
通知设置 新通知
kafka利用命令查看consumer消费情况
空心菜 回复了问题 1 人关注 2 个回复 11019 次浏览 2019-06-05 07:51
搜索引擎科学上网技能大放送
Nock 发表了文章 1 个评论 5502 次浏览 2017-01-13 00:06

在今天,用户可以通过搜索引擎轻松找出自己想要的信息,但还是难以避免结果不尽如人意的情况。实际上,用户仅需掌握几个常用技巧即可轻松化解这种尴尬。
正常情况下我们搜索的关键是正确的关键词和搜搜引擎的选择,通过正确的搜索我们能得到答案的问题可以到80%以上。
常用引擎推荐
No.1 谷歌(https://google.com)
No.2 百度 (https://www.baidu.com/)
No.3 鸭鸭快跑 (https://duckduckgo.com/)
No.4 必应 (http://cn.bing.com/ )
No.5 搜狗 (https://www.sogou.com/)
排错搜索过程
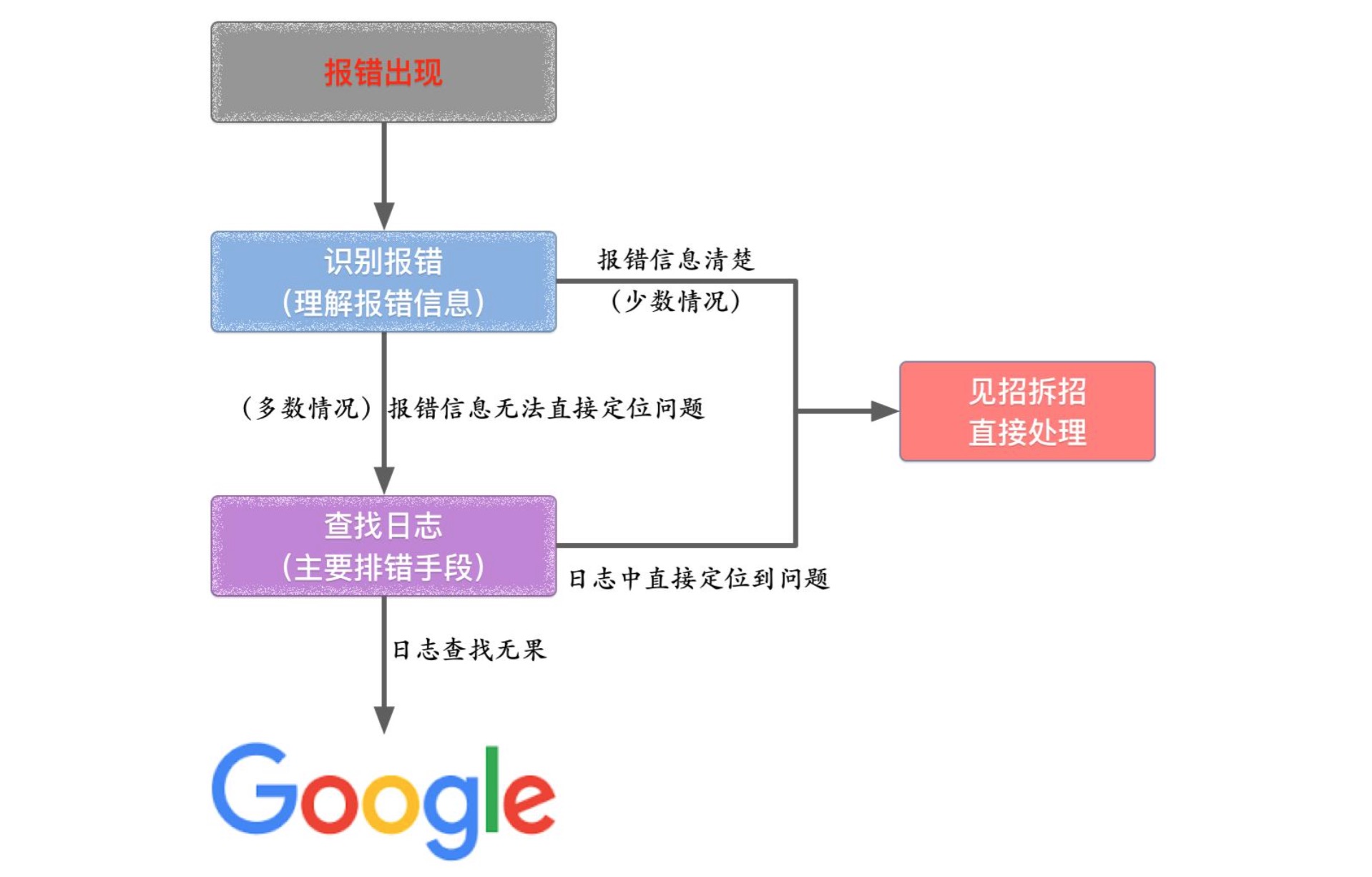
1、准确搜索
最简单、有效的准确搜索方式是在关键词上加上双引号,在这种情况下,搜索引擎只会反馈和关键词完全吻合的搜索结果, 把搜索词放在双引号中,代表完全匹配搜索,也就是说搜索结果返回的页面包含双引号中出现的所有的词,连顺序也必 须完全匹配.
比方说在搜索「zabbix mysql」的时候,在没有给关键词加上双引号的情况,搜索引擎会显示所有分别和「zabbix」以及「mysql」相关的信息,但这些显然并不是我们想要的结果。但在加上双引号后,搜索引擎则仅会在页面上反馈和「zabbix mysql」相吻合的信息。
准确搜索在排除常见但相近度偏低的信息时非常有用,可以为用户省去再度对结果进行筛选的麻烦。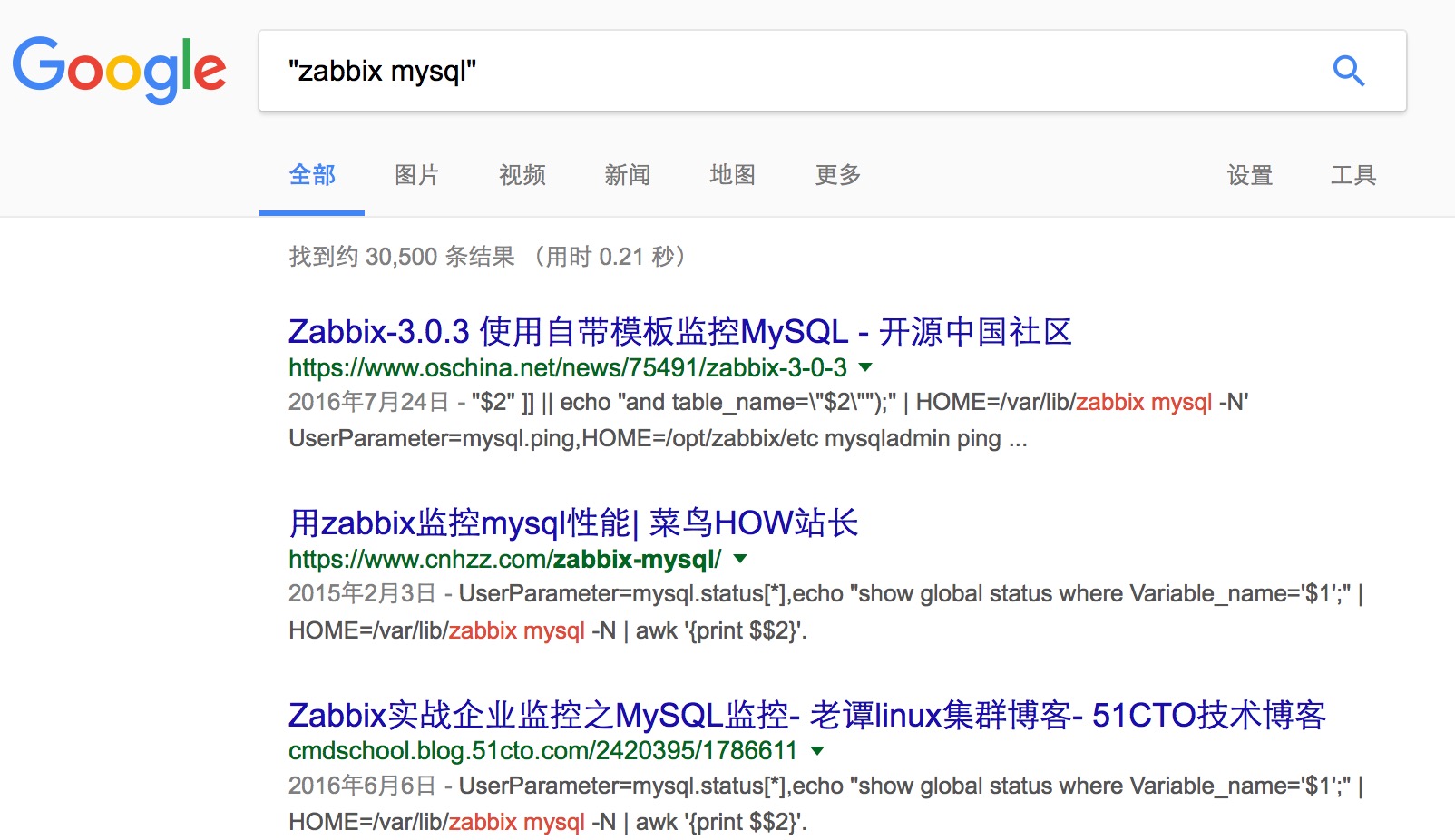
2、加号
在搜索引擎框里把多个关键字用加号(+)连接起来,搜索引擎就会自动去匹配互联网上与所有关键词相关的内容,默认与 空格等效,百度和Google都支持。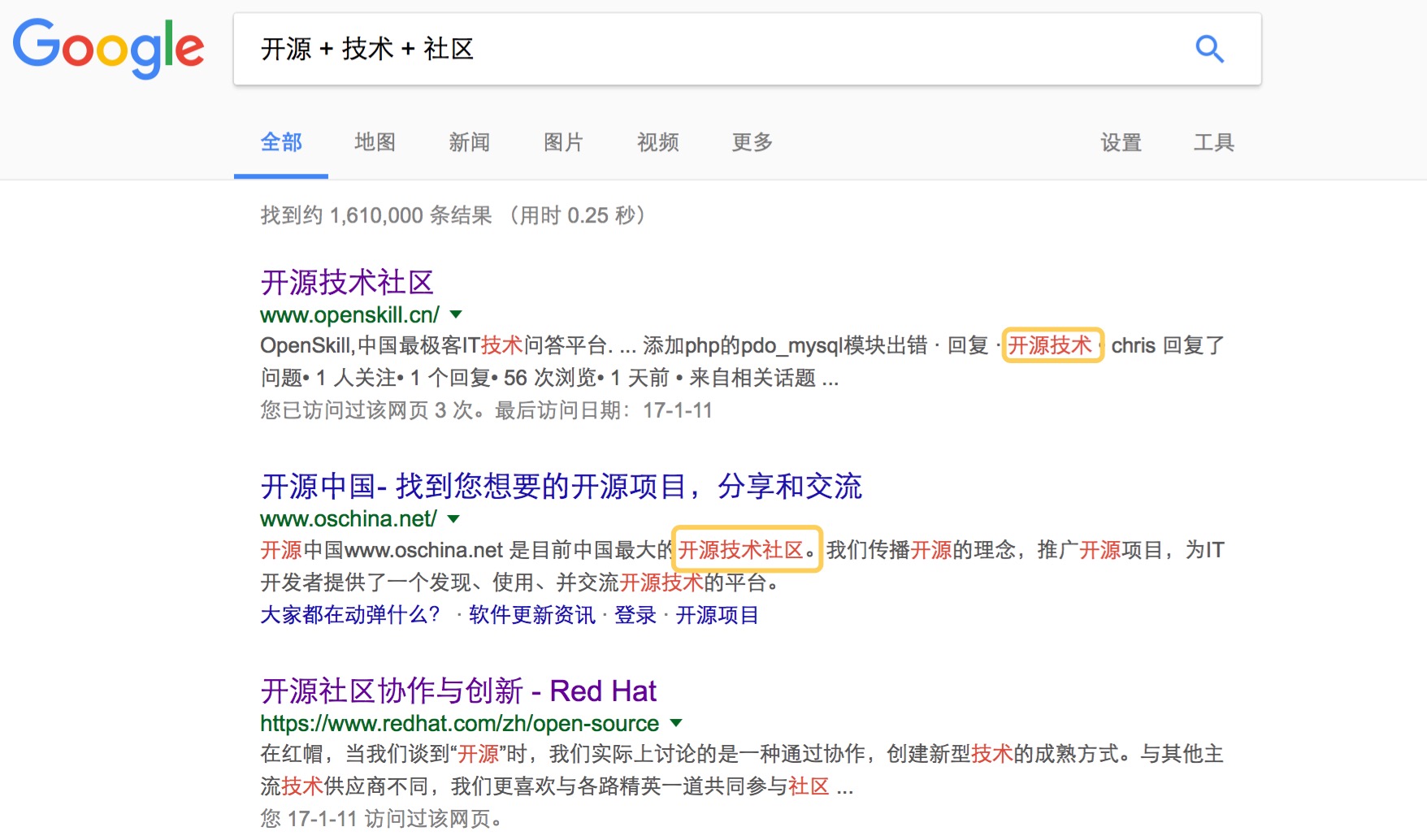
3、减号-排除关键词
如果在进行准确搜索时没有找到自己想要的结果,用户可以对包含特定词汇的信息进行排除,仅需使用减号即可。
减号代表搜索不包含减号后面的词的页面。使用这个指令时减号前面必须是空格,减号后面没有空格,紧跟着需要排除的词 。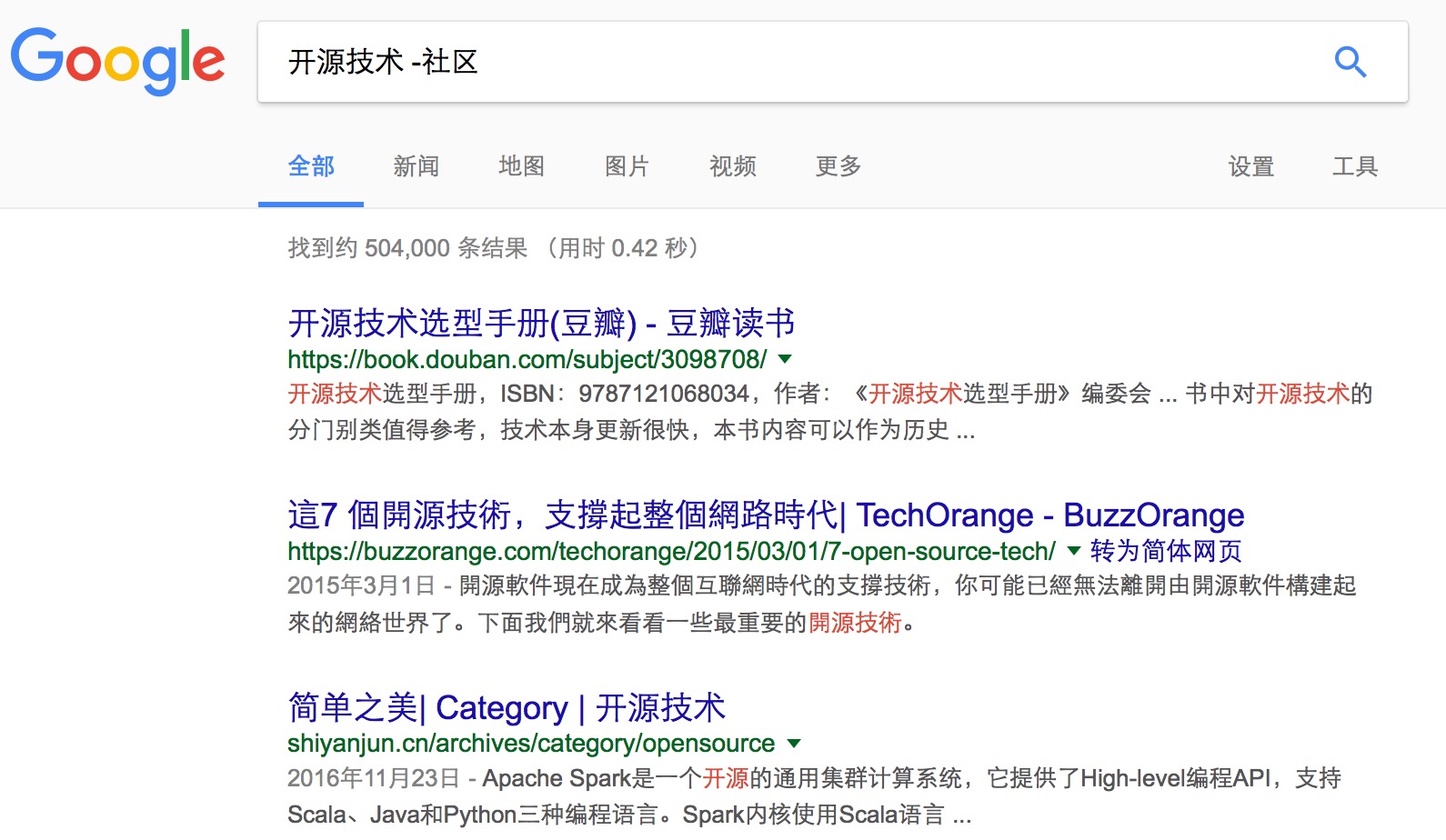
4、OR或逻辑搜索
在默认搜索下,搜索引擎会反馈所有和查询词汇相关的结果,但通过使用「OR」逻辑,你可以得到和两个关键词分别相关的结果,而不仅仅是和两个关键词 都同时相关的结果。巧妙使用「OR」搜索可以让你在未能确定哪个关键词对于搜索结果起决定作用时依然可以确保搜索结果的准确性。
5、同义词搜索
有时候对不太确切的关键词进行搜索反而会显得更加合适。在未能准确判断关键词的情况下,你可以通过同义词进行搜索。
如果你在搜索引擎输入「plumbing ~university」,你所得到的反馈结果会包含「plumbing universities」和「plumbing colleges」等相似条目。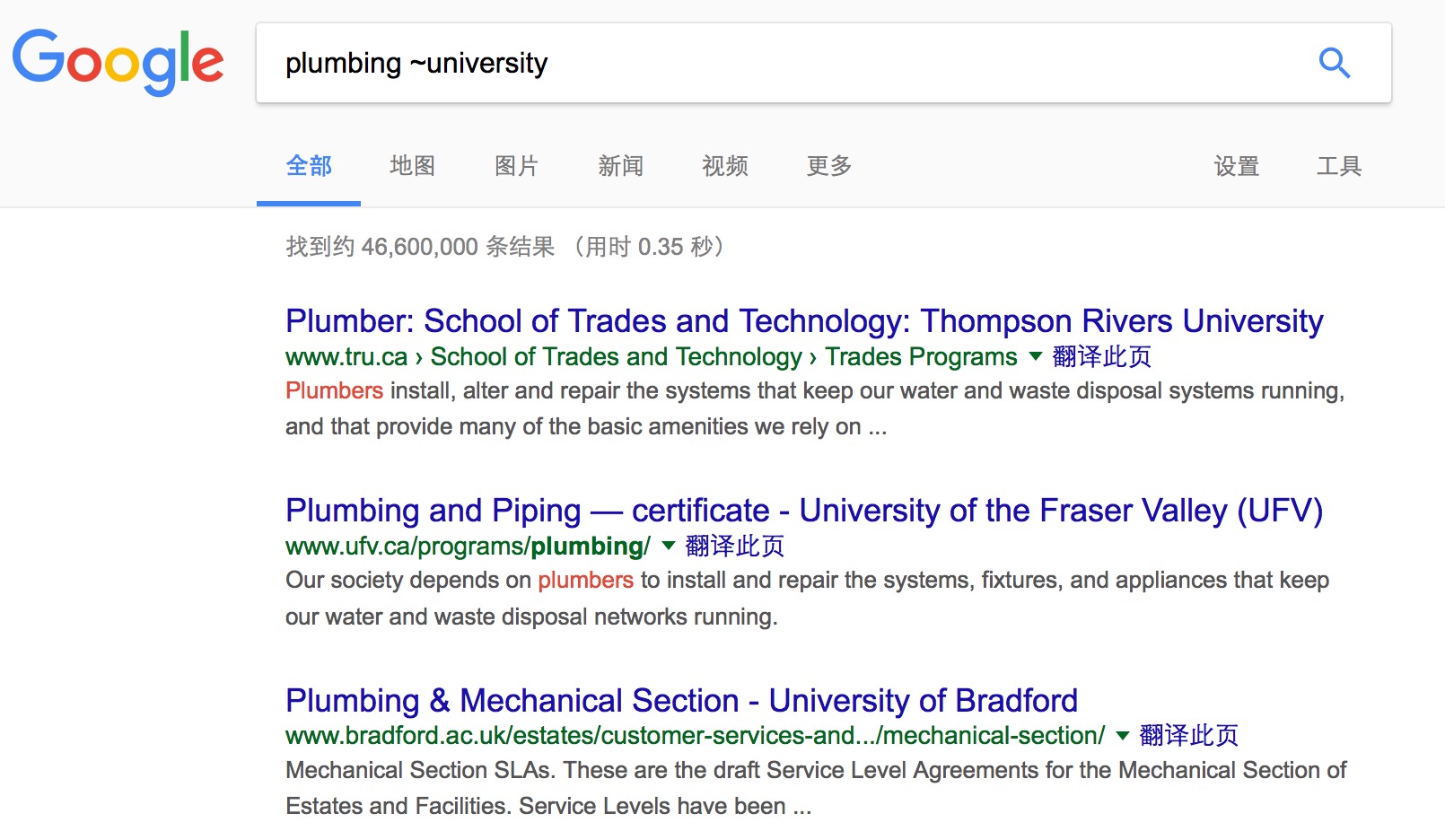
6、善用星号
正如拼图游戏「Scrabble」的空白方块一样,在搜索引擎中,我们可以用星号填补关键词中的缺失部分,不论缺失的是一连串单词的其中一个还是一个单词的某一部分。此外,当你希望搜索一篇确定性偏低的文章时,也可以使用星号填补缺失部分。
例如,如果你在搜索引擎中输入「architect*」,你所得到的反馈结果将会是所有包含 architect、architectural、architecture、architected、architecting 以及其他所有以「architect」作为开头的词汇的条目。
常用的案例:搜索报错中的特定路径 , 有个词忘记了或者不会打: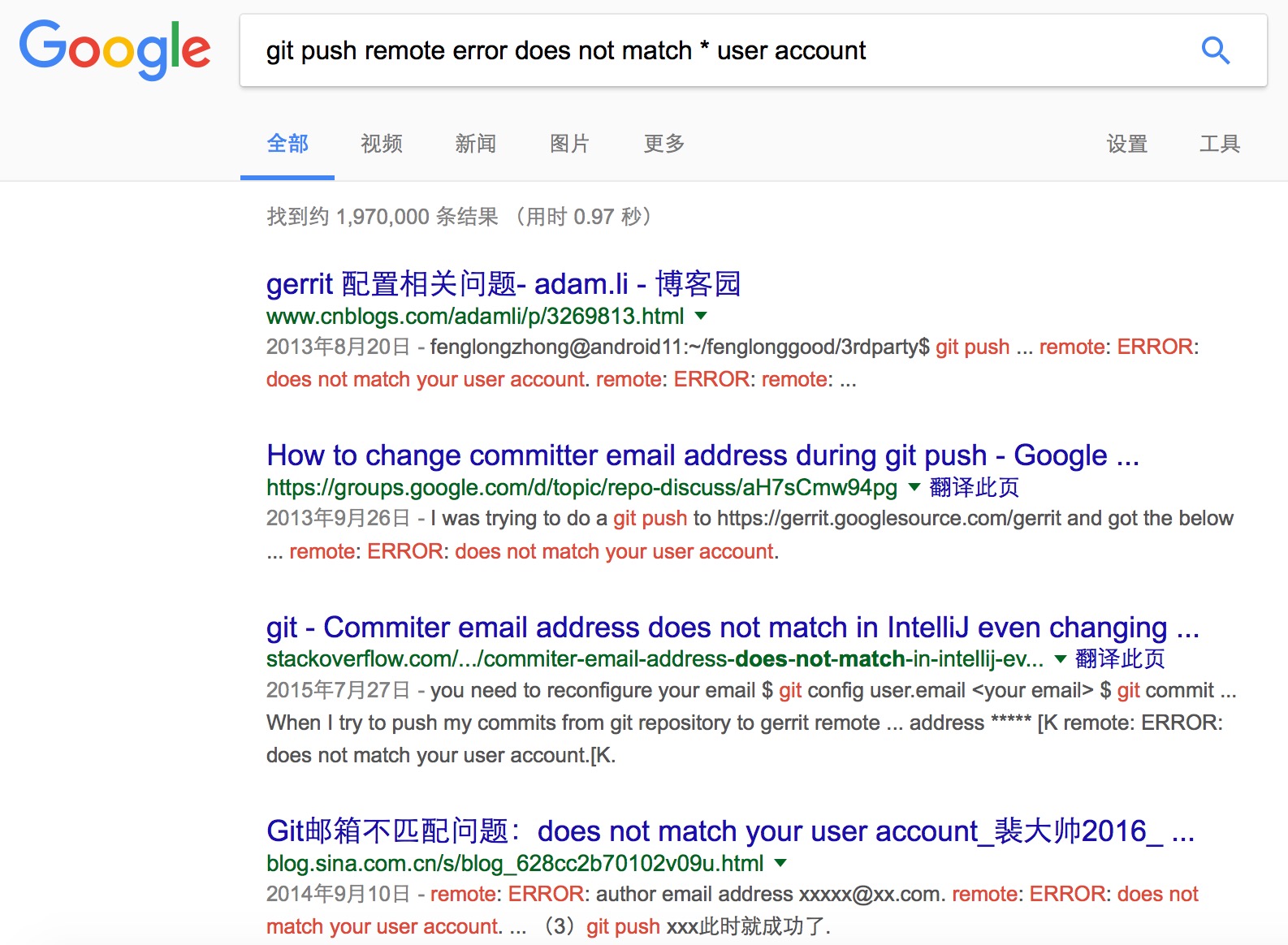
7、在两个数值之间进行搜索
在寻找问题的答案时,一个很好的方法是在一定范围内寻找和关键词相关的资讯。例如想要找出 1920 至 1950 年间的英国首相,直接在搜索引擎中输入「英国首相 1920.. 1950」即可得出想要的结果。
记住,数值之间的符号是两个英文句号加一个空格键。
8、inurl
该指令用于搜索查询词出现在url中的页面。BaiDu和Google都支持inurl指令。inurl指令支持中文和英文。 比如搜索:inurl:hadoop,返回的结果都是网址url中包含“hadoop”的页面。由于关键词出现在url 中对排名有一定影响,使用inurl:搜索可以更准确地找到与关键字相关的内容。
例如:inurl:openskill hadoop
9、intitle在网页标题、链接和主体中搜索关键词
有时你或许会遇上找出所有和关键词相关的所有网页标题、链接和网页主体的需求,在这个时候你需要使用的是限定词「inurl:」(供在 url 链接中搜索使用)、「intext:」(供在网页主体中搜索使用)以及「intitle:」(供在网页标题中搜索使用)。
使用intitle 指令找到的文件更为准确。出现在title中,说明页面内容跟关键字有很大关联。
10、allintitle
allintitle:搜索返回的是页面标题中包含多组关键词的文件。例如 :allintitle:zabbix docker,就相当于:intitle:zabbix intitle:docker,返回的是标题中中既包含“zabbix”,也包含“docker”的页面,显著提高搜索命中率。
11、allinurl
与allintitle: 类似,allinurl:zabbix hadoop,就相当于 : inurl:zabbix inurl:hadoop
12、site站内搜索
绝大部分网站的搜索功能都有所欠缺,因此,更好的方法是通过 Google 等搜索引擎对站内的信息进行搜索。
你只需要在搜索引擎上输入「site:openskill.cn」加上关键词,搜索引擎就会反馈网站「openskill.cn」内和关键词相关的所有条目。如果再结合准确搜索功能,这项功能将会变得更加强大。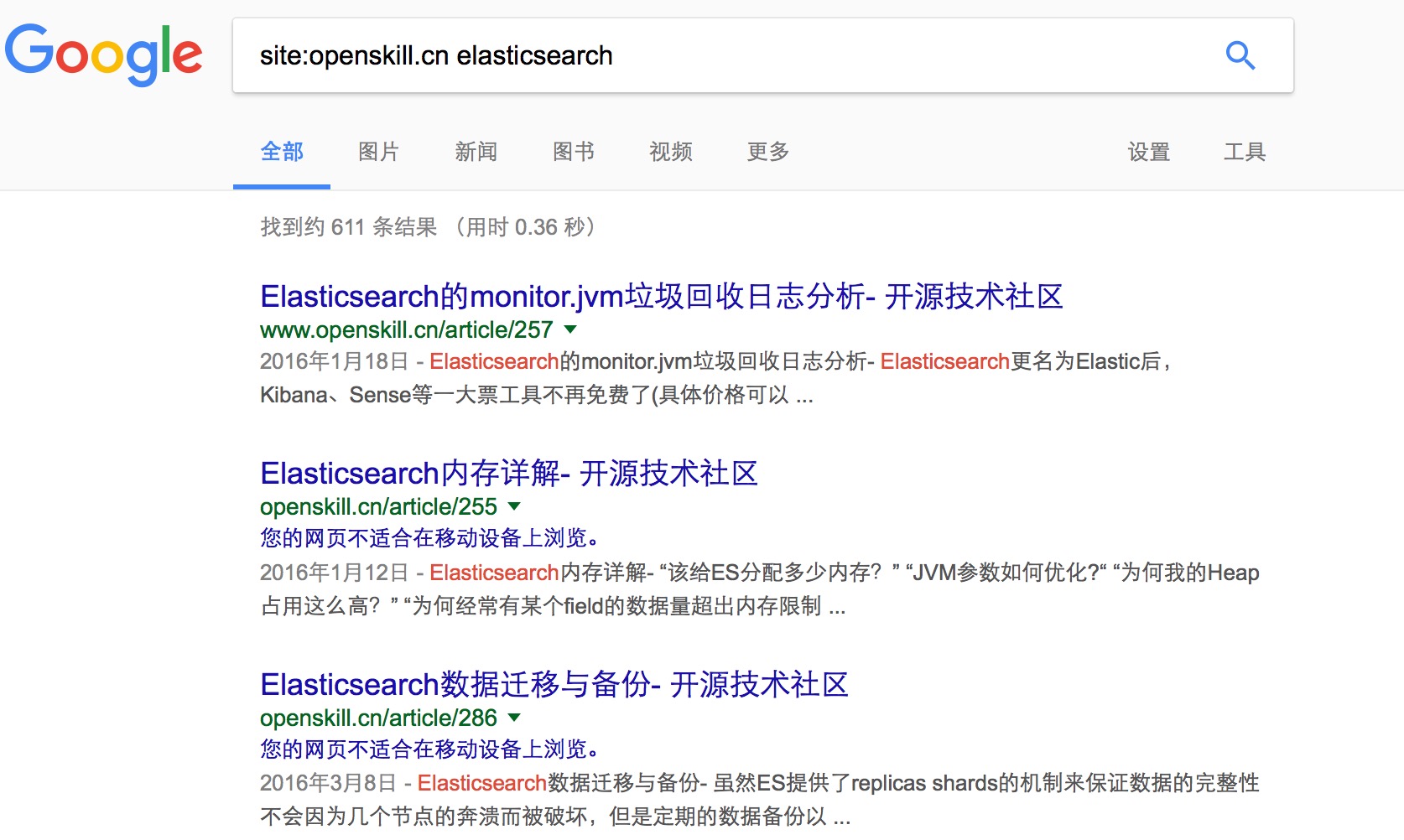
13、filetype
用于搜索特定文件格式。Google 和bd都支持filetype指令。 比如搜索filetype:pdf docker 返回的就是包含SEO 这个关键词的所有pdf 文件。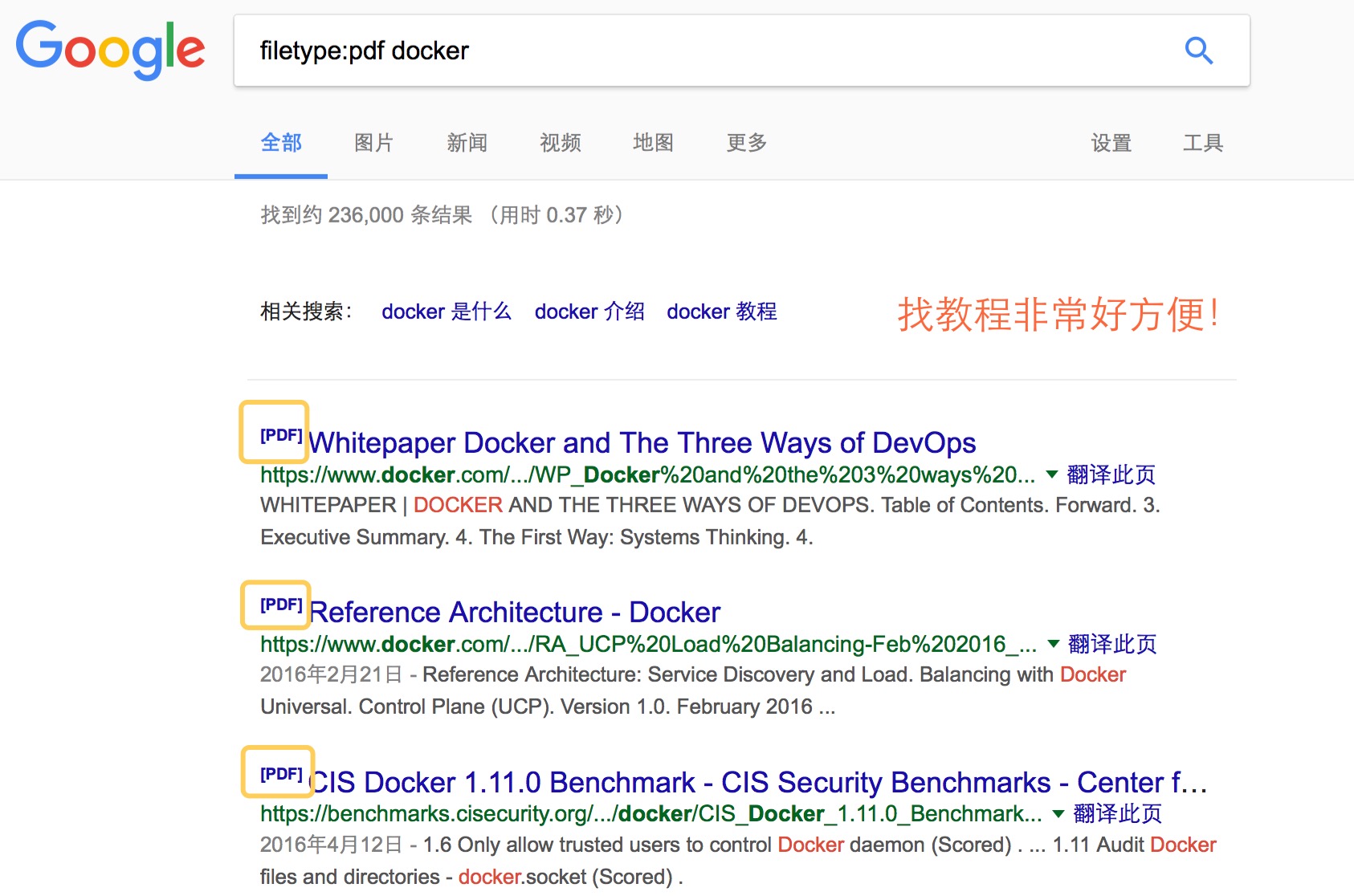
14、搜索相关网站
查找与您已浏览过的网址类似的网站, 例如,你仅需在搜索引擎中输入「related:openskill.cn」即可得到所有和「openskill.cn」相关的网站反馈结果。
15、搜索技能的组合使用
你可以对上述所有搜索技能进行组合运用,以便按照自己的意愿缩小或者扩展搜索范围。尽管有些技能或许并不常用,但准确搜索和站内搜索这些技能的使用范围还是相当广泛的。
其他技巧

随着 Google 等搜索引擎对于用户自然语言的理解程度与日俱增,这些搜索技能可以派上用场的情况或许将会变得越来越少,至少这是所有搜索引擎共同追求的目标。但是在当下,掌握这些搜索技能还是非常必要的。
参考:http://www.cnblogs.com/feiyuhuo/p/5398238.html http://blog.jobbole.com/72211/
京东咚咚架构演进
koyo 发表了文章 0 个评论 4084 次浏览 2016-08-24 22:26


咚咚是什么?咚咚之于京东相当于旺旺之于淘宝,它们都是服务于买家和卖家的沟通。 自从京东开始为第三方卖家提供入驻平台服务后,咚咚也就随之诞生了。 我们首先看看它诞生之初是什么样的。
1.0 诞生(2010 - 2011)
为了业务的快速上线,1.0 版本的技术架构实现是非常直接且简单粗暴的。 如何简单粗暴法?请看架构图,如下: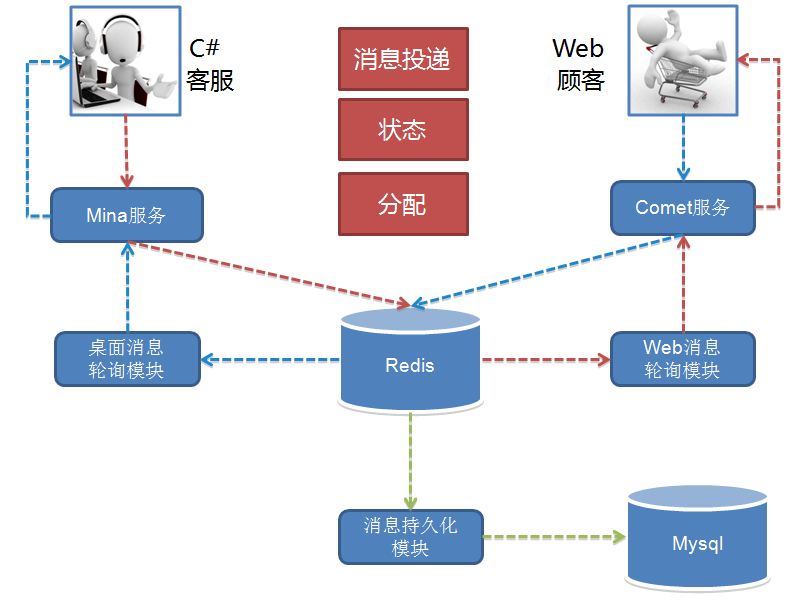
1.0 的功能十分简单,实现了一个 IM 的基本功能,接入、互通消息和状态。 另外还有客服功能,就是顾客接入咨询时的客服分配,按轮询方式把顾客分配给在线的客服接待。 用开源 Mina 框架实现了 TCP 的长连接接入,用 Tomcat Comet 机制实现了 HTTP 的长轮询服务。 而消息投递的实现是一端发送的消息临时存放在 Redis 中,另一端拉取的生产消费模型。
这个模型的做法导致需要以一种高频率的方式来轮询 Redis 遍历属于自己连接的关联会话消息。 这个模型很简单,简单包括多个层面的意思:理解起来简单;开发起来简单;部署起来也简单。 只需要一个 Tomcat 应用依赖一个共享的 Redis,简单的实现核心业务功能,并支持业务快速上线。
但这个简单的模型也有些严重的缺陷,主要是效率和扩展问题。 轮询的频率间隔大小基本决定了消息的延时,轮询越快延时越低,但轮询越快消耗也越高。 这个模型实际上是一个高功耗低效能的模型,因为不活跃的连接在那做高频率的无意义轮询。 高频有多高呢,基本在 100 ms 以内,你不能让轮询太慢,比如超过 2 秒轮一次,人就会在聊天过程中感受到明显的会话延迟。 随着在线人数增加,轮询的耗时也线性增长,因此这个模型导致了扩展能力和承载能力都不好,一定会随着在线人数的增长碰到性能瓶颈。
1.0 的时代背景正是京东技术平台从 .NET 向 Java 转型的年代,我也正是在这期间加入京东并参与了京东主站技术转型架构升级的过程。 之后开始接手了京东咚咚,并持续完善这个产品,进行了三次技术架构演进。
2.0 成长(2012)
我们刚接手时 1.0 已在线上运行并支持京东 POP(开放平台)业务,之后京东打算组建自营在线客服团队并落地在成都。 不管是自营还是 POP 客服咨询业务当时都起步不久,1.0 架构中的性能和效率缺陷问题还没有达到引爆的业务量级。 而自营客服当时还处于起步阶段,客服人数不足,服务能力不够,顾客咨询量远远超过客服的服务能力。 超出服务能力的顾客咨询,当时我们的系统统一返回提示客服繁忙,请稍后咨询。 这种状况导致高峰期大量顾客无论怎么刷新请求,都很可能无法接入客服,体验很差。 所以 2.0 重点放在了业务功能体验的提升上,如下图所示: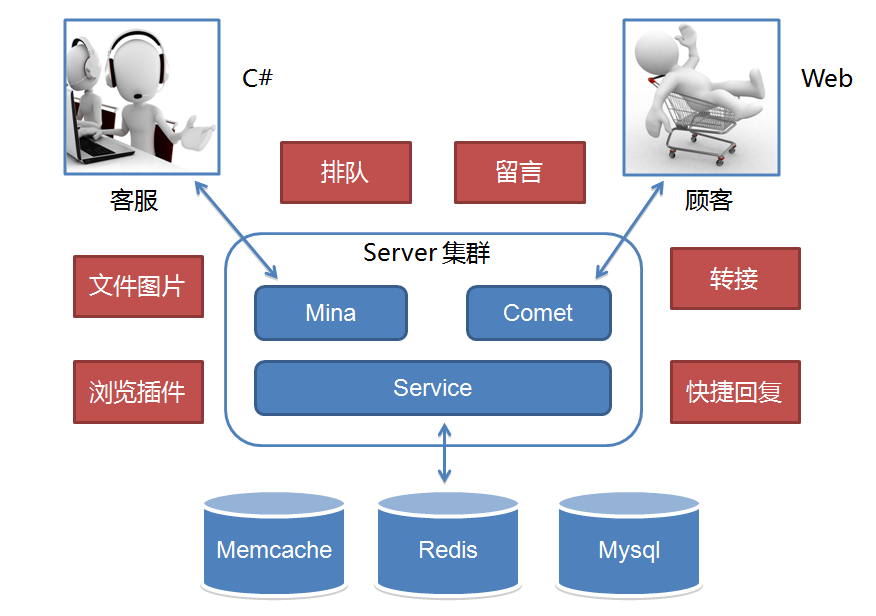
针对无法及时提供服务的顾客,可以排队或者留言。 针对纯文字沟通,提供了文件和图片等更丰富的表达方式。 另外支持了客服转接和快捷回复等方式来提升客服的接待效率。 总之,整个 2.0 就是围绕提升客服效率和用户体验。 而我们担心的效率问题在 2.0 高速发展业务的时期还没有出现,但业务量正在逐渐积累,我们知道它快要爆了。 到 2012 年末,度过双十一后开始了 3.0 的一次重大架构升级。
3.0 爆发(2013 - 2014)
经历了 2.0 时代一整年的业务高速发展,实际上代码规模膨胀的很快。 与代码一块膨胀的还有团队,从最初的 4 个人到近 30 人。 团队大了后,一个系统多人开发,开发人员层次不一,规范难统一,系统模块耦合重,改动沟通和依赖多,上线风险难以控制。 一个单独 tomcat 应用多实例部署模型终于走到头了,这个版本架构升级的主题就是服务化。
服务化的第一个问题如何把一个大的应用系统切分成子服务系统。 当时的背景是京东的部署还在半自动化年代,自动部署系统刚起步,子服务系统若按业务划分太细太多,部署工作量很大且难管理。 所以当时我们不是按业务功能分区服务的,而是按业务重要性级别划分了 0、1、2 三个级别不同的子业务服务系统。 另外就是独立了一组接入服务,针对不同渠道和通信方式的接入端,见下图。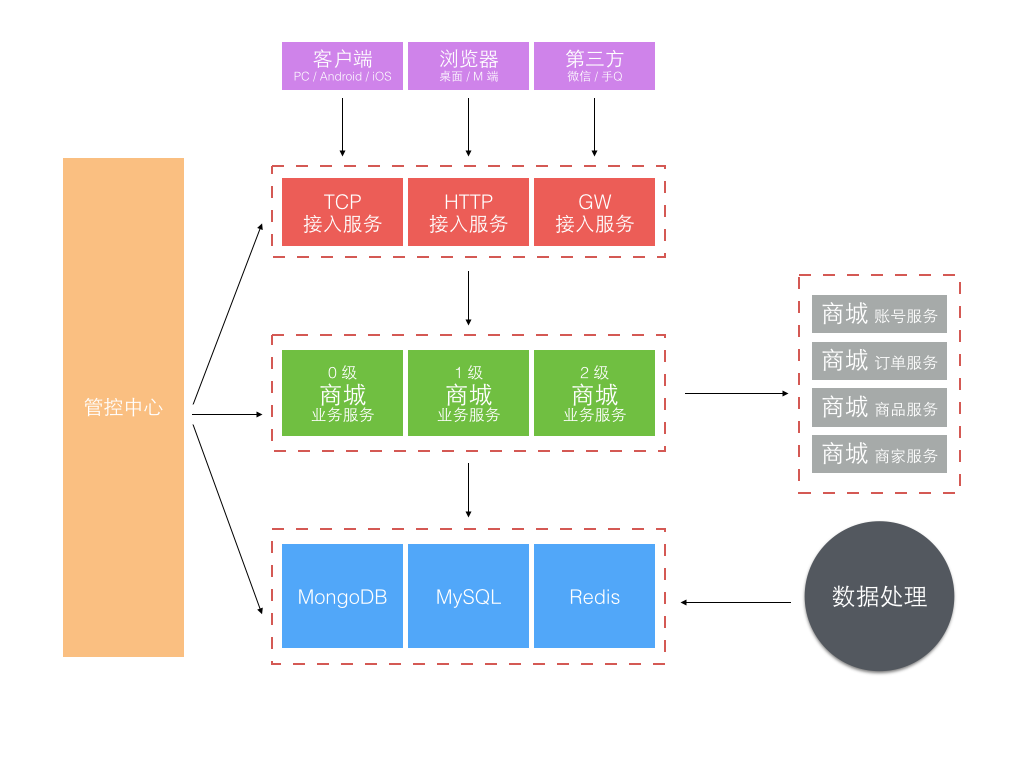
更细化的应用服务和架构分层方式可见下图: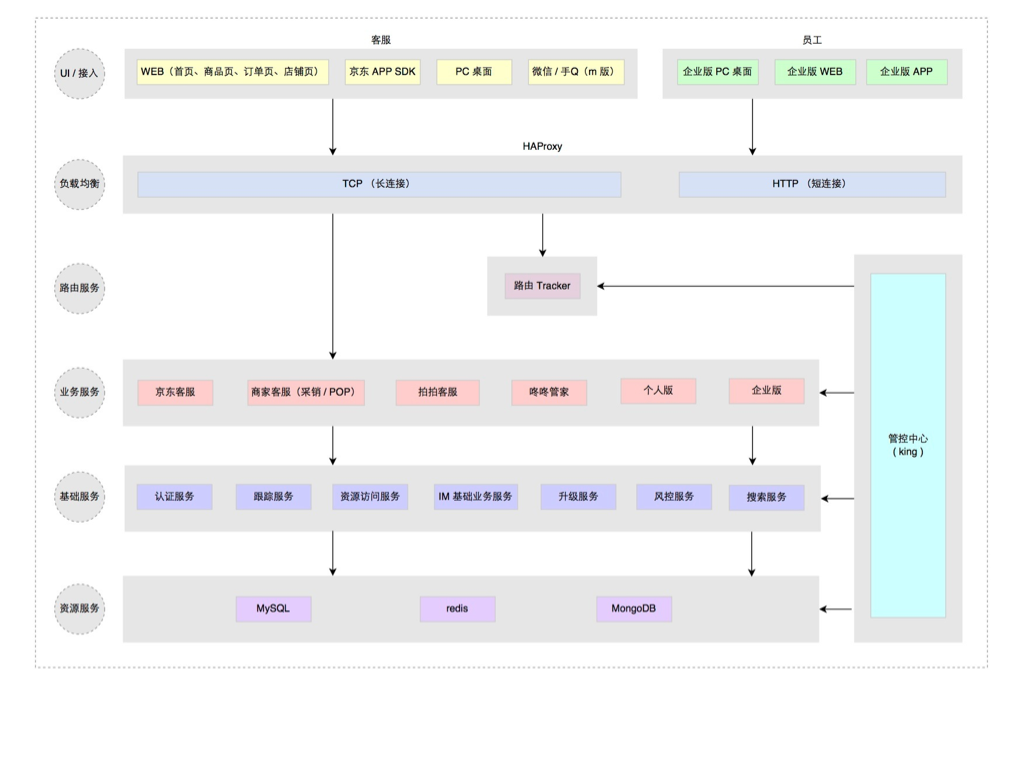
这次大的架构升级,主要考虑了三个方面:稳定性、效率和容量。 做了下面这些事情:
- 业务分级、核心、非核心业务隔离;
- 多机房部署,流量分流、容灾冗余、峰值应对冗余;
- 读库多源,失败自动转移;
- 写库主备,短暂有损服务容忍下的快速切换;
- 外部接口,失败转移或快速断路;
- Redis 主备,失败转移;
- 大表迁移,MongoDB 取代 MySQL 存储消息记录;
- 改进消息投递模型
前 6 条基本属于考虑系统稳定性、可用性方面的改进升级。 这一块属于陆续迭代完成的,承载很多失败转移的配置和控制功能在上面图中是由管控中心提供的。
第 7 条主要是随着业务量的上升,单日消息量越来越大后,使用了 MongoDB 来单独存储量最大的聊天记录。 第 8 条是针对 1.0 版本消息轮询效率低的改进,改进后的投递方式如下图所示: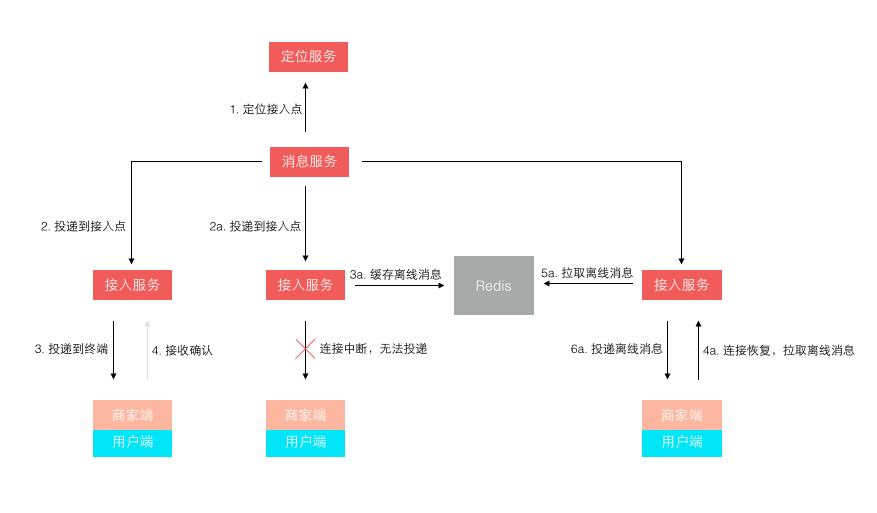
不再是轮询了,而是让终端每次建立连接后注册接入点位置,消息投递前定位连接所在接入点位置再推送过去。 这样投递效率就是恒定的了,而且很容易扩展,在线人数越多则连接数越多,只需要扩展接入点即可。 其实,这个模型依然还有些小问题,主要出在离线消息的处理上,可以先思考下,我们最后再讲。
3.0 经过了两年的迭代式升级,单纯从业务量上来说还可以继续支撑很长时间的增长。 但实际上到 2014 年底我们面对的不再是业务量的问题,而是业务模式的变化。 这直接导致了一个全新时代的到来。
4.0 涅槃(2015 至今 )
2014 年京东的组织架构发生了很大变化,从一个公司变成了一个集团,下设多个子公司。 原来的商城成为了其中一个子公司,新成立的子公司包括京东金融、京东智能、京东到家、拍拍、海外事业部等。 各自业务范围不同,业务模式也不同,但不管什么业务总是需要客服服务。 如何复用原来为商城量身订做的咚咚客服系统并支持其他子公司业务快速接入成为我们新的课题。
最早要求接入的是拍拍网,它是从腾讯收购的,所以是完全不同的账户和订单交易体系。 由于时间紧迫,我们把为商城订做的部分剥离,基于 3.0 架构对接拍拍又单独订做了一套,并独立部署,像下面这样。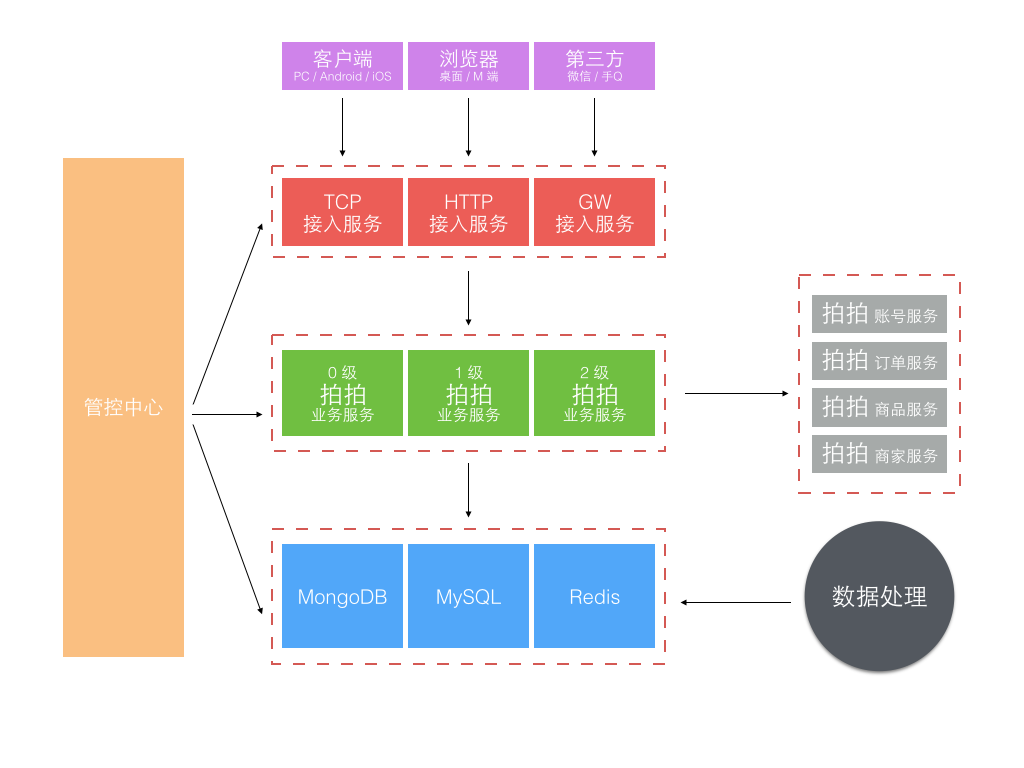
虽然在业务要求的时间点前完成了上线,但这样做也带来了明显的问题:
- 复制工程,定制业务开发,多套源码维护成本高
- 独立部署,至少双机房主备外加一个灰度集群,资源浪费大
以前我们都是面向业务去架构系统,如今新的业务变化形势下我们开始考虑面向平台去架构,在统一平台上跑多套业务,统一源码,统一部署,统一维护。 把业务服务继续拆分,剥离出最基础的 IM 服务,IM 通用服务,客服通用服务,而针对不同的业务特殊需求做最小化的定制服务开发。 部署方式则以平台形式部署,不同的业务方的服务跑在同一个平台上,但数据互相隔离。 服务继续被拆分的更微粒化,形成了一组服务矩阵(见下图)
而部署方式,只需要在双机房建立两套对等集群,并另外建一个较小的灰度发布集群即可,所有不同业务都运行在统一平台集群上,如下图: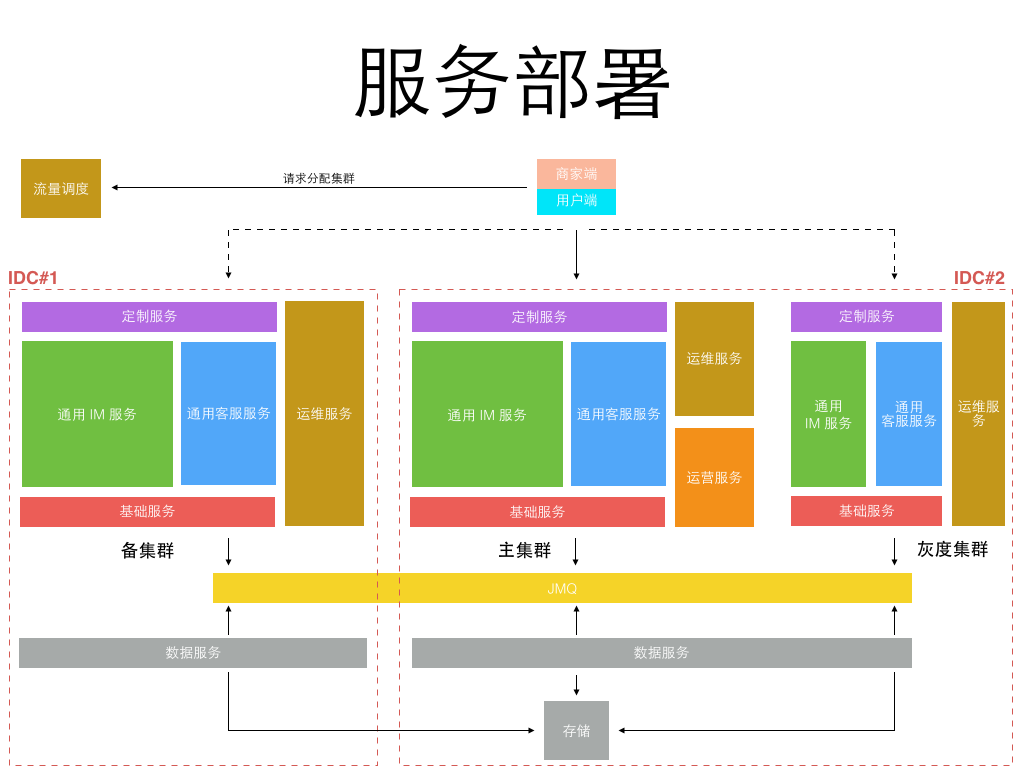
更细粒度的服务意味着每个服务的开发更简单,代码量更小,依赖更少,隔离稳定性更高。 但更细粒度的服务也意味着更繁琐的运维监控管理,直到今年公司内部弹性私有云、缓存云、消息队列、部署、监控、日志等基础系统日趋完善, 使得实施这类细粒度划分的微服务架构成为可能,运维成本可控。 而从当初 1.0 的 1 种应用进程,到 3.0 的 6、7 种应用进程,再到 4.0 的 50+ 更细粒度的不同种应用进程。 每种进程再根据承载业务流量不同分配不同的实例数,真正的实例进程数会过千。 为了更好的监控和管理这些进程,为此专门定制了一套面向服务的运维管理系统,见下图: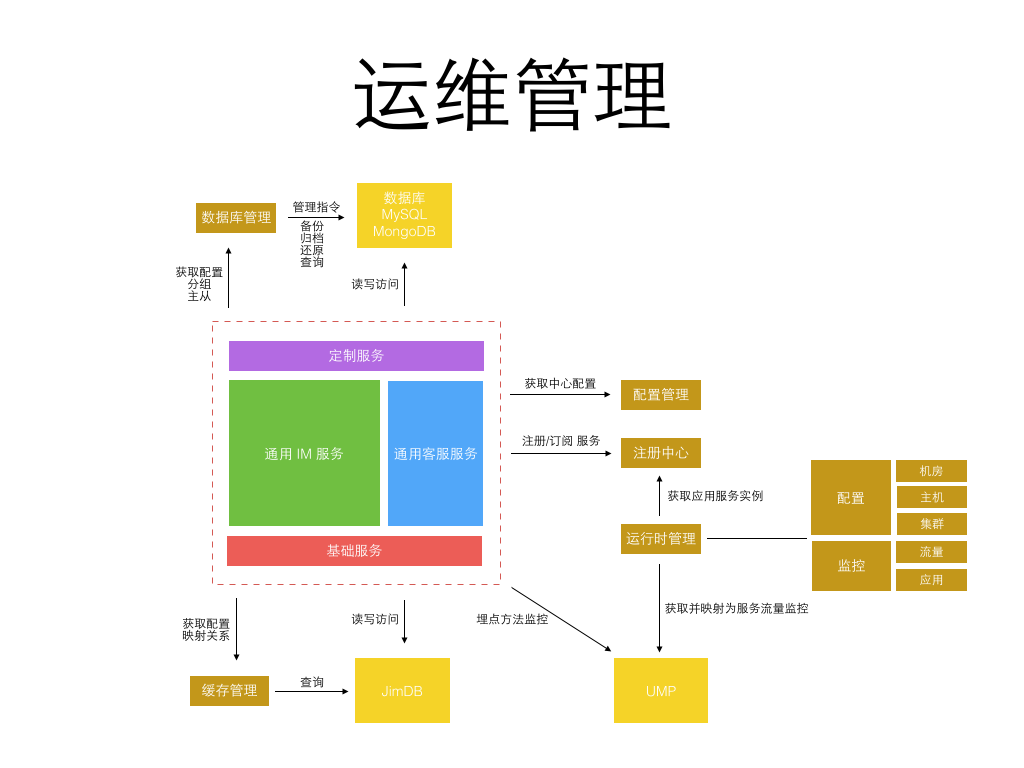
统一服务运维提供了实用的内部工具和库来帮助开发更健壮的微服务。 包括中心配置管理,流量埋点监控,数据库和缓存访问,运行时隔离,如下图所示是一个运行隔离的图示: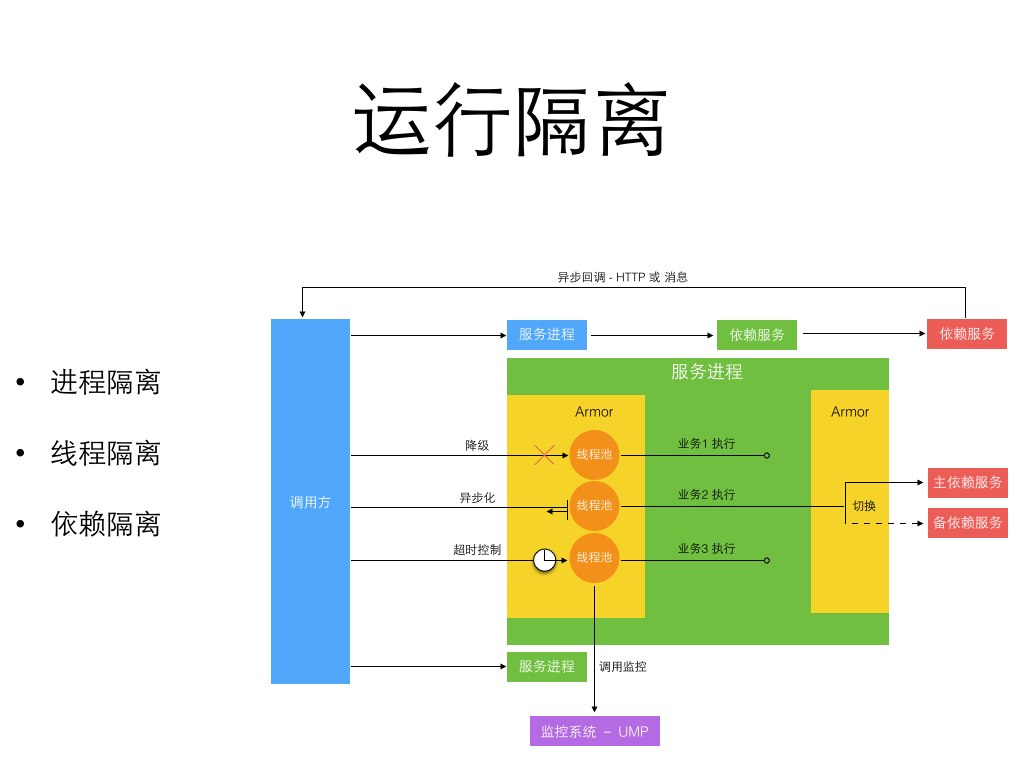
细粒度的微服务做到了进程间隔离,严格的开发规范和工具库帮助实现了异步消息和异步 HTTP 来避免多个跨进程的同步长调用链。 进程内部通过切面方式引入了服务增强容器 Armor 来隔离线程, 并支持进程内的单独业务降级和同步转异步化执行。而所有这些工具和库服务都是为了两个目标:
- 让服务进程运行时状态可见
- 让服务进程运行时状态可被管理和改变
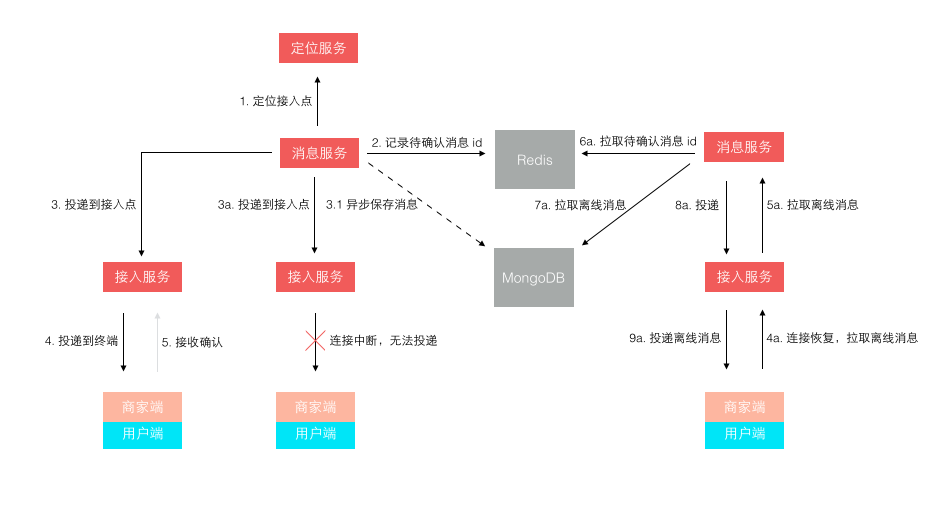
最后我们回到前文留下的一个悬念,就是关于消息投递模型的缺陷。 一开始我们在接入层检测到终端连接断开后,消息无法投递,再将消息缓存下来,等终端重连接上来再拉取离线消息。 这个模型在移动时代表现的很不好,因为移动网络的不稳定性,导致经常断链后重连。 而准确的检测网络连接断开是依赖一个网络超时的,导致检测可能不准确,引发消息假投递成功。 新的模型如下图所示,它不再依赖准确的网络连接检测,投递前待确认消息 id 被缓存,而消息体被持久存储。 等到终端接收确认返回后,该消息才算投妥,未确认的消息 id 再重新登陆后或重连接后作为离线消息推送。 这个模型不会产生消息假投妥导致的丢失,但可能导致消息重复,只需由客户终端按消息 id 去重即可。
京东咚咚诞生之初正是京东技术转型到 Java 之时,经历这些年的发展,取得了很大的进步。 从草根走向专业,从弱小走向规模,从分散走向统一,从杂乱走向规范。 本文主要重心放在了几年来咚咚架构演进的过程,技术架构单独拿出来看我认为没有绝对的好与不好, 技术架构总是要放在彼时的背景下来看,要考虑业务的时效价值、团队的规模和能力、环境基础设施等等方面。 架构演进的生命周期适时匹配好业务的生命周期,才可能发挥最好的效果。
分享阅读原文:https://henduan.com/LWnMz
大型网站系统架构演化之路
being 发表了文章 0 个评论 3374 次浏览 2016-01-10 16:26
前言
一个成熟的大型网站(如淘宝、天猫、腾讯等)的系统架构并不是一开始设计时就具备完整的高性能、高可用、高伸缩等特性的,它是随着用户量的增加,业务功能的扩展逐渐演变完善的,在这个过程中,开发模式、技术架构、设计思想也发生了很大的变化,就连技术人员也从几个人发展到一个部门甚至一条产品线。所以成熟的系统架构是随着业务的扩展而逐步完善的,并不是一蹴而就;不同业务特征的系统,会有各自的侧重点,例如淘宝要解决海量的商品信息的搜索、下单、支付;例如腾讯要解决数亿用户的实时消息传输;百度它要处理海量的搜索请求;他们都有各自的业务特性,系统架构也有所不同。尽管如此我们也可以从这些不同的网站背景下,找出其中共用的技术,这些技术和手段广泛运用在大型网站系统的架构中,下面就通过介绍大型网站系统的演化过程,来认识这些技术和手段。
一、最开始的网站架构
最初的架构,应用程序、数据库、文件都部署在一台服务器上,如图:

二、应用、数据、文件分离
随着业务的扩展,一台服务器已经不能满足性能需求,故将应用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,达到最佳的性能效果。

三、利用缓存改善网站性能
在硬件优化性能的同时,同时也通过软件进行性能优化,在大部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,大部分网站访问都遵循28原则(即80%的访问请求,最终落在20%的数据上),所以我们可以对热点数据进行缓存,减少这些数据的访问路径,提高用户体验。

缓存实现常见的方式是本地缓存、分布式缓存。当然还有CDN、反向代理等,这个后面再讲。本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,OSCache就是常用的本地缓存组件。本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,速度按理没有本地缓存快,常用的分布式缓存是Memcached、Redis。
四、使用集群改善应用服务器性能
应用服务器作为网站的入口,会承担大量的请求,我们往往通过应用服务器集群来分担请求数。应用服务器前面部署负载均衡服务器调度用户请求,根据分发策略将请求分发到多个应用服务器节点。

常用的负载均衡技术硬件的有F5,价格比较贵,软件的有LVS、Nginx、HAProxy。LVS是四层负载均衡,根据目标地址和端口选择内部服务器,Nginx和HAProxy是七层负载均衡,可以根据报文内容选择内部服务器,因此LVS分发路径优于Nginx和HAProxy,性能要高些,而Nginx和HAProxy则更具配置性,如可以用来做动静分离(根据请求报文特征,选择静态资源服务器还是应用服务器)。
五、数据库读写分离和分库分表
随着用户量的增加,数据库成为最大的瓶颈,改善数据库性能常用的手段是进行读写分离以及分库分表,读写分离顾名思义就是将数据库分为读库和写库,通过主备功能实现数据同步。分库分表则分为水平切分和垂直切分,水平切分则是对一个数据库特大的表进行拆分,例如用户表。垂直切分则是根据业务的不同来切分,如用户业务、商品业务相关的表放在不同的数据库中。

六、使用CDN和反向代理提高网站性能
假如我们的服务器都部署在成都的机房,对于四川的用户来说访问是较快的,而对于北京的用户访问是较慢的,这是由于四川和北京分别属于电信和联通的不同发达地区,北京用户访问需要通过互联路由器经过较长的路径才能访问到成都的服务器,返回路径也一样,所以数据传输时间比较长。对于这种情况,常常使用CDN解决,CDN将数据内容缓存到运营商的机房,用户访问时先从最近的运营商获取数据,这样大大减少了网络访问的路径。比较专业的CDN运营商有蓝汛、网宿。

而反向代理,则是部署在网站的机房,当用户请求达到时首先访问反向代理服务器,反向代理服务器将缓存的数据返回给用户,如果没有缓存数据才会继续访问应用服务器获取,这样做减少了获取数据的成本。反向代理有Squid,Nginx。
七、使用分布式文件系统
用户一天天增加,业务量越来越大,产生的文件越来越多,单台的文件服务器已经不能满足需求,这时就需要分布式文件系统的支撑。常用的分布式文件系统有GFS、HDFS、TFS。

八、使用NoSql和搜索引擎
对于海量数据的查询和分析,我们使用nosql数据库加上搜索引擎可以达到更好的性能。并不是所有的数据都要放在关系型数据中。常用的NOSQL有mongodb、hbase、redis,搜索引擎有lucene、solr、elasticsearch。

九、将应用服务器进行业务拆分
随着业务进一步扩展,应用程序变得非常臃肿,这时我们需要将应用程序进行业务拆分,如百度分为新闻、网页、图片等业务。每个业务应用负责相对独立的业务运作。业务之间通过消息进行通信或者共享数据库来实现。

十、搭建分布式服务
这时我们发现各个业务应用都会使用到一些基本的业务服务,例如用户服务、订单服务、支付服务、安全服务,这些服务是支撑各业务应用的基本要素。我们将这些服务抽取出来利用分部式服务框架搭建分布式服务。阿里的Dubbo是一个不错的选择。

总结
大型网站的架构是根据业务需求不断完善的,根据不同的业务特征会做特定的设计和考虑,本文只是讲述一个常规大型网站会涉及的一些技术和手段。
分享阅读整理原文:http://www.cnblogs.com/leefreeman/p/3993449.html
参考书籍:《大型网站技术架构》《海量运维运营规划》


浅谈开源工具自动化运维阶段
Rock 发表了文章 1 个评论 6988 次浏览 2016-01-02 00:48
前言
随着各种业务对IT的依赖性渐重以及云计算技术的普及,企业平均的IT基础架构规模正不断扩张。
有些Web 2.0企业可能会需要在两个星期内增加上千台服务器,因此对运维而言,通过手动来一个一个搭建的方法不仅麻烦、效率低下,而且非常不利于维护和扩展。
即使是在传统的企业当中,日常的备份、服务器状态监控和日志,通过手动的方式来进行的效率也很低,是一种人力的浪费。因此,自动化早已是每个运维都必须掌握的看家本领。
在不同的企业中,自动化的规模、需求与实现方式都各不相同,因此在技术细节层面,运维之间很难将别的企业的方法整个套用过来。然而在很多情况下,自动化的思路是有共通之处的。
运维自动化前三阶段
- []纯手工阶段:手工操作重复地进行软件部署和运维;[/][]脚本阶段:通过编写脚本、方便地进行软件部署和运维;[/][]工具阶段:借助第三方工具高效、方便地进行软件部署和运维。[/]
这几个阶段是随着运维知识、经验、教训不断积累而不断演进的。而且,第2个阶段和第3个阶段可以说是齐头并进,Linux下的第三方工具虽说已经不少了,但是Linux下的脚本编写对运维工作的促进作用是绝对不可以忽视的。在DevOps出现之前,运维工作者在工作中还是以这两种方式为主。
1、预备类工具:KickstartLinux下好用的开源工具
kickstart安装是redhat开创的按照你设计好的方式全自动安装系统的方式。安装方式可以分为光盘、硬盘、和网络。Cobbler
Cobbler是一个快速网络安装linux的服务,而且在经过调整也可以支持网络安装windows。该工具使用python开发,小巧轻便(才15k行代码),使用简单的命令即可完成PXE网络安装环境的配置,同时还可以管理DHCP,DNS,以及yum包镜像。OpenQRM
openQRM提供开放的插件管理架构,你可用很轻松的将现有的数据中心应用程序集成到其中,比如Nagios和VMware。openQRM的自动化数据中心操作不但可用帮助你提高可用性,同时还可以降低您企业级数据中心的管理费用。针对数据中心管理的开源平台,针对设备的部署、监控等多个方面通过可插拔式架构实现自动化的目的,尤其面向云计算/基于虚拟化的业务。Spacewalk
Spacewalk可管理Fedora、红帽、CentOS、SUSE与Debian Linux服务器。当你的数据中心拥有多台Linux服务器时,手动管理将不再是一个好的选择。Spacewalk就可以管理补丁、登录、更新。
[b]在自动化运维和大数据云计算时代实现预设自动化安装服务器环境、应用环境等不仅可以提高运维效率,而且还能大大减少运维的工作任务及出错概率。尤其是对于在服务器数量按几百台、几千台增加的公司而言,单单是装系统,如果不通过自动化来完成,其工作量和周期不可想象。[/b]2、配置管理类工具:前浪:Chef
Chef是一个系统集成框架,可以用Ruby等代码完成服务器的管理配置并编写自己的库。ControlTier
ControlTier是一个完全开放源码系统的自动化服务管理活动的多个服务器和多个应用层(代码,数据,配置和内容) 。共同使用的ControlTier包括部署应用程序,控制它们的状态,并运行按需行政工作在多个服务器上。ControlTier是跨平台和工程同样的物理服务器,虚拟机,或云计算基础设施。Func
Func是由红帽子公司以Fedora统一网络控制器Func,目的是为了解决这一系列统一管理监控问题而设计开发的系统管理基础框架,它是一个能有效的简化我们众多服务器系统管理工作的工具,其具备容易学习,容易使用,更容易扩展;功能强大而且配置简单等优点。Puppet
puppet是一个开源的软件自动化配置和部署工具,它使用简单且功能强大,正得到了越来越多地关注,现在很多大型IT公司均在使用puppet对集群中的软件进行管理和部署。后浪SaltStack
Salt一种全新的基础设施管理方式,部署轻松,在几分钟内可运行起来,扩展性好,很容易管理上万台服务器,速度够快,服务器之间秒级通讯。Ansible
Ansible是新出现的运维工具是基于Python研发的糅合了众多老牌运维工具的优点实现了批量操作系统配置、批量程序的部署、批量运行命令等功能。
[b]在进行大规模部署时,手工配置服务器环境是不现实的,这时必须借助于自动化部署工具。[/b]3、监控类工具Nagios
Nagios是一款免费的开源IT基础设施监控系统,其功能强大,灵活性强,能有效监控 Windows 、Linux、VMware 和 Unix 主机状态,交换机、路由器等网络设置等。一旦主机或服务状态出现异常时,会发出邮件或短信报警第一时间通知 IT 运营人员,在状态恢复后发出正常的邮件或短信通知。OpenNMS
OpenNMS是一个网络管理应用平台,可以自动识别网络服务,事件管理与警报,性能测量等任务。Cacti
Cacti是一套基于PHP、MySQL、SNMP及RRDTool开发的网络流量监测图形分析工具。它通过snmpget来获取数据,使用 RRDtool绘画图形,它的界面非常漂亮,能让你根本无需明白rrdtool的参数能轻易的绘出漂亮的图形。而且你完全可以不需要了解RRDtool复杂的参数。它提供了非常强大的数据和用户管理功能,可以指定每一个用户能查看树状结 构、host以及任何一张图,还可以与LDAP结合进行用户验证,同时也能自己增加模板,让你添加自己的snmp_query和script!功能非常强大完善,界面友好。Zenoss Core
一个基于Zope应用服务器的应用/服务器/网络管理平台,提供了Web管理界面,可监控可用性、配置、性能和各种事件。Zabbix
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。用于监控网络上的服务器/服务以及其他网络设备状态的网络管理系统,后台基于C,前台由PHP编写,可与多种数据库搭配使用。提供各种实时报警机制。Ganglia
Ganglia是一个针对高性能分布式系统(例如,集群、网格、云计算等)所设计的可扩展监控系统。该系统基于一个分层的体系结构,并能够支持2000个节点的集群。它允许用户能够远程监控系统的实时或历史统计数据,包括:CPU负载均衡、网络利用率等。Ganglia依赖于一个基于组播的监听/发布协议来监控集群的状态。Ganglia系统的实现综合了多种技术,包括:XML(数据描述)、XDR(紧凑便携式数据传输)、RRDtool(数据存储和可视化)等。
[b]数据监控和业务监控非常关键,及时发现问题,及时解决问题,监控系统主要包括:服务应用监控、主机监控、网络设备监控、网络连通性监控、网络访问质量监控、分布式系统监控、报警预设、监控图形化与历史数据等。[/b]

自动化对运维的意义
自动化就是运维为了减少重复枯燥的工作而建立的流程方法,而除此之外,自动化还能够带来减少人为错误、及时报警与故障恢复、提高业务可用性等好处。
运维工作自动化确实包含上述2个方面,归纳总结来其实就是:把零碎的工作集中化,把复杂的工作简单有序化,把流程规范化,最大化地解放生产力,也就是解放运维人员。自动化的技能/意识对于运维工作至关重要。运维工作不是简单的使用工具,这里面还有很多技巧和意识。具体的技巧/意识包括:[list=1][]如何驾驭这些琳琅满目的工具为己所用;[/][]如何根据不同的应用环境来选用不同的工具;[/][]如何根据应用来组合使用工具等等等等。[/]
一定要记住一点:工具只是利用帮助人进行运维的,这中间还需要人的干预和决策,工具不能完全代替全部运维工作。还需要结合实际业务逻辑和业务场景,就像架构一样,并不是淘宝、百度等大公司的架构,一定适合任何公司和业务。
自动化运维范畴
- []安装自动化[/][]部署自动化[/][]监控自动化[/][]发布自动化[/][]升级自动化[/][]安全管控自动化[/][]优化自动化[/][]数据备份自动化[/]
前阶段在自动化管理和安全方面的技术实现,比如说HP和IBM出品的一些ITIL和ITSM产品等,比如HP Openview,IBM Tivoli等等。这些工具都有Linux的版本,与其他同类工具相比的优势应该在于他们的商业应用成熟度,都是老品牌。现阶段有自动化的一些工具git、svn、Jenkins等等,一些开源的软件!
工具选择
针对不同规模的架构,一个小规模的网站,到百万量级、千万量级的网站,我们选择的工具就有不同。
在选择上对于百万量级、千万量级的网站,我们应该考虑选择成熟的工具、性能高的工具、熟悉的工具。而对于小规模的网站,我们应该考虑选择一些开源的、免费的工具。
这个原则就是以应用为导向,百万量级、千万量级的网站牵涉的面广、要求高,不成熟的工具往往很难说服领导和公司使用,所以主要是在成熟度方面。
自动化运维规划
自动化的实现不是单纯学习几个工具就能够做好的,甚至于规划不好的情况,自动化不仅没有节省人力,反而带来了更多的问题。所以运维人员在考虑自动化流程的过程中应该考虑如下几点原则:[list=1][]根据应用选择工具;[/][]对于关键应用,选择成熟度高的工具;[/][]不能过分依赖一种工具,需要进行对比和分析;[/][]对工具的特性做到精通;[/][]是人驾驭工具,人要监督工具,而不是工具来驾驭人;[/][]善于利用脚本实现定制化场景。[/]
[list=1][]经常逛逛一些不错的IT媒体网站和看看这方面的文章,可以多多涉猎和学习;[/][]针对公司业务场景,选择一些自动化工具,登陆到官网学习和熟悉工作原理;[/][]经常参加一些线下自动化运维的活动和媒体活动,多和一些自动化方面的大拿和资深人士交流。[/]自动化经验积累
负载均衡LVS原理和应用详解
push 发表了文章 1 个评论 4421 次浏览 2016-01-01 19:03
一、LB常用解决方案
1. 硬件负载均衡解决方案:
- []F5公司: BIG-IP[/][]Citrix公司: Netscaler[/][]A10公司: A10[/][]Array [/][]Redware[/]
1) CIP: Client ip
2) VIP: virtual ip
3) DIP: Director IP
4) RIP: Real server Ip
客户端请求,被VIP端口接收后,从DIP接口被转发出去,并转发至RIP
二、LVS类型
1. NAT(dNAT)
访问过程如下:
1) CIP访问VIP
2) VIP接收报文后,做dNAT,指向某一个RIP
3) RIP拿到接收到报文后进行回应
4) 此时需要,RIP网关指向DIP,也就是Director server. 否则若在互联网上,即便报文是可以回应给CIP客户端,但是由于CIP并没有请求RIP服务器,因此报文会被丢弃。
NAT特性:
1) RS应该使用私有地址
2) RS的网关必须指向DIP
3) RIP 和 DIP 必须在一同意网段内
4) 进出的报文,无论请求还是响应,都必须经过Director Server, 请求报文由DS完成目标地址转换,响应报文由DS完成源地址转换
5) 在高负载应用场景中,DS很可能成为系统性能瓶颈。
6) 支持端口映射。
7) 内部RS可以使用任意支持集群服务的任意操作系统。

2. DR
1)让前端路由将请求发往VIP时,只能是Dirctor上的VIP
禁止RS响应对VIP的ARP广播请求:
(1) 在前端路由上实现静态MAC地址VIP的绑定;
前提:得有路由器的配置权限;
缺点:Directory故障转时,无法更新此绑定;
(2) arptables
前提:在各RS在安装arptables程序,并编写arptables规则
缺点:依赖于独特功能的应用程序
(3) 修改Linux内核参数
前提:RS必须是Linux;
缺点:适用性差;
Linux的工作特性:IP地址是属于主机,而非某特定网卡;也就是说,主机上所有的网卡都会向外通告,需要先配置参数,然后配置IP,因为只要IP地址配置完成则开始想外通告mac地址为了使响应报文由配置有VIP的lo包装,使源地址为VIP,需要配置路由经过lo网卡的别名,最终由eth0发出
两个参数的取值含义:
arp_announce:定义通告模式
0: default, 只要主机接入网络,则自动通告所有为网卡mac地址
1: 尽力不通告非直接连入网络的网卡mac地址
2: 只通告直接进入网络的网卡mac地址
arp_ignore:定义收到arp请求的时响应模式
0: 只有arp 广播请求,马上响应,并且响应所有本机网卡的mac地址
1: 只响应,接受arp广播请求的网卡接口mac地址
2: 只响应,接受arp广播请求的网卡接口mac地址,并且需要请求广播与接口地址属于同一网段
3: 主机范围(Scope host)内生效的接口,不予响应,只响应全局生效与外网能通信的网卡接口
4-7: 保留位
8: 不响应一切arp广播请求
配置方法:
全部网卡
arp_ignore 1
arp_announce 2
同时再分别配置每个网卡,eth0和lo
arp_ignore 1
arp_annource 2
2) 特性
(1)RS是可以使用公网地址,此时可以直接通过互联网连入,配置,监控RS服务器
(2)RS的网不能指向DIP
(3)RS跟DS要在同一物理网络内,最好在一同一网段内
(4)请求报文经过Director但是相应报文不经过Director
(5)不支持端口映射
(6)RS可以使用,大多数的操作系统,至少要可以隐藏VIP


3. LVS TUN: IP隧道,IP报文中套IP报文
1)RIP,DIP,VIP都必须是公网地址
2)RS网关不会指向DIP
3)请求报文经过Director,但相应报文一定不经过Director
4)不支持端口映射
5)RS的OS必须得支持隧道功能

4. FULLNAT: 必须内核打补丁才能使用,使得各RS主机可以跨vlan. 源IP和目标IP都修改。

三、LVS调度算法
1. 静态方法:仅根据算法本身进行调度
rr: Round Robin
wrr: Weighted RR
sh: source hashing,源地址进行hash,然后分配到特定的服务器
dh: destination hashing
用于多前端防火墙的场景中,使得访问从一个防火墙进同时还从这个防火墙出来。
2. 动态方法:根据算法及RS当前的负载状况
lc: Least Connection
Overhead=Active*256+Inactive
结果中,最小者胜出;
wlc: Weighted LC
Overhead=(Active*256+Inactive)/weight
sed: Shortest Expect Delay
Overhead=(Active+1)*256/weight
nq: Nerver Queue,在Sed基础上,开局时候先轮寻一圈。
lblc: Locality-based Least Connection (基于本地的最小连接) dh+lc
lblcr: Replicated and Locality-based Least Connection 后端服务器是缓存服务器时, 可以绑定连接到某一缓存服务器中。
3. LVS缺陷:
不能检测后端服务器的健康状况,总是发送连接到后端。
Session持久机制:
1、session绑定:始终将同一个请求者的连接定向至同一个RS(第一次请求时仍由调度方法选择);没有容错能力,有损均衡效果;
2、session复制:在RS之间同步session,因此,每个RS持集群中所有的session;对于大规模集群环境不适用;
3、session服务器:利用单独部署的服务器来统一管理session;
四、ipvsadm使用方法
1.相关命令
ipvsadm -A|E -t|u|f service-address [-s scheduler] [-p [timeout]] [-M netmask]2. 集群服务相关
ipvsadm -D -t|u|f service-address
ipvsadm -C
ipvsadm -R
ipvsadm -S [-n]
ipvsadm -a|e -t|u|f service-address -r server-address [-g|i|m] [-w weight] [-x upper] [-y lower]
ipvsadm -d -t|u|f service-address -r server-address
ipvsadm -L|l [options]
ipvsadm -Z [-t|u|f service-address]
-A: 添加一个集群服务3. RS相关
-t: tcp
-u: udp
-f: firewall mark,
通常用于将两个或以上的服务绑定为一个服务进行处理时使用
例如httpd和https
iptables mongo表一起使用
service-address:
-t IP:port
-u ip:port
-f firewall_mark
-s 调度方法,默认为wlc
-p timeout: persistent connection, 持久连接
-E 修改定义过的集群服务
-D -t|u|f service-address:删除指定的集群服务
-a:向指定的Cluster services中添加RS4. 清空所有的集群服务:
-t|-u|-f service-address:指明将RS添加至哪个Cluster Service中
-r: 指定RS,可包含{IP[:port]},只有支持端口映射的LVS类型才允许此处使用跟集群服务中不同的端口
LVS类型:
-g: Gateway模式,就是DR模型(默认)
-i: ipip模式,TUN模型
-m: masquerade地址伪装自动完成后半段的原地址转换,NAT
指定RS权重:
-w # 省略权重为1
-e: 修改指定的RS属性
-d -t|u|f service-address -r server-address:从指定的集群服务中删除某RS
-C5. 保存规则:(使用输出重定向)
ipvsadm-save6. 载入指定的规则:(使用输入重定向)
ipvsadm -S
ipvsadm-restore7. 查看ipvs规则等
ipvsadm -R
-L [options]
-n: 数字格式显示IP地址
-c: 显示连接数相关信息
--stats: 显示统计数据
--rate: 速率
--exact:显示统计数据的精确值
--timeout: 超时时间
-Z: 计数器清零
五、LVS NAT模型的实现
[list=1]
[*]集群环境: 一台Director, 两台后端Real Server RS1,RS2
Director: 两网卡 [/*]
[/list] eth0: 192.168.98.133/24
eth1: 172.25.136.10/24
eth0:1: 192.168.98.128/24 作为VIP地址
RS1:
eth0: 172.25.136.11
RS2:
eth0: 172.25.136.12;
Director的eth1和RS1,RS2的eth0在模拟在同一物理网络内,使用VMnet22. 为RS添加网关指向Director
物理机windows 7 作为客户端,在192.168.98.0网络内
RS1:3. 修改内核参数,开启转发功能
# ifconfig eth0 172.25.136.11/24
# route add default gw 172.25.136.10
RS2:
# ifconfig eth0 172.25.136.12/24
# route add default gw 172.25.136.10
添加完路由条目后,应该可以ping通Director 192.168.98.0网段的两个地址。
# echo 1 > /proc/sys/net/ipv4/ip_forward4. 在RS1和RS2上面创建测试页,并在Director验证服务
RS1上5. 在Director添加集群服务
# echo 'web from RS1' > /var/www/html/index.html
# service httpd start
RS2上
# echo 'web from RS2' > /var/www/html/index.html
# service httpd start
Director上验证
# curl 172.25.136.11
web from RS1
# curl 172.25.136.12
web from RS2
# ipvsadm -A -t 192.168.98.128:80 -s wlc6. 通过物理机浏览器访问192.168.98.128, 正常情况,就可以看到轮寻的两个RS的主页了。
# ipvsadm -a -t 192.168.98.128:80 -r 172.25.136.11:80 -m -w 1
# ipvsadm -a -t 192.168.98.128:80 -r 172.25.136.12:80 -m -w 3
访问几次后,查看统计数据如下,大概接入报文比例3:1, 说明wlc生效了
# ipvsadm -L --stats
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Conns InPkts OutPkts InBytes OutBytes
-> RemoteAddress:Port
TCP 192.168.98.128:http 45 227 227 32215 19245
-> 136-11.priv25.nus.edu.sg:htt 12 62 62 8571 6055
-> 136-12.priv25.nus.edu.sg:htt 33 165 165 23644 13190
六、LVS DR模型,当DIP,VIP,RIP都为公网地址时(实验环境中,把这三个地址全部放在同一物理网络中)
[list=1]
[*]地址规划:
Director: [/*]2. 配置地址
[/list] eth0: 192.168.98.133 作为ssh通信地址
eth0:1: 192.168.98.128 作为VIP, 可以进行浮动
RS1:
eth0: 192.168.98.129/24 作为RIP1
lo:1 : 192.168.98.128 作为隐藏的VIP
RS1:
eth0: 192.168.98.130 作为RIP2
lo:2: 192.168.98.128 作为隐藏VIP
Director:3. 修改RS1,RS3的内核参数,关闭lo的arp通告和lo的arp响应,并配置隐藏地址
# ifconfig eth0 192.168.98.133/24 up
# ifconfig eth0:1 192.168.98.128/24 up
RS1
# ifconfig eth0 192.168.98.129/24 up
RS2
# ifconfig eth0 192.168.98.130/25 up
RS1:4. 为RS1和RS2添加路由条目,保证其发出报文经过eth0之前,还要先经过lo:1 VIP, 使得源地址成为VIP
# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
# echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
# echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
设置RS1的隐藏VIP地址, 并禁止其向外发广播
# ifconfig lo:1 192.168.98.128 netmask 255.255.255.255 broadcast 192.168.98.128
RS2:
# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
# echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
# echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
设置RS2的隐藏VIP地址,并禁止其向外发广播
# ifconfig lo:1 192.168.98.128 netmask 255.255.255.255 broadcast 192.168.98.128
RS1:5. 此时在Director上面添加,集群服务
# route add 192.168.98.128 dev lo:1
RS2:
# route add 192.168.98.128 dev lo:1
# ipvsadm -A -t 192.168.98.128:80 -s wlc
# ipvsadm -a -t 192.168.98.128:80 -r 192.168.98.129:80 -g -w 1
# ipvsadm -a -t 192.168.98.128:80 -r 192.168.98.130:80 -g -w 3
七、LVS持久连接
[list=1]
[*]PCC:将来自于同一个客户端发往VIP的所有请求统统定向至同一个RS
可以通过修改轮寻算法为sh算法实现[/*]2. PPC:将来自于一个客户端发往某VIP的某端口的所有请求统统定向至同一个RS;
[/list] # ipvsadm -E -t 192.168.98.128:80 -s sh
[root@www ~]# curl 192.168.98.128
eb from RS2
[root@www ~]# curl 192.168.98.128
web from RS2
[root@www ~]# curl 192.168.98.128
web from RS2
[root@www ~]# curl 192.168.98.128
web from RS2
[root@www ~]# curl 192.168.98.128
web from RS2
[root@www ~]# curl 192.168.98.128
web from RS2
[list=1]
[*]PFMC: 端口绑定,port affinity, 基于防火墙标记,将两个或以上的端口绑定为同一个服务
防火墙打标记[/*]转载阅读,原文地址:负载均衡LVS原理及其应用
[/list] # iptables -t mangle -A PREROUTING -d VIP -p tcp --dport CS_Port -j MARK --set-mark # (0-99)
定义集群服务:
# ipvsadm -A -f #(防火墙打的标记)
八大持续集成工具
push 发表了文章 0 个评论 12768 次浏览 2015-12-10 23:05
一、Hudson

Hudson 是一个可扩展的持续集成引擎,主要用于:
- []持续、自动地构建/测试软件项目,如CruiseControl与DamageControl。[/][]监控一些定时执行的任务。[/]
Hudson的特性如下:
- []易于安装-只要把hudson.war部署到servlet容器,不需要数据库支持。[/][]易于配置-所有配置都是通过其提供的web界面实现。[/][]集成RSS/E-mail/IM-通过RSS发布构建结果或当构建失败时通过e-mail实时通知。[/][]生成JUnit/TestNG测试报告。[/][]分布式构建支持-Hudson能够让多台计算机一起构建/测试。[/][]文件识别- Hudson能够跟踪哪次构建生成哪些jar,哪次构建使用哪个版本的jar等。[/][]插件支持-Hudson可以通过插件扩展,你可以开发适合自己团队使用的工具。[/]

CruiseControl是一个针对持续构建程序(项目持续集成)的框架,它包括一个email通知的插件,Ant和各种各样的CVS工具。CruiseControl提供了一个Web接口, 可随时查看当前的编译状况和历史状况。

Apache Continuum 是最新的 CI 服务器之一,也是值得关注的一个新进入者。Continuum 的安装和配置很简单:只要下载和释放 ZIP 文件,运行命令行程序,就可以运行了。基于 Web 的界面使得配置项目很容易。而且,还不需要安装 Web 服务器,因为 Continuum 内置了 Jetty Web 服务器。并且,Continuum 可以作为 Windows 服务运行,还在应用程序的某些部分嵌入了上下文敏感的文档,从而提供了很多帮助。Apache Continuum的特性:
- []与Maven 2.x的紧密集成[/][]与Maven SCM的紧密集成,支持Subversion/CVS/Starteam/Clearcase/Perforce[/][]基于web的容易使用的安装和配置接口[/][]Quartz-based scheduling[/][]简单的添加新的项目工程的方法[/][]用于 integration, automation and remoting的XML-RPC interface[/][]邮件提醒和IM(即时通讯)提醒IRC/Jabber/MSN[/]

QuickBuild 是一个持续集成和发布管理的服务器软件,它提供了一个统一的控制台用来管理这些发布的信息。
五、Bamboo

Atlassian Bamboo 是一款持续集成构建服务器软件(Build Server)。Bamboo的特点:
- []简单的用户界面 容易安装 – 顺利的话,5分钟内就可以让运行起来! 自动检测你的设置 – 如果您的Server上使用了Maven,Ant或者Java设置, Bamboo会自动检测他们; [/][]连续的日志 – 监测你的build的colour coded日志;[/][] 容易显示所有项目[/]
六、Jenkins

七、TeamCity


TeamCity是一款功能强大的持续集成(Continue Integration)工具,包括服务器端和客户端,目前支持Java,.Net项目开发。 TeamCity提供一系列特性可以让团队快速实现持续继承:IDE工具集成、各种消息通知、各种报表、项目的管理、分布式的编译等等,所有的这些,都是 让你的团队快速享有持续继承带来的效率提升、高质量的软件保障。
八、CI-Eye

CI-Eye 是一个强大的持续集成构建,无需安装和设置,CI-Eye 通过 REST API 跟很多不同的 CI 服务器交互,当前支持 Hudson, Jenkins, 以及 TeamCity. CI-Eye 在一个独立的 Web 应用中运行。
10个强大的DevOps基础设施自动化工具
空心菜 发表了文章 0 个评论 8016 次浏览 2015-12-07 01:45

Devops基础设施自动化的工具
有许多工具用于基础设施自动化。决定使用哪个工具的体系结构和基础设施的需求。下面我们列出了一些伟大的工具,受到不同类别配置管理、编制、持续集成、监控、等。
1、Chef

Chef是一个基于ruby开发的配置管理工具。你可能会遇到“基础设施代码”这个词,这意味着配置管理。厨师烹饪书的概念,你的代码基础设施DSL(领域特定语言)和一个小的编程。chef规定和配置虚拟机根据规则中提到的食谱。代理将会运行在所有的服务器配置。代理将chef主服务器的cookbooks,在服务器上运行这些配置来达到理想的状态。
2、Puppet

Puppet也基于ruby编写的配置管理工具跟chef一样。配置代码编写使用puppet DSL和封装在模块。而chef更以开发人员为中心,puppet是由系统管理员控制为中心。puppet proxy运行在所有服务器配置,它把编译模块从puppet服务器和安装所需要的软件包中指定模块。

Saltstack是一个基于python打开配置管理工具。不像chef和puppet,Saltstack支持远程执行的命令。通常在chef和puppet,配置的代码将从服务器,在Saltstack,代码可以同时被推到许多节点。编译的代码和配置是Saltstack非常快。
4、Ansible

Ansible是一个缺少代理配置管理以及编制工具。在Ansible配置模块中被称为“剧本”。剧本都写在YAML格式和它相对容易写相比其他配置管理工具。像其他工具,Ansible可用于云配置。
5、Juju

Juju是由典型的基于Python的编排工具。它已经在你的云环境应用程序的伟大的UI。你也可以使用命令行界面来完成所有的业务流程的任务。你可以配置,部署和使用且具规模的应用。
6、 Jenkins

Jenkins是一个基于java的持续集成工具更快的应用程序。Jenkins必须关联到一个版本控制系统如github或SVN。每当新代码被推到代码库,詹金斯服务器将构建和测试新代码和通知团队的结果和变化。
7、 Vagrant

vagrant是一个伟大的工具为开发环境配置虚拟机。vagrant的上面运行的VM虚拟框和流浪的解决方案。它使用一个配置文件叫做Vagrantfile,其中包含所需的所有配置VM。一旦创建了一个虚拟机,它可以与其他开发人员共享相同的开发环境。vagrant有云配置插件,配置管理工具(chef、puppet等)和docker。
8、Docker

Docker是一个自动化工具之上的Linux容器(LXC)。它工作在流程级别虚拟化的概念。Docker创造了孤立的环境称为应用程序容器。这些容器可以运往其他服务器无需更改应用程序。Docker被认为是虚拟化的下一步。码头工人有一个巨大的开发者社区,它是获得巨大的声望在Devops从业者和云计算的先驱。

New relic的基于云的解决方案(SaaS)应用程序监视。它支持各种应用程序的监控像Php、Ruby、Java、NodeJS等等。它给你实时的见解关于您的运行应用程序中。new relic的代理应该配置在应用程序中获得实时数据。New relic使用各种指标提供有价值的见解关于应用程序监控。
10、Sensu

Sensu是一个开放源码监视框架用Ruby编写的。Sensu是一个监控工具专门建立云环境。它可以很容易地部署使用工具如chef和puppet。Sensu也有一个企业版的监控。英文原文链接:http://devopscube.com/devops-tools-for-infrastructure-automation/
Linux知识工具大全
OpenSkill 发表了文章 0 个评论 5959 次浏览 2015-12-03 23:19
Linux is a Unix-ish POSIX-compliant OS family. Most of the distros are GPL or otherwise FOSS. The defining component of Linux is the Linux Kernel, first released on 5 October 1991 by Linus Torvalds.
新版本

开始

受欢迎的网站

著名发行版本

Grok Linux

Linux Virt

可调参数

Linux日志

Book/ebooks

Kernel Matrix

内核地图

In Production

Linux论坛

shell指南

Linux安全

Linux桌面

防火墙

linux NAS

最佳实践

http://openskill.cn 开源技术社区分享
只做技术的分享,欢迎关注微信订阅号:

QQ群交流:

分享英文原文链接:https://linux.zeef.com/paul.reiber





