
通知设置 新通知
Redis SAVE和BGSAVE有啥区别?
空心菜 回复了问题 2 人关注 1 个回复 2468 次浏览 2022-06-08 11:37
MySQL的三种复制模式
koyo 发表了文章 0 个评论 4183 次浏览 2021-12-10 00:04

MySQL支持的三种复制模式分别为:
- asynchronous 异步复制
- fully synchronous 全同步复制
- semi synchronous 半同步复制
异步复制 (asynchronous replication)
原理:在异步复制中,master写数据到binlog且sync,slave request binlog后写入relay-log并flush disk
优点:复制的性能最好
缺点: master挂掉后,slave可能会丢失事务
代表:MySQL原生的复制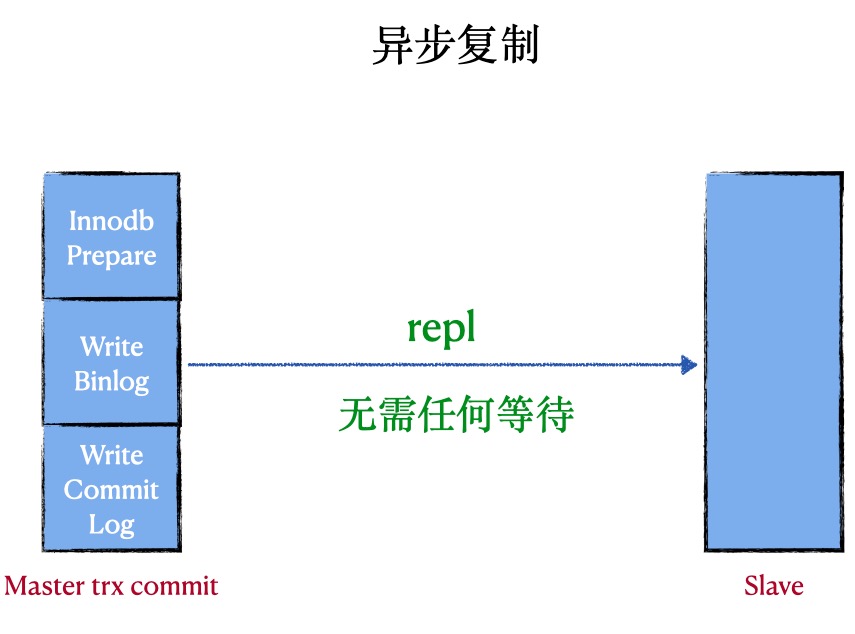
全同步复制 (fully synchronous replication)
原理:在全同步复制中,master写数据到binlog且sync,所有slave request binlog后写入relay-log并flush disk,并且回放完日志且commit
优点:数据不会丢失
缺点:会阻塞master session,性能太差,非常依赖网络
代表:MySQL Cluster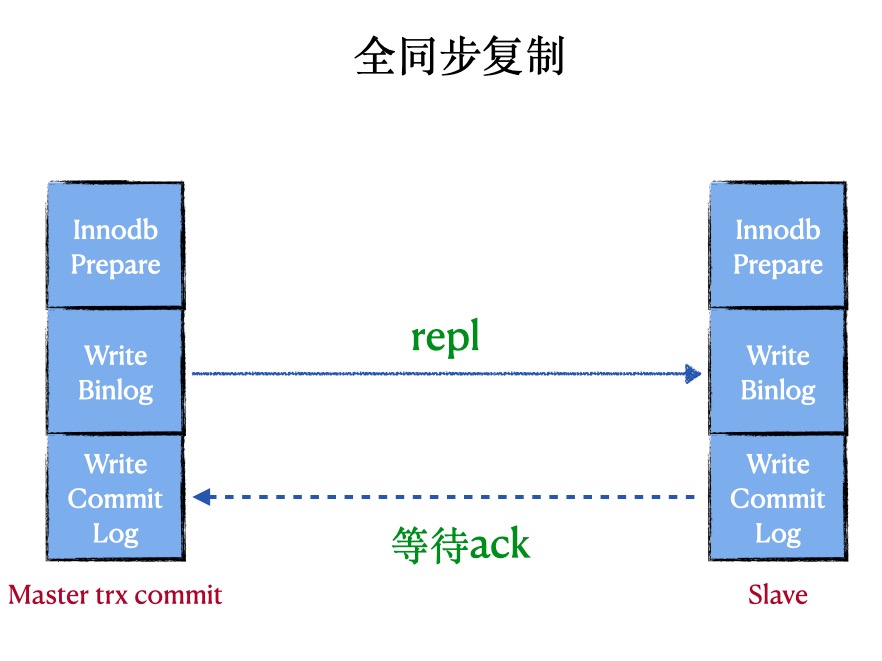
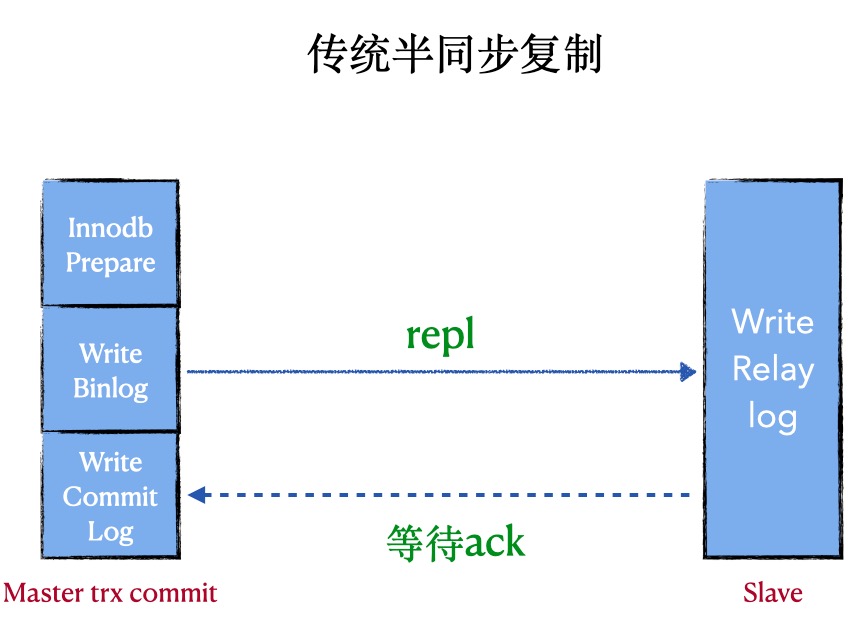
半同步复制 (semi synchronous replication)
1. 普通的半同步复制
原理: 在半同步复制中,master写数据到binlog且sync,且commit,然后一直等待ACK。当至少一个slave request bilog后写入到relay-log并flush disk,就返回ack(不需要回放完日志)
优点:会有数据丢失风险(低)
缺点:会阻塞master session,性能差,非常依赖网络,
代表:after commit, 原生的半同步
重点:由于master是在三段提交的最后commit阶段完成后才等待,所以master的其他session是可以看到这个提交事务的,所以这时候master上的数据和slave不一致,master crash后,slave数据丢失
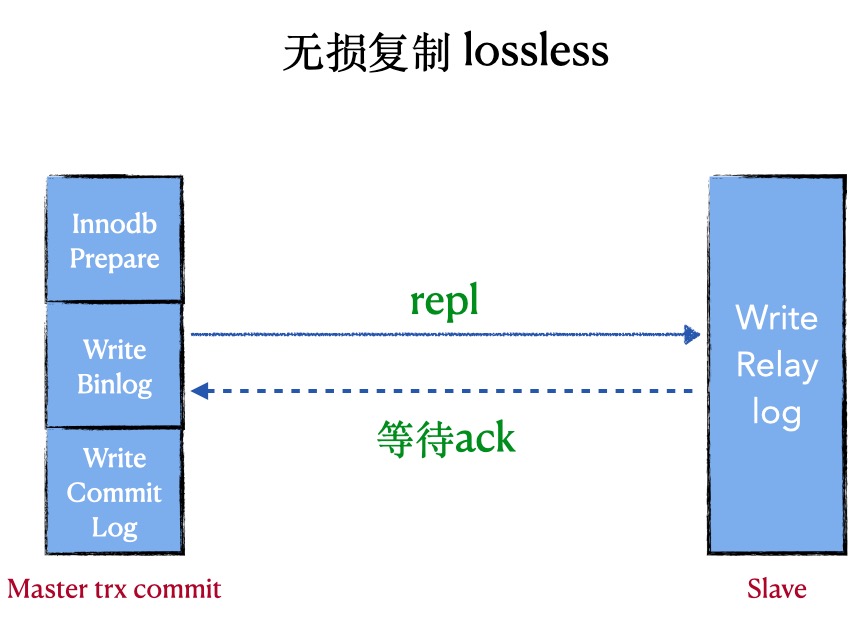
2. 增强版的半同步复制(lossless replication)
原理: 在半同步复制中,master写数据到binlog且sync,然后一直等待ACK. 当至少一个slave request bilog后写入到relay-log并flush disk,就返回ack(不需要回放完日志)
优点:数据零丢失(前提是让其一直是lossless replication),性能好
缺点:会阻塞master session,非常依赖网络
代表:after sync, 原生的半同步
重点:由于master是在三段提交的第二阶段sync binlog完成后才等待, 所以master的其他session是看不见这个提交事务的,所以这时候master上的数据和slave一致,master crash后,slave没有丢失数据
重要参数:
| 参数 | 评论 | 默认值 | 推荐值 | 是否动态 |
|---|---|---|---|---|
| rpl_semi_sync_master_wait_for_slave_count | 至少有N个slave接收到日志 | 1 | 1 | dynamic |
| rpl_semi_sync_master_wait_point | 等待的point | AFTER_SYNC | AFTER_SYNC | dynamic |
| rpl_semi_sync_master_timeout | 切换复制的timeout | 1000(10s) | 1000 (1s) | dynamic |
| rpl_semi_sync_master_enabled | 是否开启半同步 | OFF | ON | dynamic |
| rpl_semi_sync_slave_enabled | 是否开启半同步 | OFF | ON | dynamic |
如何开启lossless replication:
########semi sync replication settings########
plugin_dir=/usr/local/mysql/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_slave_enabled = 1
loose_rpl_semi_sync_master_timeout = 1000
实践是检验真理的唯一标准
如何检验上述after_sync 和 after_commit, 如何检验上述原理的正确性。
InnoDB commit: 三阶段提交过程
A阶段: wite prepare log 写入Xid
B阶段: write binlog
C阶段: write commit log
测试点:master上当一个事务Waiting for semi-sync ACK from slave的时候,后来的事务是在A,B,C哪个阶段卡住呢?
0,RC模式
1. semi-sync C阶段等待
假设设置time-out=100000s,当事务一提交了一个大事务,在write commit log(C阶段)时候等待,
那么第二个事务在敲commit命令的时候,是卡在哪个阶段呢?是卡在 wite prepare log(A阶段)?还是write binlog(B阶段)?还是write commit log(C阶段)
测试:semi-sync vs loss-less semi-sync
【semi-sync】 C阶段等待
0, 开启事务1,然后在slave上执行stop slave,制造timeout的情况,让其阻塞。(Waiting for semi-sync ACK from slave)
1,在开启一个事务2,事务2插入一条特殊记录(XXXXX)。 (Waiting for semi-sync ACK from slave)
2,在开启一个事务3。
2.1,测试案例:这个时候,kill -9 mysqld,造成人为的mysql crash
3,假设卡在A阶段,那么事务3,肯定是看不到事务1,2写入的记录(XXXXX),且重启mysql后,事务2不会提交。
4,假设卡在C阶段,那么事务3,肯定是可以看见事务1,2写入的记录(XXXXX)。
经过测试:
1,是卡在C阶段,也就是说事务3是可以看见事务1,事务2的。
2,MySQL crash重启后,事务1,事务2的dml都已经提交成功,说明不是卡在A阶段
【loss-less semi-sync】B阶段等待
0, 开启事务1,然后在slave上执行stop slave,制造timeout的情况,让其阻塞。(Waiting for semi-sync ACK from slave)
1,在开启一个事务2,事务2插入一条特殊记录(XXXXX)。(Waiting for semi-sync ACK from slave)
2,在开启一个事务3
3,假设卡在A阶段,那么事务3,肯定是看不到事务1,2写入的记录(XXXXX),且重启mysql后,事务2不会提交。。
4,假设卡在B阶段,那么事务3,肯定是可以看见事务1,2写入的记录(XXXXX),且重启mysql后,事务1,2都会提交。。
5, 假设卡在C阶段,那么事务3,肯定是可以看见事务3写入的记录(XXXXX)。
经过测试:
1,是卡在B阶段,也就是说事务3,既看不见事务1的提交内容,也看不见事务2的提交内容,且重启mysql后,事务1,2都已经提交。。
2,MySQL crash重启后,事务1,事务2的dml都已经提交成功,说明不是卡在A阶段。
性能
semi-sync vs lossless semi-sync 的性能对比
根据以上的测试,可以得知,lossless只卡在B阶段,普通的semi-sync是卡在C阶段。
lossless的性能远远好于普通的semi-sync,即(after_sync 优于 after_commit)
因为lossless 卡在B阶段的时候可以堆积事务,可以在C阶段进行group commit。
普通的semi-sync,卡在C阶段,事务都已经commit了,并没有堆积的过程。
CAP理论:
一致性【C】
可用性【A】
分区容忍性【P】
理论:CAP 三者不可兼得,必须要牺牲一个
分区,是一定存在的,不是你想不要就不要的。所以,这里只剩下两种组合
CP 牺牲可用性
这种做法,就是保留强一致性,牺牲可用性
案例:可以将rpl_semi_sync_master_timeout设置成一个无限大的值,比如:100天,那么master和slave就强一致了,但是可用性就大打折扣
AP 牺牲一致性
这种做法,就是保留高可用性,牺牲一致性
案例:比如原生的异步复制就是这样咯。可以快速做到切换,但是一致性就没有保障
什么是Redis,Redis有什么特点和优势?
OS小编 回复了问题 2 人关注 1 个回复 2064 次浏览 2021-12-01 13:09
clickhouse编译报错fatal error: sys/random.h: No such file or directory
回复空心菜 回复了问题 1 人关注 1 个回复 6683 次浏览 2021-04-27 09:33
Redis持久化有哪些,有什么优缺点?
Geek小A 回复了问题 2 人关注 1 个回复 2784 次浏览 2021-03-23 16:07
Redis有哪些优缺点?
chris 回复了问题 2 人关注 1 个回复 2511 次浏览 2021-03-19 18:51
Elasticsearch启动常见问题
being 发表了文章 0 个评论 2541 次浏览 2021-03-16 22:54

启动内存问题
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error='Cannot allocate memory' (errno=12)
分析: 默认分配的JVM内存为2g,所以当小内存的机器,默认启动的话,会报如上错误。
解决: 修改Eleasticsearch启动JVM内存参数, 修改文件: config/jvm.options
-Xms2g
-Xmx2g
修改为
-Xms1g
-Xmx1g
对于内存较低的云主机和虚拟机,你要测试Elasticsearch的基本功能,没有太大性能要求的话,这时候就需要修改启动内存。
启动用户问题
don't run elasticsearch as root
分析: 程序设计者,出于系统安全考虑设置的条件, 由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,如果获取root权限了,那问题就打了,所以默认官方是建议创建一个单独的用户用来运行ElasticSearch。
解决:添加单独的用户运行
groupadd es
useradd es -g es
更改elasticsearch文件夹及内部文件的所属用户及组为es:es
chown -R es:es elasticsearch
切换到es用户启动:
su - es
./bin/elasticsearch -d
# 或者root下
su es -c "/opt/elasticsearch/bin/elasticsearch -d"
Tips: ES5版本之前,还可以修改
ES_JAVA_OPTS启动参数,加上-Des.insecure.allow.root=true可以使用root启动,但是不推荐这么玩。
最大虚拟内存区域问题
max virtual memory areas vm.max_map_count [256000] is too low, increase to at least [262144]
什么是VMA(virtual memory areas):
This file contains the maximum number of memory map areas a process may have. Memory map areas are used as a side-effect of calling malloc, directly by mmap and mprotect, and also when loading shared libraries.
While most applications need less than a thousand maps, certain programs, particularly malloc debuggers, may consume lots of them, e.g., up to one or two maps per allocation.
The default value is 65536
max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
解决:
# 临时设置
sysctl -w vm.max_map_count=262144
# 永久设置
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
虚拟内存最大大小问题
max size virtual memory [67108864] for user [es] is too low, increase to [unlimited]
分析:引用官网的说法
The segment files that are the components of individual shards and the translog generations that are components of the translog can get large (exceeding multiple gigabytes). On systems where the max size of files that can be created by the Elasticsearch process is limited, this can lead to failed writes. Therefore, the safest option here is that the max file size is unlimited and that is what the max file size bootstrap check enforces. To pass the max file check, you must configure your system to allow the Elasticsearch process the ability to write files of unlimited size.
解决:
echo "* - as unlimited" >> /etc/security/limits.conf
echo "root - as unlimited" >> /etc/security/limits.conf
参考: https://stackoverflow.com/questions/42510873/vm-max-map-count-is-too-low
最大文件描述符问题
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
分析:elasticsearch启动bootstrap checks要求系统打开最大系统文件描述符为65536
解决:
# 临时 ulimit -f unlimited
echo "* soft nofile 65536" >> /etc/security/limits.conf
echo "* hard nofile 65536" >> /etc/security/limits.conf
确认:
ulimit -Hn
ulimit -Sn
最大线程数问题
max number of threads [3818] for user [es] is too low, increase to at least [4096]
分析:elasticsearch启动bootstrap checks要求打开最大线程数最低为4096
解决:
echo "* soft nproc 65535" >> /etc/security/limits.conf
echo "* hard nproc 65535" >> /etc/security/limits.conf
注意:修改这里,普通用户
max user process值是不生效的,需要修改/etc/security/limits.d/20-nproc.conf文件中的值。Centos6系统的是是90-nproc.conf文件。
修改 /etc/security/limits.d/20-nproc.conf
* soft nproc 65535
系统总限制
其实上面的 max user processes 65535 的值也只是表象,普通用户最大进程数无法达到65535 ,因为用户的max user processes的值,最后是受全局的kernel.pid_max的值限制。
也就是说kernel.pid_max=1024 ,那么你用户的max user processes的值是65535 ,用户能打开的最大进程数还是1024。
# 临时生效
echo 65535 > /proc/sys/kernel/pid_max
sysctl -w kernel.pid_max=65535
# 永久生效
echo "kernel.pid_max = 65535" >> /etc/sysctl.conf
sysctl -p
然后重启机器生效。
参考: https://www.cnblogs.com/xidianzxm/p/11820706.html
确认:
ulimit -Hu
ulimit -Su
运行目录权限问题
Exception in thread "main" java.nio.file.AccessDeniedException: /opt/elasticsearch-6.2.2-1/config/jvm.options
分析: es用户没有该文件夹的权限
解决:
chown es.es /opt/elasticsearch-6.2.2-1 -R
如果还有碰到其他问题的同学,可以留言补充。
修改MySQL5.7.31用户登录密码
chris 发表了文章 0 个评论 2350 次浏览 2021-03-08 22:30

默认一般安装完成MySQL数据库root用户的密码为空,一般需要设置好root的密码,要不会造成不安全的情况发生。然而登录MySQL数据库后发现5.7版本跟5.6版本User表结构发生了变化,原本的password字段没有了,这就导致在5.7下面修改用户密码的方式跟之前的版本不同,下面会介绍2种修改方式。
1. 使用set password语句
这种方法跟以前的版本修改密码是一致的,需要登录到MySQL后使用:
set password for root@localhost = password("123.com");
2. 直接更新user表
由于MySQL版本的升级,User表的结构改变了,好多网上使用的UPDATE语句不适用新版本的表结构,在这里我通过DESC语句来查看User表的结构,结果如图:
mysql> desc User;
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Host | char(60) | NO | PRI | | |
| User | char(32) | NO | PRI | | |
| Select_priv | enum('N','Y') | NO | | N | |
| Insert_priv | enum('N','Y') | NO | | N | |
| Update_priv | enum('N','Y') | NO | | N | |
| Delete_priv | enum('N','Y') | NO | | N | |
| Create_priv | enum('N','Y') | NO | | N | |
| Drop_priv | enum('N','Y') | NO | | N | |
| Reload_priv | enum('N','Y') | NO | | N | |
| Shutdown_priv | enum('N','Y') | NO | | N | |
| Process_priv | enum('N','Y') | NO | | N | |
| File_priv | enum('N','Y') | NO | | N | |
| Grant_priv | enum('N','Y') | NO | | N | |
| References_priv | enum('N','Y') | NO | | N | |
| Index_priv | enum('N','Y') | NO | | N | |
| Alter_priv | enum('N','Y') | NO | | N | |
| Show_db_priv | enum('N','Y') | NO | | N | |
| Super_priv | enum('N','Y') | NO | | N | |
| Create_tmp_table_priv | enum('N','Y') | NO | | N | |
| Lock_tables_priv | enum('N','Y') | NO | | N | |
| Execute_priv | enum('N','Y') | NO | | N | |
| Repl_slave_priv | enum('N','Y') | NO | | N | |
| Repl_client_priv | enum('N','Y') | NO | | N | |
| Create_view_priv | enum('N','Y') | NO | | N | |
| Show_view_priv | enum('N','Y') | NO | | N | |
| Create_routine_priv | enum('N','Y') | NO | | N | |
| Alter_routine_priv | enum('N','Y') | NO | | N | |
| Create_user_priv | enum('N','Y') | NO | | N | |
| Event_priv | enum('N','Y') | NO | | N | |
| Trigger_priv | enum('N','Y') | NO | | N | |
| Create_tablespace_priv | enum('N','Y') | NO | | N | |
| ssl_type | enum('','ANY','X509','SPECIFIED') | NO | | | |
| ssl_cipher | blob | NO | | NULL | |
| x509_issuer | blob | NO | | NULL | |
| x509_subject | blob | NO | | NULL | |
| max_questions | int(11) unsigned | NO | | 0 | |
| max_updates | int(11) unsigned | NO | | 0 | |
| max_connections | int(11) unsigned | NO | | 0 | |
| max_user_connections | int(11) unsigned | NO | | 0 | |
| plugin | char(64) | NO | | mysql_native_password | |
| authentication_string | text | YES | | NULL | |
| password_expired | enum('N','Y') | NO | | N | |
| password_last_changed | timestamp | YES | | NULL | |
| password_lifetime | smallint(5) unsigned | YES | | NULL | |
| account_locked | enum('N','Y') | NO | | N | |
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
45 rows in set (0.00 sec)
如上发现了一些疑似用来认证的字段,根据字段类型推断authentication_string应该是存储的用户密码,之后就开始尝试修改这一字段:
update user set authentication_string = password('123.com') where user='root' and host='localhost';
更改后退出发现依然不会生效,通过查阅资料发现,还需要把plugin字段的值改为mysql_native_password。个人感觉这个字段影响的是验证方式,更改之后就可以在登录的时候使用刚刚设置的密码来验证。修改语句如下:
update user set plugin = 'mysql_native_password' where user='root' and host='localhost';
后来了解到mysql_native_password和caching_sha2_password是MySQL的两种加密认证方式,一般MySQL 5默认使用前者,而8以后的版本使用后者,在这里虽然笔者使用的是5.7.31,但我确实是在更改了这个字段值以后才能正常用密码登录的。
每日一题-Redis 哨兵机制
peanut 回复了问题 2 人关注 2 个回复 2782 次浏览 2020-11-20 10:36
每日一题-Redis 哨兵实例是不是越多越好?
空心菜 回复了问题 2 人关注 1 个回复 2384 次浏览 2020-11-20 10:29





