能力都用到你承诺的工作上去
- 开放– Scrum 把项目中的一切开放给每个人看
- 尊重– 每个人都有他独特的背景和经验
- 勇气– 有勇气做出承诺,履行承诺,接受别人的尊重
SCRUM理论基础
Scrum以经验性过程控制理论(经验主义)做为理论基础的过程。经验主义主张知识源于经验, 以及基于已知的东西做决定。Scrum 采用迭代、增量的方法来优化可预见性并控制风险。
Scrum 的三大支柱支撑起每个经验性过程控制的实现:透明性、检验和适应。Scrum的三大支柱如下:
第一:透明性(Transparency)
透明度是指,在软件开发过程的各个环节保持高度的可见性,影响交付成果的各个方面对于参与交付的所有人、管理生产结果的人保持透明。管理生产成果的人不仅要能够看到过程的这些方面,而且必须理解他们看到的内容。也就是说,当某个人在检验一个过程,并确信某一个任务已经完成时,这个完成必须等同于他们对完成的定义。
第二:检验(Inspection)
开发过程中的各方面必须做到足够频繁地检验,确保能够及时发现过程中的重大偏差。在确定检验频率时,需要考虑到检验会引起所有过程发生变化。当规定的检验频率超出了过程检验所能容许的程度,那么就会出现问题。幸运的是,软件开发并不会出现这种情况。另一个因素就是检验工作成果人员的技能水平和积极性。
第三:适应(Adaptation)
如果检验人员检验的时候发现过程中的一个或多个方面不满足验收标准,并且最终产品是不合格的,那么便需要对过程或是材料进行调整。调整工作必须尽快实施,以减少进一步的偏差。
Scrum中通过三个活动进行检验和适应:每日例会检验Sprint目标的进展,做出调整,从而优化次日的工作价值;Sprint评审和计划会议检验发布目标的进展,做出调整,从而优化下一个Sprint的工作价值;Sprint回顾会议是用来回顾已经完成的Sprint,并且确定做出什么样的改善可以使接下来的Sprint更加高效、更加令人满意,并且工作更快乐。
全文阅读:https://www.scrumcn.com/agile/scrum-knowledge-library/scrum.html





